
Введение
Привет!
Проектирование базы данных - это один из важнейших этапов создания информационной системы. Оно включает в себя определение сущностей, их атрибутов и связей между ними, а также выбор наиболее подходящих типов данных и ограничений целостности.
В данной статье мы рассмотрим процесс проектирования базы данных с нуля (в качестве примера возьмем только один слой БД - витринный, он же Data Mart) с использованием ПО SAP PowerDesigner (далее по тексту - PD). В качестве СУБД мы будем использовать Oracle 19c, но вы можете выбрать любую другую, по вашим потребностям (как - об этом чуть ниже).
Рассмотренный в статье инструмент будет интересен системным аналитикам, архитекторам, разработчикам БД и даже бизнес-аналитикам, поскольку, помимо создания физических и логических моделей, в нем можно рисовать ER-диаграммы, BPMN-модели и многое другое.
Подробное руководство по ПО (в том числе на русском языке): https://help.sap.com/docs/SAP_POWERDESIGNER
Где скачать?
На softoroom можно скачать данное ПО и пользоваться бесплатно для личных нужд.
Описание базовых параметров
Начнем с создания новой модели: File >> New Model >> Model types >> Physical Data Model >> Physical Diagram

В качестве DBMS (Database Management System, или СУБД) я выбрал Oracle версии 19c. В дальнейшем можно в любое время поменять тип СУБД: Database >> Change current DBMS...
Справа находится Toolbox с объектами физической диаграммы:

Ниже мы рассмотрим только те элементы, которые действительно нам могут пригодиться:
Pointer (указатель) - позволяет выделять, перемещать объекты, открывать их свойства;
Zoom In (увеличить масштаб) - в качестве аналога можно использовать CTRL + scroll;
Zoom Out (уменьшить масштаб) - в качестве аналога можно использовать CTRL + scroll;
Properties (свойства) - открывает свойства объекта, в качестве аналога можно использовать двойной щелчок ЛКМ при выбранном инструменте "Pointer";
Delete (удалить) - удаляет выбранный объект, в качестве аналога можно использовать клавишу "Delete" на выделенном объекте;
Area (область) - является абстрактным объектом, способным группировать другие объекты. Объекты не принадлежат к области и только группируются в ней;
Table (таблица) - создает таблицу в модели;
View (представление) - создает представление (view) в модели;
Reference (ссылка) - создает связь объектов между собой;
Procedure (процедура) - позволяет создать процедуру или функцию для любого объекта (например, для наполнения данными);
Note (заметка) - создает объект-заметку, содержащий произвольный текст;
Title (заголовок) - создает заголовок модели;
Text (текст) - добавляет произвольный текст без рамок;
Line (линия) - создает прямую линию для связи объектов без создания reference;
Arc (дуга) - создает кривую линию для связи объектов без создания reference.
Создаем объект - таблицу, с использованием соответствующего инструмента из Toolbox. Открываем свойства таблицы:

Вкладка General:
В поле
Nameвписывается название таблицы.По умолчанию в поле
Codeпроливается то же самое значение, что и вName. При необходимости сделать кодовое наименование отличающимся от физического наименования необходимо нажать на иконку=справа.В поле
Commentвписывается комментарий к таблице. Комментарий будет отображаться в метаданных таблицы.В поле
Ownerнеобходимо выбрать пользователя (схему), где таблица будет расположена. Чтобы создать нового пользователя, необходимо справа нажать на иконкуCreate- откроется окно со свойствами пользователя и вкладкой General:

В поле
Nameвписывается логин пользователя, полеCodeзаполнится автоматически.В поле
Commentможно добавить комментарий. Например, что данный пользователь будет содержать таблицы витринного слоя.-
В поле
Identification typeможно выбрать тип авторизации для подключения под выбранным пользователем:By - пользователь идентифицируется на основе имени пользователя и пароля, которые хранятся в базе данных (необходимо заполнить поле Password);
Externally - пользователь идентифицируется на основе своей учетной записи в операционной системе;
Globally - пользователь идентифицируется на основе глобальной учетной записи, которая может использоваться для доступа к нескольким базам данных в сети.
Переходим на вкладку
Privilegesи через иконкуAdd Privilegesвыбираем необходимые доступы.На вкладке
Permissionsможно задать разрешения к другим объектам - на select, delete, insert, update и т.п.На вкладке
Optionsможно задать tablespace (логическая область хранения данных, размер которой ограничен размером жесткого диска).На вкладке
Previewможно посмотреть SQL-скрипт, который генерируется на основе заполненных параметров.

-
В поле
Dimensional typeвыбираем тип измерения для создаваемой таблицы:Fact - содержат фактические данные, такие как продажи, количество, доход и т.д. Они связаны с таблицами измерений через ключи, которые являются общими полями между таблицами.
Dimension - содержат информацию о измерениях, которые используются для анализа фактических данных. Например, имя покупателя может являться атрибутом в таблице измерений покупателей, а наименование товара, — в таблице измерений товаров.
Переходим на вкладку Columns:

В поле
Nameвписывается название атрибута, полеCodeзаполнится автоматически.В поле
Data Typeвыбирается тип данных из списка.Поле
Pявляется флагом для параметра Primary Key.Поле
Domainопределяет тип данных, длину, разрядность, обязательность, параметры проверки и бизнес-правила, и может применяться к нескольким столбцам. Домены можно определять для столбцов типа "ид.", "имя", "адрес" или любого другого типа данных, использование которых требуется стандартизировать для нескольких столбцов вашей модели. Выбрать можно только существующий домен, новый требуется создавать отдельно.Поле
Fявляется флагом для параметра Foreign Key. Назначить атрибут внешним ключом можно через объектReference(отдельно), либо через вкладкуKeys.Поле
Mявляется флагом для параметра Mandatory (признак обязательности заполнения). При заполненном PK проставляется автоматически и не может быть изменен для данного атрибута.
На вкладке Indexes, при необходимости, можно проиндексировать все необходимые атрибуты таблицы.


На вкладке Keys отображаются все ключи таблицы. При необходимости, их можно отредактировать или дополнить таблицу новыми.
На вкладке Triggers, при необходимости, можно создать триггер, который будет автоматически выполняться при соблюдении заданного условия.
На вкладке Partitions, при необходимости, можно задать партиционирование для таблицы. Данную вкладку мы подробно рассмотрим позднее.
На вкладке Database Packages, при необходимости, можно создать пакет с процедурами/функциями. Данную вкладку мы подробно рассмотрим позднее.
Импорт из Excel
А теперь жизненная ситуация: допустим, у вас уже есть список таблиц и атрибутов в excel (например, в листах спецификаций). Перебивать все руками - слишком долго и мучительно. Тут на помощь приходит встроенный модуль ExcelImport.
Для начала необходимо создать файл импорта в модели, с помощью которого будем загружать excel-файлы: Model >> Extensions... >> Attach an Extension >> Import >> Excel import >> OK


Далее в Object Browser (панель слева): ПКМ на модели >> Import Excel File... >> Options... >> ДА
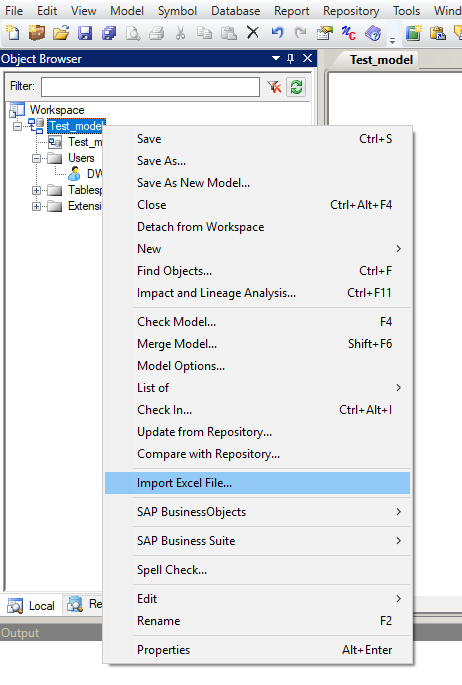
 и create symbols in active diagram (визуально отобразит загруженные объекты в модели) и нажимаем ОК.")
Теперь мы готовы импортировать excel-файл. Но для начала необходимо его подготовить, чтобы PD смог корректно распознать в нем данные:
Создаем файл с расширением .xlsx с произвольным названием;
Создаем 2 листа:
TableиTable.ColumnНа листе
Tableпрописываем атрибуты:Owner(схема),Name(название таблицы),Code(код таблицы),Comment(комментарий к таблице),Dimensional Type(тип измерения);На листе
Table.Columnпрописываем атрибуты:Parent(название таблицы),Name(название атрибута),Code(код атрибута),Comment(комментарий к атрибуту),Data Type(тип данных с указанием размерности),Primary(признак первичного ключа таблицы),Mandatory(признак обязательности заполнения атрибута).Наполняем оба листа данными и сохраняем файл.


Возвращаемся в интерфейс PD, нажимаем иконку Select File и выбираем файл, который мы подготовили выше.
Если импорт прошел успешно - появится всплывающее окно с заголовком "import complete", а также информация о предупреждениях, если что-то не удалось корректно распознать и импортировать. В случае неуспеха - появится соответствующее всплывающее окно. Подробную информацию по ошибкам и предупреждениям можно посмотреть в логах в блоке Output (внизу).

Замечания:
1. В дальнейшем нам не нужно будет заново создавать файл импорта для загрузки того же самого документа - он сохранится, и функция
Import Excel File...будет доступна.2. Если вы хотите загрузить excel-файл с другими наименованиями атрибутов - функция
Auto-map columns to propertiesне сработает, с нее нужно будет убрать галочку и выполнить mapping атрибутов по листам вручную во всплывающих окнах.
Связи таблиц
Теперь, когда у нас есть модель, состоящая из нескольких таблиц, требуется проставить связи между таблицами. Для это воспользуемся параметром Reference из правого Toolbox и проведем линию между таблицами, которые хотим связать:

Двойной клик по линии связи открывает ее свойства на вкладке General. Кроме этого, связь появилась и в Object Browser слева в папке References. В свойствах можно увидеть, какая таблица стала родительской, а какая - дочерней.
Стрелка связи должна идти от родительской таблицы к дочерней, если у вас получилось наоборот - можно в этих же свойствах поменять их местами (параметры
Parent tableиChild tableна вкладке General).

На вкладке Integrity можно настроить такие параметры, как Constraint name для нового ключа, Cardinality (тип отношения между таблицами), условие при удалении констреинта (например, удалять каскадно во всех связанных таблицах или только в текущей).
Если вы внимательный, то уже давно заметили, что в справочнике типов заказов не хватает первичного ключа. Т.к. в импортируемом экселе этот параметр не был выбран, мы исправим это руками в интерфейсе - просто в свойствах на вкладке Columns проставим галочку в атрибуте
Primary.
Настройка партиционирования
Теперь настроим партиционирование в таблице FCT_SALES. Идем в свойствах таблицы на вкладку Partitions, видим следующие типы:
Range (партиционирование по диапазону) - данные разбиваются на партиции по заданному диапазону значений в определенном столбце таблицы;
Composite (комбинированное партиционирование) - комбинация двух или более методов партиционирования для улучшения производительности запросов;
Hash (хэш-партиционирование) - данные разбиваются на партиции по хэш-функции, которая определяет номер партиции для каждой строки;
List (партиционирование по списку) - данные разбиваются на партиции по заданному списку значений в определенном столбце таблицы;
Reference (ссылочное партиционирование) - партиционирование на основе связей между таблицами, где данные в одной таблице разбиваются на партиции, соответствующие данным в другой таблице;
System (системное партиционирование) - специальный вид партиционирования, который используется для управления метаданными и системными таблицами в базе данных Oracle. Этот вид партиционирования не предназначен для обычных пользовательских таблиц и используется только для внутренних нужд системы.
Мы будем создавать интервальные партиции по полю SALE_DT, для этого:
Выбираем тип
RangePartitioning;В поле
Column listвписываем наш атрибут SALE_DT;Задаем необходимый интервал, допустим, месячный. Выбираем параметр
Define intervalи в полеExpressionвписываем значение:NUMTOYMINTERVAL(1,'MONTH');Создаем начальную (граничную) партицию, которая будет содержать архивные данные. Для этого выбираем
Insert a Row >> Properties. В полеPartitionзадаем название начальной партиции - например, PARTMM_0. В полеRange partition descвписываем:values less than (TO_DATE('2021-01-01 00:00:00', 'YYYY-MM-DD HH24:mi:SS', 'NLS_CALENDAR=GREGORIAN'))Нажимаем
Применитьдля сохранения изменений.

Создание пакета (Package)
Поскольку в примере мы проектируем витринный слой, помимо него в БД должен быть слой оперативных данных и/или слой детальных данных, из которого с помощью ETL-процесса можно наполнить данными наши витрины. Предположим, что данные мы возьмем из оперативного слоя ODS.
Возвращаемся в свойства таблицы и идем на вкладку Database Packages. Ранее мы не создавали пакеты, поэтому выбираем Create an Object.

На вкладке General мы задаем параметры Name и Owner и переходим ко вкладке Procedures, где мы создадим процедуру, наполняющую нашу таблицу. На данной вкладке аналогично выбираем Create an Object, в открывшемся окне на вкладке General задаем параметры Name и Type = "Procedure".

Переходим во вкладку Body. Здесь у нас располагается тело процедуры между ключевыми словами begin и end.

После сохранения всех изменений в окне свойств пакета переходим на вкладку Preview и смотрим на финальный вид скрипта для проверки его корректности:

Для остальных объектов создавать пакеты мы не будем, одного вполне достаточно для наглядной демонстрации функционала.
Генерация скрипта
Теперь мы готовы к тому, чтобы экспортировать скрипт для формирования нашего слоя. На верхней панели выбираем: Database >> Generate Database...
На вкладке General указываем путь, по которому будет сгенерирован SQL-файл, и его название.

Для базовой генерации этого достаточно, но если нужно кастомизировать - можно поиграться с настройками. Например, чтобы каждый объект генерировался в отдельный файл, достаточно убрать галочку с параметра One file only. Параметр Check model автоматически проверяет модель на предмет ошибок, и, в случае обнаружения критичных, выдает лог с указанием на проблемные места, файл при этом не создастся. Не рекомендую отключать данный параметр во избежание генерации некорретных скриптов.
На вкладке Format можно настроить такие параметры, как Owner prefix (префикс схемы), Title (комментарии по коду с заголовками) и даже Character case (регистр символов в коде). На вкладке Selection можно выбрать конкретные объекты модели, если вам не требуется генерация всего скоупа.

Представим ситуацию, что у вас тестовая среда, и вам необходимо сгенерировать туда произвольные данные. PowerDesigner с этим тоже поможет: Database >> Generate Test Data...
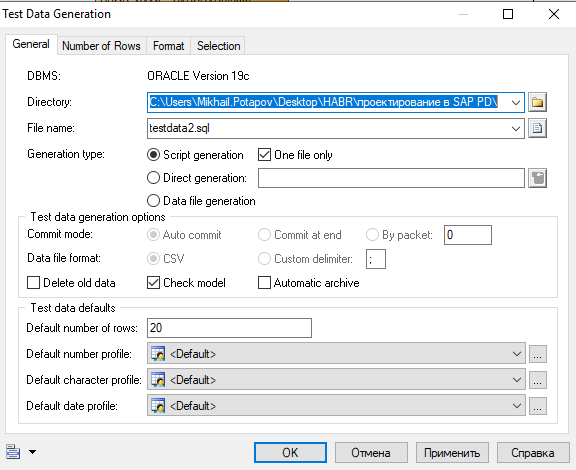
Помимо стандартного выбора пути и названия файла, здесь можно задать и другие интересные функции. Например, задать необходимое количество строк для всех таблиц. В параметрах Default number profile, Default character profile и Default data profile можно задать определенные значения или интервалы значений, если это необходимо. Если вам нужно в каждой таблице задать свое количество записей - на вкладке Number of Rows можно это сделать.
Сохранение
Ну и финально - про сохранение. Сохранить файл с моделью в формате .pdm можно стандартно через: File >> Save As...
Если сохранить нужно в другом формате - например, изображением в .png, то тогда нужно выделить все объекты визуальной модели (CTRL+A) и далее: Edit >> Export Image...
Заключение
Как мы убедились из описания выше, инструмент достаточно многофункциональный, а затронули мы лишь малую часть его возможностей. К сожалению, все функции описать в одной статье не получится, поэтому не бойтесь изучать его самостоятельно. Если у вас был опыт взаимодействия с данным ПО - поделитесь своим опытом и мнением в комментариях.
oragraf
Есть книга неплохая Анны Нартовой по PD. Можно найти в инете.
инструмент, имхо, лучший, но очень велик. Мало кто использует его хотя бы наполовину.
ценник на него конский, но сейчас "все сложно". Имхо, для sap было бы лучше выложить его в opensource. А то есть ощущение, что инструмент умирает.
Mi_Potapov Автор
Спасибо за книгу. Инструмент, действительно, лучший, я даже не знаю подобных аналогов, а уж "импортозамещенных" - и подавно нет.
Если разработчики выложат этот софт в open-source, то свой продукт точно похоронят - у сторонних разработчиков появится отличная возможность взять best practice продукта и сделать его еще лучше. Т.е. буквально сами себе создадут конкурентов, которых сейчас на рынке нет.