
Нужна ли разработчику математика? Если анализировать замеры производительности, то матстатистика понадобится. Но оказывается, о ней нужно знать не совсем то, что в учебниках. А что тогда?
Андрей Акиньшин @DreamWalker поговорил об этом в докладе на нашей конференции Heisenbug. И теперь, пока мы готовим следующий Heisenbug (где тоже будут доклады о производительности), решили опубликовать текстовую версию его выступления (а для тех, кому удобнее другие форматы, прикрепляем видеозапись и слайды). Предупреждаем: много букв, цифр, графиков и формул!
Содержание
Введение
Всем привет!
Меня зовут Андрей Акиньшин, и сегодня мы поговорим об описательной статистике перформанс-распределений.
В прошлой серии
Данная тема является продолжением моего прошлого доклада про перформанс-анализ, который я делал на конференции Heisenbug пару лет тому назад. Если вы еще не смотрели этот доклад, то обязательно посмотрите, а если смотрели, то давайте кратенько вспомним, о чем же шла речь.
Мы обсуждали тяжкую жизнь перформанс-инженера, который с утра до вечера решает перформанс-проблемы. Но стоит только разобраться с одной проблемой, сразу появляется другая, а за ней третья, четвертая и так далее.

Мы говорили о том, как же упростить жизнь нашего инженера и сделать процесс решения проблем более систематическим и контролируемым, а также по возможности сократить количество этих самых проблем.
Увы, серебряной пули тут не существует.
Потенциальное решение затрагивает множество аспектов разработки — от социально-менеджерских до инфраструктурно-девопсных. Но в центре такого решения находится набор инструментов, которые позволяют проводить надежные перформанс-исследования, писать стабильные перформанс-тесты, автоматически мониторить новые перформанс-проблемы и много чего еще. И для всех этих инструментов нам нужен специальный набор методов математической статистики.
Казалось бы, статистика существует уже давно, все нужные формулы уже явно придуманы, нужно их просто взять и реализовать. Увы, на деле основная часть классического матстата нам не очень подходит. И сегодня мы будем обсуждать, почему так и что с этим делать.
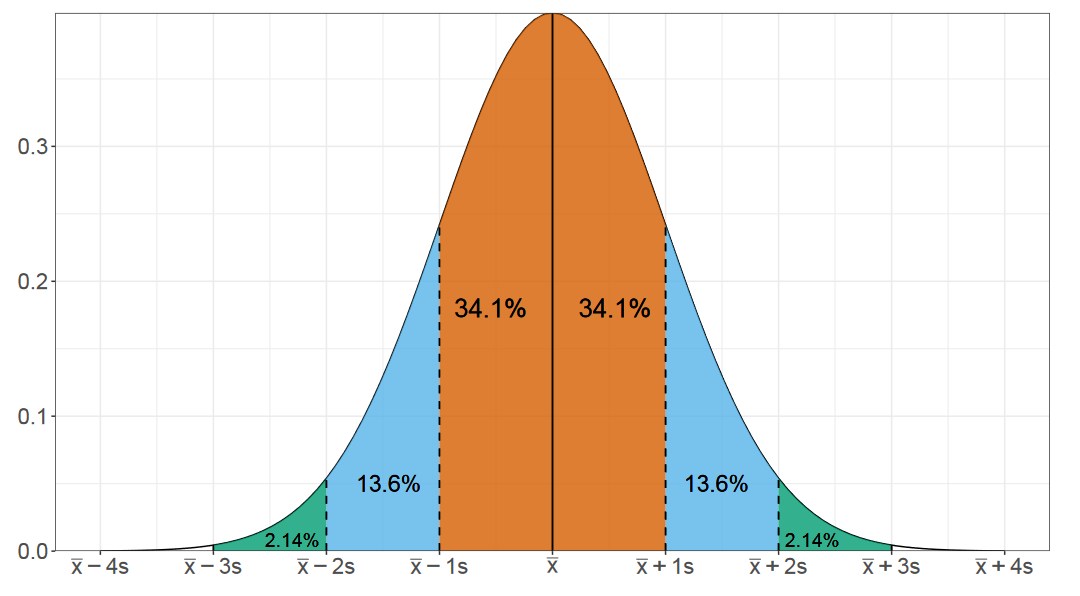
Нормальное распределение
И начнем мы разговор с нормального распределения. Наверняка вы видели подобную картинку в разных учебниках. Это распределение очень хорошо изучено. Существуют сотни методов, чтобы делать с ним самые разные вещи.
Нормальность — миф: в реальности никогда не было и не будет нормального распределения.
"Testing for normality", R.C. Geary, 1947
Но, увы, в реальности нормальное распределение можно встретить не так уж и часто. Особенно в перформанс-анализе.
Справедливости ради нужно сказать, что в нанобенчмаркинге что-то похожее на нормальное распределение действительно часто возникает. Но как только мы переходим хотя бы к микробенчмаркингу, как только у нас появляются операции или с диском, или с сетью, или хотя бы с оперативной памятью, то перформанс-распределения перестают напоминать нормальную картинку.
Обманчивые средние и дисперсия
Нормальное распределение описывается двумя параметрами: средним значением и стандартным отклонением. Но в случае ненормальных распределений эти параметры для нас не очень полезны, т.к. они не способны описать форму распределения.
На прошлом докладе мы также обсуждали замечательный пример из статьи 2017 года, в которой приводились разные наборы точек, для которых совпадают значения средних значений и дисперсий по x и y, а также коэффициент корреляции между двумя координатами.

Как мы видим, два числа не очень годятся для описания произвольных распределений. Тут нужно понимать, что если нам повезло получить что-то похожее на нормальное распределение, то мы действительно можем обойтись средним и дисперсией. Но такой подход не работает в общем случае.
Давайте посмотрим как выглядят типичные перформанс-распределения из реальной жизни.
Самопальный IO-бенчмарк
Для этого напишем простой самопальный бенчмарк на C#, который работает с диском. Я намеренно не стал использовать специальные библиотеки для бенчмаркинга, чтобы посмотреть на настоящие честные сырые данные.
В нашем бенчмарке мы будем делать 1000 итераций, внутри которых будем создавать файл на 64MB.
int N = 1000; // Количество итераций
var measurements = new long[N];
byte[] data = new byte[64 * 1024 * 1024]; // 64MB
for (int i = 0; i < N; i++)
{
var stopwatch = Stopwatch.StartNew();
var fileName = Path.GetTempFileName();
File.WriteAllBytes(fileName, data);
File.Delete(fileName);
stopwatch.Stop();
measurements[i] = stopwatch.ElapsedMilliseconds;
}Код максимально простой: N раз мы создаем файл на диске, пишем туда 64MB, а затем удаляем этот файл. Каждую итерацию замеряем и сохраняем результаты замеров. Далее мы запускаем этот код на операционной системе Windows и начинаем наслаждаться результатами.
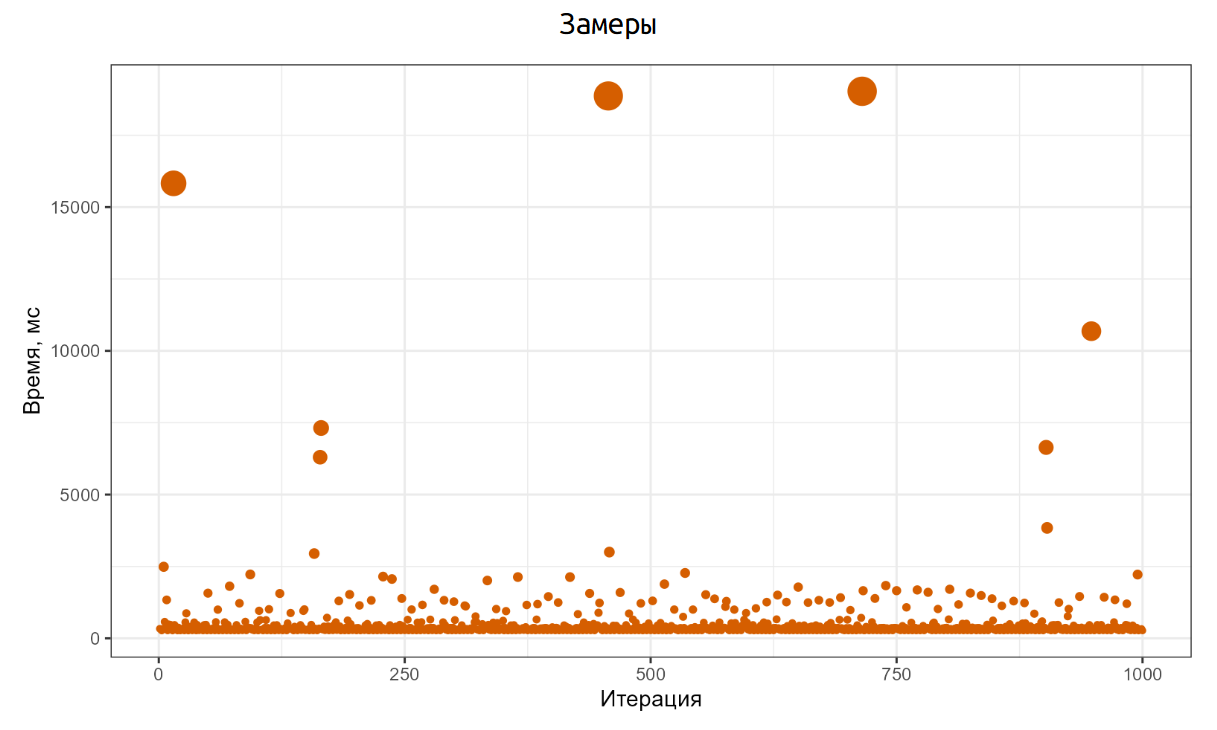
Вот как эти результаты выглядят. Основная часть итераций прошла примерно на 200ms, но есть отдельные итерации, которые заняли 15-16 секунд. И это та реальность, с которой нам нужно научиться работать.
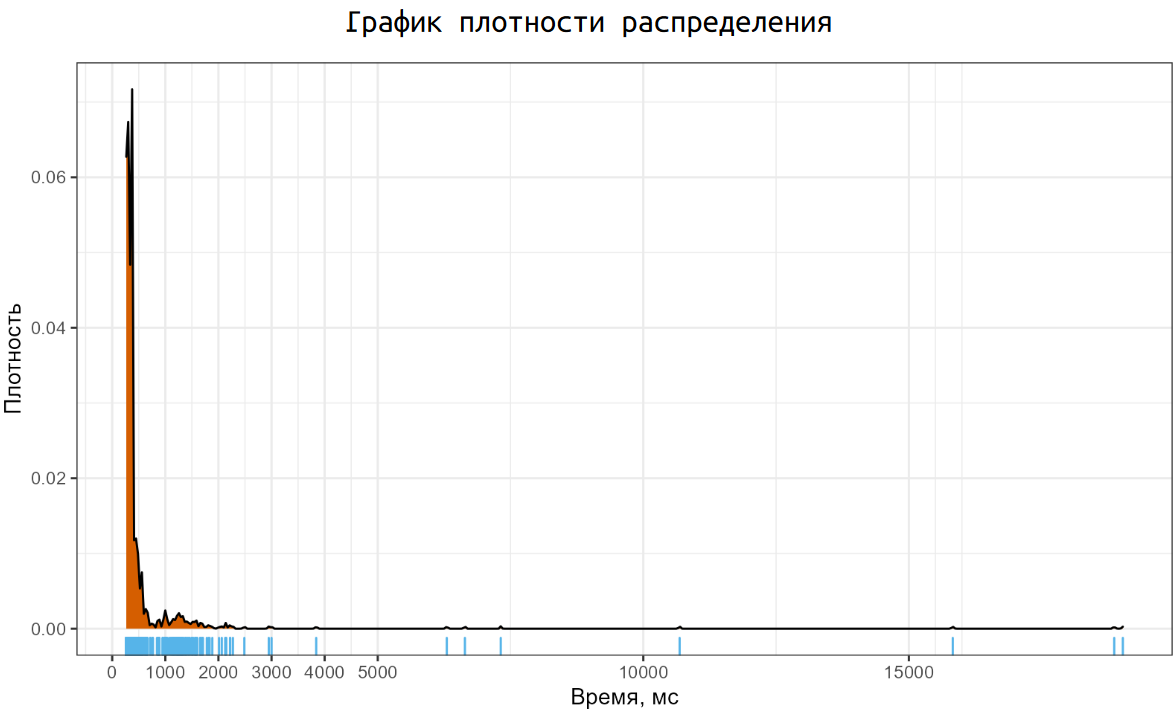
Соответствующий график плотность распределения выглядит не очень приятно. У нас есть одна большая мода около 200ms, маленькая мода между одной и двумя секундами, а также некоторое количество неприлично больших выбросов. И такой график мы получили на одной простой операции по созданию файла. А если рассматривать распределения замеров с реальных систем, то там можно найти намного более страшные картинки.
Основные проблемы
Давайте кратко пробежимся по основным проблемам, которые у нас есть:
Замеры не локализованы в небольшой окрестности, они могут быть размазаны по числовой оси и покрывать большой интервал значений.
У рассматриваемых распределений зачастую тяжелые хвосты, которые дают экстремальные выбросы.
Многие распределения имеют несколько мод.
Иногда проявляются эффекты дискретизации, когда непрерывные распределения начинают потихоньку превращаться в дискретные.
Распределения чаще всего сильно асимметричные, что добавляет некоторое количество проблем.
В этой серии
Итак, о чем же мы будем говорить сегодня? Мы будем обсуждать описательную статистику, а именно: мы будем учиться описывать перформанс-распределения с помощью набора некоторых метрик.
Более конкретно мы обсудим:
центральную тенденцию;
квантильные оценки;
вариацию;
графики плотности распределений;
мультимодальность;
теорию экстремальных значений, которая может помочь в оценке экстремальных квантилей.
Увы, мы не успеем поговорить о сравнении разных распределений и написании стабильных перформанс-тестов, так как этих базовых тем для одного доклада и так уже очень много.
Предупреждение
Данный доклад является чисто математическим. Мы не будем обсуждать программирование, бенчмаркинг, автоматизацию и прочие темы, мы сосредоточимся исключительно на описательной статистике.
Если вы заинтересовались, то давайте вместе отправимся в увлекательный мир математической статистики:
Зачем?
Прежде чем мы начнем, хочу сказать еще пару слов на тему того, зачем все это нужно.
Последние девять лет я мейнтейню библиотеку BecnhmarkDotNet, которая позволяет просто писать надежные .NET-бенчмарки.

На текущий момент библиотека очень популярна: у нас есть тысячи звездочек на GitHub и десятки тысяч пользователей — от маленьких утилит до самого .NET-рантайма.
Как правило, результаты BenchmarkDotNet довольно надежны, но иногда случаются статистические казусы, и результаты могут быть не до конца понятными, что приведет к искаженному представлению об истинном перформансе ваших бенчмарков. Сейчас я работаю над новым статистическим движком, который должен значительно уменьшить вероятность возникновения подобных казусов.
А еще у меня есть проект Perfolizer, в котором я собираю разные математические алгоритмы для надежного перформанс-анализа.

Пока что еще проект все еще на ранних этапах своего развития, но однажды он должен стать основной для создания стабильных перформанс-тестов и систем перформанс-мониторинга.
Однако, даже если у вас есть набор готовых инструментов и методов для анализа, но вы не понимаете устройства перформанс-распределений и связанных с ней проблем, то использовать эти инструменты будет не так уж и просто.
Давайте разбираться что же такого там сложного.
Центральная тенденция
Начнем мы с центральной тенденции. Этот термин выражает естественное желание человека сжать сложное перформанс-распределение до одного единственного числа.
Как же это сделать?
Среднее арифметическое
Самый простой и классический вариант центральной тенденции — это среднее арифметическое. Если у нас есть выборка из n чисел, то мы можем просто сложить все эти числа и поделить сумму на их количество.
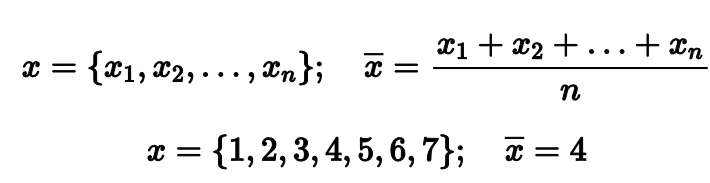
Например, если мы возьмем выборку из первых семи натуральных чисел, то среднее арифметическое будет равно четырем. Довольно ожидаемый хороший результат.
Но стоит в выборке оказаться одному-единственному выбросу, как среднее арифметическое перестает быть надежным показателем центральной тенденции. Если в нашем примере заменить 7 на 273, то среднее станет равняться 42. Согласитесь, это не лучшее описание того, что происходит у нас в распределении.
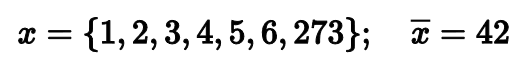
Математики говорят, что среднее арифметическое не является робастным. Это значит, что оно не устойчиво к выбросам. Хватит одного-единственного экстремально большого значения, чтобы полностью испортить результат.
При обсуждении этой проблемы классическое простое решение заключается в использовании медианы. Давайте попробуем!
Среднее арифметическое vs. медиана
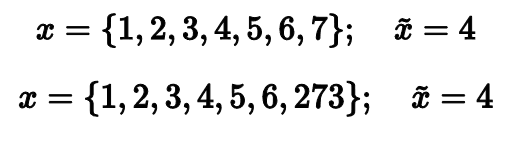
Действительно, медиана обеих выборок равна четырем, что вполне соответствует нашим ожиданиям. Может, на этом стоит и закончить? Давайте всегда использовать медиану вместо среднего арифметического и будет нам счастье!
Увы, такое счастье будет неполным. Замена среднего медианой не проходит бесплатно. Но чтобы понять сопутствующие проблемы, нам нужно обсудить такое понятие, как Гауссова эффективность.
Гауссова эффективность
Рассмотрим следующий эксперимент.
Сгенерируем много выборок из нормального распределения. Для каждой выборки посчитаем среднее арифметическое и медиану, а затем из полученных значений построим новые распределения.
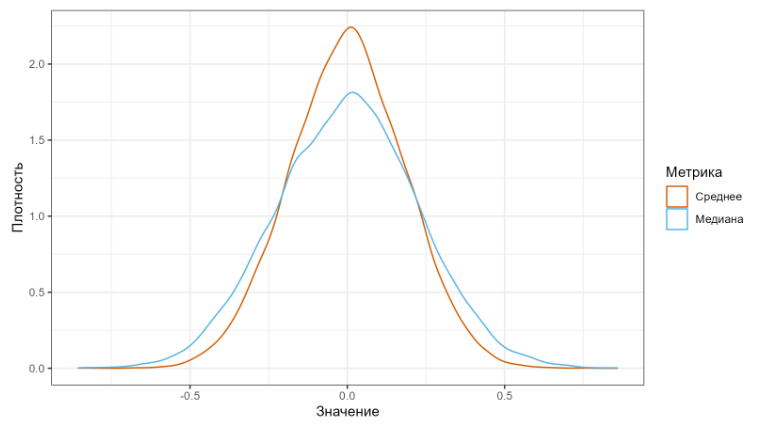
Как вы можете заметить, разброс медианных значений выше, чем разброс значений среднего арифметического.
Чтобы описать разницу между разбросами, математики придумали понятие эффективности.
Для расчета эффективности некоторой оценки T нужно посчитать дисперсию значений среднего арифметического и поделить на дисперсию значений рассматриваемой оценки.
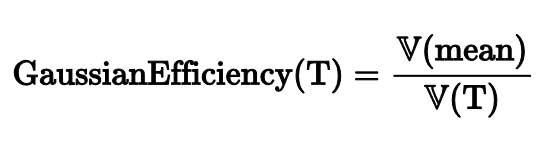
Среднее |
Медиана |
|
Гауссова эффективность |
100% |
64% |
Для среднего арифметического эффективность равна 100%, так как среднее выступает в роли T. Но если рассмотреть медиану, то ее эффективность равна всего лишь 64%. Это означает, что при замене среднего на медиану результаты наших расчетов начнут сильнее плавать от одного эксперимента к другому.
Это не очень приятно, но такова цена робастности.
Усеченное и винзоризованное среднее
Есть много альтернативных методов расчета центральной тенденции. Другими классическими примерами являются усеченное и винзоризованные средние.
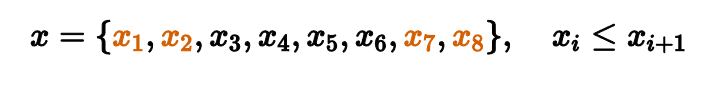
Рассмотрим выборку из восьми отсортированных чисел. Для подсчета медианы нам нужно выкинуть все элементы кроме одного-двух, которые находятся посередине. Таким образом мы повышаем робастность, но понижаем эффективность.
Но что, если мы выкинем только несколько самых маленьких и самых больших значений, а затем посчитаем среднее арифметическое от того, что осталось?
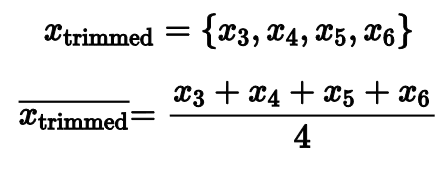
Именно таким образом работает усеченное среднее. Этот способ более робастный, чем обычное среднее, и более эффективный, чем медиана.
Есть еще один альтернативный вариант, который называется винзоризованное среднее. В этом подходе самые маленькие и самые большие элементы не выкидываются, а заменяются на другие элементы.
В нашем примере мы заменяем х₁ и х₂ на x₃, а x₇ и x₈ на x₆.

Далее мы считаем обычное среднее арифметическое для того, что осталось.
Оба подхода имеют место быть, они дают предсказуемые значения робастности и эффективности. Но зачастую они оказываются не очень оптимальными. Если мы выкидываем или винзоризируем фиксированное количество элементов, то это количество чаще всего оказывается либо слишком маленьким, либо слишком большим.
Тут может появиться желание сделать более адаптивный подход. Если среднее арифметическое портится от выбросов, то, может, нам просто найти эти выбросы и выбросить их из выборки? Давайте попробуем.
Выбрасываем выбросы
Как же нам найти выбросы?

Если мы погуглим, то по первым ссылкам нам скорее всего предложат использовать границы Тьюки. Это простая формула, которая очерчивает некоторый интервал и объявляет выбросами все элементы выборки вне интервала. На простых академических примерах это работает неплохо, но в реальной жизни нам начнут встречаться проблемы: чаще всего обычные нормальные элементы выборки помечаются как выбросы, что уменьшает Гауссову эффективность подхода. Но если ослабить условия интервала, то мы начнем пропускать важные выбросы, что поломает нам всю робастность.
Если мы поищем альтернативным способы обнаружения выбросов, то обнаружим, что есть сотни разных методов, которые решают эту задачу.
Но мне в целом не очень нравится такой подход.
Во-первых, детекторы выбросов зачастую не очень стабильно работают.
Во-вторых, очень сложно нормально оценить реальные характеристики таких подходов и построить предсказуемую модель анализа.
В-третьих, выбросы являются неотъемлемой частью самого распределения, в которой заключается важная и полезная информация.
Игра в выбрасывание выбросов может легко увести нас в плохую сторону. Я хочу проиллюстрировать важность выбросов одним интересным примером. Он взят из книжки Кэндела 1991 года про изменения климата. И хотя на деле все было не совсем так, он все еще показателен.
Важность выбросов
Об открытии озоновой дыры было объявлено в 1985 году британской командой, работавшей на земле с «обычными» приборами и изучившей свои наблюдения в деталях. Только позже, после повторного изучения данных, переданных прибором TOMS на спутнике NASA Nimbus 7, выяснилось, что дыра формировалась в течение нескольких лет. Почему никто не заметил ее? Причина проста: системы, обрабатывающие данные TOMS, разработанные в соответствии с предсказаниями, полученными из моделей, которые которые, в свою очередь, были созданы на основе того, что считалось «разумным», отвергли очень («чрезмерно») низкие значения, наблюдаемые над Антарктикой во время южной весны. Что касается программы, то, должно быть, в приборе имелся эксплуатационный дефект.
R. Kadnel, Our Changing Climate (1991)
Автор рассказывает историю о том, как 1985 году общественности анонсировали существование дыр в озоновом слое. Однако, данные, которые позволили это сделать, были в наличии уже несколько лет. Почему же эти дыры не обнаружили раньше? Все очень просто. В алгоритме анализа данных ребята решили не учитывать выбросы. Видим слишком низкое значение — убираем его из рассмотрения, чтобы наши средние характеристики не портились. Но если выкидывать из рассмотрения аномальные значения, то обнаруживать аномалии резко становится сложнее. Аналогичная ситуация имеет место быть в мире перформанс‑замеров.
Скажем, если вы будете игнорировать упавшие по таймауту запросы, чтобы у вас не портилось среднее значение обработки запроса, то вы никогда не найдете проблему, из-за которой эти таймауты возникают.
Какая метрика нам нужна?
Среднее значение — это не всегда то значение, которое нам на самом деле нужно.
Давайте взглянем на распределение Парето. Это то самое распределение, которое описывает ситуации вроде тех, что 20% людей имеют 80% доходов, или что 20% усилий дают 80% результата. Если мы в таком распределении попробуем посчитать среднее арифметическое, то получим довольно большое число, которые язык не поворачивается называть средним.
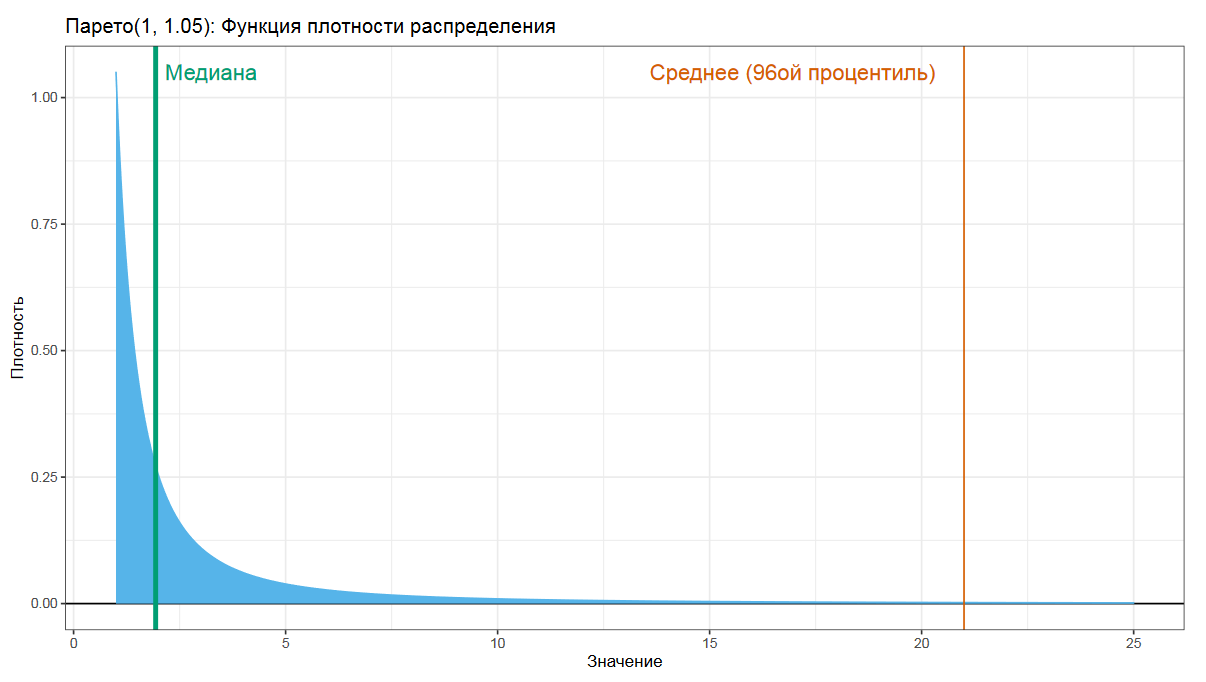
Другое дело — медиана, которая по определению разделяет распределения на две равные части.
При выборе метрики центральной тенденции важно понимать, что мы хотим получить и зачем.
Кроме вариаций средних и медиан есть и другие метрики, которые оценивают центральную тенденцию.
Оценка Ходжеса-Леманна
Я не буду перечислять их все, но мне хочется сказать пару слов про оценку Ходжеса-Леманна, т.к. она обладает интересными свойствами.
Оценка строится очень просто: нужно рассмотреть все пары чисел из нашей выборки, для каждой пары посчитать среднее арифметическое, а затем из полученных средних выбрать медиану.
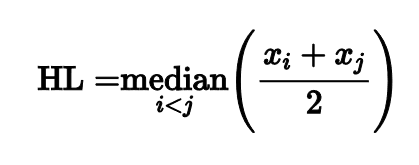
Такой незамысловатый подход дает оценку с интересными свойствами.
Сравнение
Асимптотическая Гауссова эффективность Ходжеса-Леманна 96%. Она почти не уступает среднему арифметическому.
Среднее |
Медиана |
Ходжес-Леманн |
|
Гауссова эффективность |
100% |
64% |
96% |
«Но что там с робастностью?» — спросите вы.
Для оценки робастности есть еще одна полезная метрика под названием точка перелома (на английском breakdown point). Она характеризует процент выборки, который мы можем заменить произвольно большими значениями, чтобы при этом сама оценка не попортилась.
Точка перелома среднего арифметического — 0%, т.к. один единственный элемент может полностью исказить оценку среднего.
Точка перелома медианы — 50%, т.к. мы можем произвольно менять половину чисел в выборке без изменения значения медианы.
А вот для Ходжеса-Леманна точка перелома 29%, что довольно хорошее значение с практической точки зрения.
Среднее |
Медиана |
Ходжес-Леманн |
|
Гауссова эффективность |
100% |
64% |
96% |
Точка перелома |
0% |
50% |
29% |
Действительно, если 29% выборки составляют экстремальные выбросы, то это уже не совсем выбросы, это отдельная группа замеров, которую нужно отдельно изучать и описывать.
При этом 96% — очень хорошая Гауссова эффективность, что делает Ходжеса-Леманна достойной заменой среднему арифметическому как на околонормальных распределениях, так и на распределениях произвольной формы.
Другие метрики
Есть много других интересных метрик для описания центральной тенденции:

И многие другие метрики, для каждой из которых найдутся релевантные сценарии использования.
Вывод
Хотелось бы подчеркнуть основную мысль. Для выбора центральной тенденции нужно хорошо подумать. Подумать о том, зачем вы считаете эту метрику, какие у нее статистические характеристики, на каких распределениях вы будете ее считать.
Только с учетом всех явных и неявных бизнес-требований можно принять разумное решение. Простые подходы вроде «я где-то слышал, что нормальные ребята считают медиану, поэтому давайте мы тоже будем считать медиану» редко дают оптимальный результат.
Мы переходим к нашей следующей теме под названием «квантильные оценки».
Квантильные оценки
Чтобы лучше понять предмет обсуждения, давайте взглянем на график плотности некоторого распределения.
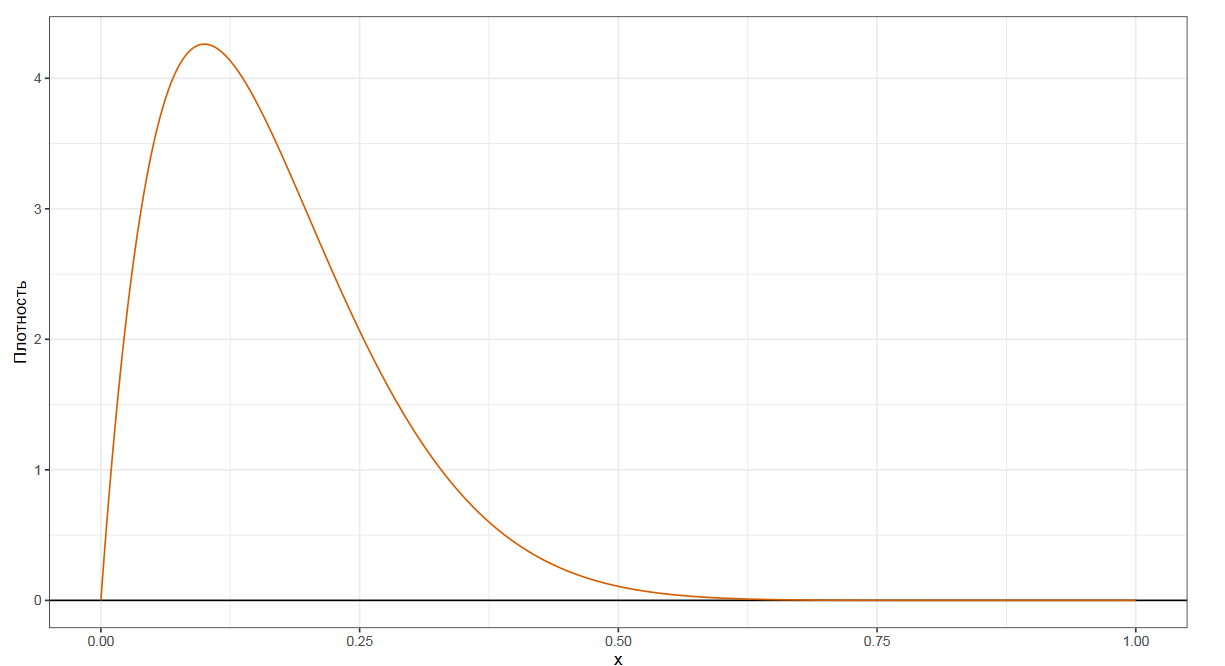
Мы уже знакомы с самой популярной квантильной оценкой — медианой. Она делит наше распределение на две равные части. Если взять случайное число из распределения, то в 50% случаев оно будет ниже медианы, а в других 50% случаев — выше медианы.
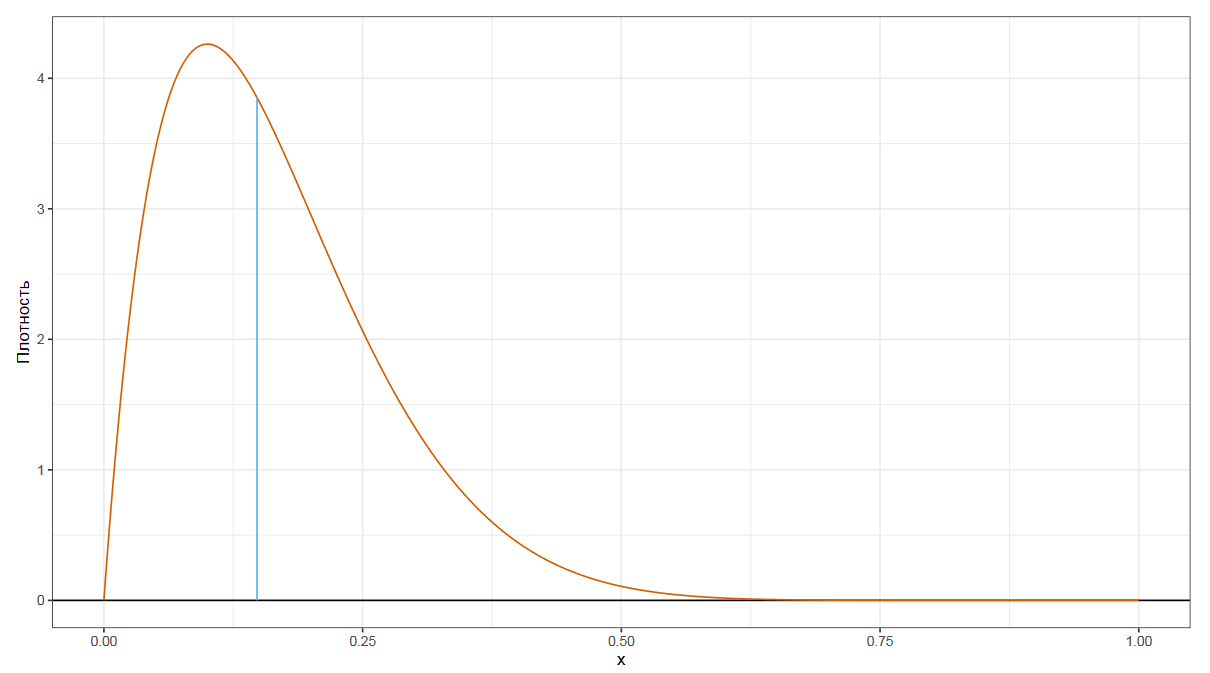
Следующим по популярности видом квантильных оценок являются квартили. Это три числа, которые делят распределение на четыре равные части.
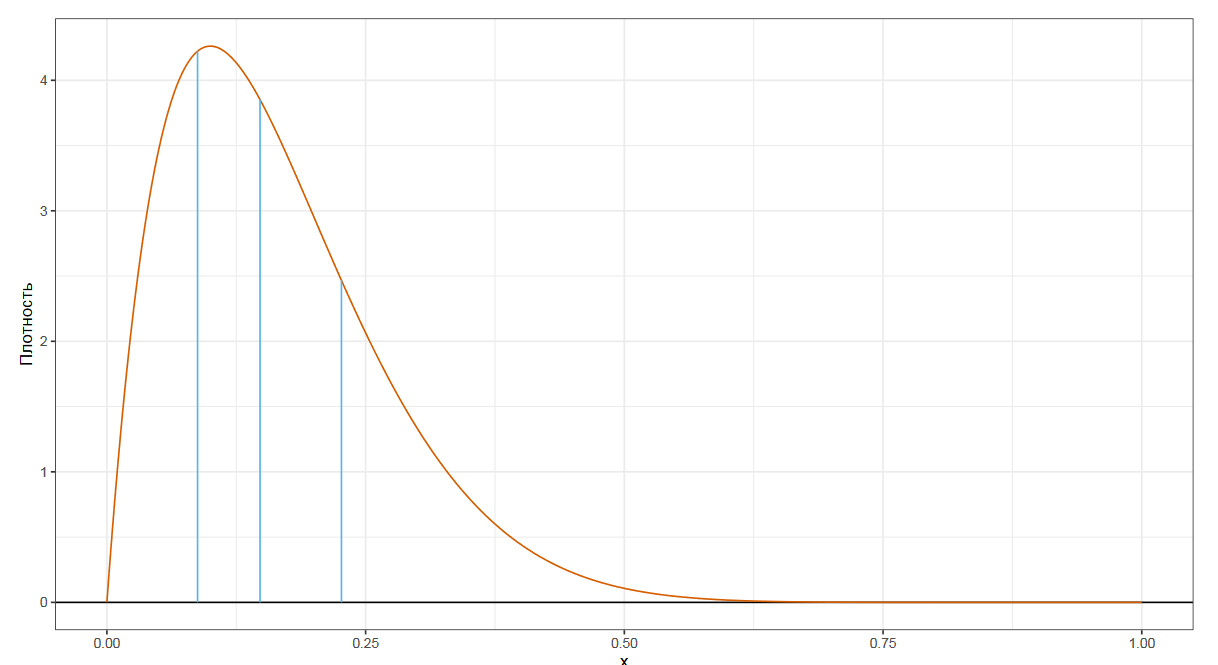
Еще мы можем рассмотреть децили, которые делят распределение на десять равных частей.
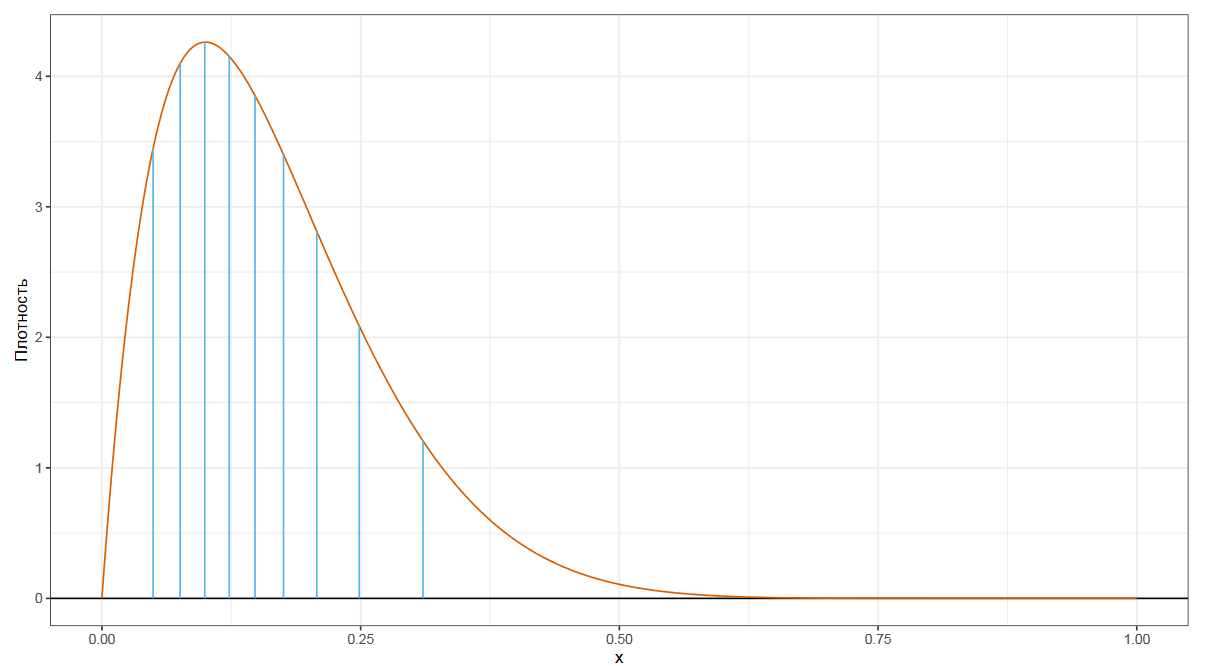
Процентили делят распределение на сто равных частей.
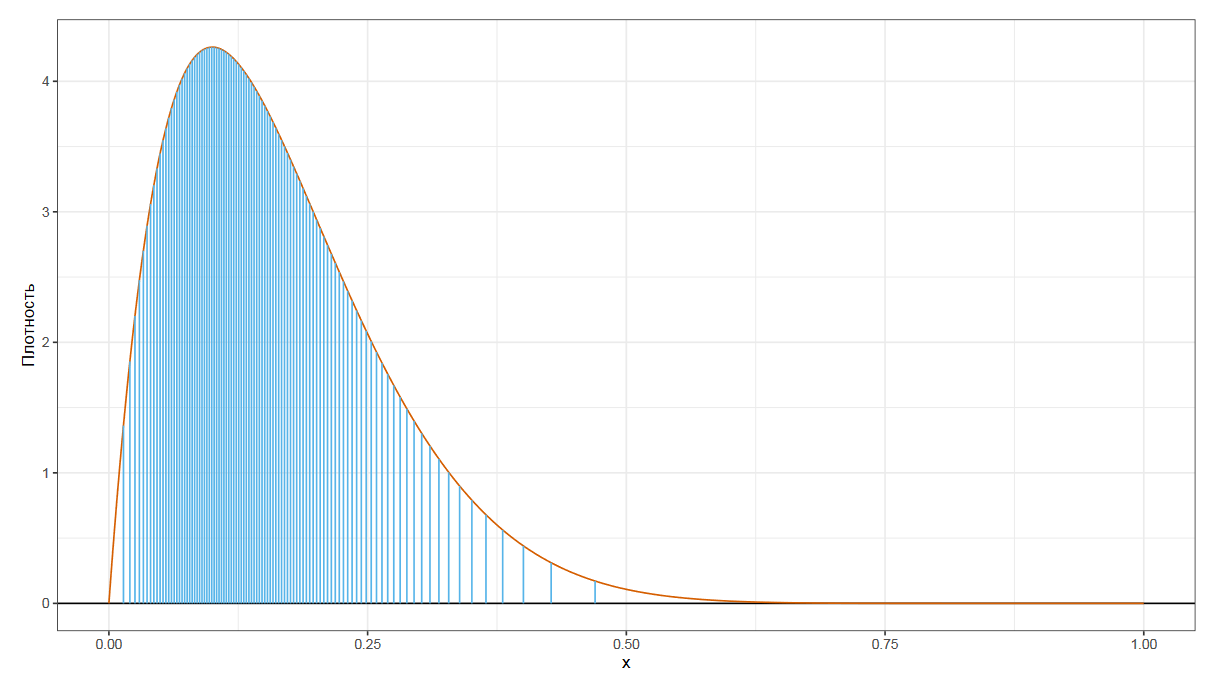
Квантили — это обобщение для вышеобозначенных понятий.
Квантиль порядка p — это такое число, для которого случайное число из данного распределения с вероятностью p оказывается ниже значения p-ого квантиля, и с вероятностью 1-p выше него.
Квантили распределения и квантили выборки
Стоит различать истинные квантили распределения и квантильные оценки, основанные на некоторой выборке. Чтобы лучше понять разницу, давайте рассмотрим небольшую выборку из нормального распределения.

Для данной выборки мы можем посчитать квартили стандартным способом, которому обычно обучают в школе или на первых курсах университета.
К стандартным трем квартилям, которые также являются 25-м, 50-м и 75-м процентилями, часто добавляют так называемые нулевой и сотый процентили, которые соответствуют минимуму и максимуму. Формально так делать нельзя, но такая нотация довольно часто используется на практике.
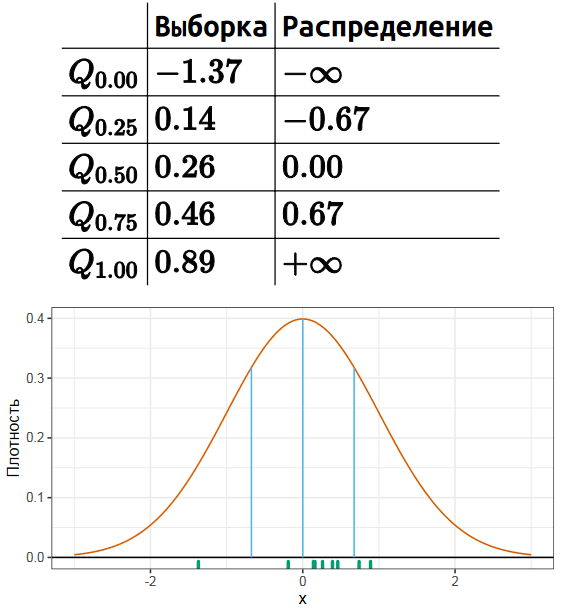
Теперь мы сравним эти числа с истинными значениями соответствующих квартилей распределения. Нетрудно заметить, что они не совпадают. Квантили некоторого распределения всегда фиксированы и являются способом описания этого распределения. А квантили выборки меняются от эксперимента к эксперименту.
Поэтому полное название этих чисел — не квантили, а квантильные оценки. Это попытка оценить истинные квантили распределения по той выборке, которая у нас есть. Но попытка не совсем точная, т.к. конечная случайная выборка не содержит достаточно данных, чтобы точно узнать истинные значения. При этом можно придумать много разных способов угадать истинное значение по данной выборке.
Строго говоря, любая функция из выборки в число может быть рассмотрена как квантильная оценка или оценка любой другой характеристики распределения. Существует некоторое количество стандартных квантильных оценок.
Классификация Хиндмана-Фана
В разных библиотеках можно найти различные варианты квантильных оценок. Если вы попробуете посчитать медиану и прочие квантили с помощью разных библиотек, пакетов, языков программирования или статистических программ, то вы можете получить разные результаты.
В 1996 году Хиндман и Фан сделали обзор формул, которые используются в разных статистических пакетах. Они выделили девять типов классических квантильных оценок.

В настоящее время самым популярным типом является седьмой — он используется по умолчанию в большинстве современных библиотек и статистических пакетов.
Все эти оценки основаны либо на одной порядковой статистике, либо на линейной комбинации двух последовательных порядковых статистик. i‑й порядковой статистикой называется i‑й элемент выборке после сортировки.
Главные достоинства представленных формул — их простота и быстрота. Если у вас есть отсортированная выборка, то квантильную оценку можно получить за O(1), используя одну тривиальную строчку кода.
Однако данные формулы не всегда дают самый эффективный способ оценки истинных квантилей. Давайте поговорим об альтернативных способах.
Квантильная оценка Харрела-Дэвиса
Мой самый любимый — это квантильная оценка Харрела-Дэвиса. Она рассчитывается как взвешенная сумма всех порядковых статистик.
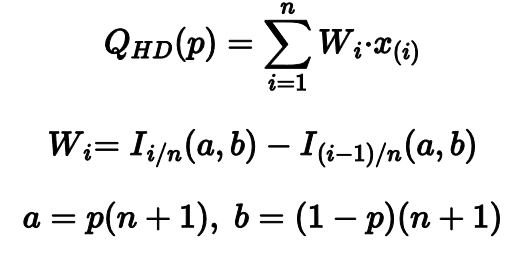
Весовые коэффициенты определяются на основе регулязированной неполной бета-функции. Это может выглядеть сложновато, но основная идея довольная простая.
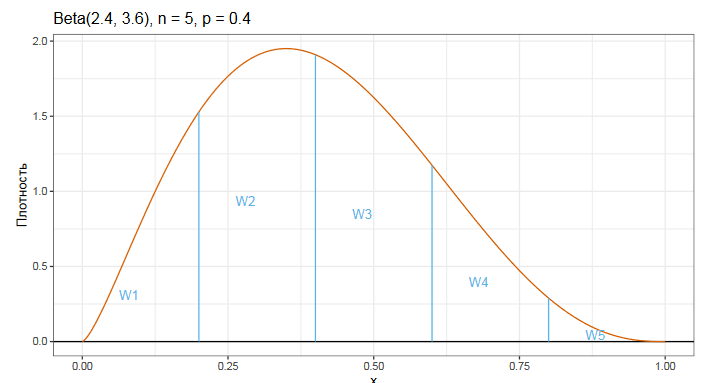
На основе порядка квантиля p и размера выборки n строится бета‑распределение. Дальше это распределение делится на n сегментов, равных по ширине.
Можно использовать следующую интуитивную модель: площадь i‑го фрагмента соответствует вероятности того, что p‑ый квантиль совпал с i‑ой порядковой статистикой.
Таким образом, мы для каждой порядковой статистики определяем вероятность W, с которой эта статистика и является искомым квантилем. Далее строится что‑то вроде математического ожидания по всем порядковым статистикам, что и дает нам итоговую квантильную оценку.
Эффективность квантильной оценки Харрела-Дэвиса
Давайте посмотрим на эффективность оценки Харрела-Дэвиса по отношению к классической оценки Хиндмана-Фана седьмого типа.
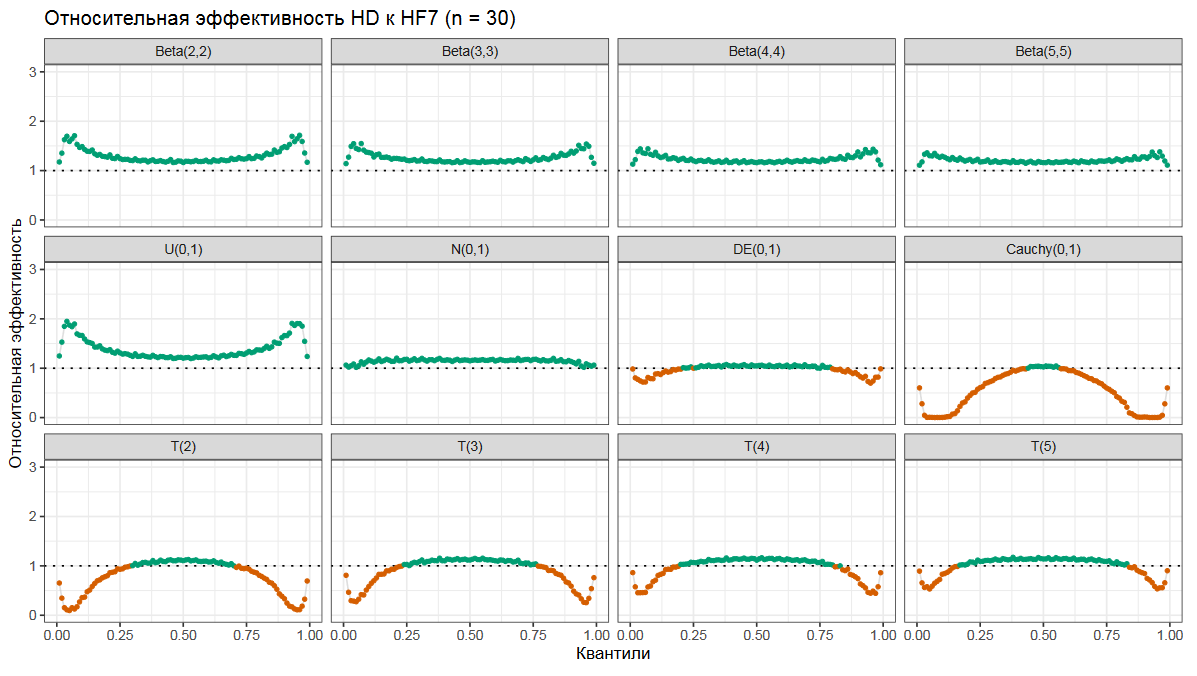
Тут на оси x находятся порядки квантилей, на оси y — относительная эффективность. Когда относительная эффективность больше единицы (что показано зеленым цветом), то это означает, что Харрел-Дэвис победил и оказался более эффективным. Когда относительная эффективность больше единицы (что показано оранжевым цветом), то Харрел-Дэвис проиграл и оказался менее эффективным.
На разных графиках показаны результаты для разных распределений. У нас есть несколько бета-распределений, равномерное распределение, нормальное распределение, двойное экспоненциальное распределение, распределение Коши и несколько Стьюдент-распределений.
Как можно видеть, оценка Харрела-Дэвиса обычно оказывается более эффективной для расчета медианы, но она не всегда эффективна в хвостах распределения.
Доверительные интервалы Мэритц-Джэррэт
Рассмотренный подход с бета-распределением позволяет делать другие интересные вещи. Например, мы можем рассчитывать доверительные интервалы квантильных оценок.
Для этого мы можем рассмотреть моменты квантильных оценок. Для расчета k-ого момента нужно взять весовые коэффициенты W, которые используются для расчета оценки Харрела-Дэвиса, но умножать мы их будем не просто на i-ую порядковую статистику, а на i-ую порядковую статистику в k-ой степени.
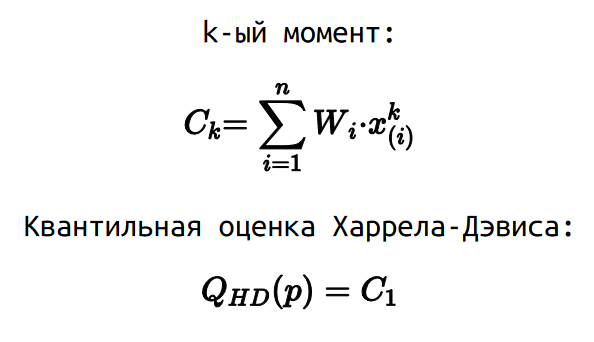
В данной нотации квантильная оценка Харрела-Дэвиса — это просто первый момент. В 1978 году Мэритц и Джэррэт показали, что можно рассчитать стандартную квантильную ошибку как квадратный корень из разницы второго момента и квадрата первого момента.
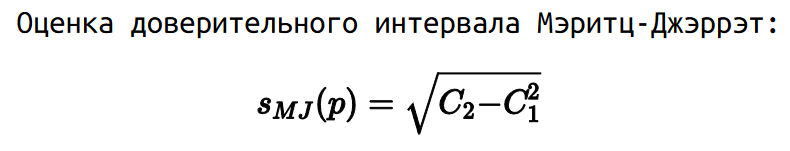
Ну а на основе стандартной ошибки можно стандартным способом рассчитать доверительный интервал.
Можно делать и другие интересные штуки. Позвольте мне представить авторскую разработку под названием усеченная квантильная оценка Харрела-Дэвиса.
Усеченная квантильная оценка Харрела-Дэвиса
У классической оценки Харрела-Дэвиса есть один недостаток: она не робастная. Так как она использует взвешенную сумму всех элементов выборке, то одно экстремальное значение может испортить все квантильные оценки. Это неприятная цена, которую приходится платить за повышенную статистическую эффективность.
Давайте внимательно посмотрим на бета-распределение, которое определяет весовые коэффициенты порядковых статистик для медианы по Харрелу-Дэвису.
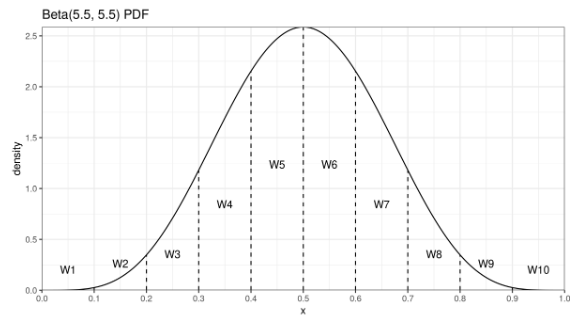
У центральных порядковых статистик веса довольно большие, а у хвостовых порядковых статистик — маленькие. Если мы немножко подумаем, то поймем, что хвостовые порядковые статистики практически не влияют на эффективность, но при этом практически полностью уничтожают робастность.
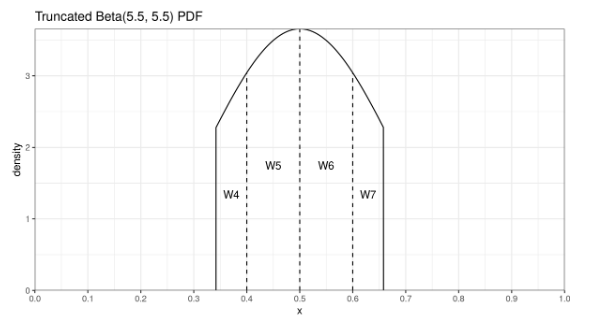
При расчете усеченного варианта оценки мы отбрасываем элементы с малыми весовыми коэффициентами и используем только порядковые статистики с большими весами. В итоге мы совсем чуть-чуть теряем в эффективности, но зато заметно улучшаем робастность. А еще этот способ быстрее с вычислительной точки зрения, т.к. нам нужно вычислять меньше значений регулязированной неполной бета-функции.
Такой подход очень хорошо зарекомендовал себя на практике. Когда мне нужно эффективно вычислить медиану, то чаще всего я беру именно усеченную оценку Харрела-Дэвиса.
Квантильная оценка Сфакианакиса-Виргиниса
Есть и другие способы расчета квантильных оценок. Как мы видели, оценка Харрела-Дэвиса часто бывает не очень эффективна для хвостовых квантильных оценок. В 2008 году Сфакианакис и Виргинс попробовали побороть эту проблему. Они предложили три новых варианта квантильных оценок.
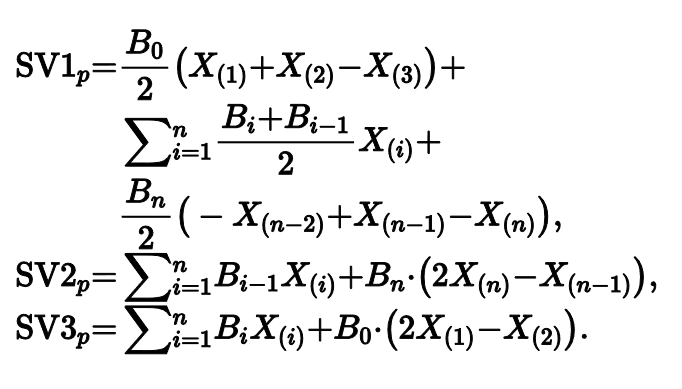
Общая идея похожа на подход Харрела-Дэвиса, но вместо бета-распределения используется биномиальное распределение. Плюс есть специальная коррекция, призванная увеличить эффективность оценок в хвостах.
Квантильная оценка Навруза-Оздемира
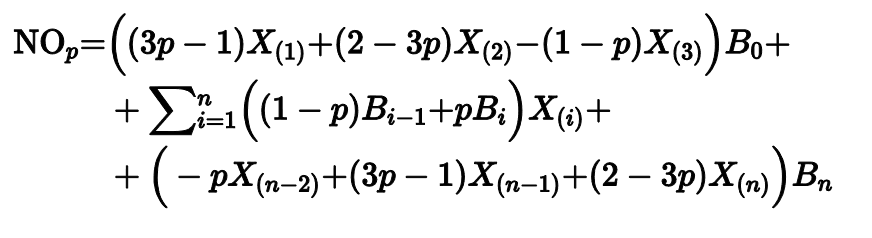
Другим вариантом этого подхода является оценка Навруза-Оздемира, предложенная в 2020 году.
Подробнее о ней можно прочитать здесь.
Проблема: агрегация истории коммитов
С квантильными оценками можно много играться, приспосабливая их к различным задачам. Давайте рассмотрим проблему агрегации истории коммитов.
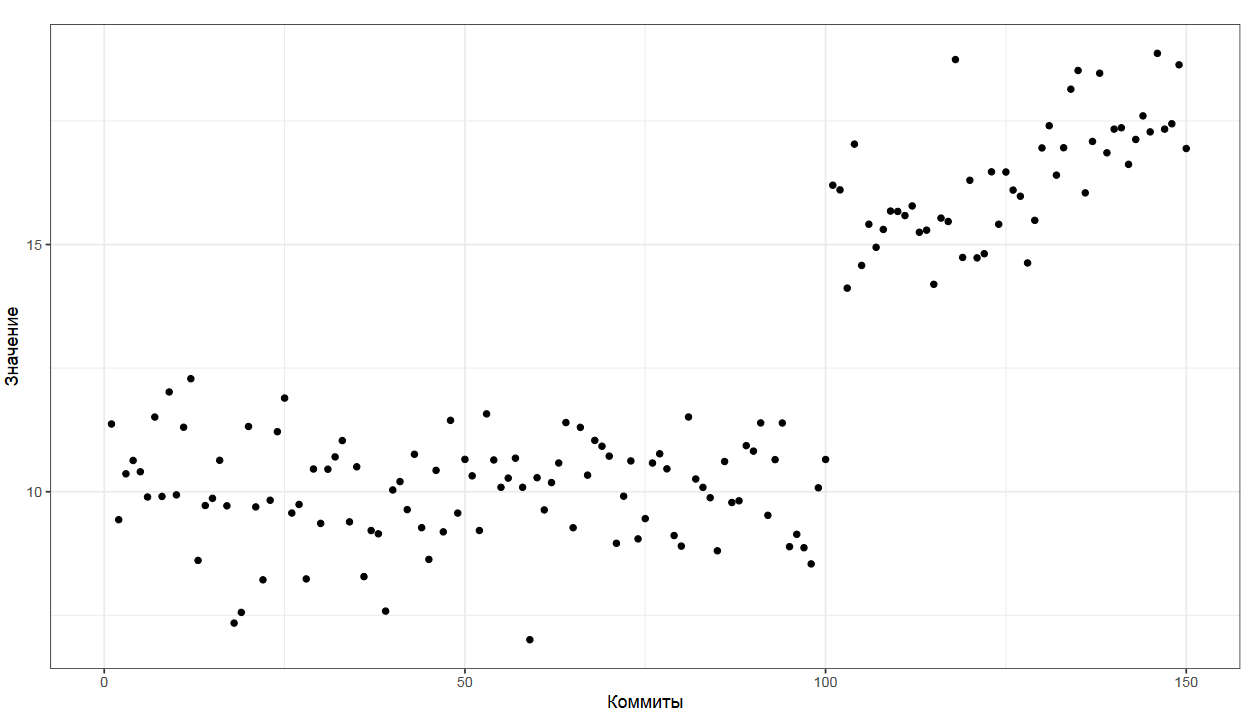
Представьте, что у вас есть некоторый метод, перформанс которого вы замеряете один раз на каждый коммит. Вам хочется получить описание распределения, которое у вас есть прямо сейчас для последнего коммита в истории. Но для этого коммита у вас есть только один замер, которого явно недостаточно, чтобы построить распределение.
Можно взять последние n коммитов, но это чревато проблемами, ведь программисты постоянно меняют код, что влияет на производительность метода непредсказуемым образом. Старые коммиты из истории могут не отражать реального состояния дел.
Чем больше коммитов мы берем, тем больше вероятность попасть на неактуальные замеры.
Чем меньше коммитов мы берем, тем меньше данных у нас есть для построения распределения.
Как же быть?
Взвешенные выборки
Одним из подходов являются взвешенные выборки, на основе которых мы можем реализовать экспоненциальное сглаживание.
Давайте рассмотрим некоторую выборку. Каждому элементу выборки мы сопоставляем некоторый вес. В нашем примере мы можем использовать экспоненциальный закон для расстановки весов.

К примеру, самый последний коммит имеет вес 1, предпоследний коммит имеет вес 0.5, предпредпоследний элемент имеет вес 0.25 и так далее.
Экспоненциальную функцию весов можно растягивать. К примеру, вес 0.5 может быть у коммита недельной давности или месячной давности, при этом прочие веса корректируются соответствующим образом. Имея подобные весовые коэффициенты, можно реализовать экспоненциальное сглаживание.
Для среднего арифметического подобное сглаживание делается очень легко и записывается простой формулой.
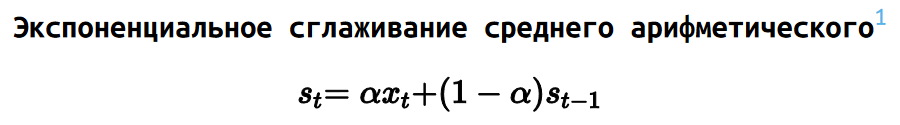
Из-за того, что среднее арифметическое не является робастным, выбросы заставляют прыгать значение среднего туда-сюда, что не совсем удобно для задач мониторинга. Но, как мы знаем, среднее арифметическое — это не всегда та метрика, которую мы хотим знать. К счастью, экспоненциальное сглаживание можно применить и к квантильным оценкам.
Например, можно построить взвешенную версию оценки Харрела-Дэвиса, изменяя площадь сегментов рассматриваемой бета-функции.
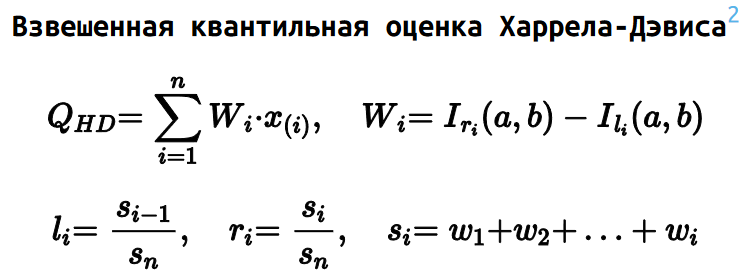
Прямо сейчас можете в это глубоко не вникать, просто запомните общую идею, что так вообще можно делать. Ну а когда такой подход понадобится на практике, то тогда и разберетесь, по ссылкам (здесь или в этой статье) вы найдете подробное описание данного подхода и референсные примеры кода.
Вывод
Резюме по данному разделу напрашивается само: для выбора квантильной оценки тоже нужно подумать.
Какие-то оценки более эффективные, какие-то более робастные, какие-то лучше работают для медианы, какие-то для хвостовых элементов, какие-то можно использовать для экспоненциального сглаживания, какие-то нельзя.
У квантильных оценок есть множество других характеристик. Если эти характеристики аккуратно сопоставить с вашими бизнес требованиями, то можно выбрать оптимальный вариант.
Скользящие квантильные оценки
Вы могли понадеяться, что на этом мы закончим обсуждать квантили, но эта тема настолько важная, что я хотел бы уделить ей еще немного внимания.
Мы переходим к рассмотрению скользящих квантильных оценок, которые рассчитываются на потоке чисел без их непосредственного хранения. На практике это очень популярная задача.
Обычные квантильные оценки удобно использовать при бенчмаркинге, когда у вас есть пара десятков замеров и достаточно времени и памяти, чтобы вычислить любой вариант оценки.
Но представьте, что вы хотите завести на сервере легковесную телеметрию на времени обработки запросов и получать актуальное описание текущего распределения, основанного на последних n значениях. Хранить все данные в памяти и пересчитывать оценки на каждый чих не всегда представляется возможным. Тут-то нам и приходят на помощь скользящие оценки.
Скользящее среднее и скользящая медиана
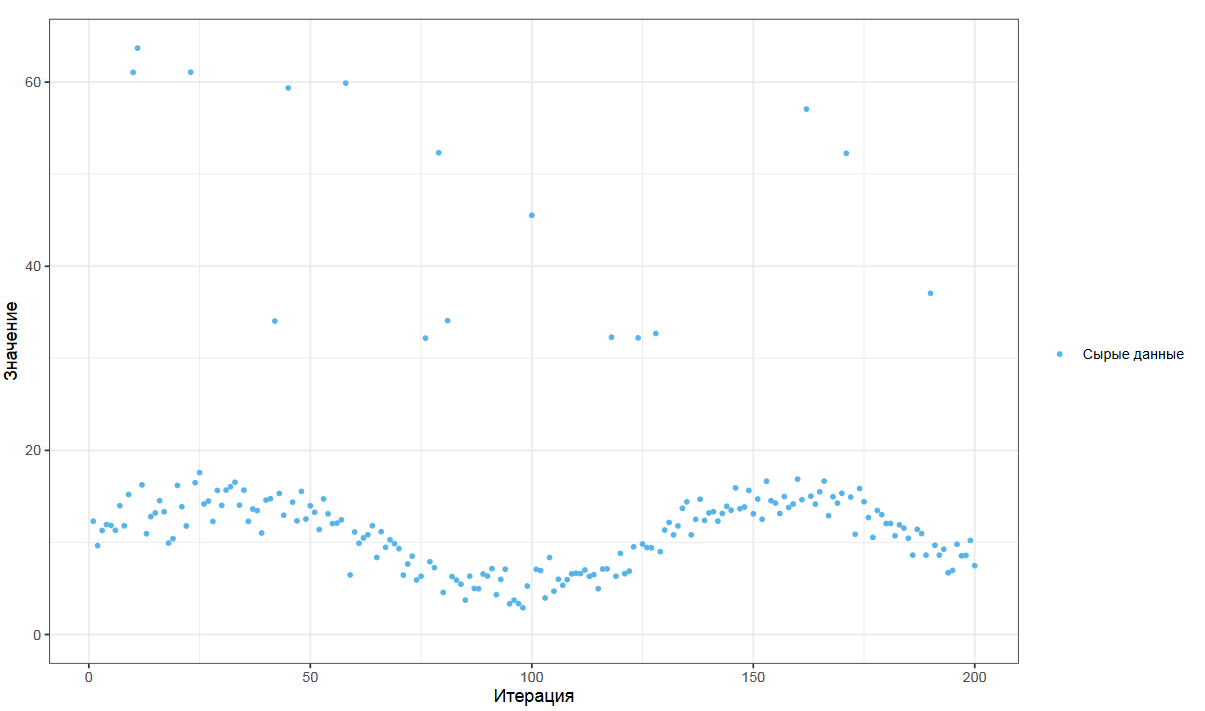
Представьте, что у вас есть поток замеров. Я взял хитрый пример с зашумленной синусоидой и небольшой порцией выбросов. Если мы по классике рассчитаем скользящее среднее, то получим что-то такое.
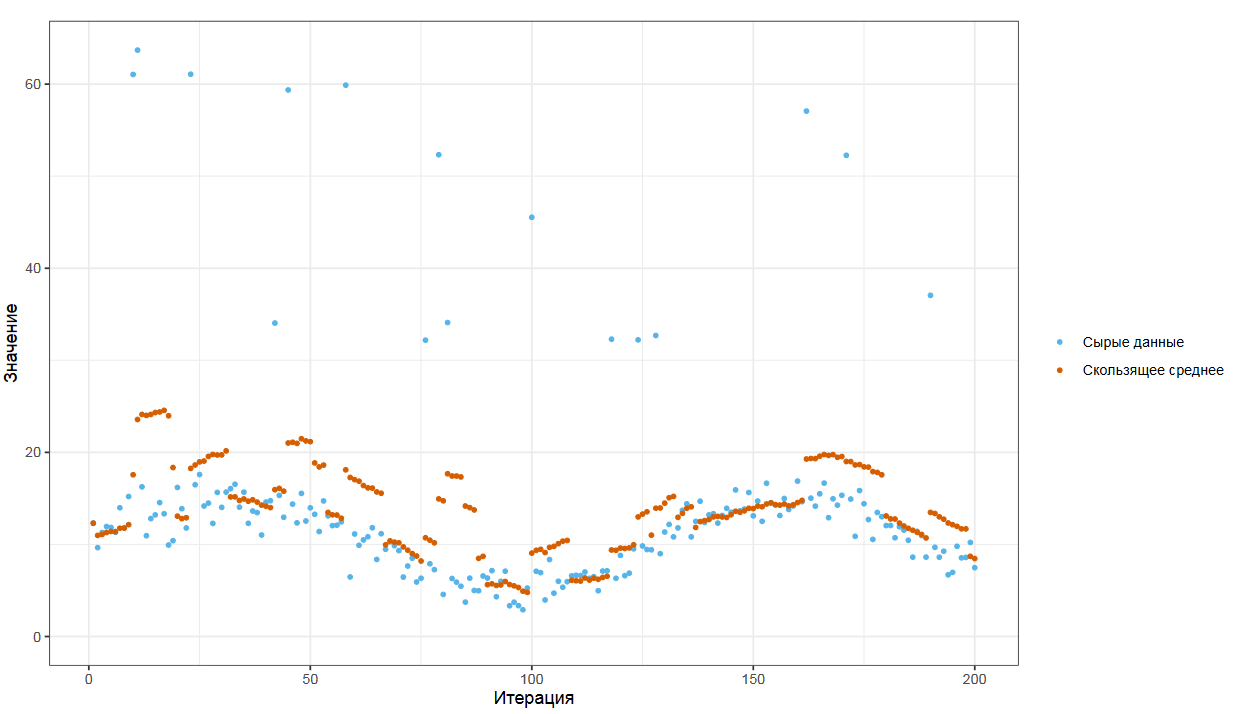
Из-за того, что среднее арифметическое не является робастным, выбросы заставляют прыгать значение среднего туда-сюда, что не совсем удобно для задач мониторинга.
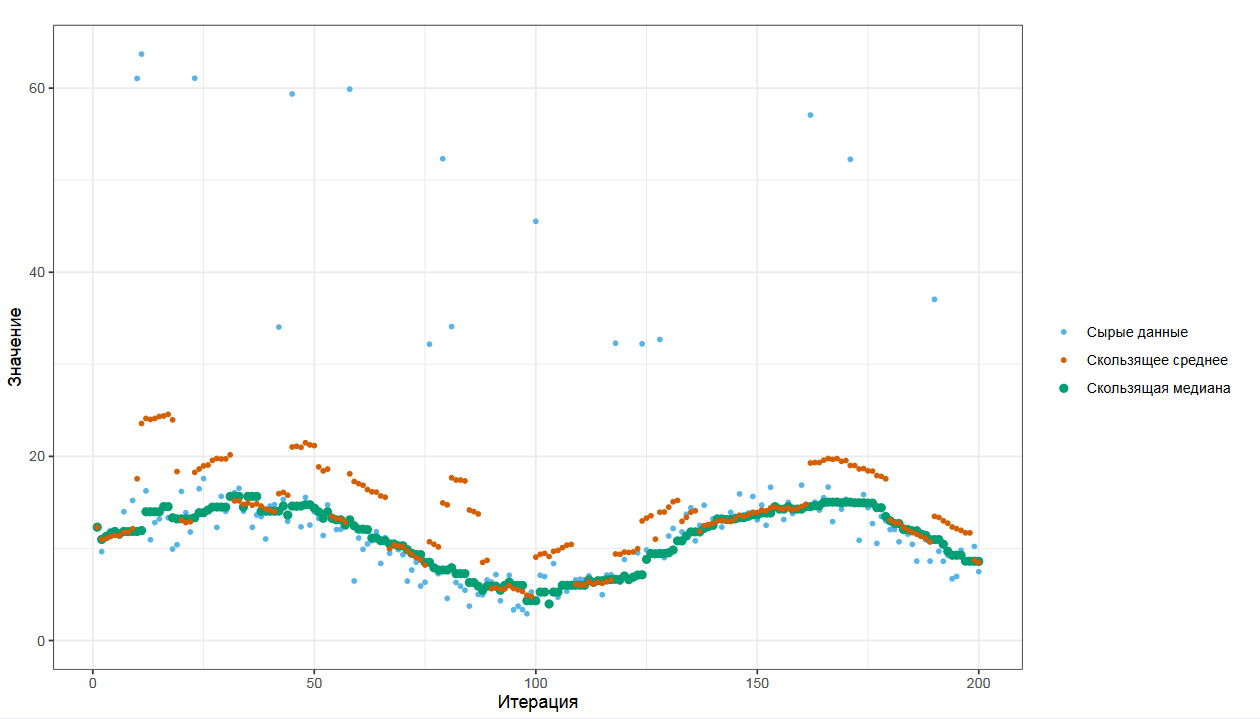
Скользящая медиана дает вам более плавный и стабильный график, который можно использовать при анализе ситуации и отправления автоматических алертов.
Но как же ее рассчитать? Как всегда, у нас есть много разных способов это сделать.
Разделенные кучи (Partitioning heaps)
Если мы по каким-то причинам хотим знать точное значение заданного квантиля среди последних n замеров, то мы можем использовать структуру данных под названием разделенные кучи.
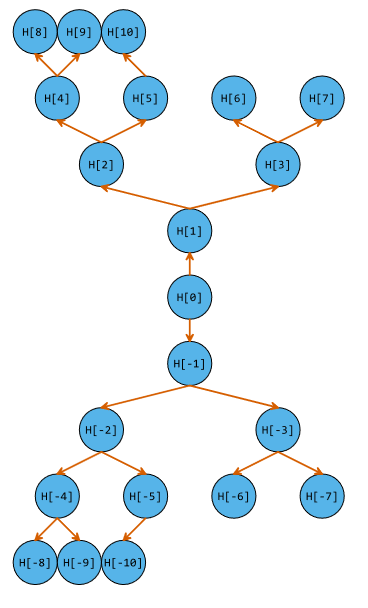
Идея простая: сначала мы берем обычную кучу. Это структура данных, которая позволяет считать минимум или максимум среди заданного набора чисел и позволяет совершать добавление, удаление или замену элемента за O(log(n)).
В предлагаемом подходе мы берем две кучи, одну из них переворачиваем вверх тормашками и соединяем две структуры данных. В итоге средний элемент — всегда больше всех элементов нижней кучи и меньше всех элементов верхней кучи.
Данная структура данных также умеет обновлять себя за O(log(n)), что позволяет реализовать потоковый вариант расчета заданной порядковой статистики с быстрым пересчетом и хранением только тех элементов, которые нам для этого пересчета нужны.
Однако, это не совсем легковесный вариант. Логарифм — это не всегда достаточно быстро, да и хранить последние n элементов не всегда есть возможность.
Квантильная оценка P²
Есть и более легковесный вариант под названием P².

Основная идея в том, что мы потоково рассчитываем пять маркеров: минимум, квантиль порядка p/2, квантиль порядка p, квантиль порядка (1+p)/2 и максимум. Для каждого маркера мы также храним его примерный порядковый номер.
По ссылке вы можете найти подробное описание метода, в котором приведены квадратичные и параболические формулы для потокового пересчета этих значений при добавлении нового замера.
Данная оценка хороша тем, что она требует O(1) памяти и работает также за O(1), что делает ее максимально легковесной. На удивление, она еще и довольно точная.
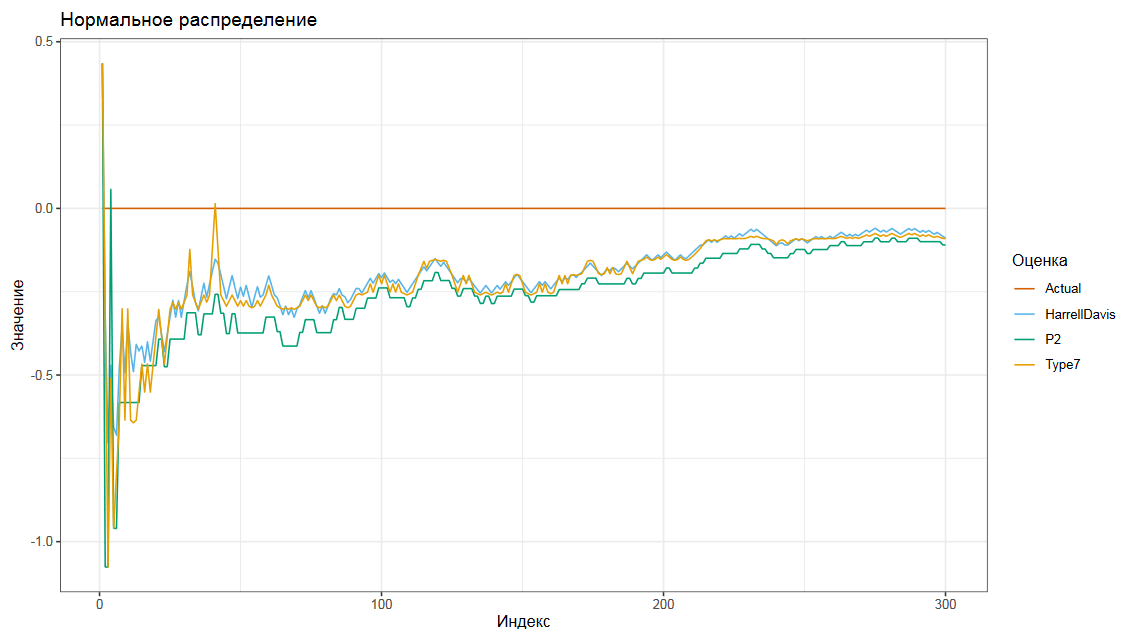
На данном графике представлен расчет потоковой медианы на числах из нормального распределения.
Мы сравниваем скользящую медиану с использованием оценок Хиндмана-Фана седьмого типа, Харрела-Дэвиса и P². Можно видеть, что оценки дают довольно похожие результаты. Конечно, P² дает только аппроксимацию, что не так эффективно, как точные оценки, но для целей телеметрии этого обычно более, чем достаточно.
Квантильная оценка MP²
Оценка P2 потоковая, но нескользящая. Она оценивает квантили с самого начала потока и никогда ничего не забывает. А на практике чаще хочется иметь именно скользящие оценки, которые учитывают только последние n элементов или около того.
Для этого у меня заготовлена модификация P² под названием MP².
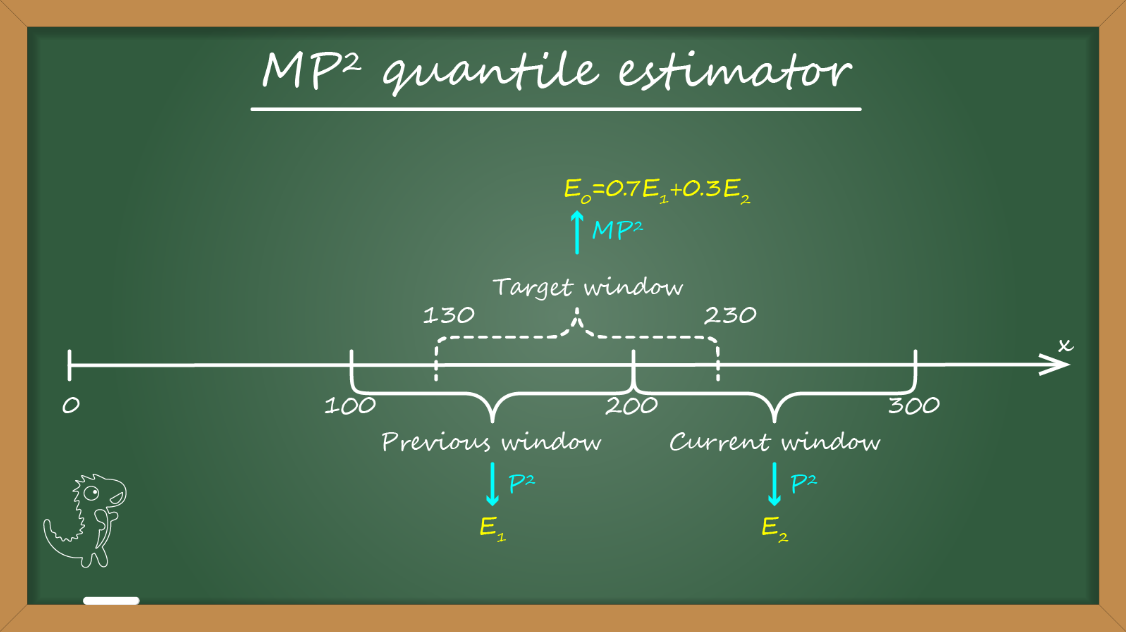
Основная идея проста. Помимо скользящего целевого окна расчета мы вводим синтетические окна такого же размера, идущие друг за другом. В начале каждого синтетического окна мы стартуем новую P2 оценку, которая начинает считать квантили с чистого листа.
Скользящее окно всегда накрывает не более двух синтетических окон. Имея в рассмотрении прошлое окно, от которого нам важен только конечное значение оценки, и текущее окно, мы можем построить оценку скользящего окна, как линейную комбинацию оценок синтетических окон.
Для работы алгоритма нам нужно хранить только два окна, что дает нам также O(1) по памяти и времени.
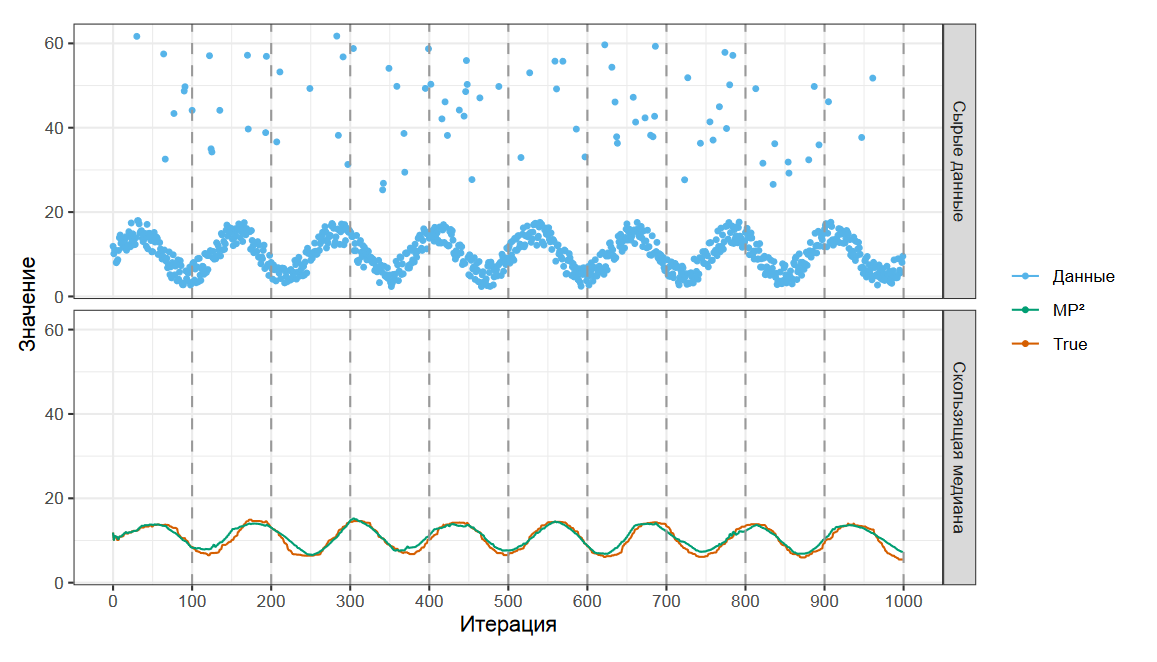
В численных симуляциях можно убедиться, что MP² также дает очень неплохую аппроксимацию истинного значения скользящей медианы.
t-digest
Еще одним популярным вариантом расчета скользящих квантилей является алгоритм под названием t-digest.

Он требует чуть больше памяти и времени, чем MP², но зато он более статистически эффективен. На GitHub можно найти очень подробное описание и референсные реализации на разных языках программирования.
Вывод
Можно было бы еще очень долго обсуждать разные варианты скользящих квантильных оценок, но я думаю, что вы поняли идею. Для выбора подходящего алгоритма нужно подумать, проанализировать требования по времени, памяти и эффективности, и выбрать наиболее подходящий подход.
Вот теперь мы наконец-то закончили с квантильными оценками. Время для следующей темы под названием вариация.
Вариация
Сперва обсудим терминологию, чтобы у вас не возникло путаницы.
Я делаю свой доклад на русском, но все материалы для изучения на английском, что может создать определенные трудности при переводе.
Терминология
Русский термин вариация переводится как dispersion. Это общее понятие для разных метрик, которые описывают разброс значений в распределении.
А русский термин дисперсия переводится как variance. Это конкретная оценка, которая соответствует квадрату стандартного отклонения.
Дисперсия, которая variance, является частным случаем вариации, которая dispersion.
С трудностями перевода закончили, теперь время переходить к формулам.
Стандартное отклонение
Стандартное отклонение — одна из самых популярных оценок вариации.
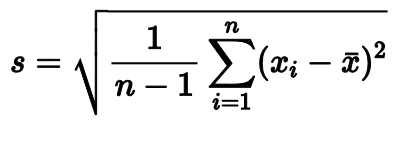
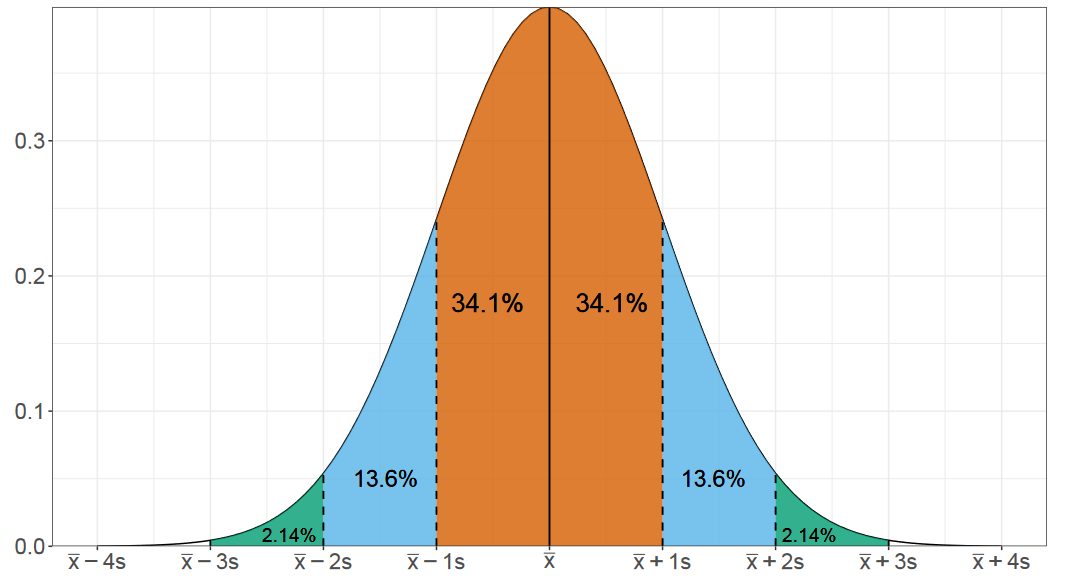
Эта оценка очень удобна при рассмотрении нормального распределения. Зная только среднее значение и стандартное отклонение, вы можете быстро прикинуть интервалы, в которых находится заданная порция распределения.
Обманчивое стандартное отклонение
Но в случае, если распределение не является нормальным, стандартное отклонение может быть обманчивым.
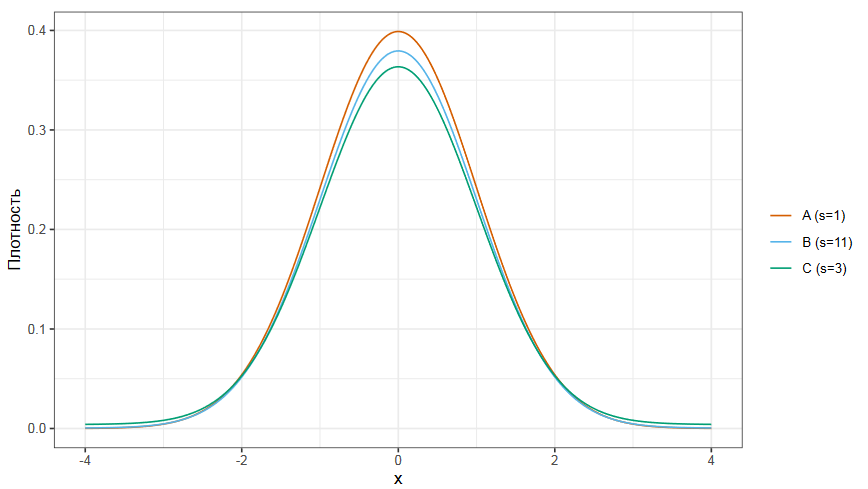
Рассмотрим следующий график, на котором показаны три распределения. Все они унимодальные и очень похожи на нормальное. А теперь посмотрим на их стандартные отклонения. Стандартные отклонения распределений A, B и C равные соответственно 1, 11 и 3. Как же так получается?
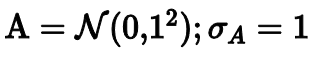
На самом деле только распределение A является стандартным нормальным распределением с единичным стандартным отклонением.
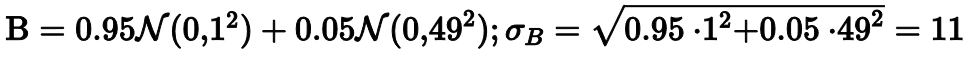
Распределение B на 95% состоит из стандартного нормального распределения и на 5% из нормального распределения со стандартным отклонением 49. В статистике такие смеси часто используются для моделирования экстремальных выбросов.
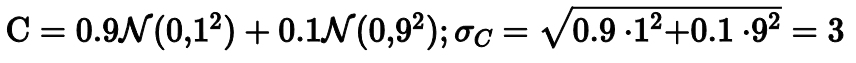
Ну а третье распределение на 90% состоит из стандартного нормального распределения и на 10% из нормального распределения со стандартным отклонением 9.
Стандартное отклонение очень чувствительно к хвостам распределения. Как и среднее арифметическое, оно не является робастным. Достаточно одного экстремального выброса, чтобы полностью испортить оценку. Давайте смотреть, какие у нас есть робастные альтернативы.
Медианное абсолютное отклонение (MAD)
Одним из самых популярных способов заменить стандартное отклонение является медианной абсолютное отклонение. Оно считается довольно просто.
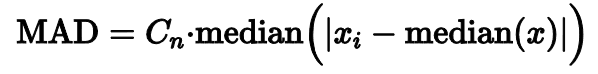
Нужно взять медиану выборки, вычислить абсолютные разницы между медианой и всеми элементами выборки, а затем взять медиану этих абсолютных разниц.
Чтобы сделать медианное абсолютное отклонение консистентным со стандартным отклонением для нормального распределения, результат умножается на специальную константу.
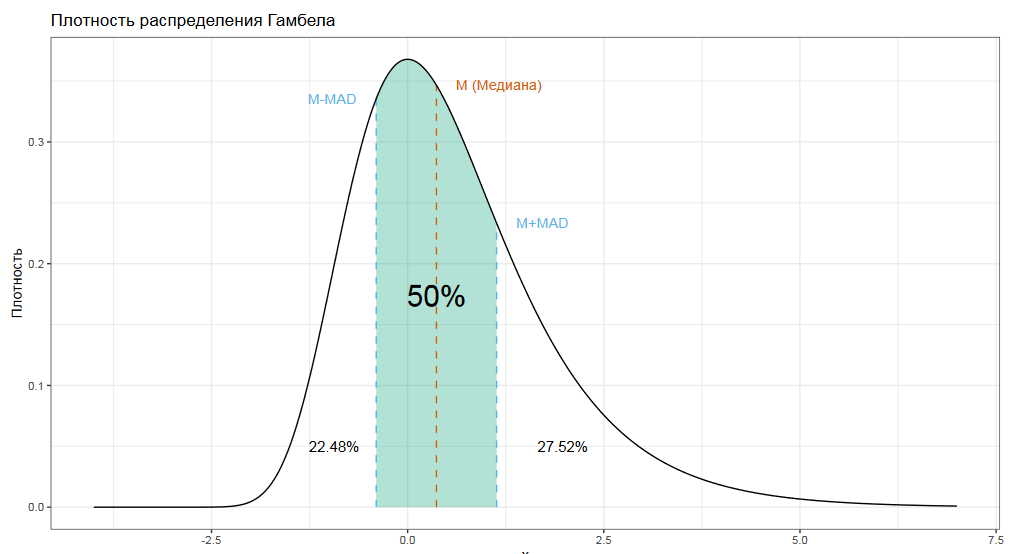
Если на константу не умножать, то физический смысл представленной метрики следующий: интервал медиана плюс-минус медианное абсолютное отклонение всегда покрывает ровно 50% распределения. Это довольно простая интуитивная модель, чтобы понимать, с чем вообще мы имеем дело.
Но вернемся к нашей константе. Если рассматривать асимптотический случай, т.е. когда размер выборки очень-очень большой, то значение этой константы примерно 1.48.
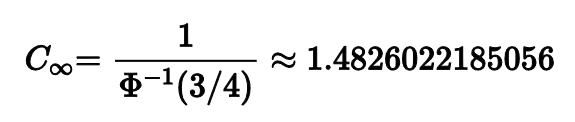
Однако, если выборка маленькая, то нам нужна коррекция этой константы.

Константа зависит от размера выборки и от квантильной оценки, которую мы используем для расчета медианы.
Очень часто люди, начитавшиеся Википедии, используют асимптотическое значение 1.48 всегда и везде, что приводит к значимым погрешностям на малых выборках. Пожалуйста, не делайте так.
Нулевые медиана/MAD
Медианное абсолютное отклонение — максимально робастное, точка перелома равна 0.5. Но, как мы знаем, у робастности всегда есть цена. И это не только Гауссова эффективность, которая в данном случае рассчитывается по отношению к дисперсии оценок стандартного отклонения. В то время, как стандартное отклонение крайне редко бывает нулевым, для медианного абсолютного отклонения это обычное дело.
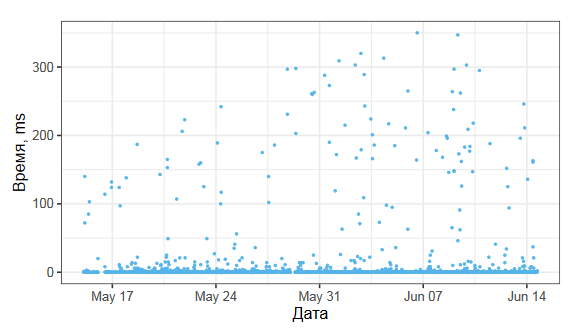
Перед вами график, который я собрал из реальных данных одного бенчмарка, измеряющего время некоторого метода в миллисекундах.
Если мы посмотрим на соответствующую гистограмму, то увидим, что больше половины значений выборки равны нулю, что приводит к нулевому медианному абсолютному отклонению.

Оценки вариации часто используются в знаменателях разных статистических формул, поэтому нулевое значение для нас крайне нежелательно.
Непрерывные и дискретные распределения
Эта проблема связана с эффектом дискретизации.
// Непрерывные распределения
x = { 2174, 1984, 2746, 1596, 1874, 2812, 2245,... } ms
y = { 1874, 2207, 1984, 1729, 2301, 1781, 2022,... } msОбычно мы рассматриваем перформанс-распределения как непрерывные, в которых все положительные значения возможны.
// Дискретные распределения
y = { 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6 } ms
z = { 6, 7, 7, 6, 6, 6, 7, 6, 6, 7, 7 } msНо если округлять время до миллисекунд, что часто происходит на практике, то в случае малых величин мы можем получить дискретное распределение. И тут начинаются проблемы, так как даже стандартное отклонение может оказаться нулевым. Дискретные распределения часто требуют своего набора подходов, что резко осложняет жизнь, так как переход из непрерывного распределения в дискретное не всегда явный и очевидный.
Квантильное абсолютное отклонение (QAD)
Конечно же, у меня есть авторские методики, которые до определенной степени позволяют победить эту проблему.

Как мы обсуждали ранее, медианное абсолютное отклонение — это медиана среди всех абсолютных отклонений от медианы выборки.
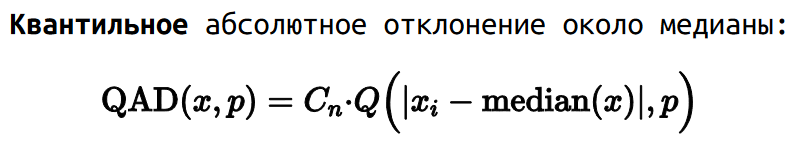
Но мы также можем рассмотреть квантильное абсолютное отклонение, которое является p-ым квантилем среди тех же абсолютных отклонений. Медианное абсолютное отклонение является частным случаем квантильного абсолютного отклонения для p=0.5.
Я также рассматриваю два дополнительных частных случая.
Первый называется стандартным квантильным абсолютным отклонением, p=0.68. Он хорош тем, что он совпадает со стандартным отклонением без необходимости умножать на константу для консистентности.
Второй называется оптимальным квантильным абсолютным отклонением (QAD), p=0.86. Он хорош своей Гауссовой эффективностью. Точка перелома для QAD рассчитывается как 1-p.
Интереснее посмотреть на асимптотическую, Гауссову эффективность. У MAD она не очень большая — всего 37%. У SQAD и OQAD значения эффективности 54 и 65% соответственно.

Если мы посмотрим на график зависимости асимптотической Гауссовой эффективности от p, то поймем почему OQAD называется оптимальным.
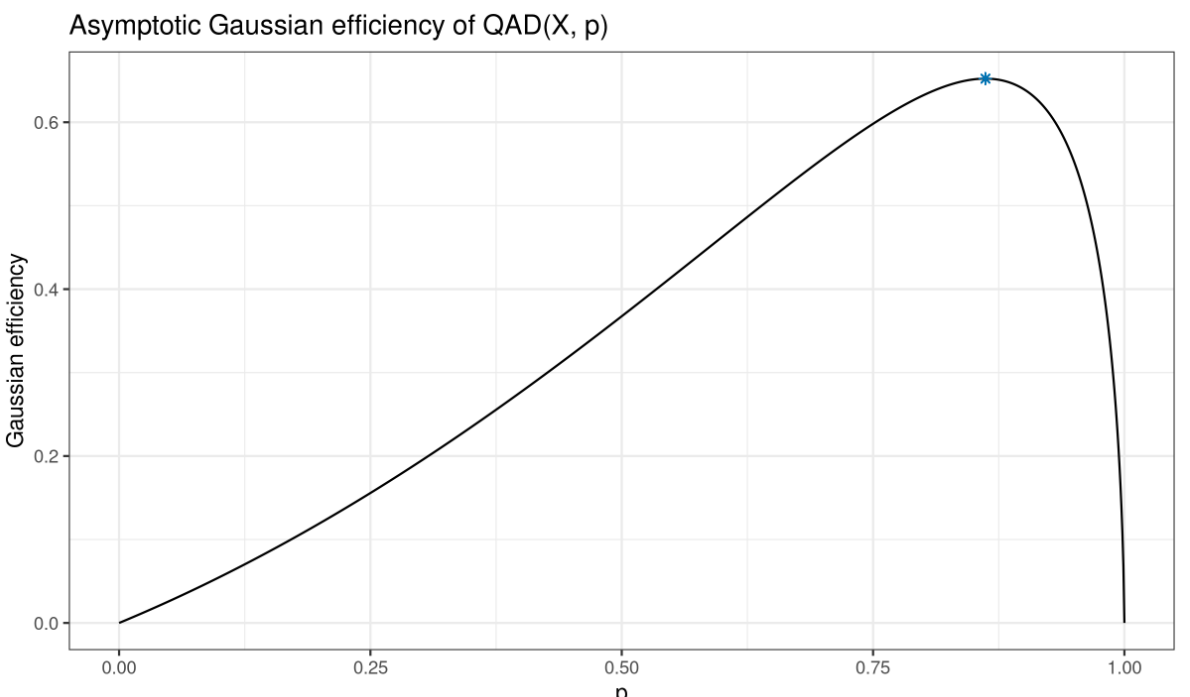
Для соответствующего p QAD имеет максимальную возможную Гауссову эффективность. Брать значения p более 0.86 смысла не имеет, мы будем терять как в эффективности, так и в робастности. А вот среди значений p между 0.5 и 0.86 мы можем найти то, которое даст разумный баланс между робастностью и эффективностью.
Прочие оценки стандартного отклонения
Есть и другие робастные оценки стандартного отклонения. Давайте посмотрим еще несколько особо примечательных.
Есть оценка Шамоса, которая довольно похожа на оценку Ходжеса-Леманна для центральной тенденции. Шамос предложил взять абсолютные попарные разницы всех элементов выборке и выбрать из них медиану.
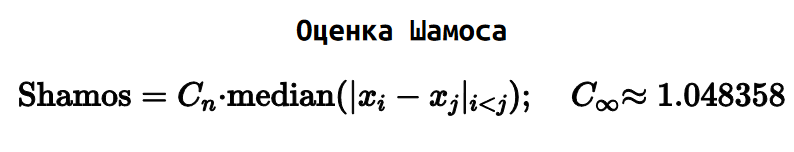
А еще есть оценки Sₙ и Qₙ от Руссо и Крукса.
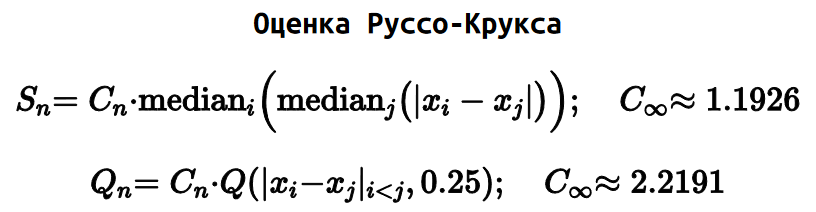
Особо примечательна оценка Qₙ, которая является развитием оценки Шамоса. Только вместо медианы всех абсолютных попарных разниц, мы берем первый квартиль.
Сравнение асимптотических оценок стандартных отклонений
Чтобы лучше сориентироваться между разными оценками, давайте их посравниваем. Основными характеристиками у нас будут асимптотические Гауссова эффективность и точка перелома.
Для обычного стандартного отклонения все понятно: эффективность 100%, точка перелома 0%. Три вида QAD мы только что обсудили, максимальная эффективность этого подхода у OQAD и равна она 65%. Оценка Шамоса выглядит очень хорошо: эффективность поднимается до 86%, при этом точка перелома 29%. А вот оценка Qₙ Руссо-Крукса выглядит еще лучше: по сравнению с Шамосом эффективность чутка проседает до 82%, но зато точка перелома целых 50%, прямо как у MAD.

Казалось бы, у нас есть победитель: можно всегда использовать Qₙ и не думать о прочих оценках. Однако, это только асимптотические оценки. Они рассчитаны для случая, когда выборка содержит бесконечно много элементов. На практике собрать бесконечно много замеров довольно сложно. Чаще всего приходиться иметь дело с конечными выборками.
Конечные выборки
Давайте посмотрим, что происходит с Гауссовой эффективностью на конечных выборках для OQAD и Qₙ.
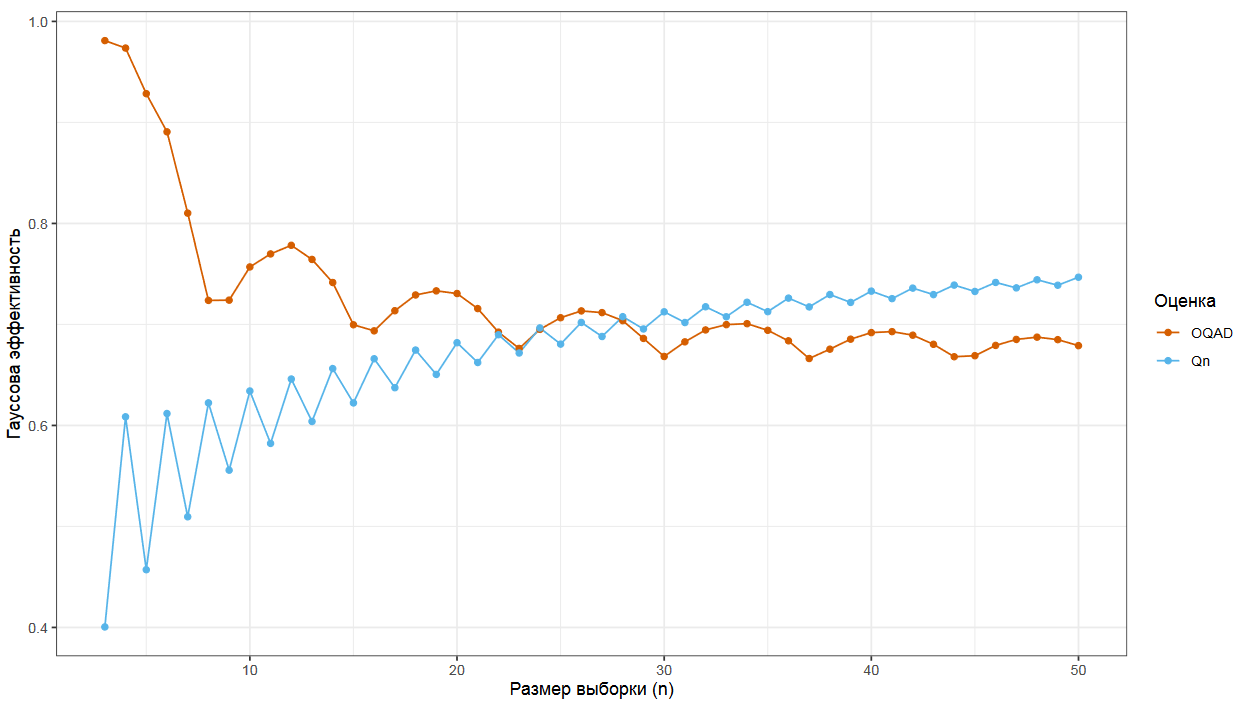
При внимательном изучении этой картинки мы увидим, что Qₙ побеждает только на больших выборках. А вот на маленьких выборках, в которых меньше 20 элементов, OQAD более эффективен.
Вывод
Это я все к тому, что нам нужно продолжать хорошо думать перед выбором правильной метрики вариации. Мы рассмотрели только несколько возможных характеристик, по которым можно сравнивать оценки. На самом деле их намного больше. И мы должны быть очень аккуратны, чтобы не попасть в неприятную ситуацию, когда выбранная оценка на реальных данных будет давать далекие от ожидаемых результаты.
Плотность распределения
А мы переходим к следующей теме — графикам плотности распределения. Казалось бы, тема довольно классическая, но с ней тоже много проблем.
Гистограммы
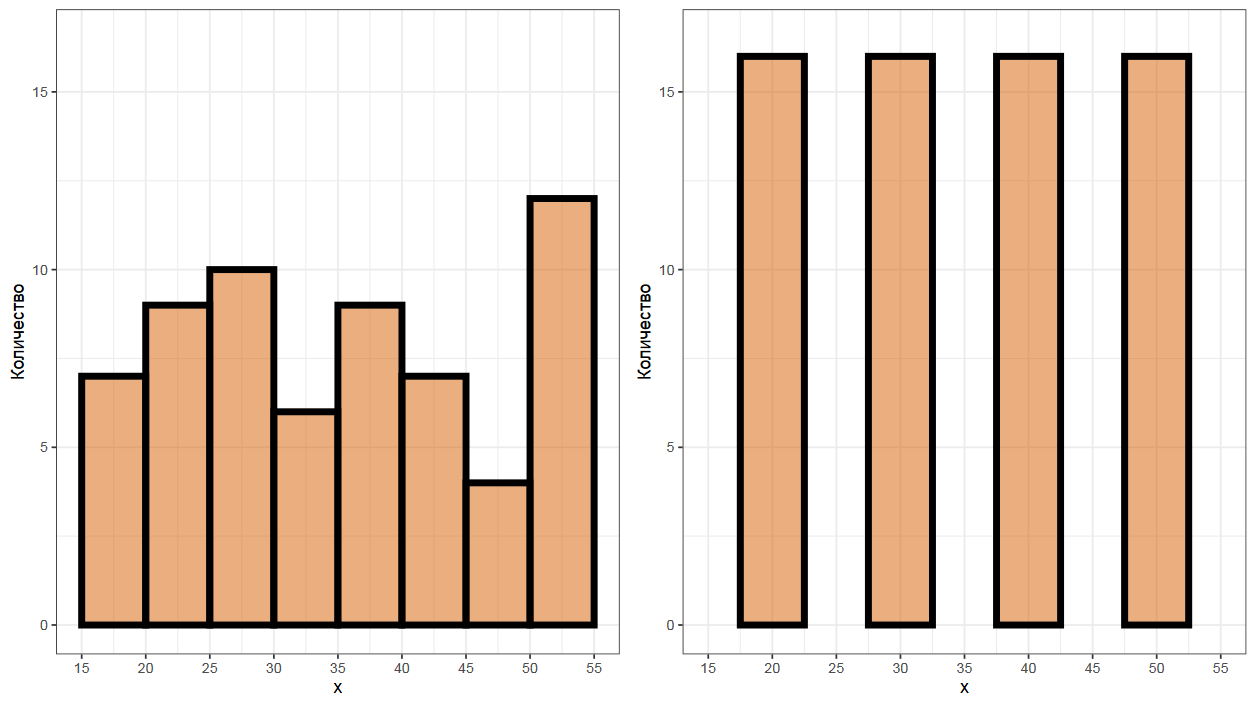
Простейшим примером графика плотности распределения является гистограмма. Давайте посмотрим на две представленные гистограммы. Что вы можете о них сказать?
Полагаю, что вы подумали, что слева у нас примерно равномерное распределение, а справа четырехмодальное распределение. Но на самом деле обе гистограммы построены на одной и той же выборке. Единственная разница — это смещение первого столбика. Этот параметр может оказать драматическое влияние на внешний вид графика. Но он еще не самый проблемный.
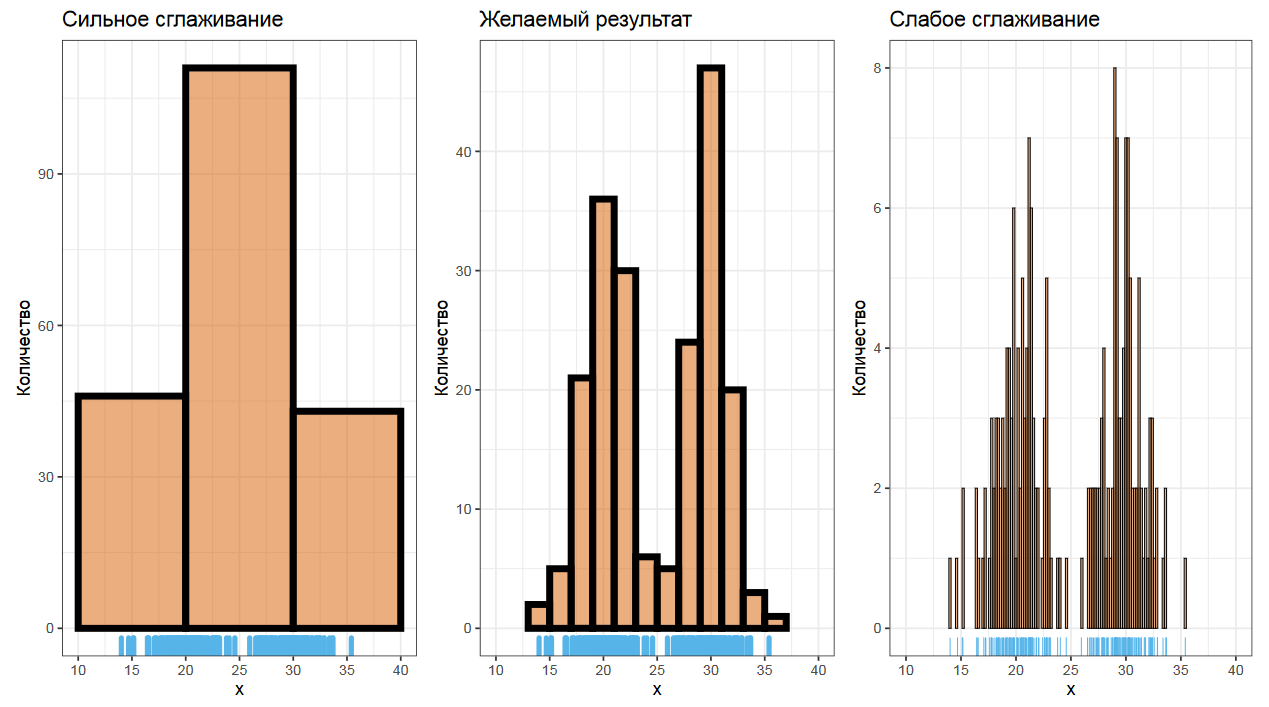
Более сложной проблемой является выбор ширины столбиков. Одно неверное движение, и график получится переглаженным или недоглаженным.
Подробно на гистограммах останавливаться не будем, но имейте ввиду, что есть множество разных алгоритмов для выбора этой ширины. А еще есть адаптивные алгоритмы, в которых у разных столбиков разная ширина. Один из таких алгоритмов как раз используется в BenchmarkDotNet.
Ядерная оценка плотности (KDE)
Другим популярным способом строить оценки плотности является ядерная оценка плотности (KDE). Она дает нам более гладкое и эстетичное представление распределений.
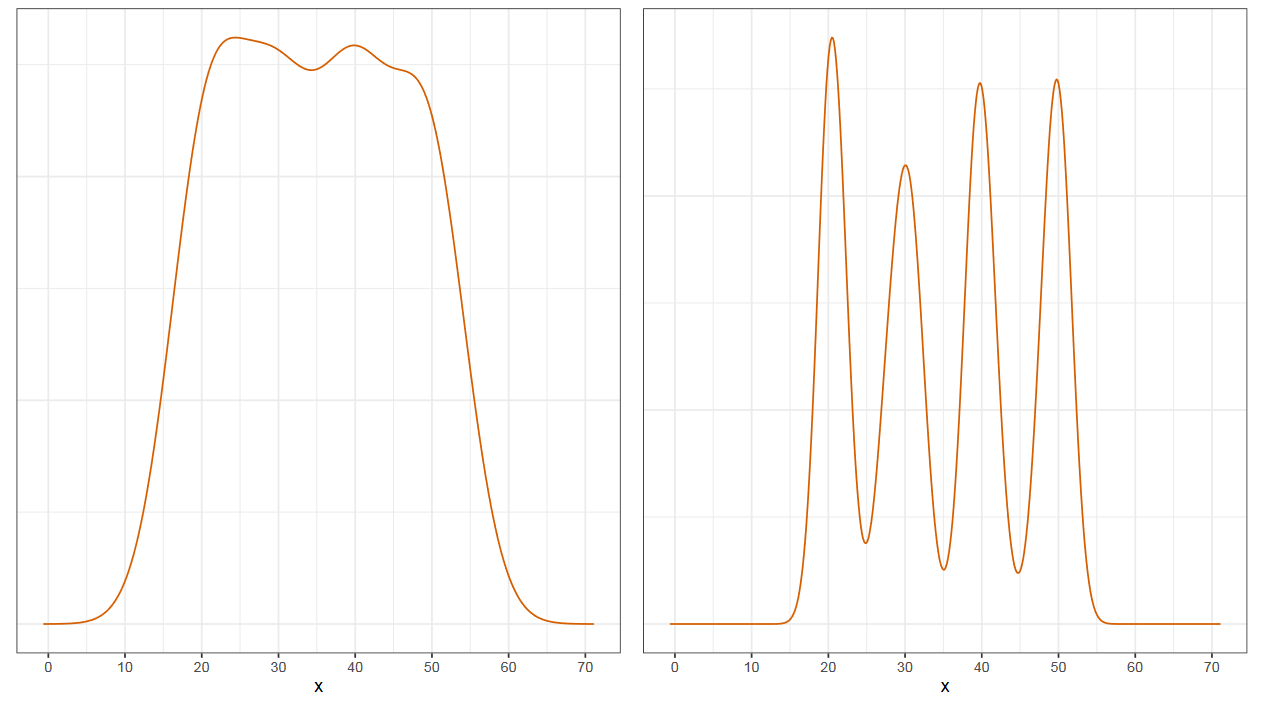
Перед вами картинка на которой два графика: равномерный и четырехмодальный. Как вы могли догадаться, они также основаны на одной и той же выборке. Ядерные оценки тоже могут быть очень обманчивыми. Давайте поговорим о них чуть подробнее.
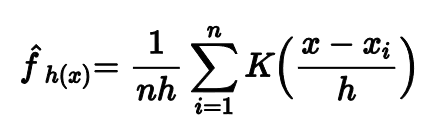
Ядерная оценка описывается вот такой формулой. Она может выглядеть непонятно, но основная идея довольно проста.
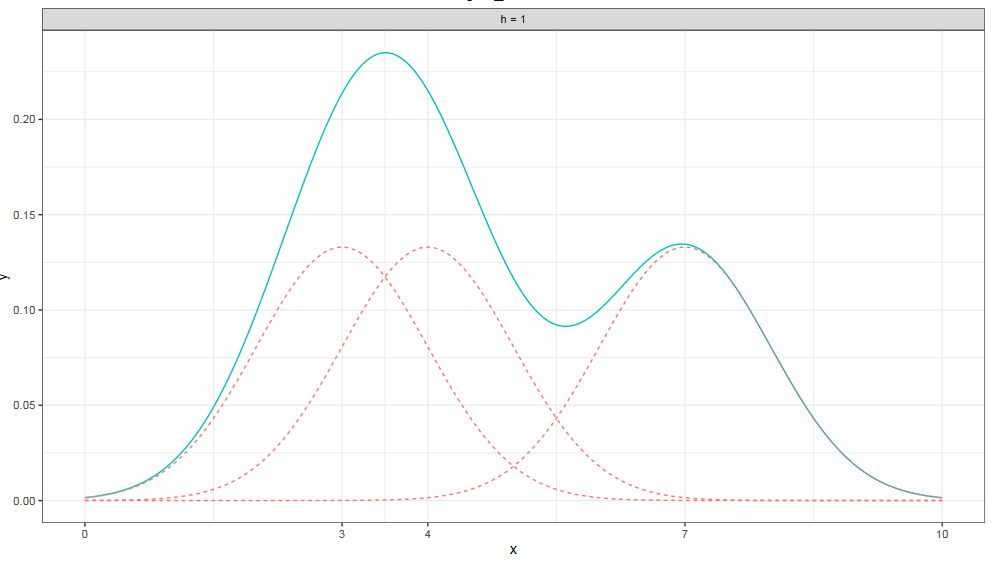
Допустим, у нас есть выборка из трех элементов: 3, 4 и 7. Чтобы построить ядерную оценку плотности, нужно над каждым элементом нарисовать нормальное распределение, которое выполняет роль ядра, а затем сложить эти три маленьких распределения в одно большое.
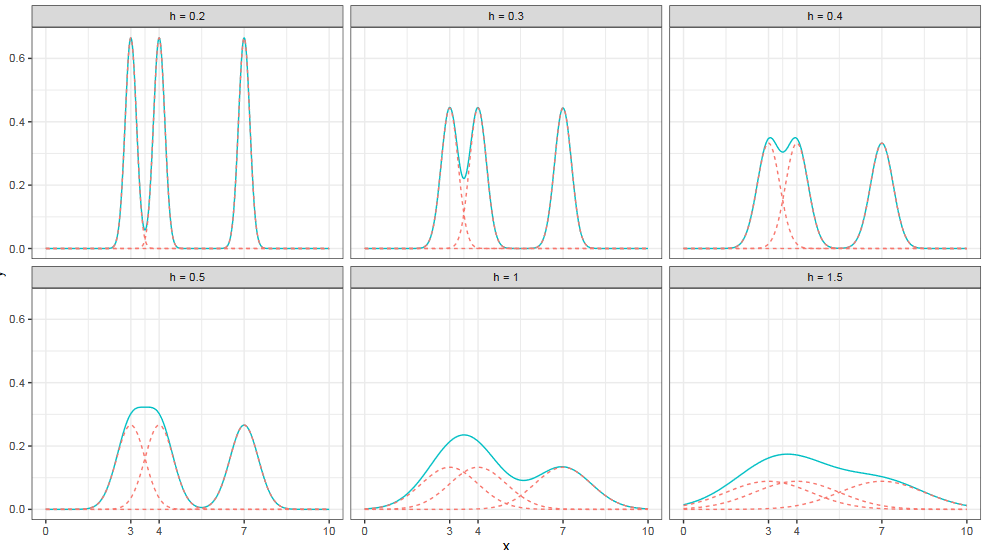
Ширина ядра является параметром, который не всегда просто выбрать. Если на том же наборе элементов выбрать слишком узкое или слишком широкое ядро, то мы получим либо трехмодальное распределение, либо равномерное.
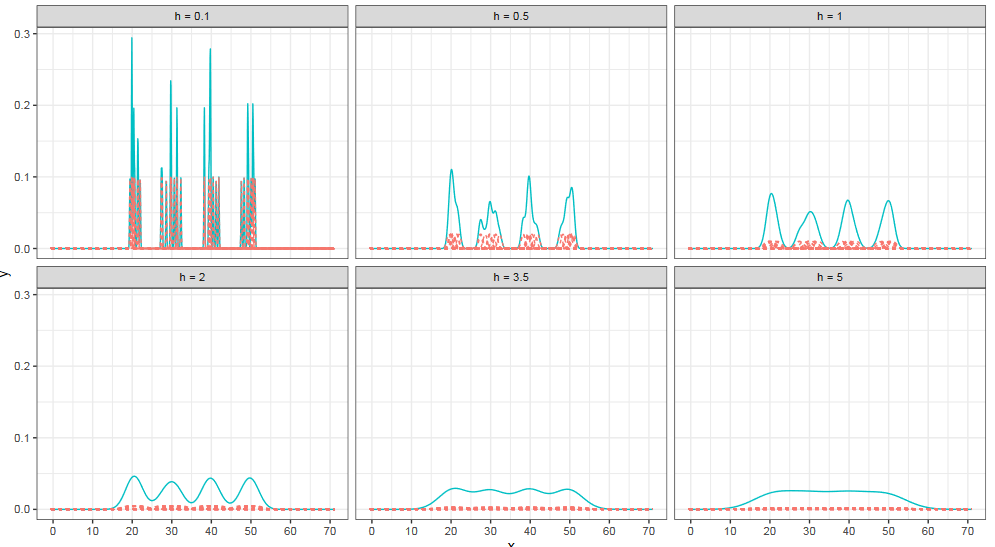
Аналогичная проблема возникает и на больших выборках. Сейчас вы видите ядерные оценки плотности на четырехмодальном распределении из самого первого примера. Как вы видите, легким движением руки четыре моды сливаются в одно равномерное распределение, если ширина ядра выбрана не очень хорошо. Имеем ту же проблему, что и для гистограмм, в результате которой могут возникнуть переглаженные или недоглаженные оценки.
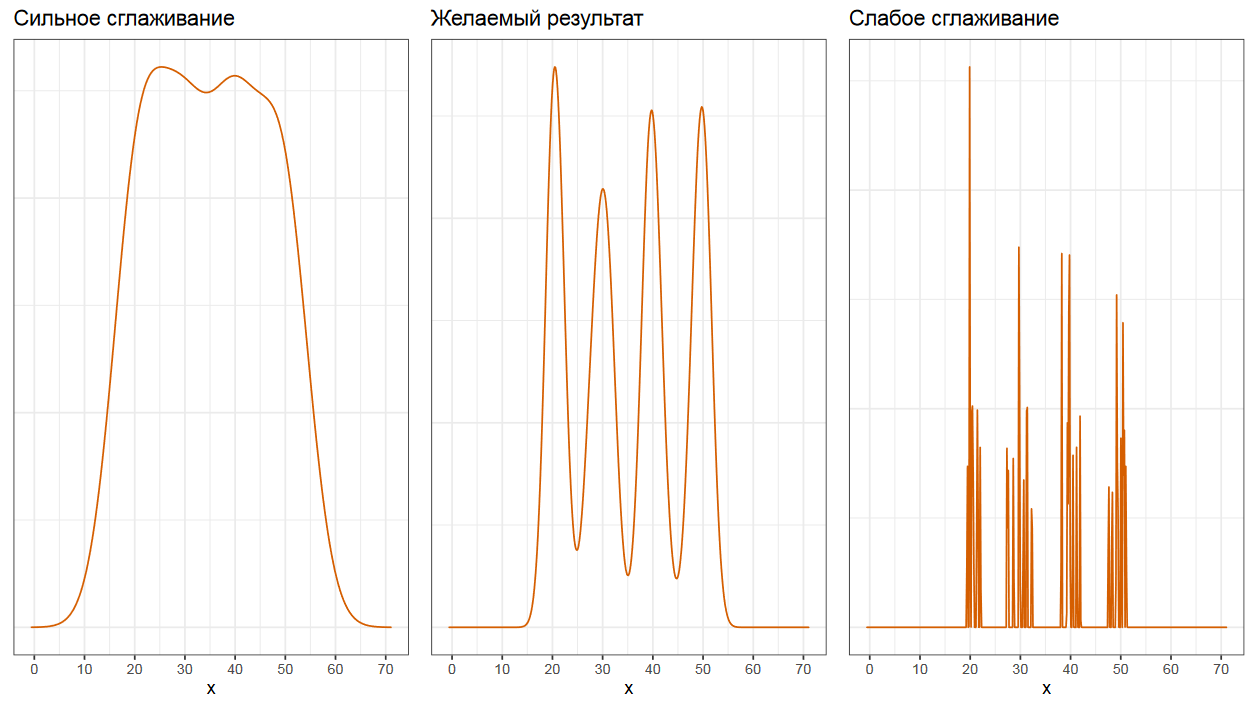
Есть много разных алгоритмов для выбора правильной ширины ядра.
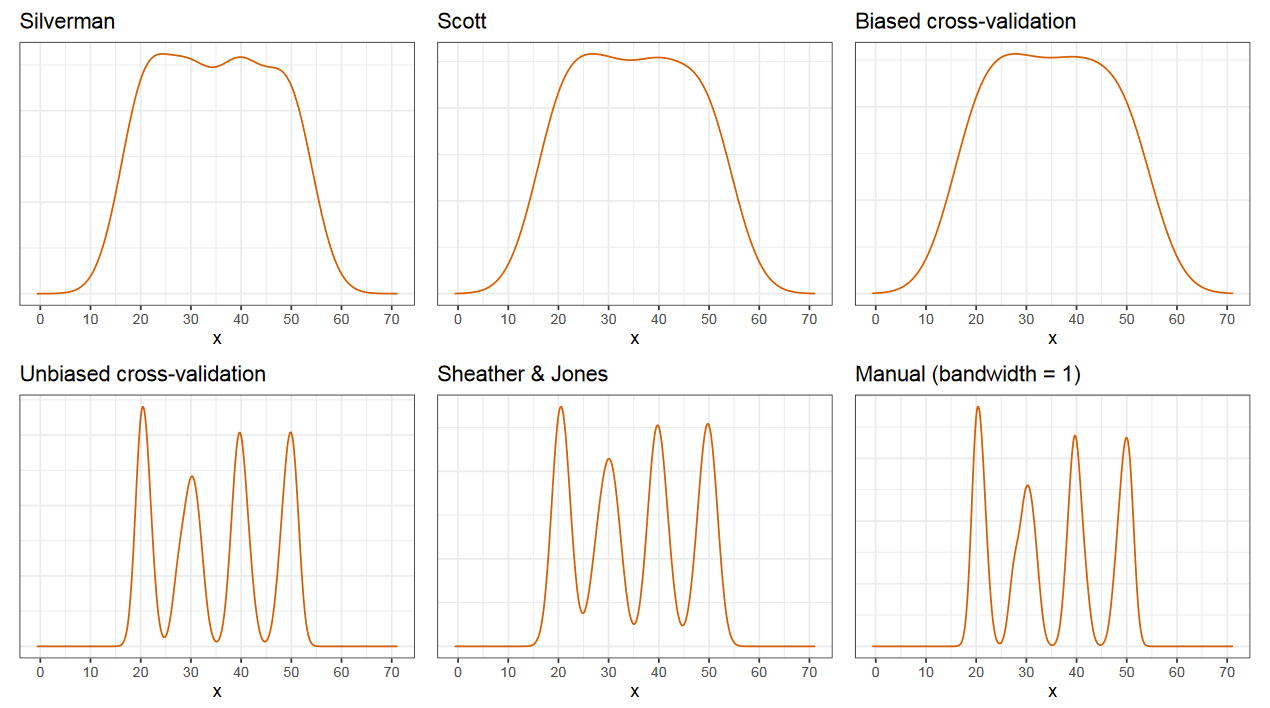
Увы, методы выбора ширины ядра, которые используются по умолчанию в разных статистических пакетах, чаще всего рассчитаны на нормальные распределения. Если вы не хотите глубоко вникать в данную тему, но хотите строить правдоподобные ядерные оценки плотности, то я советую метода Шезера и Джонса, который обычно дает что-то вменяемое в мультимодальном случае.

У ядерных оценок плотности есть еще одна проблема, а именно неконсистентность в обычными квантильными оценками. А именно, если вы построите ядерную оценку плотности, то вы получите полное описание распределения со своими значениями квантилей, которые не совпадут с классическими квантильными оценками вроде Хиндмана-Фана или Харрела-Дэвиса.
Если нам важна консистентность, то мы можем построить график плотности прямо на квантильных оценках. Лучше всего для этой цели подходит оценка Харрела-Дэвиса, т.к. она дает максимально гладкий и прилично выглядящий график.
Квантильная оценка плотности (QRDE)
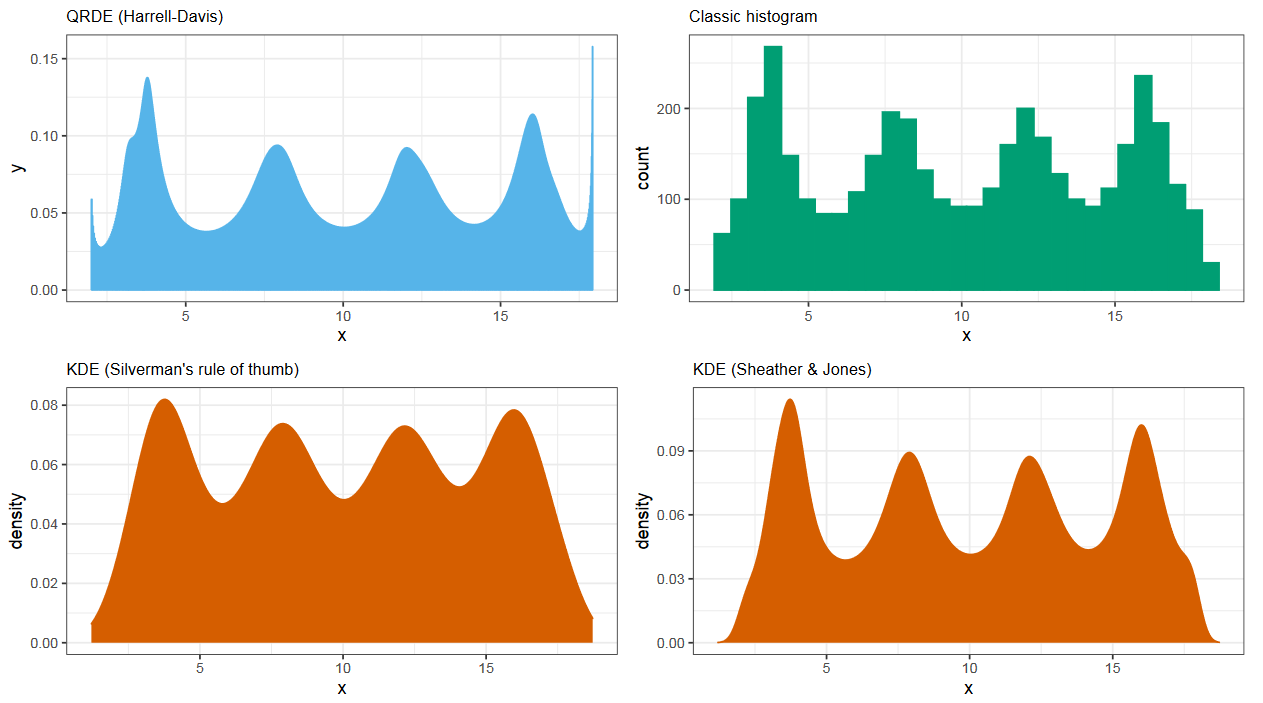
На данном слайде мы видим четыре оценки плотности. Слева сверху используется метод Харрела-Дэвиса, справа сверху гистограмма, а снизу два метода ядерной оценки плотности с разными способами выбора ширины ядра. И на данном примере все графики дают примерно одинаковый результат. Но так происходит не всегда.
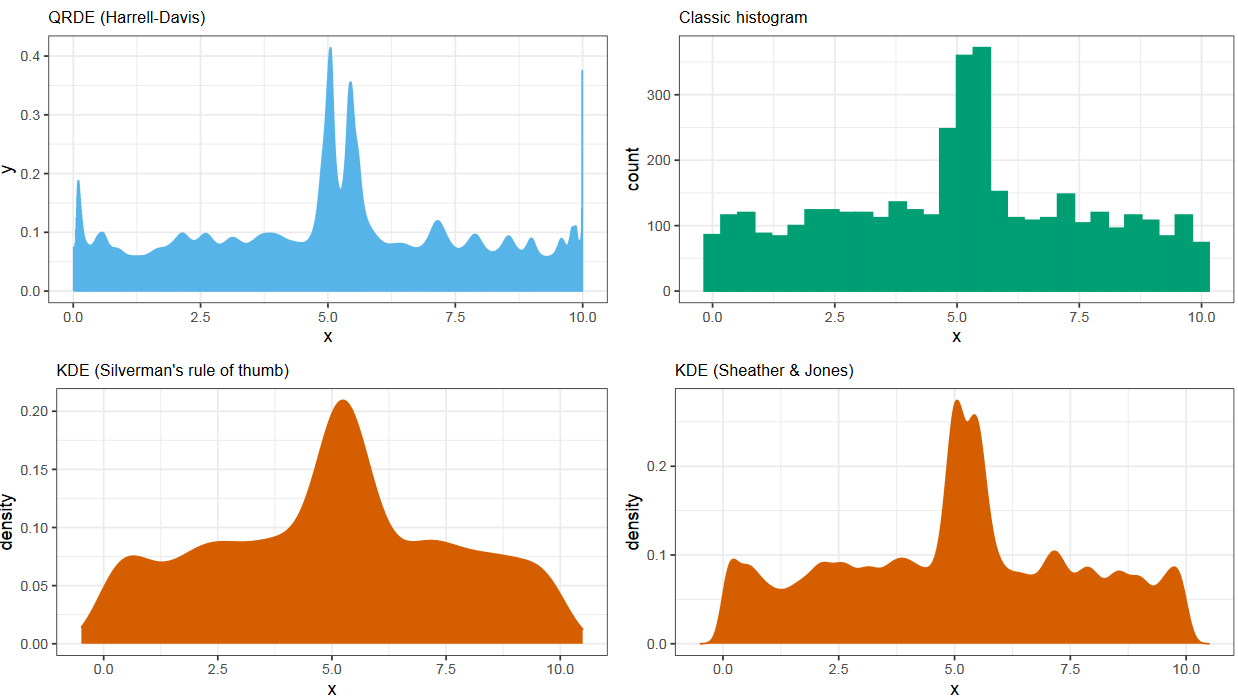
В этом примере у нас есть распределение с двумя близкими модами. Как мы видим, только метод Харрела-Дэвиса способен их хорошо разделить, в остальных случаях моды сливаются.
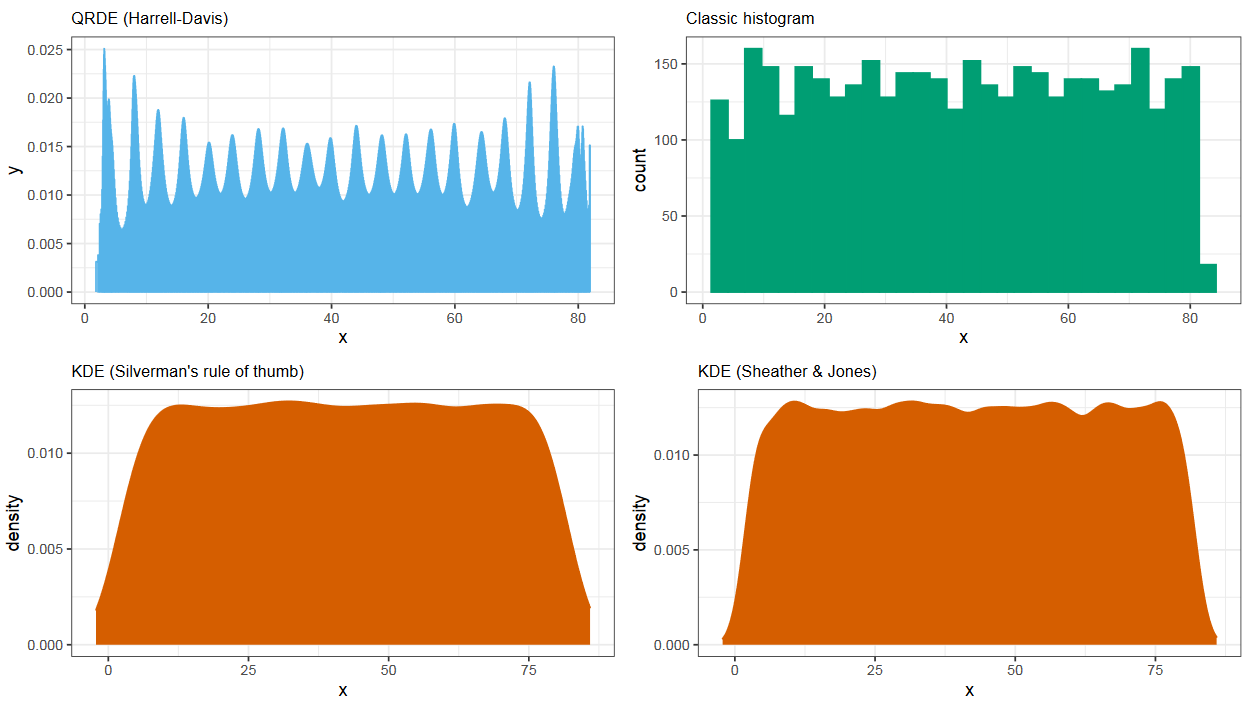
Аналогичная проблема возникает в случае существования большого количества мод. Только Харрел-Дэвис способен из нормально разделять, в остальных методах они чаще всего сливаются.
Повторяющиеся элементы (дискретные выборки)
Однако у метода оценки плотности распределения на квантильных оценках есть свои недостатки. Одна из самых больших проблем связана с эффектами дискретизации, когда выборка содержит повторяющиеся элементы.
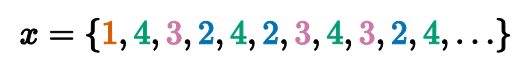
Строго говоря, в таких случаях плотность должна улетать в бесконечность, т.к. этот метод рассчитан на непрерывные распределения, в которых вероятность возникновения двух одинаковых элементов околонулевая. Но если степень дискретизации не очень большая, а мы хотим использовать функции плотности на квантильных оценках, то есть обходной путь для этой проблемы. Он называется джиттеринг.
Улучшаем KDE/QRDE с помощью джиттеринга
Идея простая: к каждому элементу мы добавляем небольшой шум, чтобы развести повторяющиеся элементы. Этот искусственный прием позволяет получить хороший гладкий график. Случайный шум я не очень люблю, т.к. он делает графики недетерминированными, лучше сразу зафиксировать форму этого шума.
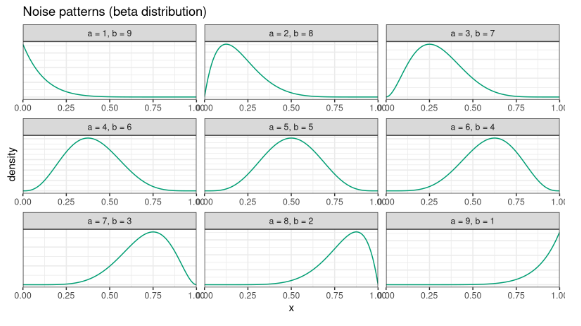
Я люблю использовать паттерны шума на основе бета-распределения, которое определяется порядковым номером соответствующего элемента.
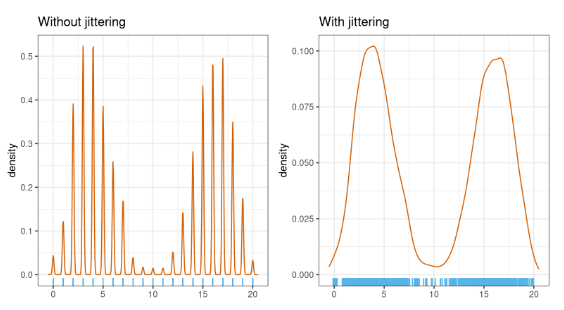
Внизу слайда вы видите эффект от применения джиттеринга к большой дискретной выборке. Слева представлен результат без джиттеринга, в котором мы видим много узких мод. Справа джиттеринг применен, что дает нам аккуратное гладкое распределение.
Вывод
В общем, оценку плотности также не всегда просто подобрать. Для этого тоже нужно подумать. Существует очень много разных методов и подходов, есть из чего повыбирать.
Мультимодальность
Мы уже несколько раз говорили о том, что мультимодальность распределения очень портит жизнь.
Проблема
Разные статистики вроде центральной тенденции и дисперсии хороши для унимодальных распределений.
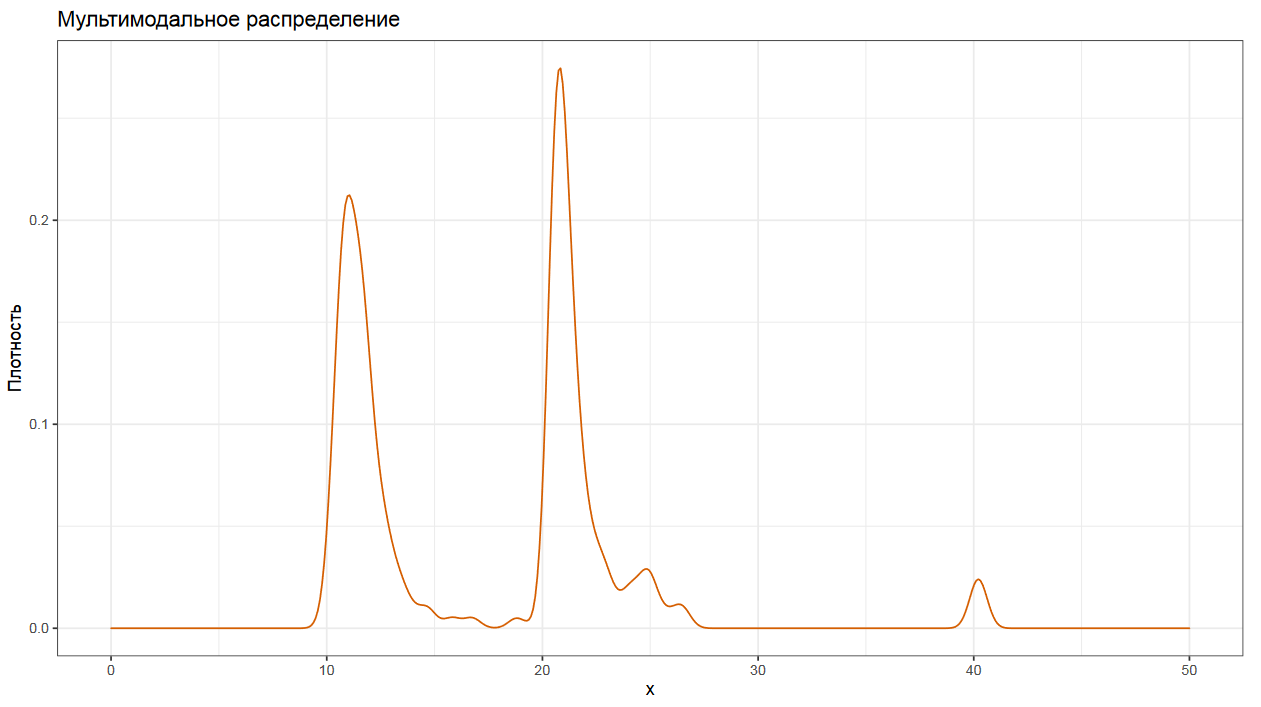
Если распределение мультимодальное, то с ним сразу возникнут проблемы. Но как же эту самую мультимодальность обнаружить?
mvalue
Когда я первый раз начал искать варианты алгоритмов, то на просторах интернета я нашел только один заслуживающий внимания подход.

В блоге Брендана Грега, который в ту пору был ведущим перформанс-инженером в Нетфликсе, описан расчет метрики mvalue, которая позволяет оценивать степень мультимодальности.
Давайте кратенько рассмотрим основную идею.
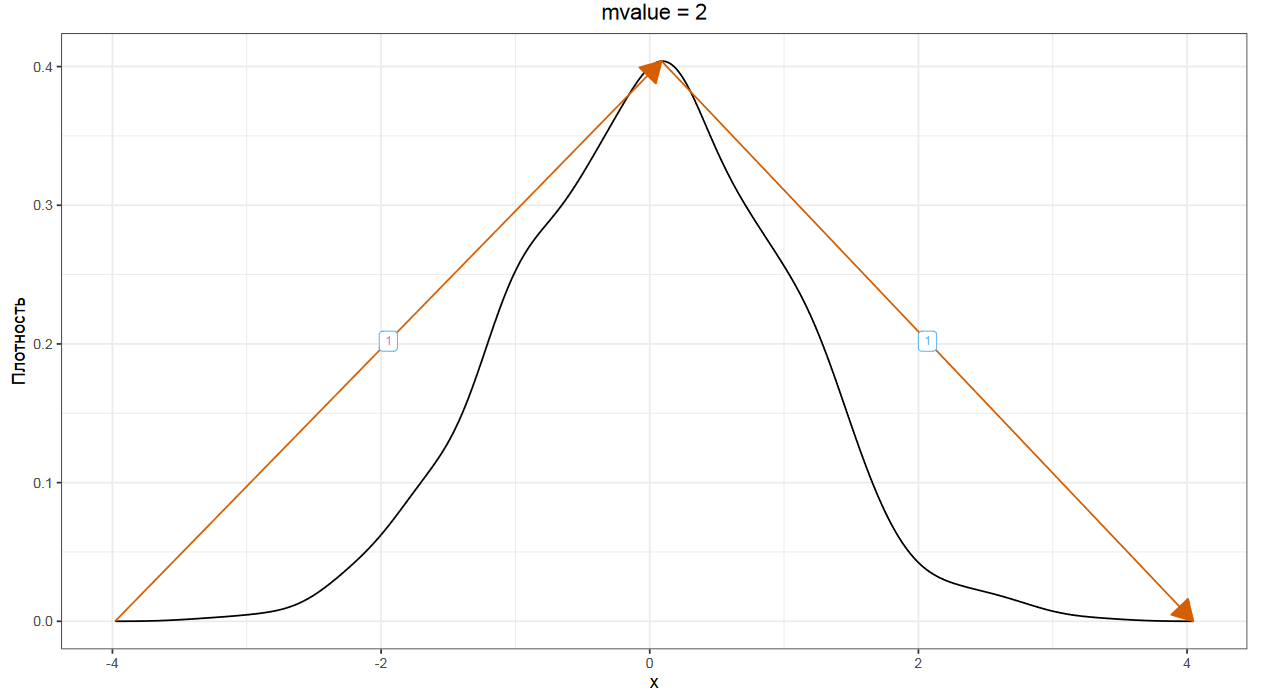
В данном подходе мы строим график плотности распределения и идем по нему слева направо, считая размер всех восходящих и нисходящих сегментов графика. Самая высокая точка графика оценивается в единицу по высоте. Для идеального унимодального распределения у нас есть один восходящий сегмент, который мы оцениваем в единицу, и один нисходящий сегмент, который мы тоже оцениваем в единицу. Суммируя эти значения, мы получаем так называемое mvalue, которое в данном случае будет равно двум.
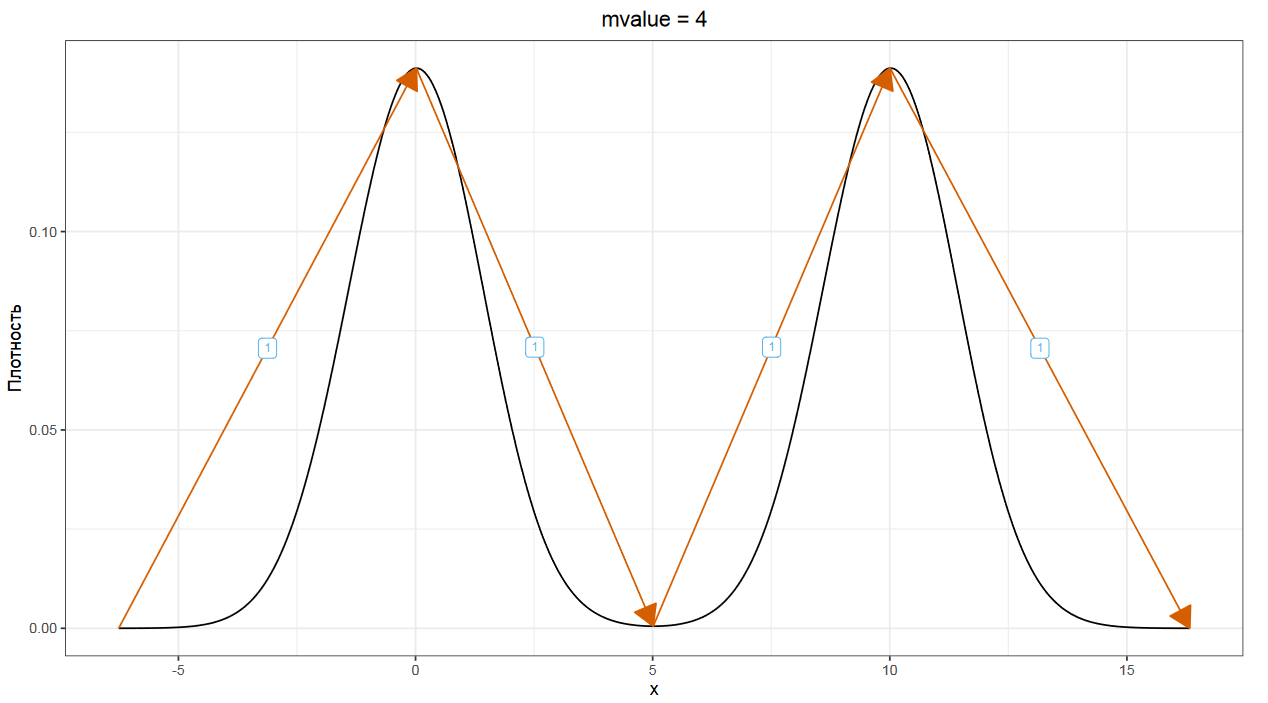
В идеальном бимодальном распределение у нас есть два восходящих сегмента и два нисходящих, что дает нам mvalue, равное четырем.
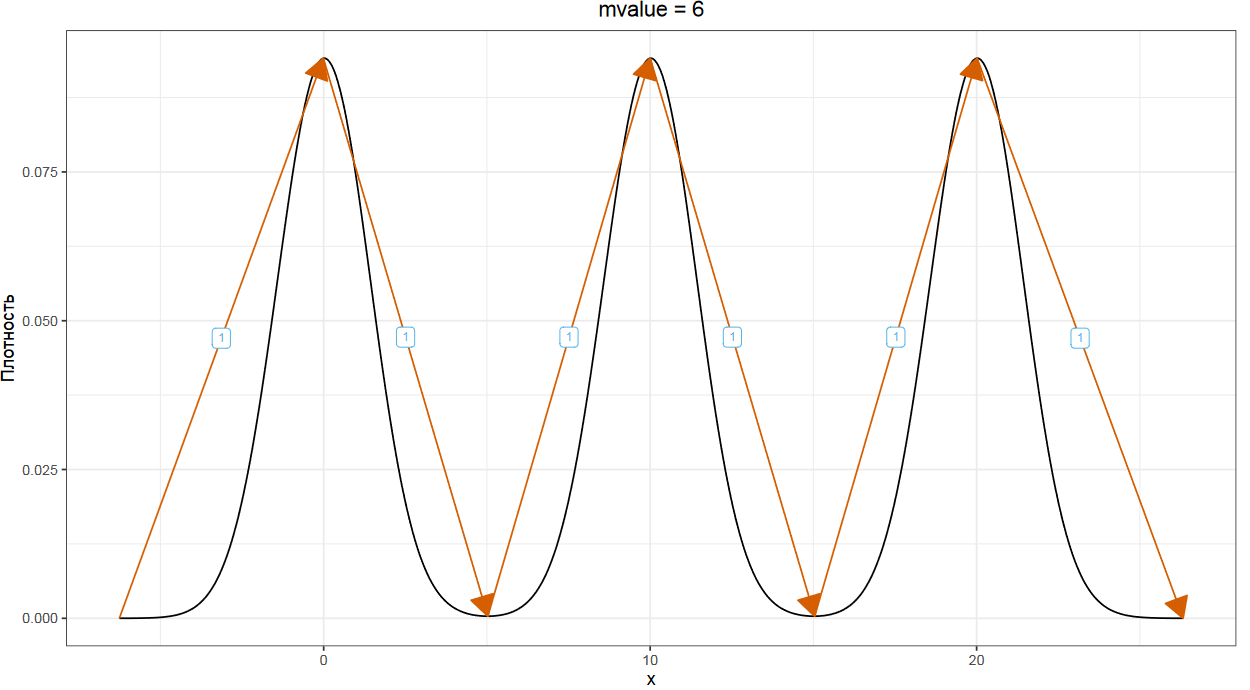
По аналогии, для идеального тримодального распределения mvalue равно шести. Казалось бы, что все разумно. Считаем mvalue, делим на два, получаем количество мод. Но как быть с реальными распределениями, которые далеки от идеальных картинок.
Как думаете, чему равно mvalue для вот этого графика?
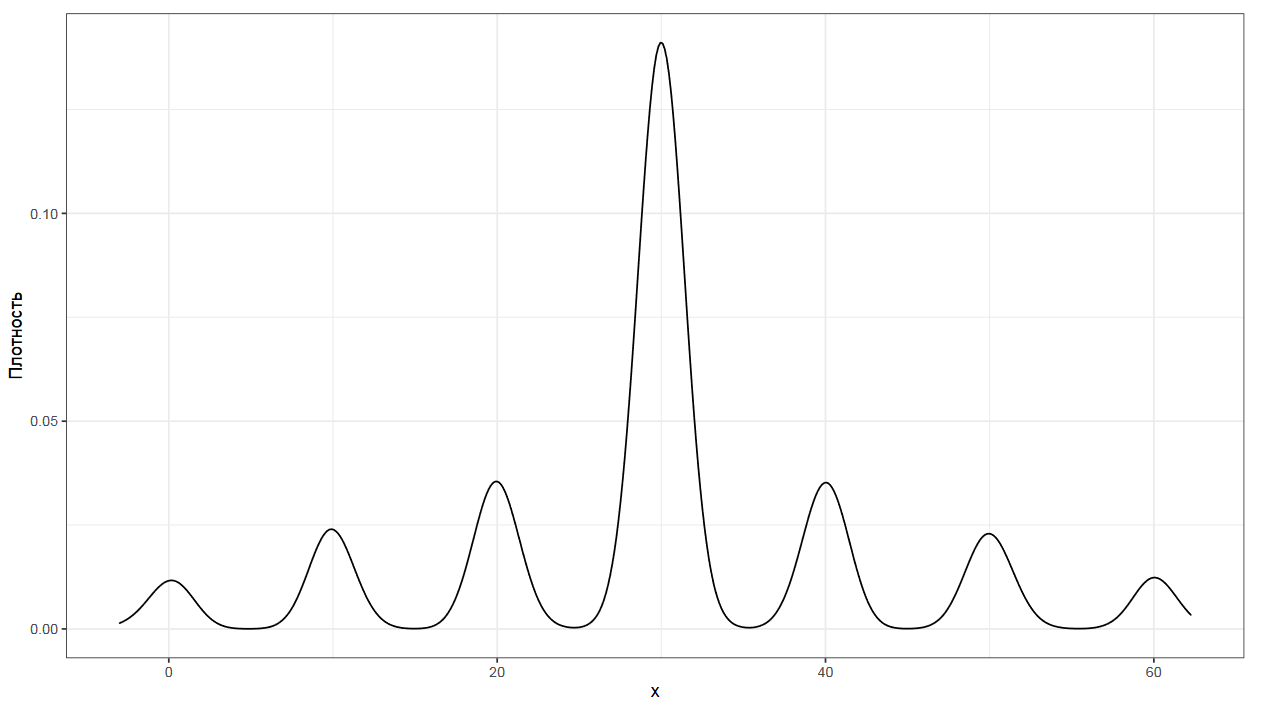
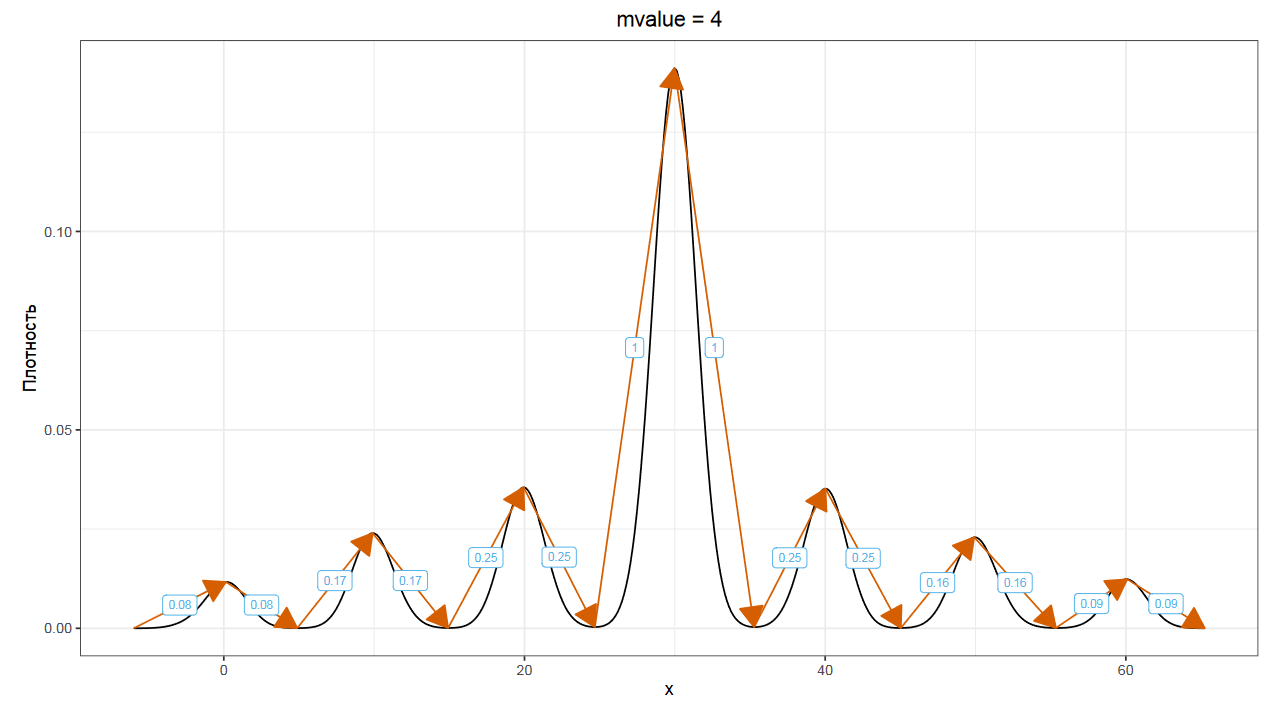
Правильный ответ — четыре, что как бы должно символизировать бимодальное распределение, но на деле это не так.
mvalue-подход позволяет очень грубо оценить степень мультимодальности, отсортировать графики плотности распределений по полученным оценкам и найти самые мультимодальные распределения. Но, увы, у него очень много крайних случаев, на которых мультимодальность оценивается не очень хорошо.
Lowland multimodality detection
Поэтому у меня есть еще одна авторская методика под названием Lowland multimodality detection, которая пытается оценить точное количество мод и найти их точные позиции.

Идея довольно проста. На первом шаге, мы строим график плотности распределения, основанный на квантильных оценка Харрела-Дэвиса. В случае эффектов дискретизации, используем джиттеринг, чтобы график получился более приличным. Далее, представляем, что внутренняя часть графика — это горный ландшафт, вид сбоку. А сверху на него идет дождь, от которого на нашем ландшафте возникают водоемы. Внутри ландшафта под водоемом все промокает, что дает нам подземные воды.
Для каждого водоема мы сравниваем площадь его воды с площадью соответствующего участка подземных вод. Если площадь водоема меньше, то мы объявляем такой водоем мелководьем и говорим, что он НЕ разделяет моды.
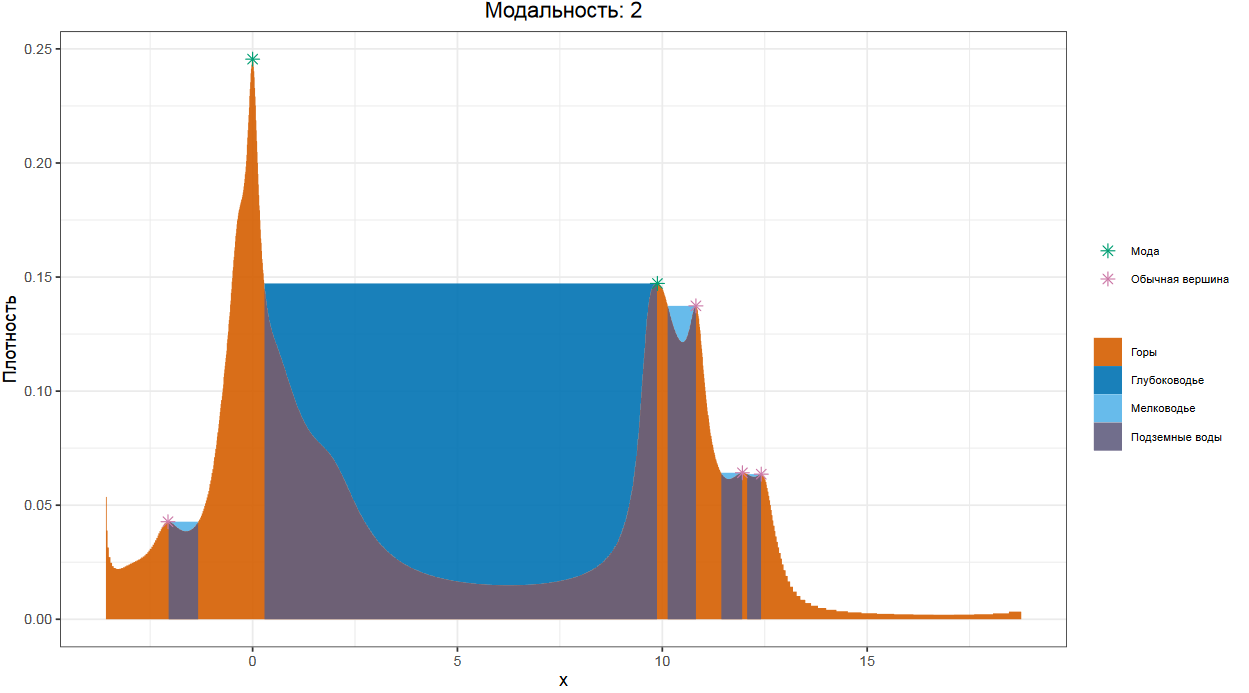
А вот если площадь водоема оказалась больше площади подземных вод, то это глубоководье, разделяющее две моды. Ну а сами моды находятся на самых высоких точках графика между глубоководными водоемами.
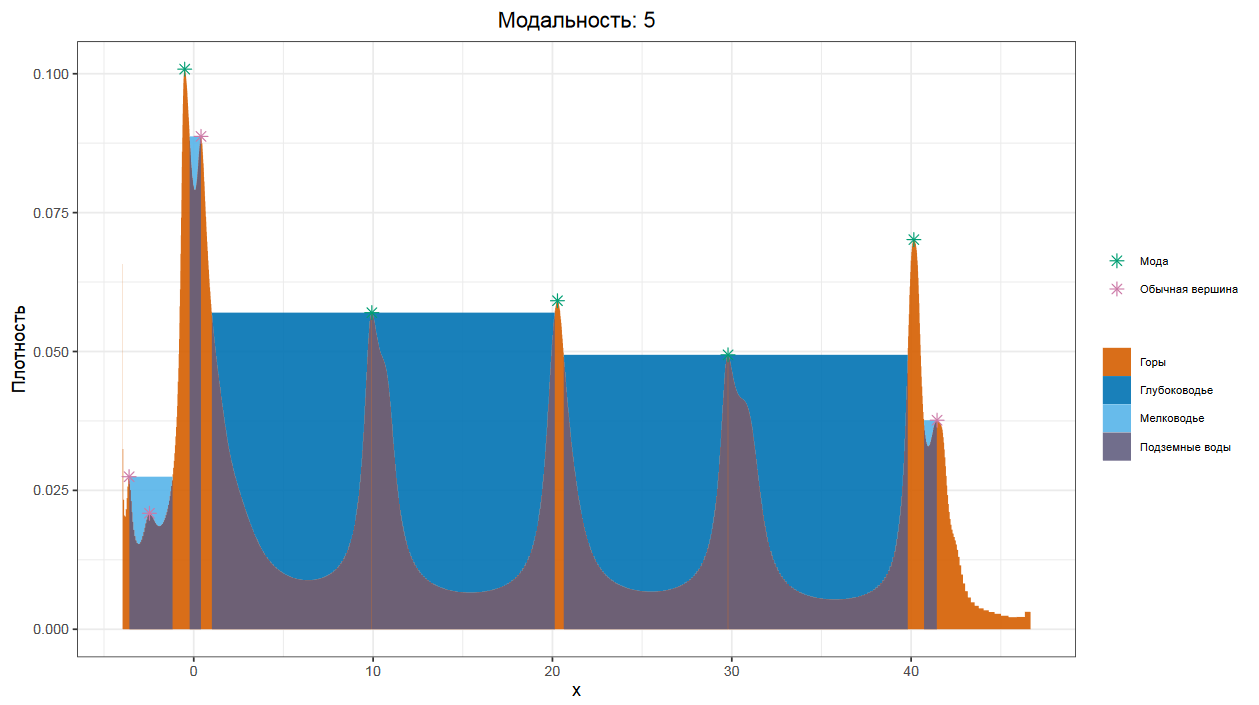
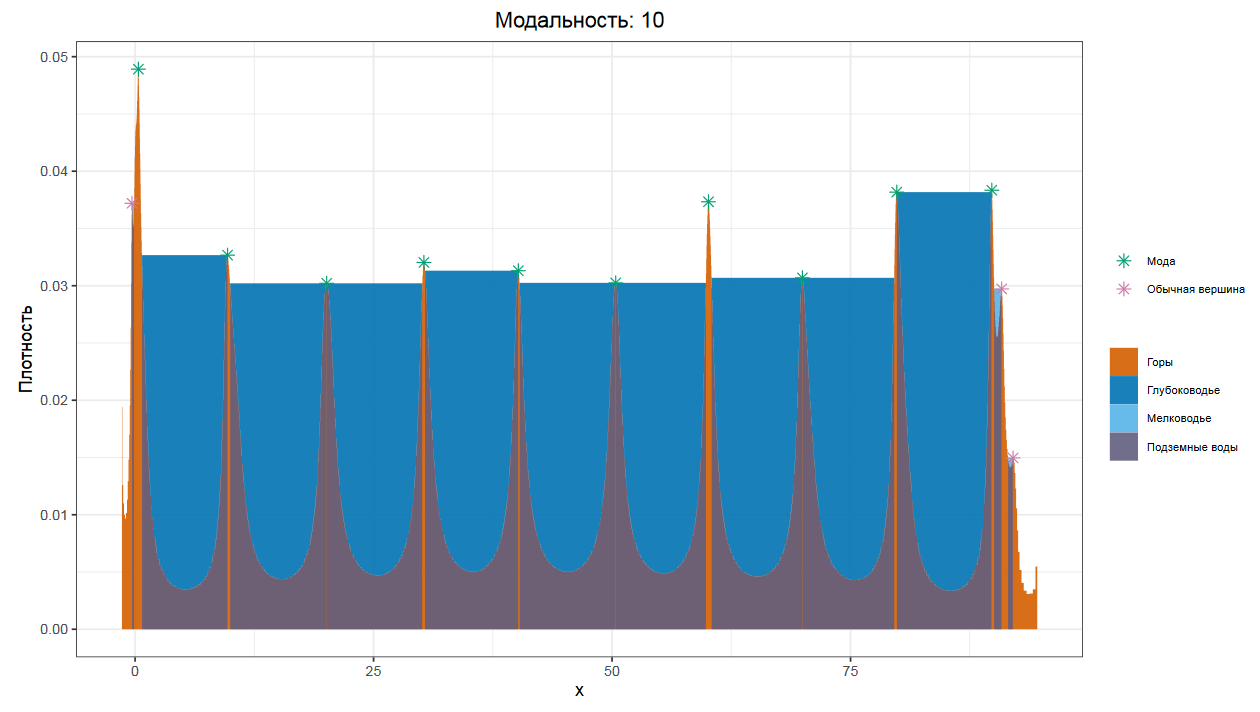
Как мы помним, график плотности распределения, основанный на квантильных оценках Харрела-Дэвиса, очень хорошо показывает эффекты мультимодальности. Поэтому можно легко и надежно обнаружить пятимодальные или даже десятимодальные распределения.
Интермодальные выбросы
После нахождения набора мод, можно делать и другие интересные вещи.
Например, искать интермодальные выбросы.
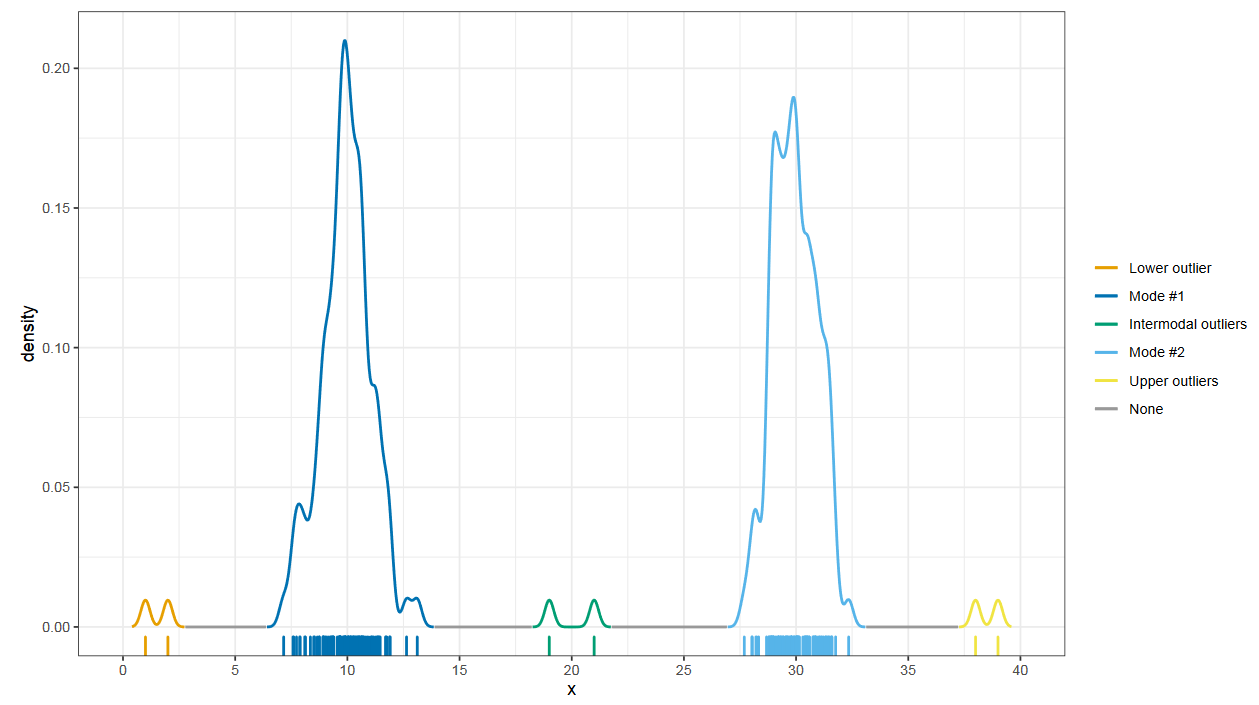
Выбросы — это не всегда экстремальные значения, это просто значения, которые далеки от общего скопления элементов выборки. Поэтому они могут присутствовать и между модами.
Вывод
Детектирование мультимодальности — это еще одна большая и сложная тема, над которой тоже нужно подумать.
Не существует подходов, которые работают хорошо всегда и везде. Но если вы подберете решение, которое даст адекватные результаты на ваших наборах данных, то вы сможете значительно улучшить качество анализа на распределениях, для которых центральной тенденции и дисперсии недостаточно.
Теория экстремальных значений
Мы переходим к последней теме, которая называется теория экстремальных значений
График
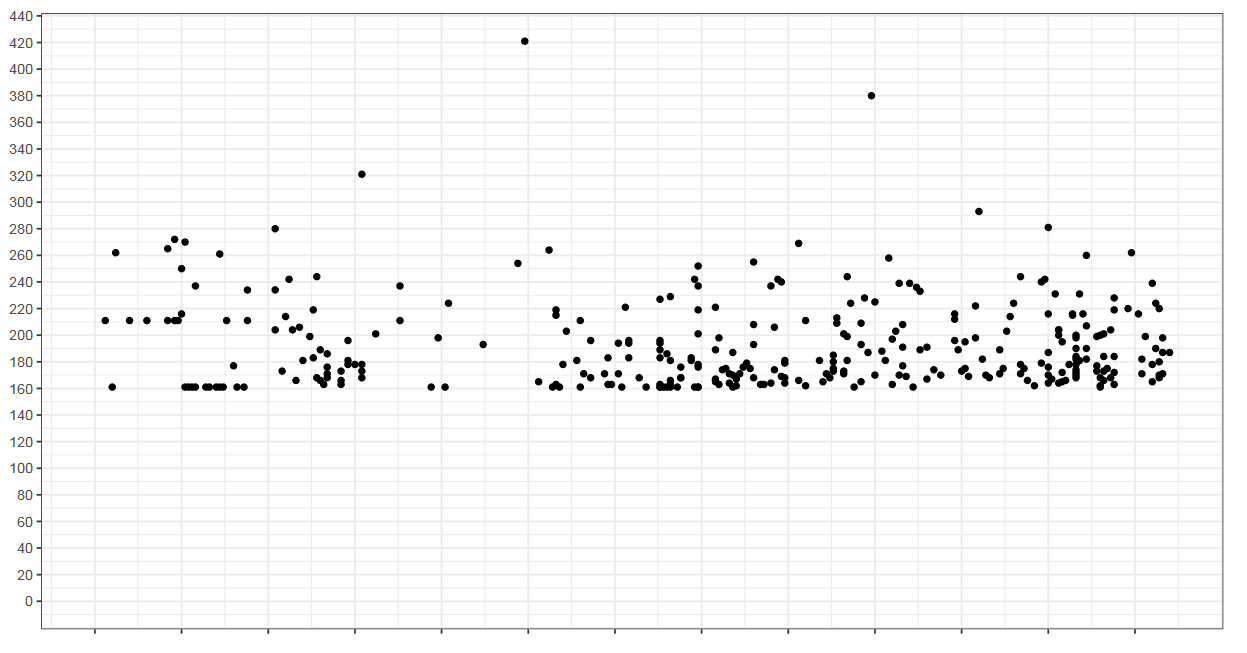
Прежде чем начать, давайте посмотрим на этот график. Как вы думаете, что здесь изображено? Возможно, вы могли подумать, что это график с перформанс-замерами.
Но на самом деле это график с уровнями наводнений в г. Санкт-Петербург с 1703 до 2011 года.

Самое больше наводнение произошло в 1824 году.
Абсолютно никто не ожидал, что такое наводнение вообще возможно, так как никто никогда не видел раньше ничего подобного.

{kind=link}
К счастью, сейчас у нас есть дамба, которая защищает Санкт-Петербург от таких катаклизмов.

Проектирование дамбы — сложное занятие.
Как выбрать подходящую высоту?
Распределение уровней наводнений
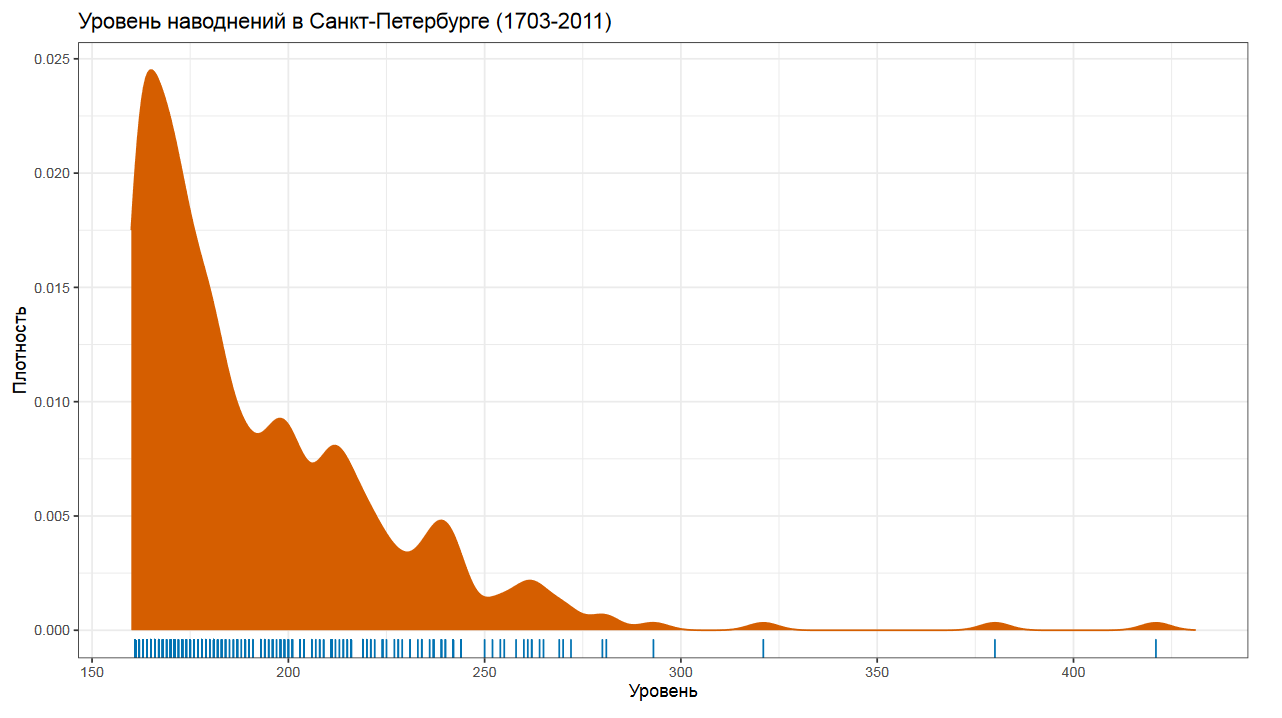
Просто посмотреть на максимальное историческое значение явно не достаточно. Ведь мы знаем, что каким бы ни был исторический максимум, всегда может случиться наводнение, которое поставит новый рекорд. При этом сильно высокой дамбу строить тоже не хочется, ведь это резко повысит расходы на строительство и архитектурную сложность конструкции.
Тяжелые хвосты
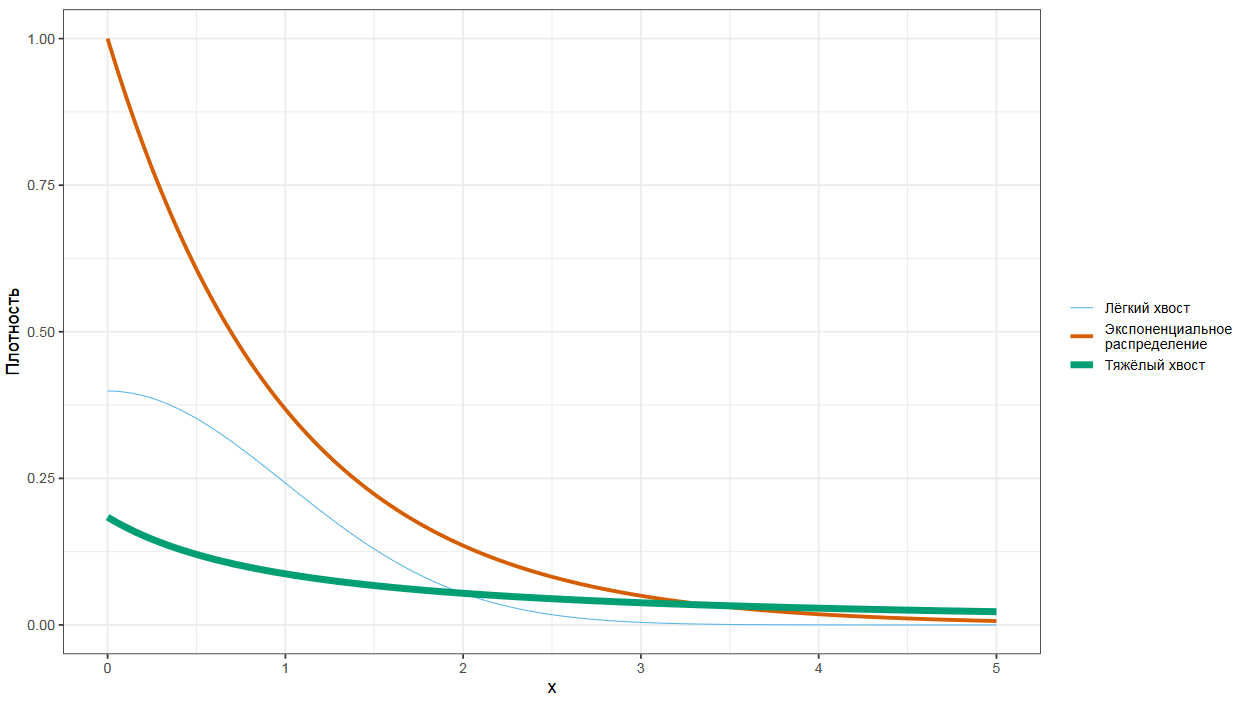
Если мы перейдем к математической классификации распределений, то мы можем сказать, что у распределения уровней наводнений тяжелый хвост. Если мы сравним тяжелохвостое распределение с экспоненциальным, то тяжелый хвост в какой-то точке графика обязательно окажется выше хвоста экспоненциального распределения.
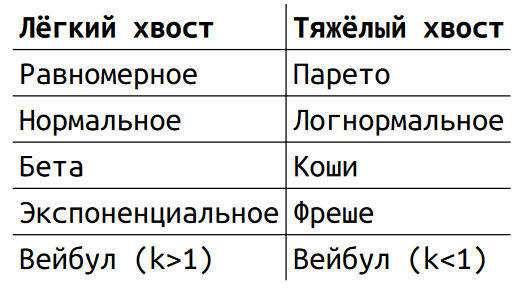
Примеры распределений
Распределения вроде равномерного, нормального, бета и экспоненциального имеют легкие хвосты. А вот такие распределения, как Парето, логнормальное, Коши или Фреше имеют тяжелые хвосты.
Приложения теории экстремальных значений
Но зачем же нам об этом знать? Дело в том, что тяжелые хвосты возникают в самых разных науках, и они всегда приносят очень много проблем, т.к. порождают экстремальные выбросы.
Теория экстремальных значений, которая изучает тяжелые хвосты, используется во многих естественно-научных дисциплинах от гидрологии и эпидемиологии, до предсказания торнадо.
А еще она используется в финансах, страховании, трейдинге и прочем финтехе, в котором экстремальные события также сильно портят жизнь. Вы можете стабильно зарабатывать в течении многих лет, а затем в один день потерять все состояние из-за очередного финансового кризиса, которого никто не ждал. При этом все вокруг могут долго говорить: «Такое невозможно, т.к. история не знает подобных примеров». Оттого-то так сложно предсказывать будущее, что исторических данных не всегда достаточно для оценки такого кризиса, который однажды может произойти.
В перформанс-анализе экстремальные значения также имеют огромную роль. Представьте, что вы делаете онлайн-магазин. И надвигается черная пятница, новый год, восьмое марта или еще какое-то особое событие, которое должно прокормить вас на весь следующий год. И вам очень хочется, чтобы сервера выдержали нагрузку. Но к какой нагрузке готовиться, если вы понимаете, что все исторические данные нагрузок были меньше, чем ожидается в этот особый день? При этом нужно выбрать какой-то ожидаемый максимум, к которому мы готовимся, так как покупать все вычислительные мощности Амазона будет явным перебором. С математической точки зрения нам нужно оценить хвостовые квантили распределения, которые могут превышать исторический максимум. И всякие Харрел-Дэвисы и Хиндманы-Фаны нам в этом не помогут, нам нужна теория экстремальных значений.
Центральная предельная теорема
Прежде, чем я вам расскажу про основные положения этой теории, нам будет полезно вспомнить центральную предельную теорему.
Допустим у нас есть некоторое распределение, из которого мы достаем выборки фиксированного размера.
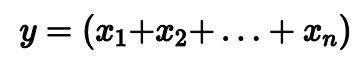
Для каждой выборки мы считаем сумму всех элементов.
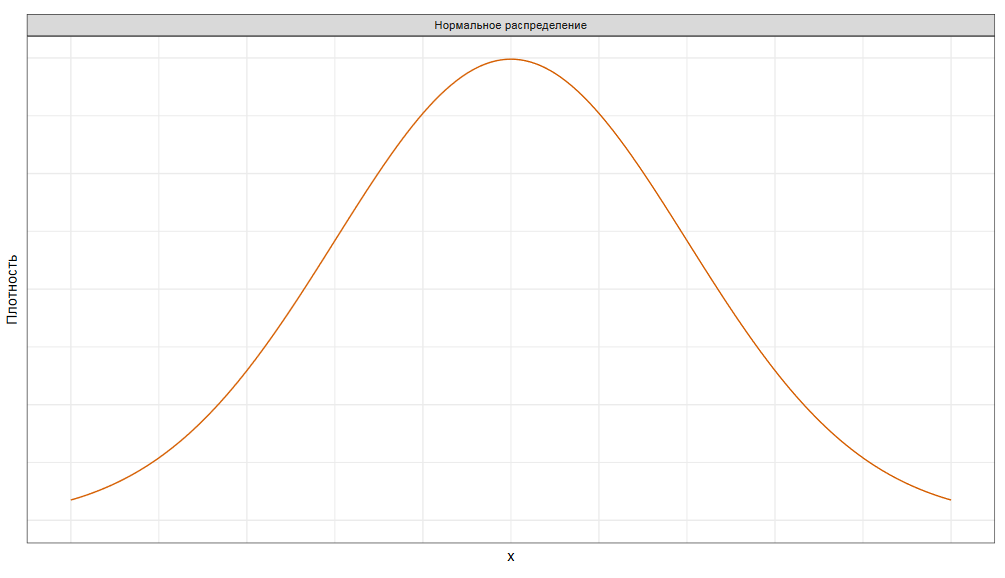
Из этих сумм мы составляем новое распределения.
Центральная предельная теорема говорит нам, что при определенных условиях в пределе это новое распределение будет нормальным. Нужно понимать, что так будет не везде и не всегда. Например, на некоторых тяжелохвостых распределениях, центральная предельная теорема работать не будет. А еще, если выборки будут недостаточно большие, то на практике сходимость к нормальности может происходить недостаточно быстро, это ведь предельная теорема, она нацелена на бесконечно большие выборки, которые не всегда удается собрать.
Теорема Фишера-Типпетта-Гнеденко
Теперь мы готовы перейти к первой теореме теории экстремальных значений, которая также известная как теорема Фишера-Типпетта-Гнеденко.

Начало там такое же, как и в центральной предельной теореме: из некоторого распределения мы достаем выборки фиксированного размера.
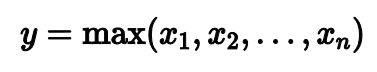
Но вместо суммы элементов, для каждой выборки мы считаем максимум.
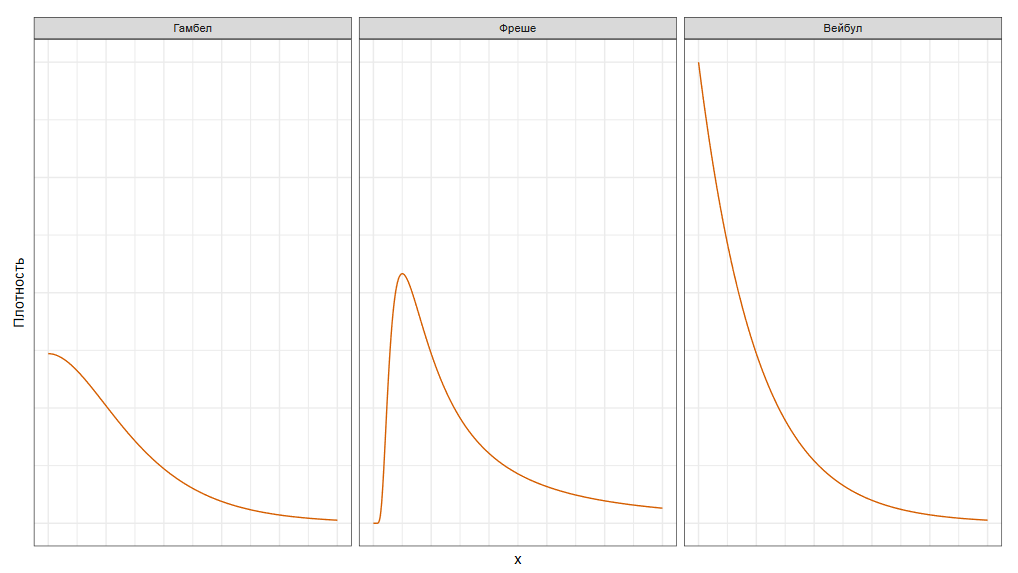
Далее, из этих максимумов мы составляем новое распределение. Теорема Фишера-Типпетта-Гнеденко говорит нам, что при определенных условиях мы в итоге получим распределение Гамбела, распределение Фреше или распределение Вейбула.
У этой теоремы есть много интересных приложений. Например, в гидрологии мы можем записывать максимальный уровень воды каждый год на основе пары столетий, на основе чего можно рассчитать с определенной вероятностью необходимый уровень высоты дамбы. А в перформанс-анализе мы можем записывать максимальную нагрузку на сервер каждый месяц, чтобы предсказать нагрузку, к которой нам стоит подготовиться перед черной пятницей. Или можем записывать ежедневную максимальную продолжительность некоторого интеграционного теста, чтобы превратить его в надежный перформанс-тест.
Но, увы, этой теоремой не всегда удобно пользоваться.
Теорема Пикандса-Балкемы-де Хаана
Хорошо, что у нас есть вторая теорема теории экстремальных значений, которая известна под названием теорема Пикандса-Балкемы-де Хаана.
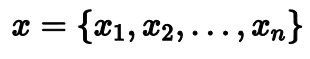
Пусть у нас есть некоторая довольно большая выборка из нашего распределения.
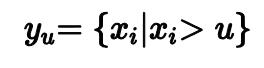
Если в некотором месте отрезать распределению хвост,то этот хвост можно будет аппроксимировать обобщенным распределением Парето.
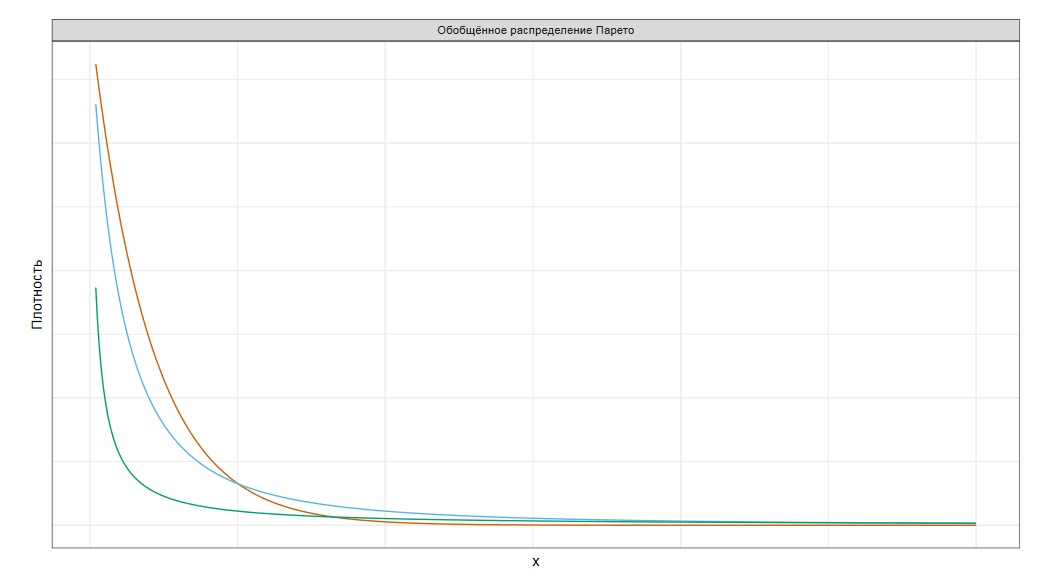
В наших реалиях это более удобная теорема, чтобы пользоваться ей на практике и предсказывать экстремальные выбросы выше исторического максимума.
Однако, ей не то чтобы легко пользоваться.
Теория экстремальных значений: R-пакеты
Для .NET нормальных пакетов с реализацией соответствующих методов я не нашел. Поэтому я подготовил небольшой обзор таких пакетов для языка программирования R, который активно используется практикующими статистами.

А пакетов таких есть очень много, все они довольно разные. Например, для подход Block Maxima, который основан на теореме Фишера-Типпетта-Гнеденко, реализован в 11 разных пакетах, каждый из которых имеет собственное видение на то, как это теорему правильно применять. А подход Peak-Over-Threshold, который основан на теореме Пикандса-Балкемы-де Хаана, доступен аж в 17 пакетах.

Выбираем пороговое значение
Давайте возьмем пакет POT (Peak Over Threshold), который является одним из самых популярных решений, и посмотрим, какие апишки там доступны.
Прежде всего, нам нужно выбрать точку, в которой мы будем отрезать распределению хвост.
tcplot(data, u.range, cmax = FALSE, r=1,
ulow = -Inf, rlow = 1, nt = 25, which = 1:npar, conf = 0.95,
lty = 1, lwd = 1, type = "b", cilty = 1, ask = nb.fig <
length(which) && dev.interactive(), ...)
mrplot(data, u.range, main, xlab, ylab,
nt = max(100, lenngth(data)), lty = rep(1,3),
col = c('grey', 'black', 'grey'), conf = 0.95, lwd = c(1, 1.5, 1), ...)
lmomplot(data, u.range, nt = max(50, length(data)), identify = TRUE, ...)
exiplot(data, u.range, tim.cond = 1, n.u = 50, xlab, ylab, ...)
diplot(data, u.range, main, xlab, ylab, nt = max(200, nrow(data)), conf=0.95, ...)Для выбора этой точки в пакете есть сразу пять разных функций. Но эти функции не выдают оптимальную точку, они строят графики, по которым точку нужно будет выбрать в ручном режиме.
Аппроксимируем обобщенное распределение Парето
Далее нужно аппроксимировать хвост, на основе имеющихся данных. Для этого в пакете есть функция fitgpd, которая поддерживает сразу 10 разных методов аппроксимации.

Как же выбрать самый подходящий метод?
Вывод
Как обычно, тут нужно подумать.
К сожалению, нет универсального подхода, в который можно засунуть выборку и получить хорошо аппроксимированный отрезанный хвост. Как и во всех ранее рассмотренных темах, у наших выборок и распределений есть очень много специфики, которая и определяет оптимальный подход. Но чтобы его выбрать, нужно во всем этом аккуратно разобраться и принять решение, основанное на бизнес-требованиях и имеющихся знаниях о ваших данных. Про теорию экстремальных значений можно было бы сделать серию отдельных лекций, но прямо сейчас у нас нет на это времени. Мне бы хотелось, чтобы вы просто запомнили, что такая теория есть, а затем вспомнили о ней в подходящей ситуации.
Заключение
А нам пора заканчивать доклад и подводить итоги.
Проблемы
Итак, у перформанс-распределений есть много своей специфики, которая резко усложняет их анализ.

Если вы хотите выполнять его не в ручном режиме, а автоматически, то вам нужно подойти к выбору правильных подходов с высоким уровнем ответственности.
Решения
Решений для каждой проблемы есть великое множество. Мне хочется только подчеркнуть те направления подходов, на которые стоит обратить особое внимание.
Прежде всего ищите непараметрические алгоритмы. Это означает, что алгоритм не требует, чтобы ваше распределение было нормальным или обладало какой-то особой формой.
Непараметрические алгоритмы поддерживают распределения произвольной формы. Когда мы говорим о робастной статистике, то мы подразумеваем, что несколько экстремальных выбросов не испортят нам полученные оценки.
Также нужно уметь детектировать мультимодальность, чтобы для распределений с несколькими модами использовать особые подходы.
А еще мы всегда должны быть готовы к тому, что рассматриваемое непрерывное распределение в самый неподходящий момент начнет демонстрировать дискретную природу, которая не всегда поддерживается методами классической статистики. Когда вы читаете характеристики разных методов, то помните, что чаще всего эти характеристики асимптотические, т.к. они подразумевают бесконечно большие выборки.
На практике у нас чаще всего данных не очень много, что может сделать асимптотически-хорошие алгоритмы абсолютно бесполезными.
В этом докладе мы обсудили только описательную статистику одного-единственного распределения. На практике чаще всего нам хочется делать более интересные вещи вроде стабильных перформанс-тестов, надежного перформанс-мониторинга, достоверных отчетов о сравнении перформанс разных алгоритмов.
Надеюсь, что однажды я соберу все такие решения в Perfolizer, так что следите за обновлениями.
Но даже когда такой набор инструментов будет готов, необходимость разбираться в математической стороне вопроса никуда не уйдет. Без этого вы просто не сможете выбрать правильный метод, который нужен в конкретной ситуации конкретно вам. А методы описательной статистики используются как кирпичики при построении более сложных подходов.
Нелинейность умножения процентов
При соединении этих кирпичиков важно понимать нелинейность умножения процентов.
Представьте, что у вас есть комбинация из 20 разных методов, каждый из которых работает только в 95 процентов случаев.
Как думаете, чему равно 0.95 в степени 20?
Правильный ответ: всего-навсего около 36 процентов.
Если мы улучшим работоспособность каждого кирпичика до 96 процентов, то в итоге будем иметь 44%.

Вы только задумайтесь об этом. Улучшение каждого метода на четыре десятых процента улучшает итоговый результат на целых 7.5%.
Конечно, это очень грубая и утрированная модель, но она хорошо описывает то, как комбинация методов ведет себя в реальной жизни. Именно поэтому мы столько внимания уделили всяким Гауссовым эффективностям, точкам перелома и прочим метрикам. Даже небольшое улучшение этих показателей при выборе методов описательной статистики может оказать драматический эффект на успешность применения комбинации этих методов.
Хорошие книжки
Ну а чтобы сделать правильный выбор, нужно хорошо разобраться в математической статистике.
Я подготовил для вас подборку из нескольких книжек, с которых можно начать вникать в данную дисциплину. В этих книжках есть как темы, про которые мы поговорили, так и более продвинутые темы вроде статистических тестов, размера эффектов, байесовской статистики, функций правдоподобия и прочих увлекательных и занимательных математических инструментов.

Если у вас будет достаточно усердия, чтобы изучить представленную подборку, то приходите ко мне, я выдам вам список литературы для дополнительного чтения.
Rand R. Wilcox — «Introduction to Robust Estimation and Hypothesis Testing»
Ricardo A. Maronna, Douglas R. Martin, Victor J. Yohai — «Robust Statistics»
Peter J. Huber — «Robust Statistics»
Peter J. Rousseeuw, Frank R. Hampel, Elvezio M. Ronchetti, Werner A. Stahel — «Robust Statistics»
Geoff Cumming, Robert Calin-Jageman — «Introduction to the New Statistics: Estimation, Open Science, and Beyond»
Geoff Cumming — «Understanding the New Statistics: Effect Sizes, Confidence Intervals, and Meta-Analysis»
John K. Kruschke — «Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan»
Richard McElreath — «Statistical Rethinking: A Bayesian Course with Examples in R and Stan»
Richard Royall — «Statistical Evidence: A Likelihood Paradigm»
Alex Reinhart — «Statistics Done Wrong: The Woefully Complete Guide»
Darrell Huff, Irving Geis — «How to Lie with Statistics»
David Freedman, Robert Pisani, Roger Purves — «Statistics»
Lisa L. Harlow, Stanley A. Mulaik, James H. Steiger — «What If There Were No Significance Tests?»
Paul D. Ellis — «The Essential Guide to Effect Sizes»
Jayakrishnan Nair, Adam Wierman, Bert Zwart — «The Fundamentals of Heavy Tails: Properties, Emergence, and Estimation»
Rolf-Dieter Reiß, Michael Thomas — «Statistical Analysis of Extreme Values: With Applications to Insurance, Finance, Hydrology and Other Fields»
Nassim Nicholas Taleb — «Statistical Consequences of Fat Tails: Real World Preasymptotics, Epistemology, and Applications»
Надеюсь, вам было интересно и познавательно.
Не забывайте думать при анализе ваших данных, и тогда вы сможете грамотно проанализировать ваши перформанс-распределения.
Спасибо за внимание!
Если вы добрались досюда, похоже, что этот доклад с Heisenbug вас всерьёз заинтересовал! А в таком случае может заинтересовать и следующий Heisenbug. Конкретно матстатистики там не обещаем, но тема тестирования производительности там будет, как и другие разновидности тестирования.
Комментарии (2)

Prometheus22
00.00.0000 00:00Спасибо за такую объемную и интересную статью! Очень понравилось, подчерпнул для себя много нового. Хотелось бы уточнить один момент, возможно, некорректно понял.
В статье на теме «Центральная предельная теорема» говорится о том, что «Для каждой выборки мы считаем сумму всех элементов» и «Из этих сумм мы составляем новое распределения». Однако в иных источниках (и из моих вузовских лекций по статистической радиотехнике) известно, что должна формироваться новая случайная величина, которая состоит из суммы других случайных величин (с одинаковым распределением) с некоторыми другими распределениями похожего масштаба, и при достаточно большом количестве этих величин, распределение стремится к нормальному. Это немного не сходится с Вашим определением, так как согласно Вашему определению мы суммируем все элементы последовательности каждого распределения, и все суммы всех распределений дадут нормальное распределение, а согласно представленному мной - последовательности параллельно суммируются, получаются новые элементы, полученные не суммой по одному распределению, а по всем.
Пример источника (в при самостоятельном поиске везде обнаруживаются плюс-минус одинаковые и именно такие определения)
P.s. Статья очень понравилась, правда :)
vanxant
Статья - бомба! Материал объемом на книгу уложен в 15 минутный лонгрид. Талант!
(Ps. Не в претензию, но всё-таки, используйте латех для формул)