
Продолжаем говорить о производительности и оптимизации кода. Сегодня поговорим о том, как и зачем оценивать сложность алгоритмов, а также наглядно покажем, как эта сложность влияет на производительность кода.
В прошлой статье мы разбирались, что такое бенчмаркинг кода и как с его помощью оценивать производительность кода в .NET. В этой – поговорим про оценку сложности алгоритмов. А чтобы все было наглядно, вместе попробуем оценить алгоритмы, которые используются для решения задачки на собеседовании в Google.
Задач такого плана полным-полно на платформах типа LeetCode, CodeWars и других. И их ценность не в том, чтобы заучить различные алгоритмы сортировок, которые вы никогда не будете на практике писать самостоятельно, а в том, чтоб увидеть типичные проблемы, с которыми вы можете столкнуться в практических задачах при разработке.
Оценка сложности алгоритмов
Зачем вообще оценивать сложность алгоритмов и какие способы оценки бывают?
Понимать сложность алгоритмов важно по следующим причинам:
без этих знаний вы не сможете отличить суб-оптимальный код от оптимального и оптимизировать его;
каждый средний или большой проект рано или поздно будет оперировать большим объемом данных. Важно, чтоб ваши алгоритмы это предусматривали и не стали бомбой замедленного действия;
если вы не понимаете концепции оценки сложности алгоритмов, есть вероятность, что вы будете писать низкопроизводительный код.
Чаще говорят про оценку алгоритма по времени (time complexity) — сколько времени понадобится для его выполнения. Время выполнения зависит от количества элементарных операций, которые выполняет компьютер.
Для каждого алгоритма можно сделать несколько оценок сложности:
O большое (O(f)) — позволяет оценить верхнюю границу сложности алгоритмов. Это отношение количества входных данных для алгоритма ко времени, за которое алгоритм сможет их обработать. Простыми словами – это максимальное время работы алгоритма при работе с большими объемами данных.
Омега (Ω(f)) — позволяет оценить нижнюю границу сложности — сколько времени займет работа алгоритма в лучшем случае.
Тета (Θ(f)) — позволяет получить “плотную” оценку сложности, то есть такую, при которой скорость работы в худшем и лучшем случае будет пропорциональна одной функции. Применимо не ко всем алгоритмам.
В IT компаниях зачастую обращают внимание на большое O (Big-O notation), поскольку чаще всего достаточно представлять, как быстро будет расти количество операций при увеличении входных данных в худшем случае. Остальные типы оценок используются редко.
В скобках после О указывают функцию, которая ограничивает сложность. При этом n — это размер входных данных. Например, O(n) означает, что сложность алгоритма растёт линейно. В таком случае время выполнения алгоритма увеличивается прямо пропорционально размеру входных данных.
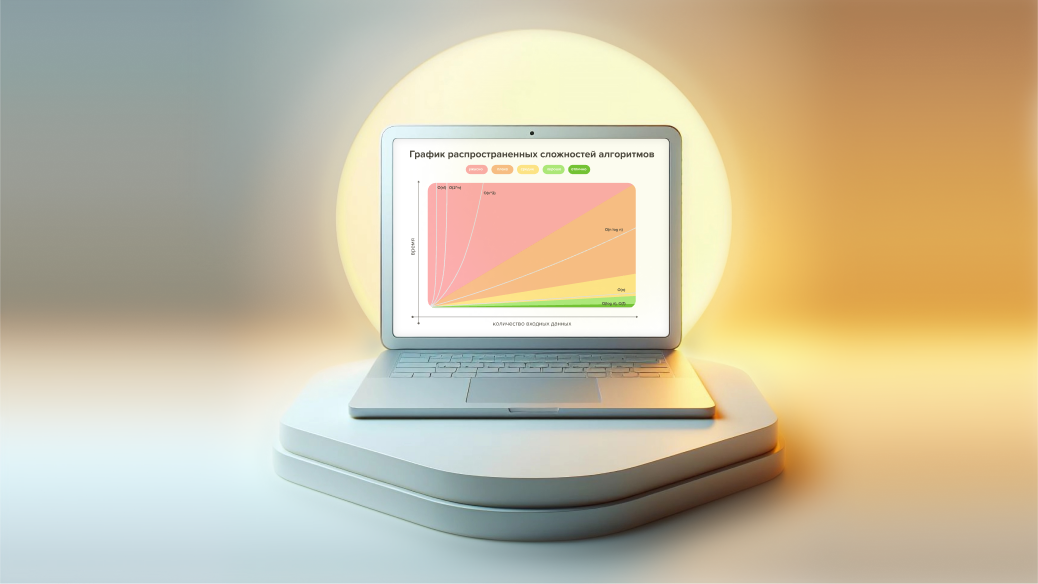
Если представить график распространенных сложностей алгоритмов, они будут выглядеть вот так:

Если условно разделить сложности на зоны, то сложности вида O(log n), O(1) или O(C) можно будет отнести к зоне «Отлично». Такие алгоритмы вне зависимости от объемов данных будут выполняться очень быстро — практически мгновенно.
Алгоритмы сложности O(n) можно отнести к зоне «Средне» — алгоритмам, сложность которых растет предсказуемо и линейно. Например, если 100 элементов ваш алгоритм обрабатывает за 10 секунд, то 1000 он обработает примерно за 100 секунд. Не лучший результат, но предсказуемый.
Алгоритмы из красной зоны со сложностями и выше трудно отнести к высокопроизводительным. НО! тут все сильно зависит от объемов входных данных. Если вы уверены, что у вас всегда будет небольшой объем данных (например, 100 элементов), и обрабатываться он будет в приемлемое для вас время, то все в порядке, такие алгоритмы тоже можно использовать. Но если же вы не уверены в постоянности объемов данных (может прийти и 10 000 элементов вместо 100) — лучше все-таки задуматься над оптимизацией алгоритмов.
Добавим, что оценка сложности по времени — это теоретическая оценка. Она не учитывает внутренние оптимизации и кеш процессора, в реальности картина может отличаться.
Оценка сложности по памяти
Оценку сложности алгоритмов следует проводить не только по времени выполнения, но и по потребляемой памяти — часто про это забывают во время изучения темы.
Например, для ускорения вычислений можно создать какую-нибудь промежуточную структуру данных типа массива или стека для ускорения алгоритма и кеширования результатов. Это приведет к дополнительным затратам памяти, но при этом может существенно ускорить вычисления.
Сложность по памяти также называют пространственной сложностью (space complexity) и для оценки используют такую же нотацию как для времени — большое O. Например, сложность по памяти
, означает что в худшем случае для алгоритма не понадобится больше памяти, чем пропорционально
.
Важно отметить, что при оценке сложности алгоритмов по памяти используют упрощенную модель работы с памятью, так называемою RAM-машину. Это означает, что мы можем читать и записывать любую ячейку памяти за время одной операции. Таким образом, время вычислительных операций и операций с памятью становится одинаковым, что упрощает анализ. Это ближе всего к работе с оперативной памятью, и, например, не учитывает регистры процессора, работу с диском, garbage collector и много чего еще.
Немного практики: правила расчета сложности на пальцах
Мы приводим примеры на C#, хотя здесь можно было бы обойтись и псевдокодом. Надеемся, что они будут понятны.
Пример 1:
Возьмем для начала простой алгоритм присвоения переменной:
private void Alg1(int[] data, int target)
{
var a = data[target];
}Какова его сложность по времени и по памяти?
С одной стороны, нас может ввести в заблуждение массив данных data неизвестной размерности. Но брать его в расчет при оценке сложности внутреннего алгоритма будет некорректно.
Правило 1: внешние данные не учитываются в сложности алгоритма.
Получается, наш алгоритм состоит только из одной строчки:
var a = data[target];
Доступ к элементу массива по индексу — известная операция со сложностью O(1) или O(C). Соответственно, и весь алгоритм по времени у нас займет O(1).
Дополнительная же память выделяется только под одну переменную. А значит, объем данных, которые мы будем передавать (хоть 1 000, хоть 10 000), не скажется на финальном результате. Соответственно, сложность по памяти у нас так же — O(1) или O(C). Такие алгоритмы называются алгоритмами на месте (in-place). Они могут использовать дополнительную память, но её размер не зависит от количества входных данных.
Для упрощения записи дальше я везде буду писать O(C) вместо O(1), C в этом случае — это константа. Она может равняться 1, 2 или даже 100 — для современных компьютеров это число не принципиально, поскольку и 1, и 100 операций выполняются практически за одно и то же время.
Пример 2:
Рассмотрим второй алгоритм, очень похожий на первый:
private void Alg2(int[] data, int target)
{
var a = data[target];
var b = data[target + 1];
}Влияет ли размерность входного массива data на количество операций в нем? Нет.
А на выделенную память? - Тоже нет.
Сложность этого алгоритма по времени выполнения можно было бы оценить как O(2*C) — поскольку у нас выполняется в два раза больше операций, чем в предыдущем примере, 2 присваивания вместо 1. Но у нас и на этот счет есть правило:
Правило 2: опускать константные множители, если они не влияют на результат кардинальным образом.
Если принять это правило в расчет, сложность этого алгоритма будет такой же, как и в первом примере — O(C) по времени и O(C) по памяти.
Пример 3:
В третьем примере добавим в наш алгоритм цикл для обработки данных:
private int Alg3(int[] data)
{
var sum = 0;
for (int i = 0; i < data.Length; i++)
{
sum += data[i];
}
return sum;
}Как мы видим, количество операций, которые будет выполнять цикл, напрямую зависит от количества входных данных: больше элементов в data — больше циклов обработки потребуется для получения финального результата.
Казалось бы, если взять в учет каждую строчку кода нашего алгоритма, то получилось бы что-то такое:
private int Alg3(int[] data)
{
var sum = 0; // O(C)
for (i=0; i < data.Length; i++) // O(n)
{
sum += data[i]; // O(C)
}
return sum;
}И тогда финальная сложность алгоритма получится O(C)+O(n). Но тут опять вмешивается новое правило:
Правило 3: опускать элементы оценки, которые меньше максимальной сложности алгоритма.
Поясню: если у вас O(C)+O(n), результирующая сложность будет O(n), поскольку. O(n) будет расти всегда быстрее, чем O(C).
Еще один пример — . При такой сложности у нас n2 всегда растет быстрее, чем N, а значит O(n) мы отбрасываем и остается только
.
Итак, сложность нашего третьего примера — O(n). По памяти без изменений — О(С).
Пример 4:
В четвертом примере посчитаем сумму всех возможных пар значений из массива:
private int Alg4(int[] data)
{
var sum = 0;
for (int i = 0; i ‹ data.Length; i++)
{
for (int j = 0; j ‹ data.Length; j++)
{
sum += data[i]*data[j];
}
}
return sum;
}И для его обработки нам теперь нужно два цикла. Оба этих цикла будут зависеть от размерности входных данных data.
Правило 4: вложенные сложности перемножаются.
Сложность внешнего цикла в нашем примере — O(n), сложность внутреннего цикла — O(n). Согласно правилу, две эти сложности должны быть умножены. В результате максимальная сложность всего алгоритма выйдет равной . По памяти без изменений — О(С).
Пример с подвохом:
Подадим на вход двумерный массив и посчитаем сумму значений.
private int Alg4_tricky_case(int[][] data)
{
var sum = 0;
for (int i = 0; i < data.Length; i++)
{
for (int j = 0; j < data.Length; j++)
{
sum += data[i][j];
}
}
return sum;
}Снова видим вложенные циклы — и если во входном массиве N x M элементов, то есть сложность O(N * M), и кажется, что это эквивалентно . Но на самом деле, нет — в данном случае на вход просто подается N * M элементов и время пропорционально N * M, то линейное O(n).
Пример 5:
А что мы видим тут? Цикл — уже известная нам сложность – O(n). Но внутри вызывается функция Alg4() из предыдущего примера:
private int Alg5(int[] data)
{
var sum = 0;
for (int i = 0; i ‹ data.Length; i++)
{
sum += Alg4(data);
}
return sum;
}Если мы вспомним ее сложность , а также правило 4, то получим, что сложность этого алгоритма —
при всей его визуальной минималистичности. Со сложностью по времени без изменений.
Правило 5: включайте в оценку общей сложности алгоритма оценки всех вложенных вызовов функций.
Именно поэтому важно понимать сложность методов синтаксического сахара вроде LINQ, базовых коллекций и типов данных — чтоб была возможность оценить, как метод будет вести себя при увеличении объемов данных. При использовании их в коде без понимания внутреннего устройства, вы рискуете получить очень высокую сложность алгоритма, который будет захлебываться при увеличении входящих данных.
Приведу пример минималистичного алгоритма, который выглядит хорошо и компактно (ни в коем случае не претендует на эталонный код), но станет бомбой замедленного действия при работе с большими объемами данных:
private List<int> Alg6(int[] data)
{
List<int> dups = new List<int>();
for (var i = 0; i < data.Length; i++)
{
var currentItem = data[i];
var newArr = data.Skip(i + 1).ToArray();
var duplicates = newArr.Where(x => newArr.Contains(currentItem));
dups.AddRange(duplicates);
}
return dups;
}Что мы тут видим? Цикл = O(n), Where = O(n), Contains = O(n), так как newArr – это массив.
Итого сложность такого алгоритма будет от по времени выполнения.
ToArray() будет выделять на каждой итерации дополнительную память под копию массива, а значит сложность по памяти составит O(n).
Задачка от Google
Возьмем для нашего финального оценивания задачку, которую дают на собеседовании в Google.
Подробный разбор задачи и алгоритмы решения можно посмотреть вот в этом видео от Саши Лукина. Рекомендую посмотреть его перед продолжением чтения этой статьи.
Вкратце, цель алгоритма — найти в отсортированном массиве два любых числа, которые в сумме дали бы нам искомое число target.
Решение 1: полный проход по массиву
public static int[] FindPairWithFullWalkthrough(int[] data, int target)
{
for (int i = 0; i < data.Length; i++)
{
for (int j=i+1; j < data.Length; j++)
{
if (data[i] + data[j] == target)
return new[] { data[i], data[j] };
}
}
return new int[0];
}Сложность по времени: O(n2)
Сложность по памяти: O(С)
Это решение в лоб. Не самое оптимальное, поскольку время быстро растет при увеличении количества элементов, но зато дополнительную память мы особо не потребляем.
Решение 2: используем HashSet
public static int[] FindPairUsingHashSet(int[] data, int target)
{
HashSet<int> set = new HashSet<int>();
for (int i = 0; i < data.Length; i++)
{
int numberToFind = target - data[i];
if (set.Contains(numberToFind))
return new [] { data[i], numberToFind };
set.Add(data[i]);
}
return new int[0]
}Проходимся по массиву и элементы, которые мы уже проверили добавляем, в HashSet. Если HashSet содержит недостающий для суммы элемент, значит все хорошо , мы закончили и можем возвращать результат. Добавление и поиск в HashSet делается за время O(C).
Сложность по времени: O(n)
Сложность по памяти: O(n)
Это как раз пример того, как можно выиграть в производительности, выделив дополнительную память для промежуточных структур.
Решение 3: используем бинарный поиск
public static int[] FindPairUsingBinarySearch(int[] data, int target)
{
for (int i = 0; i < data.Length; i++)
{
int numberToFind = target - data[i];
int left = i + 1;
in right = data.Length - 1;
while (left <= right)
{
int mid = left + (right - left) / 2;
if (data[mid] == numberToFind)
{
return new[] { data[i], data[mid] };
}
if (numberToFind < data[mid])
{
right = mid - 1;
}
else
{
left = mid + 1;
}
}
}
return new int[0];
}Алгоритм бинарного поиска имеет известную сложность — O(log(n)). O(n) нам добавилась от внешнего цикла for, а все, что внутри цикла while — это и есть алгоритм бинарного поиска. Согласно Правилу 4 сложности перемножаются.
Сложность по времени: O(n*log(n))
Сложность по памяти: O(С)
Решение 4: используем метод двух указателей
public static int[] FindPairUsingTwoPointersMethod(int[] data, int target)
{
int left = 0;
int right = data.Length - 1;
while (left < right)
{
int sum = data[left] + data[right];
if (sum == target) return new[] { data[left], data[right] };
if (sum < target)
{
left++;
}
else
{
right--;
}
}
return new int[0];
}Двигаем левый и правый указатели к центру, пока они не сойдутся или не найдется пара подходящих нам значений.
Сложность по времени: O(n)
Сложность по памяти: O(С)
И это — самый оптимальный из всех вариантов решения, не использующий дополнительной памяти и совершающий наименьшее количество операций.
Бенчмаркинг решений
Теперь, зная сложности всех четырех вариантов решения, попробуем провести бенчмаркинг этого кода и посмотреть, как алгоритмы будут вести себя на различных наборах данных. В этом поможет информация из предыдущей нашей статьи.
Результаты будут следующими:

Что мы тут видим?
За baseline решения мы берем прямой проход массиву FindPairWithFullWalkthrough. На 10 объектах он отрабатывает в среднем за 20 наносекунд и занимает второе место по производительности.
Быстрее на малом объеме данных выполняется только наш самый оптимальный вариант решения — FindPairUsingTwoPointersMethod.
Вариант же с HashSet занял в 8 раз больше времени для работы с малым объемом данных и потребовал выделения дополнительной памяти, которую потом нужно будет собрать Garbage Collector-у.
На 1 000 же элементов вариант с полным проходом по циклу (FindPairWithFullWalkthrough) начал заметно отставать от остальных алгоритмов. Причиной этому — его сложность O(n^2), которая растет заметно быстрее всех остальных сложностей.
На 10 000 элементах алгоритму с полным проходом потребовалось и вовсе 9,7 секунды для завершения расчетов, в то время как остальные справлялись за 0.1 секунды и меньше. А самый оптимальный вариант решения и вовсе нашел решение за 3 миллисекунды.
Почему же бинарный поиск обогнал HashSet? Ведь в теории O(n * log(n)) должен быть медленнее O(n)? Дело в том, что на реальных, а не теоретических компьютерах выделение и освобождение работает не за одинаковое время – то и дело включается Garbage collector. Это подтверждают значения стандартного отклонения (StdDev) в бенчмарке HashSet.
Заключение
Мы разобрались, как оценивать сложность алгоритмов, а также узнали, как с помощью BenchmarkDotNet проследить связь между сложностью алгоритмов и временем выполнения кода. Это позволит еще до выполнения бенчмаркинга приблизительно оценить — хороший код вы написали или нет.

Комментарии (18)


aleksandernekr
17.04.2024 11:58private vpid Alg2(int[]data, int target)
Опечатка: нужно void.
В 3 примере:
data.Lenght
Ещё i в цикле не инициализирована
for (i , data.Lenght; i++) // O(n)
В 4 правиле нужно data и for
for (int i = 0; i < dana.Lenght; i++)
{
fir (int j = 0; j < data[i].Lenght; j++)

andrey_stepanov1 Автор
17.04.2024 11:58Спасибо, при верстке кода со скринов наделал ошибок — вроде все исправил

Alexandroppolus
17.04.2024 11:58+1Правило 4 применимо для простого кейса - когда сложность внутреннего цикла не зависит от текущей итерации внешнего. Если зависит, то придется аккуратно просуммировать сложности, и там может выйти по разному. Например, в пузырьковой сортировке так и остается O(N^2), а вот для того же heapify внезапно оказывается O(N)
andrey_stepanov1 Автор
17.04.2024 11:58Да — именно это как раз пытался показать в Примере с подвохом.
Alexandroppolus
17.04.2024 11:58в этом примере несколько другое. А именно, что конкретно брать за "N" в О-большом. Если длину стороны матрицы, то так и будет O(N^2)

nronnie
17.04.2024 11:58+1нас может ввести в заблуждение массив данных data неизвестной размерности
Наверное, все-таки, размера а не размерности - лучше поправьте.

dyadyaSerezha
17.04.2024 11:58Но внутри вызывается функция Alg4() из предыдущего примера
Предыдущий Alg4 принимает двумерный массив. А вот предпредыдущий - одномерный. У вас два Alg4. Поправьте.
Ну и общее замечание - из-за активного кеширования у современных CPU многие классические оценки часто не работают вплоть до размеров данных в несколько К элементов. Надо тестировать.
andrey_stepanov1 Автор
17.04.2024 11:58Да, запутал с одинаковыми названиям Alg4, сейчас исправил. Добавил верное замечание про CPU — спасибо!

piton369
17.04.2024 11:58В 5 примере странно, я не вижу O(n^3) в этой строке:
что сложность этого алгоритма — O(n^3) при всей его визуальной минималистичности.но когда я скопировал эту строку для того чтобы указать на опечатку, сюда оно скопировалось.
Может это проблема на моей стороне.
mayorovp
17.04.2024 11:58Там картинка с alt-текстом, у вас не прогрузилась картинка, а при копировании в буфер попал alt-текст.
Почему картинка не прогрузилась - выясняйте сами.

MaNaXname
17.04.2024 11:58Решение 4
не хватает кода после return идут {}andrey_stepanov1 Автор
17.04.2024 11:58В последней строке?
MaNaXname
17.04.2024 11:58а ну вот поправили добавив
if (sum < target)
теперь стало понятно что код работает
LinarMast
Возник вопрос к правилу 4.
Почему пишете, что время линейное, хотя до этого правильно указали сложность O(N * M), все таки итерация проходит по двумерному массиву.
mayorovp
Потому что время измеряется относительно объёма входных данных, вот и получается линейным.
sdramare
Потому что сложность апроксимируется сверху линейной функцией.