

Исследователи искусственного интеллекта из Университета науки и технологий Китая (USTC) и лаборатории Tencent YouTu Lab разработали инновационную структуру, получившую название «Дятел» (Woodpecker). Она предназначена для коррекции «галлюцинаций» в мультимодальных языковых моделях (MLLM).
Принципы своей работы они описывают в статье, опубликованной несколько дней назад на сервере препринтов arXiv. Их технология достаточно проста, но позволяет убрать глупые, очевидно неверные ответы, которые иногда , казалось бы, в случайном порядке выдают языковые и другие GPT-модели.

В своей работе исследователи отмечают, что «Галлюцинация — это большая тень, нависшая над быстро развивающимися мультимодальными моделями большого языка (MLLM). Проблему можно свести к тому, что сгенерированный текст не соответствует содержанию изображения. Либо на входе в модель (она неверно понимает то, что нарисовано), либо на выходе (и тогда это замечает пользователь). Это проблема, которая мешает легитимации индустрии и проникновению ее во многие сферы жизни».
Существующие решения для устранения галлюцинаций в основном требуют введения все более и более детальных инструкций, чтобы модель могла еще раз проанализировать запрос с использованием более конкретных данных. Это вызывает проблемы в тех случаях, когда пользователь сам не понимает, что галлюцинация случилась, и что выдаваемые ему данные ошибочны. Более глобальное решение, используемое некоторыми стартапами — полное переобучение моделей с использованием уточненных данных. Что может требовать больших ресурсов, и, опять же, не работает для тех галлюцинаций, которые не открылись разработчикам в процессе тестирования.
Принципы работы «Дятла»
Woodpecker предлагает не требующий обучения метод, который корректирует галлюцинации на основе генерируемого моделью текста. Система выполняет коррекцию ИИ после тщательной диагностики, включающей в себя, как объясняют разработчики, в общей сложности пять этапов:
Извлечение ключевой концепции.
Формулирование вопросов.
Проверку визуальных знаний системы.
Формирование визуальных утверждений.
Коррекцию возникающих галлюцинаций.
«Это происходит подобно тому, как дятел лечит деревья, съедая лесных вредителей. Он находит, выделяет и исправляет галлюцинации из сгенерированного текста», — говорят в публикации исследователи, объясняя название своего фреймворка.
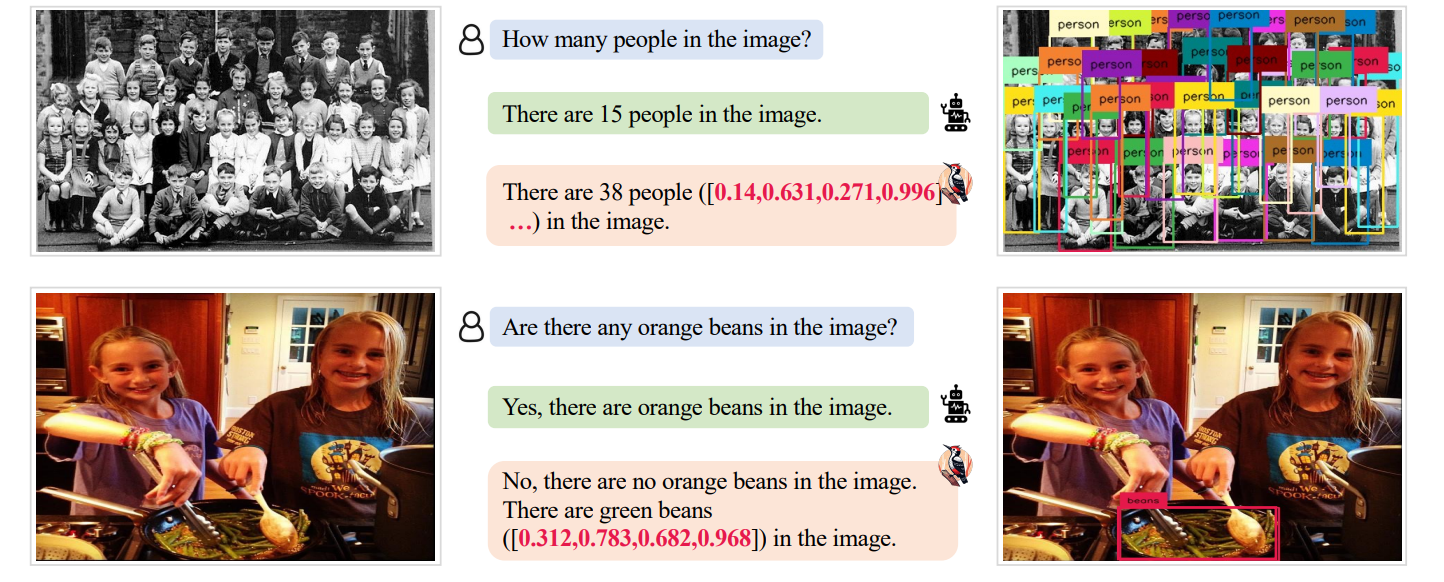
Каждый шаг конвейера прозрачен и ясен, что обеспечивает ценную для развития технологии интерпретируемость. Этапы просто идут друг за другом, проверяя и исправляя любые несоответствия между содержимым изображения и сгенерированным по нему текстом. Сначала определяются основные объекты, упомянутые в тексте. Затем «Дятел» задает вопросы об извлеченных объектах, таких как их количество и атрибуты. После этого он преобразует пары вопрос-ответ в визуальную базу своих знаний о конкретной картинке, состоящую из утверждений на уровне объекта и атрибутов (что присутствует на картинке, какого оно цвета, какое действие выполняется).
Далее «Дятел» сравнивает эту базу с ответами, получаемыми от ИИ. Находит ошибки и несоответствия. И, используя текстовые правки, модифицирует галлюцинации, добавляя к ним отсутствующие параметры. Причем это происходит в таких форматах, чтобы ИИ-модели могли их распознать: с конкретными пикселями, в которых нашлось что-то не то, а также правильным цветом и другими релевантными особенностями.
Например, если ИИ не может найти на картинке зеленую кружку, ему укажут, где именно она находится. Если он посчитал на картинке 15 людей, ему подскажут, что их на ней 38, и укажут расположение каждого. Это напоминает возможность поставить "дизлайк" ChatGPT, и рассказать, что именно он тебе выдал неверно, чтобы помочь в улучшении модели. Только автоматически, более точно, и в более крупных масштабах. По словам исследователей, уже через 600 таких «упражнений» точность модели значительно повышается, и галлюцинации в этом конкретном случае уходят.
Согласно препринту arXiv, для своей работы «Дятел» использует три отдельные модели искусственного интеллекта, помимо той MLLM, в которой он корректирует галлюцинации. Это модели GPT-3.5 Turbo, Grounding DINO и BLIP-2-FlanT5. Вместе эти ИИ работают как оценщики, выявляя ошибки и инструктируя «подопытную» модель, как генерировать выходные данные в соответствии с уточненной информацией.
Насколько «Дятел» эффективен?

Команда провела комплексные эксперименты для оценки эффективности Woodpecker, используя различные наборы данных, включая POPE, MME и LLaVA-QA90. Они говорят, что «В тесте POPE наш метод значительно повышает точность базового MiniGPT-4/mPLUG-Owl с 54,67%/62% до 85,33%/86,33%».
Этот прорыв произошел в то время, когда ИИ все больше интегрируется в различные отрасли. MLLM имеют широкий спектр применения: от создания и модерации контента до автоматического обслуживания клиентов и анализа данных. Однако галлюцинации, когда ИИ считывает информацию, отсутствующую во входных данных, стали серьезным препятствием на пути их практического применения.
Woodpecker может стать решающим шагом вперед в решении этой проблемы — открывая путь к более надежным и точным системам искусственного интеллекта. Поскольку MLLM продолжают развиваться и совершенствоваться, важность таких инструментов для обеспечения их точности и надежности невозможно переоценить.
«Дятел», с его высокой интерпретируемостью и способностью исправлять галлюцинации без необходимости переобучать всю модель, обещает изменить правила игры в мире генеративных ИИ. Исследователи опубликовали исходный код Woodpecker, поощряя дальнейшее исследование и применение платформы более широким сообществом. Вот ссылка на их GitHub: https://github.com/BradyFU/Woodpecker.
Для тех, кто хотел лично ознакомиться с возможностями Woodpecker, исследователи также разработали интерактивную демо-версию системы, которая дает возможность проверить её работу в режиме реального времени и протестировать коррекцию галлюцинаций на своих примерах. У меня их ссылка, правда, уже не работает, но может со временем её включат опять, так что на всякий случай оставлю её тут…
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
-15% на заказ любого VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Комментарии (12)


vagon333
31.10.2023 11:54Не совсем аналогия, но делаю нечто похожее для сложной обработки текста - многошаговая обработка:
Разбиваю сложный промтп на куски.
Выполняю каждый кусок и делаю проверку результата предыдущего промпта.
В добавок к проверке выполняю скрипт который бракует результат и уведомляет в канал телеги что цепочка свалилась.Результат может быть довольно сложным преобразованием.
Примечания:
Использую модель ChatGPT4 через API.
Температура всегда в 0 (чтоб получать более-менее гарантированный результат этапа).
Размер текста для моих задач не должен превышать 2к токенов, иначе GPT начинает срезать углы и филонить в качестве.
Как следствие к №3, нужно еще делать авто-разбивку текста на <2к токенов.
Как следствие к №4, нужно добавить свою считалку токенов.
По кол-ву вызвов API получается дороже, зато результат предсказуем.

akakoychenko
31.10.2023 11:54Мне кажется, что любые разбивки входа на батчи убивают саму суть LLMов, либо же, разбивалка должна быть невероятно сложной. Если мы хотим от модели решения задачи с реально большим контекстом, то наше ожидание именно в том, чтобы модель смогла вычленить из контекста > 1 факта из произвольных мест контекста и синтезировать их. Более того, понимание любого предложения из не первого батча может быть невозможным в принципе без предложения перед ним.
На первый взгляд кажется, что единственный способ обработать текст на >2K токенов и выполнить над ним задачу - это последовательно суммаризировать текст, и только после этого уже над ним работать. Условно, у нас есть текст на 10000 токенов.
Сначала даем первые 2К, и просим сжать до 400. Потом выход первого + 1600 новых и просим суммаризировать до 720, и так далее, чтобы в итоге получить исходный текст, сжатый до 2К. Но что-то, подсознательно чувствую, что работать оно не будет...vagon333
31.10.2023 11:54Если мы хотим от модели решения задачи с реально большим контекстом, то наше ожидание именно в том, чтобы модель смогла вычленить из контекста > 1 факта из произвольных мест контекста и синтезировать их.
Согласен с идеей, но практика такова что если даешь полный текст и требуешь найти все факты, то модель аккуратно вытаскивает до 15 фактов (эмпирически), а выше 15 - крайне не надежно.
Меняли промпт, заставляли перепроверять себя, представлять в виде нумерованного списка, упрашивали ничего не пропускать. Пофиг - 15+ и начинает филонить.akakoychenko
31.10.2023 11:54А пробовали через LoRA напихивать факты в более простые оффлайн модели? Все же, довольно много задач имеют хоть и большой, но достаточно постоянный контекст?

eandr_67
31.10.2023 11:54+2Например, если ИИ не может найти на картинке зеленую кружку, ему укажут, где именно она находится. Если он посчитал на картинке 15 людей, ему подскажут, что их на ней 38, и укажут расположение каждого.
Если нейросеть не смогла найти на картинке зелёную кружку, то каким образом Дятел сумеет её найти на картинке? Если нейросеть не смогла выделить всех людей, то каким образом это может сделать Дятел? Результат гарантированно ошибающейся эвристики-нейросети корректируется тремя столь же гарантированно ошибающимися эвристиками. Да, разные эвристики будут ошибаться по-разному (каждая из эвристик даст своё кол-во людей - никаких 38 в помине не будет) и во многих случаях частично нивелировать ошибки друг друга. Но будут и другие случаи - когда в результате действия Дятла правильный ответ нейросети будет заменён заведомо ошибочным.
Aquahawk
Классный способ сделать галлюцинации гораздо более сложно обнаруживаемыми. Хотя это интересный философский вопрос, люди тоже галлюцинируют же, и тем не менее цивилизация как то справляется с определённым уровнем галлюцинаций
Wizard_of_light
Ну, такова жизнь - галлюцинация, которую не удалось распознать, считается реальностью.
Kenya-West
SadOcean
Естественный отбор.
В остальном, как показывает практика, можно галлюцинировать бесконечно долго и прекрасно жить в иллюзиях.
Kenya-West
Тем не менее, чтобы продолжать галлюционировать, нужно успешно прятаться от санитаров и не привлекать их внимания. В некоторых случаях, когда галлюцинации требуют внешней подпитки, бегать придётся ещё и от местного товарища майора. Например, жить на отшибе цивилизации и успешно микродозить (осуждаю).
Тоже своего рода естественный отбор, особенно если успеть воспитать своё потомство аналогичному образу жизни.
AcckiyGerman
Вместо того, чтобы бегать от санитаров, можно убедить главврача, что твоя картина мира полезнее для управления больницей. Вон христиане 300 лет бегали, а потом (Миланский эдикт) понемногу перехватили управление
больницейбогадельней.