
Известная шутка программистов гласит, что если решение вашей проблемы включает в себя парсинг текста при помощи регулярного выражения, то теперь у вас есть две проблемы. Некоторые программисты, прочитав шутку, решают попробовать иной подход. Возможно, регулярные выражения не так уж нужны. Возможно, задачу можно решить простым split строки или чем-то подобным. Однако другие могут задуматься немного глубже и задаться вопросом: «А если я сделаю нечто настолько дерзкое, что в результате получу три проблемы?» Мой пост написан в таком духе!
В нём используется код на Python, однако его легко можно адаптировать под любой язык с поддержкой функций высшего порядка.
▍ Элементарные частицы
Если вы задумаетесь о парсинге, то поймёте, что во многом он связан с потреблением входных данных. Давайте напишем функцию, выполняющую эту задачу:
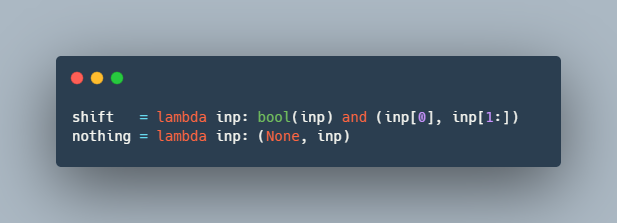
def shift(inp):
return bool(inp) and (inp[0], inp[1:])Получая входную последовательность
inp, она возвращает первый элемент inp[0] и все оставшиеся элементы inp[1:]. Если входных данных не было, она возвращает False. Функция выглядит странно, но вот как она работает пошагово для символов строки:>>> shift('bar')
('b', 'ar')
>>> shift('ar') # Применяется к оставшимся символам 'ar'
('a', 'r')
>>> shift('r')
('r', '')
>>> shift('')
False
>>>Всегда полезно бывает создать для каждой функции обратную ей функцию. По крайней мере, этому я научился, работая над ПО для физических расчётов. Что противоположно потреблению входных данных? Разумеется, отсутствие потребления входных данных. Давайте напишем эту функцию:
def nothing(inp):
return (None, inp)nothing() не выполняет обработку. Она возвращает None для любых входных данных. Также она возвращает полученные входные данные (без изменений).>>> nothing('bar')
(None, 'bar')
>>>nothing() отличается от отсутствия доступных входных данных. Она просто означает, что вы решили НЕ делать ничего с имеющимися входными данными.Обе эти функции являются примерами того, что я буду называть «парсер». Парсер — это функция, определяемая своей сигнатурой вызова и соглашением о возвращаемых данных. В частности, парсер — это любая функция, принимающая какие-то входные данные (
inp), а в случае успеха возвращающая кортеж (value, remaining), где value — это некое нужное значение, а remaining — все оставшиеся входные данные, парсинг которых нужно выполнить. При неудаче парсер возвращает False.Хотя эти функции и так короткие, можно ещё больше их сократить при помощи
lambda:shift = lambda inp: bool(inp) and (inp[0], inp[1:])
nothing = lambda inp: (None, inp)Преимущество
lambda в том, что она делает код компактным и наглядным. Кроме того, она не позволяет разработчикам пытаться добавлять значимые имена, документацию или type hint к тому, что будет развёрнуто.Кстати,
lambda — это третья проблема. Сдвиг, ничего и лямбда — это три проблемы. Давайте двигаться дальше.▍ Система парсинга
То, что мы получили, называется системой для парсинга. Как и у любой другой системы, у неё есть правила. В этой системе мы можем использовать только два имеющихся парсера (
shift и nothing). Также можно использовать lambda для создания новых парсеров из имеющихся. Вот и всё.▍ Модификаторы парсеров
Давайте напишем правило, применяющее предикат к результату парсера:
filt = lambda predicate: (
lambda parser:
lambda inp: (m:=parser(inp)) and predicate(m[0]) and m)Три лямбды?!? Моржовый оператор? Вычисление по краткой схеме? Что за ужас здесь творится? Да, я мог использовать вместо этого четыре лямбды:
filt = lambda predicate: (
lambda parser:
lambda inp:
(lambda m: m and predicate(m[0]) and m)(parser(inp)))Однако читаемость важна. К тому же — бог любит троицу. Три проблемы. Три лямбды. Три бивня. Не четыре лямбды и ни одного бивня.
Функция
filt() получает на входе предикат и парсер и комбинирует их, чтобы создать новый парсер. Это выглядит немного странно, но работает схоже с декоратором. Вот пример того, как это использовать:>>> digit = filt(str.isdigit)(shift)
>>> letter = filt(str.isalpha)(shift)
>>> digit('456')
('4', '56')
>>> letter('456')
False
>>>Возвращаемое значение
False в данном случае означает, что парсинг не сработал. Точно так же, как shift() возвращает False, когда заканчиваются входные данные, созданный при помощи filt() парсер возвращает False, если созданное значение не соответствует переданному предикату.Забавная формулировка
filt() позволяет вам легко создавать другие типы полезных фильтров, просто передавая произвольные предикаты. Вот фильтр для точного соответствия литералу:literal = lambda value: filt(lambda v: v == value)Вот фильтр, в котором значения должны браться из заданного множества допустимых значений:
memberof = lambda values: filt(lambda v: v in values)Вот несколько примеров применения этих фильтров к имеющемуся парсеру:
>>> dot = literal('.')(shift)
>>> even = memberof('02468')(digit) # Да, digit, не shift.
>>> dot('.456')
('.', '456')
>>> dot('45.6')
False
>>> even('456')
('4', '56')
>>> even('345')
False
>>>Естественно, можно продолжить всё упрощать. Чтобы выявлять соответствия отдельным символам, можно написать следующую вспомогательную функцию:
char = lambda v: literal(v)(shift)>>> dot = char('.')
>>> dot('.456')
('.', '456')
>>>Аналогично тому, что задача
filt() заключается в игнорировании элементов, противоположностью игнорирования является какое-то действие. Поэтому, чтобы сохранить баланс кода, нам нужна противоположная сила. Давайте назовём эту операцию fmap():fmap = lambda func: (
lambda parser:
lambda inp: (m:=parser(inp)) and (func(m[0]), m[1]))fmap() получает на входе функцию и парсер и создаёт новый парсер, в котором переданная функция применяется для успешного парсинга. fmap() используется для преобразования значений. Например:>>> ndigit = fmap(int)(digit)
>>> ndigit('456')
(4, '56')
>>> tenx = fmap(lambda x: 10*x)
>>> tenx(ndigit)('456')
(40, '56')
>>> tenx(digit)('456')
('4444444444', '56')
>>>Примечание:
map и filter — имена встроенных функций, которые Python использует для работы с итерируемыми элементами. Я бы использовал их, если бы это не запутывало присвоение имён. Поэтому я выбрал fmap и filt. Концептуально наши функции служат семантически схожей цели.▍ Повторение
Пока наши парсеры работают только с одиночными входными данными. Чтобы делать более интересные вещи, нужно заставить их сопоставлять несколько входных данных. Например, несколько цифр или букв. Было бы здорово, если бы мы смогли задать нечто подобное:
digits = one_or_more(digit)Чтобы сделать это, мы можем использовать функциональные техники, задействующие рекурсию. Однако скажем напрямую — Python ужасно справляется с рекурсией по различным «причинам», меньшей из которых является его внутреннее ограничение на рекурсии. Этого мы делать не будем. Вместо этого вдохновимся театром и «сломаем четвёртую стену», повернувшись к зрителям и признав, что мы всё-таки пишем код на Python. Ладно, да будет так:
def one_or_more(parser):
def parse(inp):
result = [ ]
while (m:=parser(inp)):
value, inp = m
result.append(value)
return bool(result) and (result, inp)
return parseДа, цикл
while не согласуется с нашей системой лямбд. Однако можно сказать, что это «pythonic» просто потому, что не ломает ограничения на рекурсии, поэтому давайте сделаем так. Как и другие наши функции, one_or_more() принимает на входе парсер и создаёт на выходе новый парсер. Он многократно вызывает переданный парсер, пока больше не найдётся совпадений. Список создан.>>> digit = filt(str.isdigit)(shift)
>>> digits = one_or_more(digit)
>>> digits('456')
(['4','5','6'], '')
>>> digits('1abc')
(['1'], 'abc')
>>> digits('abc')
False
>>>Если вам не нравится, что цифры разделены на список, то используйте
fmap, чтобы снова соединить их:>>> digits = fmap(''.join)(one_or_more(digit))
>>> digits('456')
('456', '')
>>>Если вам нужно числовое значение, то добавьте ещё одну
fmap:>>> value = fmap(int)(digits)
>>> value('456')
(456, '')
>>>Примечание: если вы покажете своим коллегам функцию
one_or_more(), то они, вероятно, рассердятся, потому что вы не соблюдаете руководство по стилю. Они скажут: «Тебе нужно было использовать лямбду». Исправить это не так просто, но, возможно, вам удастся их обмануть при помощи functools.wraps():from functools import wraps
@wraps(lambda parser:_)
def one_or_more(parser):
@wraps(lambda inp:_)
def parse(inp):
...
return parseПо крайней мере, в этом случае функция выглядит так, как будто берётся из лямбды, если кто-то не потратит время на изучение её определения.
Домашнее задание: или же можно просто переписать
one_or_more(), не пользуясь ничем, кроме как лямбдой и рекурсией.▍ Последовательность
Иногда вам нужно спарсить одно после другого. Для этого можно написать оператор последовательности:
def seq(*parsers):
def parse(inp):
result = [ ]
for p in parsers:
if not (m:=p(inp)):
return False
value, inp = m
result.append(value)
return (result, inp)
return parseseq() получает на входе произвольное количество парсеров. Затем она создаёт новый парсер, в котором они выстроены по порядку, один за другим. Для успешного завершения парсинга все парсеры должны успешно выполнить свою задачу. Вот пример:>>> seq(letter, digit, letter)('a4x')
(['a', '4', 'x'], '')
>>> seq(letter, digit, letter)('abc')
False
>>> seq(letter, fmap(''.join)(one_or_more(digit)))('x12345')
(['x', '12345'], '')
>>> Написав способ задания последовательностей, можно создать его полезные варианты. Например, иногда полезно выбрать только левую или правую часть пары.
left = lambda p1, p2: fmap(lambda p: p[0])(seq(p1, p2))
right = lambda p1, p2: fmap(lambda p: p[1])(seq(p1, p2))Вот пример:
>>> left(letter, digit)('a4')
('a', '')
>>> right(letter, digit)('a4')
('4', '')
>>>Домашнее задание: напишите версию
seq() с использованием лямбды.▍ Выбор
Создание последовательности требует, чтобы все парсеры совпадали. Какой будет обратная операция? Возможно, это функция, которая требует, чтобы совпадал только один из переданных парсеров. Давайте назовём эту операцию
either():either = lambda p1, p2: (lambda inp: p1(inp) or p2(inp))Вот пример:
>>> alnum = either(letter, digit)
>>> alnum('4a')
('4', 'a')
>>> alnum('a4')
('a', '4')
>>> alnum('$4')
False
>>>either() позволяет создавать необязательные параметры и, наконец, даёт возможность воспользоваться nothing. Например:maybe = lambda parser: either(parser, nothing)>>> maybe(digit)('456')
('4', '56')
>>> maybe(digit)('abc')
(None, 'abc')
>>>Также можно использовать её для реализации
zero_or_more():zero_or_more = lambda parser: either(one_or_more(parser), seq())>>> zero_or_more(digit)('456')
(['4','5','6'], '')
>>> zero_or_more(digit)('abc')
([], 'abc')
>>>И последнее: можно использовать
either() для создания более мощной функции choice(), позволяющей выбирают между любым количеством переданных парсеров.choice = lambda parser, *parsers: (
either(parser, choice(*parsers)) if parsers else parser)Домашнее задание: перепишите
choice() так, чтобы не использовалась рекурсия.Домашнее задание: а действительно ли нам нужна
nothing? Можно ли создать nothing из чего-то?▍ Пример: числа
Давайте рассмотрим задачу парсинга чисел. Предположим, что числа поступают в двух вариациях. Целые числа имеют вид
1234, а десятичные дроби — 12.34. Однако с десятичными дробями всё чуть сложнее, потому что их можно записывать с замыкающим десятичным разделителем, например, 12. или с начальным десятичным разделителем, например, .34. Допустим, нам нужно преобразовать целые числа в integer языка Python, а десятичные дроби — во float. Как вы будете парсить числа? Вот как это можно сделать:dot = char('.')
digit = filt(str.isdigit)(shift)
digits = fmap(''.join)(one_or_more(digit))
decdigits = fmap(''.join)(choice(
seq(digits, dot, digits),
seq(digits, dot),
seq(dot, digits)))
integer = fmap(int)(digits)
decimal = fmap(float)(decdigits)
number = choice(decimal, integer)Давайте проверим нашу функцию
number().>>> number('1234')
(1234, '')
>>> number('12.3')
(12.3, '')
>>> number('.123')
(0.123, '')
>>> number('123.')
(123.0, '')
>>> number('.xyz')
False
>>>▍ Пример: пары «ключ-значение»
Допустим, вам нужно спарсить пары «ключ-значение» в вид
name=value;, где name состоит из букв, а value — это любое численное значение. Также предположим, что вокруг каждой из пар могут быть произвольные пробелы (которые нужно игнорировать). Вот как это можно сделать:letter = filt(str.isalpha)(shift)
letters = fmap(''.join)(one_or_more(letter))
ws = zero_or_more(filt(str.isspace)(shift))
token = lambda p: right(ws, p)
eq = token(char('='))
semi = token(char(';'))
name = token(letters)
value = token(number)
keyvalue = seq(left(name, eq), left(value, semi))Давайте проверим:
>>> keyvalue('xyz=123;')
(['xyz', 123], '')
>>> keyvalue(' pi = 3.14 ;')
(['pi', 3.14], '')
>>>Обработка пробелов может потребовать небольшого исследования. Решением станет использование особой функции
token() для отбрасывания начального пробела.▍ Пример: построение словаря
Допустим, вы хотите расширить возможности парсера, чтобы он преобразовывал произвольное число в пары «ключ-значение», записываемые как
key1=value1; key2=value2; key3=value3; в словарь Python с теми же ключами и значениями. Вот как это сделать:keyvalues = fmap(dict)(zero_or_more(keyvalue))Пример:
>>> keyvalues('x=2; y=3.4; z=.789;')
({'x': 2, 'y': 3.4, 'z': 0.789}, '')
>>> keyvalues('')
({}, '')
>>>▍ Пример: валидация ключей словаря
Допустим, нужно написать парсер, принимающий только словари с ключами
x и y. Для проверки этого можно использовать filt():xydict = filt(lambda d: d.keys() == {'x', 'y'})(keyvalues)Пример:
>>> xydict('x=4;y=5;')
({'x': 4, 'y': 5}, '')
>>> xydict('y=5;x=4;')
({'y': 5, 'x': 4}, '')
>>> xydict('x=4;y=5;z=6;')
False
>>>Этот пример показывает, как можно интересным образом сочетать возможности. Раньше функция
filt() использовалась для фильтрации отдельных символов, а теперь она применяется к словарям.▍ Обсуждение: композиция
Важнейшее свойство, позволяющее всему работать — это внимание к композиции. Вот как выглядит интерфейс для парсера в своей основе:
def parser(inp):
...
if success:
return (value, remaining)
else:
return FalseВсё остальное создаётся на этом фундаменте. Всё множество различных функций наподобие
filt(), fmap(), zero_or_more(), seq() и choice() создаёт новые парсеры, имеющие идентичный интерфейс. Поэтому всё работает со всем и везде. Возможно, основным источником проблем может быть fmap(). Так как она применяет пользовательскую функцию к подвергающемуся парсингу значению, очевидно, что передаваемая функция должна быть совместимой.▍ Обсуждение: анализ концепций
Задумаемся на минуту над формулировкой
filt(). Когда вы использовали filt(), то, вероятно, думали, что это выглядит немного забавно. Примерно так:digit = filt(str.isdigit)(shift)Почему
shift находится снаружи? Кроме того, разве это не внутренняя подробность реализации? Разве мы не можем спрятать её вот так:filt = lambda predicate: (
lambda inp: (m:=shift(inp)) and predicate(m[0]) and m)
digit = filt(str.isdigit)Да, это можно сделать, однако перемещение её внутрь ограничивает полезность
filt() до отдельных символов. Я предпочту filt(), которая опасно гибка. Исходная формулировка позволяет применять предикат к ЛЮБОМУ парсеру, даже к сложным, которые возвращают структуры данных. И это здорово. Этого нельзя было бы сделать, если бы выбор парсера находился внутри.Ещё один вопрос по
filt() (и связанным с ней функциям) относится к её странному формату вызова. Почему входной предикат и аргументы парсера обрабатываются вызовами отдельной функции, а не передаются вместе одной функции? Например, почему не сделать вот так?filt = lambda predicate, parser: (
lambda inp: (m:=parser(inp)) and predicate(m[0]) and m)
digit = filt(str.isdigit, shift)Если сформулировать функцию таким образом, то определять полезные варианты наподобие
literal станет неудобнее. Ранее literal определялась, завися только от части с предикатом. Вот так:literal = lambda value: filt(lambda v: v == value)Это сжатая и изящная запись. Однако, если
filt() потребуется дополнительный аргумент, это этот аргумент растекается на внешние функции, заставляя нас писать такой код:literal = lambda value, parser: filt(lambda v: v == value, parser)Это некрасиво. В исходном случае нам не требуется знать дополнительные подробности о
filt().▍ Магия
Давайте обсудим функцию
shift(). В исходной формулировке она разбивает входную строку на её первый символ и оставшийся текст. Вот как выглядел код:shift = lambda inp: bool(inp) and (inp[0], inp[1:])А вот как он работал:
>>> shift('hello world')
('h', 'ello world')
>>>Это неэффективный способ обработки текста на Python. На самом деле, вероятно, это наихудший способ обработки текста, который только можно придумать. На моей машине тест парсинга строки с 100000 парами «ключ-значение» в словарь занял почти 2,5 минуты! Ужас!
Основная проблема заключается в копировании памяти, происходящем при вычислении
inp[1:]. На самом деле, каждый вызов shift() выполняет почти полную копию входного текста. Можно ли этого избежать?Внимательный наблюдатель заметит, что во всём представленном коде ничего не делается со входным значением
inp, за исключением его передачи в другое место. Единственный код, который с ним работает — это функция shift()! Более того, никакой код никогда не смотрит на значение оставшегося текста. Поэтому мы можем поменять описание данных для этих частей на нечто совершенно иное. Вместо того чтобы представлять входные данные в виде строки, мы, возможно, сможем использовать кортеж (text, n), где n — это integer, обозначающий текущую позицию. Давайте попробуем переписать shift() следующим образом:def shift(inp):
text, n = inp
return n < len(text) and (text[n], (text, n+1))Вот как работает новая версия:
>>> shift(('abc', 0)) # Обратите внимание, что теперь используется кортеж
('a', ('abc', 1))
>>> shift(('abc', 1))
('b', ('abc', 2))
>>> shift(('abc', 2))
('c', ('abc' 3))
>>> shift(('abc', 3))
False
>>>Обратите внимание, что входная строка никогда не меняется. Не происходит ни копирования, ни нарезания. По сути, Python передаёт строку как ссылку. Единственное изменяющееся значение — это целочисленный индекс.
Никакой другой код менять не требуется. Вы можете убедиться, что всё по-прежнему идеально работает, при условии передачи входных данных в ожидаемом формате.
>>> keyvalues(('x=2; y=3.4; z=.789;', 0)) # Обратите внимание: здесь кортеж
({'x': 2, 'y': 3.4, 'z': 0.789}, ('x=2; y=3.4; z=.789;', 19))
>>>Чтобы сокрыть часть подробностей входных данных, я могу добавить специальную функцию
Input() для преобразования передаваемого пользователем ввода в мой внутренний формат. Например:Input = lambda inp: (inp, 0)
# Пример
result = keyvalues(Input('x=2; y=3.4; z=.789'))Я назвал
Input с заглавной, чтобы оставить пространство для манёвра. Возможно, когда-нибудь я превращу её в класс. Возможно, я просто делаю это, чтобы высказать своё «фи» PEP-8. Кто знает?Как бы то ни было, при тестировании на тех же входных данных с 100000 парами «ключ-значение» время парсинга упало с 2,5 минуты до примерно 2,3 секунды. Это потрясающе. Мы решили проблему производительности, изменив представление входных данных и подправив одну строку кода.
Почему это сработало? Думаю, потому, что всё написанная нами функциональность основана не на прямых манипуляциях с входными данными, а на композиции функций. Изменение представления данных не повлияло на композицию частей.
▍ Ещё немного магии
Хотя мы сильно повысили производительность, всё равно выполняется много низкоуровневых манипуляций с отдельными символами. Возможно, будет логично использовать более правильный токенизатор. Например, можно просто использовать мой инструмент SLY для написания такого лексического анализатора:
from sly import Lexer
class KVLexer(Lexer):
tokens = { EQ, SEMI, NAME, INTEGER, FLOAT }
ignore = ' \t\n'
FLOAT = r'(\d+\.\d+)|(\d+\.)|(\.\d+)'
INTEGER = r'\d+'
NAME = r'[a-zA-Z]+'
EQ = r'='
SEMI = r';'Лексический анализатор создаёт токены, не символы. Например:
>>> lexer = KVLexer()
>>> list(lexer.tokenize("x=2;"))
[Token(type='NAME', value='x', lineno=1, index=0, end=1),
Token(type='EQ', value='=', lineno=1, index=1, end=2),
Token(type='INTEGER', value='2', lineno=1, index=2, end=3),
Token(type='SEMI', value=';', lineno=1, index=3, end=4)]
>>>Можем ли мы использовать свой фреймворк парсинга с таким токенизатором? Конечно! Для этого нужно заменить низкоуровневую работу с символами на использвание токенов, но во всём оставив парсер неизменным. Вот как выглядит новый парсер:
expect = lambda ty:\
fmap(lambda tok: tok.value)(filt(lambda tok: tok.type == ty)(shift))
name = expect('NAME')
integer = fmap(int)(expect('INTEGER'))
decimal = fmap(float)(expect('FLOAT'))
value = choice(decimal, integer)
keyvalue = seq(left(name, expect('EQ')), left(value, expect('SEMI')))
keyvalues = fmap(dict)(zero_or_more(keyvalue))
Input = lambda inp: (list(KVLexer().tokenize(inp)), 0)Давайте убедимся, что он работает:
>>> r = keyvalues(Input('x=2; y=3.4; z=.789;'))
>>> r[0]
{'x': 2, 'y': 3.4, 'z': 0.789}
>>>При тестировании на моих больших входных данных эта версия выполняется около 0,9 секунды, что примерно в 2,5 раза быстрее, чем раньше.
▍ Бум!
Я задумался о бесчисленных часах, потраченных мной на микрооптимизации парсера LALR(1) в моих инструментах наподобие PLY и SLY. Серьёзно, я потратил кучу времени на изучение этого кода, пытаясь убрать всё, что мешало производительности. Поэтому эти инструменты уже давно являются самыми быстрыми реализациями парсеров на чистом Python. Как моя новая методика будет выглядеть по сравнению с ними?
Чтобы протестировать это, я задал схожий парсер пар «ключ-значение» в SLY:
from sly import Parser
class KVParser(Parser):
tokens = KVLexer.tokens
@_('{ keyvalue }')
def keyvalues(self, p):
return dict(p.keyvalue)
@_('NAME EQ value SEMI')
def keyvalue(self, p):
return (p.NAME, p.value)
@_('INTEGER')
def value(self, p):
return int(p.INTEGER)
@_('FLOAT')
def value(self, p):
return float(p.FLOAT)Вот как его можно использовать для парсинга нашего примера:
>>> lexer = KVLexer()
>>> parser = KVParser()
>>> tokens = lexer.tokenize('x=2; y=3.4; z=.789;')
>>> parser.parse(tokens)
{'x': 2, 'y': 3.4, 'z': 0.789}
>>>А теперь я попробую его на моих входных данных с 100000 пар «ключ-значение». Выполнение заняло 2,3 секунды. Это в три раза медленнее предыдущего теста, в котором использовался тот же поток токенов! Он даже немного медленнее, чем исходная «магическая» версия, которая просто работала с отдельными символами. Как такое может быть?
Такого результата я не ожидал. Парсер LALR(1) управляется только поиском по таблице и автоматом. В нём отсутствует поиск с возвратом и он не использует глубокий стек композиции функций.
В качестве последней надежды я решил заново реализовать весь парсер при помощи PLY, имеющего более оптимизированную реализацию. Он выполняется примерно за 1,2 секунды. Получается, он тоже проигрывает.
Должен сказать, что моя цель не заключается в подробном анализе производительности, существует множество патологических пограничных случаев, в которых у новой методики могут возникнуть проблемы. Главный вывод заключается в том, что она намного быстрее, чем я предполагал.
▍ Примечание: итерация
В Python концепция итерации определена чётко. Логично спросить, почему не использовать для этого итератор или функцию-генератор? Можно ли переписать
shift() таким образом?shift = lambda inp: (x:=next(inp, False)) and (x, inp)Похоже, эксперимент подтверждает, что это может сработать:
>>> inp = iter('abc')
>>> shift(inp)
('a', <str_iterator object at 0x10983e140>)
>>> shift(inp)
('b', <str_iterator object at 0x10983e140>)
>>> shift(inp)
('c', <str_iterator object at 0x10983e140>)
>>> shift(inp)
False
>>>К сожалению, на самом деле это не работает, потому что в нашей методике парсинга используется поиск с возвратом, особенно при принятии решения в функциях
either(), maybe() и choice(). При обработке either() парсинг какое-то время может выполняться успешно, а потом внезапно завершиться неудачно. Когда такое происходит, всё откатывается назад и проверяется другая ветвь парсинга.Для отката назад стандартного итератора Python механизмы отсутствуют. Хотя иногда можно скопировать итератор или использовать какую-нибудь магию из
itertools, это выглядит довольно сложным. Хуже того, чтобы это заработало, необходимо вносить тонкие изменения во всей реализации, а не изолировать их в одном месте. Пока я оставлю это в качестве домашнего задания.▍ Полный код
Вот полная реализация базового фреймворка парсинга, описанного в этой статье. Я решил, что будет интересно просто увидеть его целиком.
# -- Фреймворк парсинга
def shift(inp):
text, n = inp
return n < len(text) and (text[n], (text, n+1))
nothing = lambda inp: (None, inp)
filt = lambda predicate: (
lambda parser:
lambda inp: (m:=parser(inp)) and predicate(m[0]) and m)
literal = lambda value: filt(lambda v: v==value)
char = lambda value: literal(value)(shift)
fmap = lambda func: (
lambda parser:
lambda inp: (m:=parser(inp)) and (func(m[0]), m[1]))
either = lambda p1, p2: (lambda inp: p1(inp) or p2(inp))
maybe = lambda parser: either(parser, nothing)
choice = lambda parser, *parsers: either(parser, choice(*parsers)) if parsers else parser
def seq(*parsers):
def parse(inp):
result = [ ]
for p in parsers:
if not (m:=p(inp)):
return False
value, inp = m
result.append(value)
return (result, inp)
return parse
left = lambda p1, p2: fmap(lambda p: p[0])(seq(p1, p2))
right = lambda p1, p2: fmap(lambda p: p[1])(seq(p1, p2))
def one_or_more(parser):
def parse(inp):
result = [ ]
while (m:=parser(inp)):
value, inp = m
result.append(value)
return bool(result) and (result, inp)
return parse
zero_or_more = lambda parser: either(one_or_more(parser), seq())
Input = lambda inp: (inp, 0)
# -- Пример: преобразование "key1=value1; key2=value2; ..." в словарь
# числа и значения
dot = char('.')
digit = filt(str.isdigit)(shift)
digits = fmap(''.join)(one_or_more(digit))
decdigits = fmap(''.join)(choice(
seq(digits, dot, digits),
seq(digits, dot),
seq(dot, digits)))
integer = fmap(int)(digits)
decimal = fmap(float)(decdigits)
number = choice(decimal, integer)
# имена
letter = filt(str.isalpha)(shift)
letters = fmap(''.join)(one_or_more(letter))
# Пробел
ws = zero_or_more(filt(str.isspace)(shift))
token = lambda p: right(ws, p)
# Токены (с удалённым пробелом)
eq = token(char('='))
semi = token(char(';'))
name = token(letters)
value = token(number)
# Одна пара key=value;
keyvalue = seq(left(name, eq), left(value, semi))
# Несколько пар "ключ-значение"
keyvalues = fmap(dict)(zero_or_more(keyvalue))
# Пример
result, remaining = keyvalues(Input("x=2; y=3.4; z=.789;"))
print(result)▍ Похожие работы
Если вас потряс этот пост, то вам следует изучить комбинаторы парсеров. Программирование при помощи комбинаторов — не самая распространённая вещь в Python, но это может быть интересным способом достижения необычной чрезвычайной гибкости.
В мире Python есть множество связанных с парсингом инструментов, построенных на схожих концепциях. Большинство из них содержит излишества, но их стоит изучить:
▍ Размышления
За последние двадцать лет я много работал с парсингом на Python. В том числе я разработал множество пакетов генераторов парсеров LALR(1) и преподавал курс по компиляторам, на котором обычно даю студентам задание написать парсер с рекурсивным спуском. Хотя я раньше слышал сочетание слов «комбинатор парсеров», впервые попробовал поработать с ними только недавно.
В этом январе я решил, что попробую в качестве хобби-проекта реализовать свой курс по компиляторам на Haskell. Ранее никогда не программировав на Haskell, я был вынужден перестроить часть своего мозга. Я начал работу с книги «Programming in Haskell» Грэма Хаттона. Как оказалось, Грэм обладает существенным опытом в монадных комбинаторах парсеров (см., например, эту статью) и многие примеры в его книге используют эту технику.
Мне никогда не доводилось писать парсер таким образом. Поэтому по большей части в моём посте приведён «ремикс» этих идей на Python. Я свободно использовал идиомы Python и делал всё немного иным способом. Однако код всё равно воплощает общую большую идею. Кроме того, я писал код на Python в «эквациональном стиле», отражающем упор на композицию функций, а не на реализацию функций.
Меня поразил минимализм и выразительность кода. Здесь не используется никакого сложного метапрограммирования, перегрузки операторов и даже классов. Если вы хотите посмотреть, как всё работает, то код у вас прямо перед глазами. Большинство функций очень компактно. Удивительно то, как они сочетаются друг с другом.
Примечание: иногда люди спрашивают меня: «Как мне улучшить свои навыки Python?». К их удивлению, я часто предлагаю создать проект на совершенно другом языке или за рамками их сферы опыта. Я думаю, что основной выигрыш от этого заключается в том, что часто вы видите совершенно иной способ мышления о задачах, который можно привнести в свои проекты.
▍ В заключение: буду ли я действительно использовать это?
Как уже говорилось, я изучил эту технику в версии для Haskell. Однако позже я применил её к реализации на Python в моём проекте курса по компиляторам. Получившийся в результате парсер был примерно вдвое меньше написанного вручную парсера рекурсивного спуска и включал в себя меньшее количество концепций. Кроме того, получившийся код напрямую отражал грамматику языка, определённую при помощи PEG. И, наконец, оказалось, что новая реализация имеет множество хороших свойств, связанных с обработкой ошибок и с сообщениями об ошибках. В конечном итоге, она понравилась мне намного больше.
Более подробное обсуждение написания полного парсера языка программирования стоит отложить для другой статьи. Однако в заключение надо сказать, что я действительно могу использовать эту технику для создания парсера чего-то реального.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх ????️

Комментарии (60)

anonymous
10.04.2023 16:42НЛО прилетело и опубликовало эту надпись здесь

slonopotamus
10.04.2023 16:42+11Ну почему велосипед, parser combinator'ы вполне имеют право на существование.
Меня больше зацепило что автора беспокоит перфоманс, но при этом он пишет на питоне.

defaultvoice
10.04.2023 16:42+8Автор оригинального кода буквально преподавал в Университете Чикаго, о чём можно прочесть в его биографии

lorc
10.04.2023 16:42+7Мне кажется, что эта статья - это не мануал о том как писать парсеры. А скорее пример того насколько крутые штуки можно делать с использованием композиции функций. Эдакий аккуратный ввод в функциональное программирование. Тут даже каррирование применяется, просто автор не стал использовать это слово.

domix32
10.04.2023 16:42+1Честно говоря и парсер у него крайне сомнительный вышел без традиционных комбинаторов а ля
one_of,many0,many1и прочих. Кишка лямбд в кишке лямбд.lorc
10.04.2023 16:42Честно говоря и парсер у него крайне сомнительный вышел
Вот именно поэтому я и написал "это не мануал о том как писать парсеры". Странно ожидать идеальный парсер от чего-то, что не является мануалом по парсерам, не так ли?
domix32
10.04.2023 16:42Так и композиция функций в статье выглядит ровно настолько же сомнительной и выделение сколько-нибудь обобщенных сущностей наоборот показала красоту и аккуратность. А в итоге - ни парсерная рыба, ни функциональное мясо.

mayorovp
10.04.2023 16:42+1Я недавно использовал ANTLR, так что могу про него рассказать. Так вот, это та ещё хрень.
Во-первых, у него уродские умолчания — при любой ошибке разбора он просто возвращает null, причём не обязательно на верхнем уровне. Мне пришлось реализовать 3 интерфейса и основательно покопаться во внутренностях просто чтобы заставить его кидать нормальные исключения.
Во-вторых, у токенов лексера нет значений. В итоге все токены приходится парсить два раза — сначала лексером, а потом вручную чтобы "достать" из них то что внутри лежит.
В-третьих, совершенно интуитивно непонятное API, нарушающее каноны самодокументируемого кода. К примеру, в его рантайме на .NET есть свойство, возвращающее изменяемый список перехватчиков не помню чего. Если список изменяемый, значит туда можно что-то добавить? А вот и нет, генерируется новый список при каждом обращении к свойству!
Ну и последнее — сложно что ли было создателям формат EBNF взять для грамматик?..
mayorovp
10.04.2023 16:42Да, сейчас вот добрался до кода и вспомнил:
В-четвёртых, несмотря на то, что у них в их дереве разбора кишки парсера торчат наружу отовсюду (из-за чего невозможно использовать дерево разбора в качестве AST), информацию о местоположении узла в исходном тексте они надёжно инкапсулировали. Казалось бы, стандартная функциональность — сообщать где именно в исходном тексте произошла ошибка, но чтобы этого добиться — надо лезть в дебри их абстракций.
PS вот кусок кода, который пришлось написать чтобы эта штука начала адекватно работать:
Кодpublic (ITokenStream, MyFilterParser.FilterContext) Parse(string filter) { var output = new LogWriter(logger, LogLevel.Information); var errOutput = new LogWriter(logger, LogLevel.Error); var charStream = CharStreams.fromString(filter); var lexer = new MyFilterLexer(charStream, output, errOutput); lexer.RemoveErrorListeners(); lexer.AddErrorListener(new ThrowingErrorListener(filter)); var tokenStream = new CommonTokenStream(lexer); var parser = new MyFilterParser(tokenStream, output, errOutput); parser.RemoveErrorListeners(); parser.AddErrorListener(new ThrowingErrorListener(filter)); return (tokenStream, parser.filter()); } // … private Range GetLocation(ISyntaxTree context) { var interval = context.SourceInterval; var start = tokenStream.Get(interval.a).StartIndex; var stop = tokenStream.Get(interval.b).StopIndex; return start..(stop+1); }

KvanTTT
10.04.2023 16:42К сожалению, ANTLR все больше устаревает, а автор почти не принимает новые риквесты и не дает мэинтейнить проект.
Во-первых, у него уродские умолчания — при любой ошибке разбора он просто возвращает null, причём не обязательно на верхнем уровне.
Да, такое вполне может быть.
Во-вторых, у токенов лексера нет значений. В итоге все токены приходится парсить два раза — сначала лексером, а потом вручную чтобы "достать" из них то что внутри лежит.
Строго говоря, у токенов они не обязательно должны быть, парсер в теории может работать и без лексера. Однако в подавляющем большинстве случаев парсятся тексты, а значит лексер присутствует.
Но два раза парсить точно не стоит — нужно использовать локацию токена, а по ней уже извлекать строку из входного текста.
В-третьих, совершенно интуитивно непонятное API, нарушающее каноны самодокументируемого кода. К примеру, в его рантайме на .NET есть свойство, возвращающее изменяемый список перехватчиков не помню чего. Если список изменяемый, значит туда можно что-то добавить? А вот и нет, генерируется новый список при каждом обращении к свойству!
Да, с этим много проблем, но вряд ли что-то изменится в рамках ANTLR 4, т.к. поломается обратная совместимость и в связи со стагнацией проекта.
Ну и последнее — сложно что ли было создателям формат EBNF взять для грамматик?..
А вот это спорно — как раз язык ANTLR лаконичней EBNF и в нем больше возможностей. Хотя тут тоже есть что улучшать.
Казалось бы, стандартная функциональность — сообщать где именно в исходном тексте произошла ошибка, но чтобы этого добиться — надо лезть в дебри их абстракций.
Это опять-таки объясняется тем, что парсер не обязательно подразумевает лексер, поэтому инфу о позиции нужно доставать через уровень лексера. Хотя и согласен — можно было получше сделать.
mayorovp
10.04.2023 16:42Но два раза парсить точно не стоит — нужно использовать локацию токена, а по ней уже извлекать строку из входного текста.
Вот её-то и придётся парсить второй раз. Простейший пример:
STRING_LITERAL : '"' ([^"\\]* | '\\' .)* '"'Эта конструкция выделит токен строкового литерала с учётом возможного наличия экранированных кавычек внутри. Однако если необходимо получить значение литерала — всё экранирование придётся обрабатывать самому, несмотря на то что лексер его уже обрабатывал.
А вот это спорно — как раз язык ANTLR лаконичней EBNF и в нем больше возможностей. Хотя тут тоже есть что улучшать.
Только вот в итоге получается, что невозможно просто взять и сгенерировать код по куску грамматики из RFC, приходится каждую конструкцию переписывать, потенциально допуская ошибки на пустом месте.
KvanTTT
10.04.2023 16:42Эта конструкция выделит токен строкового литерала с учётом возможного наличия экранированных кавычек внутри. Однако если необходимо получить значение литерала — всё экранирование придётся обрабатывать самому, несмотря на то что лексер его уже обрабатывал.
А как это по вашему должно выглядеть? Как определить, что символ является экранирующим? Есть ли пример генератора, где реализовано такое извлечение значений?
Только вот в итоге получается, что невозможно просто взять и сгенерировать код по куску грамматики из RFC, приходится каждую конструкцию переписывать, потенциально допуская ошибки на пустом месте.
По крайней мере у ANTLR есть репозиторий грамматик, и, я думаю, самый большой.
mayorovp
10.04.2023 16:42Ага, и там наступает отдельное веселье: переиспользовать чужие грамматики можно только копипастом, внимательно изучая всё что копируешь.
Потому что лексический анализ происходит независимо от синтаксического, и если в двух импортах окажутся одинаковые токены — один из них "поглотит" второй. Для борьбы с этим вроде и есть режимы — только вот оператор импорта не позволяет этот режим переопределить.
А как это по вашему должно выглядеть? Как определить, что символ является экранирующим?
Ну, всяческие
-> skipи-> channel(HIDDEN)уже есть, могли бы туда же добавить и переопределение значения токена. Или хотя бы разрешить тот же skip для фрагментов использовать.Есть ли пример генератора, где реализовано такое извлечение значений?
Генератора-нет, но после детального знакомства с Antlr мне всё больше нравятся комбинаторные парсеры.

saboteur_kiev
10.04.2023 16:42+15не понимаю, почему люди считают, что re нечитабельные.
Может неправильно их учат? Вместо того, чтобы изучить основные структуры в регулярках, пытаются запомнить сами символы. Но это не нужно.
re - язык лексического разбора, и для него есть готовые IDE типа regex101.com и др.
Кроме того, не обязательно писать килобайтные регулярки, если нужно что-то простое на 10-15 символов, без атомарных выражений и сверхжадных квантификаторов.В общем, регулярки - это хороший и удобный инструмент
И знать его на уровне чуть больше чем средний нужно не только, чтобы знать "всякие сложные символы", а чтобы быстро определять, когда пользоваться регуляркой, а когда искать другой инструмент.

POPSuL
10.04.2023 16:42+4Я когда-то очень давно тоже смотрел на RE как баран на новые ворота. А потом я просто понял как они работают (ну, и так, ради интереса закрепил это прочтением очень годной книжечки). Сейчас RE воспринимаются более чем легко, особенно если есть подсветка кода и нормальное форматирование с комментами (/x). Не понимаю эту боязнь регулярок... Да, HTML конечно ими парсить нельзя, но прям повсеместно от них избавляться — излишне и не нужно)
saboteur_kiev
10.04.2023 16:42Да-да, я на своих курсах тоже активно рекомендую эту книжечку.
Джеффри Фридл вместе с Кеном Томпсоном и создавали первые парсеры регэкспов, и книга от создателя читается даже не столько, как учебник, а как художественный исторический обзор, после чего понимаешь зачем, почему и как.POPSuL
10.04.2023 16:42Да, я именно из нее и понял как оно вообще внутри работает, а так же зачем, и что такое ДКА, НКА.
А читается она и правда прям очень легко!

Dimaasik
10.04.2023 16:42+4Кто слишком ленивый, я закинул эту статью в chatGPT и вот вам короткое и понятное содержание
"Знаете, как в фильмах про Хэллоуин злые духи берут на себя облик того, что хотят? Так вот, регулярные выражения - это как злые духи Хэллоуина для текста! Они могут принимать на себя любой облик, чтобы найти и заменить нужную вам информацию в строках. Будьте осторожны, чтобы не взорвать ваш мозг при написании слишком сложных регулярок!"

strelok369
10.04.2023 16:42+1Есть риск, что поговорю с копипастой.
Хотел написать, что вы изобретаете parser combinators, но они были упомянуты в конце (думаю, следовало бы задекларировать вначале).
Чего люди хейтят regexp, кроме слабо предсказуемой вычислительной сложности сверху (ну еще контекст кастомный не прикрутить, или не знаю как), мне не понятно, наверное про regex101.com не знают. В парсер комбинаторах можно и regexp применить на уровне повыше символов, если религия позволяет.
Вы попытались использовать функциональщину в python, но он, на мой взгляд с ней плохо дружит. И с итераторами, когда вместо красивого chain call надо писать бесконечные вложенные вызовы. Для написания кастомных парсеров и, в частности, применения parser combinators советую потрогать rust с его строковыми слайсами, там ('H', "ellow world") норм будет работать, если не чудить.
Пытался писать когда-то свой protobuf-like протокол с парсером dsl на нескольких языках по приколу, rust больше Java, js и C++ понравился, Kotlin ещё не плох был. Если бы сегодня собирался, питон бы не взял по своей воле (3 года на нем пишу по рабочим задачам - плююсь, если бы только нашлась либа, делающая 90% всей задачи, (f)lex, yacc, bison не предлагать).

funca
10.04.2023 16:42вы изобретаете parser combinators
Это перевод, автор вряд-ли ответит). Вообще он преподаватель, изучил подход к теме в хаскеле и решил сделать так же питоне. Это решение не для продакшна.
Просто, если вы сможете реализовать принцип на другом языке, который может для этого не особо и предназначен, значит вы разобрались в теме, а не просто заучили мануал. Заодно это помогает лучше понять сильные и слабые стороны, а так же границы применимости того или иного подхода.

Refridgerator
10.04.2023 16:42-1Я пишу парсеры опираясь на концепцию "автоматное программирование". Код получается тупой, понятный, быстрый и полностью контролируемый.
mayorovp
10.04.2023 16:42Это автоматный код-то получается понятным? Ну-ну...
Refridgerator
10.04.2023 16:42+1Ну да, если не полениться прописать осмысленные наименования для состояний, немного поразмышлять над декомпозицией и не пытаться запихнуть всю логику в единственный switch с миллионом case.

flx0
10.04.2023 16:42+3Вы таки не поверите, но регулярки - это и есть язык описания автоматов, который в них компилируется.
Refridgerator
10.04.2023 16:42Регулярки — это не язык описания автоматов, они просто через него реализуются и всех возможностей не покрывают. Плюс очевидная характерность регэкспов в том, что их сложность растёт экспоненциально сложности задачи, и отлаживать и редактировать выражения типа такого (отсюда)
"~^(,[ \\t]*)*([!#$%&'*+.^_`|~0-9A-Za-z-]+=([!#$%&'*+.^_`|~0-9A-Za-z-]+|\"([\\t \\x21\\x23-\\x5B\\x5D-\\x7E\\x80-\\xFF]|\\\\[\\t \\x21-\\x7E\\x80-\\xFF])*\"))?(;([!#$%&'*+.^_`|~0-9A-Za-z-]+=([!#$%&'*+.^_`|~0-9A-Za-z-]+|\"([\\t \\x21\\x23-\\x5B\\x5D-\\x7E\\x80-\\xFF]|\\\\[\\t \\x21-\\x7E\\x80-\\xFF])*\"))?)*([ \\t]*,([ \\t]*([!#$%&'*+.^_`|~0-9A-Za-z-]+=([!#$%&'*+.^_`|~0-9A-Za-z-]+|\"([\\t \\x21\\x23-\\x5B\\x5D-\\x7E\\x80-\\xFF]|\\\\[\\t \\x21-\\x7E\\x80-\\xFF])*\"))?(;([!#$%&'*+.^_`|~0-9A-Za-z-]+=([!#$%&'*+.^_`|~0-9A-Za-z-]+|\"([\\t \\x21\\x23-\\x5B\\x5D-\\x7E\\x80-\\xFF]|\\\\[\\t \\x21-\\x7E\\x80-\\xFF])*\"))?)*)?)*$"
лично мне не особо интересно. Особенно учитывая то, что автоматное программирование использовать регэкспы никак не запрещает, равно как и другие вспомогательные инструменты для синтаксического разбора.

Fedorkov
10.04.2023 16:42+1В четверг сдавал ЕГЭ по информатике.
Несколько задач решил практически одной строчкой регекса, потратив на каждую по паре минут.

ef_end_y
10.04.2023 16:42+1Мне кажется, что эта статья больше документации по re. Практически никто (исключения есть везде) не пишет гигантские и непонятные регекспы. Все, что я встречал и использовал в многолетней практике, это очень лаконичные шаблоны в одну не длинную строчку, которая сразу интерпретировалась мозгом. Ну, реально, выучить базу re и потренироваться чтоб отложилось в памяти, это день. Никто ж не заставляет их тулить везде, но там где они к месту, гораздо удобнее чем прыгать глазами по вызовам новых (которые надо изучать) функций написанных программистом, которому пренепременно надо сделать без ре

AlexeyK77
10.04.2023 16:42Приходится часто писать regexp для разбора различных security-logs в SIEM-системах.
Частенько логи сделаны так, что одно и тоже значение надо вытаскивать из разных мест, в зависимости от окружающего контекста, и тогда регекс становится негуманным для мозга.
Но видать лучше ничего человечество пока не придумало, так что навык писать и читать регексы считай что базовый.

Hemml
10.04.2023 16:42-1К сожалению, на самом деле это не работает, потому что в нашей методике
парсинга используется поиск с возвратом, особенно при принятии решения в
функцияхeither(),maybe()иchoice(). При обработкеeither()
парсинг какое-то время может выполняться успешно, а потом внезапно
завершиться неудачно. Когда такое происходит, всё откатывается назад и
проверяется другая ветвь парсинга.Поиск с возвратом можно написать с использованием continuations, но они не включены в штатный питон, тут stackless python в помощь.

bbc_69
10.04.2023 16:42Не любите регекспы? Да вы просто не умеете их готовить!
import re DIGIT = '\d' # при желании DOT = '\.' # эти две строчки можно и опустить. INTEGER = f'{DIGIT}+' FLOAT = f'{INTEGER}{DOT}(?:{INTEGER})?|{DOT}{INTEGER}' NUMBER = f'^((?P<integer>{INTEGER})|(?P<float>{FLOAT}))$' m = re.match(NUMBER, '15') m.groupdict() # {'integer': '15', 'float': None} m = re.match(NUMBER, '15.2') m.groupdict() # {'integer': None, 'float': '15.2'} m = re.match(NUMBER, '.15') m.groupdict() # {'integer': None, 'float': '.15'} m = re.match(NUMBER, '1e3') m is None # True - при желании можно и это предусмотреть, тогда надо только поправить определение FLOAT.PS Если такая запись кажется сложной:
FLOAT = f'{INTEGER}{DOT}({INTEGER})?|{DOT}{INTEGER}'то её можно разбить на две части:
F1 = f'{INTEGER}{DOT}(?:{INTEGER})?' F2 = f'{DOT}{INTEGER}' FLOAT = f'{F1}|{F2}'проще некуда.
johnfound
Отказ от RE совсем не означает, что надо написать свой универсальный парсер. Ровно наоборот – надо обрабатывать данные кодом специально для них написанным. Данные ведь бывают разными.
А RE плох потому что совершенно нечитабельный. Даже если человек эксперт в RE.
0xd34df00d
Особенно хорошо специальный код обновлять, когда оказывается, что формат данных надо немного поменять.
Классическое представление RE плохо. Есть и более читабельные, например.
johnfound
А если RE, что, не понадобиться обновлять, что ли? А, да, только придется прежде чем менять, понять что же именно делал прежний RE написанный 3 года назад программистом, который давно уже уволился. :D
0xd34df00d
А таки что проще обновлять — конкретный RE или NFA, в который он скомпилировался?
Поэтому я предпочитаю монадические парсеры даже для регулярных языков, да и дал вам там ссылку на более читаемый (и композабельный!) вариант изложения RE.
johnfound
Вы мне соломенное чучело не подсовывайте. Код, который написан для специальной обработки частного случая, всегда будет намного проще, чем универсальный RE и то что компилятор из него нагенерирует. Так что пока вы разбираете прежний RE, я три раза разберусь что здесь было и как сделать по другому.
0xd34df00d
Окей, там по ссылке такой код:
Вы можете написать эквивалентный код для данного специального случая? А потом мы оба его немножко модифицируем.
johnfound
Могу. А что этот код делает? Я же ваши языки не понимаю.
0xd34df00d
Парсит простенькие урлы в простенькую структуру данных.
Сначала протокол (
httpилиftp), потом обязательно://, потом хост (любое количество любых кроме/символов), потом обязательно/, потом любое количество символов. Всё распаршенное сохраняется в какую-то структуру данных.johnfound
О, понятно. Я такое писал вроде. Найти только… Вот:
StrSplitURL
P.S. Только у меня более универсально, вроде писал по какому-то RFC.
0xd34df00d
Поэтому я и попросил написать полный аналог — чтобы не было потом «более универсально», «менее универсально», и так далее. Ну да ладно, писать с более универсальными абстракциями сложнее, как вы пишете, поэтому требовать от вас написать то, что я бы написал с этими абстракциями за несколько минут — непозволительная наглость.
У меня по вашему коду до всяких модификаций есть несколько вопросов, если вы не против.
Во-первых, как вы сообщаете об ошибках? Ну вот заматчилось ли у вас что-то или нет?
Во-вторых, что у вас происходит вон там вначале со схемой? Это в RFC проверки на 0-9, что ли? Как человек, не помнящий наизусть RFC, должен понять, что здесь происходит и что ожидается?
В-третьих, вы уверены, что называть «подфункции» как
parse1,parse2и так далее — хорошая идея? Может, лучше было назватьparse4какparse_path, не знаю, потому что видетьв коде парсинга схемы — это ну такое.
В-четвёртых, как вы это проверяете на корректность? Для кода выше я могу написать совершенно офигенный набор из нескольких тестов (через property-based-тестирование), который, как показывает практика, очень сильно помогает понять, что что-то не так. Не доказательства, но уже близко.
Ну и про модификации: предположим, что мы хотим сделать слеш на конце и часть после него опциональной. Как вы будете модифицировать ваш код?
mayorovp
Ровно те же самые тесты можно написать на любой код разбора URL...
0xd34df00d
На ассемблер уже портировали quickcheck?
mayorovp
Ассемблерный модуль можно слинковать почти с любой программой, в том числе написанной на языке куда quickcheck портирован. Так что было бы желание...
0xd34df00d
И всё это, конечно, проще, понятнее и надёжнее, чем сразу писать на куда более предназначенных для этого всего языках.
johnfound
Так, это же парсер. Он просто разделяет URL на компоненты. Проверка об ошибках делает тот кто вызвал парсер. Ведь, кому-то схема например, или порт обязательны, а кому-то нет.
Это проверка на порт ":123". Ведь, может быть URL например такое: "http://:1234/" – тогда, scheme="http", host="", port="1234";
Ну, у меня слеш в конце и так опциональный, как и вообще все элементы URL.
Давайте сделаем по другому. Вы правы, что мы сравниваем разные вещи.
Давайте напишите более подробно что делает ваш код. (Можно с тестовыми примерами – что на входе, что на выходе) Потом я напишу более простой код для этого частного случая, а вы преобразуете ваш код в классическое RE. (мы обсуждаем именно его) И сравним результаты на читабельность.
Потом поищем добровольцев которые сделают какое-то изменение в коде. (потому что сразу после написания и мне и вам все будет понятно и менять легко).
Тогда и оценим насколько код или RE удобны для изменений и поддержки.
0xd34df00d
Это разные классы ошибок и разные проверки. Ну да ладно, требовать выражать это на ассемблере, наверное, перебор.
Ну, я там выше упоминал:
Я с радостью отвечу на вопросы по этой формулировке.
А ещё лучше — постепенно эту формулировку каждому из нас уточнять, потому что в реальном мире эти уточнения происходят постоянно. Как раз посмотрим, сколько действий надо совершить для этого самого уточнения.
Из
http://stackoverflow.com/questions/fooвытащится схемаhttp, хостstackoverflow.com, локейшнquestions/foo. От этого можно играть, думаю.Мы обсуждаем регулярные выражения как класс грамматик. В примере выше библиотека именно для этого класса. Я не очень понимаю, зачем что-то переписывать, изменяя синтаксис без изменения семантики и выразительной силы. Это как просить вас переписать с макроассемблера в машинные коды.
Можно просто посмотреть, сколько действий надо сделать для изменений. Я код выше не писал, а скопипастил из документации к библиотеке, и его, считайте, впервые вижу, но что делать, чтобы сделать локейшн опциональным, сказал бы вам за примерно 5 секунд после ознакомления.
johnfound
То есть, я поработаю, а вы так, оцените со стороны? Вы случайно преподавателем не работаете?
0xd34df00d
Оба поработаем. Но вообще код выше (очень сложный, с абстракциями) занимает 14 строк, включая четыре пустые строки. Его можно написать минут за пять. Вам должно быть ещё проще с вашим подходом!
Не хотите — как хотите. Ну или можете предложить мне написать что-нибудь аналогично достаточно тривиальное для этого маленького баттла в комментах, тогда я поработаю, а там посмотрим.
lorc
Под регулярными выражениями вы наверное понимаете язык записи Perl Regular Expression, который, как и все в перле, - совершенно не читаем если нет опыта. Но кроме них еще есть GNU Regular Expressions, например. Они более читаемы.
AstarothAst
Вообще-то это работа программиста — писать код, и менять его, если условия изменились. И менять структурированный и документированный код, который написан специально, что бы хорошо делать конкретную работу гораздо проще и приятнее, чем универсальное заклинание на регэкспах.
funca
Регеспы по сути это нотация для компактной записи грамматик. Писать структурированный и документированный код это ацкая мука, когда перед вами лишь командная строка). В общем я не спорю, тут все сводится к банальному - инструмент под задачу.
0xd34df00d
И эту работу с разными инструментами можно выполнять с разным количеством усилий.
Да, выше мы видели пример, как вся эта простота и приятность очень быстро сдулась. Практически на втором комменте, где вместо того, чтобы адаптировать уже написанный код под изменившиеся требования (что у меня заняло бы не более пяти минут), человек просто вывалил что-то, как-то пересекающееся с обсуждаемой темой по каким-то ключевым словам, и потом оказалось, что менять этот код — непозволительная роскошь.
Регекспы — это класс языков, а не конкретный синтаксис со всеми этими
|*?. Впрочем, похоже, современному программисту очень тяжело понять эту идею даже с примерами эквивалентного, но читабельного синтаксиса под носом — нет времени думать, надо менять код, если условия изменились.AstarothAst
Ого, сколько снобизма.
Ну, да, дело, конечно, в современных программистах, хотя мысль о том, что если при решении проблемы воспользовался регулярками, то у тебя теперь две проблемы, возникла уж точно не сегодня, и даже не вчера, и возникла у тех самых не современных программистов, на знаниях которых и выросли современные.
0xd34df00d
Ну что поделать, извините. Впрочем, как по мне, снобизм — это долго и упорно рассказывать, как лучше-проще-понятнее писать по конкретному парсеру под задачу (в упор не видя в написанном коде ту или иную форму FA и говоря что-то там про соломенные чучела), но отказываться от даже игрушечных упражнений на тему. Но, опять же, впрочем, что я понимаю в людях.
20-30 лет назад не было подобных способов выражения регулярных языков (или они были менее известны), теперь они есть (либо более известны).
Politura
В большинстве случаев требуется что-то относительно простое, и регекс вполне читабелен. Там, где сложная логика, будет одна строчка регекса и, пара строчек коментариев, так что результат получится вполне читабельный. Уж во всяком случае сильно читабельнее, чем несколько экранов какой-то замудреной логики с кучей условных переходов.
Ну и комментарий к следующему комментарию: :)
Если надо обновить какой-то сложный и непонятный регекс, просто вставьте его в какую-нибудь онлайн тулзу вроде приведенного раннее regex101.com и можно будет достаточно быстро разобраться, сильно быстрее, чем разобраться в каком-то коде с запутанной логикой "написанный 3 года назад программистом, который давно уже уволился. :D" и поправить его.
NNikolay
До определенного размера сложности это ок. А ещё, я всех в команде заставляю писать коммент к каждому регексу с пояснением что происходит и зачем.
И главный лайфхак - если попросить chatGPT написать регекс, то он пишет офигенный коммент что там и как. Можно его и в код положить. Но только чат иногда ошибается в самом регексе. Так что тут как с стековерфлоу - нужно проверять.
N-Cube
Как будто мы сами никогда не ошибаемся в сложном регекспе и он всегда работает с первого раза и его проверять не надо :)
Proydemte
Для этого было бы круто интегрировать что-то типа юнит тестов в сам регекс. Т.е. в самом регекс, можно указать ссылку на данные которые можно использовать для тестирования. Несколько проверяемых строк по позитивным/негативным сценариям и ожидаемый результат. Тогда IDE/CI при изменение регекс, прогоняет тесты. Конечно не гарантия, но уже веселее.
Плюс можно использовать эти тестовые данные, чтобы подсветить что куда матчиться или построить визуальную подсказку в виде дерева.
tenzink
Мне кажется, что в ходе дальнейшего обсуждения автор опровергает своё же утверждение. Приводится портянка на ассемблере с неясными именами и полным отстуствием комментариев (StrSplitURL). У меня есть большие сомнения, что даже неудачно написанный RE для этой задачи будет сложнее понимать и модифицировать в будущем новому разработчику