

В теории информации для сравнения распределений вероятностей используется понятие относительной энтропии. Это похоже на измерение абстрактного расстояния: если относительная энтропия между двумя распределениями равна нулю, то становится невозможно применить статистический анализ для раскрытия секрета.
Другими словами, никакое статистическое наблюдение не сможет его обнаружить. Ни человек, ни машина не сможет детектировать наличие скрытого послания внутри текста, изображения, в звукозаписи речи или другом канале коммуникации. Передача будет идеально скрыта.
В прошлом году учёные доказали, что создание такого алгоритма теоретически возможно. Это и есть математически идеальная стеганография.
Стеганография — это практика кодирования секретной информации в безобидный контент таким образом, чтобы злоумышленник (третья сторона) не догадался о наличии скрытого послания.
Таким образом можно внедрять секретные сообщения в картинки, видео, даже тексты — и спокойно выкладывать в публичный доступ, на YouTube, в эфире телевидения или даже публиковать на Хабре. А прочитать секретное сообщение сможет только получатель, который:
- знает о наличии сообщения;
- знает ключ для расшифровки (о генераторе ключа договариваются заранее)

Хотя проблема изучается давно, последние достижения в области генеративных моделей ML привели к тому, что исследователи безопасности и машинного обучения заинтересовались разработкой масштабируемых методов стеганографии.
Авторы научной статьи доказали, что процедура стеганографии является абсолютно безопасной в рамках информационно-теоретической модели стеганографии Кэчина (1998) тогда и только тогда, когда она индуцирована сцеплением.
Авторы также показали, что среди процедура является максимально эффективной тогда и только тогда, когда она индуцирована минимальным энтропийным взаимодействием/сцеплением (minimum entropy coupling).
Благодаря этим идеям появилась возможность создать первые алгоритмы стеганографии с совершенной гарантией безопасности. Кроме того, они хорошо масштабируются.
Алгоритмы кодирования и декодирования в общем виде выглядят следующим образом.
Шифрование:

Расшифровка:

Оба алгоритмы имеют схожую структуру. Первый жадно кодирует информацию об x в S, используя индуцированное апостериорное значение над X для максимизации эффективности соединения. Декодирование просто воспроизводит это апостериорное значение.
Для проверки авторы сравнили свой алгоритм с тремя современными базовыми алгоритмами:
- арифметическое кодирование;
- Meteor;
- адаптивная динамическая группировка (ADG).
В качестве каналов связи использовался контент GPT-2, WaveRNN и Image Transformer, то есть три распространённых типа коммуникации: текст, речь и изображения.
Эксперименты показали, что инновационная реализация iMEC на основе связи минимальной энтропии обеспечивает более высокую эффективность кодирования, несмотря на более жёсткие ограничения безопасности:

Расхождения Куллбэка-Лейблера между распределением стеготекста и распределением скрытого текста для каждого метода
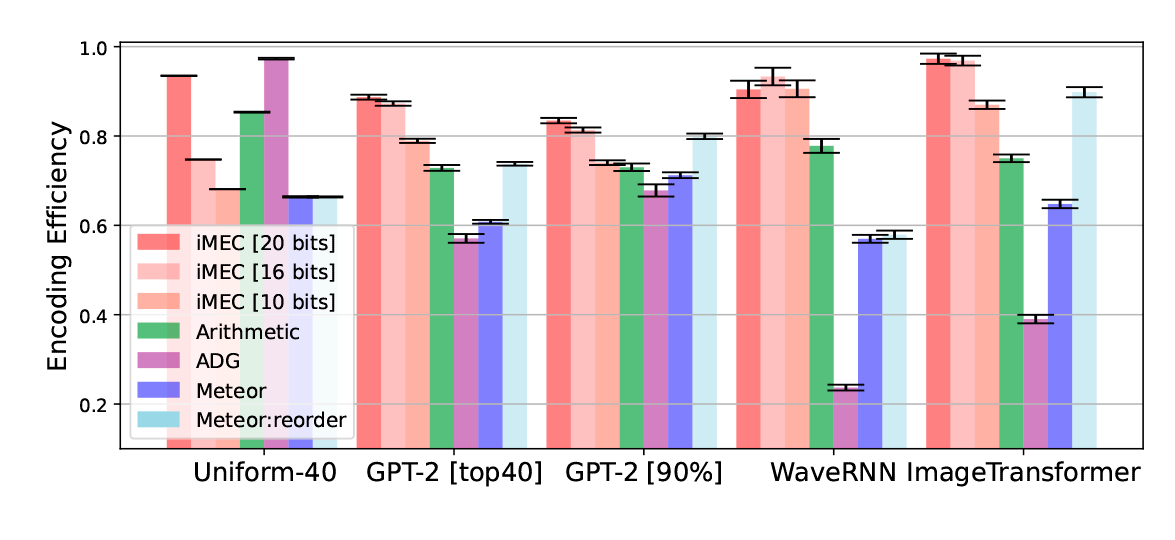
Сравнительная эффективность кодирования iMEC с базовыми методами. Каждый метод оценивается при настроенных гиперпараметрах
Все эксперименты проводились на процессоре AMD Ryzen Threadripper PRO 3955WX с 16 физическими ядрами и 2x GPU NVIDIA GeForce RTX 3090. Помимо запросов к модели, кодирование и декодирование iMEC заняли всего одно ядро CPU, в то время как арифметическое кодирование, ADG и Meteor использовали несколько CPU, а Meteor:reorder также использовал GPU во время кодирования и декодирования.

Сравнительное время кодирования стеготекста разными алгоритмами. Горизонтальные линии показывают время вывода модели для GPT-2, WaveRNN и Image Transformer
На последнем графике видно, что с увеличением размера блока iMEC скорость кодирования существенно падает.
Все шифротексты представляли собой 80-битные битовые строки, выбранные случайным образом. Эффективность шифрования определялась путём измерения количества текста, необходимого для передачи этих битовых строк. Гиперпараметры каждого метода настроены для достижения наилучшей производительности в этой задаче. Производилось по 1000 прогонов каждого алгоритма. При вычислении среднего не учитывались случаи, когда Meteor застревал в бесконечном цикле.
Таким образом, теперь доказано существование невскрываемой стеганографии при условии, что контент сгенерирован нейросетью.
Открытия в области теории информации не всегда применима в практической стеганографии, но здесь именно такой случай. Сейчас авторы работают над адаптацией алгоритмов для использования с популярными мессенджерами (WhatsApp, Signal).
Новые алгоритмы ограничены в плане размера секретного сообщения: По оценке одного из авторов научной работы, при сегодняшнем уровне развития технологий их система может скрыть файл размером 225 КБ в голосовом сообщении примерно на 30 секунд.
Нахождение самого минимального энтропийного взаимодействия — это NP-трудная задача, то есть идеальное решение требует длительных вычислений. Считается, что алгоритмов с полиномиальным временем для NP-трудных задач не существует, но это не доказано. Однако некоторые NP-трудные задачи можно полиномиально аппроксимировать до некоторого постоянного (константного) коэффициента аппроксимации. Авторам как раз удалось найти такую процедуру аппроксимации для практического применения в стеганографии.
Статья «Абсолютно безопасная стеганография с использованием минимального энтропийного взаимодействия» опубликована 22 октября 2022 года (последняя версия за 11 апреля 2023 г) на сайте препринтов arXiv.org (doi: 10.48550/arXiv.2210.14889) и представлена на конференции ICLR 2023.
Комментарии (6)

simenoff
23.07.2023 17:39+2Возможно, что противодействие стеганографии - одна из причин, почему тот же Вацап так сильно пережимает картинки и видео при пересылке?

WASD1
23.07.2023 17:39Честно говоря ни фига не понял как работает "наблюдающий знает ключ для расшифровки" и "наблюдающий знает о наличии сообщения".
Вот у нас есть картинка Pic, в которых младшие биты информации о цвете как-то распределены и текс Tex (много меньше картинки) который нам надо передать.
1. Что можно сделать - это получить новую картинку: Hide(Pic, Tex) = Pic_Tex такую, что:
а) текст Tex будет замешан в картику Pic
б) статистики распределения разных битов в картинке Pic_Tex не вызовут подозрений.2. Что мы в итоге получим:
а) Получатель может извлечь из Pic_Tex текст Tex
б) Атакующий тоже может извлечь из Pic_Tex текст Tex (если будет просто пытаться вскрывать все сообщения от подозреваемого отправителя).
3. Итак вопрос: что же всё-таки сделали (я честно не понял)?


shuhray
23.07.2023 17:39А вот знает ли кто-нибудь , этот способ записи алгоритмов (после слов "Шифрование:" и "Расшифровка:") - это что такое? Чем это набирают?

CkpytAalmar
23.07.2023 17:39Вся суть статьи: мы нашли распространненные шумные данные, среди которых можно спрятать наш шум!
Проблема в том, что нейросети сейчас УЧАТ генерировать как можно менее шумные данные.
Ибо шум обычного пользователя - раздражает.
petropavel
Я просто оставлю это здесь: тыц, тыц