
Я писал ранее статью Генерация API сайта на основе заданных пользователем функций, однако информация там была о конечной реализации (к тому же теоретической), и, ожидаемо, никто не понял для чего это вообще нужно. Поэтому попробую расписать это с другой стороны: от задачи к её решению через генерируемое в Samoyed CMG API.
Описание задачи
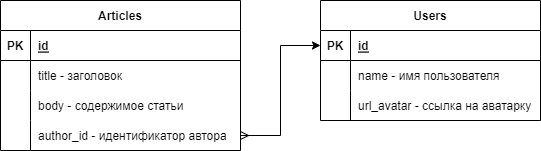
Пусть у нас есть небольшой сайт со списком статей с пагинацией. Статьи пишут пользователи сайта.
На главной странице выводим список последних 10 статей. В списке заголовок и автор. При нажатии на заголовок выводится страница с выбранной статьёй. На странице статьи выводится заголовок, содержимое + автор.
Простейшая схема таблиц базы данных представлена ниже.
Реализация
Сайт имеет два маршрута:
- index.html — главная страница со списком статей
- article/{id}.html — страница статьи
Для реализации описанного выше требуются следующие функции:

- articleList(int nPage, int countPerPage=10) — возвращает список статей. Получить список статей для страницы nPage, количество статей на странице = countPerPage
- articleGet(int id) — возвращает информацию о статье id
- articlePut(int id, array data) — изменить данные о статье id
- userGet(int id) — получить информацию о пользователе id
- userPut(int id, array data) — изменить данные пользователя id
Вот и вся реализация backend-а. Функции вида get возвращают данные, которые мы в контролерах передаём в шаблоны и генерируем на сервере страницу для клиента. Сами функции отделяют логику от представления. Функции вида put изменяют данные. Такой подход позволит, при необходимости, изменить логику работы этих функций без переписывания кода, который их использует.
В силу простоты реализацию функций приводить не буду, так как это просто один SQL запрос на функцию.
Реализация с кешированием
Описанная выше реализация будет отлично работать при небольшом количестве пользователей на сайте. Однако если их количество будет расти (а это задача любого сайта), то начнутся проблемы из-за максимального количества соединений с БД. Т.е. если вдруг 100 человек одновременно откроют сайт, то при максимальном количестве соединений = 20, 80 из этих 100 получат ошибку соединения с БД. После этого они обновят страницу и опять 60 из 80 увидят ошибку. Такие ошибки отпугивают пользователей, а значит нужно их избегать. И поможет нам КЕШИРОВАНИЕ.
Самый простой вариант кеширования — это кеширование по времени (LifeTime). Т.е. указываем время жизни данных. Функция возвращает данные и записывает их в КЕШ на N секунд. В качестве ключа КЕШ-а выступает имя функции + её параметры. При следующем запросе этих же данных происходит их поиск в КЕШ-е + проверка времени жизни и если время не истекло, то берутся данные из КЕШ-а.
Более сложный вариант работы с КЕШем, это очистка КЕШа при изменении данных, которые находятся в КЕШ-е. К примеру мы вызываем функцию articleGet которая при вызове генерирует ключ articleGet.$id и проверяет наличие значения по ключу в КЕШ-а. Если его нет, то производим выборку из БД, если есть, то возвращаем значение из КЕШ-а. Также меняем функцию articlePut, в которой также генерируем ключ articleGet.$id и удаляем по этому ключу значение из КЕШ-а. А значит если после этого будет вызвана функция articleGet с номером статьи которую изменили, то она будет заново выбрана из БД.
Вариант кеширования по времени хорошо подойдет для страницы со списком статей, так как она будет меняться достаточно часто (потому что статьи добавляются). А для функций получения статей и пользователей подойдет более сложный вариант с удалением данных из КЕШ-а (потому что меняться статьи и данные будут достаточно редко).
В итоге схема получится следующая

На схеме цветом выделены разные типы функций + добавились функции вида put, от которых зависят функции вида get (на предыдущей схеме функции put не были указаны, так как они были "сами по себе" и зависимости никакой не было). Эти зависимости важны, так как при изменениях необходимо удалять значения из КЕШ-а.
Итого функции могут быть следующих типов:
- lifetime — получение данных, результат кешируется на время
- get — получение данных, результат кешируется до изменения данных
- put — изменение данных, сброс кеша всех зависимых данных
- direct — получение данных. Результат не кешируется. (в текущем примере функций указанного типа нет)
Проблема N+1 запросов
Проблема N + 1 возникает, когда фреймворк доступа к данным выполняет N дополнительных SQL-запросов для получения тех же данных, которые можно получить при выполнении одного SQL-запроса.
В качестве примера можно взять функцию articleList. При реализации "в лоб" в ней выбирается список идентификаторов статей (1 запрос), а потом выбирается информация о каждой статье по его идентификатору (N запросов). На практике же можно обойтись двумя запросами. Сначала выбрать список статей, а потом сформировать список идентификаторов пользователей и вторым запросом выбрать информацию сразу обо всех пользователях.
Однако вариант с двумя запросами ломает систему кеширования так как для правильного КЕШ-ирования функция articleGet должна вызываться отдельно для каждого идентификатора.
И вот тут будет полезна группировка вызовов функций.
Группировка вызовов функций
Функция API c группировкой вызовов возвращает не результат, а обещание вернуть результат позже. Т.е. функция будет работать в асинхронном режиме. При этом в функцию будут приходить параметры не одного вызова, а сразу нескольких. Что и позволяет успешно решать проблему N+1 запроса.
Для понимания исходный код
// Эта анонимная функция определяет список параметров функции API
// Параметр с именем return указывает тип возвращаемого значения
return function (int $page, int $perPage, array $return): \Closure {
// Эта анонимная функция определяет функцию, которая выполняет группировку вызовов всех функций API
// Параметр $fnCalls опреляет тип функции Calls[Get|Put|Lifetime|Direct]
// $fnCalls является итерируемым объектом и позволяет перебирать все вызовы
return function (CallsLifetime $fnCalls, IDatabase $database): void {
// Создаём объект для кеширования вызовов в памяти
$cacheCall = new CacheCall();
// Перебираем все вызовы
foreach ($fnCalls as $fnCall) {
// Установить время жизни для вызова функции $fnCall КЕШ-а = 5 минут
$fnCall->setTtl(5 * 60);
// Выбрать список идентификаторов статей по входным параметрам функции API: page и perPage (и завешировать результат в памяти)
$articles = $cacheCall($fnCall->arg('page'), $fnCall->arg('perPage'), function (int $page, int $perPage) use ($database) {
return $database->select('articles', 'id')->orderBy('id', false)->pagination($perPage, $page);
});
// Для каждого идентификатора статьи вызвать функцию получения статьи
$waits = [];
foreach ($articles->items() as $article) {
$waits[] = $fnCall->fns()->articleGet($article['id']);
}
// Ждать завершения выполнения всех функций
$fnCalls->all($waits)->wait(function ($items, $err) use ($fnCall, $articles) {
// Вернуть результат (точнее установить результат)
$fnCall->setValue($articles->args($items));
});
}
};
};// Эта анонимная функция определяет список параметров функции API
// Параметр с именем return указывает тип возвращаемого значения
return function (int $id, array $return): \Closure {
// Эта анонимная функция определяет функцию, которая выполняет группировку вызовов всех функций API
// Параметр $fnCalls опреляет тип функции Calls[Get|Put|Lifetime|Direct]
// $fnCalls является итерируемым объектом и позволяет перебирать все вызовы
return function (CallsGet $fnCalls, IDatabase $database): void {
// Выбрать информацию о статьях
// $fnCalls->args() - получает список параметров всех вызовов
// ArrArr::value('id', $fnCalls->args()) - получает уникальные значения параметра id
// ArrArr::groupBy('id', ...) - группировать массив по полю id
$articles = ArrArr::groupBy('id', $database->select('articles')->in('id', ArrArr::value('id', $fnCalls->args()))->get());
// Разобрать выбранные данные по вызовам API функций
foreach ($fnCalls as $fnCall) {
// Информция о статье
$article = $articles[$fnCall->arg('id')];
// Указать зависимость вызова от функции PUT
// Т.е. при вызове функции articlePut с указанным параметром КЕШ функции $fnCall будет сброшен
$fnCall->fns()->articlePut($article['id']);
// Выбрать информацию о пользователе
$fnCall->fns()->userGet($article['author_id'])->wait(function ($value, $err) use ($article, $fnCall) {
// Информация о пользователе
$article['author'] = $value;
// Установить значение функции
$fnCall->setValue($article);
});
}
};
};// Эта анонимная функция определяет список параметров функции API
// Параметр с именем return указывает тип возвращаемого значения
return function (int $id, array $return): \Closure {
// Эта анонимная функция определяет функцию, которая выполняет группировку вызовов всех функций API
// Параметр $fnCalls опреляет тип функции Calls[Get|Put|Lifetime|Direct]
// $fnCalls является итерируемым объектом и позволяет перебирать все вызовы
return function (CallsGet $fnCalls, IDatabase $database): void {
// Выбрать список уникальных идентификаторов пользователей
$author_ids = ArrArr::value('id', $fnCalls->args());
// Выбрать информацию о пользователях
$users = ArrArr::groupBy('id', $database->select('users')->in('id', $author_ids)->get());
// Разобрать выбранные данные по вызовам
foreach ($fnCalls as $fnCall) {
// Информация о пользователе с идентификатором вызова $fnCall->arg('id')
$user = $users[$fnCall->arg('id')];
// Указать зависимость вызова от функции PUT
$fnCall->fns()->userPut($user['id']);
// Установить значение функции
$fnCall->setValue($user);
}
};
};Группировка вызовов функций позволяет использовать кеширование. Т.е. в функцию группового вызова попадут только те вызовы функции, для которых нет значений в КЕШ-е. Изменение значения в КЕШ-е произойдет только при вызове соответствующей функции изменения данных.
Сервис API позволяет вызывать асинхронные функции в синхронном коде:
// Вызов функций API
$articles = $api(function (CallAll $apiCall) use ($request) {
// Вызватиь функцию articleList
$apiCall->fns()->articleList($request->query()->get('p', 0), 10)->wait(function ($value, $err) use ($apiCall) {
// Установить результат вызова API
$apiCall->setValue($value);
});
});В результате в $articles будет результат который установили с помощью вызова $apiCall->setValue($value);. Т.е. данные из асинхронного блока возвращаются в синхронный код.
Для чего эти ваши функции?
В API удобно реализовать функции бизнес-логики. При этом разработчику не нужно будет думать о реализации КЕШирования, всё это идет из коробки. Достаточно просто написать API функцию заданного типа. При работе с базой данных, на мой взгляд, весьма полезная "фишка". Пример выше наглядно показывает сокращение количества выборок из БД. После первого вызова реально вызываться будет только функция articleList(), да и то не всегда а только когда выйдет время жизни кеша. Т.е. раз в 5 минут.
Функции достаточно легко использовать не только на backend, но и на frontend. Для этого достаточно автоматически сгенерировать удобную для вашей задачи точку доступа. Так как имеется список всех функций и их параметров, то это не сложная задача. А значит мы можем одну и туже функцию, к примеру, aticleList(), вызывать как на сервере, так и на клиенте. Возвращаемые данные будут идентичны. Т.е. по данным одной и той же функции можно генерировать страницу как на сервере (к примеру php+twig), так и на клиенте (к примеру vue/react/angular).