
На собеседованиях на позицию middle/senior разработчика часто задают вопросы по распределенным транзакциям в микросервисной архитектуре.
Мой коллега однажды посоветовал отличную статью со сравнением основных паттернов для решения проблем распределённых транзакций.
Я проработал статью и подготовил конспект простыми словами, местами дополнил информацией из других источников и полезными ссылками.
Перед тем как начать, делюсь ссылкой на мой блог в телеграм, где я раньше всего публикую материалы по java разработке и личной эффективности.
Оглавление
Проблема двойной записи
Модульный монолит
Двухфазный коммит
Оркестрация SAGA
-
Хореография SAGA
Хореография с двойной записью
Хореография без двойной записи
Хореография с Debezium
Хореография с event sourcing
-
Parallel pipelines
Listen to yourself
Общие выводы по всем паттернам
В статье рассматриваются общие подходы к решению проблемы двойной записи, когда два микросервиса должны гарантировано, атомарно записать информацию в бд.
Каждый из рассмотренных вариантов имеет свои достоинства и недостатки, и может быть применен в промышленной разработке.
Проблема двойной записи
dual write problem
Главным индикатором проблемы двойной записи является необходимость атомарной записи в нескольких микросервисах.
Например:
ваш сервис должен обновить свою бд и также уведомить другой сервис об изменениях
имеются транзакции, выполняемые в нескольких сервисах
В нашем примере клиент вызывает микросервис А, который должен обновить бд, и данный сервис вызывает микросервис Б, который также должен выполнить операцию записи в свою бд.
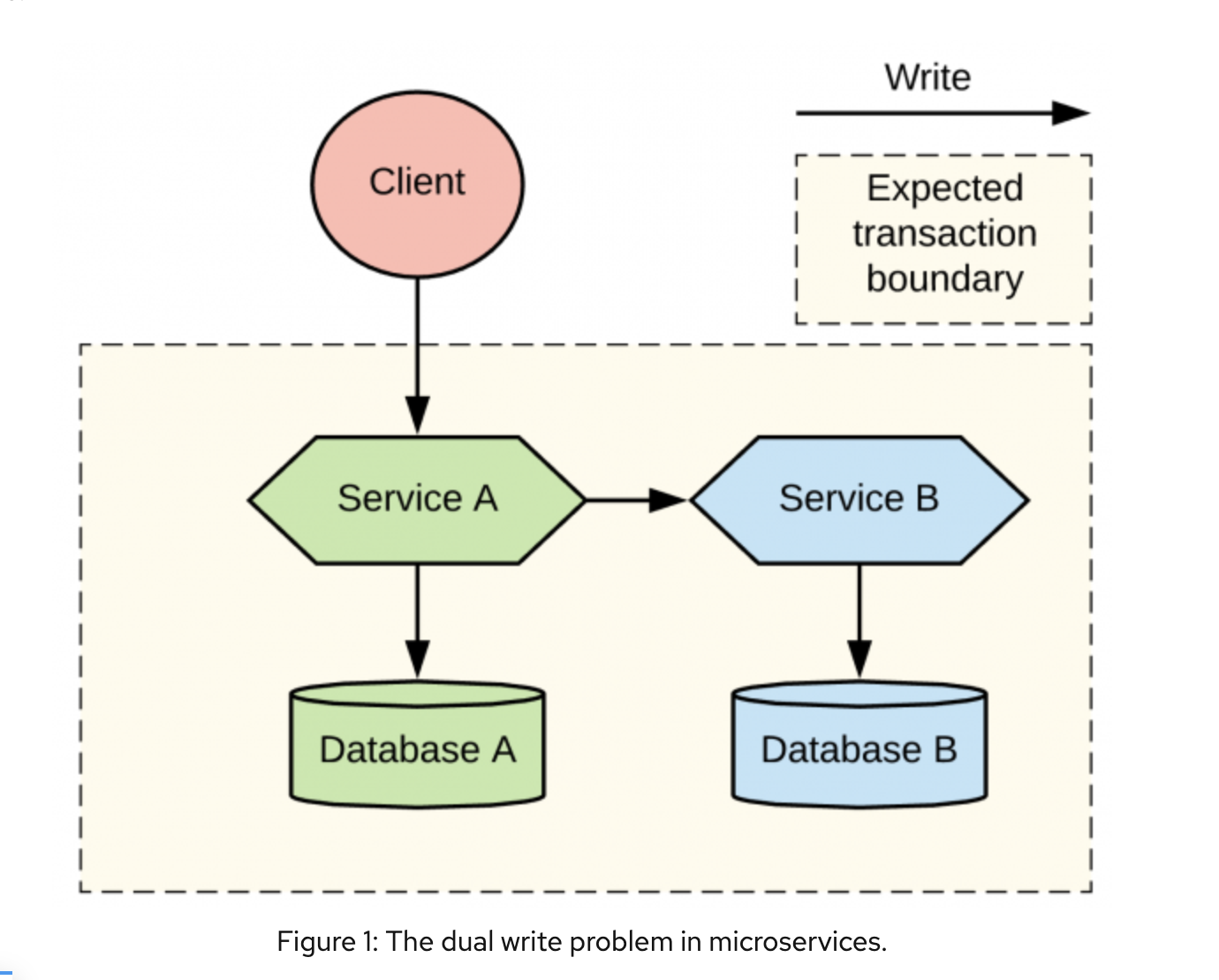
Здесь есть критичный момент, если уведомление об обновлении бд будет отправлено сервисом А после записи в бд А, то существует вероятность, что отправка прервется, из-за чего сервис Б останется в неконсистентном состоянии.
Если же сообщение будет отправлено перед записью в бд А, то есть вероятность, что запись в бд А прервется с ошибкой и сервис А останется неконсистентным.
Далее будут рассмотрены варианты решения данной проблемы
Модульный монолит
Modular monolith
Данный подход не является паттерном микросервисов, но на практике он работает хорошо, и может быть использован в микросервисной архитектуре в качестве комбинированного решения (какие-то сервисы будут представлять из себя монолитное решение, какие-то останутся микросервисами).
Подойдет, когда строгая связь между сервисами важнее, чем масштабируемость.
Архитектура модульного монолита
Наличие модульного монолита не означает что архитектура приложения плохая.
В данном подходе каждый из микросервисов А и Б является отдельной библиотекой, которые устанавливаются в общее пространство и имеют доступ к одной и той же бд.
Поскольку они находятся в одном пространстве и используют одну бд, они могут выполнять обработку в рамках одной и той же транзакции.
Тем не менее существует возможность полностью разделить два этих сервиса, даже в рамках одного монолита. Они могут смотреть на разные схемы, быть в разных пакетах, поддерживаться разными командами.
Иллюстрация разных уровней изоляции в монолитных и микросервисных архитектурах:

Последней частью данного подхода является сервис-обертка (например класс, который будет оборачивать вызовы модулей в транзакцию), который может использовать оба наших сервиса А и Б и включать их в контекст существующей транзакции.
Это увеличивает связность сервисов, но сервис-обертка позволяет запустить транзакцию, вызвать наши сервисы, обновить их бд, закоммитить или откатить транзакцию в рамках одной операции, сохраняя все в консистентном состоянии.

Плюсы Модульного монолита:
простая семантика транзакций, позволяющая легко обеспечивать консистентность данных
Минусы Модульного монолита:
единый рантайм сервисов А и Б не позволяет нам независимо деплоить и масштабировать модули, а также обеспечивать отказоустойчивость
логическое разделение таблиц в рамках одной бд не является надежным, его могут захотеть изменить
транзакция увеличивает связность между сервисами
Распределенных транзакций желательно избегать, однако они являются необходимыми в следующих случаях:
когда записи в разные бд не могут быть согласованными
когда нам приходится писать в разнородные источники данных (например в две разные бд)
когда требуется однократная обработка сообщения и мы не можем сделать операции идемпотентными
при интеграции со сторонними black-box системами (такие системы мы не можем изменить) или устаревшими системами, которые реализуют спецификацию двухфазного коммита
Двухфазный коммит
2 Phase Commit - 2PC
Технические требования для имплементации 2PC:
наличие менеджера транзакций, например Narayana
надежное хранилище транзакционных логов
все бд, к которым подключены микросервисы должны иметь совместимость со стандартном DTP XA (distributed transaction processing) (XA - extended architecture), а также mq и кеши должны поддерживать XA драйвер
если у вас есть все необходимое, но при этом приложение деплоится в динамическое окружение, такое как Kubernetes, вам понадобиться некий управляющий механизм, который будет гарантировать, что есть только один экземпляр менеджера распределенных транзакций. Транзакционный менеджер должен быть всегда доступен и для него всегда должен быть обеспечен доступ к транзакционным логам. Пример Snowdrop Recovery Controller
Пример работы 2PC в статье описан очень плохо, поэтому описание алгоритма 2PC взято из другого источника.
Код приложения в первую очередь обращается к координатору, получает номер транзакции.
С этим номером обращается к остальным системам, например к нескольким разным микросервисам, просит их внести изменения с указанным идентификатором транзакции
Затем приложение обращается к координатору с просьбой закоммитить транзакцию, после чего координатор сначала отправляет всем сигнал prepare, если все сервисы ответили успехом (они захватили write locks на своих бд), то им посылается сигнал commit.

Теперь транзакция завершена.
Протокол двухфазного коммита появился в 70-х годах.
Двухфазный коммит предлагает те же гарантии что и единая транзакция в монолите, разве что возможны ошибки в данных при падении транзакционного менеджера.
Плюсы 2PC
является стандартным решением, существуют готовые менеджеры транзакций и множество бд его поддерживают
строгая консистентность данных
Минусы 2PC
сложная конфигурация
низкая производительность
ограниченная масштабируемость (практически невозможно масштабировать)
возможные отказы, при падении менеджера транзакций
не все системы имеют поддержку (например NoSQL не интегрируются, mq или кеши могут не поддерживать спецификацию)
особые требования в динамических окружениях, таких как Kubernetes
Оркестрация SAGA
Orchestration
В модульном монолите и 2PC мы гарантируем консистентность данных.
Но что если мы хотим ослабить требования к консистентности, при этом сохранив управление из одного места. В таком случае нам подойдет оркестрация. Когда один из сервисов выступает в качестве Оркестратора для всего состояния в распределенной системе.
Оркестратор несет ответственность за вызов сервисов, до тех пор пока они не достигнуть требуемого состояния или выполнит корректирующие действия в случае возникновения ошибки. Оркестратор использует свою бд для хранения состояния изменений и он ответственен за восстановление при любом падении в процессе изменения состояния.
Внедрение архитектуры оркестрации
Наиболее популярная имплементация - BPMN спецификация, пример jBPM или Camunda.
Есть также новые решение, которые не основываются на BPMN спецификации, но предлагают похожий подход - Conductor от Netflix, Cadence от Uber, Airflow от Apache.
Также к этой категории относятся serverless statefull functions такие как Amazon StepFunctions, Azure Durable Functions, Azure Logic Apps.
Есть opensource библиотеки, которые позволяют внедрить данное поведение - Apache Camel's Saga, NServiceBus Saga.
Множество доморощенных систем имплементируют паттерн Saga.

У нас есть сервис А, который выступает как оркестратор, он вызывает сервис Б и восстанавливается от падений с помощью компенсаторной операции при необходимости.
Ключевым моментом является то, что оба сервиса работают в своих локальных транзакциях
В данном случае запрос от сервиса А к сервису Б будет выполнен в рамках транзакции.
Пример плохо прописан в статье, поэтому привожу более простое описание:
Есть один сервис-оркестратор, который запускает транзакции в остальных сервисах и если что-то пошло не так, то вызывает соответствующие компенсирующие транзакции в этих сервисах, при этом выполнение каждого из шагов обновляет текущий статус операции.
Оркестрация является подходом с консистентностью в конечном счете, которая может включать в себя реатраи и роллбеки, для поддержки консистентного состояния.
Сервисы участники данного паттерна должны предоставлять идемпотентные операции, поскольку возможно выполнение ретраев, также они должны предоставлять эндпоинты для отката транзакций, чтобы сохранять согласованность данных.
Сильной стороной данного подхода является возможность разных сервисов, не поддерживающих распределенных транзакций, оставаться в консистентном состоянии используя только локальные транзакции.
При этом всегда можно узнать текущее состояние системы у координатора.
Плюсы Оркестрации:
управление состоянием между разными сервисами в распределенной системе
нет необходимости в XA транзакциях
всегда можно узнать в каком состоянии находится система
Минусы Оркестрации:
сложная распределенная модель разработки
требует наличия идемпотентности и компенсаторных транзакций
согласованность в конечном счете
возможны невосстанавливаемые падения (unrecoverable failures) при выполнении компенсаторных транзакций
Хореография SAGA
Choreography
Альтернативным решением для Оркестрации является Хореография - где нет оркестратора, управляющего всем процессом.
В данном паттерне каждый из сервисов выполняет локальную транзакцию и публикует события, которые вызывают локальные транзакции в остальных сервисах.
Каждый компонент системы участвует в принятии решения о судьбе транзакции.
Исторически сложилось, что самой популярной имплементацией хореографии является подход использующий асинхронный обмен сообщениями для взаимодействия между сервисами.

Хореография с двойной записью
При использовании данного паттерна мы сталкиваемся с проблемой двойной записи, когда нам необходимо выполнить локальную транзакцию и отправить сообщение в очередь.
Здесь присутствуют те же недостатки:
отправить сообщение затем закоммитить - является непрактичным решением, поскольку локальная транзакция может откатиться, а сообщение уже будет отправлено
закоммитить транзакцию и затем отправить сообщение - остается возможность падения приложения после коммита транзакции и перед отправкой сообщения. Однако данное решение лучше, поскольку можно задизайнить приложение таким образом, чтобы выполнялись ретраи
Хореография без двойной записи
Одним из возможных решений является запись в рамках одной транзакции в бд и никуда не отправлять сообщение.
Пример - Сервис А сохраняет запрос и пишет в бд А. Сервис Б периодически опрашивает Сервис А и находит изменения, при обнаружении изменений Сервис Б обновляет свою бд.
Важнейшей частью данного подхода является то, что оба сервиса выполняют запись в свои бд в рамках локальных транзакций.

В данном подходе сервис Б смотрит напрямую в бд А.
Что выстраивает жесткую связность между сервисами, поскольку изменения в структуре бд на стороне сервиса А влекут за собой изменения на стороне сервиса Б.
Мы можем улучшить данный подход, создав на стороне сервиса А отдельную таблицу, которую будет читать Б, что упрощает внесение изменений.
Либо пойти дальше и создать на стороне сервиса А API для подключению к бд А.
Однако данный подход страдает от одного недостатка - необходимость постоянно запрашивать сервисом Б данные из сервиса А.
Хореография с Debezium
Один из вариантов сделать хореографию более удобной - использовать инструмент наподобие Debezium, который может отследить обновления в Сервисе А, захватывая изменение данных бд (CDC - change data capture), используя транзакционный лог базы данных А.

Debezium умеет отслеживать транзакционный лог в ожидании необходимых событий, после чего отправлять их в Apache Kafka.
Сервис Б слушает топик в Kafka, вместо того, чтобы опрашивать сервис А.
Такой подход более надежный и масштабируемый.
Возможный сайд эффект - сервис Б может получить одно и то же сообщение дважды, это может быть исправлено, если сделать сервис Б идемпотентным, или использовать подход дедубликации (Apache Active MQ duplicate message detection, Apache Camel's idempotent consumer pattern).
Данный вариант является примером паттерна Transactional Outbox, однако про него стоит почитать отдельно в данной статье.
Хореография с Event sourcing
При данном подходе состояние сущности хранится как последовательность событий, меняющих это состояние.
Атомарное добавление записи об обновлении состояния записывается в бд с помощью локальной транзакции.
При этом хранилище событий также выступает как mq для других сервисов.
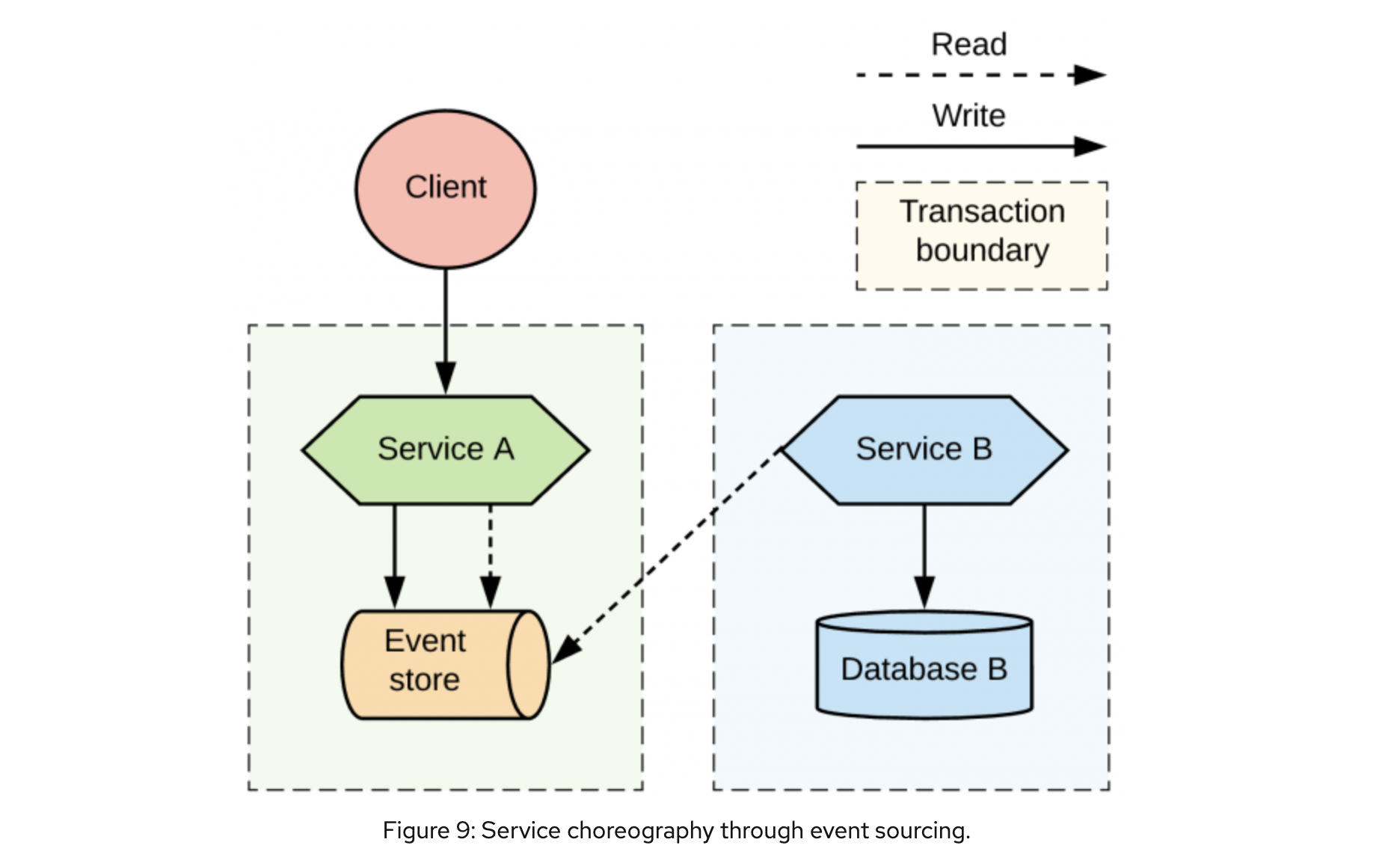
В приведенном примере запросы клиента будут храниться в append-only хранилище событий.
Также хранилище событий должно позволять Сервису Б быть подписанным на него.
Тем самым Сервис А использует свое хранилище для коммуникации с другими сервисами.
Event sourcing является непривычным подходом к программированию и добавляет сложность для воспроизведения состояния сущности.
Про него также стоит почитать подробнее в данной статье.
Плюсы Хореографии
убирает связность между реализацией и взаимодействием
нет единого координатора
улучшенная масштабируемость и устойчивость
проще при использовании соответствующих инструментов, таких как Debezium
Минусы Хореографии
глобальное состояние системы распределено по сервисам-участникам (сложно узнать текущее состояние)
согласованность в конечном счете
Parallel pipelines
Предыдущие паттерны предлагают нам последовательную обработку входящего запроса, однако возможна ситуация когда один и тот же запрос должен обрабатываться разными сервисами параллельно.
Данный паттерн подразумевает возможность параллельно обрабатывать запросы, когда между сервисом А и сервисом Б нет прямой зависимости.
Добавляется сервис router, который будет посылать сообщения в оба сервиса в рамках одной транзакции.

Listen to yourself
Еще одним вариантом parellel pipelines является ситуация, когда один из сервисов сам выступает роутером.
Тогда сервис А при получении сообщения кладет его в брокер сообщений, откуда оно будет считано как сервисом А, так и сервисом Б.

Плюсы Parallel Pipelines:
простая, масштабируемая архитектура для параллельной обработки
Минусы Parallel Pipelines:
сложно понять в каком состоянии находится системам в конкретный момент времени
Общие выводы по всем паттернам
Нет единого подхода для решения проблемы распределенных транзакций.
Каждый паттерн имеет свои достоинства и недостатки, решая свою конкретную проблему.
Таблица с характеристикой каждого подхода:


Высокая масштабируемость: Parallel pipelines и Хореография
Если сервисы не связаны между собой, то стоит использовать паттерн Parallel pipelines.
Если вам нужна обработка по порядку, то стоит использовать паттерн Хореография.
Средняя масштабируемость: Оркестрация
Если хореография не подходит и вам нужен центральный сервис, ответственный за координацию, то вам подойдет оркестрация.
Низкая масштабируемость: Модульный монолит и 2PC
Если вам нужна строгая консистентность данных, то вам подойдет 2PC, но он имеет свои требования к софту, а также его сложно имплементировать на современных отказоустойчивых кластерах.
Поэтому лучше использовать модульный монолит.
В большой распределенной системе скорее всего будет применен не один, а сразу несколько из описанных подходов, которые стоит применять по необходимости.
hard_sign
Неплохой обзор, но чуть добавлю.
Непонятно, почему у оркестратора «средняя масштабируемость». Можно же запустить любое количество экземпляров оркестратора.
Непонятно, почему в недостатках хореографии не указано наличие компенсирующих транзакций. Они там нужны так же, как и при оркестрации.
Непонятно, где в 2PC сложная конфигурация. Сами же пишете, что существует множество готовых реализаций.
Непонятно, почему у 2PC плохая масштабируемость. Если, конечно, вы хотите все транзакции пускать через единственный координатор, то да. Но ведь у каждой транзакции может быть собственный координатор! Например, так работает Apache Ignite.
Падение координатора – не единственная проблема 2PC. Стандарт вообще не предусматривает потерю узла: предполагается, что у узла есть надёжное хранилище, и если узел упал, то через некоторое время он будет восстановлен, причём содержимое его диска сохранится. Восстановление после безвозвратной потери узла – каждый раз произведение искусства.
Для полноты картины здесь можно было бы упомянуть детерминированные транзакции – это третий способ выполнения распределённых транзакций, пусть и не связанный с микросервисной архитектурой.