

С приходом широкополосного доступа и высоких скоростей мобильного интернета нагрузка на сеть стала одним из ключевых бутылочных горлышек для производительности систем. Сетевые провайдеры столкнулись с необходимостью постоянно увеличивать и оптимизировать сетевую пропускную способность и ёмкость при сохранении прибыли. Попыткой решить эту задачу стала Software Defined Network — концепция выведения сетевых функций из специализированного железа на программный уровень и дальнейшего разделения ответственности на разные слои.
За время существования SDN появилось много причин для того, чтобы использовать именно этот подход:
- сокращение затрат на всех уровнях — проще управлять сетевым состоянием и инфраструктурой, более понятное масштабирование и отказоустойчивость, понятная архитектура с центральным контроллером;
- возможность автоматической настройки и подстройки сети;
- наличие условно бесконечной гибкости настройки логики обработки трафика;
- упрощение инвентаризации сетевых элементов — например, автоматизация удаления объектов при выходе из строя или утилизации и перебалансировка сетевого состояния;
- уход к вендор-нейтральным решениям (что особенно важно).
Несмотря на то что последние разработки и всеобщее внимание возникли относительно недавно, принципы и фундамент для Software Defined Network закладывались последние десятилетия. Мы в VK Cloud тоже делаем свою SDN под названием Sprut. Несколько лет назад разработчики начали миграцию на неё с предыдущей, Neutron. Мы спросили их, что происходит с разработкой новой SDN.
Под катом история SDN для тех, кто не погружён в контекст. А если вы уже в курсе, то пропускайте и читайте дальше.
История SDN
Long time ago…
Компьютерные сети непросто администрировать. Много оборудования: роутеры, свичи. Много софта: брандмауэры, NAT, балансеры, безопасность. На роутерах и свичах управляющий софт обычно сложный, закрытый и проприетарный, он реализует протоколы и функциональность. Всё это вместе постоянно переосмысляется, стандартизируется и тестируется в работе с другими технологиями. Богатство технологий и любовь к разработке всего собственного довольно сильно замедляла инновации, увеличивала сложность и все виды затрат.
Первые «подходы к снаряду» предпринимались ещё в середине 1990-х, когда в технологии Active Networking воплотились программируемые функции на уровне сетей. В этот период интернет обрастал новыми сценариями, и стало понятно, что обойтись текущими подходами к разработке и поддержке сетей недостаточно. Началось моделирование нагрузок и общение с IETF, чтобы стандартизировать новые подходы.
Если интересно почитать больше про эти инициативы, то можно изучить GENI (Global Environment for Network Innovations), NSF FIND (Future Internet Design), EU FIRE (Future Internet Research and Experimentation Initiative).
К ключевым интересным тенденциям в этот период можно отнести:
Исследования велись по всем фронтам — от архитектуры, железа и производительности до вопросов безопасности. Были исследования о том, безопасно ли делать сеть более активной, если по ней могут пройти зловреды-приложения, на тот момент больше упоминали Java.
Active Networking стало радикальным изменением. Раньше сети программировать было нельзя, теперь же стало возможным вытащить API на ресурсы сетевых узлов (процессинг, очереди) и обработку пакетов. Тогда не все поддержали эту идею, были сторонники подхода «чем проще, тем лучше, а программировать сети — это уже сложно и просто идеологически неправильно». Проблемой Active Networking было отсутствие поддержки предлагаемых всеобъемлющих решений со стороны рынка. Дополнительная проблема была связана с географией: в разных регионах планеты разные стандарты, и проприетарные разработки иногда не учитывали это, усложняя сетевые процессы. Попытка сдвинуть ситуацию на тот момент провалилась.
Позже, примерно с 2000-го по 2007-й, продолжились исследования более узких и понятных задач: маршрутизации, управления конфигурацией, разделения ответственности. В этот период начали кристаллизоваться реализации основной характеристики SDN: чёткое разделение функциональности в Control и Data layer. Control layer управляет трафиком, Data layer занимается отработкой решений контрольного слоя. Control layer был более открытым к инновациям, чем Data layer, поэтому фокус был на нём.
Исследованиям очень помогло удешевление вычислительных ресурсов: оказалось, что серверы имели гораздо больше ресурсов, чем выделялось в роутерах на контрольный слой.
На этом этапе выделились два направления:
Открытый интерфейс между слоями, который нужно было стандартизировать в IETF, и интерфейсы для работы с пакетами на уровне ядра Linux. Рабочая группа ForCES выдвинула предложения по интерфейсу, важной частью которых было предложение по использованию API для установки правил для трафика на слое данных. По этой логике можно было бы полностью убрать слой контроля с роутера. Не получилось. Продолжили использовать BGP, стандартный протокол слоя контроля, для установки правил на легаси-роутерах.
Архитектура платформы и управление состоянием. Централизация контроллеров не помогала решению проблемы с распределённым управлением состояния, с репликацией и фейловером. И если с репликами могло и не возникнуть особых проблем, которые обосновали бы специальные меры (реплики в конце концов обработали бы одни и те же маршруты), то с масштабированием было слегка сложнее, особенно с в случае с SDN-контроллерами.
Удешевление вычислительных ресурсов означало, что один простой сервер может хранить в себе и выполнять всю необходимую для большой сети логику по маршрутизации. Тут же обнаружились и дополнительные плюсы: бэкапы стало делать гораздо проще.
На этом этапе всё ещё было много сопротивления новым идеям, особенно на уровне архитектуры (как будет вести себя распределённая система даже внутри одного периметра) и регламентов (что делать, если что-то сломается). Также волновались, что индустрия уходит от симпатичной модели распределённого консенсуса, когда все в конце концов синхронизируют своё состояние. По факту же уже тогда симпатичная модель и реализация имела изъяны: например, протоколы распределённой маршрутизации использовали техники маршрутизации типа OSPF Area / BGP Route Reflector.
Логично было также некоторое сопротивление со стороны ключевых игроков. Принятие стандартов, особенно открытых, означало (и продолжает означать сегодня), что на рынке могут появиться новые игроки.
В сухом остатке: этот период так и не ознаменовался какими-то серьёзными индустриальными сдвигами, однако сформировал архитектуру SDN такой, какой она стала потом. В том числе за счет появления проекта 4D, который постулировала SDN, состоящую из четырех слоев: Data plane (процессинг пакетов на основе правил), Discovery plane (сбор топологии и измерение), Dissemination plane (размещение правил для обработки пакетов), Decision plane (логическое объединение контроллеров, реализующих обработку пакетов). Появились определяющие проекты: Ethane, SANE. Ethane стал предтечей OpenFlow — дизайн системы стал первой версией OpenFlow API.
OpenFlow — это сетевой протокол связи, применяемый для связи между контроллерами и коммутаторами в архитектуре SDN. У него есть таблицы управления трафиком, каждое правило в которых обозначает часть трафика и действие: дроп, форвард, флуд. Пакеты отслеживаются отдельно, и поверх ещё накладывается приоритет, чтобы развести правила с пересекающейся логикой.
OpenFlow смог найти баланс в ответе на логичный вопрос критиков о том, зачем вообще делать полностью программируемые сети без полного понимания задач, которые они будут решать. OpenFlow расширил функциональность раннего железа, при этом не ломая обратную совместимость того, что уже было. Это ограничило гибкость самого проекта, но развернуть OpenFlow можно было быстро (по сути, апгрейдом прошивки), что открыло путь для SDN. Оборудование уже поддерживало технологии, которые стандартизировались в протоколе OpenFlow, например гибкий контроль доступа и мониторинг потоков.
Первые исследования и реальные внедрения OpenFlow начались в университетских кампусах, но довольно быстро пошла волна и в дата-центрах, для которых модель, в которой они могли нанять разработчиков для написания контроллеров большим количеством однотипного оборудования, стала выгоднее покупки и поддержки проприетарного, закрытого и сложного для обновления оборудования.
С тех пор как SDN начала набирать популярность, образовалось некоторое количество рабочих групп и консорциумов типа Open Networking Foundation и Open Daylight Initiative.
OpenFlow, по сути, стал мотиватором и реальным кейсом для исследований в области сетевой операционной системы, разбивающей сетевую функциональность на три слоя: Data plane с открытым интерфейсом, State management layer для поддержки консистентного понимания состояния сети и Control layer.
Любопытно, что в это время возникло два подхода к анализу трафика. Старый, классический (Ethane) — первый пакет каждого потока должен пройти через контроллер. Подход OpenFlow и в целом других SDN был в том, чтобы реагировать только на изменения топологии и обновления в ответ на ошибки в передаче либо на забитую сеть.
Протоколов, которые расширяли SDN, после OpenFlow было множество. Из интересных можно упомянуть:
Каждый из протоколов привносил какую-то часть удобства для инженеров. NETCONF добавил RPC для работы с конфигурацией сетевых элементов, архитектурные части для хранения состояния и данных, а также язык YANG для моделирования данных. RESTCONF добавил к уравнению HTTP CRUD, работавший с конфигурацией. gRPC позволил посмотреть на работу с большим количеством передаваемых данных с новой стороны плюс HTTP2.
Активное внедрение протоколов и стандартов позволило постепенно уйти к вендор-нейтральным решениям, к Open-Source-модели, где сейчас многие SDN и находятся. Open-Source-модель открыла много возможностей для доработки, получения обратной связи и интеграции экосистемных компонентов.
На сегодняшний день можно сказать, что всплеск внимания к SDN случился примерно в 2016 году, когда Open Virtual Network (OVN) добавили в OpenStack. С тех пор Linux Foundation и Open Networking Foundation работают над тем, чтобы стандартизировать подходы, и помогают проектам (OpenDaylight, vSwitch и т. д.) найти свою нишу.
История SDN
Long time ago…
Компьютерные сети непросто администрировать. Много оборудования: роутеры, свичи. Много софта: брандмауэры, NAT, балансеры, безопасность. На роутерах и свичах управляющий софт обычно сложный, закрытый и проприетарный, он реализует протоколы и функциональность. Всё это вместе постоянно переосмысляется, стандартизируется и тестируется в работе с другими технологиями. Богатство технологий и любовь к разработке всего собственного довольно сильно замедляла инновации, увеличивала сложность и все виды затрат.
Первые «подходы к снаряду» предпринимались ещё в середине 1990-х, когда в технологии Active Networking воплотились программируемые функции на уровне сетей. В этот период интернет обрастал новыми сценариями, и стало понятно, что обойтись текущими подходами к разработке и поддержке сетей недостаточно. Началось моделирование нагрузок и общение с IETF, чтобы стандартизировать новые подходы.
Если интересно почитать больше про эти инициативы, то можно изучить GENI (Global Environment for Network Innovations), NSF FIND (Future Internet Design), EU FIRE (Future Internet Research and Experimentation Initiative).
К ключевым интересным тенденциям в этот период можно отнести:
-
программируемые функции для снижения барьера для инноваций. Отсутствие гибкости и было одной из ключевых причин разработки SDN. На этом этапе большое внимание стали уделять программированию слоя данных. Со временем стало больше инвестиций в такие SDN-протоколы, как OpenFlow, FlowVisor и др.;
-
виртуализация и демультиплексирование, правила на основе заголовков пакетов.
Исследования велись по всем фронтам — от архитектуры, железа и производительности до вопросов безопасности. Были исследования о том, безопасно ли делать сеть более активной, если по ней могут пройти зловреды-приложения, на тот момент больше упоминали Java.
Active Networking стало радикальным изменением. Раньше сети программировать было нельзя, теперь же стало возможным вытащить API на ресурсы сетевых узлов (процессинг, очереди) и обработку пакетов. Тогда не все поддержали эту идею, были сторонники подхода «чем проще, тем лучше, а программировать сети — это уже сложно и просто идеологически неправильно». Проблемой Active Networking было отсутствие поддержки предлагаемых всеобъемлющих решений со стороны рынка. Дополнительная проблема была связана с географией: в разных регионах планеты разные стандарты, и проприетарные разработки иногда не учитывали это, усложняя сетевые процессы. Попытка сдвинуть ситуацию на тот момент провалилась.
Позже, примерно с 2000-го по 2007-й, продолжились исследования более узких и понятных задач: маршрутизации, управления конфигурацией, разделения ответственности. В этот период начали кристаллизоваться реализации основной характеристики SDN: чёткое разделение функциональности в Control и Data layer. Control layer управляет трафиком, Data layer занимается отработкой решений контрольного слоя. Control layer был более открытым к инновациям, чем Data layer, поэтому фокус был на нём.
Исследованиям очень помогло удешевление вычислительных ресурсов: оказалось, что серверы имели гораздо больше ресурсов, чем выделялось в роутерах на контрольный слой.
На этом этапе выделились два направления:
Открытый интерфейс между слоями, который нужно было стандартизировать в IETF, и интерфейсы для работы с пакетами на уровне ядра Linux. Рабочая группа ForCES выдвинула предложения по интерфейсу, важной частью которых было предложение по использованию API для установки правил для трафика на слое данных. По этой логике можно было бы полностью убрать слой контроля с роутера. Не получилось. Продолжили использовать BGP, стандартный протокол слоя контроля, для установки правил на легаси-роутерах.
Архитектура платформы и управление состоянием. Централизация контроллеров не помогала решению проблемы с распределённым управлением состояния, с репликацией и фейловером. И если с репликами могло и не возникнуть особых проблем, которые обосновали бы специальные меры (реплики в конце концов обработали бы одни и те же маршруты), то с масштабированием было слегка сложнее, особенно с в случае с SDN-контроллерами.
Удешевление вычислительных ресурсов означало, что один простой сервер может хранить в себе и выполнять всю необходимую для большой сети логику по маршрутизации. Тут же обнаружились и дополнительные плюсы: бэкапы стало делать гораздо проще.
На этом этапе всё ещё было много сопротивления новым идеям, особенно на уровне архитектуры (как будет вести себя распределённая система даже внутри одного периметра) и регламентов (что делать, если что-то сломается). Также волновались, что индустрия уходит от симпатичной модели распределённого консенсуса, когда все в конце концов синхронизируют своё состояние. По факту же уже тогда симпатичная модель и реализация имела изъяны: например, протоколы распределённой маршрутизации использовали техники маршрутизации типа OSPF Area / BGP Route Reflector.
Логично было также некоторое сопротивление со стороны ключевых игроков. Принятие стандартов, особенно открытых, означало (и продолжает означать сегодня), что на рынке могут появиться новые игроки.
В сухом остатке: этот период так и не ознаменовался какими-то серьёзными индустриальными сдвигами, однако сформировал архитектуру SDN такой, какой она стала потом. В том числе за счет появления проекта 4D, который постулировала SDN, состоящую из четырех слоев: Data plane (процессинг пакетов на основе правил), Discovery plane (сбор топологии и измерение), Dissemination plane (размещение правил для обработки пакетов), Decision plane (логическое объединение контроллеров, реализующих обработку пакетов). Появились определяющие проекты: Ethane, SANE. Ethane стал предтечей OpenFlow — дизайн системы стал первой версией OpenFlow API.
OpenFlow — это сетевой протокол связи, применяемый для связи между контроллерами и коммутаторами в архитектуре SDN. У него есть таблицы управления трафиком, каждое правило в которых обозначает часть трафика и действие: дроп, форвард, флуд. Пакеты отслеживаются отдельно, и поверх ещё накладывается приоритет, чтобы развести правила с пересекающейся логикой.
OpenFlow смог найти баланс в ответе на логичный вопрос критиков о том, зачем вообще делать полностью программируемые сети без полного понимания задач, которые они будут решать. OpenFlow расширил функциональность раннего железа, при этом не ломая обратную совместимость того, что уже было. Это ограничило гибкость самого проекта, но развернуть OpenFlow можно было быстро (по сути, апгрейдом прошивки), что открыло путь для SDN. Оборудование уже поддерживало технологии, которые стандартизировались в протоколе OpenFlow, например гибкий контроль доступа и мониторинг потоков.
Первые исследования и реальные внедрения OpenFlow начались в университетских кампусах, но довольно быстро пошла волна и в дата-центрах, для которых модель, в которой они могли нанять разработчиков для написания контроллеров большим количеством однотипного оборудования, стала выгоднее покупки и поддержки проприетарного, закрытого и сложного для обновления оборудования.
С тех пор как SDN начала набирать популярность, образовалось некоторое количество рабочих групп и консорциумов типа Open Networking Foundation и Open Daylight Initiative.
OpenFlow, по сути, стал мотиватором и реальным кейсом для исследований в области сетевой операционной системы, разбивающей сетевую функциональность на три слоя: Data plane с открытым интерфейсом, State management layer для поддержки консистентного понимания состояния сети и Control layer.
Любопытно, что в это время возникло два подхода к анализу трафика. Старый, классический (Ethane) — первый пакет каждого потока должен пройти через контроллер. Подход OpenFlow и в целом других SDN был в том, чтобы реагировать только на изменения топологии и обновления в ответ на ошибки в передаче либо на забитую сеть.
Протоколов, которые расширяли SDN, после OpenFlow было множество. Из интересных можно упомянуть:
- NETCONF (XML поверх SSH) — 2006;
- RESTCONF (XML/JSON поверх HTTP) — 2017;
- gMNI (gRPC поверх HTTP2) — 2019.
Каждый из протоколов привносил какую-то часть удобства для инженеров. NETCONF добавил RPC для работы с конфигурацией сетевых элементов, архитектурные части для хранения состояния и данных, а также язык YANG для моделирования данных. RESTCONF добавил к уравнению HTTP CRUD, работавший с конфигурацией. gRPC позволил посмотреть на работу с большим количеством передаваемых данных с новой стороны плюс HTTP2.
Активное внедрение протоколов и стандартов позволило постепенно уйти к вендор-нейтральным решениям, к Open-Source-модели, где сейчас многие SDN и находятся. Open-Source-модель открыла много возможностей для доработки, получения обратной связи и интеграции экосистемных компонентов.
На сегодняшний день можно сказать, что всплеск внимания к SDN случился примерно в 2016 году, когда Open Virtual Network (OVN) добавили в OpenStack. С тех пор Linux Foundation и Open Networking Foundation работают над тем, чтобы стандартизировать подходы, и помогают проектам (OpenDaylight, vSwitch и т. д.) найти свою нишу.
SDN в облаке
SDN стали основополагающим сервисом для облачных платформ. Одна из основных характеристик облака — это эластичность. Она, а также скорость и другие характеристики развёртываний подразумевают, что нижележащие сервисы должны быть максимально автоматизированы, отслеживая жизненный цикл объектов, на основе которых функционирует развёртываемый сервис. Например, для виртуальных машин это могут быть хранилище и сетевые настройки. Когда вы настраиваете виртуальную машину в любом облаке и переходите на вкладку сетей, чтобы настроить, в какой подсети будет виртуалка, вы участвуете в формировании запроса для SDN.
SDN — это важная часть автоматизации по настройке сети. Поэтому SDN — это неотъемлемая часть любого облачного продукта.
История разработки SDN в VK Cloud
Облако VK Cloud стартовало с OpenStack. SDN была с самого начала взята как часть OpenStack — Neutron. Основная причина была в том, что нужно было начать быстро и в условиях ограниченных человеческих ресурсов. В начале любого проекта кадры решают всё — при становлении облака это всегда ключевой вопрос. Когда времени мало, написать что-то серьезное с нуля очень сложно.
Техническое примечание
Neutron интегрирован в OpenStack и имеет:
- много разных вариантов организации сети: Vlan, Overlay, Flat;
- большой набор сетевых функций: роутеры, балансировщики нагрузки, VPN, DNS, Firewall, BGP-сигналинг;
- подробную исчерпывающую документацию.
OpenStack Neutron имеет простую архитектуру из:
- Neutron API, который принимает входящие пользовательские запросы;
- плагина ML2, который реализует всю базовую логику работы Neutron;
- базы данных;
- RabbitMQ на слое transport;
- агентов, занимающихся настройкой Data plane;
- Data plane, в качестве которых могут быть OVS, NetNS, Daemons и другие.
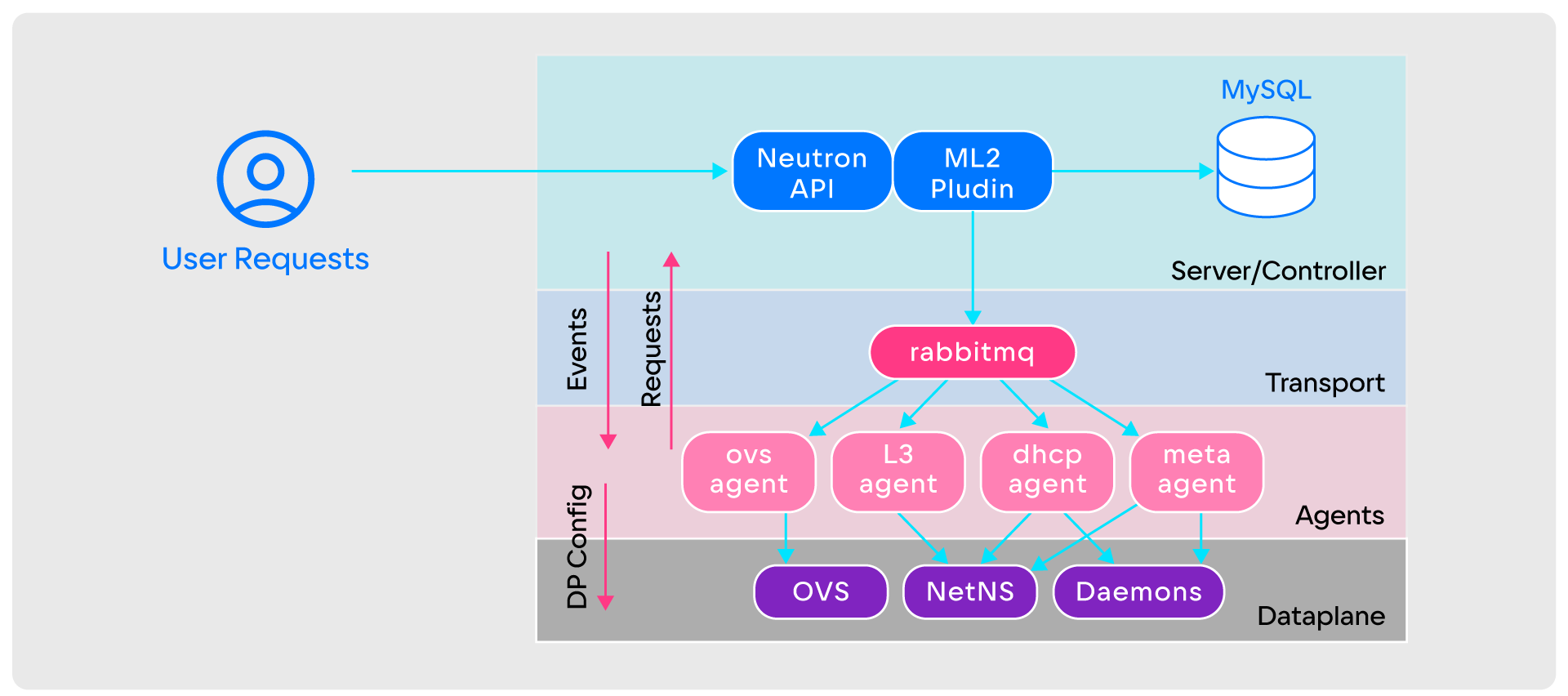
OpenStack Neutron работает следующим образом:
- Для создания виртуальной сети пользователь делает запрос в Neutron API.
- Neutron API передаёт запрос в плагин ML2.
- Плагин ML2 рассылает уведомления о создании сети всем агентам через RabbitMQ.
- После получения уведомлений агенты определяют, на каких вычислительных узлах создаётся сеть. Если узлы их, начинают настройку Data plane, если нет — игнорируют.
Начало проблем с эксплуатацией на больших объёмах
Спустя пару лет команда выросла, клиентская база увеличилась, и вместе с этим возникли некоторые сложности с Neutron — в основном эксплуатационные, так как с добавлением фич проблем не было. Сам OpenStack Neutron довольно простой в плане работоспособности, но на практике из-за архитектурных особенностей и отсутствия изначальной адаптации к большим объёмам часто случаются сбои. Несколько из них перечислены ниже, и стоит уточнить, что становятся они особенно неудобными именно при эксплуатации на облачных объёмах.
Агенты не хранят состояния (stateless). Они не помнят настройки Data plane, нет обратной связи о том, как именно он настроился и настроился ли вообще. Это создаёт трудности. Например, агент может пропустить часть событий из-за временного отключения, перегрузки или загруженности ноды, на которой он расположен. Это критично в облаке, где состояние ресурсов постоянно меняется.
Частично эту проблему нивелирует механизм Full Sync. Он позволяет агенту запрашивать у сервера всю информацию о своём состоянии в случае любых ошибок. Но при сотнях сущностей в ноде Full Sync может занимать несколько часов.
Переусложненный Data plane. Как правило, в оверлейной конфигурации Neutron центром всего Data plane выступает OVS. Он отвечает за связь виртуальных машин и подключение сетевых функций: DHCP, DNS, Metadata Proxy и других. За настройку OVS отвечает OVS Agent. По сути, логика всей сети находится внутри OVS и OVS Agent.
Такое усложнение делает почти невозможным отслеживание событий. Если на ноде запущено несколько виртуалок, в OVS будут десятки тысяч правил, в которых сложно разобраться. Даже трассировка OVS и мониторинг не всегда помогает с этим.
Event-based-общение через RabbitMQ. Агенты общаются с сервером с помощью событий. Но в коде всех сервисов — Neutron, агентов, RabbitMQ — бывают ошибки. Из-за этого агенты могут частично игнорировать события, а RabbitMQ — терять их при доставке из-за разных Race conditions. При его отказе весь SDN будет недоступным и неуправляемым. Кроме того, масштабируемость RabbitMQ ограничена: с увеличением потока событий часть событий может теряться. Это приводит к многочисленным проблемам. Возникают пробелы в настройке Data plane и ошибки при передаче трафика. Мониторить эти события сложно.
Больше функциональности — больше событий. OpenStack Neutron вариативен в настройках и позволяет включать много разных функций. Но это приводит к лавинообразному увеличению количества событий от каждой из них. Например, Neutron с простой конфигурацией Plane-сеть или VLAN-сеть и базовыми сервисами, такими как DHCP и Metadata Proxy, может стабильно работать на 1000 гипервизоров. Но при включении оверлейных сетей с механизмом распределённой маршрутизации, signaling по BGP и другими функциями проблемы появляются уже при 100 гипервизорах.
Предотвратить их помогает предварительное нагрузочное тестирование. Его нужно проводить перед включением любой дополнительной функциональности.
Лимиты архитектуры. Сам Mirantis говорит о том, что 500 узлов — это предел и Neutron не позиционируется как бесконечно масштабируемый продукт, который выдержит облачные масштабы.
Выбор между своей разработкой и готовым решением
Надёжность, стабильность облака напрямую связана с выбором решения. До некоторых пор Neutron подходил под запросы VK Cloud, но потом перестал. Объективный анализ рынка показал, что в одну SDN фичи добавляются легко, в другую — сложно, в некоторые — очень сложно.
Из-за отсутствия достойной альтернативы разработка собственной SDN стала необходимостью.
При выборе альтернативной SDN рассматривалось всего два варианта:
- Переехать на другую SDN: Tungsten Fabric/OpenContrail, OpenDayLight, OVN.
- Переработать OpenStack Neutron.
К искомой SDN предъявляли несколько требований:
-
Поддержка текущего набора сетевых функций. Уже было подключено много функций, нужных клиентам. Отключать их нельзя: новое решение должно иметь такую же функциональность.
-
Сеть DC вида «L3 на стойку (ToR)». В ЦОДах сети построены по принципу «L3 на стойку». Из-за этого не поддерживаются некоторые протоколы отказоустойчивости, такие как VRRP, которые опираются на единый L2-широковещательный домен между всеми серверами. Кроме того, внешний трафик нужно сигналить в сторону ToR по BGP.
-
Масштабирование. Возможность масштабирования или шардирования нужна, чтобы обеспечить отказоустойчивость сети при обнаружении узких мест и упростить их устранение.
-
Плавный переезд с текущей SDN. Переезд на новую SDN не должен повлиять на работу клиентов и функциональность.
-
Возможность и потенциал доработки. Готового решения «из коробки» под заявленные требования не было, поэтому нужны только Open-Source-решения, которые можно доработать самостоятельно.
Исходя из требований, выбор сократился до двух вариантов: Tungsten Fabric и всё тот же OpenStack Neutron. Но:
- У Tungsten Fabric нет нужной функциональности, его нужно сразу доделывать. Доработку усложняет огромная кодовая база, в которой трудно разобраться из-за недостатка документации в открытом доступе. Дополнительная проблема — большой набор технологий. Это усложняет внедрение, эксплуатацию и поддержку. В итоге недостатки решения перевешивают преимущества Tungsten Fabric — широкую функциональность и возможность интеграции в «L3 на стойку».
- В переработке OpenStack Neutron много плюсов: уже есть нужные функции, не нужна миграция, улучшение можно проводить пошагово, а у команды есть достаточная экспертиза. Но недостатки Neutron, которые перечисляли выше, никуда не деваются — из-за них мы и искали альтернативную SDN. Кроме того, для переработки понадобится менять слишком много кода и работать с неподходящей архитектурой.
Поскольку и Tungsten Fabric, и OpenStack Neutron отвечали только части требований, мы решили разработать собственную SDN.
Как написать свою SDN и мигрировать на нее платформу, когда всё работает на старой
У написания собственного решения есть два ключевых недостатка:
-
Написать SDN сложно. Нужна большая команда с экспертизой в Control plane и Data plane и знанием сетей.
-
Большой Time-to-market. До получения готового решения и его запуска в работу нужно много времени.
Но преимуществ больше, и они значимее:
- Можно сделать любую архитектуру без дополнительных ненужных элементов.
- Можно предусмотреть любую миграцию.
- Можно решить интересную для разработчиков задачу.
Взвесив за и против, команда VK Cloud приступила к разработке своей SDN. Назвали ее Sprut. На разработку ушло меньше года. Конечно, сейчас у Sprut есть ещё не вся функциональность, но он уже находится вместе с Neutron в продакшене.
Что важно, у Sprut нет проблем, характерных для Neutron. Ради этого была глобально переработана его архитектура:
- Для агентов предусмотрена возможность постоянного сбора информации о настройках Data plane.
- Больше нет событийной модели общения между компонентами. Теперь агенты всегда получают от сервера целевое состояние, в котором должны быть, и непрерывно перезапрашивают его. Получился аналог постоянного Full Sync, при котором агенты сравнивают текущее состояние Data plane с целевым состоянием от сервера, накладывают необходимый diff на Data plane и приводят его к актуальному состоянию. В теории автоматического управления такой подход называют замкнутым контуром управления.
- RabbitMQ заменён обычным HTTP REST API. Он лучше справляется с большими массивами данных о таргетном состоянии агентов, его проще разрабатывать и мониторить.
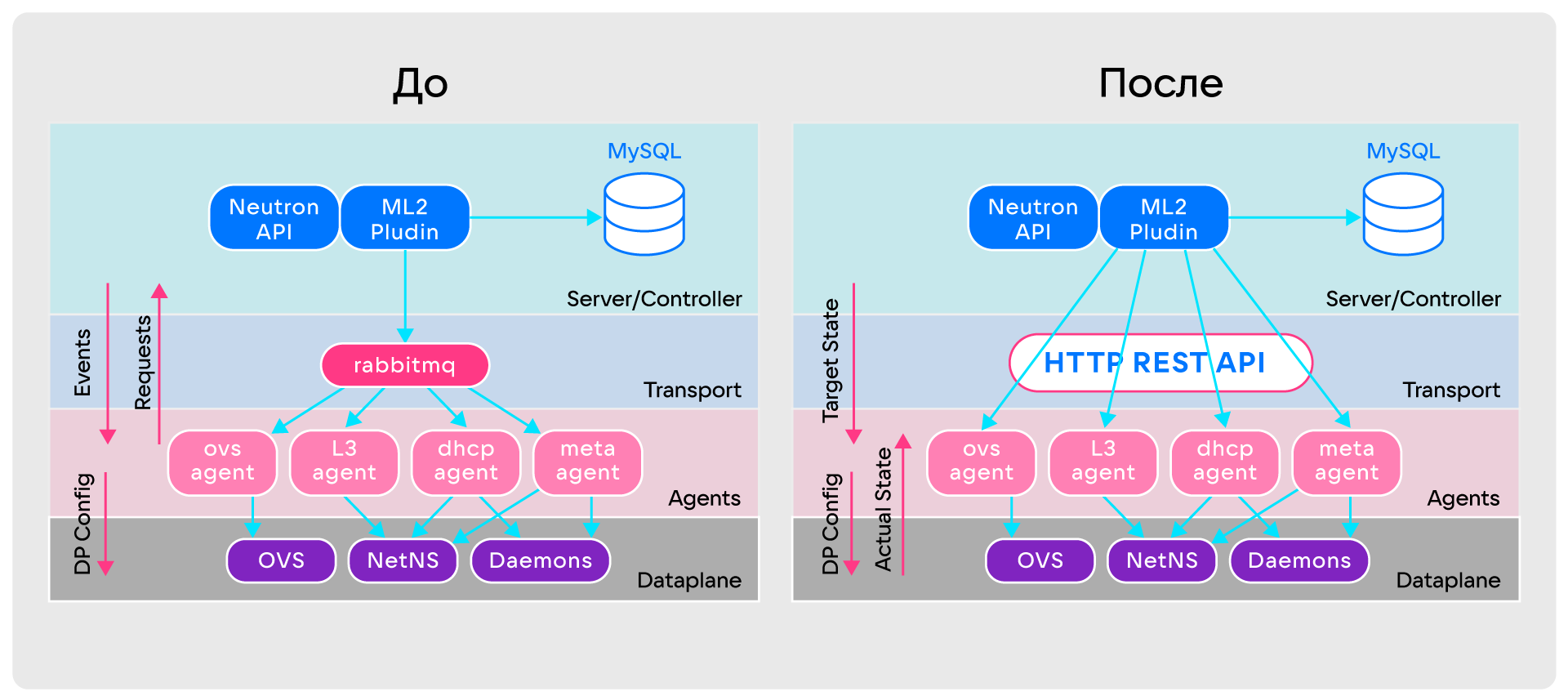 Сравнение архитектур OpenStack Neutron и SPRUT
Сравнение архитектур OpenStack Neutron и SPRUTНо эти переделки не решили главную проблему — Data plane оставался сложным. Чтобы понять, как его упростить, пришлось углубиться в теорию и разобрать основные виртуальные примитивы Neutron: порт, сеть, подсеть, роутер.
Понять принцип работы облачной сети просто, если спроецировать компоненты виртуальной сети на привычную физическую.
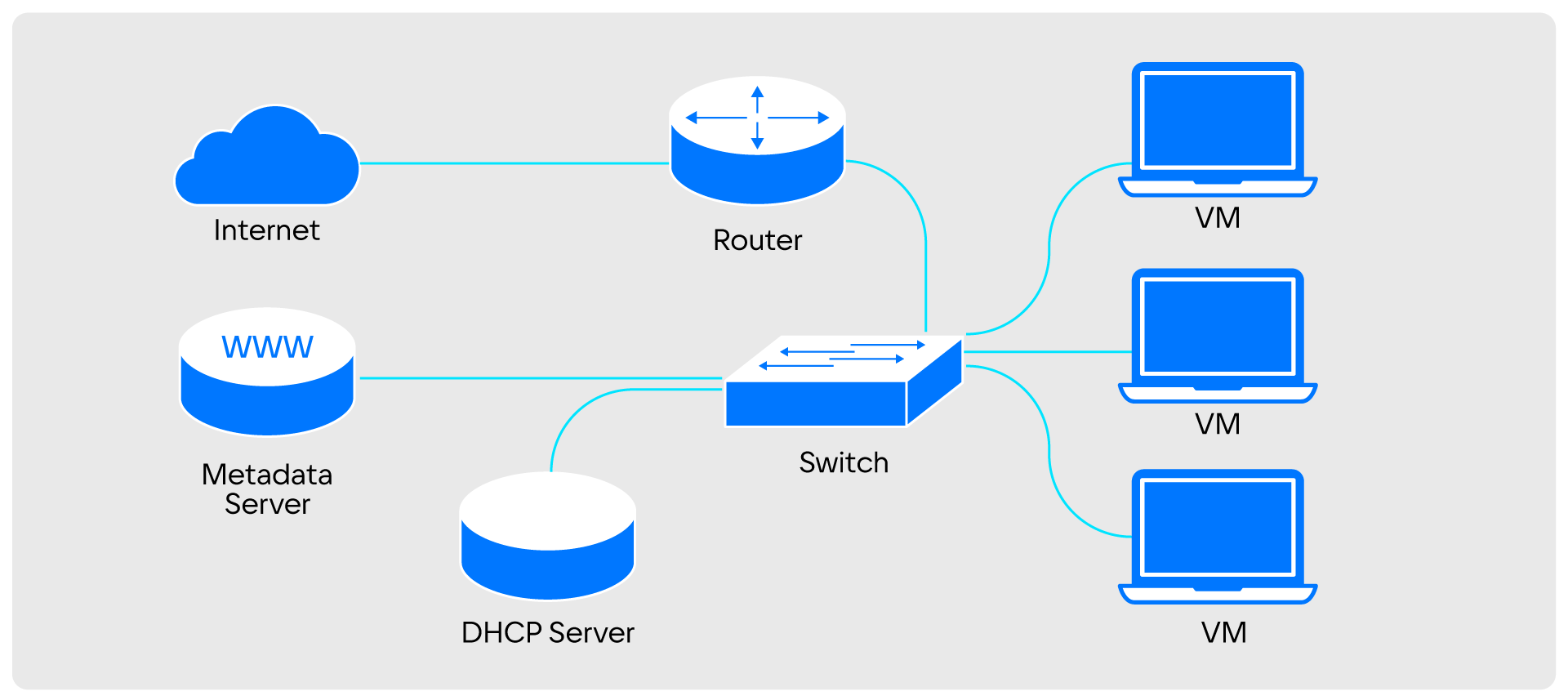 Виртуальная сеть превращается в Switch и в Metadata Proxy. Виртуальная подсеть превращается в DHCP-сервер. Виртуальный роутер становится физическим. Порты становятся обычными или виртуальными машинами
Виртуальная сеть превращается в Switch и в Metadata Proxy. Виртуальная подсеть превращается в DHCP-сервер. Виртуальный роутер становится физическим. Порты становятся обычными или виртуальными машинамиВ формате физической инфраструктуры все эти компоненты распределены по огромному кластеру физических узлов, которые соединены между собой. Для этого компоненты соединяют набором коммутаторов.
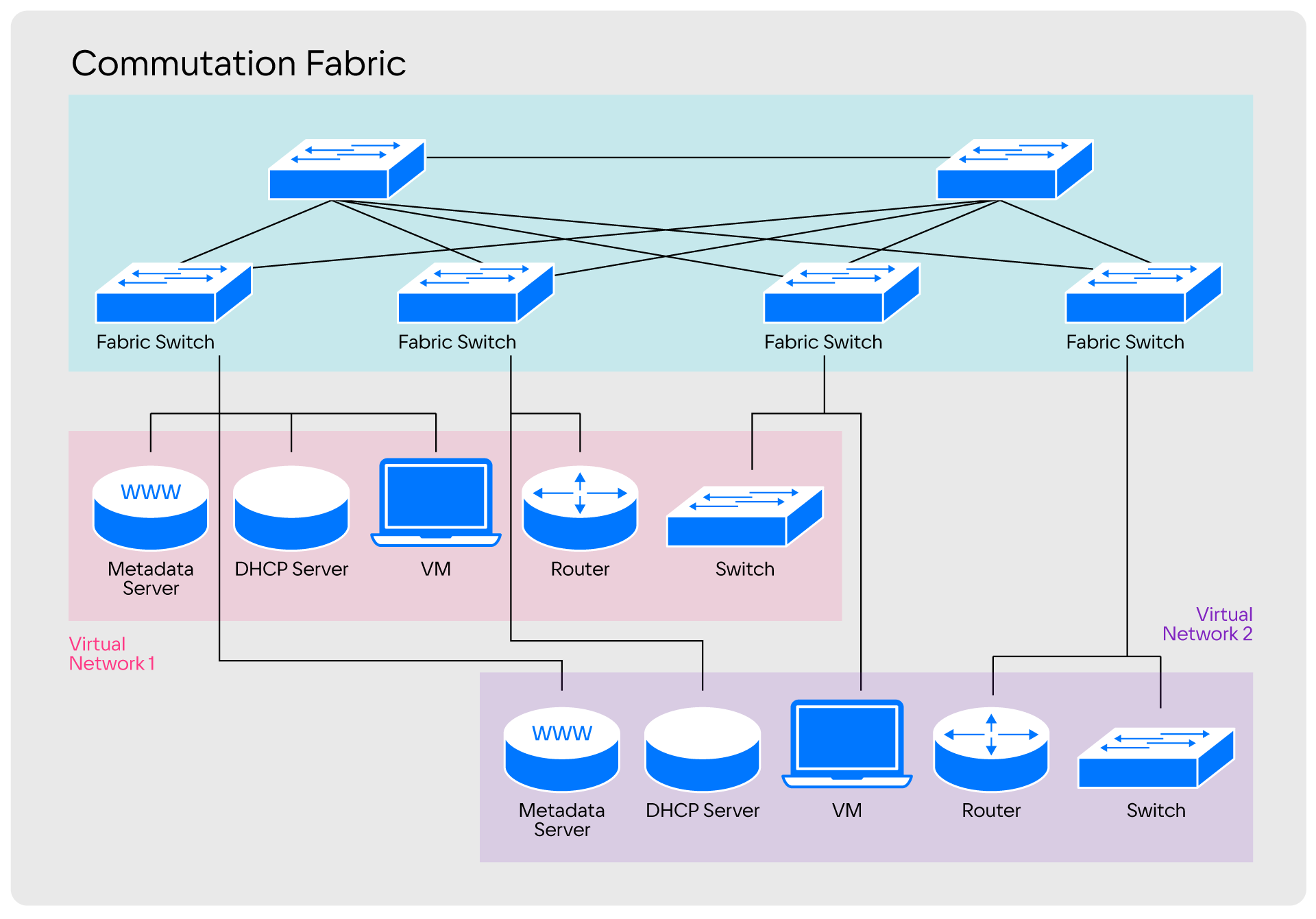
Разделение на сегменты среди этих коммутаторов происходит с помощью технологии VLAN или более современной MPLS. В данном случае все сегменты представляют собой разные виртуальные сети.
Разделение, которое используют в стандартных сетях, полностью отвечает нашим эксплуатационным запросам, поэтому при проектировании SPRUT мы точно так же разделили зоны ответственности на три уровня: NFV, SDN и APP.
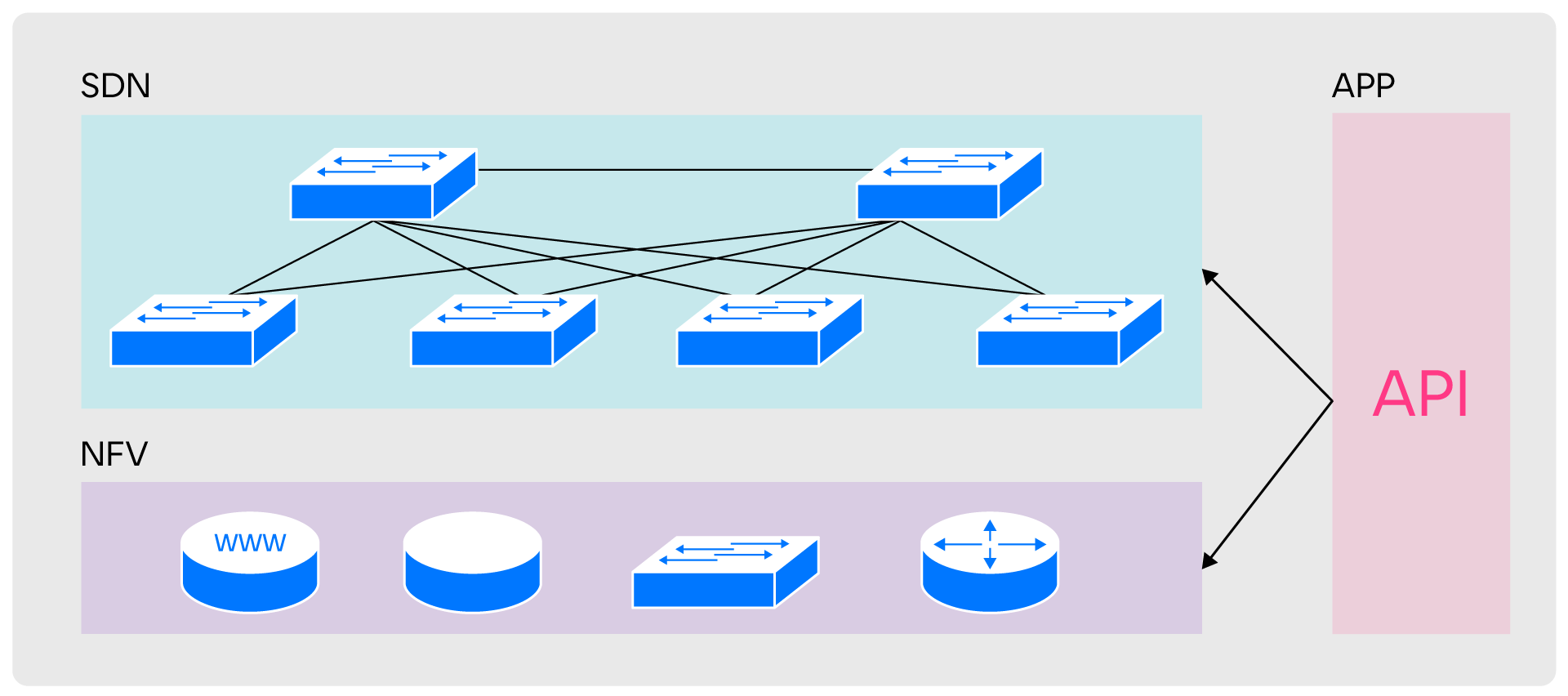
NFV (Network Function Virtualization) отвечает за предоставление сетевых сущностей, SDN — за их связь между собой. APP обеспечивает совместимость уровней по API
Разделение зон ответственности помогло нам упростить Data plane в исходной архитектуре SPRUT.

После внесения изменений в архитектуре появилось два независимых уровня, каждый со своими агентами, контроллерами, базами данных и API. Уровни работают со своими примитивами и не зависят друг от друга. Связь уровней обеспечивает Application (APP).
Такая модернизация упростила разработку Control plane и помогла нативно избавиться от проблем, характерных для Neutron. В SPRUT:
- агенты получают информацию о настройках Data plane;
- события не теряются из-за отказа от событийной модели;
- Data plane настраивается проще и гибче.
Техническая справка
Устройство архитектурных уровней SPRUT
В архитектуре SPRUT у каждого уровня есть свои особенности.
SDN. Уровень состоит из SDN-агентов, работающих на вычислительных узлах, SDN-контроллера и SDN API. Взаимодействие происходит следующим образом:
- После запуска агенты создают на своих хостах виртуальные коммутаторы и соединяют их между собой туннелями
 Туннели могут иметь любую конфигурацию: полную связность, частичную, разделённые регионы или другую.
Туннели могут иметь любую конфигурацию: полную связность, частичную, разделённые регионы или другую.
- После создания туннелей агенты сообщают об этом контроллеру. Одновременно с этим агенты мониторят туннели, посылая по ним пакеты данных. Информация о состоянии туннелей в реальном времени передаётся контроллеру, который строит граф сети.
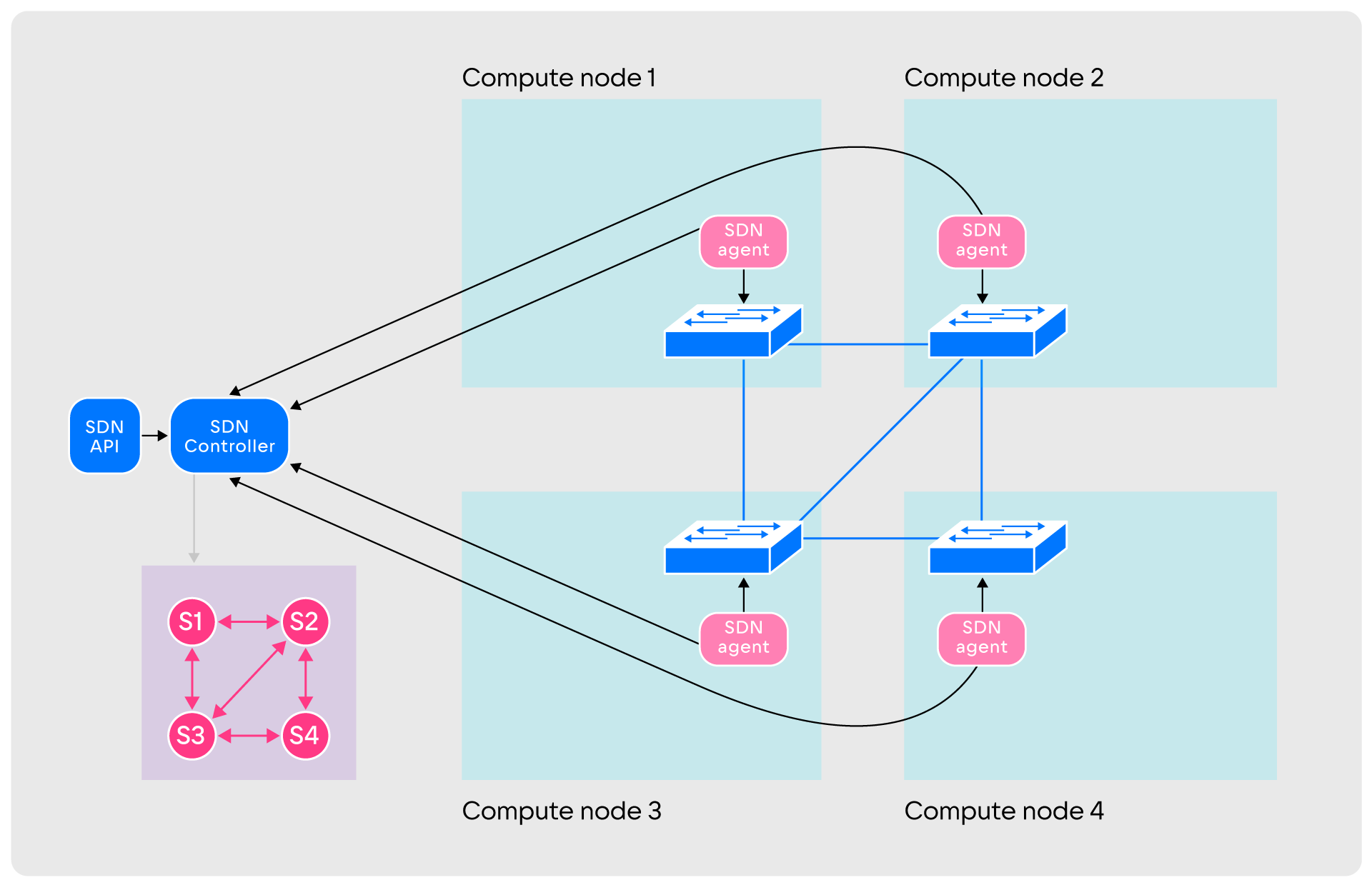 Вершины графа — коммутаторы, рёбра — построенные туннели. Граф постоянно обновляется с учётом актуальной информации
Вершины графа — коммутаторы, рёбра — построенные туннели. Граф постоянно обновляется с учётом актуальной информации
- После этого SDN готова создавать примитивы. Она работает с двумя: Link и Endpoint. Link — сущность, соединяющая два Endpoint. Endpoint — точка подключения к системе из коммутаторов. К одному Endpoint подключается только один Link, а Link соединяет не более двух Endpoint.
- При создании соединения между нодами на них через API запускаются два Endpoint. Начинается добавление событий в API и базу. Затем между Endpoint строится Link, после чего контроллер определяет кратчайший путь передачи трафика от одного узла ко второму. Для этого он использует граф сети и алгоритм Дейкстры.

Все коммутаторы на выбранном маршруте получают правила передачи трафика с указанием последовательности портов. В последующем правила загружают в агенты, которые строят маршрут на реальных свичах. Отчасти эта схема напоминает работу протокола маршрутизации OSPF.
Такой формат взаимодействия обеспечивает быстродействие и исключает ошибки при передаче трафика. Но SDN не единственный слой в SPRUT, ведь с помощью Link и Endpoint можно соединить только две виртуальные машины. Этого недостаточно для создания полноценной виртуальной сети — нужны сетевые сущности, за которые отвечает уровень NFV.
Устройство уровня NFV. По устройству уровень NFV отчасти похож на SDN:

Агенты NFV-уровня могут располагаться не на всех узлах, а только на выбранных командой эксплуатации: это помогает экономить сетевые ресурсы виртуальных машин. NFV-уровень оперирует DHCP, Switch, Router, Metadata Proxy и другими примитивами, количество функций постоянно увеличивается. Компоненты уровня взаимодействуют следующим образом:
- При запуске NFV-агенты создают определённое командой эксплуатации количество сущностей.
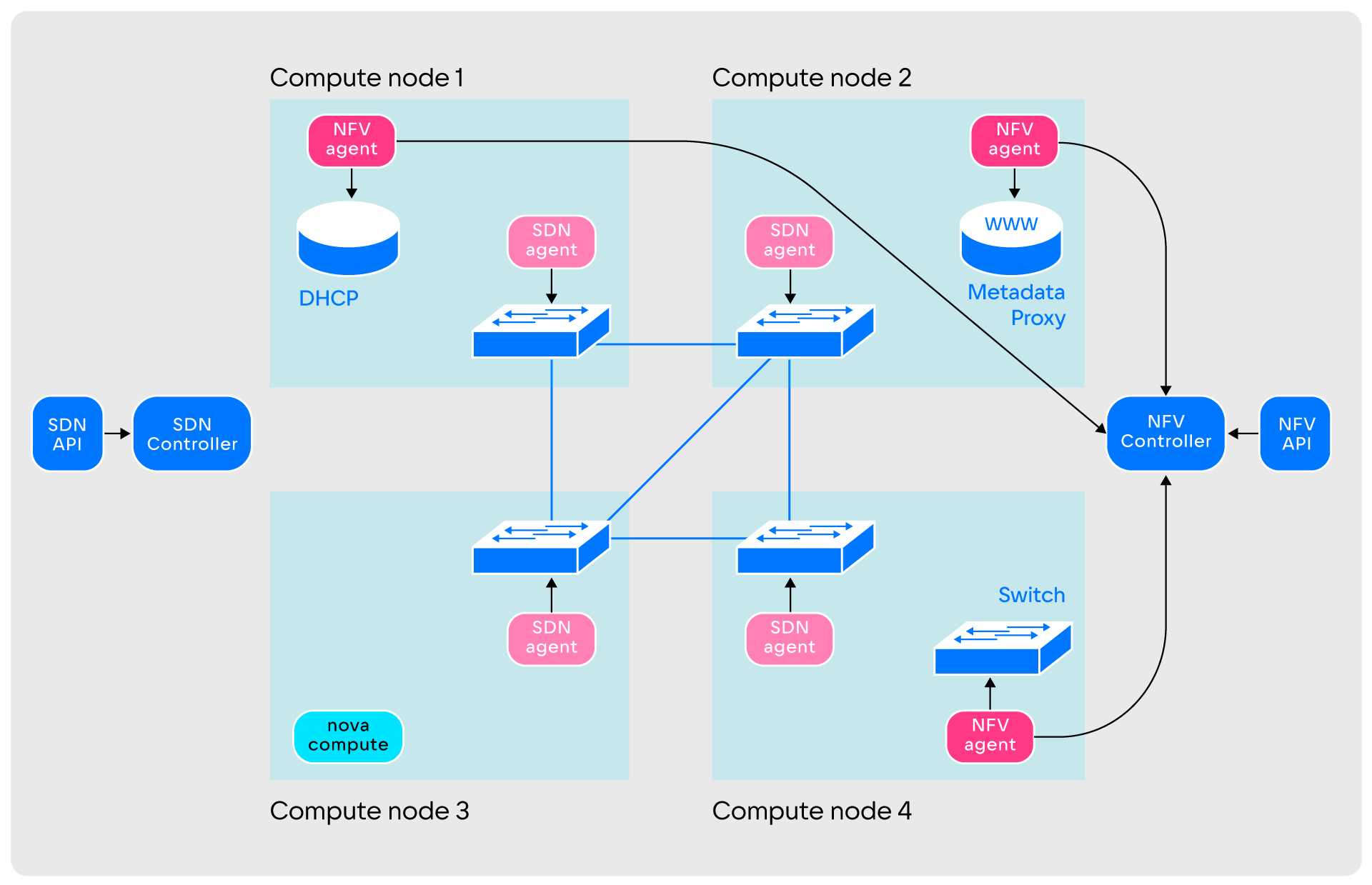 Сущности создаются пустыми и никем не используемыми
Сущности создаются пустыми и никем не используемыми
- Агенты передают информацию контроллеру. После этого уровень готов к обслуживанию пользовательских запросов.
Принцип совместной работы SDN- и NFV-уровней
На практике создание виртуальной сети с помощью SPRUT происходит следующим образом:
- Пользователь, желающий создать виртуальную сеть, делает запрос в уровень Application.
- Полученные запросы уровень Application перенаправляет и преобразовывает в набор сущностей уровней SDN и NFV.
- Из уровня NFV берутся неиспользуемые сущности и соединяются между собой с помощью Link и Endpoint. В этой сети пока не хватает только виртуальных машин.

- Дальше пользователь обращается к сервису OpenStack, ответственному за виртуальные машины. Запрос пользователя доходит до агента Nova-compute, который запускает процесс QEMU.
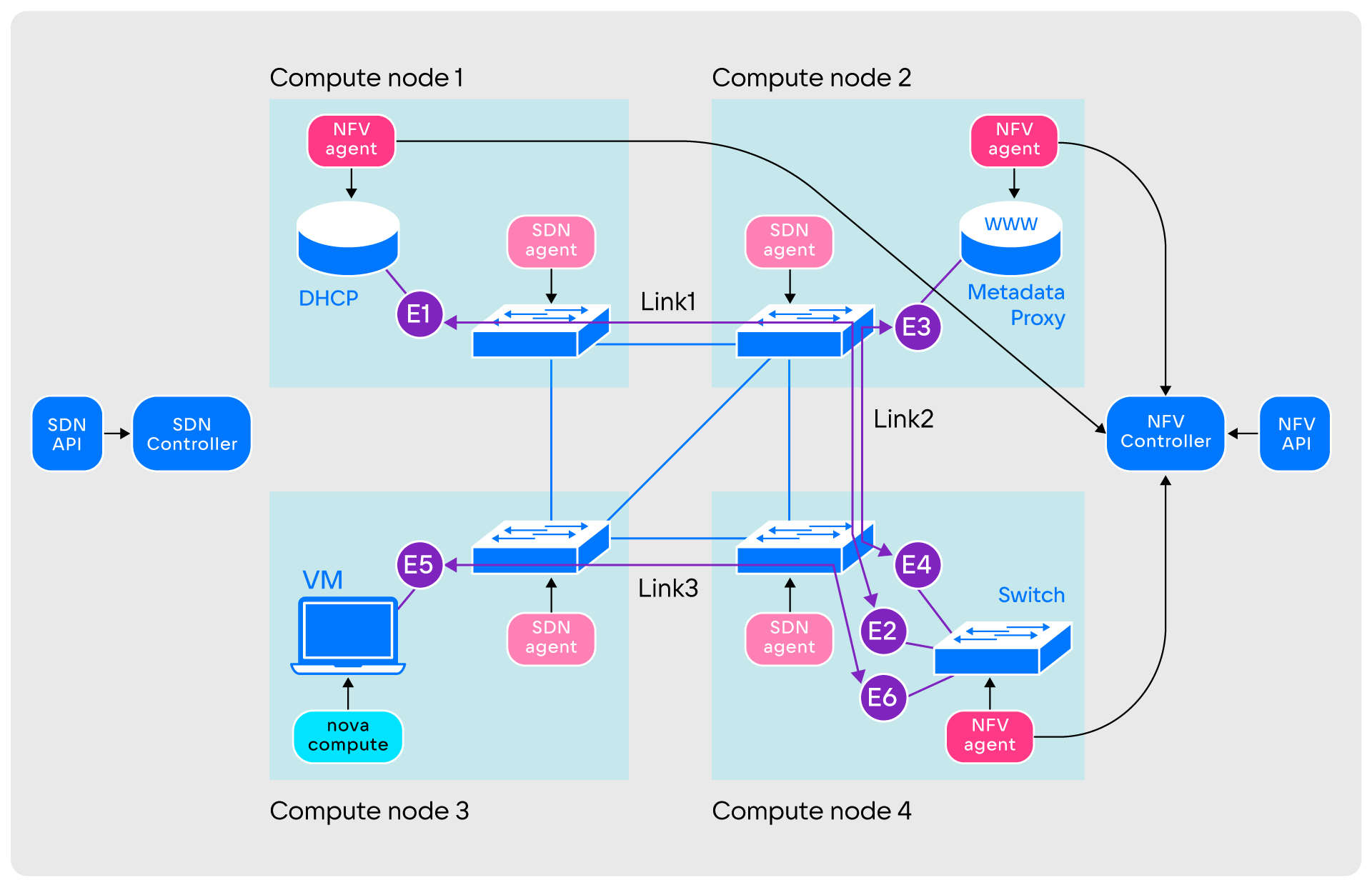
- Одновременно с запуском QEMU агент Nova-compute обращается в Application-уровень для подключения виртуальной машины к сети. В ответ на это Application-уровень создаёт набор Link и Endpoint для соединения виртуальной машины со свичем. На этом создание виртуальной сети заканчивается.
В полном варианте схема SPRUT обширнее и включает больше компонентов:
 Общая схема компонентов SPRUT. Все их мы не перечисляем, чтобы статья не стала совсем уж астрономических размеров, коснулись только самого главного
Общая схема компонентов SPRUT. Все их мы не перечисляем, чтобы статья не стала совсем уж астрономических размеров, коснулись только самого главногоУровень Application в SPRUT представляет собой кастомный плагин для Neutron, который заменяет ML2-плагин. Он отвечает за преобразование сущностей Neutron в необходимые компоненты. Аналогичный подход используют и другие SDN. Помимо этого, для стабильной работы с Nova в Sprut предусмотрен Nova Driver.
История разработки SDN в VK Cloud: сегодня и планы на завтра
22 августа 2023 года исполнилось 10 лет одной из самых успешных SDN в истории — OpenDaylight. За эти годы разработчики и архитекторы докрутили масштабируемость, выкинули множество Legacy-кода, а дальше планируют разбираться с совместимостью: много было сделано, а теперь надо удостовериться, что все они не будут мешать друг другу.
Также стало очевидно, что переход на модульную микросервисную архитектуру — это шаг, который необходимо сделать для развития продукта. Микросервисная архитектура позволяет свободнее относиться к инструментам хостинга, например контейнеризации. Как следствие — масштабируемость, управляемость и возможность снижать связность компонентов.
Наш Sprut моложе. Мы очень довольны тем, что смогли не просто воспользоваться наработками наших товарищей из индустрии, но и улучшить продукт. В результате Sprut получил ряд важных особенностей, среди которых:
- микросервисная архитектура,
- OpenVSwitch в качестве Data plane,
- интеграция с Nova и Neutron,
- внедрение и использование закрытого контура управления,
- небольшой объём кодовой базы — около 15 000 строк.
Что важно — на разработку до продакшена ушло меньше года. В будущем мы планируем допиливать продукт и обязательно расскажем, что у нас получилось.
27–28 ноября в Москве пройдет конференция Highload++. Разработчики SDN Sprut будут выступать на ней с докладом, в котором расскажут о внедрении EVPN в VK Cloud и проблемах вендорных решений.
Abcde123
Поддерживают ли ваши устройства BGP c BFD для связи с клиенскими instance в новой SDN? Это, наверное, главная проблема у AWS. Хотя там также нет, толком, поддержки IPv6 - если кто пользовался на уровне neighbour discovery, тот поймет.