

Предупреждение
Crackme (как, впрочем, следует из названия) это программы, созданные специально для того, чтобы их взломать (понять алгоритмы, заложенные разработчиком, и используемые для проверки введенных пользователем паролей, ключей, серийных номеров). Подходы и методики, использованные в статье, ни в коем случае не должны применяться к программному обеспечению, производителями которого подобные действия не одобрены явно (например, в лицензионных соглашениях, договорах, и т.д.). Материал опубликован исключительно в образовательных целях, и не предназначен для получения нелегального доступа к возможностям программного обеспечения в обход механизмов защиты, установленных производителем.
Введение
Исследуемая crackme является оконным приложением, и написана на assembler. Наша задача состоит в том, чтобы понять алгоритм генерации ключа, найти валидный серийный номер (или номера), и написать кейген.
Для анализа и проверки гипотез нам понадобится:
- IDA
- Python
Осмотр
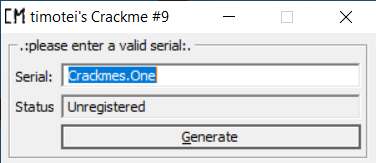
Запустив crackme мы видим одно окно, с полем для ввода серийного номера, и кнопкой, почему-то называющейся "Generate", и очевидно отвечающей за проверку введенного серийного номера. Что бы я ни вводил в поле — статус по прежнему оставался "Unregistered".
Загрузимся в IDA и попробуем найти код, который отвечает за валидацию серийного номера. Сначала ищем строку Unregistered. Для этого идем в меню View — Open Subviews — Strings, находим строку, и переходим в дизассемблированный код. Далее через меню Jump to xref to operand... переходим к коду, который использует эту строку.
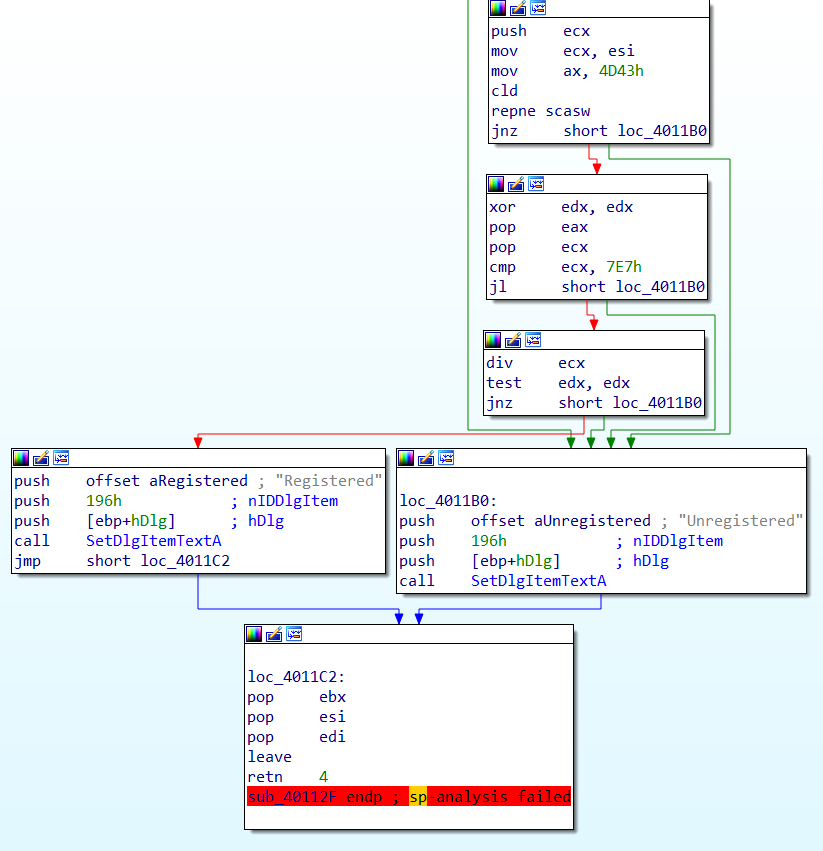
Беглый осмотр показывает, что статус Registered проставляется соседней веткой кода, а также осуществляется цепочка проверок, из которой четыре ветки ведут к Unregistered, и только полное прохождение всех проверок ведет к статусу Registered. Давайте разбираться.
Проверка серийного номера на валидность
Прокрутив граф кода вверх, посмотрим на первый блок кода.
; Attributes: bp-based frame
; int __stdcall sub_40112F(HWND hDlg)
sub_40112F proc near
hDlg= dword ptr 8
push ebp
mov ebp, esp
push edi
push esi
push ebx
push 32h ; '2' ; cchMax
push offset byte_403050 ; lpString
push 195h ; nIDDlgItem
push [ebp+hDlg] ; hDlg
call GetDlgItemTextA
lea edi, byte_403050
push edi ; lpString
call lstrlenA
cmp eax, 0
jz short loc_4011B0Очевидно, что код, с помощью функции GetDlgItemTextA получает значение введенного номера, и, если длина строки равна нулю — перебрасывает нас к статусу Unregistered.
Следующий блок кода, выполняющийся в случае, если введено хоть что-нибудь:
mov esi, eax
push offset byte_403050 ; String
call ds:atoi
push eax
mov ecx, eax
xor eax, eaxЭтот код вызывает функцию atoi, которая вытаскивает число из строки (если оно там, конечно, есть) и возвращает int (в регистр EAX, значение которого кладется в стек, и регистр обнуляется).
Затем, следует еще четыре блока кода.
Блок №1
loc_40116C:
movsx ebx, byte ptr [edi+eax]
add ebx, 1E240h
add ecx, ebx
inc eax
cmp eax, esi
jl short loc_40116CСмысл этого блока в получении некой контрольной суммы введенной строки. Сразу после вызова atoi результат сохранялся в стек, и копировался в регистр ECX. Здесь же каждый байт введенного нами серийного номера суммируется с числом 1E240 (123456 в десятичной системе), и эта сумма добавляется к значению в ECX. Таким образом, блок проходит все байты введенного нами серийного номера, и на выходе мы получаем некую сумму.
Блок №2
push ecx
mov ecx, esi
mov ax, 4D43h
cld
repne scasw
jnz short loc_4011B0Главный момент этого блока — инструкция repne scasw, которая осуществляет поиск подстроки во введенном серийном номере. Ее задача найти в строке 2 байта (2 bytes = word, поэтому и scasw) — 4D 43, по кодовой таблице ASCII это соответствует строке "CM".
Блок №3
xor edx, edx
pop eax
pop ecx
cmp ecx, 7E7h
jl short loc_4011B0Этот блок достает из стека результат работы функции atoi и сравнивает его с числом 7E7 (2023 в десятичной системе).
Блок №4
div ecx
test edx, edx
jnz short loc_4011B0Последний блок проверки вызывает иструкцию div, деля значение в EAX на ECX. Целая часть помещается в EAX, а остаток в EDX. Инструкция test edx, edx проверяет, что деление прошло без остатка.

Алгоритм проверки
Что мы имеем в итоге:
- Введенная строка должна быть не пустой
- В строке обязательно должно присутствовать число "2023"
- В строке обязательно должна присутствовать подстрока "CM"
- Сумма, полученная функцией свертки, должна делиться без остатка на 7E7 (2023).
Строка "2023CM" не является валидным серийным номером, а значит нам немного не хватает символов до прохождения проверки. Теперь понадобится немного поразмыслить о том, как найти валидные серийные номера.
Фактически нам надо решить уравнение вида:
2023 + sum("CM") + (x1 + ... + xN + 123456*N) mod 2023 = 0Однако, хотя (x1 +… + xN + 123456 * N) как-то смахивает на арифметическую прогрессию, и наверное можно было бы решить это математическим методом, мы пойдем по пути перебора.
It's Python time
Тут-то нам и поможет Python. Мы точно знаем, что:
- Контрольная сумма должна делиться без остатка на 2023
- Контрольная сумма не может быть больше 4-х байт (0xFFFFFFFF)
- Так как в строке, кроме "2023CM" должно быть что-то еще, то как минимум следует искать числа выше контрольной суммы строки "2023CM" + 123456.
Для начала найдем все варианты контрольных сумма, которые выше контрольной суммы строки "2023CM" + 123456, меньше 0xFFFFFFFF, делящиеся на 2023 без остатка:
def calc(str_input):
'''Вычисление контрольной суммы строки'''
val = 2023
for i in str_input:
val = val + ord(i) + 123456
return val
a = 2023
b = 0xFFFFFFFF
l = []
while a < b:
a = a + 2023
if a >= calc('2023CM') + 123456:
l.append(a)Теперь, когда мы получили все варианты контрольных сумм, примерно пододящие под заданный диапазон, прокрутим мясорубку в обратную сторону. Нам нужно понять, в какое из чисел, за минусом контрольной суммы строки, влезет равное количество байт из ASCII от кода 88 до 122, т.е. от a до z.
Так как мы точно знаем, что в алгоритме контрольной суммы каждый байт суммируется с числом 123456 мы можем:
- Вычесть сумму строки "2023CM", получив сумму всех байт кроме "2023CM"
- Поделить остаток на 123456 (целоцисленно), чтобы понять сколько байт "влезет" в диапазон
- Вычесть из числа, полученного на шаге 1 число, полученное на шаге 2, вычислив таким образом сумму байтов без учета сложения с 123456
- Поделить сумму байтов без учета числа 123456 на количество, вычислив код символа.
start = calc('2023CM')
l1 = []
for i in l:
a = i - start
char_count = a // 123456
char_sum = a % 123456
# Вся строка может содержать 94 символа, за вычетом 6 известных нам нужно еще максимум 88
if char_count > 88:
continue
if (char_sum % char_count) > 0:
continue
if char_sum >= 97 * char_count and char_sum <= 122 * char_count:
l1.append(i)Теперь в l1 у нас остаются только числа, точно подходящие под заданный диапазон ASCII-кодов. Попробуем собрать строку.
for i in l1:
print('code:')
a = i - start
csum = a % 123456
ccount = a // 123456
charcode = csum // ccount
print('2023CM', end='')
print(chr(charcode)*ccount)
print()В результате мы имеем 2 серийных номера:
code:
2023CMtttttttttttttttttttttttttttttttt
code:
2023CMnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnПроверяем, и… да! Серийный номер валиден, статус "Registered"!


iminfinitylol
помнится когда я думал над способом защиты для одной своей программы я сразу отказался от обычных серийных ключей, вместо это я сделал файл лицензии на какой либо период
ну то есть шифрованный файл, в котором есть информация (по началу пустой, из коробки), в который генерировался ключ программы, исходя из крайней даты валидности лицензии, которая сравнивалась с датой на компьютере, имени пользователя, названия компьютера
вся эта информация и была ключем, который по верх просто в формате строки превращал символы в хекс коды (к примеру а -> 0x000001)
а снизу уже добавлял мусорные строки для отвлечения внимания,
[product key]
ololo
[serial]
atata
и тд
при этом на событиях инициации программы были назначены функции check_key() и validate_key(), которые ничего не делали
проверка лицензии происходила обратной дешифровкой и сравнением с параметрами системы в событиях создания нового проекта, открытия, сохранения, и вызове библиотеки
хотя такая защита не сказать что была очень нужной так как программа была не очень популярна -_-
robert_ayrapetyan
Плоть, Север, мера, срок, необходимость
iminfinitylol
это что какой то мемитический агент?
Morthan
Это вещи, которые бывают крайними, согласно правилам русского языка. Ко всему остальному полагается применять прилагательное «последний». (Не помню, из какой книги цитата. Кажись, «Акулы из стали».)
runapa
Но ведь живой язык постоянно изменяется, так что: ничто не вечно под луной, в том числе и этот список.
Alexey2005
Он не меняется, его меняют. Конкретно это изменение инициировано мракобесами, которые непонятно с чего решили, что если они будут говорить "последний", то это повысит шансы указанного события действительно стать для них последним.
Поэтому не вижу смысла идти на поводу у чрезмерно суеверных людей, поддерживая подобные изменения.
Alexey2005
Определение даты, чтение данных из системы - это же всё идёт через WinAPI, а потому ловится на раз. Хакеры могут даже и не ломать защиту, а просто отследить, что там ожидает найти программа, и подставлять нужное.
А вот например защита Themida помимо прочего привязывается к идентификатору процессора. И вот вызов инструкции cpuid ни один отладчик отследить не позволяет, да и хук на неё не поставишь.
Собственно, все эти крякмисы в плане сложности к взлому реальных коммерческих программ имеют такое же отношение, как страйкбол - к реальным боевым действиям.
Вот просто попробуйте сами написать простенькую программу, проверяющую ключ, навесьте сверху любую коммерческую защиту, да хоть той же Themida сверху завесьте, и попробуйте потом это сломать.
Первым делом сильно удивитесь, в какое *** там превращён код. Каждые 3 инструкции - jmp хз куда, код модифицируется прямо во время работы, всюду непрямые вызовы через ret с переписанным адресом возврата и вызовом контролируемых исключений. IDA покажет вам просто груду мусора, вы даже начальный загрузчик, который расшифровывает основной код, там разобрать не сможете.
Такое только "вживую" в отладчике изучать. Предварительно разобравшись, как бороться с антиотладочными приёмами, которых там выше крыши.
А ведь это далеко не самая крутая защита - так, крепкий середнячок.
В общем и целом, современные коммерческие защиты уже вышли на уровень, на котором они принципиально не ломаются без специализированного самописного софта на тысячи человеко-часов работы. Поэтому-то тут рулят хакерские группы, где куча народу совместными усилиями пишет анализаторы с распаковщиками и специализированные инструменты. Этот софт очень сложный, в него вложена куча времени продвинутых спецов, и он приносит им реальные деньги, а потому в свободный доступ не попадает.
iminfinitylol
вот такую концепцию не совсем понимаю, пиши больше - делай меньше, почему тогда не имеет смысл доставить исходники этой приблуды на прямую поставщика, нежели ломать готовую программу?
BerserkZak
Звучит очень интересно, я правда только начинающий разработчик, если так можно выразиться. Возьму на вооружение в дальнейшем, когда буду свои проекты защищать, хд
ame0ba
т.е. обойти её можно изменением даты ПК?