
Привет, Хабр! Представляю вам перевод статьи "How Uber Serves Over 40 Million Reads Per Second from Online Storage Using an Integrated Cache" автора Preetham Narayanareddy. Из неё вы узнаете, как в Uber проектировалась система кэширования на основе Redis, с какими сложностями и тонкостями пришлось столкнуться разработчикам, и как в итоге им удалось создать действительно высокопроизводительное решение.

Введение
Docstore – это собственная распределенная база данных Uber, построенная на основе MySQL®. Хранящий десятки ПБ данных и обслуживающий десятки миллионов запросов в секунду, он является одним из крупнейших движков баз данных в Uber, используемым микросервисами всех отраслей бизнеса. С момента своего создания в 2020 году число пользователей и вариантов использования Docstore постоянно растет, увеличивается объем запросов и объем данных.
Растущее количество требований со стороны бизнес отраслей и бизнес решений приводит к появлению сложных микросервисов и созданию графов зависимостей. В результате приложения требуют от базы данных низких задержек, высокой производительности и масштабируемости, одновременно создавая более высокие рабочие нагрузки.
Проблематика
Большинство микросервисов Uber используют для хранения базы данных, основанные на дисковых хранилищах. Однако любая база данных сталкивается с проблемами при обслуживании приложений, требующих доступа к чтению с малой задержкой и высокой масштабируемости.
Дело дошло до точки кипения, когда для одного из вариантов использования потребовалась гораздо более высокая пропускная способность чтения, чем у любого из наших существующих клиентов. Docstore мог бы удовлетворить их потребности, поскольку в его основе лежат NVMe SSD накопители, обеспечивающие низкую задержку и высокую пропускную способность. Однако использование Docstore в вышеописанном сценарии было бы слишком дорогостоящим и потребовало бы решения многих проблем масштабирования и эксплуатации.
Прежде чем погрузиться в проблемы, давайте разберемся в высокоуровневой архитектуре Docstore.
Архитектура Docstore
Docstore в целом делится на три уровня: уровень механизма запросов без сохранения состояния (stateless), уровень механизма хранения с сохранением состояния (stateful) и плоскость управления. В рамках этого блога мы поговорим об уровнях механизма запросов и хранения данных.
Уровень механизма запросов без сохранения состояния отвечает за планирование запросов, маршрутизацию, шардирование, управление схемами, мониторинг состояния узлов, парсинг запросов, валидацию и AuthN/AuthZ.
Уровень механизма хранения отвечает за консенсус через Raft, репликацию, транзакции, управление параллельным доступом и распределение нагрузки. Партиция обычно состоит из нод MySQL, подключенных к NVMe SSD-накопителям, которые способны выдерживать большие нагрузки при чтении и записи. Кроме того, данные распределены по нескольким партициям, содержащим одну ведущую и две дополнительные ноды, использующим Raft для достижения консенсуса.

Теперь давайте рассмотрим некоторые проблемы, возникающие, когда сервисы требуют чтения с низкой задержкой при большом уровне масштабирования:
Скорость получения данных с диска имеет пороговое значение: Существует предел, до которого можно оптимизировать модели данных и запросы приложения, чтобы уменьшить задержку и повысить производительность базы данных. Выжать больше производительности не представляется возможным.
Вертикальное масштабирование: Выделение дополнительных ресурсов или переход на более мощные сервера с более высокой производительностью имеет свои ограничения, когда узким местом становится сам движок базы данных.
Горизонтальное масштабирование: Разделение шардов на большее количество партиций в определенной степени помогает решить проблему, однако с операционной точки зрения это более сложный и длительный процесс. Мы должны обеспечить надежность и устойчивость данных без простоев. Также это решение не полностью помогает решить проблемы с "горячими" партициями и шардами.
Дисбаланс запросов: Зачастую количество поступающих запросов на чтение на порядки превышает количество запросов на запись. В таких случаях нода, обслуживающая MySQL, будет с трудом справляться с большой нагрузкой и еще больше повлияет на задержки.
Стоимость: Вертикальное и горизонтальное масштабирование для уменьшения задержек дорого обходится в долгосрочной перспективе. Затраты умножаются в 6 раз, чтобы обслуживать каждую из трех stateful нод в обоих регионах. Кроме того, масштабирование не решает проблему полностью.
Чтобы преодолеть эту проблему, микросервисы используют кэширование. В Uber мы используем Redis™ в качестве решения для распределенного кэширования. Типичным паттерном проектирования микросервисов является запись в базу данных и кэш, а также чтение из кэша для уменьшения задержек. Тем не менее, этот подход имеет следующие проблемы:
Каждая команда должна организовать и поддерживать свой собственный кэш Redis для соответствующих сервисов.
Логика инвалидации кэша реализуется децентрализованно в каждом микросервисе.
В случае отказа региона сервисы либо должны поддерживать репликацию кэша, чтобы оставаться "горячими", либо страдать от повышенных задержек, пока кэш "разогревается" в других регионах.
Отдельным командам приходится тратить много сил на реализацию собственных решений по кэшированию базы данных. Возникла необходимость найти лучшее, более эффективное решение, которое не только обслуживало бы запросы с низкой задержкой, но и было бы простым в использовании и повышало производительность разработчиков.
CacheFront
Мы решили создать интегрированное решение для кэширования, CacheFront для Docstore, преследуя следующие цели:
Минимизация необходимости вертикального и/или горизонтального масштабирования для поддержки запросов на чтение с низкой задержкой.
Сокращение выделения ресурсов на уровень движка базы данных; кэширование может быть построено на относительно дешевых хостах, что повышает общую экономическую эффективность.
Улучшение задержек P50 и P99 и стабилизация скачков задержек чтения во время микросбоев.
Замена большинства кастомных решений для кэширования, которые были (или будут) созданы отдельными командами для удовлетворения своих потребностей, особенно в тех случаях, когда кэширование не является основным видом деятельности или компетенцией команды.
Прозрачность, использование существующего клиента Docstore без дополнительных шаблонных решений, что позволяет использовать преимущества кэширования.
Повышение производительности труда разработчиков и возможность выпускать новые функции или заменять базовую технологию кэширования прозрачно для клиентов.
Отделение решения по кэшированию от схемы шардирования, лежащей в основе Docstore, чтобы избежать проблем, возникающих из-за "горячих" шардов или партиций.
Предоставление возможности горизонтального масштабирования слоя кэширования независимо от механизма хранения данных.
Передача ответственности за поддержку и обслуживание Redis от команды разработчиков функционала к команде Docstore.
Дизайн CacheFront
Шаблоны запросов Docstore
Docstore поддерживает различные способы запросов по первичному ключу или ключу партиции, а также опциональную фильтрацию данных. На высоком уровне это можно разделить на следующее:
Тип ключа / Фильтр |
Нет фильтра |
Фильтрация по условию WHERE |
Строки |
ReadRows |
– |
Партиции |
ReadPartition |
QueryRows |
Мы хотели построить наше решение постепенно, начав с наиболее распространенных шаблонов запросов. Оказалось, что более 50 % запросов, поступающих в Docstore, – это запросы ReadRows, а поскольку это еще и самый простой вариант использования – без фильтров и точечных чтений, – это было естественным местом для начала интеграции.
Высокоуровневая архитектура
Поскольку уровень механизма запросов Docstore отвечает за обслуживание чтения и записи для клиентов, он хорошо подходит для интеграции слоя кэширования. Он также отделяет кэш от дискового хранилища, позволяя нам масштабировать их независимо друг от друга. Уровень механизма запросов реализует интерфейс к Redis для хранения кэшированных данных, а также механизм для инвалидации кэшированных записей. Архитектура высокого уровня выглядит следующим образом:

Docstore – это строго согласованная база данных. Хотя интегрированное кэширование обеспечивает более быстрые ответы на запросы, некоторые семантические характеристики, связанные с согласованностью, могут быть неприемлемы для некоторых микросервисов при использовании кэша. Например, инвалидация кэша может не сработать или отстать от записи в базу данных. По этой причине мы сделали интегрированное кэширование опциональной функцией. Сервисы могут настраивать использование кэша для каждой базы данных, для каждой таблицы и даже для каждого запроса.
Если определенные потоки требуют высокой согласованности (например, добавление товаров в корзину потребителя), то кэш можно обойти, в то время как другие потоки с низкой пропускной способностью (например, получение меню ресторана) выиграют от использования кэша.
Кэшированные чтения
CacheFront использует стратегию кэширования на стороне для реализации кэшированных чтений:
Уровень механизма запросов получает запрос на чтение еще одной строки.
Если кэширование включено, пробуем получить строки из Redis; передаем ответ пользователям.
Извлекаем оставшиеся строки (если они есть) из хранилища.
Асинхронно помещаем эти строки в Redis.
Передаем оставшиеся строки пользователям.

Инвалидация кэша
«В информатике есть только два сложных вопроса: инвалидация кэша и присвоение имен».
— Фил Карлтон
Хотя стратегия кэширования, описанная в предыдущем разделе, может показаться простой, для того чтобы кэш работал, необходимо было учесть множество деталей, особенно инвалидацию кэша. Без явной инвалидации кэша срок действия записей кэша истекает с заданным TTL (по умолчанию 5 минут). Хотя в некоторых случаях это может быть нормально, большинство пользователей ожидают, что изменения будут отражаться быстрее, чем TTL. Значение TTL по умолчанию может быть снижено, однако это уменьшит процент попадания в кэш без существенного улучшения гарантий согласованности.
Обновление по условию
Docstore поддерживает обновления по условию, когда одна или несколько строк могут быть обновлены на основе условия фильтра. Например, обновить расписание праздников для всех сетей ресторанов в заданном регионе. Поскольку результаты данного фильтра могут меняться, наш слой кэширования не может определить, какие строки будут затронуты условным обновлением, пока фактические строки не будут обновлены в движке базы данных. Из-за этого мы не можем проводить инвалидацию и добавлять кэшированные строки для обновления по условию в слое механизма запросов без сохранения состояния.
Использование захвата изменения данных для инвалидации кэша
Чтобы решить эту проблему, мы воспользовались захватом изменения данных Docstore и сервисом потоковой передачи данных, Flux. Flux отслеживает события MySQL по binlog для каждого из кластеров в нашем слое механизма хранения и публикует их для списка потребителей. Flux обеспечивает работу Docstore CDC (Change Data Capture - захват изменения данных), репликацию, материализованные представления, загрузку в озеро данных и проверку согласованности данных между нодами в кластере.
Был написан новый консьюмер, который подписывается на события, связанные с данными, и либо делает инвалидацию, либо вставляет новые строки в Redis, либо обновляет существующие строки. Теперь при использовании этой стратегии инвалидации условное обновление будет приводить к событиям изменения базы данных для затронутых строк, которые будут использоваться для инвалидации или заполнения строк в кэше. В результате мы смогли обеспечить согласованность кэша в течение нескольких секунд после изменения базы данных, а не минут. Кроме того, используя журналы binlog, мы не рискуем допустить загрязнения кэша незафиксированными транзакциями.
Окончательный маршрут чтения и записи с учетом инвалидации кэша выглядит следующим образом:

Дедупликация записей в кэше, сделанных движком запросов и Flux
Однако у описанной выше стратегии инвалидации кэша есть недостаток. Поскольку запись в кэш происходит одновременно как при чтении данных, так и при записи, существует вероятность того, что мы случайно запишем в кэш устаревшую строку, перезаписав самое новое значение, которое было получено из базы данных. Чтобы решить эту проблему, мы дедуплицируем записи на основе временной метки набора строк в MySQL, которая фактически служит его версией. Временная метка извлекается из закодированного значения строки в Redis (см. последующий раздел о кодеке).
Redis поддерживает атомарное выполнение пользовательских Lua-скриптов с помощью команды EVAL. Этот скрипт принимает те же параметры, что и MSET, однако он также выполняет логику дедупликации, проверяя значения временных меток всех строк, уже записанных в кэш, и убеждаясь, что значение, которое будет записано, является более новым. При использовании EVAL все это может быть выполнено в одном запросе вместо того, чтобы требовать многократных обходов между уровнем механизма запросов и кэшем.
Более строгие гарантии согласованности для точечных записей
Хотя Flux позволяет нам делать инвалидацию кэша гораздо быстрее, чем если бы мы полагались исключительно на TTL Redis для истечения срока хранения записей в кэше, он все еще предоставляет нам семантику согласованности в конечном счете. Однако некоторые сценарии использования требуют строгой согласованности, например, чтение собственных записей, поэтому для таких сценариев мы добавили в механизм запросов специальный API, который позволяет пользователям явно инвалидировать кэшированные строки после завершения соответствующих записей. Это позволило нам гарантировать более строгую согласованность для точечных записей, но не для условных обновлений, которые по-прежнему подлежат инвалидации с помощью Flux.
Схемы таблиц
Прежде чем перейти к более подробному описанию реализации, давайте определим несколько ключевых терминов. Таблицы Docstore имеют первичный ключ и ключ партиции.
Первичный ключ (часто называемый ключом строки) уникально идентифицирует строку в таблице Docstore и обеспечивает ограничение уникальности. Каждая таблица должна иметь первичный ключ, который может состоять из одного или нескольких столбцов.
Ключ партиции – это префикс всего первичного ключа, и он определяет, в каком шарде будет находиться строка. Они не являются полностью отдельными – скорее, ключи партиций просто являются частью первичных (или совпадают с ними).

В приведенном выше примере person_id является одновременно первичным ключом и ключом партиции для таблицы person. В то время как для таблицы orders cust_id является ключом партиции, а cust_id и order_id вместе образуют первичный ключ.
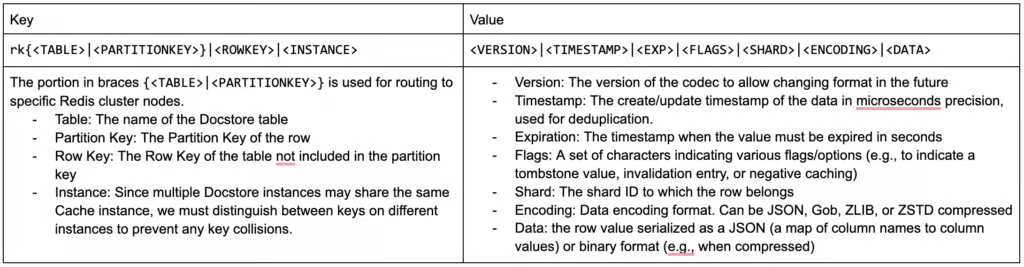
Redis кодек
Поскольку в основном мы будем кэшировать чтение строк, мы можем однозначно идентифицировать значение строки с заданным ключом строки. Поскольку ключи и значения Redis хранятся в виде строк, нам нужен специальный кодек для кодирования данных MySQL в формат, который принимает Redis.
Мы остановились на следующем кодеке, поскольку он позволяет совместно использовать ресурсы кэша разными базами данных, сохраняя при этом изолированность данных.

Функционал
После завершения высокоуровневого проектирования наше решение стало функциональным. Теперь пришло время подумать о масштабируемости и устойчивости:
Как проверить согласованность между базой данных и кэшем в режиме реального времени.
Как переносить сбои в работе зон/регионов.
Как переносить сбои в работе Redis.
Проверка кэша
Все эти разговоры об улучшении согласованности ничего не значат, если это нельзя измерить, поэтому мы добавили специальный режим, при котором особым образом обрабатываются запросы чтения из кэша. При обратном чтении мы сравниваем данные из кэша и базы данных и убеждаемся, что они одинаковы. Любые несоответствия - либо устаревшие строки, присутствующие в кэше, либо строки, присутствующие в кэше, но не в базе данных, - регистрируются и выдаются в виде метрик. С добавлением инвалидации кэша с помощью Flux, согласованность кэша составляет 99,99%.

Разогрев кэша
Инстанс Docstore содержит два разных географических региона для обеспечения высокой доступности и отказоустойчивости. Развертывание происходит по принципу active-active, то есть запросы могут отправляться и обслуживаться в любом регионе, а все записи реплицируются между регионами. В случае отказа региона другой регион должен быть в состоянии обслужить все запросы.
Эта модель привносит сложности в работу CacheFront, поскольку кэши всегда должны быть "разогретыми" во всех регионах. В противном случае при отказе региона количество запросов к базе данных увеличится из-за отсутствия в кэше записей от трафика, который изначально обслуживался в отказавшем регионе. Это не позволит нам сократить масштабирование хранилища и освободить ресурсы, поскольку нагрузка на базу данных будет такой же высокой, какой она была бы без кэширования.
Проблему холодного кэша можно решить с помощью межрегиональной репликации Redis, но это представляет определенную проблему. Docstore имеет собственный механизм межрегиональной репликации. Если мы будем реплицировать содержимое кэша с помощью межрегиональной репликации Redis, у нас будет два независимых механизма репликации, что может привести к несогласованности между кэшем и механизмом хранения. Чтобы избежать этой проблемы несогласованности кэша для CacheFront, мы усовершенствовали компоненты кросс-региональной репликации Redis, добавив новый режим разогрева кэша.
Чтобы кэш всегда был "теплым", мы подключаемся к потоку записи Redis и реплицируем ключи в удаленный регион. В удаленном регионе вместо прямого обновления удаленного кэша запросы на чтение направляются на уровень механизма запросов, который в случае отсутствия данных в кэше считывает их из базы данных и записывает в кэш, как описано в разделе "Кэшированные чтения". Выполняя запросы на чтение только при пропуске кэша, мы также избегаем излишней перегрузки механизма хранения данных. Ответный поток прочитанных строк с уровня механизма запросов просто отбрасывается, поскольку результат нас не интересует.
Благодаря репликации ключей, а не значений, мы всегда гарантируем, что данные в кэше согласуются с базой данных в соответствующем регионе, и сохраняем один и тот же рабочий набор кэшированных строк в Redis в обоих регионах, в то же время ограничивая потребление трафика между регионами.

Отрицательное кэширование
В сценариях, где многие чтения выполняются для несуществующих строк, было бы неплохо кэшировать отрицательный результат вместо того, чтобы фиксировать пропуск кэша и каждый раз запрашивать базу данных. Для этого мы встроили в CacheFront отрицательное кэширование. Подобно обычной стратегии заполнения кэша, когда все строки, возвращенные из базы данных, записываются в кэш, мы также отслеживаем все строки, которые были запрошены, но не прочитаны из базы данных. Эти несуществующие строки записываются в кэш со специальным флагом, и при последующих чтениях, если флаг найден, мы игнорируем строку при запросе к базе данных, а также не возвращаем пользователю никаких данных для этой строки.
Шардирование
Хотя Redis не слишком подвержен влиянию проблем с горячими партициями, некоторые крупные клиенты Docstore генерируют очень большое количество запросов на чтение и запись, которые было бы сложно кэшировать в одном кластере Redis, обычно ограниченном максимальным числом нод, которые он может иметь. Чтобы смягчить эту проблему, мы позволяем одному инстансу Docstore подключаться к нескольким кластерам Redis. Это также позволяет избежать полного краха базы данных, когда к ней может быть направлено огромное количество запросов, в случае если несколько нод в одном кластере Redis не работают и кэш недоступен для определенных диапазонов ключей.
Однако даже если данные распределены по нескольким кластерам Redis, выход из строя одного кластера Redis может привести к возникновению проблемы "горячего шарда" для базы данных. Чтобы смягчить эту проблему, мы решили шардировать кластеры Redis по ключу партиции, что отличается от схемы шардирования в базе данных Docstore. Теперь мы можем избежать перегрузки одного шарда базы данных, когда один кластер Redis выходит из строя. Все запросы с отказавшего шарда Redis будут распределены между всеми шардами базы данных, как показано ниже:

Circuit Breaker
Если нода Redis выходит из строя, мы хотели бы иметь возможность отключать запросы к этой ноде, чтобы избежать лишней задержки при get/set запросе в Redis, в отношении которого у нас есть большая уверенность, что он не сработает. Для этого мы используем Circuit Breaker и метод скользящего окна. Мы подсчитываем количество ошибок на каждой ноде за временной интервал и вычисляем количество ошибок за ширину скользящего окна.

Circuit Breaker настроен на отключение части запросов к ноде пропорционально количеству ошибок. При достижении максимально допустимого количества ошибок срабатывает Circuit Breaker, и больше никаких запросов к данной ноде нельзя выполнить до тех пор, пока не будет пройдено скользящее окно.
Адаптивные таймауты
Мы поняли, что иногда трудно установить правильные таймауты для операций Redis. Слишком короткий таймаут приводит к тому, что запросы в Redis завершаются с ошибкой слишком рано, расходуя ресурсы Redis и создавая дополнительную нагрузку на движок базы данных. Слишком длительный таймаут влияет на задержки P99.9 и P99.99, и в худшем случае запрос может исчерпать весь таймаут, указанный в запросе. Хотя можно смягчить эти проблемы, настроив условно низкий таймаут по умолчанию, мы рискуем установить слишком низкий таймаут, при котором многие запросы будут обходить кэш и обращаться к базе данных, или установить слишком высокий таймаут, что приведет нас к исходной проблеме.
Нам нужно было автоматически и динамически настраивать таймауты запросов таким образом, чтобы P99 запросов к Redis выполнялись в отведенное время, и в то же время полностью сократить большое количество задержек. Настройка адаптивных таймаутов означает возможность динамически изменять значение таймаута для get/set запросов в Redis. Разрешая адаптивные таймауты, мы можем установить таймаут эквивалентный P99.99 задержке запросов к кэшу, тем самым позволяя 99.99% запросов отправляться в кэш с быстрым ответом. Оставшиеся 0,01 % запросов, которые заняли бы слишком много времени, могут быть прерваны быстрее и обслужены базой данных.
С помощью адаптивных таймаутов нам больше не нужно настраивать таймауты вручную, чтобы они соответствовали желаемой задержке P99, и вместо этого мы можем только установить максимально допустимый лимит таймаута, за который фреймворк не может выйти (поскольку максимальный таймаут все равно задается клиентским запросом).

Полученные результаты
Так удалось ли нам добиться успеха? Изначально мы ставили перед собой задачу создать интегрированный кэш, прозрачный для наших пользователей. Мы хотели, чтобы наше решение помогло уменьшить задержки, было легко масштабируемым, способствовало снижению нагрузки и затрат на наш механизм хранения и при этом имело хорошие гарантии согласованности.

Задержки запросов с интегрированным кэшем значительно лучше. Задержка P75 снизилась на 75%, а задержка P99.9 – более чем на 67%, при этом, как показано выше, уменьшились скачки задержки.
Инвалидация кэша с помощью Flux и режим проверки кэша помогают нам обеспечить хорошую согласованность.
Поскольку он работает за нашими существующими API, он прозрачен для пользователей и может управляться изнутри, обеспечивая при этом гибкость для пользователей за счет опций, передаваемых в заголовках запросов.
Шардирование и "разогрев" кэша позволяют ему быть масштабируемым и отказоустойчивым. Один из наших самых крупных начальных примеров использования показал производительность более 6M RPS при 99% попадании в кэш, с успешной отработкой failover сценария, когда весь трафик был перенаправлен в удаленный регион.
Изначально для обслуживания 6 млн RPS системой хранения напрямую потребовалось бы около 60K CPU ядер. С помощью CacheFront мы обслуживаем около 99,9% попаданий в кэш, используя всего 3K ядер Redis, что позволяет нам сократить потребление ресурсов.
Сегодня CacheFront поддерживает более 40 миллионов запросов в секунду для всех производственных инстансов Docstore, и это число постоянно растет.

С помощью CacheFront мы решили одну из основных проблем, связанных с масштабированием нагрузки чтения на Docstore. Это не только позволило охватить масштабные сценарии использования, требующие высокой пропускной способности и низких задержек при чтении, но и помогло нам снизить нагрузку на механизм хранения и сэкономить ресурсы, улучшив общую стоимость организации хранения и позволив разработчикам сосредоточиться на создании продуктов, а не на управлении инфраструктурой.
Комментарии (6)

mikegordan
02.05.2024 05:44+1Много всего напихано... Им уже давно нужно переходить на стриминговые базы, но они всё делают свои самокаты, нагромождая и усложняя архитектуру. Очевидно что в компании на основных позициях сидят деды со старым виженом и на старых технологиях.
У нас бы в бинанс таких уволили.

Anarchist
02.05.2024 05:44Вы прекратите спихивать всё на дедов. Деды бы распилили базу географически как минимум.

murkin-kot
02.05.2024 05:44Зачем им 40 миллионов запросов в секунду?
Заказ такси не могут одновременно делать миллионы человек, потому что населения на земле для таких масштабов не хватит.
Значит система явно перегружена внутренними коммуникациями. Но что это за коммуникации? Ответ прост - микросервисы. Вместо пусть миллиона в секунду (и то много) имеем на пару порядков больше.

bondeg
02.05.2024 05:44У них там ещё uber eats как минимум есть типа Яндекс еды и наверняка что-то ещё.
Хотя, конечно, оверхед от микросервисов тоже имеет место быть.

krote
02.05.2024 05:44Для транснациональных компаний как Uber очевидно напрашивается решение с разделением данных на регионы, так как нет никакой надобности хранить локальную OLTP инфу в единой базе, а сливать данные воедино уже в OLAP базу. Ведь очевидно же что клиенты из одного региона запрашивают 99.99% инфы из этого же региона?
Ну типа промежуточный диспетчер обрабатывает запрос и направляет его в локальный сервис либо в сервис другого региона, при надобности, что сразу распределит нагрузку.
Потому скорее было бы интересно не только реализация описанная в статье, но и причины такой централизации децентрализованных данных. Т.е. зачем было создавать сложности?
serginfo2009
Мы в одном из продуктов применяем похожую схему. Не в таких масштабах, правда.