
Привет! Меня зовут Дима Курганский. Я — MLOps инженер в команде машинного обучения в Банки.ру. Эта статья будет особенно интересна тем, кто понимает общие принципы работы с Great Expectations, как минимум базово знаком с составляющими компонентами и хочет вывести этот инструмент на прод с использованием Apache Airflow.
Введение
В мире разработки есть много информации, что такое Apache Airflow и как его развернуть. Нет и недостатка в ресурсах, посвященных Great Expectations (GX*) и созданию проверок данных.
Разработчики инструмента сокращают название именно так — GX, а не GE.
Когда речь идет о продуктивном взаимодействии этих инструментов, информации часто не хватает. И пусть эта тема не слишком сложная, практических примеров все равно мало, а документация библиотеки провайдера остается недостаточно подробной. В процессе настройки интеграции этих инструментов в Банки.ру мы столкнулись с проблемами, которые успешно преодолели. Хотел бы поделиться нашим опытом и знаниями с сообществом, чтобы сделать этот процесс более доступным и понятным.
Продуктивизация GX в Airflow
Под продуктивизацией GX в Airflow мы понимаем запуск заранее сформированных проверок качества наборов данных. Конечно, можно поставить в расписание и процесс их автоматизированного создания. Однако, как нам кажется, это более творческая задача.
При написании этой статьи использовались следующие версии инструментов:
airflow 2.3.4 (март 2022)
great expectation 0.17.22 (октябрь 2023)
airflow-provider-great-expectations 0.2.7 (октябрь 2023)
SQLAlchemy 1.4.27 (ноябрь 2021)
Как все устроено
Продуктивизировать GX в Airflow можно тремя способами, используя:
BashOperator. Запускаем проверки через консольный клиент GX: great_expectations checkpoint run my_checkpoint. О какой-то конфигурации запуска при этом сценарии речи не идет. Способ скорее теоретический.
PythonOperator. Этот вариант позволяет реализовать гибкий запуск проверок, используя весь функционал библиотеки great expectations, но для этого нужно описать всю логику самостоятельно. После проделанной работы на выходе, скорее всего, получится аналог третьего варианта.
GreatExpectationsOperator. Основной мост в продуктивизацию GX, предоставляемый библиотекой airflow-provider-great-expectations от astronomer. Оператор довольно богатый на конфигурации, возможно, даже слишком, чтобы быть понятным при первом знакомстве.
Все богатство конфигураций оператора заключается в разных вариантах определения компонент GX через if-else-взаимосвязь их атрибутов. Описание настройки этих компонент через GreatExpectationsOperator — самое полное и понятное из найденных нами — есть в документации разработчиков. Однако после прочтения документации у нас все равно остались вопросы для первого запуска в проде.
Прежде всего в источниках мало информации по выбору места хранения ключевых компонент. Физически все они по сути — Python-объекты, тесно взаимосвязанные между собой. Для себя мы их разделяем на входящие и исходящие. И те, и другие представлены структурой данных «Словарь», который в свою очередь удобно хранить в формате json/yaml/html*. Подробнее в таблице:
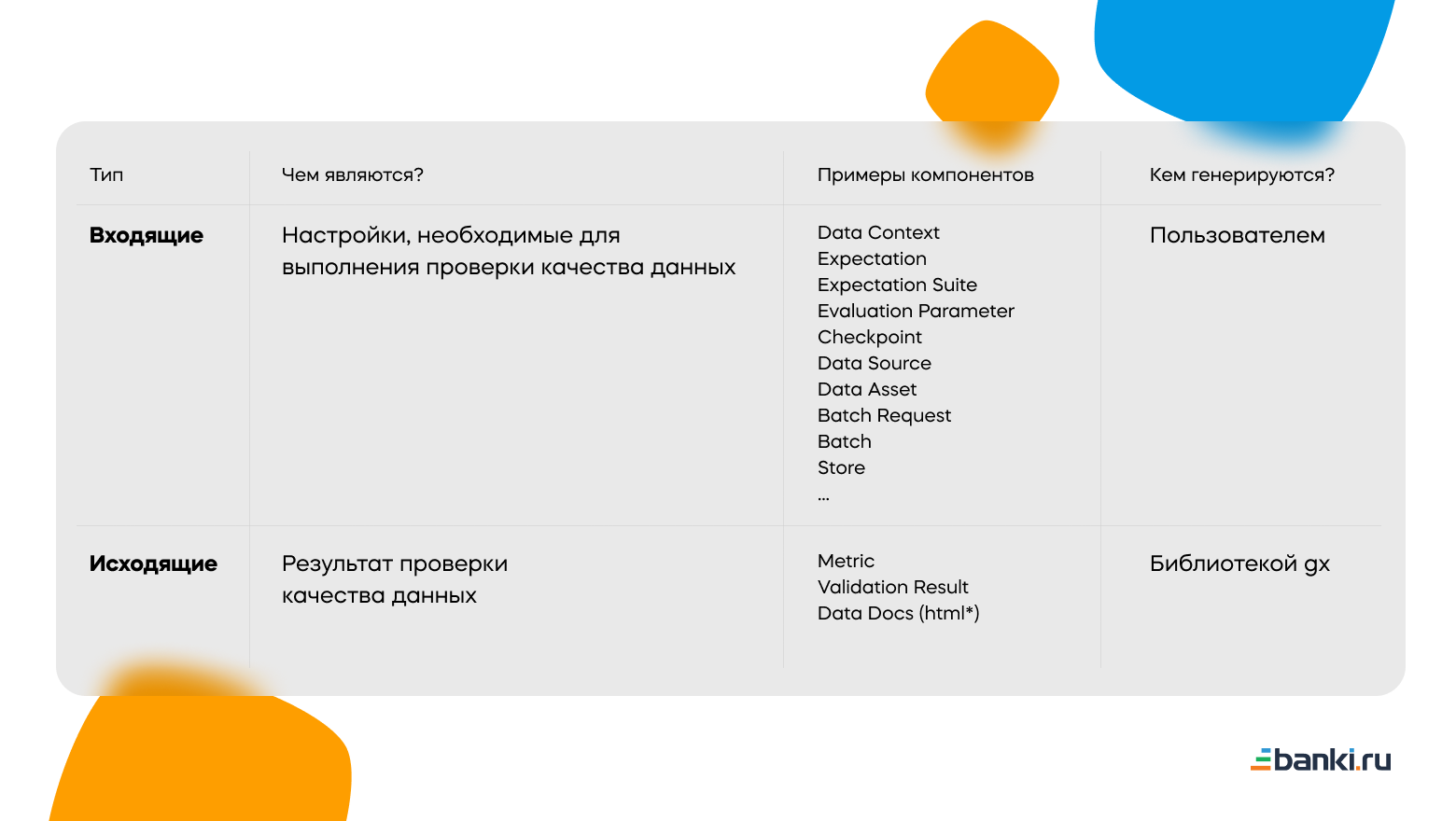
Компонента Store библиотеки GX, настраиваемая в файле great_expectations.yml, как раз определяет тип хранилища для трех основных входящих компонент (Expectation Suite, Checkpoint, Evaluation Parameter) и трех исходящих из таблицы выше:
локальное (если речь идет про Airflow, то проще всего в dags_folder).
удаленное (S3/GCS/Azure).
Кроме того, библиотека airflow-provider-great-expectations передает некоторые входящие компоненты целиком в виде словаря как атрибут оператора или же генерирует их в процессе выполнения проверки на основе одного или нескольких входящих атрибутов.
Для себя пришли к такому варианту:
Храним Expectation Suite локально как json-файлы, чтобы версионировать. Не хочется, чтобы кто-то незаметно (
для самого себя)изменил проверки в удаленном хранилище. Поэтому держим их в поддиректории great_expectations внутри dags_folder. Настроечные файлы great_expectations.yml, config_variables.yml, из которых формируется компонента Data Context, храним там же.Checkpoints у нас генерируется в процессе выполнения на основе атрибутов оператора. Хранить этот объект отдельно смысла не видим.
А вот результат проверок (Validations) в виде json и Data Docs поверх них в виде html логично хранить в S3, так как версионировать эти результаты нет смысла.
Evaluation Parameter, Metric пока не применяем, поэтому хранилище не определили.
Теперь пробежимся по компонентам, отвечающим за генерацию набора данных: Data Source, Data Assets, Batch Request. Отдельного хранилища для них GX не предусматривает, при этом в GreatExpectationsOperator определить каждую из них можно также несколькими способами.
Data Source — тремя:
заранее в data_context (great_expectations.yml);
через параметр data_source передать словарь с описанием компоненты;
в процессе запуска на основе параметров conn_id и execution_engine.
Для Data Assets работают первый или второй вариант, только уже через строковый параметр data_asset_name.
Batch Request определить в data_context уже нельзя (более динамичная компонента), но для нее вполне работают второй и третий варианты таким образом:
передаем словарь через параметр batch_request.
задаем параметры (data_asset_name и conn_id) или (data_asset_name, query_to_validate и conn_id) или (data_asset_name и dataframe_to_validate) в зависимости от способа получения данных и типы источника данных.
Небольшая ремарка по поводу data_asset_name и query_to_validate. В случае работы с табличными данными, а мы пока работаем именно с ними, data_asset_name используется как наименование таблицы, которую необходимо проверить. Если же хотим проверять, например, ежедневный batch данных, то пишем полноценный sql-запрос через атрибут query_to_validate. Он, как и несколько других, поддерживает шаблоны jinja, поэтому выбрать актуальный по дате batch данных очень просто. При этом из-за особенностей реализации при использовании query_to_validate все равно необходимо задать data_asset_name. Можно произвольным значением. Еще опционально можем определить схему отдельным параметром или указать ее в data_source.
В итоге наш оператор для проверки ежедневного набора данных выглядит примерно так:
check_scores_dq = GreatExpectationsBankiruOperator(
task_id="check_some_table",
data_context_root_dir="/opt/airflow/dags/great_expectations",
conn_id='database_conn',
schema='schema',
expectation_suite_name="table_exp",
data_asset_name="some_name",
query_to_validate="select * from some_table where dt = '{{ ds }}'",
validation_failure_callback=some_validation_failure_callback,
return_json_dict=True,
)Для проверки целой таблицы убираем параметр query_to_validate и задаем data_asset_name равным наименованию проверяемой таблицы.
Немного о проблемах
Инициализация всех рассмотренных выше компонент происходит в методах класса GreatExpectationsOperator. Помимо них есть еще три основных метода. Познакомиться с ними ближе придется большинству разработчиков, так как в их реализации есть несколько, на наш взгляд, непродуманных моментов. Кода там не так много, к тому же он не особо сложный. Итак:
make_connection_configuration. Создание подключения к базам данных для GX на основе имеющихся connections в Airflow.
execute. Запуск проверок качества на наборе данных, связанных между собой компонентом checkpoint.
handle_result. Управление результатом проверки, то есть алерты, логи, исключения.
На Habr уже писали, что не для всех баз данных есть соединения. Более того, те, что есть, не всегда без проблем настраиваются и интегрируются с connections Airflow. Для решения изучаем первый метод из списка выше и вносим правки.
Также в текущей версии библиотеки провайдера не работает кнопка, отображаемая в UI для оператора GX и работающая как ссылка в Data Docs:

Вроде мелочь, а неприятно. Технически эта кнопка называется operator extra link. Чтобы она работала, необходимо ее определить и зарегистрировать через Airflow Plugin или в метаданных библиотеки провайдера. Лично мы в метаданных ее на нашли. Видимо, разработчик забыл. Поэтому можно либо зарегистрировать класс GreatExpectationsDataDocsLink через Plugin, либо форкнуть библиотеку целиком и дополнить метаданные. Для себя пока выбрали первый способ. Подробнее про оба варианта — тут.
Если говорить про мелочи, то несмотря на богатый функционал оператора, нельзя, например, пробросить параметр create_temp_table. При работе с базами данных GX по умолчанию создает временные таблицы, чтобы ускорить повторные проверки данных. Однако подобное поведение не всегда желательно и допустимо. Как решение добавляем в метод build_runtime_sql_datasource_config_from_conn_id такую правку:
def build_runtime_sql_datasource_config_from_conn_id(
self,
) -> Datasource:
datasource_config = {
"name": f"{self.conn.conn_id}_runtime_sql_datasource",
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "SqlAlchemyExecutionEngine",
"create_temp_table": "false",
**self.make_connection_configuration(),
},
...Обратим отдельное внимание на алерты. Для их реализации в операторе провайдера есть параметр validation_failure_callback, который срабатывает именно при неудачной проверке качества данных. Однако его реализация не подразумевает передачу объекта context, в отличие от классического on_failure_callback. Вместо context на вход функция-callback получит объект CheckpointResult или словарь, содержащий результат валидации. Это хорошо, но чтобы использовать алерты по максимуму, хочется, чтобы они возвращали ссылку на Data Docs и url на log задачи в Airflow. Алерты далее будут отправлены через Email / Slack и должны содержать ссылки, по которым можно перейти для анализа проблемы и перезапуска. Как вариант: можно переопределить метод execute, добавив нужной информации к переменной-словарю result прямо перед вызовом метода handle_result. Например, вот такими строчками кода:
result['log_url'] = context.get('task_instance').log_url
result['data_docs_site'] = data_docs_siteВ идеале — иметь ссылку на log задачи Airflow прямо в Data Docs: разобрались с проблемой, вернулись к задаче Airflow, перезапустили. Сделать это возможно, но точно придется больше шаманить, хотя такой необходимости пока не было.
Таким образом, на выходе у нас получается переписанный под наши потребности оператор GreatExpectationsBankiruOperator, который мы используем во всех продуктивных dag–ах вместо исходного.
Заключение
Сейчас есть ощущение, что библиотека-коннектор не особо поспевает за GX. Развитие подобного продукта невозможно без интеграции с инструментами, которые управляют потоками данных. Поэтому надеюсь, что разработчики в скором времени наверстают. А библиотека, как и сам GX, — open source, поэтому все заинтересованные могут помочь своим PR.
Возможно, по всем пунктам, что мы рассмотрели, есть более простой и грамотный рецепт. Не исключено, что какие-то проблемы мы сами себе придумали. Поэтому постараемся обновлять материал по мере роста нашей глубины познания продукта и его развития в целом. Буду очень рад вопросам и комментариям.