
Прошлая статья по данной теме была чисто теоретическая. Теперь есть готовый пакет. И данная статья - инструкция к нему.
Базовый функционал
Самое очевидное применение группировки вызовов - решение проблемы N+1 запросов. Данная проблема возникает когда фреймворк доступа к данным выполняет N дополнительных SQL-запросов для получения тех же данных, которые можно получить при выполнении одного запроса.
К примеру для получения данных имеются вызовы следующих функций, каждая из которых выполняет один SQL-запрос. При применении пакета 6 вызовов функций группируются в две группы по типу функции вызова. И в каждую группу попадают все аргументы вызова.
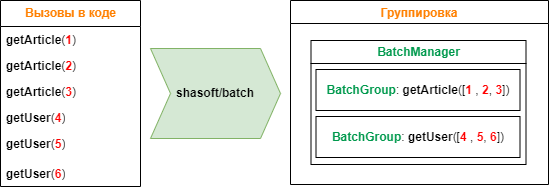
В результате вместо шести SQL-запросов будет выполнено всего два.
Код реализации алгоритма с картинки:
// Функция для получения асинхронных данных и их возврата в синхронный код
// Анонимная функция должно возвращать обещание,
// результат которого и будет возвращен из функции run
$articles = BatchManager::run(function (): BatchPromise {
// Функция all выполняет массив обещаний
// и возвращает массив значений этих обещаний
return BatchManager::all([
getArticle(1),
getArticle(2),
getArticle(3)
]);
});
// Получить информацию о статье
function getArticle(int $id): BatchPromise
{
// Создаем и возвращаем обещание
return BatchManager::create(
// Функция для обработки сгруппированных данных
function (BatchGroup $group) {
// Получить список уникальных значений аргумента с номером 0
$ids = $group->arg(0);
// Выбрать из БД информацию о статьях
$articles = sql('SELECT * FROM `articles` WHERE `id` IN (' . implode(',', $ids) . ')');
// Создадим обещания получения информации о пользователях
$promises = [];
foreach ($articles as $article) {
$promises[] = getUser($article['author_id']);
}
BatchManager::all($promises)->then(function (array $users) use ($articles, $group) {
// Сгруппировать пользователей по идентификатору
$mUsers = [];
foreach ($users as $user) {
$mUsers[$user['id']] = $user;
}
// Проставить информацию об авторе
foreach ($articles as $article) {
$article['author'] = $mUsers[$article['author_id']];
}
// Сгруппировать статьи по идентификатору
$mArticles = [];
foreach ($articles as $article) {
$mArticles[$article['id']] = $article;
}
// Вернуть информацию о статьях
$group->setResult(function (int $id) use ($mArticles) {
return $mArticles[$id] ?? null;
});
});
},
$id // Функция имеет только один аргумент (его номер = 0)
);
}
// Получить информацию о пользователе
function getUser(int $id): BatchPromise
{
// Создаем и возвращаем обещание
return BatchManager::create(
// Функция для обработки сгруппированных данных
function (BatchGroup $group) {
// Получить список уникальных значений аргумента с номером 0
$ids = $group->arg(0);
// Выбрать из БД информацию о пользователях
$users = sql('SELECT * FROM `users` WHERE `id` IN (' . implode(',', $ids) . ')');
// Сгруппировать пользователей по идентификатору
$mUsers = [];
foreach ($users as $user) {
$mUsers[$user['id']] = $user;
}
// Вернуть информацию о пользователе
$group->setResult(function (int $id) use ($mUsers) {
return $mUsers[$id] ?? null;
});
},
$id // Функция имеет только один аргумент (его номер = 0)
);
}
Функция BatchManager::all получает на вход список объектов BatchPromise, возвращаемых групповыми функциями и выполняется когда выполнятся ВСЕ обещания из переданного массива.
Цепочки вызовов
Как и все обещания в данном случае поддерживаются цепочки вызовов.
$articles = BatchManager::run(function (): BatchPromise {
return getArticle(1)
->then(function($article) {
// Функция получает значение, его можно изменить
$article['genderName'] = $article['gender']=='M' ? 'мужчина' : 'женщина';
// и передать дальше по цепочке
return $article;
})
->then(function($article) {
// Функция получает значение, его можно изменить
if( empty($article['avatar']) {
$article['avatar'] = '/avatar/default.png';
}
// и передать дальше по цепочке
return $article;
});
});
Обработка ошибок
Каждая функция (обещание) может генерировать ошибку. В отличии от обещаний в том же JavaScript я в своем пакете пошёл другим путем. Вместо указания отдельной функции для получения ошибки необходимо возвращать эту ошибку с помощью вызова BatchError:create(). В качестве примера перепишем функцию getUser.
// Получить информацию о пользователе
function getUser(int $id): BatchPromise
{
// Создаем и возвращаем обещание
return BatchManager::create(
// Функция для обработки сгруппированных данных
function (BatchGroup $group) {
// Получить список уникальных значений аргументов с номером 0
$ids = $group->arg(0);
// Выбрать из БД информацию о пользователях
$users = sql('SELECT * FROM `users` WHERE `id` IN (' . implode(',', $ids) . ')');
// Сгруппировать пользователей по идентификатору
$mUsers = [];
foreach ($users as $user) {
$mUsers[$user['id']] = $user;
}
// Вернуть информацию о пользователе
$group->setResult(function (int $id) use ($mUsers) {
// Возвращаем ошибку если по идентификатору ничего не выбралось
return $mUsers[$id] ?? BatchError::create("Пользователь {$id} не найден",$id);
});
},
$id
);
}
При создании ошибки необходимо указать текст + (опционально) код ошибки. Также класс работы с ошибками содержит статические методы для удобной обработки ошибок.
// Работа с ошибками
class BatchError
{
// Создать ошибку
static public function create(string $message, ?int $code = null): static;
// Создать ошибку отсутствия значения
static public function createUndefined(): static;
// Значение является ошибкой?
static public function has(mixed $value): bool;
// Все значения массив являются ошибками?
static public function hasErrors(array $values): bool;
// Отфильтровать массив значений удалив: true - ошибки/ false - не ошибки
static public function filter(array $values, bool $removeError = true): array;
// Заполнить ошибки значениями
static public function fill(array $values, mixed $value): array;
}
Приоритизация
В нашем случае группы будут выполняться последовательно. Т.е. в каждый момент времени в списке групп будет только одна группа. В более сложной ситуации групп может быть несколько. И в этом случае важно в какой последовательности они будут выполняться.
Возьмем пример с картинки. Предположим у нас в очереди сразу две группы: getArticle и getUser. В зависимости от последовательности выполнения групп у нас будет выполнено разное количество SQL-запросов. При такой последовательности getArticle, getUser 2 запроса: getArticle, getUser. При такой - getUser, getArticle, getUser 3 запроса: getUser, getArticle, getUser.
В первом случае после выполнения группы getArticle будут добавлены вызовы в группу getUser, а потом она выполнится. Во втором случае выполняется группа getUser, а после выполнения группы getArticle будет создана ещё одна группа getUser.
В функционале предусмотрен способ задания приоритизации с помощью расширенного создания обещания:
// Получить информацию о пользователе
function getUser(int $id): BatchPromise
{
// Создаем и возвращаем обещание
return BatchManager::createEx(
// Функция указания расширенных настроек
function (BatchGroupConfig $config) {
// Указываем пониженный приоритет (чтобы эта группа выполнялась последней)
$config->setPriority(BatchManager::PRIORITY_LOW);
},
// Функция для обработки сгруппированных данных
function (BatchGroup $group) {
// ...
},
$id
);
}
Теперь в независимости от того в какой очередности группы находятся в списке для выполнения, группа с пониженным приоритетом будет выполнена последней.
Для более рациональной работы необходимо для групп, которые не создают других групп, указывать пониженный приоритет. Чтобы они выполнялись в последнюю очередь.
Кэширование
Дополнительная полезная возможность использования функций группировок вызовов - это кэширование результата работы. Для этого Все функции разделяются на несколько видов:
Функция без КЭШирования
Это функция по-умолчанию. Значение функции не КЭШируется.
Функция вида LifeTime - кэширование на время
Самый простой вариант кэширования.
class ExampleCacheLifeTime
{
// Функция вида LifeTime - кэширование на время
static public function fnLifeTime(int $x): BatchPromise
{
return BatchManager::createEx(function (BatchGroupConfig $groupConfig) {
// Установить тип функции = LifeTime, установить время жизни = 5 минут
$groupConfig->setCacheLifetime(5 * 60);
}, function (BatchGroup $group) {
// Функция получения результата для каждого набора аргументов
$group->setResult(function (int $minValue) {
// Вернуть случайное число от $minValue до 1000
// и кэшировать это значение на 5 минут
return random_int(min($minValue, 1000), 1000);
});
}, $x);
}
}
Функции вида Get/Put - кэширование до изменения значения
Тип функции Get устанавливается в параметрах расширенного вызова + необходимо указать функции вида Put, от которых эта функция зависит. Если зависимостей нет, то кэширование выполняется навсегда. Если зависимости указаны, то значение кэшируется до изменения текущих значений.
// Пример функции Get и Put
class ExampleCacheGetPut
{
// Хранение значений
static protected array $data = [];
// Функция вида Get
static public function fnGet(int $x): BatchPromise
{
return BatchManager::createEx(function (BatchGroupConfig $groupConfig) {
// Установить тип функции = Get
$groupConfig->setCacheGet();
}, function (BatchGroup $group) {
// Функция получения результата для каждого набора аргументов
$group->setResult(function (int $x) {
// Читать текущее значение
$ret = self::$data[$x] ?? 0;
// Установить зависимость от функции вида Put
self::fnPut($x, $ret);
// Вернуть результат
return $ret;
});
}, $x);
}
// Функция вида Put
public function fnPut(int $x, int $value): BatchPromise
{
return BatchManager::createEx(function (BatchGroupConfig $groupConfig) {
// Установить тип функции = Put
// Указать список индексов ключевых аргументов
$groupConfig->setCachePut(0);
}, function (BatchGroup $group) {
// Функция получения результата для каждого набора аргументов
$group->setResult(function (int $x, int $value): void {
// Установить значение
self::$data[$x] = $value;
});
}, $x, $value);
}
}
Для работы кэширования необходимо установить объекты КЭШирования.
// Установить глобальные интерфейсы КЭШа
BatchConfig::setICache(CacheItemPoolInterface|callable|null $cacheGet, CacheItemPoolInterface|callable|null $cachePut = null): void;
В качестве параметров можно указать либо объект интерфейса КЭШа CacheItemPoolInterface либо замыкание которое такой объект возвращает.
Имеется два КЭШа:
Для сохранения значений функций вида Get (хранит значения результатов работы функций Get).
Для сохранения значений функций вида Put (хранит значения зависимостей функций вида Put). Если указать только аргумент $cacheGet, то аргумент $cachePut будет автоматически установлен в то же значение.
Как работает кэширование вида Get/Put?

Описание шагов:
(1) КЭШ Put и Get пустые.
(2) Вызываем функцию fnPut(2,7) в результате в КЭШ-е Put сохраняется значение 7 с ключом fnPut,2.
(3) Вызываем функцию fnGet(2). Функция проверяет значение в КЕШе Get, не находит его и вызывает групповую функцию fnGet в аргументом 2, получает результат 14 и сохраняет в КЕШ полученный результат + зависимые значения.
(3а) Вызываем функцию fnGet(2). Функция проверяет значение в КЕШе Get по ключу fnGet,2, находит его и получает значение 14. Также считывается список зависимостей и проверяется что все зависимости соответствуют значениям в КЭШе Put. В данном случае они соответствуют и возвращается значение 14. Т.е. значение берется из КЭШа и групповая функция не вызывается.
(4) Вызываем функцию fnPut(2,9) в результате в КЭШ-е Put сохраняется значение 9 с ключом fnPut,2.
(5) Вызываем функцию fnGet(2). Функция проверяет значение в КЕШе Get по ключу fnGet,2, находит его и получает значение 14. Также считывается список зависимостей и проверяется что все зависимости соответствуют значениям в КЭШе Put. В данном случае они НЕ соответствуют (7!=9) и поэтому вызывается групповая функция которая возвращает значение 18. После сохраняет в КЕШ Get полученный результат + зависимые значения.
Режим работы с КЭШем
Групповая функция с кэшированием хороша, но иногда необходимо чтобы такая функция игнорировала значения в КЭШе и выполняла прямое чтение значения через групповую функцию. И такая возможность есть. Каждая функция возвращает объект BatchPromise содержащий метод setCacheMode, который позволяет установить следующий режим работы:
BatchPromise::MODE_CACHE_OFF - отключить КЭШирование. Т.е. в независимости от типа функции она будет вызвана так как обычная функция. И результат её работы не будет сохранен в КЭШе.
BatchPromise::MODE_CACHE_DIRECT - отключить КЭШирование, но сохранять изменения в КЭШ. Т.е. в независимости от типа функции она будет вызвана так как обычная функция. И результат её работы будет сохранен в КЭШе.
BatchPromise::MODE_CACHE_ON - включить КЭШирование (значение по умолчанию). Т.е. функция работает в режиме КЭШирования - читает и сохраняет значения в КЭШ.
Комментарии (15)

SpiderEkb
10.11.2023 05:47Подход интересный, но тут сразу вопрос возникает - это как-то тестируется на нагрузку? Есть какие-то цифры, показывающие что такой подход работает быстрее? На сколько быстрее?
SQL вообще "вещь в себе". Недавно как раз возились - достаточно сложный запрос (ну примерно на экран размером (по 5-ти таблицам, два вложенных подзапроса, куча условий). Работает плохо - почти 25 минут на копии промсреды (таблицы объемные - по несколько десятков миллионов записей).
План получается примерно вот такой

Крутили-вертели так и этак, потом решили выкинуть две проверки существования записи в одной из таблиц. Фактически, "обрезали хвост ему"
// and ( // ( // CLTP = 'P' and HDA1DAT >= :BlockDte and // not exists // ( // select RDKMCUS // from RDKMPF // where (RDKMCUS, RDKMCLC, RDKMSTS, RDKMTP) = // (HDA1.HDA1CUS, HDA1.HDA1CLC, '01', '9') // ) // ) // or // ( // HDA1DAT < :BlockDte and // not exists // ( // select RDKMCUS // from RDKMPF // where (RDKMCUS, RDKMCLC, RDKMSTS, RDKMTP) = // (HDA1.HDA1CUS, HDA1.HDA1CLC, '01', 'A') // ) // ) // );Да, запрос получается "избыточным" - отдает данных больше чем нужно, потом они просеиваются уже в процессе постобработки. Но результат шокировал - план запроса стал намного проще

а время выполнения (задачи полностью, с фильтрацией выборки) на тех же данных сократилось с 24.5мин до 209сек. В 7(!!!) раз...
Правда, тут небольшая хитрость - наш инструментарий позволяет не только SQL доступ к БД, но и прямое обращение - позиционирование в индексе, прямое чтение записи... А для проверки наличия записи (просто есть-нет) читать ее не нужно, просто проверить есть ли она в индексе или нет. И вот этот многострочный "хвост", который все портил, превратился в
setll (dsSQLData(row).CUS: dsSQLData(row).CLC: '01': msgTyp) RDKM02LF; if not %equal(RDKM02LF); .... endif;setll позиционируется в индексе на записи со значением индекса равным или меньшим заданному. %equal возвращает индикатор точного позиционирования (встали на запись именно с таким значением индекса, а не меньшим) - т.е. такая запись в БД есть.
А было еще веселее как-то. Тоже сложный запрос, оптимизировали, результат хороший, но в плане видим фуллскан по одной из таблиц. Оптимизатор предлагает добавить новый индекс. Ну ок. Добавили - ну раз сам оптимизатор предлагает... Наверное еще лучше станет...
Черта с два! Становится хуже, дольше. Потому что оно начинает фуллсканить по другой, кратно более тяжелой таблице. Плюнули, убрали индекс, оставили первоначальный вариант.
Так что еще раз - вот эти игры с объединением запросов - они дают реальный выхлоп в скорости выполнения? Вы это как-то контролируете?

mayorovp
10.11.2023 05:47Да, все эти игры с объединением запросов - они дают реальный выхлоп в скорости выполнения на стандартных архитектурах. Этот "выхлоп" обусловлен сетевой задержкой. Вы его не видите потому что общаетесь с СУБД не через сеть.
К слову, при работе с SQLite тоже никто не объединяет запросы.
SpiderEkb
10.11.2023 05:47Ок. Я ж не против. Просто к тому, что SQL штука хитрая и не всегда интуитивно очевидная. Неоднократно сталкивался с тем, что для двух, несколько по разному сформулированных запросов, оптимизатор строит один и тот же план.
Потому и спросил - все эти игры проверяются на конечный результат? Если да и он есть (не важно - за счет оптимизации сетевого трафика или еще за счет чего) - замечательно. Если нет - зачем?
Понятно, что везде разные условия. Мы работаем в пределах сервера - нам не страшно сделать более линейный запрос (например, не использовать агрегирование - оно достаточно затратное) с избыточностью выборки и просеять ее уже в постобработке. А когда результат отдается в сеть, на избыточности можно очень много потерять.
Просто в таких статьях хочется более подробный анализ видеть - сколько выиграли, за счет чего выиграли, во что это обошлось... Тогда все это и в личную копилку опыта откладывается.
mayorovp
10.11.2023 05:47Некоторые оптимизации настолько очевидны, что не нуждаются в измерении.
Условно, когда запрос, который выполнялся секунд 20, начинает выполняться меньше чем за секунду - вот вообще нет смысла ни проводить точные измерения, ни сохранять старый код для потомков.
Какой смысл в подробном анализе, когда программа переходит из качества "невозможно пользоваться" в качество "можно пользоваться"?
SpiderEkb
10.11.2023 05:47+1Некоторые оптимизации настолько очевидны, что не нуждаются в измерении.
Увы, это не всегда так. Приводил пример выше - реализуем рекомендацию оптимизатора, добавляем индекс (вроде бы "очевидная оптимизация") и становится хуже.
Условно, когда запрос, который выполнялся секунд 20, начинает выполняться меньше чем за секунду - вот вообще нет смысла ни проводить точные измерения
"Выполнялся за 20 секунд" и "выполняется меньше чем за секунду" - это уже измерения, нет?
Кроме того, SQL может строить разные планы для одного и того же запроса в зависимости от объема данных - на тестовом сервере, где данных мало и на проме, где данных много планы будут разными.
Другое дело, что если время передачи выборки клиенту по сети занимает, условно, 10сек, то практически не важно выполняется выборка за секунду или за 5 секунд (если речь идет об асинхроне) - основное время потратится не на выборку, а на передачу ее клиенту.
Какой смысл в подробном анализе, когда программа переходит из качества "невозможно пользоваться" в качество "можно пользоваться"?
Вопрос философский. Вот чем занимался сейчас? Оптимизацией старого кода. Есть некий бизнес-процесс - 5 модулей, запускаются каждый день, последовательно один за другим в некоем временном окне. Написаны были достаточно давно, когда у нас было 20-25млн клиентов. И тогда это было "можно пользоваться" - время работы всех устраивало.
Сейчас у нас 50млн клиентов и все это стало работать неприлично долго - 45 минут. Т.е. оно работает, но тормозит другие процессы и грозит выходом за рамки допустимого временного окна.
Пришлось потратить определенное время на оптимизацию - исследование логики, тесты разных подходов, прогоны с измерением времени, регресс-тесты... В результат удалось сократить время работы (суммарное) до 10ти минут.
Если бы тот человек, который это писал тогда, сразу сделал бы нормально (вдумчиво, не по принципу "можно пользоваться", а "сделали максимально эффективно"), я это время потратил бы на что-то другое, более актуальное на текущий момент.
Т.е. вопрос в том, что "можно пользоваться сейчас" совершенно не означает что через год-два этим по прежнему будет "можно пользоваться". Увы, но вот так вот...
mayorovp
10.11.2023 05:47+1Добавление индекса в сложный запрос - не такая и очевидная оптимизация. Лично мне тут скорее очевидно что одним индексом дело не ограничится.
Это вообще не похоже на оптимизацию вида "отправить вместо 100 запросов 1".
"Выполнялся за 20 секунд" и "выполняется меньше чем за секунду" - это уже измерения, нет?
Измерения - это когда есть инструменты для измерения, а подобная разница ловится без всяких инструментов.
Кроме того, SQL может строить разные планы для одного и того же запроса в зависимости от объема данных - на тестовом сервере, где данных мало и на проме, где данных много планы будут разными.
Ага, и это тоже сильно мешает анализу. При работе над новым проектом, у которого нет никаких накопленных данных, многие оптимизации приходится делать без всякого анализа, просто на основе опыта. Потому что план запроса смотреть бесполезно, а измерять время ещё бесполезнее.
Если бы тот человек, который это писал тогда, сразу сделал бы нормально (вдумчиво, не по принципу "можно пользоваться", а "сделали максимально эффективно"), я это время потратил бы на что-то другое, более актуальное на текущий момент.
Ага, а теперь внимание вопрос: как тот человек мог сделать всё сразу нормально, если смотрел исключительно на планы запросов и замеры времени на тех данных?
Чтобы сделать "сразу нормально", надо опираться не только на планы запросов и замеры времени, но и на теоретические рассуждения.
SpiderEkb
10.11.2023 05:47Измерения - это когда есть инструменты для измерения, а подобная разница ловится без всяких инструментов.
Ну я могу только по своему опыту говорить.
У нас запросы все достаточно сложные. И "сразу в код" никто никогда их не пишет. Сначала все это гоняется в интерактивном режиме - просто в окне пишешь запрос, "выполнить", видишь результат. Там же оно напишет за сколько времени запрос выполнился. Там же можно "демонстрировать" - попросить нарисовать план запроса, посмотреть рекомендации оптимизатора.
Какой-никакой, но инструмент. По крайней мере, когда вставляешь в код, то уже знаешь что это рабочий запрос который выдает нужный результат.
Потому что план запроса смотреть бесполезно, а измерять время ещё бесполезнее.
Ну не совсем. Если я вижу что один запрос выполняется 6 секунд, второй 4.5секунды, а если от него "откусить хвост" (как показано выше), то сразу 1.2 секунды, то все это дает некоторую информацию к размышлению.
Конечно, последняя инстанция - нагрузочное тестирование на копии промсреды, но там очередь из задач и просто так дергать людей, которые этим занимаются, не станешь. Это уже заключительный (но обязательный у нас) этап.
как тот человек мог сделать всё сразу нормально, если смотрел исключительно на планы запросов и замеры времени на тех данных?
А это уже опыт. Когда примерно понимаешь как оно работает, то понимаешь какую часть логики стоит втащить в сам запрос, а какую вынести из него на постобработку где она будет реализована быстрее (скажем, агрегирование в запросах, особенно сложных, в подавляющем большинстве случаев на постобработке выборки работает быстрее - дробление логики дает лучший результат, чем переусложнение запроса втаскиванием туда всей логики целиком). И когда получаешь результат "вроде работает", просмотреть его еще раз и подумать - нельзя ли где-то сделать быстрее, эффективнее (в принципе, не только запросов касается, но кода вообще).
Как пример - вот этот тип контейнера здесь кажется очевидным и удобным в использовании. Но если подумать, то понимаешь, что в данной конкретной задаче быстрее будет работать другой контейнер (с иной внутренней логикой), даже несмотря на то, что строк кода там получится чуть больше.
Когда изначально пишешь код, то идешь по логике ТЗ. Когда просматриваешь его второй-третий раз, то уже видишь, что вот тут два цикла один за другим, но если чуть подправить, то можно все уложить в один.
К сожалению, часто вижу что вот этот "второй-третий раз" свой код никто не смотрит на предмет "а можно ли это же сделать быстрее" - как написалось, так и написалось.
Часто сталкиваешься необходимостью создания и решения параллельной подзадачи для более эффективного решения основной. Как пример:
Есть некая сущность, которая хранится в "исторической" таблице (вся история изменений - кто, когда менял). Но значительная часть потребителей пользуется только актуальным значением сущности - с максимальной датой последнего изменения. А это значит, что каждый раз требуется агрегирование - having max(...) group by ... Что достаточно долго.
Делаем подзадачу на создание "витрины" - дополнительная таблица, где хранится только самое последнее, актуальное значение сущности. Для нее потребуется реализовать как минимум скрипт начального заполнения (чтобы оно само заполнилось при развертывании поставки) и механизм "ведения" - любые изменения в исторической таблице автоматически отражаются в витрине.
После этого уже везде, где было использование этой сущности с агрегированием по исторической таблице, используется витрина без агрегирования, просто чтение записи по уникальному ключу. Что, естественно, быстрее.
Но обо всем этом надо думать на этапе разработки, а не просто "херак-херак, вроде как-то работает, в продакшн". Т.е. исходить из принципе "всегда делаем максимально эффективно". Тогда на последующее масштабирование остается больший запас.
mayorovp
10.11.2023 05:47У нас запросы все достаточно сложные. И "сразу в код" никто никогда их не пишет. Сначала все это гоняется в интерактивном режиме - просто в окне пишешь запрос, "выполнить", видишь результат.
Это у вас. А тут обсуждаются запросы вида getArticle.
Ну не совсем. Если я вижу что один запрос выполняется 6 секунд, второй 4.5секунды, а если от него "откусить хвост" (как показано выше), то сразу 1.2 секунды, то все это дает некоторую информацию к размышлению.
Я же писал: на старте проекта, когда никаких накопленных данных нет в принципе. На пустой базе вы никак не получите 6 секунд.
Да, чем больше данных уже есть, тем проще смотреть на запросы. У вас эти данные есть, вам проще.
А это уже опыт. [...]
Вы сейчас с чем спорите?
SpiderEkb
10.11.2023 05:47Я же писал: на старте проекта, когда никаких накопленных данных нет в принципе. На пустой базе вы никак не получите 6 секунд.
Так подумать и сразу не пихать в запрос всю логику. Вынести агрегирование в постобработку, например. Избавиться от лишних циклов. Использовать не те типы контейнеров, которые первыми на ум пришли, а те, что лучше под конкретную задачу подходят... Там много чего такого, что не требует наполненной под завязку базы. Просто общие подходы к разработке.
Многие просто суммируют коллективный опыт в виде набора "нефункциональных требований к разработке".

shasoftX Автор
10.11.2023 05:47+1Это инструмент. А вот насколько он ускорит процесс и ускорит ли, это уже зависит от того как его применить.


Andreyika
Все очень интересно.. похоже на библиотеку для тех, кому тимлид запретил передавать массивы в аргументы функций и ему прям крайне необходимо использовать getArticle(1) + getArticle(2) вместо getArticles([1,2]).
Вроде бы никакой другой функциональности (если не считать кэширования, которое тут вообще сбоку) оно не несет... ну еще вместо десятков строчек кода делает несколько сотен
shasoftX Автор
Вы не очень хороший пример взяли. Лучше в данном случае брать функцию getUser(). Т.е. вы выбрали список статей, потом вам для каждой нужно выбрать информацию об авторе. Для этого вам необходимо
Собрать список уникальных идентификаторов пользователей
Выбрать данные по пользователям
Распихать полученные данные по статьям
Пакет делает всё это автоматически. При этом вам достаточно написать функцию getUser() один раз и потом вы можете использовать её и для статей, и для комментариев, и для постов. Т.е. вы получаете единую функцию для всего. Да к тому же с кэшированием результата работы.
Andreyika
Не вижу ничего автоматического.. вот вообще не вижу. Все эти распихивания вы делаете вручную в foreach.
Давайте попробуем провести рефакторинг "избавление от ненужного пакета"
Вот основной код.. в общем-то на этом этапе мы уже знаем все айдишники статей
и просто перемещаем их в аргумент функции getArticles
теперь из getArticles просто убираем ваш пакет и делаем небольшое изменение
Ну и финально выпиливаем пакет из getUsers
а теперь подскажите, какую функциональность / синтаксический сахар / удобство я потерял?
Кэш - вопрос отдельный, всякие коллекции тоже вполне реализуются кучей других пакетов
а что мне помешает даже в таком варианте получить сначала комментарии, а потом пользователей? вроде ничего.
т.е. по итогу не понятно, зачем делать какой-то нечитаемый вообще код. ради каких плюшек?
shasoftX Автор
(1) Вы потеряли возможность кэшировать результат выполнения. При использовании пакета вы пишете одну функцию без оглядки на кэширование. Указываете объект кэширование и всё работает.
В случае с тем кодом что у вас получился после выпиливания, вам необходимо в каждой функции это самое кэширование прикручивать.
При этом результат работы функции может кэшироваться не по времени, а до момента изменения. Т.е. вызвали вы функцию getUser(1), результат кэшировался до момента изменения. Если пользователь c id = 1 данные меняет раз в месяц, то они так и будут лежать месяц в кэше, без запроса из БД.
(2) Вы опять смогли показать что любой пример можно переписать вручную более оптимально. Но давайте попробуем изменить постановку. Допустим нам нужно выбрать статью 1 + выбрать комментарии к этой статье. Каждый комментарий содержит автора. В моем примере я напишу функцию getComments($id,$type) { ...getUser()... } после чего сделаю вызов
И на выходе получу статью и список комментариев. При этом будет 3 запроса:
-Выборка информации о статье
-Выборка списка комментариев
-Выборка информации о пользователях (т.е. один запрос для выборки информации по автору статьи и авторам комментариев)
Ваш код нужно сильно усложнять для получения тех же трех запросов, потому что вам придется вызывать функцию getUsers и в getArticle и getComments. И в случае синхронного кода у вас будет два разных вызова и две разных выборки из БД.