
Это вторая и заключительная часть статьи, в которой мы рассматриваем задачу классификации экзопланет. Если предыдущая статья была больше про предобработку данных, то здесь мы будем строить модели, отбирать лучшие и экспериментировать.
P.S. некоторые моменты могут быть не понятны, поэтому лучше начать с первой части: https://habr.com/ru/articles/800999/
Итак я надеюсь что все кто хотел, посмотрели первую часть, поэтому можно начинать.
Случайный Лес
В тот раз мы отобрали признаки методом Gain, используя случайный лес, сейчас посмотрим, насколько эффективно было это делать, построив еще одну модель случайного леса.
rfi = RandomForestClassifier(max_depth=2, random_state=42)
rfi.fit(X_train[['koi_fpflag_nt', 'koi_fpflag_ss', 'koi_fpflag_co', 'koi_fpflag_ec',
'koi_depth', 'koi_prad', 'koi_prad_err1', 'koi_prad_err2', 'koi_teq',
'koi_insol_err1', 'koi_insol_err2', 'koi_model_snr', 'koi_steff_err1',
'koi_steff_err2']], y_train)
rfi_pred_train=rfi.predict(X_train[['koi_fpflag_nt', 'koi_fpflag_ss', 'koi_fpflag_co', 'koi_fpflag_ec',
'koi_depth', 'koi_prad', 'koi_prad_err1', 'koi_prad_err2', 'koi_teq',
'koi_insol_err1', 'koi_insol_err2', 'koi_model_snr', 'koi_steff_err1',
'koi_steff_err2']])
rfi_pred_test=rfi.predict(X_test[['koi_fpflag_nt', 'koi_fpflag_ss', 'koi_fpflag_co', 'koi_fpflag_ec',
'koi_depth', 'koi_prad', 'koi_prad_err1', 'koi_prad_err2', 'koi_teq',
'koi_insol_err1', 'koi_insol_err2', 'koi_model_snr', 'koi_steff_err1',
'koi_steff_err2']])На самом деле не очень красочно таскать с собой этот список из признаков, но я человек ленивый, увидел вывод признаков в Feature Selection, скопировал, добавил скобочки [квадратные] и вперед.
Посмотрим на метрики
metrics(y_test,rfi_pred_test)accuracy: 0.9456351280710925
f1: 0.94831013916501
roc auc: 0.9462939057241274
А че это за функция такая может спросить читатель, который не перешел на первую часть и поленился. Не осуждаю. Это функция и вот она:
def metrics(y_true,y_pred):
acc=accuracy_score(y_true, y_pred)
f1=f1_score(y_true, y_pred)
roc_auc=roc_auc_score(y_true, y_pred)
print(f'accuracy: {acc}\nf1: {f1}\nroc auc: {roc_auc} ')Поскольку мы будем строить больше чем несколько моделей наличие такой функции упрощает нам жизнь, инженерное решение, можно сказать)
Теперь вспомним про то, что еще мы использовали F-тест для отбора признаков, получили такой список: ['koi_fpflag_nt', 'koi_fpflag_ss', 'koi_fpflag_co', 'koi_fpflag_ec', 'koi_depth', 'koi_teq', 'koi_steff_err1', 'koi_steff_err2'] , с него просто забираем переменную X_f, которая объявлялась в коде первой части
y_f=y
X_f_train, X_f_test, y_f_train, y_f_test = train_test_split(X_f, y_f, test_size=0.2, random_state=42)
model_f=RandomForestClassifier(max_depth=2, random_state=42)
model_f.fit(X_f_train, y_f_train)
f_pred=model_f.predict(X_f_test)
metrics(y_f_test, f_pred)accuracy: 0.9790904338734971
f1: 0.9801192842942346
roc auc: 0.9798926657489797
Пока что F-test это самое лучшее что случалось с этими данными, мне очень нравятся такие метрики, но мы на этом не остановимся.
XGBoost

Прежде чем строить модель XGBoost, прогоним его через GridSearchCV, скорее всего это произойдет относительно быстро. Я просто отмечу, что чем больше параметров вы решили прогнать, тем больше времени это займет.
GridSearchCV позволяет отобрать лучшие параметры для обучения модели, по моим ощущениям у XGBoost данная функция работает быстрее чем у Catboost, как и в принципе процесс обучения. Возможно я не прав, поэтому если у кого то есть мысли на этот счет, хотелось бы их послушать.
Запускаем процесс:
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
xgbmodel = XGBClassifier()
parameters = {'learning_rate': [0.03, 0.1],
'max_depth': [2,3.5, 10],
'colsample_bytree': [0.7, 0.5, 1],
'n_estimators': [0,150,10]}
xgb_grid = GridSearchCV(xgbmodel,
parameters,
cv = 2,
n_jobs = 5,
verbose=True)
xgb_grid.fit(X,y)
print(xgb_grid.best_score_)
print(xgb_grid.best_params_)На выходе получаем такое:
Fitting 2 folds for each of 54 candidates, totalling 108 fits 0.9807611877875366 {'colsample_bytree': 1, 'learning_rate': 0.03, 'max_depth': 2, 'n_estimators': 150}
записываем эти параметры в нашу модель XGBoost
xgb=XGBClassifier(n_estimators=150, learning_rate=0.1, max_depth=2, colsample_bytree=0.7 ,randomstate=0)
xgb.fit(X_f_train, y_f_train)
metrics(y_test, xgb.predict(X_f_test))accuracy: 0.9822268687924726
f1: 0.9831516352824579
roc auc: 0.982836728555653
Метрики лучше, чем у случайного леса, причем во всех 3-х построенных его вариациях.
Можно сверху накинуть Gain и уменьшить выборку, но как по мне 8 параметров и такие метрики это хорошее соотношение. Если у кого- то будет желание, думаю реализовать метод Gain по аналогии с Random-Forest (снова же предыдущая статья) не составит труда.
А мы делаем следующий шаг
CatBoost

Отбор параметров можно сделать и через Catboost, к тому же у него есть для этого свой метод, который еще и график прикольный строит, но вам придется ждать, а параметры XGBoost у нас уже есть и думаю никто не будет против, если мы их интегрируем в Catboost с небольшими изменениями:
from catboost import CatBoostClassifier
cat=CatBoostClassifier(n_estimators=150, learning_rate=0.1, max_depth=2,bootstrap_type='Bayesian', task_type='GPU')
cat.fit(X_f_train,y_f_train, verbose=False)
cat_pred=cat.predict(X_f_test)
metrics(y_test, cat_pred)Метрики:
accuracy: 0.9822268687924726
f1: 0.9831516352824579
roc auc: 0.982836728555653
Итак, с точки зрения классического ML мы реализовали наиболее популярные модели и получили как и ожидалось получили лучшие метрики на моделях градиентного бустинга.
Нейросеть на tensorflow
Теперь проверим поставленный тезис в I части о том, что можно эту задачу решить через нейронную сеть.
Для начала стандартизируем данные относительно нормального распределения
mean=X_train.mean(axis=0)
std=X_train.std(axis=0)
X_train-= mean
X_train/= std
X_test-= mean
X_test/= std
#запринтим что мы сделали
print('train mean',X_train.mean(axis=0)[:5])
print('test mean',X_test.mean(axis=0)[:5])
print('train std',X_train.std(axis=0)[:5])
print('train std',X_test.std(axis=0)[:5])std- среднеквадратичное отклонение
mean- среднее
Кстати std будет для всех равно 1 в print-е

Небольшое отступление
Для построения НС мы будем использовать tensorflow, который после версии 2.11 перестал поддерживать обучение на GPU на Windows, подробнее можно прочитать на их сайте: https://www.tensorflow.org/install/pip?hl=ru#windows-native_1
Чтобы решить данную проблему нужно установить python версии 3.9 (у меня 3.9.18), удалять текущий пайтон не нужно, но для версии 3.9 нужно создать отдельную виртуальную среду, например через miniconda, скачать CUDA и CUDNN если у вас NVidia, насчет альтернатив не знаю, так как у самого Nvidia. Все веселье с установкой состоит в том что нужно правильно подобрать версии всех этих расширений и библиотеки tensorflow. На это действительно может уйти много времени, если ранее вы ничего подобного не делали, поэтому дополнительно может помочь этот парень с ютуба, который заморочился и сделал подробную установку всех Cuda и Cudnn: https://www.youtube.com/watch?v=xTF_n1jp9n8
Однако о создании новой Venv ( виртуальной среды) он вроде не очень много говорил, поэтому тем кто ищет гугл в помощь.
Альтернатива всему этому либо обучение на CPU то есть на обычном процессоре, либо же google Colab, где можно выбрать на чем будет работать ваша среда и пользоваться плюшками сервиса. Для данной задачи их мощностей должно хватить.
Обучение на GPU явно быстрее чем на CPU, прирост в 1.5-2 раза можно получить точно.
На этом закончим отступление
Зададим параметры модели, а перед этим проверим, работает ли GPU
import tensorflow as tf
physical_devices = tf.config.list_physical_devices('GPU')
print("Num GPUs:", len(physical_devices))
#output: 1 если gpu работает
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, activation='relu', input_shape=(X_train.shape[1],)),
tf.keras.layers.Dense(16, activation='relu' ),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
# Model: "sequential"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense (Dense) (None, 32) 1376
# dense_1 (Dense) (None, 16) 528
# dense_2 (Dense) (None, 1) 17
# =================================================================
# Total params: 1,921
# Trainable params: 1,921
# Non-trainable params: 0
# _________________________________________________________________Обучаем и смотрим на lossы
model.compile(optimizer='adam', loss='binary_crossentropy')
history = model.fit(X_train, y_train, epochs=16, verbose=1)
# Визуализация процесса обучения
plt.plot(history.history['loss'])
plt.xlim(-0.5,20)
plt.title('Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
Воспользуемся Datageneratorом, позаимствованным у этого прекрасного автора с youtube: https://www.youtube.com/watch?v=PLlic60dgS4&list=PLkJJmZ1EJno4lRvtQjQrNNACpeMLOd-SD&index=7
В нем задается batch_size, поэтому если вы хотите получить результат поскорее, то просто увеличьте его например до 16, 32 или 48 и т.д. Качество модели упадет, но зато она быстрее построится.
import numpy as np
from tensorflow.keras.utils import Sequence
class DataGenerator(Sequence):
def __init__(self, data, labels, batch_size=1):
self.batch_size = batch_size
self.data = data
self.labels = labels
def __len__(self):
return int(np.round(len(self.data) / self.batch_size))
def __getitem__(self, index):
X = self.data[index * self.batch_size : (index+1) * self.batch_size]
y = self.labels[index * self.batch_size : (index+1) * self.batch_size]
return X, y
train_datagen = DataGenerator(X_train, y_train)
test_datagen = DataGenerator(X_test, y_test)
print(len(train_datagen))
print(len(test_datagen))Обучим еще одну нейронку с оценкой данных на валидации
from tensorflow.keras.callbacks import ModelCheckpoint
# Создаем коллбэк для выполнения оценки на валидационных данных
checkpoint = ModelCheckpoint(filepath='best_model.h5', save_best_only=True, save_weights_only=True)
# Обучение модели с выполнением оценки на валидационных данных
history = model.fit(train_datagen, epochs=16, batch_size=100, validation_data=test_datagen, callbacks=[checkpoint])
# Загрузка лучших весов модели
model.load_weights('best_model.h5')
plt.plot(history.history['loss'], label='train loss')
plt.plot(history.history['val_loss'], label='validation loss')
plt.legend( );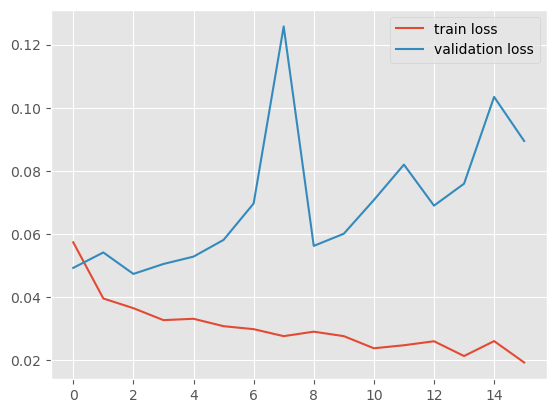
Ну такое себе, видимо не сегодня, tensorflow.
Можно покрутить параметры модели и возможно выйти на неплохие метрики, но эта игра не стоит свеч.
Бонус. Isolation Forest
Казалось бы мы сделали все что можно и после градиентного бустинга можно было остановиться и сказать что модель готова, но ради интереса можно рассмотреть Isolation Forest. Это метод обучения без учителя, который используется в задачах кластеризации и поиска аномалий.
from sklearn.ensemble import IsolationForest
clf = IsolationForest(max_samples=50, random_state=0)
clf.fit(X_f)
pred=clf.predict(X_f_test)
# на выход модель выдает либо 1 либо -1, для перехода к нашим параметрам, нужно переписать значения:
pred_processed = np.where(pred == -1, 0, pred)
pred_counts = pd.Series(pred_processed).value_counts()
# Строим график
pred_counts.plot(kind='barh', color=sns.palettes.mpl_palette('Dark2'))
plt.gca().spines[['top', 'right']].set_visible(False)
plt.title('Isolation Forest')
plt.xlim(0, pred_counts.max())
plt.show()
zeros_count = y_test[y_test == 0].count()
ones_count = y_test[y_test == 1].count()
print("Количество нулей в y_test:", zeros_count)
print("Количество единиц в y_test:", ones_count)Количество нулей в y_test: koi_pdisposition 894 dtype: int64
Количество единиц в y_test: koi_pdisposition 1019 dtype: int64
Можно прогнать его через метрики, но это не имеет особого смысла, ведь количество 0 в реальных данных примерно на 150-200 значений выше, чем у модели, да и в принципе подход метрик к задачам без учителя процесс сомнительный. Может быть мы получили совсем не то, что искали.
Вывод
Градиентный бустинг остается грозой Kaggle и является отличной моделью для решения данной задачи, которая справилась лучше чем НС. Причина как мне кажется в том, что данных для нейронки нужно на порядок больше и тогда она по другому заиграет и ожидание процесса обучения окупится. Я надеюсь, что последние 2 статьи заинтересовали определенный круг людей, как новичков, так и более опытных в data science, хотелось бы получить какой-то фидбэк по проделанной работе, или какие то советы по тому, как можно было бы улучшить результаты моделей.
CBET_TbMbI
Не спец в мл, но по самим статьям...
Сути я так и не понял. Совсем не понял. Если классификация планет, то по каким признакам (масса, размер, орбита?). И где она в итоге?
Больше похоже на поиск экзопланет, но тоже многг непонятного. Если поиск, то по каким признакам. И вообще, что в исходных данных, что в результате.
Выглядит так, что непонятно что взяли, что-то с этим сделали и непонятно что получили. А уж плохая это работа или плохая статья - судить не берусь.
Bogdan_m01 Автор
В первой статье (https://habr.com/ru/articles/800999/) как раз таки об этом и шла речь, 50 признаков в сумме, пытаемся разделить планеты на кандидатов и не кандидатов, в датасете есть начальная разметка данных, а более подробно о признаках можно прочитать здесь:
https://exoplanetarchive.ipac.caltech.edu/docs/API_kepcandidate_columns.html
поскольку данная статья рассматривалась больше в ключе ML и соответственно призвана выполнять следующее:
Определить исходя из отобранных признаков является ли небесное тело, которую обнаружили по спутнику Kepler кандидатом в экзопланету, или же нет.
Соответственно подробное рассмотрение признаков в этой статье предусмотрено не было, а ссылка на их описание может помочь тем, кто действительно готов потратить на это своё время и возможно добавить что то от себя.