
«Зацепила» крайняя статья про многопоточность [1]. Но, с другой стороны, — а что ожидал автор, предложив исходное решение без синхронизации? Получил то, что и должен был получить. На другое рассчитывать было бы достаточно наивно. Во‑первых, потому, что используется весьма проблемная модель параллелизма. Во‑вторых, расплывчатое представление о решаемой проблеме (по крайней мере, если судить по описанию). Но это уже мое личное мнение и хотелось бы его пояснить. И не просто так, а подкрепив решением.
Имеем счетчик. Только это уже не просто счетчик, а общий ресурс, с которому пытаются получить доступ множество параллельных процессов. Налицо некая общая проблема, с которой приходится сталкиваться на практике. Тут можно добавить, что проблема эта давняя, рассматривалась не раз и ее решений предлагалось множество.
Но, может, автор достиг чего‑то нового? Да, вроде, нет. То, что нужно синхронизировать — не новость. Нов ли предложенный механизм синхронизации? Не знаю, поскольку не специалист в Python. Надеюсь такие найдутся и ответят на этот вопрос.
Покажу, как подобные проблемы решаю я. Причем совсем не прибегая ни к многопоточности, ни к всему тому, что нынче на волне успеха в так называемом параллельном программировании. И, как сказал автор статьи, «не спешите закрывать вкладку», а посмотрите, что будет дальше. А вдруг вам понравится?
Но для начала...
Краткая история вопроса
Использование переменной‑счетчика в качестве общего ресурса — отнюдь не новость. Это элементарный и естественный подход к демонстрации проблем множества параллельных процессов. Насколько я припоминаю, впервые с подобным примером в серьезной литературе я столкнулся в книге [2].Предлагаемые там решения не вызвали восторга, а потому были задвинуты. И, кстати, об этом я не испытываю сожаления.
Несколько иной более формализованный взгляд на работу с общим ресурсом и все с тем же счетчиком (при рассмотрении проблем работы с общей памятью) представлен в [3]. Но опять же, он принципиально не отличался от упомянутого, а потому также не был взят на вооружение.
Перечисленные источники убеждают, что минимум уже лет этак 50 тому назад эти проблемы были известны, как и их рассмотрение и решения в рамках столь популярных нынче потоков и сопрограмм (тьфу‑тьфу, корутин). Получается, что годы летят, а проблемы у потоков как были, так и остались. Что‑что, а именно это автору статьи показать удалось достаточно убедительно. Но только надо ли было тратить время на демонстрацию того, что было известно и до этого?
Тем не менее, я даже соглашусь с тем, что статья не бесполезна, т.к. послужила триггером к написанию статьи, в которой я представлю альтернативный подход к решению подобных проблем. Альтернативы, ставшей результатом капризного взгляда автора на подобные многопоточные решения.
Автоматная модель доступа к общему ресурсу
Сначала рассмотрим самый простой вариант — счетчик и один процесс. В формализованном виде это представлено на рис. 1. Здесь X, N и counter - глобальные переменные, .cnt, .n — локальные переменные процесса, где X — число наращиваний счетчика, N - максимальное значение задержки перехода из состояния в состояние. При этом counter - собственно счетчик, .cnt — локальный счетчик процесса, .n — конкретное значение задержки. При N=0 задержка на переходе не формируется.
В состоянии s1, которое одновременно считается и начальным состоянием автомата, происходит подсчет циклов изменения счетчика. Когда количество циклов станет равным заданному, происходит переход в заключительное состояние s0.
Чтобы упростить модель, мы схитрили. Даже дважды. Во‑первых, нет действий сбросу/установки переменных. Это делает среда при запуске проекта. Во‑вторых, зная, что последовательность запуска формально параллельных действий (параллельными считаются множество действий, помечающих один переход) определяется их номером, мы упростили цикл наращивания счетчика до петли при состоянии.
Поясним последнее. Если следовать отмеченному выше порядку действий, то на самом деле сначала выполняется наращивание внутреннего счетчика циклов — действие y1, затем наращивание внешнего счетчика — y2, после этого вычисляется текущее значение задержки — y3 и затем реализуется сама задержка — y4. Собственно параллельными можно считать в полной мере только действия y1 и y2. Они в свою очередь могут исполнятся параллельно действиям y3, y4. Последние по отношению друг к другу последовательны. Все это можно было бы описать в явной форме, но автомат стал бы при этом несколько сложнее.
Задержка введена, чтобы смоделировать скорость процессов, что влияет на моменты обращения к общему ресурсу. Изменяя значение N можно моделировать «разнобой» в поведении процессов.

В окончательном виде приложение состоит из множества подобных процессов. Структурная схема решения, состоящего из 10-ти процессов, приведена на рис. 2.

На рис. 3 приведен вид решения в среде ВКПа (среда автоматного Визуального Компонентного Программирования). В данном случае представлены три окна среды - два прикладных, как примеры реализации двух выбранных процессов, и стандартное окно среды, отражающее глобальные переменные приложения и множество прикладных процессов.

В окне переменных подчеркиванием выделен наш общий ресурс — переменная counter и ее свойство — посл. тип. Свойство, как мы увидим далее, определит режим работы процессов с данной переменной. Если флаг взведен, то процесс будет работать с переменной в обычном последовательном режиме. А это означает, что изменение переменной будет отражено ровно в момент изменения ее прикладным процессом. Если флаг сброшен, то новое значение переменной будет помещено в теневую переменную и станет ее текущим значением только в конце дискретного такта, когда все процессы уже завершат работу с переменными на текущем дискретном такте.
Результаты тестирования
Для начала рассмотрим чисто параллельный режим работы процессов, когда общий ресурс работает в режиме переменной параллельного типа (флаг посл.тип сброшен). При N=0, когда все процессы абсолютно одинаковы значение counter будет равно числу изменений счетчика X. И это верно, т.к. параллельные процессы, работая синхронно, считывают в какой‑то момент текущее значение общего ресурса (оно для всех процессов будет одно и то же) и наращивают его. Но это новое значение ресурса станет текущим лишь в конце дискретного такта. Поэтому на текущем такте значение ресурса будет увеличено лишь на единицу, несмотря на то, что множество процессов будут пытаться проделать эту операцию одновременно.
Изменим значение N, оставив режим работы с ресурсом прежним. Мы сразу увидим результат: значение ресурса будет больше X, но меньше или равно X*К, где K — число процессов. При этом чем больше будет N, тем ближе будет значение счетчика к максимальному значению, но при соответствующем увеличении времени работы (когда все процессы попадут в состояние s0). Так мы сымитировали разнобой в поведении процессов. Заметим, что мы одновременно показали режим работы с памятью типа CRCW — параллельная запись/параллельное чтение (подробнее см.[4]).
Изменим тип ресурса на последовательный, когда флаг посл.тип взведен. Значение счетчика станет равным максимальному значению, т. е. counter = X*K. В этом случае любой параллельный процесс, получив доступ к ресурсу, изменяет его и это новое значение становится мгновенно текущим значением ресурса. Следующий процесс получит уже новое значение и также увеличивает его и т. д. При этом изменение значения N не повлияет на результат, а лишь увеличит время работы.
Выше было показано, что программировать параллельно можно, не используя при этом потоки. Но если все же к ним тянет, то есть и более детальное их описание, как, например, в [5]. Ну, а когда начитаетесь, то не забудьте просмотреть статью [6]. А, может, даже лучше с нее и начать? Ведь за последние почти 20 лет, т. е. с момента написания данной работы, проблем у потоков меньше не стало.
Нет правил без исключений
Казалось бы в параллельном программировании все должно быть параллельным без исключения. К процессам это относится в полной мере, но в их работе с памятью есть все же нюансы. Они отражены в режимах работы с памятью [4]. Рассматриваются обычно четыре режима и распространяются они на всю память. Но иногда желательно уметь задавать режим для отдельной области памяти. В ВКПа это можно делать вплоть до переменной. Выше мы это и продемонстрировали. Это значительно позволяет упростить алгоритм. Но пользоваться такой возможностью надо осторожно, чтобы не повлиять на само правило — выбранную концепцию параллелизма.
PS
Отвечая на ... "Вопрос: какое значение счетчика выведет программа?" из статьи [1] я бы ответил так:
Ответ:
Если все процессы абсолютно одинаковы (а это так, исходя из кода программы), если они параллельны (будем считать, что это так), если запись и чтение счетчика также выполняются параллельно (это тоже должно быть так), то значение счетчика будет равно X (в статье это значение переменной operationsPerThreadCount).
Литература
Многопоточность в Python: очевидное и невероятное. [Электронный ресурс], Режим доступа: https://habr.com/ru/articles/764420/ свободный. Яз. рус. (дата обращения 05.10.2023).
Шоу А. Логическое проектирование операционных систем: Пер. с англ. – М.: Мир, 1981. – 360 с.
Хоар Ч. Взаимодействующие последовательные процессы: Пер. с англ. – М.: Мир, 1989. 264 с.
Дж.Макконелл Анализ алгоритмов. Вводный курс. – М.: Техносфера, 2002. – 304 с.
Multithreading. [Электронный ресурс], Режим доступа: https://habr.com/ru/companies/otus/articles/549814/ свободный. Яз. рус. (дата обращения 03.10.2023).
Эдвард А. Ли Проблемы с потоками. 2006. [Электронный ресурс], Режим доступа: http://www.softcraft.ru/parallel/pwt/pwt.pdf свободный. Яз. рус. (дата обращения 05.10.2023).
Комментарии (19)

BasicWolf
06.10.2023 04:26+20"Крайняя статья". Даль и Ожегов в гробу перевернулись.

lws0954 Автор
06.10.2023 04:26-4...Даль и Ожегов в гробу перевернулись.
Тоже неплохо. Лежать все время - скука скучная :) Вы не поняли - это все шутка юмора. См. ниже про парашютистов. А есть еще летчики и другие рисковые профессии. Программисты - менее рисковая работа, а потому, возможно, им и не очень понятен такой "профессиональный юмор" (судя по минусам парашютистам)... Задорнова им на их голову... :)




iig
06.10.2023 04:26Окошки напоминают Windows, Windows система многопоточная, скорее всего запущена на многоядерном проце, вряд ли у вас Pentium 1. Что такое ВКП и почему оно без потоков?
lws0954 Автор
06.10.2023 04:26+1Что такое ВКП и почему оно без потоков?
См. здесь на Хабре Автоматное программирование: определение, модель, реализация

AndreyDmitriev
06.10.2023 04:26+6Уважаемый Вячеслав, у Вас есть удивительнейшая способность изложить материал так, что полёт мысли будет понятен очень немногим.
Вообще говоря, параллельное программирование родилось не сегодня, есть устоявшиеся паттерны. Состояние гонки, семафоры, рандеву, критические секции, очереди и всё такое - всё это хорошо известно и обсуждается в любом учебнике.
Если хочется эзотерики, её тоже есть у меня. Возьмём LabVIEW, нарисуем два параллельных for цикла, инкрементирующих одну и ту же переменную по тысяче раз:

Это классическое состояние гонки (race condition), мы не можем сказать в какой момент произойдёт чтение и запись, циклы не синхронизированы, результат выполнения на выходе неопределён, будет где-то между 1000 и 2000 (типичная ошибка, которую почти все новички делают, кстати).
Что мы можем сделать - добавить семафор, блокируюший критическую секцию:

Вот теперь всегда будет выполняться код либо сверху либо снизу (кто первый захватит семафор), и результат будет всегда 2000 - каждый инкремент отработает.
Если нужно получить 1000, можно воспользоваться рандеву, тогда будет так (этот паттерн редко используется, но тем не менее):
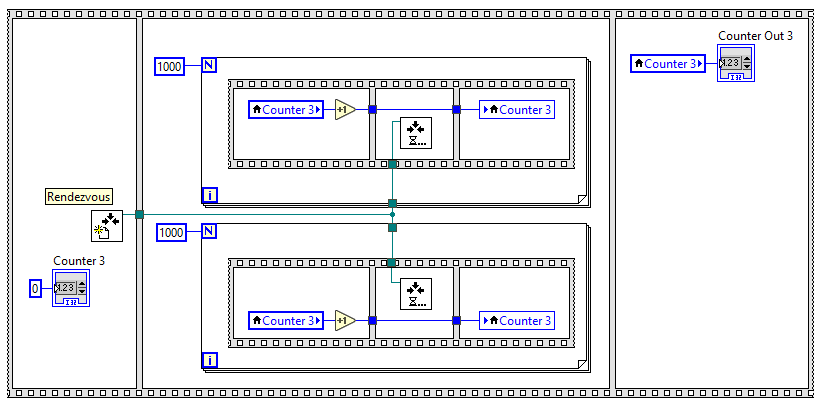
Теперь я торможу оба цикла перед записью и мне уже без разницы, отработает один или оба - они теперь синхронизированы и результат на выходе будет строго 1000.
Теоретически можно и автоматы можно навесить с синхронизацией переходов, но зачем?
В случае ПЛК есть своя специфика - там жёсткий реалтайм и циклическое выполнение кода, где происходит чтение переменных/работа с ними/запись, хотя и там можно состояние гонки сделать, если очень захотеть, а можно действительно сделать "потокобезопасный" код без использования общепринятых методик.
lws0954 Автор
06.10.2023 04:26-2Уважаемый Вячеслав, у Вас есть удивительнейшая способность изложить материал так, что полёт мысли будет понятен очень немногим.
Вы же знаете - "лучше меньше да лучше".
В случае ПЛК есть своя специфика ...
Причем здесь это. Для кого-то это, видимо, новость или даже нонсенс, но есть модель параллельных вычислений, в которой ни слова про потоки. От слова совсем. Есть даже ее реализация в форме ВКПа. На каком языке сделана, на какой платформе - дело, можно сказать, случая. Главное, что есть и демонстрирует свои возможности. И в ней, как можно убедиться, нет проблем потоков. Наоборот - все много проще и несравненно надежнее. Но... перечитайте еще раз статью Ли про потоки. Там все сказано. Про потоки, конечно. Это важно, а о том, чем их заменить, несколько, на мой взгляд, не то.
Да, LabVIEW, конечно, хорошая среда. Но у меня она не прошла тест на моделирование RS-триггера. Было это правда давно. Но не думаю, что что-то изменилось...
AndreyDmitriev
06.10.2023 04:26+2Что касается ПЛК, то мне просто подумалось, что вы с этим явно связаны, поскольку слишком глубокое погружение в этот мир вызывает определённую, хммм, скажем так - "профессиональную деформацию", но это я по себе сужу, у меня случай вдвойне тяжёлый - я ещё и на LabVIEW больше двадцати лет программирую.
На самом деле у Ли, как мне кажется, проблема несколько надумана. Сейчас в общем нет особых проблем с параллельным программированием, современные средства весьма неплохие и развиваются. Я по жизни занимаюсь машинным зрением в реальном времени и мне постоянно приходится распараллеливать вычисления, чтобы добиться требуемой производительности и "выжать" всё из современного железа. И есть несколько уровней параллелизации - я могу использовать SIMD команды (AVX, AVX2, AVX512 и FMA) и обсчитывать несколько пикселей буквально одной командой процессора. Или же я могу разбить изображение на блоки и уже их обрабатывать несколькими потоками, ну или построчно. Или ещё на уровень выше - если идёт видеопоток, то каждое изображение на своём процессоре. Я это называю для себя нано-, микро- и макро- параллелизацией.
LabVIEW сама по себе весьма неплоха в этом смысле, вы же знаете, как там устроена модель потоков данных - вот если я хочу сложить две картинки, а другие две вычесть, а затем результат перемножить, то я просто делаю вот так:

И сложение и вычитание будут осуществляться параллельно. Там, под капотом действительно будут созданы два потока, в кадом вызовется DLL, но я от ручного создания потоков избавлен. Равно как избавлен и от синхронизации - умножение "дождётся" результатов этих двух потоков и выполнение продолжится только после их завершения - мне и тут не надо прилагать никаких усилий, это гарантирует модель потоков данных (ну та, что data flow).
Более того, используя Timed Loop я могу даже управлять тем, на каком процессоре будет выполнен мой код, вот два while(true); цикла без пауз:

Ну и вот, два процессора с номерами 1 и 2 загружены под завязку:

При использовании С/С++ я могу параллелить всё через OMP, просто написав перед циклом
#pragma omp parallel forЭто избавит меня от низкоуровневой возни с потоками. В общем всё не так плохо (опять же статья эта 2006 года, с тех пор много что поменялось в лучшую сторону).
lws0954 Автор
06.10.2023 04:26вот если я хочу сложить две картинки, а другие две вычесть, а затем результат перемножить, то я просто делаю вот так:
Если я заменю картинки на обычные переменные, то LabVIEW тоже распараллелит?







ivankudryavtsev
Дорогой друг, вы просто ничего из исходной статьи не поняли и написали кучу непонятных слов с непонятной интенцией. Но зато ваша статья по модулю имеет шансы набрать то же количество минусов, что и плюсов исходная.
Статья о GIL и его поведении. Поинт автора был в том, что даже атомарная операция тип +=, казалось бы исполняемая в одном цикле блокировки GIL все равно не атомарная и без синхронизации мютексом не обойтись, как могло бы показаться неопытным разработчикам. В общем, как то так, а не вот так, как у вас. К сожалению, гора родила мышь.
Поскольку у вас и ссылка на исходную статью битая, позволю себе: https://habr.com/ru/amp/publications/764420/
Если ваша ВКП за окошками не использует потоки или процессы - это не параллельное программирование, а в лучшем случае конкурентное, если же использует - вы наглый обманщик :)
lws0954 Автор
Дорогой друг (хоть один друг есть при наличии 16-ти врагов на текущий момент) , параллельное программирование, как и последовательное, не привязано к платформе реализации. Это как минимум - микро, как максимум - макро. Но лучше не микро. Последнее это как уровень ассемблера. Микро можно связать с языком высокого уровня, макро - уровень визуальной среды. Последнее, чтобы было понятно, это типа LabVIEW, MATLAB, SimInTech и т.д. и т.п. Это достаточно наглядно показано чуть ниже на уровне LabVIEW. Что там "под капотом" - уже не столь важно. Важен результат. Чтобы даже по нему Вы, мой друг, не смогли сказать параллельная это программа или последовательная, реализована она на потоках или на чем-то еще. Поскольку Вы про мою реализацию ни чего такого тоже сказать не можете, а лишь только гадать, то это даже меня радует, т.к. защищает от
наглыхобвинений в чем-то, что к параллельному программированию не имеет отношения.Мой друг, параллельное программирование - это прежде всего параллельная вычислительная модель. Многопоточность, конкурентность и то, что Вы считаете, насколько я могу судить, параллельным или конкурентным к алгоритмической вычислительной модели ни как не относится. От слова, как нынче модно говорить, совсем. Все это может использоваться, как средство реализации той или иной вычислительной модели (например, data flow в LabVIEW или автоматные параллельные вычисления в ВКПа), где все это скрывается под капотом, но и не более того. Вот такое, я бы сказал, минимальное введение в начала теории алгоритмов и программ... В том числе и параллельных. Но ... не спешите благодарить. Вам - по дружески :)
ivankudryavtsev
Спасибо что объяснили. От этого Ваш опус не становится более релевантным или адекватным исходной посылке. Человек про GIL писал, а Вы - не знаю Python, но «осуждаю», а вот вам мое «кто о чем, а лысый о расческе». Вам бы расслабиться и не гонориться про введение в алгоритмы, Вы же ничего о моем образовании не знаете, да и неадекватных статей я не пишу.
lws0954 Автор
Человек написал прежде все про то, как он решал элементарную казалось бы параллельную задачку... В этом смысле я ни кого и ни за что не осуждаю да и не обсуждаю. Я привел свое решение той же задачи. Вот только, если Вы обратили внимание, в завершение у меня возникли сомнения, а той ли задачи. А что мы должны были получить в идеале?
В конце статьи, если Вы заметили, я привел свой ответ на вопрос, изначально поставленный автором статьи. Вот почему-то на его счет нет ни возражений, ни согласия с ним. А ведь это то, с чего надо было начать автору статьи. GIL ни GIL, потоки или что иное, Python, C++ или LabVIEW. Все это бессмысленно, если нет четкого понимания - а что должно быть? И вот тут появились определенные сомнения, т.к. то, к чему стремился автор не есть тот результат, который должен быть в идеальном параллельном решении (специально не говорю - программы). И свой вариант ответа я и привел...
А потому конкретный вопрос - а что, например, ожидали бы Вы - Х или X*К или промежуточный между этими значениями результат? В принципе я получил их все. Но вот только какой правильный? ;)
ivankudryavtsev
Процитируем же автора:
И еще:
Это вообще не о том, как сделать многопоточный счетчик.
lws0954 Автор
Вы ушли от ответа. Пусть автор обсуждает что угодно, но он это обсуждение базирует на конкретном примере и ждет от него какой-то результат. Выбрал ли он корректный пример, тот ли он получил результат, который ждал получить. Но самое интересное - а верны ли его ожидания. Судя по статье, то он ожидал все же ровно X*K. Но поскольку исходная постановка - абсолютно одинаковые параллельные процессы и переменная-счетчик, к которой ни как не оговорен режим доступа. И тут - или неверное представление о решаемой задаче или просто неверное представление о том результате, который он должен был бы получить по его замыслу.
Повторю еще раз. Я тоже могу заблуждаться... Но хотелось бы все знать, а что ожидали Вы, лично? Какое значение счетчика должно быть? Судя по всему, Вы все же на стороне автора и, наверное, лучше меня понимаете его замысел... Или, может, автора на сцену? Если он, конечно, отслеживает наше общение ;)