
Возможно некоторые знают аналогию с краном и плотиной - заткнуть протечку воды в кране на кухне это один инструмент, а вот в плотине - совершенно другой. Иногда нам надо переложить JSON из одного микросервиса в другой. Иногда JSON размером в пару гигабайт и ты ловишь ошибку с максимальным размером строки в V8.
Кейс из жизни - синхронизируем данные из стрима. Стрим очень деревянный, на HTTP в виде эдакого SSE - канал не закрывается, запрос не завершается сам по себе, данные летят по чуть-чуть, привычный нам JSON, по объекту, можно парсить библиотеками для стримов JSON или реализовать что-то своё. Так или иначе получаем набор данных. И всё хорошо. Но при первом подключении мы получаем слепок данных, текущий стейт, а потом летят обновления. И стейт прилетает пачкой в пару гигабайт JSON.
Пройдемся по порядку в вариантах решения проблемы.
Шаг 1 - в лоб

Нам прилетели данные, мы их парсим, создаем модели под сущности, пишем в базу по одному. Неплохо. Неплохо если там сотня объектов. Но вот если их тысяча - долго лить будем, да и какой-то ддос базы получаем. Неприемлемо.
Шаг 2 - балк

Отлично, чего нам писать в базу по одному, обычно мы имеем функциональность балк-записей в базу, запишем пачку за один раз. И это решает проблему, данные летят компактно. Только вот если объектов реально тысяча и они не в пару полей - тяжелый запрос в базу, надо бы как-то порезать. Да и пока пишем - надо ведь свежее прилетающее где-то хранить, нужен какой-то буффер.
Шаг 3 - массив

Хорошо, мы можем положить данные в массив, а потом забирать оттуда данные, пачками, а потом писать в базу. Хороший кейс, не делаем ддоса, свежие данные есть куда положить. Правда к базе можно подключаться пулом потоков, ну и пока мы ждем ответа - можно ещё данных заслать.
Бонус для любителей иммутабельности - если начать пересоздавать массив на каждое изменение, то мы умрем примерно вот на этом шаге. Увы, такие подходы подходят только для малых наборов данных, что свойственно, к примеру, для фронтенда, и это нормально и правильно. Но вот на тысячу толстых элементов у нас быстро закончится память и очистка мусора зашьется удалять старое на лету. Иммутабельность для массивов мы забываем на этом шаге.
Шаг 4 - пул

Хорошо, сделаем пачку циклов, либо рекурсий - будем доставать из буффера данные, балком писать в базу, ждать завершения и доставать ещё данные. Главное при выборе варианта с рекурсией не забыть что объявленая ещё в ES2015 поддержка хвостовых рекурсий так и не была завезена в V8 ноды и надо сделать разрыв для обхода ограничения на глубину рекурсий и потребление памяти из-за стека вызова, самый лучший вариант это setImmediate, потому что с промисами разрыва не будет, а на таймаутах мы получим толстый оверхед очереди таймера, слишком толстый чтобы не взять иммедиэйт. Или просто сделать цикл.
Всё хорошо у нас... но на миллионе объектов мы получаем лютейшую просадку, что пошло не так?
Нам нужно знать порядок поступления данных - к нам приходит слепок, затем новые данные, это апдейты старых. Нам очень важно знать порядок. А это значит нам надо класть в массив с одной стороны, а вот забирать с другой. И это значит у нас будет pop и shift. И с pop у нас всё хорошо, мы забираем последний элемент, а вот с шифтом всё интереснее. Дело в том чтобы добавить что-то в начало массива - нужно передвинуть весь масив, буквально. Под капотом полетит перемещение каждого элемента вперед и потом добавление нового в начало. Могут быть внутренние оптимизации, но результат всегда один - адские тормоза на миллионе элементов.
Но что же делать? Ведь нам важен порядок, а что мы можем использовать кроме массива? С объектом не выйдет, мапы с итераторами... как ни странно, но работают, однако в определенный момент счетчик внутри ломается и что-то теряется, не так пишется. Только массивы могут нам обеспечить порядок данных, чтобы друг за другом. Можно решить через сдвигание не сразу, завести счетчик, очищать раз в минуту и прочие оптимизации, когда мы откладываем перемещение массива на потом. Они помогают, реально помогают, но не очень, да и память заполняется. У нас нет решения на основе типов данных JS, но, возможно, есть решения другого толка?
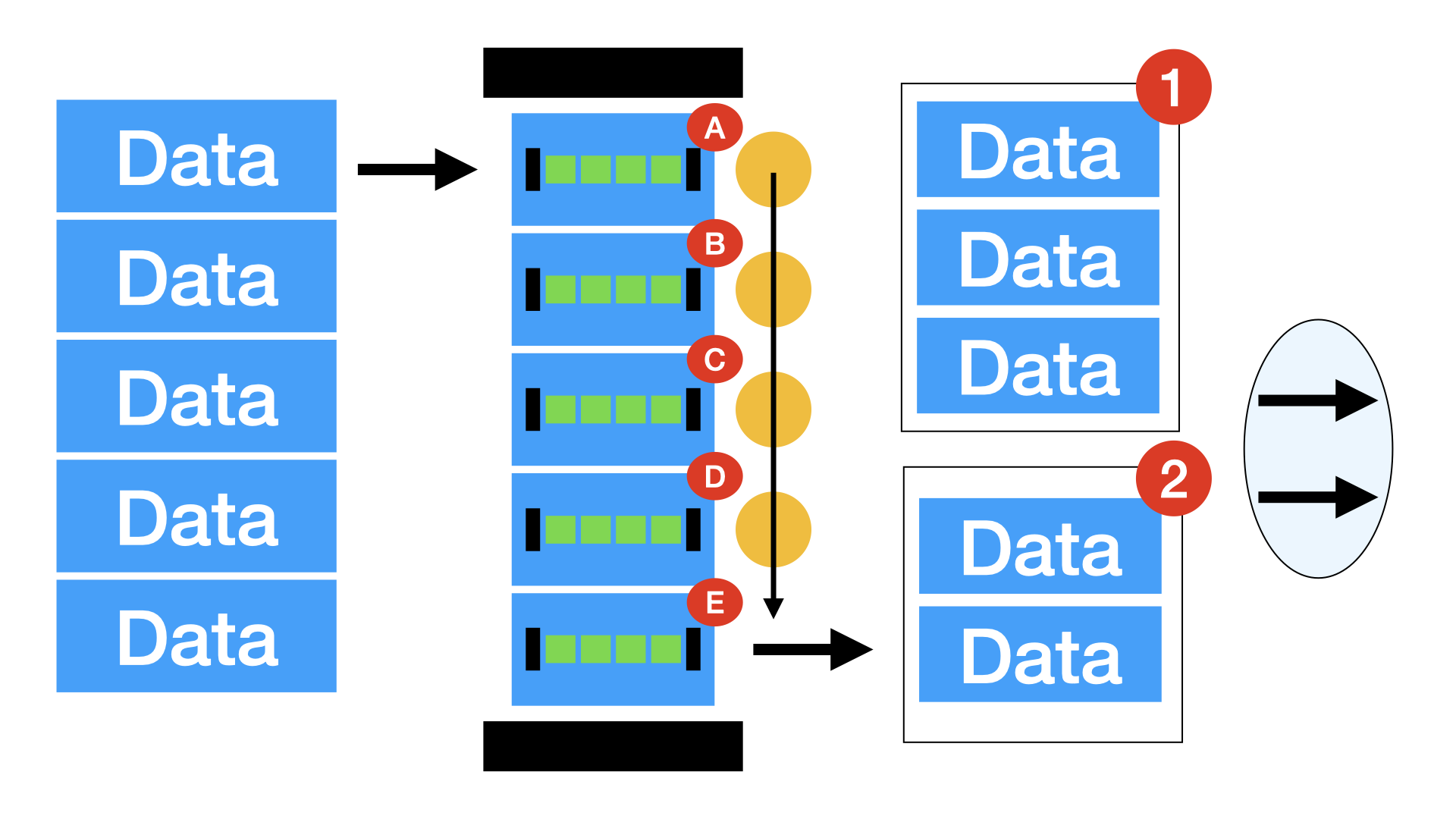
Шаг 5 - цепочка

И вот тут к нам приходят алгоритмы базовых собеседований. Чаще всего в жизни оно нам не нужно, но вот в такой задаче - как раз этот самый кейс. Ответ банален и смешон - односвязный список. Просто объект, узел, которых хранит значение и ссылку на следующий узел.
В итоге мы можем хранить ссылку на самый первый узел и самый последний. При приходе новых данных - мы создаем новый узел, берем ссылку на конец, берем этот концевой узел, прописываем ему ссылку на следующий узел как ссылку на наши новые данные, на наш новый узел, ну а после обновляем нашу ссылку на конец, теперь она будет ссылаться на наши новые данные, свежесозданый узел. И так повторяем для каждого нового пришедшего слепка данных. Ну а данные для записи в базу достаем из начала, по ссылке на первый узел, после меняем ссылку на начало - теперь это ссылка на следующий узел, которая хранилась в текущем узле. В конце обнуляем сслыку на следующий узел, открепляя взятый в работу узел окончательно. Дальше с ним разберется уже очистка памяти движка ноды, как только произойдет запись в базу и он выпадет из видимости функций записи. Элегантно, просто, эффективно.
В итоге мы никогда не имеем проблем с тем что нужно передвигать большие объемы данных, у нас нет проблем со всякими счетчиками, вообще нет даже такого понятия. Мы просто примитивно манипулируем ссылками на данные, а дальше V8 делает всё сам. Результат - у нас больше нет тормозов.
Но, о боже, к нам пришло пару гигабайт JSONа, сервера обзаводятся новыми планками оперативки, что же нам делать?
Шаг 6 - ключи

Не все знают, но понятие ключ-значение - это лишь удобство. Более того, у нас есть в живую примеры того как эта проблема решается - современные табличные базы данных. Дело в то что хранить ключи... совсем не обязательно. Мы можем хранить значения просто по порядку, массивом, главное точно соблюсти порядок. А вот ключи мы можем не хранить в данных вовсе, лишь знать по бизнес-логике по какому номеру какие данные лежат. Чего уж там - в базу данных мы можем записать данные таким же образом, массивом, такой синтаксис поддерживается, ключи не нужны. Казало бы простая мысль, но осознаешь это не сразу, ведь пришел JSON с ключами... ну... так и сохраним. Однако когда у нас есть буффер и он очень большой - удаление ключей в процессе парсинга экономит память иногда кратно, кейс из жизни - уменьшение потребления оперативки в 2 раза. Да, для этого у нас должна быть схема данных, если это произвольный JSON - не получится, однако, за исключением специфических кейсов, всегда есть определенный формат апи, тем более в базу как-то кладем. Если там есть колонки - значит нам уже есть где поиграться с такой оптимизацией. А ещё лучше - если поставщик данных сразу пришлет данные в виде массивов, но не всегда можно влиять на поставщика.
Бонус
Также мы можем хранить некоторые данные в типизированных буферах, типе данных в ноде для всяких бинарных вещей и, при некоторых кейсах, мы можем этим пользоваться, однако, использование такого может быть и во вред, конвертация туда-сюда может выйти затратной. Так что этот пункт только для узких применений.
Результаты

Таким вот набором шагов мы можем выживать в случае получении пачек данных в гигабайтах и выживать, при этом, без боли, без магии, без костылей - просто правильные структуры данных и алгоритмы. Обычно это нам не нужно, и всё же когда оно нужно - об этом эта статья. Без такой оптимизации работа подобного сервиса не возможна просто физически - не поместится в память, ддос базы, оверхед в перемещении в часах перемалываний. Не реализуема в лоб принципиально. А с нашими шестью шагами - быстро, эффективно, экономно. Красиво.
dyadyaSerezha
Это в JavaScript или ее основных библиотеках нет коллекции типа "очередь"? Дорогая редакция, я фигею.
Кстати, выражение "сжимаем память" тут вообще не подходит.
Format-X22 Автор
Да, из коробки такого типа данных нет, но есть сторонние библиотеки, от однофункциональных модулей до комбайнов. Но в базе у нас массивы, объекты (ключ-строка со значением), и ещё близкие к этому мапы и сеты. Чего уж там - и типов чисел всего два - просто число и BigInt. И тем не менее оно работает уже грубо тридцать лет и вполне. Однако иногда требуется чуть большее.
Под сжатием тут про потребление и упаковку данных, сжатие хранения в буфере том же, возможно с опытом системного программирования звучит чуть иначе, но мы про JS и более абстрактно.
titovmaxim
Тоже очень долго ждал, когда появится какое-то откровение и уникальность. Банальная очередь. Ну односвязный список, если заморачиваться не хочется. Здесь лучше кольцевой на один передатчик и один приемник. Т.е. вообще lock free. Сколько раз делал и не знал, что над этим думать нужно...
mayorovp
В однопоточном языке нет смысла в lock free алгоритмах.