

Сегментация, то есть распознавание пикселей изображения, принадлежащих объекту — базовая задача компьютерного зрения, используемая в широком спектре применений, от анализа научных снимков до редактирования фотографий. Однако для создания точной модели сегментации под конкретные задачи обычно требуется высокоспециализированный труд технических экспертов, имеющих доступ к инфраструктуре обучения ИИ и большим объёмам тщательно аннотированных данных, относящихся к предметной области.
Наша лаборатория Meta AI* стремится сделать сегментацию более доступной, основав проект Segment Anything: новую задачу, датасет и модель для сегментации изображений (подробности см. в нашей исследовательской статье). Мы публикуем нашу Segment Anything Model (SAM) и датасет масок Segment Anything 1-Billion mask dataset (SA-1B) (крупнейший в мире датасет сегментации), чтобы их можно было использовать во множестве разных областей и стимулировать дальнейшие исследования базисных моделей компьютерного зрения. Мы открываем доступ к датасету SA-1B, позволяя использовать его в исследовательских целях; модель Segment Anything Model доступна по открытой лицензии (Apache 2.0). Вы можете протестировать демо SAM со своими собственными изображениями.
* Принадлежит корпорации Meta Platforms, которая признана экстремистской организацией, её деятельность в России запрещена.
Основной целью проекта Segment Anything стало снижение потребности в экспертизе моделирования под конкретные задачи, в вычислительных ресурсах для обучения и аннотирования собственных данных с целью сегментации изображений. Для реализации этого видения мы поставили перед собой задачу создания базисной модели для сегментации изображений: модель с возможностью ввода промптов, обученной на разнообразных данных и способной адаптироваться под конкретные задачи аналогично тому, как промпты используются в моделях обработки естественного языка. Однако данные сегментации, необходимые для обучения такой модели, в отличие от изображений, видео и текстов, не были доступны онлайн или где-либо ещё. Поэтому в процессе работы над Segment Anything мы решили параллельно разработать управляемую промптами модель сегментации общего назначения и использовать её для создания датасета сегментации беспрецедентного масштаба.
SAM обучили общему понимаю того, что такое объекты; она способна генерировать маски для любого объекта на любом изображении и в любом видео, в том числе для объектов и типов изображений, которые не встречались ей во время обучения. SAM достаточно обобщена, чтобы покрывать широкий спектр областей применения и может использоваться без необходимости дополнительного обучения (это свойство часто называют zero-shot transfer) в исходном виде в новых «предметных областях» изображений, будь то подводные снимки или исследования клеток под микроскопом.
В будущем SAM можно будет использовать для расширения возможностей приложений в различных областях, требующих поиска и сегментации любого объекта на любом изображении. Для сообщества исследователей ИИ SAM может стать компонентом более крупных ИИ-систем с целью выработки более общего мультимодального понимания мира, например, для распознавания одновременно и визуального, и текстового содержимого веб-страницы. В сфере AR/VR модель SAM позволит выбирать объект на основании направления взгляда пользователя и «преобразовывать» его в 3D. Для создателей контента SAM может расширить возможности творческих задач, например, извлечение областей изображений для коллажей или монтажа видео. Также SAM можно использовать в научных исследованиях природных явлений на Земле и даже в космосе, например, с целью обнаружения в видео животных или объектов для изучения и трассировки. Мы верим, что возможности модели широки и с радостью будем узнавать новые способы её применения, о которых пока даже не догадываемся.
Архитектура Segment Anything на основе промптов обеспечивает гибкую интеграцию с другими системами. SAM может получать входные промпты, например, направление взгляда пользователя со шлема AR/VR.
SAM: обобщённый подход к сегментации
В прошлом для решения любых видов задач сегментации существовало два класса методик. Первая (интерактивная сегментация) позволяла сегментировать любой класс объектов, но требовала вмешательства пользователя, итеративно указывающего маску. Вторая (автоматическая сегментация) позволяла сегментировать конкретные заданные заранее категории объектов (например, котов или стулья), однако требовала существенных объёмов размеченных вручную объектов для обучения (например, тысяч или даже десятков тысяч примеров сегментированных котов), а также вычислительных ресурсов и технической экспертизы для обучения модели сегментации. Ни одна из этих двух методик не обеспечивала обобщённого, полностью автоматического подхода к сегментации.
SAM стала объединением этих двух классов методик. Это единая модель, способная с лёгкостью выполнять как интерактивную, так и автоматическую сегментацию. Управляемый промптами интерфейс модели (о нём мы скажем чуть ниже) можно гибко использовать в широком спектре задач сегментации благодаря простому созданию нужного промпта модели (щелчков мыши, прямоугольников, текста и так далее). Кроме того, SAM обучена на разностороннем высококачественном датасете из более чем одного миллиарда масок (собранных в рамках этого проекта), что позволяет обобщать модель до новых типов объектов и изображений, не наблюдавшихся во время обучения. Такая способность к обобщению означает, что специалистам больше не понадобится собирать собственные данные сегментации и выполнять тонкую настройку модели под свой способ применения.
В целом, эти возможности позволяют обобщать SAM на новые задачи и новые предметные области. Такой гибкости в сфере сегментации изображений удалось достигнуть впервые.
Вот короткое видео с демонстрацией некоторых возможностей SAM:
(1) SAM позволяет пользователям сегментировать объекты простым щелчком мыши или интерактивно щёлкая по точкам, включаемым в объект и исключаемым из него. Также в качестве промпта модели может использоваться ограничивающий прямоугольник.
(2) В случае возникновения неопределённости относительно сегментируемого объекта SAM может выдавать несколько валидных масок: это важная и необходимая способность для решения задачи сегментации в реальном мире.
(3) SAM способна автоматически находить все объекты на изображении и создавать их маски.
(4) SAM может генерировать в реальном времени маску сегментации для любого промпта после предварительного вычисления эмбеддинга изображения, что позволяет взаимодействовать с моделью в реальном времени.
Как работает SAM: сегментация на основе промптов
В обработке естественного языка, а с недавнего времени — и в компьютерном зрении одним из наиболее интересных направлений развития являются базисные модели, которые могут выполнять обучение zero-shot и few-shot для новых датасетов и задач при помощи техник «промптинга». Мы использовали это направление в качестве источника вдохновения.
Мы обучили SAM возвращать валидную маску сегментации для любого промпта, а промпт при этом может быть точками фона/переднего плана, приблизительный прямоугольник или маска, произвольный текст или, в общем случае, любая информация, сообщающая, что нужно сегментировать на изображении. Требование возврата валидной маски просто означает, что даже когда промпт неоднозначен и может относиться к нескольким объектам (например, точка на рубашке может означать или рубашку, или человека в ней), результатом должна быть бинарная маска для одного из этих объектов. Эта задача используется для предварительного обучения модели и для решения дальнейших общих задач сегментации при помощи промптинга.
По нашим наблюдениям, задача предварительного обучения и интерактивный сбор данных накладывают определённые ограничения на архитектуру модели. В частности, для эффективного аннотирования модель должна выполняться в реальном времени на CPU в веб-браузере, чтобы аннотаторы могли интерактивно использовать SAM. Хотя ограничение на среду исполнения подразумевает компромисс между качеством и средой исполнения, мы выяснили, что на практике эта простая архитектура даёт хорошие результаты.
Внутри системы кодировщик изображений создаёт единовременный эмбеддинг для изображения, а легковесный кодировщик в реальном времени превращает любой промпт в вектор эмбеддинга. Эти два источника информации комбинируются в легковесном декодере, прогнозирующем маски сегментации. После вычисления эмбеддинга изображения SAM может создать в веб-браузере сегмент для любого промпта всего за 50 милесекунд.
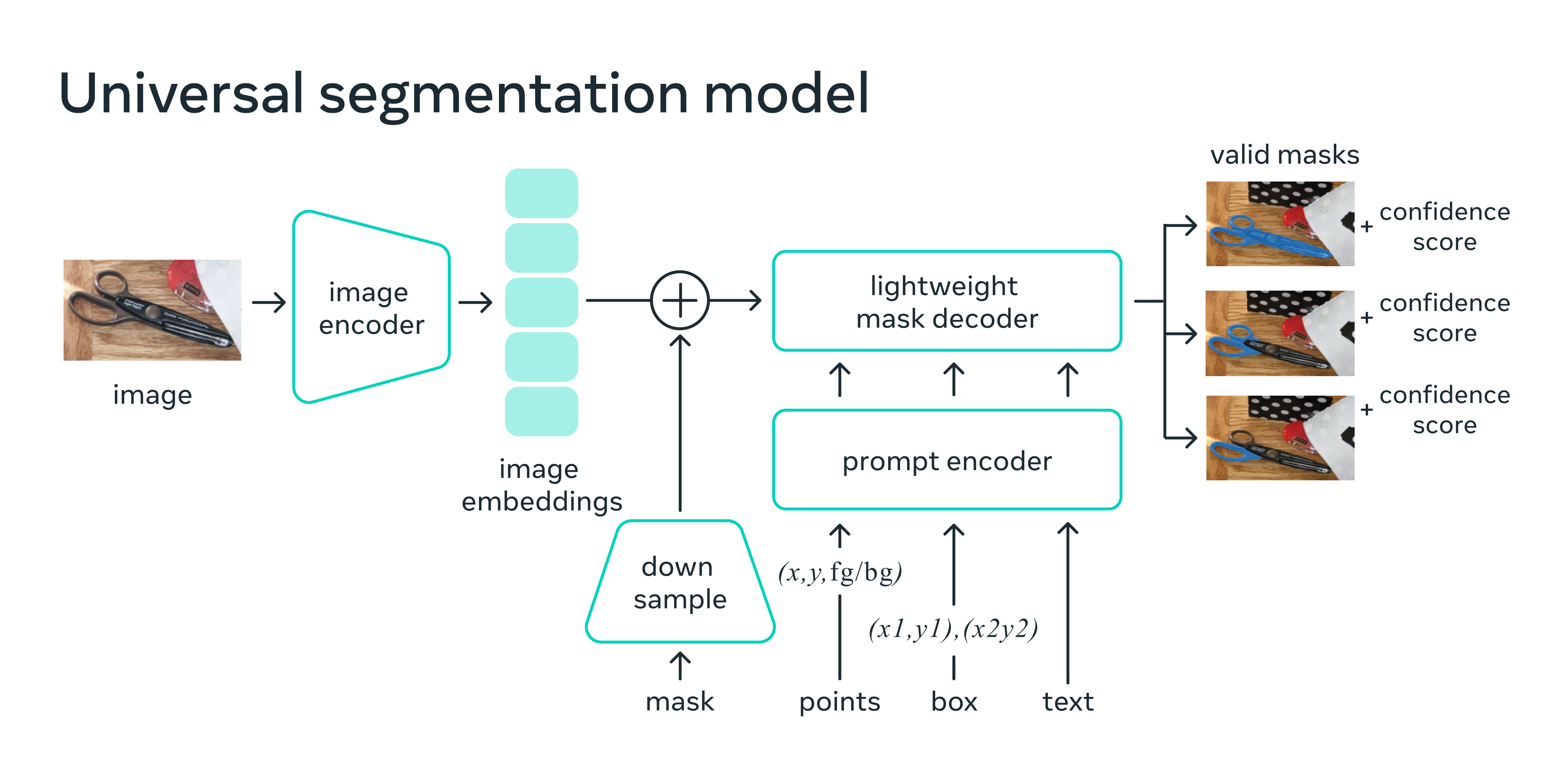
В веб-браузере SAM, по сути, преобразует признаки изображения и множество эмбеддингов промпта для создания маски сегментации.
Сегментация одного миллиарда масок: как мы создали SA-1B
Для обучения нашей модели нам нужен был огромный и разнообразный источник данных, которого в начале нашей работы не существовало. Выпущенный нами датасет сегментации на сегодня является самым крупным. Данные были собраны при помощи SAM. В частности, разметчики использовали SAM для интерактивной разметки изображений, а затем размеченные ими данные, в свою очередь, использовались для обновления SAM. Мы повторяли этот цикл много раз, чтобы итеративно совершенствовать и модель, и датасет.
Благодаря SAM сбор новых масок сегментации стал быстрым, как никогда.
При использовании нашего инструмента для интерактивного аннотирования маски требуется примерно 14 секунд. Наш процесс аннотирования масок всего в два раза медленнее, чем аннотирование ограничивающих прямоугольников, которое при использовании самых быстрых инструментов аннотирования занимает примерно 7 секунд. Если сравнивать с предыдущими крупномасштабными проектами сбора данных сегментации, наша модель в 6,5 раз быстрее, чем полностью ручное аннотирование масок из многоугольников в COCO и в два раза быстрее, чем предыдущий самый большой проект аннотирования данных, в котором тоже использовалась помощь модели.
Однако применение интерактивного аннотирования масок не обеспечит достаточного уровня масштабирования для создания датасета из одного миллиарда масок. Поэтому для генерации датасета SA-1B мы собрали движок обработки данных. Этот движок состоит из трёх «передач». На первой передаче модель помогает аннотаторам, как это описано выше. Вторая передача — это смесь полностью автоматического аннотирования и аннотирования с помощью модели, что позволяет увеличить разнообразие собираемых масок. Последняя передача движка обработки данных — это полностью автоматическое создание данных, позволяющее масштабировать наш датасет.
Готовый датасет содержит более 1,1 миллиарда масок сегментации, собранных из примерно 11 миллионов лицензированных и сохраняющих конфиденциальность изображений. SA-1B содержит в четыреста раз больше масок, чем любой другой датасет сегментации; ручная проверка показала, что маски обладают высоким качеством и разнообразием, а в некоторых случаях даже сравнимы по качеству с масками из предыдущих, гораздо меньших датасетов, полностью размеченных вручную.
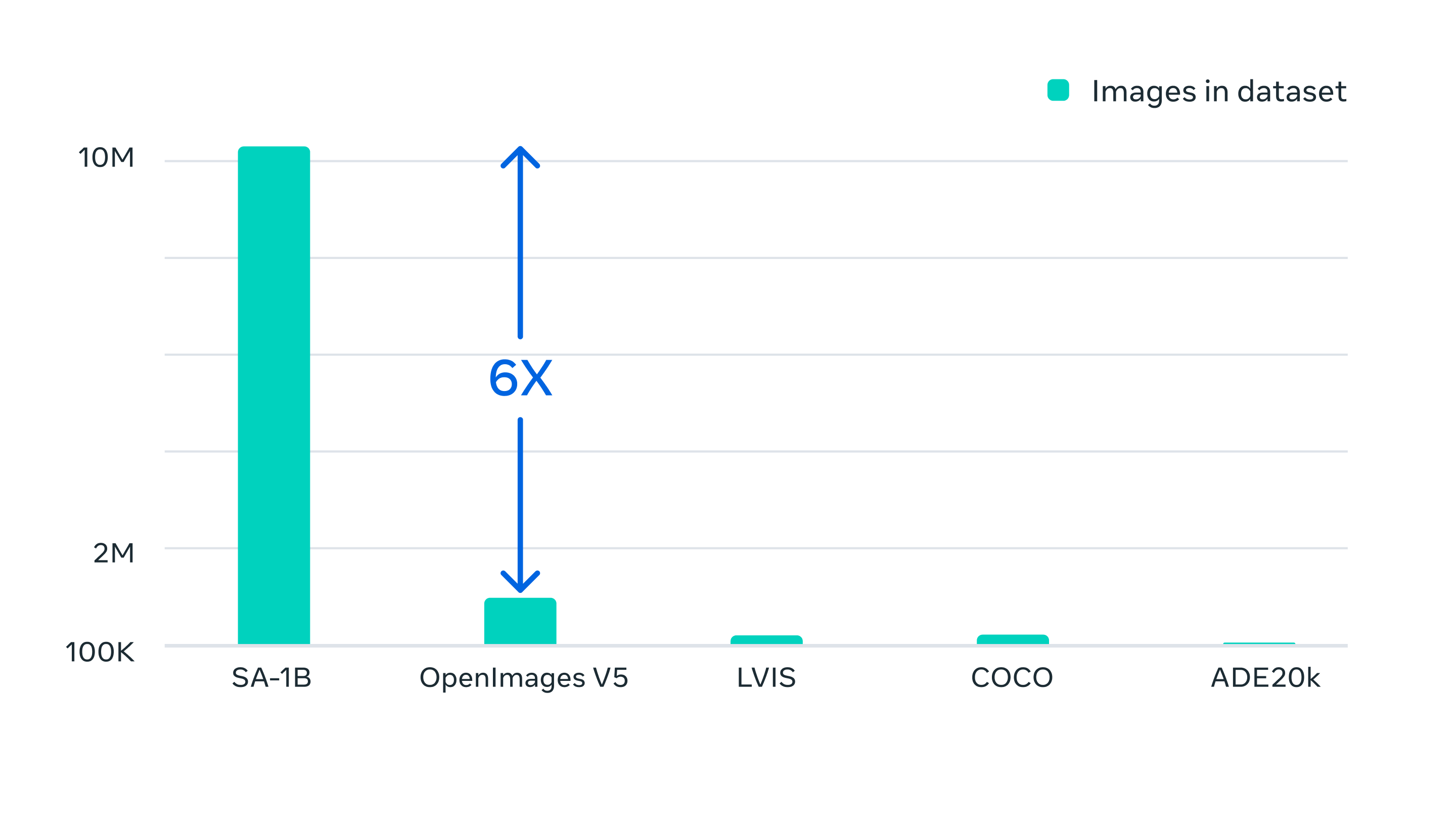
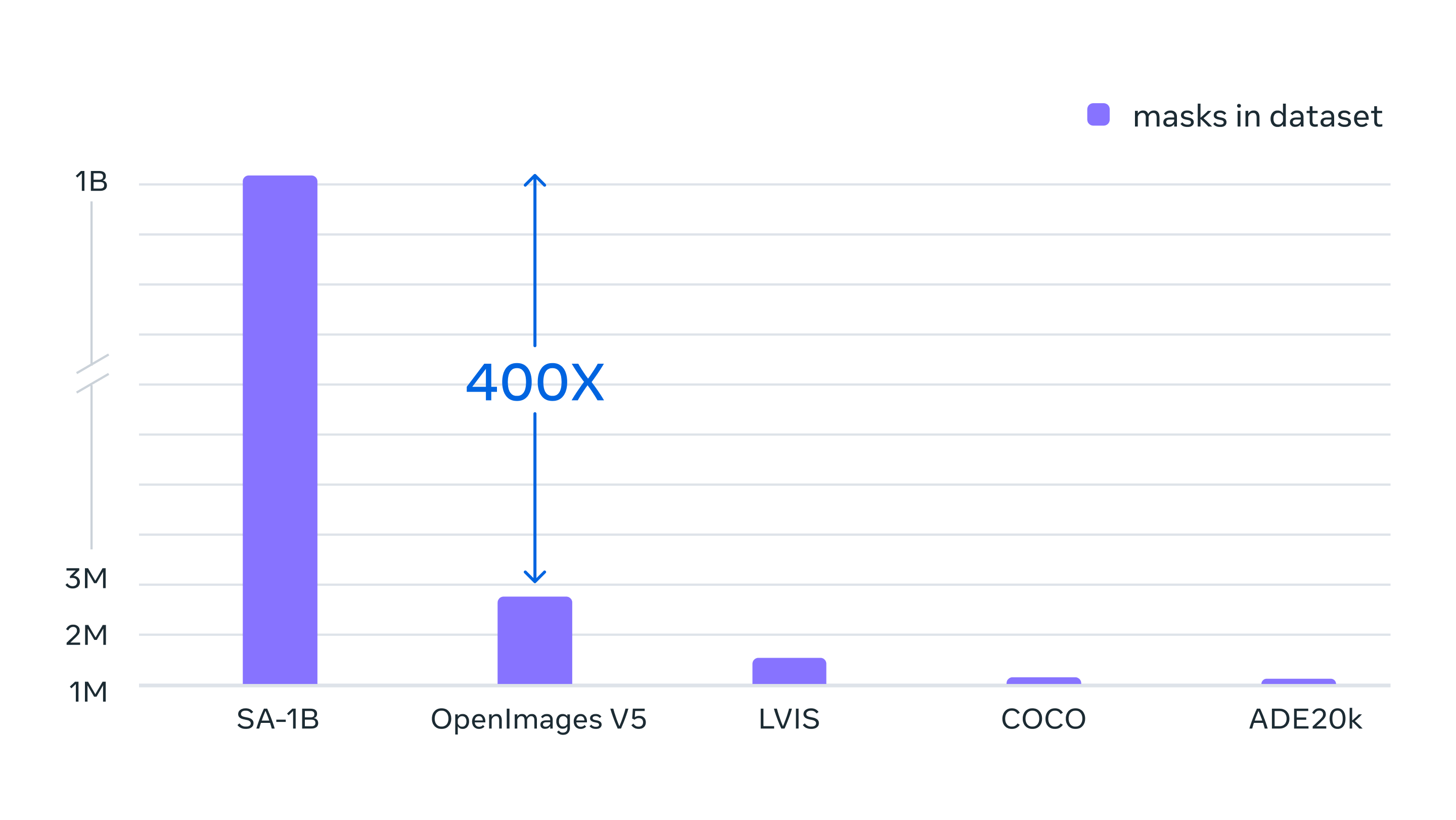
Возможности Segment Anything стали результатом обучения на миллионах изображений и масок, собранных при помощи движка обработки данных. В итоге мы получили датасет из более чем миллиарда масок сегментации, что в четыреста раз больше, чем самый крупный датасет сегментации до него.
Изображения для SA-1B брались из источника фотографий из разных стран, чтобы обеспечить разнообразное множество географических регионов и уровней дохода. Хотя мы признаём, что некоторые географические регионы всё ещё представлены недостаточно широко, в SA-1B содержится большее количество и разнообразие изображений, чем в любом другом датасете сегментации до него. Более того, мы проанализировали возможные перекосы нашей модели по гендерному соотношению, цвету кожи и возрастному диапазону людей, и выяснили, что точность результатов SAM для разных групп схожа. Мы надеемся, что это сделает нашу работу более полезной для применения в реальном мире.
Благодаря датасету SA-1B стало возможным наше исследование, но он может помочь и другим исследователям обучать базисные модели для сегментации изображений. Мы также надеемся, что эти данные смогут стать фундаментом для новых датасетов с дополнительными аннотациями, например, с текстовым описанием, соответствующим каждой маске.
Что нас ждёт в будущем

В будущем SAM можно будет использовать для распознавания повседневных предметов через AR-очки, помогающие пользователям напоминаниями и подсказками.

SAM имеет возможность повлиять на широкий спектр предметных областей; может быть, когда-нибудь он поможет фермерам в ведении хозяйства или биологам в их исследованиях.
Опубликовав свои исследования и датасет, мы надеемся ускорить изучение сегментации и более широкого понимания изображений и видео. Наша управляемая промптами модель сегментации может выполнять задачу сегментации, работая компонентом более крупной системы. Возможность комбинирования — это мощный инструмент, позволяющий использовать одну модель различными способами, возможно, даже для решения задач, неизвестных на момент проектирования модели. Мы надеемся, что компонентная архитектура системы, которая стала возможной благодаря таким техникам, как prompt engineering, позволит применять её в более широком спектре областей, чем системы, обученные на выполнение конкретного набора задач, и что SAM сможет стать мощным компонентом в таких сферах, как AR/VR, создание контента, наука и системы ИИ общего назначения. В будущем мы предвидим более тесную связь между пониманием изображений на уровне пикселей и более высокоуровневым семантическим пониманием визуального контента, что позволит создавать ещё более мощные системы ИИ.