
Привет, меня зовут Артем Сидорук, я работаю в «Лаборатории Касперского» в роли Senior Software Development Engineer in Test (SDET), то есть совмещаю в себе навыки разработчика, тестировщика и DevOps.

Сегодня я расскажу о том, что такое L2-тесты в понимании нашей команды, как их развернуть и какие результаты можно получить. Эти тесты позволили нам избавиться от ночных восьмичасовых прогонов интеграционных тестов. Фактически мы спустили часть интеграционных тестов на уровни ниже, и теперь можем получать результаты значительно быстрее. Однако L2-тестирование требует более высокой квалификации тестировщиков и заставляет команды больше общаться — об этом тоже поговорим.
Как правило, тестировщики видят целый набор сервисов, которые как-то взаимодействуют между собой. Не вдаваясь в подробности, скажем, что их рассматривают как единое целое с неким API, не задумываясь о том, что внутри может быть своя архитектура.
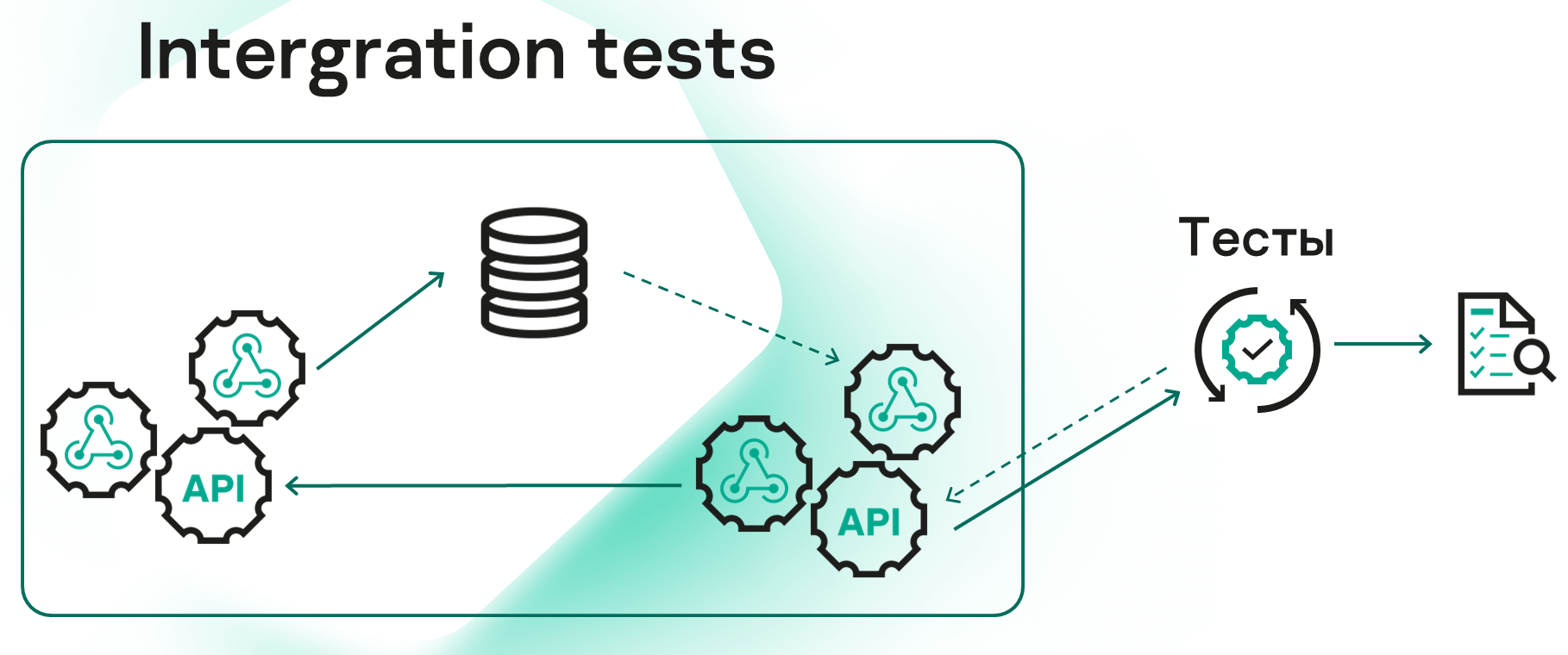
Раньше мы смотрели на ситуацию так же. Проблема в том, что если один из сервисов в цепочке ломается, мы уже не можем тестировать остальные. А кроме того, процесс, затрагивающий все сервисы, проходит достаточно долго. Из-за этого мы были вынуждены запускать тесты по ночам, получая результаты и фидбэк о вчерашней работе только утром следующего дня. Суммарно прогон занимал порядка 8 часов.
На пирамиде тестирования существующая ситуация выглядела следующим образом.

Опираясь на такое представление, мы попытались найти решение своей проблемы. И наткнулись на вот эту статью в блоге Microsoft, где описывался подход, примененный в схожей ситуации в одной из команд корпорации.
В Microsoft ввели свою градацию уровней тестирования. Не предлагая конкретных названий, они просто предложили ввести уровни L1 и L2. Если наложить это на нашу ситуацию, получится:

Сегодня поговорим как раз про L1 и L2, причем в основном о втором, поскольку без уровня L2, об L1 говорить нет смысла — его сложнее победить по ресурсам.
Рассмотрим чуть подробнее тесты L1.
Если выше мы смотрели на множество сервисов как на единое целое с неким API, то теперь каждый отдельный сервис будем рассматривать как самостоятельную единицу и тестировать его в изоляции.
Каждому из сервисов для тестирования нужно передавать необходимые зависимости — БД, другие сервисы и т. п. Вместо этих зависимостей мы ставим моки, а где не сможем этого сделать, подключим заранее подготовленные реальные ресурсы — БД, очереди и т.п. (лучше персонально, если это возможно).
Для организации L1-среды можно использовать, например, docker-контейнер сервиса, который хотим протестировать. Деплоим его в docker и начинаем писать тесты.
Также, на .NET это можно сделать с помощью библиотек TestServer/WebApplicationFactory.
Пара ссылок с деталями:
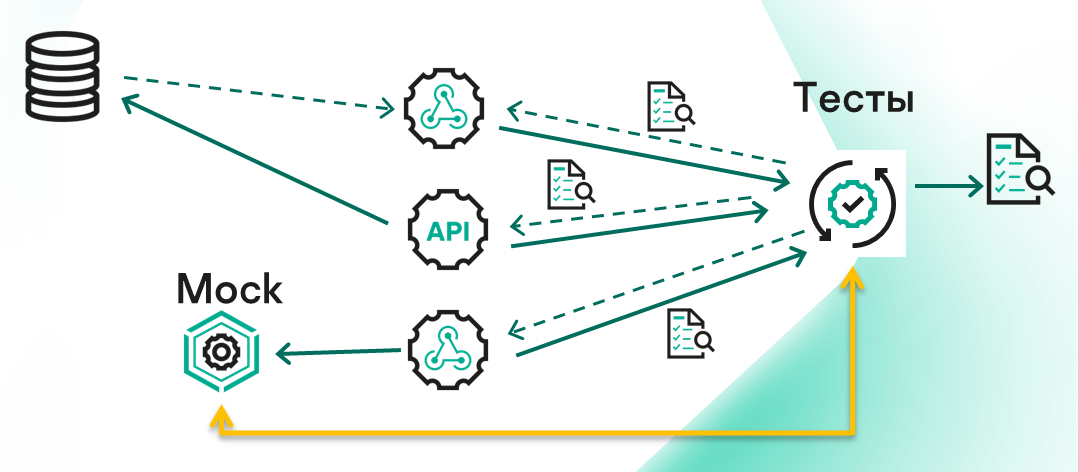
В микросервисной архитектуре все сервисы взаимодействуют между собой. На самом деле, «не все и не со всеми». Большинству сервисов, для нормальной работы, нужно общаться лишь с 1-3 другими. А наличие рядом остальных сервисов нужно лишь для каких-то минимальных контрактных взаимодействий.
И если выделить такие группы сервисов, то можно обнаружить потоки данных, которые вполне могли бы быть покрыты тестами (красная стрелка на схеме).

Если мы добавляем в нашу пирамиду L2-тесты, схема получается такой:
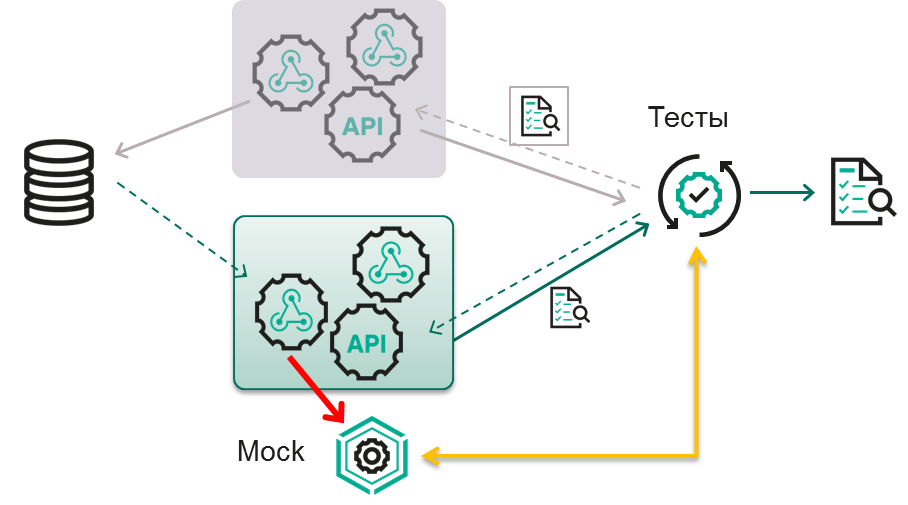
Мы можем разделить сервисы на группы в соответствии с бизнес-логикой: например, отдельно можно выделить взаимодействие с пользователями, и отдельно — работу с заказами. В этом случае логично протестировать только работу с заказами. А в тех местах, где нужно будет обратиться к другой группе сервисов — получить адрес доставки пользователя или что-нибудь еще, — мы используем мок, который будет притворяться конкретным сервисом или их группой.
При таком подходе тестов становится больше, но деление на группы позволяет рассматривать каждую из них в отдельности, и не зависеть от того, что происходит с сервисами из других групп.
L2-тесты запускаются уже не локально. Они отправляются туда, где должны быть: в Kubernetes, в Docker и т. д. Единственное отличие в том, что разворачивать необходимо только небольшую группу сервисов, а также некоторое количество моков и БД, чтобы для этой группы все было максимально похоже на прод (с точностью до подмены чужих зависимостей).
В первую очередь можно тестировать логику работы всей бизнес-сущности по тест-кейсам, которые создают тестировщики. Например, можно отправить запрос в API на создание заказа. Задача перейдет в соседний сервис, который вычитает сообщения из очереди, узнает адрес, постучавшись в мок, и поставит задание на доставку. В API мы сможем получить результат, и принять решение успешно ли прошел тест.
Так же мы можем тестировать контракты — взаимодействие сервисов разных команд, которые ранее согласовали, в каком формате они будут обмениваться информацией. Допустим, это будет JSON с определенными строками, что и следует проверить. Контракт можно зафиксировать в моке и проверять, приходит ли в тесте то, что нужно.
Все эти тесты более приближены к интеграционным, которые ранее мы запускали по ночам. L2-тесты тоже можно запускать каждую ночь, но нет смысла это делать на одних и тех же данных. Если однажды тесты прошли, значит, при отсутствии изменений в коде, результат не изменится (потому что мы всегда создаем с нуля БД, готовим пустой мок и т. д.). Поэтому самый правильный момент для запуска — pull-request, т. е. на этапе, когда принимается решение, можно ли изменения от разработчика переместить в основную ветку. Как правило, все системы управления задачами позволяют создать политики и запускать L2-тесты перед тем, как мержить изменения. Если тесты проходят, изменения можно вносить. Если нет, значит, в коде есть какая-то проблема, которую необходимо решить и только потом возвращаться к pull request.
Локально L2-тесты запускать тоже можно, но, если честно, это довольно сложно, и об этом необходимо говорить отдельно. У нас предусмотрены инструкции Terraform — они помогают создать персональную инфраструктуру для запуска тестов, которые не будут никому мешать. Так что мы действительно так делаем. Но описание подробных механизмов — за рамками данной статьи.
Далее поговорим подробнее про каждый из шагов, необходимых для запуска L2 в среде.
Как я уже упоминал, нам понадобится моки. И они бывают очень разные.
Если тестируемый сервис читает очередь из RabbitMQ или аналога, необходимо притвориться тем, кто пишет туда сообщения. Каждый тест будет начинаться с того, что мы кладем в очередь некую задачу и убеждаемся, что сервис ее действительно читает и переходит к дальнейшим действиям. Аналогична ситуация с БД и ее таблицей, или файловыми ресурсами в облаке. В начале теста мы можем сами в зайти БД, добавить необходимые данные и посмотреть, что сервис с ними сделает.
Но все это — обычные подключения, а не моки. Интереснее становится, когда микросервисы расположены в Kubernetes и общаются по API (а у нас это процентов 80 взаимодействий). Чаще всего это Restful API. Если у вас тоже так, рекомендую обратить внимание на сервис WireMock (About wiremock.NET: https://github.com/WireMock-Net/WireMock.Net).
Wiremoсk, выложенный в GitHub — опенсорсный. Есть несколько вариантов, написанных на разных языках — Java, Golang и .NET. Прототипом для всех версий была Java, а потом уже появились .NET и Golang. Однако все они выполняют примерно одну и ту же задачу.
Wiremoсk можно запустить в удобной форме — как dotnet tools, как консольное приложение, как Windows-сервис, или даже развернуть на IIS-сервере. Можно его запустить в контейнере. И в нашем случае, когда мы говорим про тесты в Kubernetes, мы будем рассматривать его именно как отдельный контейнер с сервисом, предназначенным для тестирования.
Расскажу о возможностях Wiremock.NET на его собственных примерах:
В первую очередь мы можем дернуть с помощью Wiremoсk вот такой URL:
В ответ мы получим JSON с историей всех запросов, которые в него приходили.
Предположим, мы в сервисе вместо настоящего адреса прописали URL мока. Эта команда позволяет посмотреть, что в моке произошло — какие запросы приходили и по каким адресам.
В примере мы видим POST-запрос
Его хедеры:
Тело запроса:
А также ответ кодом 404:
Структура здесь довольно легко читается. У нее есть объект request, где сохранен пришедший запрос:
И есть объект response, в котором мок описывает, как именно он ответил на этот запрос. В нашем примере мок ответил кодом 404 и JSON-ом «no matching mapping found». Это дефолтное поведение мока в ответ на все, что ему незнакомо:
Мы можем задать поведение Wiremock в ответ на конкретные запросы. Для этого надо отправить POST или PUT запрос на URL https://wiremock-url.com/__admin/mappings (PUT отправляется в случае внесения изменений):
В нашем примере есть блок Request:
И есть блок Response:
Мы можем предопределить, что если кто-нибудь придет на определенный URL:
Неважно, большие или маленькие буквы будут в запросе:
И это будет метод POST,
А в BODY будет поле grant_type с определенным значением и с непустым code:
Тогда необходимо ответить так, как описано в Response (кодом 200 и JSON-ом):
Значения в JSON ответа не обязательно должны быть статичными. Их можно генерировать под каждый запрос. Например, вот так:
В документации на GitHub есть миллион примеров. Можно генерировать цифры, слова, номера телефонов, IP-адреса.
Но вернемся к запросам. Посмотрим на такой пример:
Грубо говоря, был некоторый request, который пришел по такому адресу:
Это был GET с некоторыми хедерами:
Мок ему ответил кодом 200 и JSON-ом, потому что ранее был выполнен такой маппинг:
То есть помимо самого ответа Wiremock сохраняет информацию о маппинге:
В данном случае запрос совпал по пути и по методу (других правил маппинга не было):
Бывает, что запрос мапится не полностью. В запросе, который мы обсуждали выше, была такая штука:
Это означает, что Wiremock не нашел ни одного варианта, который полностью соответствовал бы запросу. Поэтому ответил кодом 404 (no matching found). Но на самом деле был похожий маппинг, который он не стал использовать из-за неполного совпадения (он подошел по пути, но не подошел по методу и body):
Здесь «Score»: 0. Возможно, так и было задумано — маппинг не должен был подойти. А возможно, вы допустили ошибку, думая, что в body будет иное условие, и ожидали другой ответ. В этом случае ошибку надо исправлять — либо изменить маппинг, либо вообще убрать условие на body. Есть множество вариантов, как этот вопрос решить. Но суть в том, что Wiremock умеет предупреждать про такое.
Перейдем к следующему шагу — сборке.
Тестируемые сервисы у нас уже собраны — либо наши DevOps (если на проекте выделена такая роль), либо наши разработчики наверняка уже написали какие-то пайплайны, которые собирают и выкладывают сервисы, а потом они каким-то образом разворачиваются в Kubernetes. Все это не относится к задачам тестировщика. Однако на уровне L2 следует подумать о том, что разворачиваться будет только ограниченная группа сервисов. Поэтому стоит завести для них отдельный файл конфигурации, в котором вместо реальных ссылок на другие сервисы будет проставлена ссылка на Wiremock. В остальном в сборку вмешиваться не надо.
Помимо сервисов у нас есть тестовый проект. Возможно, до этого мы гоняли тесты локально, но так как сейчас все в Kubernetes, почему бы не запустить оттуда и тесты? Так что наш следующий шаг — собираем тестовый проект. Рядом с привычными DLL-ками или EXE-шками должен появиться DockerFile — инструкция, которая описывает, как из DLL сделать контейнер. Впоследствии он отправится в Docker. Подробнее про эту инструкцию мы еще поговорим далее.
После ее создания надо выполнить две команды:
В итоге мы создали все три вида контейнеров, необходимых для начала тестирования:
Остановлюсь чуть подробнее на docker-файле. Он может сильно отличаться от кода. В нашем случае тесты пишутся на C#, поэтому пример я привел для него:
Любой docker-файл — это набор инструкций.
Для начала мы сообщаем, на чем этот набор будет основан: с помощью команды From выбираем, какую библиотеку нужно подключить (какие команды установить на воображаемом виртуальном сервере, чтобы это все работало). В нашем случае понадобится команда dotnet vstest с набором параметров.
Основной параметр — в последней строке, где указана ссылка на конкретную DLL с тестовыми методами. Кроме нее, обязательно нужно знать, где будут результаты наших тестов (параметр ResultsDirectory) и в каком формате (параметр logger).
Этой командой я сообщаю, что результаты должны лежать в формате trx в файлике с названием BUILD_NUMBER.trx. Эти файлы подойдут для системы, где мы заводим задачи и фиксируем прогоны (TFS). На самом деле форматов, помимо trx, много. От проекта к проекту они будут меняться, но подвох в том, что нужно понимать, где именно лежат ваши результаты.
Замечу, что если тесты пишутся не на .NET (C#), команда будет другая, хотя и похожая.
Мы создали три контейнера, теперь их нужно запустить.
Начинаем с сервисов. Деплоим их на среду точно так же, как мы это делали бы на проде. В конфигурациях должны быть уже прописаны строки подключения к БД, ссылки на моки и т. п. Возможно, деплой будет сопровождаться какими-то дополнительными командами (очисткой или созданием базы данных). У нас чуть более сложная схема — мы создаем все ресурсы с помощью Terraform.
Деплоить лучше на ту среду, где кроме тестов никого не будет, чтобы никто не помешал прогону и каждый следующий запуск был похож на предыдущий по своему первичному состоянию.
После деплоя сервиса необходимо рядом задеплоить контейнер с моком, чтобы эмулировать другие сервисы. Как мок, так и сервис живут бесконечно долго, т. е. они не завершатся, пока мы их явно не выключим (если, конечно, в сервисе не обнаружится ошибка и он не объестся памяти). В териминах Kubernetes это называется «Deployment».
И на третьем шаге необходимо задеплоить сами тесты. Их имеет смысл разместить рядом, в том же кластере Kubernetes. В отличие от сервиса и мока, тесты рано или поздно завершатся сами (когда прогон закончится). А это значит, что абстракция «Deployment» не подойдет. Но подойдет «Job», то есть о задача, по завершении которой ресурсы высвобождаются, а контейнер перестает существовать (отличая ее от deployment, который существует бесконечно).
Важно в ходе такого автоматического завершения не потерять результаты тестов. Поэтому прежде чем запускать тесты, к контейнеру необходимо подключить папку, которая не исчезнет после его удаления. В терминах Kubernetes такая папка называется persistentVolume.
Через некоторое время после запуска тестов нам необходимо посмотреть, чем все закончилось — прошли ли тесты.
Самый простой, но не самый правильный вариант — просто посмотреть в папку с результатами (ту, что мы подключили к тестам). Как только в ней появится файл .trx с номером билда, тесты завершились.
Другой вариант, если мы хотим видеть результаты тестов сразу по мере их прохождения. Чтобы это реализовать, непосредственно из тестов необходимо уведомлять Test Management System (в нашем случае — Azure DevOps) о том, что пройдено, а что нет. Так вся информация будет появляться в режиме реального времени.
Можно использовать какой-то свой подход — например, мониторить job, когда она высвободит ресурсы в Kubernetes.
Какой подход удобнее — зависит от времени прогона тестов. Если он занимает три минуты, в постепенной публикации результатов нет смысла, можно и подождать.
Рано или поздно мы получаем список результатов и можем принимать решение, что делать дальше. Если тесты прошли, можно завершить pull-request и закрывать задачу, а релиз выкатывать на другие среды.
Если тесты не прошли, придется искать ошибку. Она может быть в коде или в тестах. Задача — добиться зеленого прогона и только потом завершать pull request.
Благодаря появлению в нашей команде L2-тестов люди стали больше общаться.
Раньше разработчик мог запилить фичу и отдать ее в интеграционное тестирование. Если на этом этапе какой-то сторонний сервис не работал, все ломалось, фактически тестирование новой доработки затягивалось надолго, и, иногда, только через неделю будут какие-то результаты по новой фиче.
L2-тесты понятнее, чем интеграционные. Там порой встречаются более низкоуровневые моменты, которые проще спросить, чем понять самостоятельно. Если где-то обнаруживается проблема, разработчик и тестировщик садятся рядом и выясняют, на чьей она стороне. Плюс такие тесты могут писать и сами разработчики, вникая в процесс тестирования. Тестировщики, в свою очередь, чаще заглядывают в код разработки, чтобы понять, как лучше написать тесты. И в итоге больше людей в курсе, что меняется, и как устроены процессы.
Второй важный плюс L2-тестов — это то, что мы теперь не зависим от сторонних сервисов. Раньше все сервисы были в одной куче. Если хотя бы один из них ломался, мы не могли тестировать другие. Когда мы говорим про L2-тесты, достаточно смотреть только на маленькую группу сервисов. Вокруг нее моки, поэтому все гораздо проще. Мы ни от кого не зависим и можем полностью все проверить, закрыв pull request. Это удобно и очень сильно сокращает время.
Третий момент — обратная связь стала быстрее. Тут сразу два нюанса. Во-первых, я уже упомянул изоляцию — мы не ждем, когда починят другие сервисы. Во-вторых, изменился сам процесс тестирования. Если раньше надо было создавать пользователя, потом от его имени разместить заказ, и это занимало какое-то время, то теперь можно на этом не останавливаться. Достаточно просто предупредить мок, что из сервиса придут за адресом пользователя, указав, что следует вернуть. И с этого момента можно уже запускать тест на заказ — все будет полностью работать. А то время, которое я бы потратил на создание пользователя, можно использовать на другие задачи.
Тесты стали быстрее, их можно гонять не по ночам, а за 5 минут перед pull request. Так разработчик быстрее понимает, все ли хорошо он сделал.
Наличие моков позволяет тестировать значительно больше. Раньше мы не могли заставить сервис ответить как-то «неправильно», например «http 502 time out», потому что для этого требовалось бы реально его сломать. А теперь мы вполне можем это сделать, попросив мок ответить с нужной нам ошибкой. Так можно изучить поведение других сервисов в случае поломки первого. Раньше мы это просто не тестировали. Так что тестов действительно становится больше.
Но есть, конечно, и обратная сторона медали.
L2-тесты — это все-таки не панацея. Они не отменяют интеграционных тестов («L3», как мы их называем), Unit-тестов и прочего. Они просто позволяют иногда быть быстрее и иметь те плюсы, о которых я сказал выше.
L2-тесты сложнее. Для их написания нужны некоторые DevOps-навыки, потому что нужно понимать, как работают контейнеры, как они взаимодействуют, как самому сходить в очереди и что необходимо подменить на мок. Раньше мы просто кидали запросы в API через Postman. Теперь же необходимо кидать сообщения в очередь, писать записи в БД. Поэтому скилл должен быть чуть выше. Джуны могут не справиться, и в принципе новые люди дольше погружаются в то, как все работает.
Также надо понимать, что L2-тесты запускаются всегда с чистого листа, иначе в них бы не было смысла. То есть мы всегда должны иметь чистую базу данных, чистый мок, одно и то же поведение. Сервис не должен читать старые данные. Если об этом не думать, в L2-среде все тесты могут пройти, а потом на проде обнаружится, что сервис не может прочитать данные, потому что поддерживает только новый формат, а при получении старых сообщений все падает. По-хорошему, надо заранее пойти в мок и предупредить его, что иногда надо отвечать в старом формате данных, и написать соответствующий тест. На интеграционном уровне о таком даже думать не надо. Там всегда среда забита всем подряд — и новыми, и старыми форматами. Там, как раз, тесты не пишутся с чистого листа и случается всякое.
Также стоит добавить, что на написание L2-тестов понадобится больше времени, чем на написание интеграционных. Если раньше мы могли описать в первом шаге теста создание юзера, во втором — создание заказа, а на третьем проверить, создан ли заказ, теперь нам нужно отдельно написать тест на создание юзера и убедиться, что он действительно создается. Потом написать отдельный тест на создание заказа. Все тестируется по отдельности, и на это нужно чуть больше времени. Но, поверьте, это вполне окупается скоростью прогонов.
Еще важно не забывать о том, что не все взаимодействия внутренние. Даже если вы сделаете L2-тесты на каждый из своих сервисов, у вас наверняка останутся внешние взаимодействия с другими продуктами — требования взаимодействия, контракты. На уровне L2 мы, скорее всего, их «замокаем» в полном соответствии с требованиями. Но если другая команда, не уведомив нас, что-то поменяет, на уровне L2 мы об этом не узнаем и продолжим мокать по-старому — как написано в документации. Только когда мы выйдем на интеграционный уровень и запросим какие-то данные из другого продукта, будет заметна ошибка. В итоге остается верить, что другая команда будет тестировать качественно и уведомит нас об изменениях. В общем, не стоит забывать о том, что интеграционные тесты должны оставаться хотя бы в позитивном варианте.
Если у вас маленькие микросервисы, L2-тесты вам действительно нужны. Их легко писать, они приносят с собой много плюсов — тестирование идет быстрее, результат виден сразу и не нужны никакие ночные прогоны. Количество интеграционных тестов сокращается очень сильно. Для микросервисов L2 — это идеальный вариант.
Однако если у вас огромный монолит, внутри которого есть миллион интеграций, вы просто устанете ставить моки.
Понятно, что может быть какой-то промежуточный вариант — уже в Kubernetes, но все еще нечто большое и неповоротливое. Тогда можно попробовать L2-тестирование, но придется потратить много времени. Однако в целом с появлением двух тестов L2 у нас пропала необходимость в одном интеграционном тесте на уровень выше. То есть в пирамиде тестирования мы потихоньку сдвигаем вниз тесты с интеграционного уровня. Они становятся быстрее, за счет чего можно чаще проверять себя. В нашем примере вместо восьми часов мы можем прогонять тесты за час-полтора.

Уровни L1 и L2, о которых мы сейчас говорили, я бы назвал тестированием контрактов и тестированием компонентов соответственно. Если у вас есть свой вариант названия — добро пожаловать в комментарии.
А если хотите поучаствовать в подобных изысканиях, приходите к нам в команды SDET и в смежную команду DevOps. Продолжим эксперименты с пирамидой тестирования вместе :)
Сегодня я расскажу о том, что такое L2-тесты в понимании нашей команды, как их развернуть и какие результаты можно получить. Эти тесты позволили нам избавиться от ночных восьмичасовых прогонов интеграционных тестов. Фактически мы спустили часть интеграционных тестов на уровни ниже, и теперь можем получать результаты значительно быстрее. Однако L2-тестирование требует более высокой квалификации тестировщиков и заставляет команды больше общаться — об этом тоже поговорим.
Как правило, тестировщики видят целый набор сервисов, которые как-то взаимодействуют между собой. Не вдаваясь в подробности, скажем, что их рассматривают как единое целое с неким API, не задумываясь о том, что внутри может быть своя архитектура.
Раньше мы смотрели на ситуацию так же. Проблема в том, что если один из сервисов в цепочке ломается, мы уже не можем тестировать остальные. А кроме того, процесс, затрагивающий все сервисы, проходит достаточно долго. Из-за этого мы были вынуждены запускать тесты по ночам, получая результаты и фидбэк о вчерашней работе только утром следующего дня. Суммарно прогон занимал порядка 8 часов.
На пирамиде тестирования существующая ситуация выглядела следующим образом.
- L0 — это юнит-тесты, которые пишут разработчики; тестеры не в курсе, что там происходит.
- L3 — интеграционные тесты, которые пишут автотестеры.
- L4 — ручные end-to-end тесты. Они появляются непосредственно перед релизом на конкретной среде.
Опираясь на такое представление, мы попытались найти решение своей проблемы. И наткнулись на вот эту статью в блоге Microsoft, где описывался подход, примененный в схожей ситуации в одной из команд корпорации.
В Microsoft ввели свою градацию уровней тестирования. Не предлагая конкретных названий, они просто предложили ввести уровни L1 и L2. Если наложить это на нашу ситуацию, получится:
Сегодня поговорим как раз про L1 и L2, причем в основном о втором, поскольку без уровня L2, об L1 говорить нет смысла — его сложнее победить по ресурсам.
L1-тесты
Рассмотрим чуть подробнее тесты L1.
Если выше мы смотрели на множество сервисов как на единое целое с неким API, то теперь каждый отдельный сервис будем рассматривать как самостоятельную единицу и тестировать его в изоляции.
Каждому из сервисов для тестирования нужно передавать необходимые зависимости — БД, другие сервисы и т. п. Вместо этих зависимостей мы ставим моки, а где не сможем этого сделать, подключим заранее подготовленные реальные ресурсы — БД, очереди и т.п. (лучше персонально, если это возможно).
Для организации L1-среды можно использовать, например, docker-контейнер сервиса, который хотим протестировать. Деплоим его в docker и начинаем писать тесты.
Также, на .NET это можно сделать с помощью библиотек TestServer/WebApplicationFactory.
Пара ссылок с деталями:
- https://learn.microsoft.com/ru-ru/aspnet/core/test/middleware?view=aspnetcore-6.0
- https://blog.markvincze.com/overriding-configuration-in-asp-net-core-integration-tests/
L2-тесты
В микросервисной архитектуре все сервисы взаимодействуют между собой. На самом деле, «не все и не со всеми». Большинству сервисов, для нормальной работы, нужно общаться лишь с 1-3 другими. А наличие рядом остальных сервисов нужно лишь для каких-то минимальных контрактных взаимодействий.
И если выделить такие группы сервисов, то можно обнаружить потоки данных, которые вполне могли бы быть покрыты тестами (красная стрелка на схеме).
Если мы добавляем в нашу пирамиду L2-тесты, схема получается такой:
Мы можем разделить сервисы на группы в соответствии с бизнес-логикой: например, отдельно можно выделить взаимодействие с пользователями, и отдельно — работу с заказами. В этом случае логично протестировать только работу с заказами. А в тех местах, где нужно будет обратиться к другой группе сервисов — получить адрес доставки пользователя или что-нибудь еще, — мы используем мок, который будет притворяться конкретным сервисом или их группой.
При таком подходе тестов становится больше, но деление на группы позволяет рассматривать каждую из них в отдельности, и не зависеть от того, что происходит с сервисами из других групп.
L2-тесты запускаются уже не локально. Они отправляются туда, где должны быть: в Kubernetes, в Docker и т. д. Единственное отличие в том, что разворачивать необходимо только небольшую группу сервисов, а также некоторое количество моков и БД, чтобы для этой группы все было максимально похоже на прод (с точностью до подмены чужих зависимостей).
Что мы тестируем на этом уровне
В первую очередь можно тестировать логику работы всей бизнес-сущности по тест-кейсам, которые создают тестировщики. Например, можно отправить запрос в API на создание заказа. Задача перейдет в соседний сервис, который вычитает сообщения из очереди, узнает адрес, постучавшись в мок, и поставит задание на доставку. В API мы сможем получить результат, и принять решение успешно ли прошел тест.
Так же мы можем тестировать контракты — взаимодействие сервисов разных команд, которые ранее согласовали, в каком формате они будут обмениваться информацией. Допустим, это будет JSON с определенными строками, что и следует проверить. Контракт можно зафиксировать в моке и проверять, приходит ли в тесте то, что нужно.
Все эти тесты более приближены к интеграционным, которые ранее мы запускали по ночам. L2-тесты тоже можно запускать каждую ночь, но нет смысла это делать на одних и тех же данных. Если однажды тесты прошли, значит, при отсутствии изменений в коде, результат не изменится (потому что мы всегда создаем с нуля БД, готовим пустой мок и т. д.). Поэтому самый правильный момент для запуска — pull-request, т. е. на этапе, когда принимается решение, можно ли изменения от разработчика переместить в основную ветку. Как правило, все системы управления задачами позволяют создать политики и запускать L2-тесты перед тем, как мержить изменения. Если тесты проходят, изменения можно вносить. Если нет, значит, в коде есть какая-то проблема, которую необходимо решить и только потом возвращаться к pull request.
Локально L2-тесты запускать тоже можно, но, если честно, это довольно сложно, и об этом необходимо говорить отдельно. У нас предусмотрены инструкции Terraform — они помогают создать персональную инфраструктуру для запуска тестов, которые не будут никому мешать. Так что мы действительно так делаем. Но описание подробных механизмов — за рамками данной статьи.
Далее поговорим подробнее про каждый из шагов, необходимых для запуска L2 в среде.
Моки
Как я уже упоминал, нам понадобится моки. И они бывают очень разные.
Если тестируемый сервис читает очередь из RabbitMQ или аналога, необходимо притвориться тем, кто пишет туда сообщения. Каждый тест будет начинаться с того, что мы кладем в очередь некую задачу и убеждаемся, что сервис ее действительно читает и переходит к дальнейшим действиям. Аналогична ситуация с БД и ее таблицей, или файловыми ресурсами в облаке. В начале теста мы можем сами в зайти БД, добавить необходимые данные и посмотреть, что сервис с ними сделает.
Но все это — обычные подключения, а не моки. Интереснее становится, когда микросервисы расположены в Kubernetes и общаются по API (а у нас это процентов 80 взаимодействий). Чаще всего это Restful API. Если у вас тоже так, рекомендую обратить внимание на сервис WireMock (About wiremock.NET: https://github.com/WireMock-Net/WireMock.Net).
Wiremoсk, выложенный в GitHub — опенсорсный. Есть несколько вариантов, написанных на разных языках — Java, Golang и .NET. Прототипом для всех версий была Java, а потом уже появились .NET и Golang. Однако все они выполняют примерно одну и ту же задачу.
Wiremoсk можно запустить в удобной форме — как dotnet tools, как консольное приложение, как Windows-сервис, или даже развернуть на IIS-сервере. Можно его запустить в контейнере. И в нашем случае, когда мы говорим про тесты в Kubernetes, мы будем рассматривать его именно как отдельный контейнер с сервисом, предназначенным для тестирования.
Расскажу о возможностях Wiremock.NET на его собственных примерах:
- Request body sample
https://gist.github.com/Sugrob57/d2666d099c03e49034b90c1ea6bd8cbe; - Requests response sample
https://gist.github.com/Sugrob57/a5b6cf13e73dd774ce94a4cf9a317389.
В первую очередь мы можем дернуть с помощью Wiremoсk вот такой URL:
// GET https://wiremock-url.com/__admin/requests
В ответ мы получим JSON с историей всех запросов, которые в него приходили.
Предположим, мы в сервисе вместо настоящего адреса прописали URL мока. Эта команда позволяет посмотреть, что в моке произошло — какие запросы приходили и по каким адресам.
"Path": "/Subscriptions/v2.0/api/Subscription/notifyUsage",
В примере мы видим POST-запрос
"Method": "POST",
Его хедеры:
"Headers": {
"Date": [
"Mon, 21 Nov 2022 10:35:41 GMT"
],
"Content-Type": [
"application/json; charset=utf-8"
],
"Accept": [
"application/json"
],
"Host": [
"wiremock.my-site.com"
],
"Content-Length": [
"65"
},
Тело запроса:
"Body": "{\"LicenseId\":\"a11be891-1777-4685-ac00-4fd7aae1bc7a\",\"Quantity\":1}",
"BodyAsJson": {
"LicenseId": "a11be891-1777-4685-ac00-4fd7aae1bc7a",
"Quantity": 1
},
А также ответ кодом 404:
"Response": {
"StatusCode": 404,
"Headers": {
"Content-Type": [
"application/json"
]
},
Структура здесь довольно легко читается. У нее есть объект request, где сохранен пришедший запрос:
"Request": {
"ClientIP": "10.222.22.22",
"DateTime": "2022-11-21T10:35:41.5508475Z",
"Path": "/Subscriptions/v2.0/api/Subscription/notifyUsage",
"AbsolutePath": "/Subscriptions/v2.0/api/Subscription/notifyUsage",
"Url": "http://wiremock.my-site.com/Subscriptions/v2.0/api/Subscription/notifyUsage",
"AbsoluteUrl": "http://wiremock.my-site.com/Subscriptions/v2.0/api/Subscription/notifyUsage",
…
И есть объект response, в котором мок описывает, как именно он ответил на этот запрос. В нашем примере мок ответил кодом 404 и JSON-ом «no matching mapping found». Это дефолтное поведение мока в ответ на все, что ему незнакомо:
"BodyAsJson": {
"Status": "No matching mapping found"
},
Мы можем задать поведение Wiremock в ответ на конкретные запросы. Для этого надо отправить POST или PUT запрос на URL https://wiremock-url.com/__admin/mappings (PUT отправляется в случае внесения изменений):
// POST/PUT https://wiremock-url.com/__admin/mappings
В нашем примере есть блок Request:
"Request": {
"ClientIP": null,
"Path": {
"Matchers": [
{
"Name": "WildcardMatcher",
"Pattern": "/AuthPortal/api/v1/token",
"Patterns": null,
"IgnoreCase": true,
"RejectOnMatch": null
…
И есть блок Response:
"Response": {
"StatusCode": 200,
"BodyDestination": null,
"Body": null,
"BodyAsJson": {
"token_type": "Bearer",
"expires_in": 3600,
"id_token": {
"iss": "https://dev.mysite.com",
…
Мы можем предопределить, что если кто-нибудь придет на определенный URL:
"Pattern": "/AuthPortal/api/v1/token",
Неважно, большие или маленькие буквы будут в запросе:
"IgnoreCase": true,
И это будет метод POST,
"Methods": [
"Post"
],
А в BODY будет поле grant_type с определенным значением и с непустым code:
"Body": {
"Matchers": [
{
"Name": "JmesPathMatcher",
"Pattern": "grant_type == 'authorization_code' && code != null",
"Patterns": null,
"IgnoreCase": true,
"RejectOnMatch": null
}
]
}
Тогда необходимо ответить так, как описано в Response (кодом 200 и JSON-ом):
"Response": {
"StatusCode": 200,
"BodyDestination": null,
"Body": null,
"BodyAsJson": {
"token_type": "Bearer",
"expires_in": 3600,
"id_token": {
"iss": "https://dev.mysite.com",
"sub": "{{Random Type=\"TextRegex\" Pattern=\"[a-f0-9]{32}\"}}",
"aud": "DLP",
"exp": 1605631164,
"iat": 1605627564
}
},
Значения в JSON ответа не обязательно должны быть статичными. Их можно генерировать под каждый запрос. Например, вот так:
"sub": "{{Random Type=\"TextRegex\" Pattern=\"[a-f0-9]{32}\"}}",
В документации на GitHub есть миллион примеров. Можно генерировать цифры, слова, номера телефонов, IP-адреса.
Но вернемся к запросам. Посмотрим на такой пример:
"Request": {
"ClientIP": "10.222.22.22",
"DateTime": "2022-10-27T12:41:35.9487807Z",
"Path": "/api/v1/access/f1209fbd-db77-498f-8f86-6c0b12351717",
"AbsolutePath": "/api/v1/access/f1209fbd-db77-498f-8f86-6c0b12351717",
"Url": "http://wiremock.my-web-site.com/api/v1/access/f1209fbd-db77-498f-8f86-6c0b12351717",
"AbsoluteUrl": "http://wiremock.my-web-site.com/api/v1/access/f1209fbd-db77-498f-8f86-6c0b12351717",
"Query": {},
"Method": "GET",
"Headers": {
"Date": [
"Thu, 27 Oct 2022 12:41:35 GMT"
],
"Accept": [
"application/json"
],
…
Грубо говоря, был некоторый request, который пришел по такому адресу:
"Path": "/api/v1/access/f1209fbd-db77-498f-8f86-6c0b12351717",
Это был GET с некоторыми хедерами:
"Method": "GET",
Мок ему ответил кодом 200 и JSON-ом, потому что ранее был выполнен такой маппинг:
"Response": {
"StatusCode": 200,
"Headers": {
"Content-Type": [
"application/json"
]
},
"BodyAsJson": {
"Access": "true"
},
То есть помимо самого ответа Wiremock сохраняет информацию о маппинге:
"MappingGuid": "03b76624-f1b2-4bd9-94cb-918647449080",
В данном случае запрос совпал по пути и по методу (других правил маппинга не было):
"MatchDetails": [
{
"Name": "PathMatcher",
"Score": 1.0
},
{
"Name": "MethodMatcher",
"Score": 1.0
}
]
Бывает, что запрос мапится не полностью. В запросе, который мы обсуждали выше, была такая штука:
"PartialMappingGuid": "ad8a6891-eb47-4b05-8e34-0e50f4cb4d05",
Это означает, что Wiremock не нашел ни одного варианта, который полностью соответствовал бы запросу. Поэтому ответил кодом 404 (no matching found). Но на самом деле был похожий маппинг, который он не стал использовать из-за неполного совпадения (он подошел по пути, но не подошел по методу и body):
"PartialRequestMatchResult": {
"TotalScore": 1,
"TotalNumber": 3,
"IsPerfectMatch": false,
"AverageTotalScore": 0.3333333333333333,
"MatchDetails": [
{
"Name": "PathMatcher",
"Score": 1
},
{
"Name": "MethodMatcher",
"Score": 1
},
{
"Name": "BodyMatcher",
"Score": 0
}
]
}
Здесь «Score»: 0. Возможно, так и было задумано — маппинг не должен был подойти. А возможно, вы допустили ошибку, думая, что в body будет иное условие, и ожидали другой ответ. В этом случае ошибку надо исправлять — либо изменить маппинг, либо вообще убрать условие на body. Есть множество вариантов, как этот вопрос решить. Но суть в том, что Wiremock умеет предупреждать про такое.
Сборка тестов
Перейдем к следующему шагу — сборке.
Тестируемые сервисы у нас уже собраны — либо наши DevOps (если на проекте выделена такая роль), либо наши разработчики наверняка уже написали какие-то пайплайны, которые собирают и выкладывают сервисы, а потом они каким-то образом разворачиваются в Kubernetes. Все это не относится к задачам тестировщика. Однако на уровне L2 следует подумать о том, что разворачиваться будет только ограниченная группа сервисов. Поэтому стоит завести для них отдельный файл конфигурации, в котором вместо реальных ссылок на другие сервисы будет проставлена ссылка на Wiremock. В остальном в сборку вмешиваться не надо.
Помимо сервисов у нас есть тестовый проект. Возможно, до этого мы гоняли тесты локально, но так как сейчас все в Kubernetes, почему бы не запустить оттуда и тесты? Так что наш следующий шаг — собираем тестовый проект. Рядом с привычными DLL-ками или EXE-шками должен появиться DockerFile — инструкция, которая описывает, как из DLL сделать контейнер. Впоследствии он отправится в Docker. Подробнее про эту инструкцию мы еще поговорим далее.
После ее создания надо выполнить две команды:
- docker build с некоторыми параметрами — по факту она создаст контейнеры по инструкции из DockerFile;
- docker push — после создания контейнер лежит локально, а эта команда выложит его в репозиторий, откуда его уже заберет деплой пайплайн для развертывания в нужной среде.
В итоге мы создали все три вида контейнеров, необходимых для начала тестирования:
- контейнер с сервисом, у которого в конфигах прописан URL на Wiremock;
- контейнер с Wiremock (он и сейчас доступен в публичном репозитории);
- контейнер с нашими тестами.
Остановлюсь чуть подробнее на docker-файле. Он может сильно отличаться от кода. В нашем случае тесты пишутся на C#, поэтому пример я привел для него:
FROM mcr.microsoft.com/dotnet/sdk:6.0.201-focal
ARG BUILD_NUMBER
ENV BUILD_NUMBER=${BUILD_NUMBER}
WORKDIR /app
COPY . .
ENTRYPOINT echo "Build Number: ${BUILD_NUMBER}"; dotnet vstest `
--logger:"trx;LogFileName=$BUILD_NUMBER.trx" `
--ResultsDirectory:/results `
--Parallel `
--Settings:Parallel.runsettings `
Kaspersky.B2BCloud.MyService.L2.Autotests.dll
Любой docker-файл — это набор инструкций.
Для начала мы сообщаем, на чем этот набор будет основан: с помощью команды From выбираем, какую библиотеку нужно подключить (какие команды установить на воображаемом виртуальном сервере, чтобы это все работало). В нашем случае понадобится команда dotnet vstest с набором параметров.
Основной параметр — в последней строке, где указана ссылка на конкретную DLL с тестовыми методами. Кроме нее, обязательно нужно знать, где будут результаты наших тестов (параметр ResultsDirectory) и в каком формате (параметр logger).
dotnet vstest `
--logger:"trx;LogFileName=$BUILD_NUMBER.trx" `
--ResultsDirectory:/results `
--Parallel `
--Settings:Parallel.runsettings `
KasperskyLab.B2BCloud.MyService.L2.Autotests.dll
Этой командой я сообщаю, что результаты должны лежать в формате trx в файлике с названием BUILD_NUMBER.trx. Эти файлы подойдут для системы, где мы заводим задачи и фиксируем прогоны (TFS). На самом деле форматов, помимо trx, много. От проекта к проекту они будут меняться, но подвох в том, что нужно понимать, где именно лежат ваши результаты.
Замечу, что если тесты пишутся не на .NET (C#), команда будет другая, хотя и похожая.
Деплой
Мы создали три контейнера, теперь их нужно запустить.
Начинаем с сервисов. Деплоим их на среду точно так же, как мы это делали бы на проде. В конфигурациях должны быть уже прописаны строки подключения к БД, ссылки на моки и т. п. Возможно, деплой будет сопровождаться какими-то дополнительными командами (очисткой или созданием базы данных). У нас чуть более сложная схема — мы создаем все ресурсы с помощью Terraform.
Деплоить лучше на ту среду, где кроме тестов никого не будет, чтобы никто не помешал прогону и каждый следующий запуск был похож на предыдущий по своему первичному состоянию.
После деплоя сервиса необходимо рядом задеплоить контейнер с моком, чтобы эмулировать другие сервисы. Как мок, так и сервис живут бесконечно долго, т. е. они не завершатся, пока мы их явно не выключим (если, конечно, в сервисе не обнаружится ошибка и он не объестся памяти). В териминах Kubernetes это называется «Deployment».
И на третьем шаге необходимо задеплоить сами тесты. Их имеет смысл разместить рядом, в том же кластере Kubernetes. В отличие от сервиса и мока, тесты рано или поздно завершатся сами (когда прогон закончится). А это значит, что абстракция «Deployment» не подойдет. Но подойдет «Job», то есть о задача, по завершении которой ресурсы высвобождаются, а контейнер перестает существовать (отличая ее от deployment, который существует бесконечно).
Важно в ходе такого автоматического завершения не потерять результаты тестов. Поэтому прежде чем запускать тесты, к контейнеру необходимо подключить папку, которая не исчезнет после его удаления. В терминах Kubernetes такая папка называется persistentVolume.
Публикация результатов
Через некоторое время после запуска тестов нам необходимо посмотреть, чем все закончилось — прошли ли тесты.
Самый простой, но не самый правильный вариант — просто посмотреть в папку с результатами (ту, что мы подключили к тестам). Как только в ней появится файл .trx с номером билда, тесты завершились.
Другой вариант, если мы хотим видеть результаты тестов сразу по мере их прохождения. Чтобы это реализовать, непосредственно из тестов необходимо уведомлять Test Management System (в нашем случае — Azure DevOps) о том, что пройдено, а что нет. Так вся информация будет появляться в режиме реального времени.
Можно использовать какой-то свой подход — например, мониторить job, когда она высвободит ресурсы в Kubernetes.
Какой подход удобнее — зависит от времени прогона тестов. Если он занимает три минуты, в постепенной публикации результатов нет смысла, можно и подождать.
Рано или поздно мы получаем список результатов и можем принимать решение, что делать дальше. Если тесты прошли, можно завершить pull-request и закрывать задачу, а релиз выкатывать на другие среды.
Если тесты не прошли, придется искать ошибку. Она может быть в коде или в тестах. Задача — добиться зеленого прогона и только потом завершать pull request.
Подведем итоги
Что улучшилось
Благодаря появлению в нашей команде L2-тестов люди стали больше общаться.
Раньше разработчик мог запилить фичу и отдать ее в интеграционное тестирование. Если на этом этапе какой-то сторонний сервис не работал, все ломалось, фактически тестирование новой доработки затягивалось надолго, и, иногда, только через неделю будут какие-то результаты по новой фиче.
L2-тесты понятнее, чем интеграционные. Там порой встречаются более низкоуровневые моменты, которые проще спросить, чем понять самостоятельно. Если где-то обнаруживается проблема, разработчик и тестировщик садятся рядом и выясняют, на чьей она стороне. Плюс такие тесты могут писать и сами разработчики, вникая в процесс тестирования. Тестировщики, в свою очередь, чаще заглядывают в код разработки, чтобы понять, как лучше написать тесты. И в итоге больше людей в курсе, что меняется, и как устроены процессы.
Второй важный плюс L2-тестов — это то, что мы теперь не зависим от сторонних сервисов. Раньше все сервисы были в одной куче. Если хотя бы один из них ломался, мы не могли тестировать другие. Когда мы говорим про L2-тесты, достаточно смотреть только на маленькую группу сервисов. Вокруг нее моки, поэтому все гораздо проще. Мы ни от кого не зависим и можем полностью все проверить, закрыв pull request. Это удобно и очень сильно сокращает время.
Третий момент — обратная связь стала быстрее. Тут сразу два нюанса. Во-первых, я уже упомянул изоляцию — мы не ждем, когда починят другие сервисы. Во-вторых, изменился сам процесс тестирования. Если раньше надо было создавать пользователя, потом от его имени разместить заказ, и это занимало какое-то время, то теперь можно на этом не останавливаться. Достаточно просто предупредить мок, что из сервиса придут за адресом пользователя, указав, что следует вернуть. И с этого момента можно уже запускать тест на заказ — все будет полностью работать. А то время, которое я бы потратил на создание пользователя, можно использовать на другие задачи.
Тесты стали быстрее, их можно гонять не по ночам, а за 5 минут перед pull request. Так разработчик быстрее понимает, все ли хорошо он сделал.
Наличие моков позволяет тестировать значительно больше. Раньше мы не могли заставить сервис ответить как-то «неправильно», например «http 502 time out», потому что для этого требовалось бы реально его сломать. А теперь мы вполне можем это сделать, попросив мок ответить с нужной нам ошибкой. Так можно изучить поведение других сервисов в случае поломки первого. Раньше мы это просто не тестировали. Так что тестов действительно становится больше.
Но есть, конечно, и обратная сторона медали.
Что стоит учесть
L2-тесты — это все-таки не панацея. Они не отменяют интеграционных тестов («L3», как мы их называем), Unit-тестов и прочего. Они просто позволяют иногда быть быстрее и иметь те плюсы, о которых я сказал выше.
L2-тесты сложнее. Для их написания нужны некоторые DevOps-навыки, потому что нужно понимать, как работают контейнеры, как они взаимодействуют, как самому сходить в очереди и что необходимо подменить на мок. Раньше мы просто кидали запросы в API через Postman. Теперь же необходимо кидать сообщения в очередь, писать записи в БД. Поэтому скилл должен быть чуть выше. Джуны могут не справиться, и в принципе новые люди дольше погружаются в то, как все работает.
Также надо понимать, что L2-тесты запускаются всегда с чистого листа, иначе в них бы не было смысла. То есть мы всегда должны иметь чистую базу данных, чистый мок, одно и то же поведение. Сервис не должен читать старые данные. Если об этом не думать, в L2-среде все тесты могут пройти, а потом на проде обнаружится, что сервис не может прочитать данные, потому что поддерживает только новый формат, а при получении старых сообщений все падает. По-хорошему, надо заранее пойти в мок и предупредить его, что иногда надо отвечать в старом формате данных, и написать соответствующий тест. На интеграционном уровне о таком даже думать не надо. Там всегда среда забита всем подряд — и новыми, и старыми форматами. Там, как раз, тесты не пишутся с чистого листа и случается всякое.
Также стоит добавить, что на написание L2-тестов понадобится больше времени, чем на написание интеграционных. Если раньше мы могли описать в первом шаге теста создание юзера, во втором — создание заказа, а на третьем проверить, создан ли заказ, теперь нам нужно отдельно написать тест на создание юзера и убедиться, что он действительно создается. Потом написать отдельный тест на создание заказа. Все тестируется по отдельности, и на это нужно чуть больше времени. Но, поверьте, это вполне окупается скоростью прогонов.
Еще важно не забывать о том, что не все взаимодействия внутренние. Даже если вы сделаете L2-тесты на каждый из своих сервисов, у вас наверняка останутся внешние взаимодействия с другими продуктами — требования взаимодействия, контракты. На уровне L2 мы, скорее всего, их «замокаем» в полном соответствии с требованиями. Но если другая команда, не уведомив нас, что-то поменяет, на уровне L2 мы об этом не узнаем и продолжим мокать по-старому — как написано в документации. Только когда мы выйдем на интеграционный уровень и запросим какие-то данные из другого продукта, будет заметна ошибка. В итоге остается верить, что другая команда будет тестировать качественно и уведомит нас об изменениях. В общем, не стоит забывать о том, что интеграционные тесты должны оставаться хотя бы в позитивном варианте.
Когда L2-тесты вам нужны?
Если у вас маленькие микросервисы, L2-тесты вам действительно нужны. Их легко писать, они приносят с собой много плюсов — тестирование идет быстрее, результат виден сразу и не нужны никакие ночные прогоны. Количество интеграционных тестов сокращается очень сильно. Для микросервисов L2 — это идеальный вариант.
Однако если у вас огромный монолит, внутри которого есть миллион интеграций, вы просто устанете ставить моки.
Понятно, что может быть какой-то промежуточный вариант — уже в Kubernetes, но все еще нечто большое и неповоротливое. Тогда можно попробовать L2-тестирование, но придется потратить много времени. Однако в целом с появлением двух тестов L2 у нас пропала необходимость в одном интеграционном тесте на уровень выше. То есть в пирамиде тестирования мы потихоньку сдвигаем вниз тесты с интеграционного уровня. Они становятся быстрее, за счет чего можно чаще проверять себя. В нашем примере вместо восьми часов мы можем прогонять тесты за час-полтора.
Уровни L1 и L2, о которых мы сейчас говорили, я бы назвал тестированием контрактов и тестированием компонентов соответственно. Если у вас есть свой вариант названия — добро пожаловать в комментарии.
А если хотите поучаствовать в подобных изысканиях, приходите к нам в команды SDET и в смежную команду DevOps. Продолжим эксперименты с пирамидой тестирования вместе :)