
Абсурдная идея
Если создать в интернете базу данных всех существующих файлов, то любой архив будет представлять собой список имен каталогов, файлов, дата+время изменения/создания и хеши этих файлов. А при распаковке архива достаточно будет просто скачать из интернета содержимое файла по его хешу, записать на диск и присвоить атрибуты (дата,время). Т.е. даже архив с полным сезоном какого-нибудь сериала из 20 серий будет занимать не больше нескольких килобайт (в независимости от качества видео).
Всем понятно, что создать базу хешей всех файлов просто физически невозможно. И даже не потому что для этого требуется большой объем для хранения файлов, а потому что новые файлы появляются каждую секунду. И такая online база данных просто не будет успевать сохранять огромный массив данных.
Уменьшение абсурда
Упростим условия и будем ограничится не всеми файлами, а только какой-то группой файлов. В этом случае скорость появления новых файлов будет не такой огромной и объем данных также будет в разумных пределах.
И самое очевидное применение такого подхода - это система контроля версий файлов. Т.е. мы будем ограничиваться только файлами одного проекта.
Небольшое лирическое отступление
Практически программа ближе к системе резервного сохранения с версионностью, чем к системе контроля версий. Но так как изначально я эту систему делал для сохранения кода, то пусть так и останется Система контроля версий.
Формализация задачи
Сохранение всех элементов (файлов, каталогов, ссылок) папки проекта с возможностью вернуться к любому сохраненному состоянию.
-
Проект - папка(директория) с элементами. Элементом может быть
Файл
Директория
Символьная ссылка (если она указывает на элемент внутри проекта)
Состояние проекта - список всех имен элементов проекта + их состояния.
-
Состояние элемента определяется как
Файл - имя(путь внутри проекта)+хеш файла + размер + дата/время последнего изменения
Директория - имя(путь внутри проекта)
Символьная ссылка - имя(путь внутри проекта) + относительный путь (относительно базового пути проекта) на ссылающийся элемент
ХЕШ файла = хеш (SHA-3+crc32) данных файла + размер файла
Трансформация - список команд (добавление, удаление), которые переводят проект из предыдущего состояние в следующее.
-
Команда трансформации - состоит из
-
Тип команды
D Добавление элемента
R Удаление элемента
Имя элемента
-
Данные команды (только для команды Добавления)
Добавление каталога - нет данных
-
Добавление ссылки
LINK - ссылка на элемент
-
Добавление файла
HASH - хеш данных файла
SIZE - размер
TIME - дата/время изменения
-
Описание процесса сохранения на сервер
Первоначально папка проекта находится в состоянии "пусто". Трансформация 1 переводит её в Состояние 1. В трансформации 1 две команды, которые добавляют два файла. Затем трансформация 2 переводит проект в Состояние 2. Во второй трансформации четыре команды: удаление file1.txt, удалить file2.txt, добавить file2.txt, добавление file3.txt
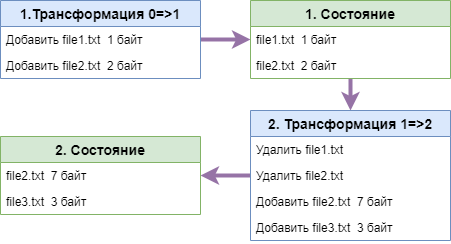
Схема процесса сохранения:
Сканируем папку проекта и получаем список состояний всех локальных элементов.
Запрашиваем с сервера все трансформации проекта.
Выполняем все трансформации и получаем состояние проекта на сервере.
Определяем трансформацию со списком команд, которые переводят проект из состояние на сервере в локальное состояние.
Отправляем на сервер все новые файлы.
Отправляем на сервер новую трансформацию.
Процесс восстановления аналогичен, только трансформация со списком команд строится для перевода из состояния сервера в локальное состояние.
Для получения нужного состояния клиенту необходимо скачать все трансформации, предшествовавшие этому состоянию, и выполнить их у себя.
Сервер хранения
Сервер хранения будет выступать только как хранилище файлов. Использовать можно FTP, HTTP или облачное API. В простейшем случае в качестве сервера хранилища может выступать каталог на локальном компьютере или сетевом диске.
Файловая структура хранилища:
files - все файлы хранилища. Имя файла это хеш файла.
-
projects - проекты
-
имя проекта
NN трансформации - номер трансформации. От 1 до 4.294.967.295
-
Алгоритм запроса с сервера состояний элементов (т.е. всех трансформаций проекта):
Читаем в корне директории проекта файл `shasoft-vcs.json` и из него получаем имя проекта.
Номер трансформации NN = 1.
Проверяем на сервере наличие трансформации NN в файле `projects/<хеш имени проекта>/NN`. Если нет то КОНЕЦ.
Читаем с сервера трансформацию NN.
NN = NN + 1.
Идти к пп.3.
При сохранении новых трансформаций определяем последний номер трансформации и сохраняем новые трансформации под следующем номером на сервер.
Для уменьшения размера будем упаковывать список трансформаций (и файлы) в архив GZIP. Как вариант, можно прикрутить и другой формат упаковки. Однако реализация GZIP у меня есть + этот формат может распаковывать PHP. Что удобно если я всё-таки сделаю HTTP сервер аля github.
Реализация работы с хранилищем
Адрес сервера хранения задаётся в виде: <тип хранилища>://<параметры хранилища>
Функции работы с хранилищем располагаются в dll с именем storage-<тип хранилища>. Динамическая библиотека должна реализовать следующие функции:
-
int32 storage_connect(const byte *url) - установить соединение
Возвращает идентификатор соединения или 0 в случае ошибки
void storage_disconnect(int32 idConnect) - разорвать соединение
-
int32 storage_upload(int32 idConnect, const byte *filepathFrom, const byte *filenameTo) - записать файл в хранилище
-
Возвращает статус выполнения операции
0 - Ok
1 - Ошибка записи, так как файл с таким именем уже существует
99 - Ошибка записи
-
-
int32 storage_download(int32 idConnect, const byte *filenameFrom, const byte *filepathTo) - получить файл из хранилища
-
Возвращает статус выполнения операции
0 - Ok
1 - Ошибка чтения, так как файла с таким именем не существует
99 - Ошибка чтения
-
-
int32 storage_file_exists(int32 idConnect, const byte *filename) - проверить существование файла
Возвращает статус выполнения операции
0 - файл НЕ существует
1 - файл существует
99 - Ошибка
Имена файлов передаются в виде utf-8 строки с символом \0 в конце.
На текущий момент поддерживается два типа хранилища:
fs - файловая система. Пример адреса `fs://<путь до каталога хранилища>`
ftp - работа с FTP. Пример адреса `ftp//:[[<логин>[:<пароль>]@]<хост>[:<порт>]][/<папка на сервере>]`
Безопасность
Слабая сторона данной схемы - безопасность. В общем случае нет возможности на сервере проверить имя пользователя (потому что сервер выступает как файловое хранилище и не может выполнять функции авторизации). А значит любой, кто знает параметры доступа к файловому серверу может удалить или изменить там данные. Как вариант решения - отключить эту возможность, оставив только возможность добавления файлов. В этом случае вредитель не сможет удалить или изменить данные. Но сможет добавить некоректные значения. Что тоже не очень хорошо.
Вариант решения тут только один - сделать специальный файловый сервер (к примеру HTTP/HTTPS) для работы с системой контроля версий который будет проверять авторизацию пользователя и не давать выполнять какие-то действия, если у пользователя нет на это прав.
Справка по работе с программой
Shasoft VCS version 1.0.0-beta.15
Usage: shasoft-vcs.exe -m -s [-l] [-n] [--nosave] folder
Positional arguments:
folder Project folder
Optional arguments:
-m, --mode Working mode
backup Save data to storage
restore Restore data from storage
-s, --storage Link to storage/Storage ID
-l, --log Display log on screen
-n, --nn Recovery Version ID
--nosave Without saving the result
Storage ID settings file:
<...>/AppData/Roaming/Shasoft VCS/storages.jsonfolder - папка проекта. В указанной папке ищется файл `shasoft-vcs.json` с именем проекта.
{
"name" : "<имя проекта в формате /[a-zA-Z0-9_@$\\-]{1,}\\/[a-zA-Z0-9_@$\\-]{1,}/>"
}В случае отсутствия поиск продолжается в родительской папке. И так до самого верхнего уровня. Если файл с именем проекта не найден, то ошибка. Если найден, то происходит сохранение в найденный проект. При этом сохраняется только указанная папка, а не весь проект. Т.е. если файл проекта находится в `c:/myproject/shasoft-vcs.json` и указана папка `c:/myproject/aaa/bbb`, то сохранится/восстановится только папка проекта `aaa/bbb`.
-
-m, --mode - режим работы. Два значения
backup - сохранение
restore - восстановление
-s, --storage - адрес/псевдоним хранилища.
-n, --nn - номер версии для восстановления
--save - без внесения изменений. Режим добавлен для тестирования системы игнорирования элементов проекта через файл .gitignore
Внизу указывается расположение файла с соответствиями псевдонима хранилища его адресу в формате
{
"<псевдоним 1>" : "<адрес 1>",
"<псевдоним 1>" : "<адрес 1>",
...
}Так как файл с псевдонимами хранится в директории пользователя, то таким образом можно скрыть адреса хранилищ от других пользователей компьютера.
Планы
1. Добавить шифрование. Это позволит создавать хранилища даже в облаке без опасения что данные "утекут"
2. Собрать программу под linux. Для этого проект был переведен на cmake. Установил VSCode в Simply Linux. Нужно разбираться дальше.
Комментарии (13)

maeris
09.12.2022 06:58+4Похоже на IPFS.
maeris
09.12.2022 07:03-1Я бы, впрочем, предложил написать не на С++ (правильно же угадал?), а на каком-нибудь более безопасном языке, чтобы оно легче читалось и поддерживалось. Кстати, а исходники вы из каких-то побуждений не выкладываете на github?

shasoftX Автор
09.12.2022 07:14Чтобы выкладывать исходники, нужно их "причесать". Иначе это будет просто куча непонятно чего. Пока руки до этого не дошли.
на каком-нибудь более безопасном языке,
Вообще идеи такие были на Go или Rust переписать. Заодно и потренироваться. Но тут опять нужно время + понимание что же более безопасно.
чтобы оно легче читалось и поддерживалось
C++ более распространен, так что большинству разработчиков его читать и поддерживать проще,

domix32
09.12.2022 11:27Читать код меньшая из проблем. Да и лаконичный код намного понятнее пелёнок с итераторами и прочими. Или вы сразу на 20х стандартах пишите?
shasoftX Автор
09.12.2022 11:35Да, судя по настройке в cmake
set(CMAKE_CXX_STANDARD 20)Но это для скорости написания. Скорее всего можно и уменьшить версию, переписав какой-то код. Это я себя уже по рукам стал бить и принял волевое решение что 20x это нормально и на текущий момент поддерживать более старые стандарты не к чему.

ri1wing
09.12.2022 09:13Я правильно понял, что если я отредактирую файл сто раз, у меня будет сто трансформаций вида "Удалить file1.txt Добавить file1.txt" и на сервере будет храниться сто самостоятельных версий file1.txt? Но при этом, если я захочу восстановить версию 99й итерации, я не могу её просто скачать, а мне нужно будет сначала последовательно добавить-удалить предыдущие 98?
shasoftX Автор
09.12.2022 09:18Если в результате редактирований файл будет иметь 100 разных содержимых, то да, на сервере будет 100 файлов. ,Что вполне понятно: если у вас 100 разных файлов и вы хотите иметь возможность получить любой из них, то все они должны хранится на сервере.
если я захочу восстановить версию 99й итерации
Нет. Трансформации выполняются в памяти и скачивается только итоговый вариант файла.
Т.е. у вас 100 разных файлов и 100 трансформаций (200 команд =100 удалений + 100 добавлений). Трансформации будут выполнены, будет определено что нужен файл № 100 и скачен будет только он. Все остальные 99 файлов скачиваться не будут. Потому что это файл с одним и тем же именем. И в проекте он будет только один. А значит нет смысла качать 99 его исторических копий, которые нам не нужны.
ri1wing
09.12.2022 09:41Нет. Трансформации выполняются в памяти и скачивается только итоговый вариант файла. <...>
А значит нет смысла качать 99 его исторических копий, которые нам не нужны.Тогда следующий абзац ввёл меня в заблуждение.
Для получения нужного состояния клиенту необходимо скачать все трансформации, предшествовавшие этому состоянию, и выполнить их у себя.
shasoftX Автор
09.12.2022 09:50Понял. Да, сами трансформации придется качать все. Иначе не ясно какой файл в последней итерации.
У меня было два варианта:
Хранить все состояния в каждой трансформации
Хранить в трансформации только изменения
Я выбрал вариант № 2 потому что в 1-ом слишком много избыточных данных. А так как размер самих трансформаций небольшой (+они кэшируются в папке проекта), то скорость не падает.

firegurafiku
10.12.2022 03:53ХЕШ файла = хеш (SHA-3+crc32) данных файла + размер файла
Удивительное сочетание алгоритмов! Если у вас уже есть криптостойкая контрольная сумма, зачем добавлять к ней CRC-32? Кстати, а почему SHA-3?
shasoftX Автор
10.12.2022 08:26зачем добавлять к ней CRC-32
На "всякий случай"
Кстати, а почему SHA-3
Почитал, пишут что он более надёжен чем sha-2

nixtonixto
10.12.2022 09:13Очень похоже на инкрементальный бэкап — таких программ мне известно десятки (на Windows), с сохранением куда угодно — от WebDAV/FTP до облаков, с сжатием и шифрованием, платных и бесплатных.
Deosis
Похоже на торренты.