
С момента выхода оригинальной статьи про трансформер прошло уже больше 7 лет, и эта архитектура перевернула весь DL: начав с NLP она теперь применяется везде, включая генерацию картинок. Но та ли это архитектура или уже нет? В этой статье я хотел сделать краткий обзор основных изменений, которые используются в текущих версиях моделей Mistral, Llama и им подобным.
Positional Embeddings (PE)
Базовый подход — к вектору каждого токена на входе добавляем вектор абсолютной позиции, может быть обучаемым, может быть какой-то функцией от позиции
Relative PE — будем на стадии attention, когда считаем
<q_i*k_j>добавлять туда эмбеддинг разностиi-j. Плюс такого подхода — легко обобщить на последовательности новой длины, которой не было на обучении-
RoPE — самый трендовый подход сейчас. На стадии attention будем поворачивать вектора
qиkв зависимости от позиции токена. Условно, если позицияtто повернем на уголt*alpha. В чем прикол — позиция кодируется поворотом, меньше вычислений чем с Relative PE, при этом relative информация сохраняется: если мы добавим текст перед парой слов, но между ними число слов не изменится — мы дополнительно повернем оба вектора на одинаковый угол, и угол между ними сохранится, а значит скалярное произведение не изменится (то, что нам важно в attention)! На самом деле там чуть сложнее: поворачивать будем не весь эмбеддинг целиком, а разобьем его на много маленьких векторов по 2 координаты, и каждый отдельно повернем (см. картинку). Ускоряет обучение, улучшает метрики, красивая идея — что еще надо?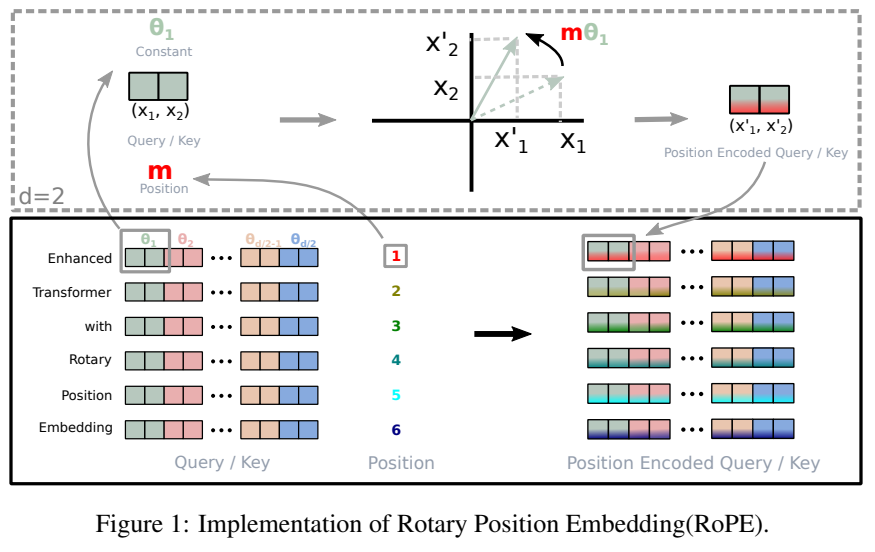
Activation Function
Немного напомню архитектуру, в трансформер-блоке после attention у нас идет линейный слой, ака linear-activation-linear. Изначально там было старое-доброе ReLU. Сейчас там SwiGLU. Вообще GLU-like слои про то, чтобы контролировать силу идущего сигнала. Условно: glu(x) = f1(x)*f2(x), где f1(x) будет сигнал, f2(x) сила сигнала, а результат это их поэлементное умножение. Дальше f1 это обычный линейный слой, а f2 может быть разной, в данном случае функция silu. Почему именно эта функция а не другая — неясно, но метрики опять же улучшает.

Attention
Главная часть трансформера. Тут сразу несколько используемых апдейтов, все так или иначе про то, чтобы ускориться/уменьшиться по памяти:
Grouped Query Attention: в обычном multi-head в каждой голове у нас для токена свои вектора
q,kиv. Тут мы разбиваем головы на группы, и внутри каждой группы вектораkиvу токена будут одинаковые. В чем суть — меньше вычислений, при не очень большой потере качестваFlash Attention: тут суть в том, что bottleneck в обращении к памяти, а не в вычислениях, и можно поменять подход на менее эффективный в плане вычислений, но более эффективный в плане памяти, за счет чего получить прирост по скорости работы — то есть это именно про то, как построить вычисления, суть и результат не меняется, а ускориться получается прилично
Sliding Window Attention: во время attention токен будет обращаться не ко всем предыдущим токенам, а только к
Wпоследним. Если у насkслоев, то наk-том слое элементiсможет получить информацию от последнихW*kтокенов. Опять же цель сэкономить по памяти, чтобы получалось работать с очень длинными последовательностямиKV-cache: тут речь про то, чтобы сэкономить во время инференса. Вообще-то мы генерируем текст рекурсивно, то есть для каждого нового токена мы прогоняем модель с самого начала. Если в тупую запускать ее для "Шла", "Шла Маша", "Шла Маша по", и т.д., то мы будем вынуждены каждый раз для всех токенов текста вычислять
q,k,vв attention. Но вообще-то для предсказания следующего токена нам не нужны предыдущие вектораq, а еще вектораkиvвсех токенов кроме последнего мы уже вычисляли и они никак не изменятся. Поэтому идея в том, чтобы держать в памяти вектораkиvво время генерации (в случае sliding window даже не все), на каждом шаге вычисляя только один вектор q, k и v для последнего токена. Тоже сильно ускоряет процесс инференса, тк позволяет избавиться от избыточных вычислений
Normalization
Базовый подход
x = norm(x + attention(x))
x = norm(x + linear(x))Текущий подход
x = x + attention(norm(x))
x = x + linear(norm(x))Почему — просто лучше сходимость. Еще одно изменение: раньше использовали layer norm: вычитаем среднее, делим на стандартное отклонение, потом умножаем на обучаемую статистику и прибавляем еще одну. Авторы статьи RMSNorm такие: ну вообще среднее не обязательно вычитать, давайте просто на что-то поделим, а потом умножим на обучаемую статистику: оказалось, что вычислений + обучаемых параметров стало меньше, а качество не ухудшилось. Так что теперь все используют.

Experts
Ну и FFN слой не обошли стороной. Люди подумали: а что если там тоже будут головы, как в attention, но по-другому?)
Пусть у нас будет не один такой FFN слой, а n. Каждый слой — это и будет "эксперт". Но при этом каждый токен будет проходить не через всех экспертов, а через k. Но как выбрать через какие k экспертов пройдет конкретный токен? Допустим, у нас есть последовательность токенов длины M и размерности D. Используем максимально тупую классификацию: домножим последовательность токенов MxD на матрицу DxN, для каждого токена получим n чисел, из них выберем k самых больших — индексы которым они соответствуют и будут индексы экспертов для этого токена. Потом к этим k числам применим softmax, получим веса для экспертов. Итоговый пайплайн такой:
классифицируем каждый токен, для него получаем индексы экспертов и их веса
каждый токен прогоняем через k экспертов (каждый эксперт это такой же SwiGLU слой, как мы обсудили)
для каждого токена складываем результаты k экспертов с весами
В чем прикол: легко параллелится + можно увеличивать число экспертов n, но не менять k — в итоге общее количество параметров модели (sparse parameter count) вырастет, можно больше информации туда запихнуть, а сложность вычислений не изменится (потому что сохранится active parameter count) — мы для каждого токена все равно будем применять k слоев. В итоге реально работает — качество растет, все супер. Довольно простая для понимания статья на тему от Mistral — вот. Они, кстати, используют n=8 и k=2.

Источники
Помимо статей, ссылки на которые есть в тексте, могу порекомендовать:
видео про experts и статью от mistral
обзор по +- всем этим темам
подробное видео про RoPE

DarkSold
Почему у отличных статей так мало просмотров, комментариев…
Danyache Автор
Ну, статья довольно специализированная, думаю, она просто не для всех)
DarkSold
Раньше подобных "специфичных" больше было. Но сейчас хабр превращается в Пикабу. Как раз, после того, как объеденили хабр с Мегамозг и гиктаймс.