

С развитием генеративного искусственного интеллекта (ИИ) и расширением сфер его применения создание серверов с искусственным интеллектом стало критически важным для различных секторов — от автопрома до медицины, а также для образовательных и государственных учреждений.
Эта статья рассказывает о наиболее важных компонентах, которые влияют на выбор сервера для искусственного интеллекта, — о центральном и графическом процессорах (CPU и GPU). Выбор подходящих процессоров и графических карт позволит запустить суперкомпьютерную платформу и значительно ускорить вычисления, связанные с искусственным интеллектом на выделенном или виртуальном (VPS) сервере.
Арендуйте выделенные и виртуальные GPU серверы с профессиональными графическими картами NVIDIA RTX A5000 / A4000 и Tesla A100 / H100 80Gb, а также с игровыми картами RTX4090 в надежных дата-центрах класса TIER III в Москве, Нидерландах и Исландии. Принимаем оплату за услуги HOSTKEY в Европе в рублях на счет российской компании. Оплата с помощью банковских карт, в том числе и картой МИР, банковского перевода и электронных денег. Аренда серверов с почасовой оплатой.
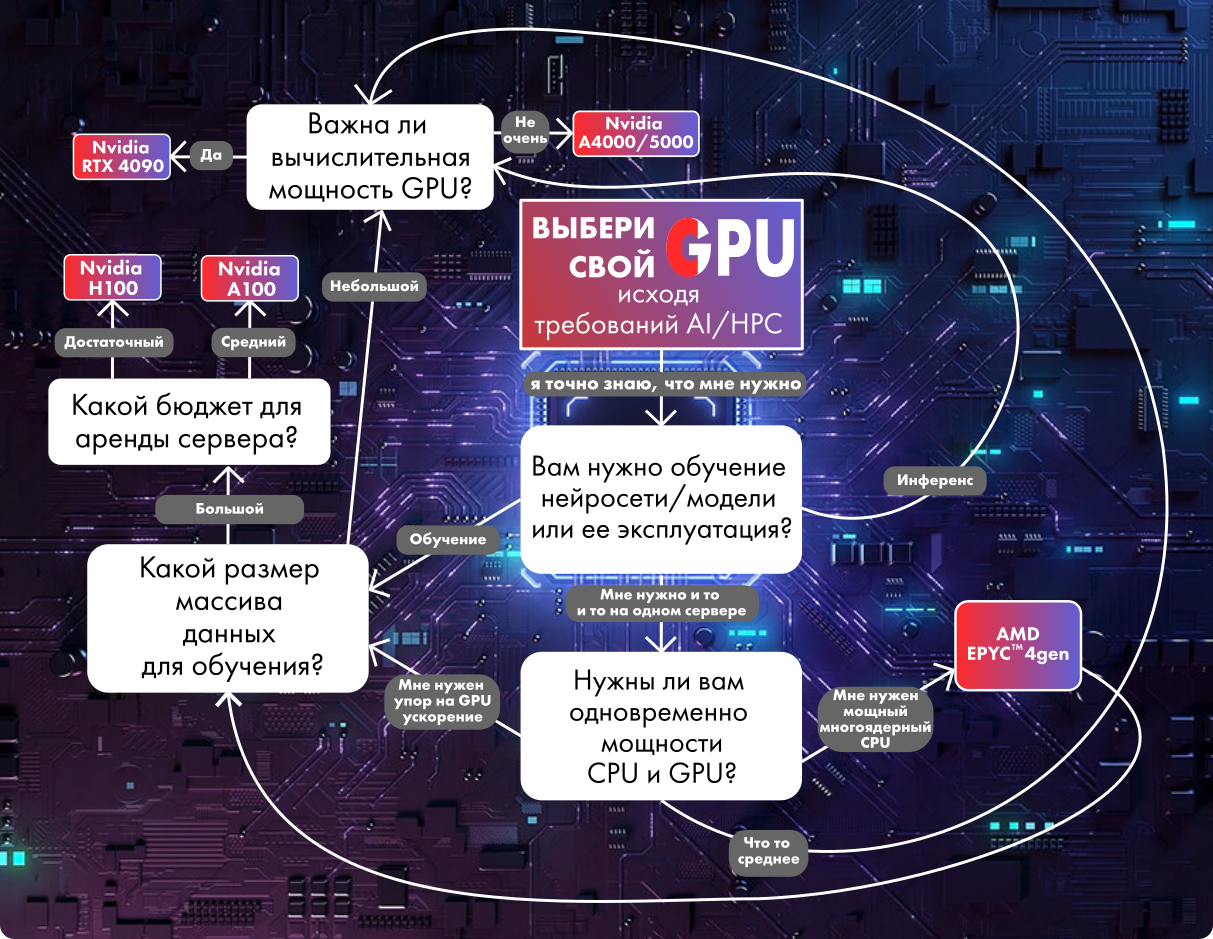
Как выбрать подходящий процессор для вашего ИИ-сервера?
Процессор — это основной «вычислитель», который получает команды от пользователя и выполняет «циклы команд», которые дадут желаемые результаты. Поэтому большая часть того, что делает сервер ИИ таким мощным, — это процессор, который находится в его сердце.
Возможно, вы ожидаете увидеть сравнение процессоров AMD и Intel. Да, эти два лидера в отрасли стоят на переднем крае производства процессоров, а линейка процессоров Intel пятого поколения Intel® Xeon® (кстати, уже анонсировано шестое поколение) и линейка AMD EPYC™ 8004/9004 представляют собой вершину развития CISC-процессоров на базе x86.
Если вы ищете отличную производительность в сочетании со зрелой и проверенной экосистемой, то выбор топовых продуктов от этих производителей будет правильным решением. Если бюджет ограничен, можно рассмотреть более старые версии процессоров Intel® Xeon® и AMD EPYC™.
Даже настольные процессоры от AMD или Nvidia старших моделей будут хорошим выбором для начала работы с ИИ, если ваша рабочая нагрузка не требует большого количества ядер и ограниченных возможностей многопоточности. На практике для языковых моделей выбор между типами CPU будет иметь меньшее значение, чем выбор между графическим ускорителем или объемом установленной в сервере оперативной памяти.
Хотя некоторые модели (например 8x7B от Mixtral) могут на процессоре показать результаты, сравнимые с вычислительными мощностями тензорных ядер видеокарт, но и потребовать вдвое–втрое больший объем ОЗУ, чем в связке CPU + GPU. Например модель, которая будет работать на 16 GB ОЗУ и 24 Гб GPU видеопамяти, при работе только на центральном процессоре может потребовать до 64 Гб оперативной памяти.
Помимо AMD и Intel существуют и другие варианты. Это могут быть решения от на основе архитектуры ARM, например NVIDIA Grace™, который сочетает ядра ARM с запатентованными функциями NVIDIA или Ampere Altra™.
Как выбрать подходящий графический процессор (GPU) для вашего ИИ-сервера?
Графический процессор (GPU) играет важную роль в работе ИИ-сервера. Он служит ускорителем, который помогает центральному процессору (CPU) обрабатывать запросы к нейросетям гораздо быстрее и эффективнее. GPU может разбивать задачу на более мелкие сегменты и обрабатывать их одновременно с помощью параллельных вычислений или специализированных ядер. Те же тензорные ядра NVIDIA обеспечивают на порядок более высокую производительность при вычислениях в формате 8 бит с плавающей точкой (FP8) в Transformer Engine, Tensor Float 32 (TF32) и FP16 и отлично себя показывают в высокопроизводительных вычислениях (HPC).
Особенно это заметно не при инференсе (работе нейросети), а при ее обучении, так как, например, для моделей с FP32 этот процесс может занять несколько недель или даже месяцев.
Чтобы сузить круг поиска, нужно найти ответ на следующие вопросы:
-
Изменится ли характер моей рабочей нагрузки ИИ со временем?
Большинство современных графических процессоров предназначены для выполнения очень специфических задач. Архитектура их чипов может подходить для определенных областей разработки или применения ИИ, а новые аппаратные и программные решения могут сделать предыдущее поколение GPU неконкурентоспособным уже в ближайшие два–три года.
-
Будете ли вы в основном заниматься обучением ИИ или инференсом (эксплуатацией)?
Эти два процесса лежат в основе всех современных итераций ИИ с ограниченным бюджетом по памяти.
Во время обучения модель ИИ поглощает большое количество больших данных с миллиардами или даже триллионами параметров. Она корректирует «веса» своих алгоритмов до тех пор, пока не сможет последовательно генерировать правильный результат.
Во время инференса ИИ опирается на «память» своего обучения, чтобы реагировать на новые входные данные в реальном мире. Оба этих процесса требуют значительных вычислительных ресурсов, поэтому для ускорения работы устанавливаются карты и модули расширения GPU.
Для обучения искусственного интеллекта предназначены графические процессоры, оснащенные специализированными ядрами и механизмами, которые могут оптимизировать этот процесс.
Например, NVIDIA H100 с 8 ядрами GPU способна обеспечить более 32 петафлопс производительности при глубоком обучении в FP8. Каждый H100 содержит тензорные ядра четвертого поколения, использующие новый тип данных FP8, а также Transformer Engine для оптимизации обучения модели. Недавно NVIDIA представила следующее поколение своих GPU B200, которые будут еще мощнее.
Хорошей альтернативой решениям AMD будет AMD Instinct™ MI300X. Его особенностью является огромная память и высокая пропускная способность данных, что важно для инференс-режима генеративных ИИ, например больших языковых моделей (LLM). AMD утверждает, что их GPU на 30% эффективнее, чем решения от NVIDIA, хотя и проигрывают по программному обеспечению.
Если вы готовы немного пожертвовать производительностью, чтобы уложиться в бюджетные ограничения, или если набор данных, с которым вы обучаете ИИ, не такой большой, стоит присмотреться к другим предложениям от AMD и NVIDIA. Для инференс-режимов или когда нет необходимости в бесперебойной работе под полной загрузкой в режиме 24/7, для обучения подойдут «бытовые» решения на основе Nvidia RTX 4090 или даже RTX 3090.
Если вы ищете стабильность в долговременных вычислениях для обучения моделей, можно рассмотреть видеокарты Nvidia RTX A4000 или A5000. Хотя H100 на шине PCIe может быть более мощным решением (на 60–80% в зависимости от задач), RTX A5000 доступнее и подойдет для некоторых задач (например, для работы с моделями 8x7B).
Из более экзотических решений для инференса можно обратить внимание на карты AMD Alveo™ V70, NVIDIA A2/L4 Tensor Core, Qualcomm® Cloud AI 100. В ближайшее время AMD и NVIDIA на рынке обучения ИИ готовятся потеснить Intel с GPU Gaudi 3.
Исходя из вышеперечисленного и с учетом оптимизации программного обеспечения для HPC и AI, можем порекомендовать сервера с процессорами Intel Xeon и AMD Epyc и GPU от NVIDIA. Для инференса ИИ можно использовать GPU от RTX A4000/A5000 до RTX 3090, а для обучения и работы мультимодальных нейросетей стоит заложить бюджет на решения от RTX 4090 до H100.
Арендуйте выделенные и виртуальные GPU серверы с профессиональными графическими картами NVIDIA RTX A5000 / A4000 и Tesla A100 / H100 80Gb, а также с игровыми картами RTX4090 в надежных дата-центрах класса TIER III в Москве, Нидерландах и Исландии. Принимаем оплату за услуги HOSTKEY в Европе в рублях на счет российской компании. Оплата с помощью банковских карт, в том числе и картой МИР, банковского перевода и электронных денег. Аренда серверов с почасовой оплатой.
Комментарии (11)

rPman
17.04.2024 11:22+2Без цен на железо и затрат энергии на fflops, нет никакого смысла обсуждать, какое лучше железо выбирать. Да бывают минимальные требования по объему памяти на ноду, но в этих случаях не до жиру, бери что надо и не заморачивайся.
Разница в производительности cpu и gpu может разниться от 10крат до 100 (например если нужны batch вычисления с одной нейронной)

akdengi
17.04.2024 11:22Будет сравнение дальше с ценами, мощностью потребляемой и т.п. CPU, GPU разных поколении и типов. Просто сравнивать в MLPerf, данные которого есть массово не интересно, поэтому на модельках смотрим.
rPman
17.04.2024 11:22пожалуйста, проведите тесты одних и тех же моделей с помощью transformers python кода и с помощью llama.cpp (в т.ч. с квантизацией 8b и если не лень 4b), у меня есть ощущение что llama.cpp быстрее не только на процессоре

ivankudryavtsev
17.04.2024 11:22+1Сравнение от людей, которые не понимают о чем пишут. На уровне рекламы - есть 5 по 2 или 4 по 3. Выбирайте!
Если вы ищете стабильность в долговременных вычислениях для обучения моделей, можно рассмотреть видеокарты Nvidia RTX A4000 или A5000.
Раскройте нам глупым сию причинно-следственную связь, ну и смысл предложения заодно в части «стабильность в долговременных вычислениях». При том что эти карты вообще не для обучения, как бы.
akdengi
17.04.2024 11:22С чего вы взяли что они не для обучения? По производительности да, A4000 это 3070 Ti примерно, и сама NVidia именно A4000/5000 преподносила и для машинного обучения (да, это PCI-E, типа рейтрейс, CAD и видео, но по тестам норм и в обучение применяли, где хватало 16+ Гб). А вот наличие той же ECC памяти или необходимости работать пару суток под нагрузкой вам скажется на десктопных картах. Это извечный спор (reddit вам в помощь), что нафига карта в 3-5 раз дороже десктопной, но для чего то они существуют и покупаются? Вот пример бенчмарков на Deep Learn: https://www.exxactcorp.com/blog/Benchmarks/nvidia-rtx-a4000-a5000-and-a6000-comparison-deep-learning-benchmarks-for-tensorflow
Даже в инференсе по тестам та же 4090 на длинных текстах начинает ошибки выдавать в больших моделях (понятно, что которые влазят в 24 гига 4090) гораздо раньше и чаще, чем H100 - хотя карты тоже сравнимы.ivankudryavtsev
17.04.2024 11:22Возможно, Вы путаете инференс и обучение? Понятно, что тренировать можно хоть на Jetson, но эти карты не для обучения, а для проф использования и инференса (сервинга моделей).
akdengi
17.04.2024 11:22Официально они для рабочих станций, но и 3090/4090 игровые. ... и A4000/5000/6000 почему-то используют для обучения. Почему бы и нет?
Понятно что сейчас рекомендации A6000 или A100/H100 для больших моделей (официально от Nvidia) и 4080/4090 для S и M моделей (неофициально, но поддержка есть в дровах) и тем более с поддержкой 8-bit Float. Поэтому вопрос будет только в средствах. По мне взять недорогой сервер на A5000, например по цене в два раза меньше, чем на 4090, где по производительности обучения там около 60% разница, а не в два раза для LoRA и небольших датасетов будет оптимальным. И стабильность выше. Люди берут даже 3090 до сих пор для обучения (хотя тут A5000 при текущих ценах надежней будет и одинаково).
akdengi
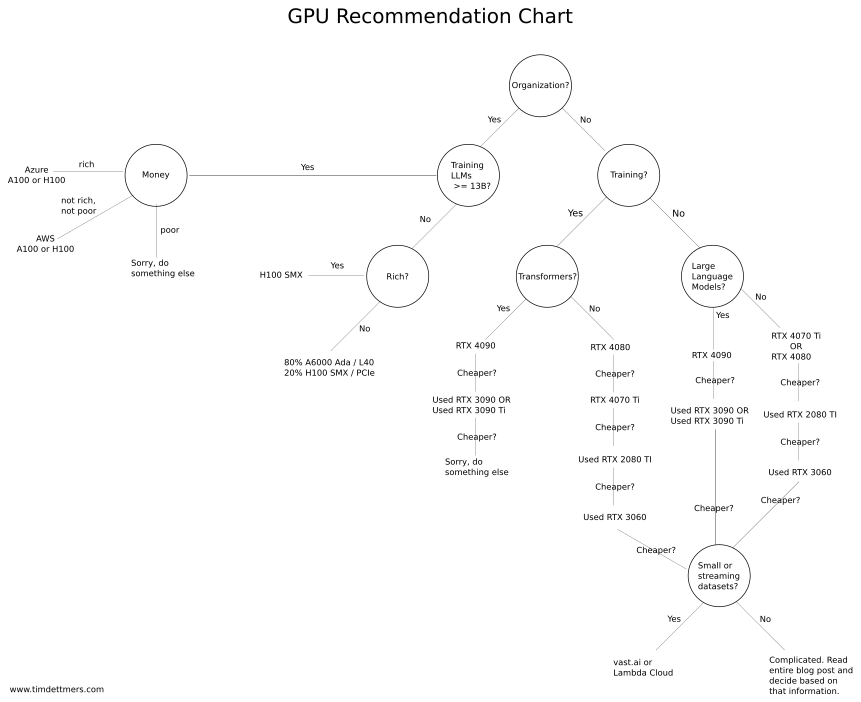
17.04.2024 11:22По схемам же - вот такое есть: https://fullstackdeeplearning.com/cloud-gpus/dettmers_recs.png
Тут также можно не соглашаться :)
{kind=link}
Akuma
Гораздо удобнее было бы сравнение вида:
Берем какой-нибудь docker образ с вот-такой-конкретной-моделью и запускаем его на наших серверах (таком, таком и таком)
Выполняем одни и те же запросы/обучение и смотрим разницу во времени
akdengi
Сейчас прогоняю тесты на A4000/5000 4900 H100 Epyc 4-поколения на koboldcpp (хотя можно любой бенчмарк, но тут тоже удобно и окно ответа задать и gpu offload) на иференс с модельками Mixtral и Lllama с разным квантованием и размером.
Starling-LM-10.7B-beta-Q4_K_M.gguf
mixtral-8x7b-instruct-v0.1.Q3_K_M.gguf
llama-2-70b-chat.Q4_K_M.gguf
7.5, 26 и 41 гиг соответственно весят.
единственное что среднюю модельку попробую загнать по слоям полностью в GPU, возьму чуть меньше. Все с максимальный использованием gpu offload.
Еще добавлю свою личную RTX 4060 в сравнимых условиях, так как в теории она по производительности равна A4000 но проигрывает в памяти (8 против 14 гигов)
H100 у нас на EPYC 7451 24 ядерных, 4090 на i9-14900 или на Райзенах, но CPU не буду трогать, но попробую без GPU и на десктопных 8x7b модель.
Все в единую табличку сведем, еще добавлю производительности в том же Automatic1111 c SD XL моделью.
По обучению смотрю, как лучше тест сделать, чтобы сравнение было корректным, если подскажете, буду рад, как и по тестам, что еще хотелось бы сравнить.
rPman
совет, если будете на cpu гонять llama.cpp, протестируйте с разным количеством процессорных ядер (ключ -t), можно получить не очевидные результаты