

В последнее время я усиленно занимался изучением Rust, и как любой разумный человек после написания 100 строк различных программ решил взяться за более амбициозный проект. В итоге я написал на этом языке Java Virtual Machine, которую без лишней оригинальности назвал
rjvm.Весь код доступен на GitHub.
Я хочу подчеркнуть, что это лишь упрощённая JVM, созданная в образовательных целях, а не в качестве серьёзной реализации. В частности, она не поддерживает:
- обобщения;
- потоки;
- отражение;
- аннотации;
- ввод-вывод;
- JIT-компилятор;
- пул строк.
Тем не менее я реализовал в ней ряд весьма нетривиальных вещей:
- инструкции потока управления (
if,for, ...); - создание примитивов и объектов;
- вызов виртуальных и статических методов;
- исключения;
- сбор мусора;
- разрешение классов из файла
jar.
Например, вот код, который является частью набора тестов:
class StackTracePrinting {
public static void main(String[] args) {
Throwable ex = new Exception();
StackTraceElement[] stackTrace = ex.getStackTrace();
for (StackTraceElement element : stackTrace) {
tempPrint(
element.getClassName() + "::" + element.getMethodName() + " - " +
element.getFileName() + ":" + element.getLineNumber());
}
}
// Используется вместо System.out.println ввиду отсутствия реального ввода-вывода
private static native void tempPrint(String value);
}Я использую реальный
rt.jar, содержащий классы из OpenJDK 7 — то есть класс java.lang.StackTraceElement в примере выше взят из реального JDK!Сразу скажу, что рад всем полученным в процессе знаниям — о Rust и о реализации виртуальной машины. В частности, я очень доволен тем, что смог реализовать реальный, рабочий сборщик мусора. Он довольно посредственный, но он мой, и я им доволен. Учитывая, что мне удалось достичь всех поставленных изначально целей, я решил на этом проект завершить. Знаю, он не лишён ошибок, но исправлять их я не стану.
Обзор темы
В этой статье я в общих чертах расскажу, как работает моя JVM, а в последующих публикациях я более углублённо раскрою некоторые из описанных здесь аспектов.
▍ Организация кода
Код представляет собой типичный проект Rust. Я разделил его на три крейта (то есть пакета):
-
reader, способный считывать файлы.classи содержащий различные типы, моделирующие их содержимое; -
vm, содержащий виртуальную машину, которая может выполнять код как библиотеку; -
vm_cli, содержащий очень простой лаунчер командной строки для запуска виртуальной машины в духе исполняемого файла java.
Я планирую перенести крейт
reader в отдельный репозиторий и опубликовать его на crates.io, поскольку он вполне может пригодиться кому-то ещё.▍ Парсинг файла .class
Как вам известно, Java — это компилируемый язык. Компилятор
javac получает исходные файлы .java и создаёт из них различные файлы .class, распределяемые в файле .jar, представляющем обычный архив zip. Таким образом, первым делом при выполнении кода Java загружается файл .class, содержащий сгенерированный компилятором байткод. При этом файл классов содержит различные компоненты:- метаданные класса, например, его название или имя исходного файла;
- имя суперкласса;
- реализованные интерфейсы;
- поля вместе с их типами и аннотациями;
- методы:
- с их дескриптором, то есть строкой, представляющей тип каждого параметра и тип, возвращаемый методом;
- с метаданными, такими как условие
throws, аннотация и информация об обобщениях; - с байткодом и дополнительными метаданными, такими как таблица обработчика исключений и таблица нумерации строк.
rjvm я создал отдельный файл под названием reader, который может парсить файл класса и возвращать структуру Rust, моделирующую класс и его содержимое.▍ Исполнение методов
Основной API крейта
vm — это Vm::invoke, который используется для выполнения метода. Он получает CallStack, содержащий различные CallFrame, по одному для каждого выполняемого метода. Изначально перед выполнением main стек вызовов является пустым, и при его запуске создаётся новый фрейм. Далее вызов каждой функции приводит к добавлению в стек очередного фрейма. Когда выполнение метода завершается, соответствующий ему фрейм из стека вызовов удаляется.Большинство методов реализованы на Java, поэтому будет выполняться их байткод. Тем не менее
rjvm также поддерживает нативные методы, то есть реализуемые непосредственно JVM, а не являющиеся частью байткода Java. В нижних частях Java API, где требуется взаимодействие с операционной системой (например, для ввода-вывода) или поддержка среды выполнения, их присутствует немало. К возможно известным вам примерам именно поддержки среды выполнения относятся System::currentTimeMillis, System::arraycopy или Throwable::fillInStackTrace. В rjvm они реализуются функциями Rust.JVM является виртуальной машиной на основе стека, то есть инструкции байткода работают в основном со стеком значений. Здесь также присутствует набор локальных переменных, идентифицируемых по индексу, которые можно использовать для хранения значений и передачи аргументов методам. Они ассоциируются с каждым фреймом в
rjvm.▍ Моделирование значений и объектов
Тип
Value моделирует возможное значение локальной переменной, элемента стека или поля объекта и реализуется так:/// Моделирует обобщённое значение, которое может сохраняться в локальной переменной или стеке.
#[derive(Debug, Default, Clone, PartialEq)]
pub enum Value<'a> {
/// Неинициализированный элемент. Никогда не должен находиться в стеке, но является предустановленным состоянием локальных переменных.
#[default]
Uninitialized,
/// Моделирует все типы до 32 бит включительно в jvm: `boolean`,
/// `byte`, `char`, `short` и `int`.
Int(i32),
/// Моделирует значение `long`.
Long(i64),
/// Моделирует значение `float`.
Float(f32),
/// Моделирует значение `double`.
Double(f64),
/// Моделирует значение объекта.
Object(AbstractObject<'a>),
/// Моделирует нулевой объект.
Null,
}Кстати, это одно из мест, где тип-сумма, например
enum в Rust, выступает прекрасной абстракцией — он отлично подходит для отражения того факта, что значение может иметь несколько разных типов.Для хранения объектов и их значений изначально я использовал простую структуру
Object, содержащую ссылку на класс (для моделирования типа объекта) и Vec‹Value› для хранения значений полей. Тем не менее, когда я реализовал сборщик мусора, то изменил его на использование низкоуровневой реализации со множеством указателей и приведений типов — прямо в стиле Си. В текущей реализации AbstractObject (моделирующий «реальный» объект или массив) является просто указателем на массив байтов, который содержит пару слов заголовка, сопровождаемые значениями полей.▍ Выполнение инструкций
Выполнение метода означает выполнение его инструкций байткода, по одной за раз. JVM содержит обширный список закодированных в байткоде инструкций (более двухсот), каждая по одному байту. Многие инструкции сопровождаются аргументами, а некоторые имеют переменную длину. Всё это моделируется в коде типом
Instruction:/// Представляет инструкцию байткода Java.
#[derive(Clone, Copy, Debug, Eq, PartialEq)]
pub enum Instruction {
Aaload,
Aastore,
Aconst_null,
Aload(u8),
// ...Как говорилось выше, при выполнении метода поддерживается стек и массив локальных переменных, на которые инструкции ссылаются по их индексу. Его выполнение также инициализирует счётчик инструкций на нуль — то есть адрес очередной инструкции для выполнения. После обработки инструкции счётчик обновляется, обычно увеличиваясь на один. Но иногда различные инструкции перехода могут перемещать его к другой области.
Подобные переходы используются для реализации всех операций потока управления, таких как
if, for или while.К особому семейству относятся инструкции, которые могут вызывать другой метод. Существуют различные способы разрешения метода
which, который должен быть вызван: основные — это виртуальный или статический, но есть и другие. После разрешения корректной инструкции rjvm добавит новый фрейм в стек вызовов и запустит выполнение метода. Возвращаемое методом значение будет передано в стек, если не окажется void, и выполнение продолжится.Формат байткода Java довольно интересен, и я планирую посвятить отдельный пост различным видам инструкций.
▍ Исключения
Исключения являются довольно сложным элементом в реализации, поскольку разрывают стандартный поток управления и могут приводить к раннему возвращению методом результата (и распространяться на стек вызовов). Хотя я доволен тем, как мне удалось их реализовать, и покажу вам часть соответствующего кода.
Первым делом вам нужно знать, что любой блок
catch соответствует записи таблицы исключений метода — каждая запись содержит диапазон охватываемых счётчиков инструкций, адрес первой инструкции в блоке catch и имя класса исключения, которое блок перехватывает.Сигнатура
CallFrame::execute_instruction выглядит так:fn execute_instruction(
&mut self,
vm: &mut Vm<'a>,
call_stack: &mut CallStack<'a>,
instruction: Instruction,
) -> Result<InstructionCompleted<'a>, MethodCallFailed<'a>>Где типами выступают:
/// Возможный результат выполнения инструкции
enum InstructionCompleted<'a> {
/// Указывает, что выполненная инструкция являлась инструкцией возвращения.
/// Вызывающий должен прекратить выполнение метода и вернуть значение.
ReturnFromMethod(Option<Value<'a>>),
/// Указывает, что инструкция не являлась return, а значит выполнение должно
/// продолжиться с инструкции, обозначенной счётчиком.
ContinueMethodExecution,
}
/// Моделирует факт провала выполнения метода.
pub enum MethodCallFailed<'a> {
InternalError(VmError),
ExceptionThrown(JavaException<'a>),
}И стандартный тип
Result в Rust:enum Result<T, E> {
Ok(T),
Err(E),
}Таким образом, выполнение инструкции может привести к четырём возможным состояниям:
- инструкция завершена успешно и выполнение текущего метода может продолжаться (стандартный случай);
- инструкция завершена успешно и оказалась инструкцией возврата, значит, текущий метод должен вернуть (не обязательно) возвращаемое значение;
- выполнить инструкцию не удалось из-за внутренней ошибки VM;
- выполнить инструкцию не удалось из-за возникновения стандартного исключения Java.
Код, выполняющий метод, выглядит так:
/// Выполняет весь метод.
impl<'a> CallFrame<'a> {
pub fn execute(
&mut self,
vm: &mut Vm<'a>,
call_stack: &mut CallStack<'a>,
) -> MethodCallResult<'a> {
self.debug_start_execution();
loop {
let executed_instruction_pc = self.pc;
let (instruction, new_address) =
Instruction::parse(
self.code,
executed_instruction_pc.0.into_usize_safe()
).map_err(|_| MethodCallFailed::InternalError(
VmError::ValidationException)
)?;
self.debug_print_status(&instruction);
// Перемещение pc к следующей инструкции без её выполнения, поскольку нам нужно перейти (goto) к другой области.
self.pc = ProgramCounter(new_address as u16);
let instruction_result =
self.execute_instruction(vm, call_stack, instruction);
match instruction_result {
Ok(ReturnFromMethod(return_value)) => return Ok(return_value),
Ok(ContinueMethodExecution) => { /* продолжение цикла */ }
Err(MethodCallFailed::InternalError(err)) => {
return Err(MethodCallFailed::InternalError(err))
}
Err(MethodCallFailed::ExceptionThrown(exception)) => {
let exception_handler = self.find_exception_handler(
vm,
call_stack,
executed_instruction_pc,
&exception,
);
match exception_handler {
Err(err) => return Err(err),
Ok(None) => {
// Выброс исключения вызывающему
return Err(MethodCallFailed::ExceptionThrown(exception));
}
Ok(Some(catch_handler_pc)) => {
// Повторная передача исключения в стек и продолжение выполнения этого метода с обработчика перехватов.
self.stack.push(Value::Object(exception.0))?;
self.pc = catch_handler_pc;
}
}
}
}
}
}
}Я знаю, что в этом коде довольно много деталей реализации, но надеюсь, по нему ясно, что использование
Result и сопоставления шаблонов прекрасно соответствует описанному выше поведению. Должен сказать, что весьма горжусь этим кодом.▍ Сбор мусора
Заключительным этапом создания
rjvm стала реализация сборщика мусора. Для этого я выбрал алгоритм копирующего сборщика (semispace copying collector) с приостановкой выполнения. Я воссоздал упрощённый вариант алгоритма Чини, но мне всё же стоит реализовать что-то посерьёзней. Идея состоит в разделении доступной памяти на две части, называемые полупространствами — одно выступает активным и служит для выделения объектов, а второе находится в резерве. После заполнения первого запускается сбор мусора, и все действующие объекты копируются во второе. Затем все ссылки на объекты обновляются. Наконец, два этих полупространства меняются ролями — по аналогии с тем, как работает blue-green deployment*.
*Blue-green deployment — технология развёртывания обновлений и исправлений приложения без перерыва в обслуживании клиентов.

Начало
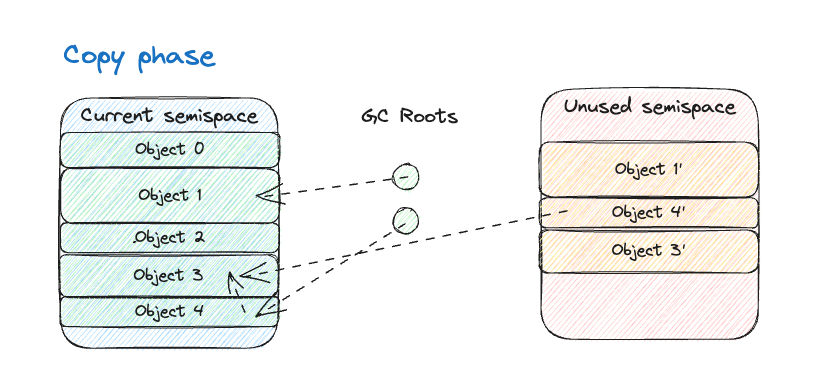
Фаза копирования

Исправление ссылок

Смена ролей подпространств
Для этого алгоритма характерны следующие особенности:
- очевидно, что он тратит впустую много памяти (половину возможного максимума);
- выделение происходит очень быстро (смещение указателя);
- копирование и сжатие объектов исключает необходимость обработки фрагментации памяти;
- сжатие объектов может повышать быстродействие ввиду более эффективного использования кэш-линий.
В настоящих виртуальных машинах Java используются более сложные алгоритмы. Обычно это сборщики мусора, учитывающие поколения объектов, такие как G1 или параллельный GC, который задействует более продвинутую стратегию копирования.
Заключение
В процессе написания rjvm я узнал много нового и вдоволь поразвлёкся. Что ещё можно пожелать от любительского проекта? Хотя, пожалуй, в следующий раз для освоения нового языка я выберу менее амбициозную задачу.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх ????️

dopusteam
https://habr.com/ru/companies/otus/articles/755946/
Как будто бы уже было)