

Пару недель назад Meta* представила ИИ-модель Voicebox, которая генерирует и редактирует устную речь. Они говорят, что это очередная революция в сфере генеративных ИИ. Модель не только создает речь в точном стиле и голосе любого человека по короткому образцу, но также умеет автоматически удалять шум, поправлять оговорки, понимать контекст. Авторы проекта охарактеризовали Voicebox как «прорыв в моделях речевого ИИ» и «самый универсальный ИИ для генерации речи».
В нашем распоряжении оказался документ с подробностями о реализации этого проекта. Спешим ознакомить с ним вас.
Что такое Voicebox
Voicebox — ИИ, озвучивающий любой написанный текст в нужном вам стиле, тоне, интонации и голосе. Он умеет кричать, повышать голос, шептать, даже звучать эротично. Сгенерированные Midjourney корейские девушки на OnlyFans теперь смогут общаться со своими фанатами голосом! А стать витубером-миллионником смогут не только сладкоголосые девочки с милым акцентом.
Кроме того, Voicebox умеет производить обработку уже готовой записи — скажем, удалять оттуда лишние звуки вроде собачьего лая или гудков машины, понимая, что речь, а что нет. При необходимости с ним можно даже переиграть часть записи, исправив неверно произнесённую фразу или поправив ударения.
Пока что поддерживаются 6 языков: английский, немецкий, испанский, французский, португальский и польский. За счет этого инструмент можно использовать в качестве синхронного переводчика, при этом он будет передавать все интонации и манеру речи собеседника. Так что появилась ещё одна профессия, которую скоро заменит ИИ.
Если подробнее, то Voicebox позволяет решать такие задачи:
Синтез речи в контексте. Используя звуковой образец длиной всего две секунды, Voicebox может начать преобразовывать тексты в речь в том же стиле. Он может обрабатывать текст с фразами, которые видит в первый раз, и правильно генерировать контекст, ударения и интонации. Точно так же, как новый для себя текст читал бы человек.
Редактирование речи и шумоподавление. Voicebox может воссоздать часть речи, прерванную шумом, или заменить оговорки. Как ластик, только для редактирования аудио. Система понимает, когда слово было сказано неверно, и заменяет его. В итоге любой индиец или филиппинец с тремя классами школы может начать говорить как будто на чистейшем английском (по крайней мере, в записи).
Межъязыковая передача стиля. При получении образца чьей-то речи и отрывка текста Voicebox может начать воспроизводить текст на любом из поддерживаемых им языков (даже если образец речи и текст на разных языках). Эту возможность можно использовать в будущем, чтобы помочь людям общаться естественным и аутентичным образом, даже если они не говорят на одном языке. Причем за счет большого разнообразия данных Voicebox способен генерировать речь, похожую на то, как люди разговаривают в реальной жизни.
На практике разработчики Voicebox говорят, что все эти возможности могут оказаться очень полезными в приложениях метавселенной (да, Цукерберг всё еще с этим не успокоился). Чтобы сближать людей из разных социальных бэкграундов и с разными возможностями.
Удивительно, что модель не нуждается в часах аудиофайлов, чтобы научиться мимикрировать под человека. Ей достаточно двухсекундного сэмпла. Благодаря этому ИИ сможет генерировать речь, например, ваших друзей. Скажем, у вас в Телеграме есть пятисекундное голосовое сообщение от человека. Значит, все следующие текстовые сообщения от этого человека дальше может читать ИИ — точно таким же голосом и со всеми характерными интонациями. Или вы сами можете диктовать, что сказать его голосом. На слух понять, что это говорит не тот же человек, будет почти невозможно.

Также предполагается, что такие голосовые генеративные ИИ смогут создавать естественно звучащие голоса для виртуальных помощников и персонажей в играх. Кстати, похожую технологию уже активно используют в «Мире Варкрафта»: игроки сами создали аддон, который озвучивает тысячи NPC разных рас, используя GPT (в данном случае это был EvenLabs AI). Орки звучат хрипло и грубо, гномы пищат, дворфы картавят, таурены вещают мерным басом. Причем каждый персонаж — слегка по-разному. Обычно нужно было бы найти с десяток хороших актеров озвучки, неделями работать в студии, собирать и микшировать сэмплы, потратить на это сотни тысяч долларов. Но теперь всё может быть реализовано внутри одного аддона одним энтузиастом — и совершенно бесплатно (вот, кстати, их GitHub).
Создатели Voicebox полагают, что этот тип технологий может быть использован в будущем, чтобы позволить слабовидящим людям слышать письменные сообщения от своих друзей и близких, а также позволить людям говорить на любом иностранном языке своим собственным голосом. А в качестве бонуса — любимые артисты и звёзды будут читать вам аудиокниги или петь колыбельные.
Как всё это было построено
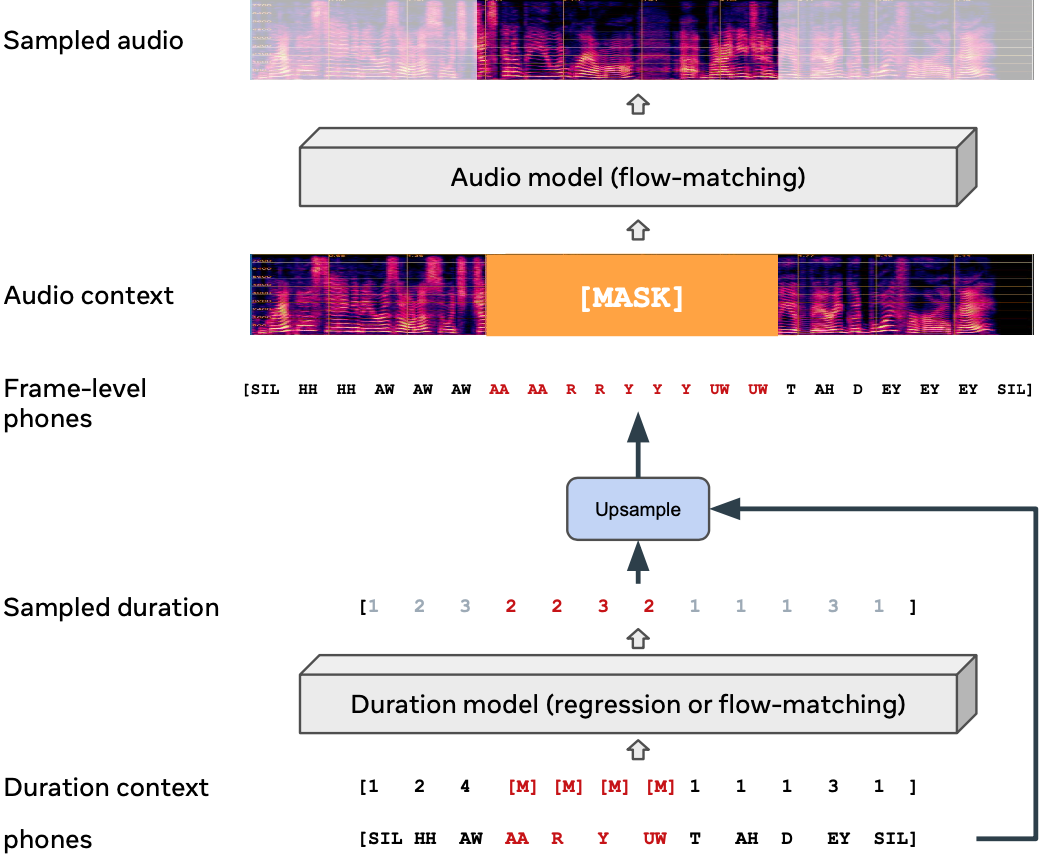
Одним из основных ограничений существующих синтезаторов речи является то, что их можно обучать только на данных, специально подготовленных для этой задачи. Расшифрованных, размеченных, проверенных. Эти входные данные (известные как «монотонные», чистые данные) трудно воспроизвести, поэтому их очень мало.
Но разработчики Meta* построили Voicebox на основе недавно предложенного метода Flow Matching — вместо обычной авторегрессивной модели. Flow Matching — последнее достижение компании Цукерберга в области неавторегрессивных генеративных ИИ. Оно позволяет изучать недетерминированное сопоставление между текстом и речью, искать в словах логику и контекст. Что позволяет Voicebox учиться на различных речевых данных без необходимости тщательно их маркировать. В результате их модель смогла обучаться на более разнообразных данных и гораздо большем их количестве.
Обычно речевые генеративные ИИ обучаются на нескольких десятках или максимум сотнях часов данных. Voicebox же учился на 60 000 часах аудиокниг на английском языке и ещё 50 000 часах аудиокниг на других языках. Разработчики также говорят, что у них самый большой дата-сет голосов в мире — в том числе из-за возможности доступа к данным социальной сети.
В документе, опубликованном Meta AI, компания утверждает, что может генерировать аудиосэмплы в 20 раз быстрее, чем VALL-E от Microsoft, и куда более разборчиво (1,9% ошибок вместо 5,9%). Также они утверждают, что по сравнению с предыдущей лучшей многоязыковой моделью YourTTS (см. GitHub) новый продукт снижает средний уровень ошибок при произношении «не английских» слов с 10,9% до 5,2%, а также увеличивает сходство звука с 0,335 до 0,481.
Джинн в бутылке

Meta* часто делает свои новые ИИ общедоступными, но не на этот раз. В компании не раскрыли, на каких материалах производилось обучение Voicebox, и пока не открыли технологию публике — потому что очень опасаются злоупотреблений. Компания боится, что система будет использоваться для изготовления «слишком реалистичных» дипфейков, и они погрязнут в череде скандалов. Возможно, Voicebox останется закрытым, пока разработчики не выпустят инструмент для выявления созданных им голосов.
Среди ограничений модели создатели отмечают, что, хотя Voicebox дает впечатляющие результаты в плане передачи звукового стиля (голос, тон, эмоции и так далее), модель не позволяет контролировать каждый атрибут в отдельности. То есть нельзя попросить модель генерировать речь, напоминающую голос одного образца, но с эмоцией из другого образца. Разработчики планируют реализовать контроль всех этих атрибутов через текстовые описания (уже всем известные промпты, как у ChatGPT) — чтобы можно было сказать "сделай то же самое, но на два тона выше" или "сделай с придыханием", или "сделай в назидательном тоне". Но это на будущее.
Пока что создатели больше всего боятся этических и юридических последствий от выпуска своего детища. С ним любой сможет создавать аудио, используя записи человеческого голоса без разрешения. Делать песни голосом Джона Леннона или заявления голосом Байдена. Можно использовать голоса политиков, умерших людей, вообще кого угодно. Право человека на свой собственный голос уходит куда-то в прошлое.
Чтобы как-то нивелировать это, в своих документах Meta* утверждает, что уже разработала модель бинарной классификации, которая сможет различать реальную речь и ту, что была сгенерирована с помощью Voicebox. Сейчас они изучают, есть ли способы обойти эту проверку. Если все будет нормально — Voicebox, возможно, смогут выпустить из бутылки.
Пока что прослушать варианты синтезированной речи можно тут. Имплементация на GitHub есть здесь. Подробное описание метода Flow Matching, которое они использовали для создания модели — в третьем разделе этого документа.
* — признана экстремистской организацией, деятельность компании запрещена в России.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
-15% на заказ любого VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Комментарии (2)

Kristaller486
27.06.2023 12:57+1Но теперь всё может быть реализовано внутри одного аддона одним энтузиастом — и совершенно бесплатно
Модель совершенно закрытая и вряд-ли будет открыта
Ничего не смущает?
berng
Репа на гите пустая