
Уже очень давно мне хотелось попробовать создать проект, который бы представлял собой настоящие JavaScript Application, а именно толстый клиент, без backend и своего хостинга, на основе open source и какого-нибудь BaaS/DaaS. К тому же я окончательно устал от jsperf.com, от этих бессмысленных двух шагов, от отсутствия хоть какого-то редактора кода и нормального поиска и от постоянной потери своих тестов, а история с капчой, которая не всегда срабатывает, окончательно добила меня. Я наконец выкроил время, чтобы осуществить давно задуманное и убить двух зайцев, реализовав альтернативу jsperf.

Итак, перво-наперво требования к проекту:
А теперь самое интересное: где хранить исходники тестов? А результаты?
Если среди вас есть постоянные пользователи jsperf, то они помнят недавнюю историю, когда он был полностью недоступен именно по причине хранения кода и результатов прогона тестов. Так что задача сводилась к одному: как сделать так, чтобы ничего не хранить у себя, а переложить это на какой-нибудь сервис, а лучше на юзера? Ответ напрашивался сам собой: идеальное место для хранения исходников — GitHub, точнее Gist. Он есть практически у каждого разработчика, и это решает сразу несколько поставленных задач:
У GitHub есть чудесный REST API, это, наверное, одна из эталонных реализаций, также есть API и для работы с Gist. Вопрос оставался за малым: как сохранить Gist от имени пользователя?
Для авторизации GitHub предлагает использовать OAuth, это несложно, но требует минимального backend’а. Тут можно было пойти несколькими путями:
Я выбрал OAuth.io, как очень простой и быстрый способ для начала работы, к тому же при необходимости от сервиса можно безболезненно избавиться. Плюс у него есть неплохая аналитика, простенькая либа для работы API и куча провайдеров под любой сервис, в том числе и GitHub. А самый кайф, что для начала работы вам даже не нужно проходить нудную регистрацию, — просто нажимаете «Sign in with GitHub» и добавляете ключи от вашего приложения.
Следующий шаг — это написание обёртки для работы с GitHub API. И тут есть небольшой нюанс: я очень хотел лишний раз не дёргать OAuth.io, чтобы не выходить за лимиты free-плана. Как оказалось, GitHub позволяет обращаться к API неавторизованным, но такие вызовы жёстко лимитируются, поэтому метод получения Gist имеет достаточно нетривиальную логику:
Переводим это в код, посыпаем Promise + fetch и получаем вот такой метод:
Если с исходниками я определился быстро, то вот с результатами не всё так просто. Не буду томить, просто перечислю решения, которые я знал на тот момент:
Так как проект был экспериментальным, выбор пал на Firebase: кроме JavaScript API, он предлагал в два раза больше места, чем на том же MongoLab, — целый гигабайт.
На самом деле был ещё один вариант: localStorage/IndexedDB + WebRTC. Идея заключалась в следующем: результаты прогонов храним в localStorage и если в онлайне есть ещё кто-нибудь, то синхронизируем данные :).
Итак, Firebase. Использовать его до безобразия просто, документация не врёт: https://www.firebase.com/docs/web/quickstart.html.
Это весь код, который мне пришлось написать для работы с Firebase, но самое классное, что событие обновления «узла» срабатывает всякий раз, когда кто-либо запускает бенчмарки, и вы прямо онлайн, без каких-либо F5 или cmd + r, получаете обновление графиков.
Эх, вот чего не умею, того не умею, поэтому всё выглядит так:

Интерфейс максимально информативен, отображены основные важные параметры, справа от кода теста выводится результат прогона, после завершения теста строчки подсвечиваются соответствующим цветом, а под кодом строятся графики. Setup и Teardown вынесены в «уши» внизу экрана — решение спорное, но подходит для большинства задач. В итоге вся возможная информация умещается на одном экране.
Как можно заметить, в отличие от jsperf, у меня есть подсветка кода, для этого используется Ace.
Ace — это чудесный инструмент для интеграции редактора кода в ваше приложение. Чтобы его использовать:
Для прогона тестов используются Platform.js и Benchmark.js, графики рисую при помощи Google Visualization, так что результаты прогона и графики выглядят точно так же, как на jsperf.
Одна из фич — это шаринг теста, сейчас поддерживаются только Twitter и Facebook.
Twitter
Тут особо нечего рассказывать: открываем popup с предустановленным текстом, а дальше пользователь сам решает, постить или нет.
Facebook
Вот тут интереснее, хотелось не просто ссылку постить, а сразу график в ленту. У Google Visualization есть метод получения dataURI, а у FB — Graph API, осталось их подружить:
Для преобразования dataURI используем https://github.com/blueimp/JavaScript-Canvas-to-Blob/.
И публикуем:
Планы на будущее
Полный список используемых библиотек и полифилов
Как видите, в настоящий момент можно собирать качественный прототип с помощью готовых решений и бесплатных платформ, затрачивая на это только своё время. А ведь это не просто экономия денег — это и экономия времени на выбор хостинга, установку, настройку необходимого софта и дальнейшее администрирование. Все эти проблемы исчезают, когда вы используете любой BaaS или DaaS — они дают вам готовое решение без головной боли. Плюс, если проект вырастет и окрепнет, вы всегда можете перейти на подходящий платный тариф или поднять точно такой же стек на своём хостинге.
Страница проекта: http://jsbench.github.io/
Исходный код и задачи: https://github.com/jsbench/jsbench.github.io/
Итак, перво-наперво требования к проекту:
- компактный и понятный интерфейс, без шагов и капчи;
- нормальный редактор с подсветкой кода, а не просто textarea;
- сохранение бенчмарка, чтобы потом его можно было без труда найти, а также удаление (всякое бывает);
- возможность скачать бенчмарк и запустить его локально или через Node.js;
- возможность добавить в «Избранное»;
- другие ништяки.
А теперь самое интересное: где хранить исходники тестов? А результаты?
Где хранить исходники?
Если среди вас есть постоянные пользователи jsperf, то они помнят недавнюю историю, когда он был полностью недоступен именно по причине хранения кода и результатов прогона тестов. Так что задача сводилась к одному: как сделать так, чтобы ничего не хранить у себя, а переложить это на какой-нибудь сервис, а лучше на юзера? Ответ напрашивался сам собой: идеальное место для хранения исходников — GitHub, точнее Gist. Он есть практически у каждого разработчика, и это решает сразу несколько поставленных задач:
- хранение;
- нормальный поиск (по уникальному тегу);
- избранное;
- бонусом: история изменения тестов (diff) и fork’и.
У GitHub есть чудесный REST API, это, наверное, одна из эталонных реализаций, также есть API и для работы с Gist. Вопрос оставался за малым: как сохранить Gist от имени пользователя?
OAuth
Для авторизации GitHub предлагает использовать OAuth, это несложно, но требует минимального backend’а. Тут можно было пойти несколькими путями:
- Найти какой-нибудь бесплатный хостинг или BaaS и развернуть там одно из open source решений для работы с GitHub.
- Воспользоваться сервисом OAuth.io, у которого есть приемлемый free-план.
Я выбрал OAuth.io, как очень простой и быстрый способ для начала работы, к тому же при необходимости от сервиса можно безболезненно избавиться. Плюс у него есть неплохая аналитика, простенькая либа для работы API и куча провайдеров под любой сервис, в том числе и GitHub. А самый кайф, что для начала работы вам даже не нужно проходить нудную регистрацию, — просто нажимаете «Sign in with GitHub» и добавляете ключи от вашего приложения.
GitHub API
Следующий шаг — это написание обёртки для работы с GitHub API. И тут есть небольшой нюанс: я очень хотел лишний раз не дёргать OAuth.io, чтобы не выходить за лимиты free-плана. Как оказалось, GitHub позволяет обращаться к API неавторизованным, но такие вызовы жёстко лимитируются, поэтому метод получения Gist имеет достаточно нетривиальную логику:
- Проверяем Runtime cache, если есть данные, отдаём.
- Если в
localStorageесть данные о юзере, считаем, что он уже авторизован, вызываем получение токена через OAuth.io и делаем запрос к API. Если авторизация не прошла, отправляем запрос неавторизованным и надеемся, что лимиты ещё не исчерпаны. - Если в
localStorageничего нет, делаем запрос как неавторизованный, в случае ошибки пытаемся авторизоваться через OAuth.io и повторить запрос уже как авторизованный.
Переводим это в код, посыпаем Promise + fetch и получаем вот такой метод:
function findOne(id) {
let promise;
const url = 'gists/' + id;
const _fetch = () => {
return fetch(API_ENDPOINT + url).then(res => {
if (res.status !== API_STATUS_OK) {
throw 'Error: ' + res.status;
}
return res.json();
});
};
if (_gists[id]) {
// Runtime cache
promise = Promise.resolve(_gists[id]);
} else if (github.currentUser) {
// Есть авторизация, запрашиваем Gist через OAuth.io
promise = _call('get', url)['catch'](() => {
// Ошибка, пробуем запросить напрямую у GitHub API
github.setUser(null);
return _fetch();
});
} else {
// Нет авторизации, обращаемся напрямую к GitHub API
promise = _fetch()['catch'](() => {
// Ошибка, пробуем авторизоваться и запросить повторно
return _call('get', url);
});
}
return promise.then(gist => {
// Добавляем в Runtime cache
_gists[gist.id] = gist;
return gist;
});
}
Где хранить результаты?
Если с исходниками я определился быстро, то вот с результатами не всё так просто. Не буду томить, просто перечислю решения, которые я знал на тот момент:
- Parse.com — BaaS, есть опыт использования, удобный JS SDK;
- MongoLab.com — DaaS, микроскопический опыт использования, требуется JS-велосипед для работы;
- Firebase.com — DaaS+, опыта не было, есть JavaScript SDK и кое-что ещё ;).
Так как проект был экспериментальным, выбор пал на Firebase: кроме JavaScript API, он предлагал в два раза больше места, чем на том же MongoLab, — целый гигабайт.
На самом деле был ещё один вариант: localStorage/IndexedDB + WebRTC. Идея заключалась в следующем: результаты прогонов храним в localStorage и если в онлайне есть ещё кто-нибудь, то синхронизируем данные :).
Итак, Firebase. Использовать его до безобразия просто, документация не врёт: https://www.firebase.com/docs/web/quickstart.html.
// Создаём экземпляр Firebase (предварительно создав application, в моём случае это JSBench)
const firebase = new Firebase('https://jsbench.firebaseio.com/');
// Подписываемся на событие изменения «узла» (stats / {gist_id} / {revision_id}):
firebase.child('stats').child(gist.id).child(getGistLastRevisionId(gist)).on('value', (snapshot) => {
const values = snapshot.val();
// Обрабатываем данные
});
// Где-то в коде в какой-то момент добавляем данные
firebase.child('stats').child(gist.id).child(getGistLastRevisionId(gist)).push(data);
Это весь код, который мне пришлось написать для работы с Firebase, но самое классное, что событие обновления «узла» срабатывает всякий раз, когда кто-либо запускает бенчмарки, и вы прямо онлайн, без каких-либо F5 или cmd + r, получаете обновление графиков.
Дизайн
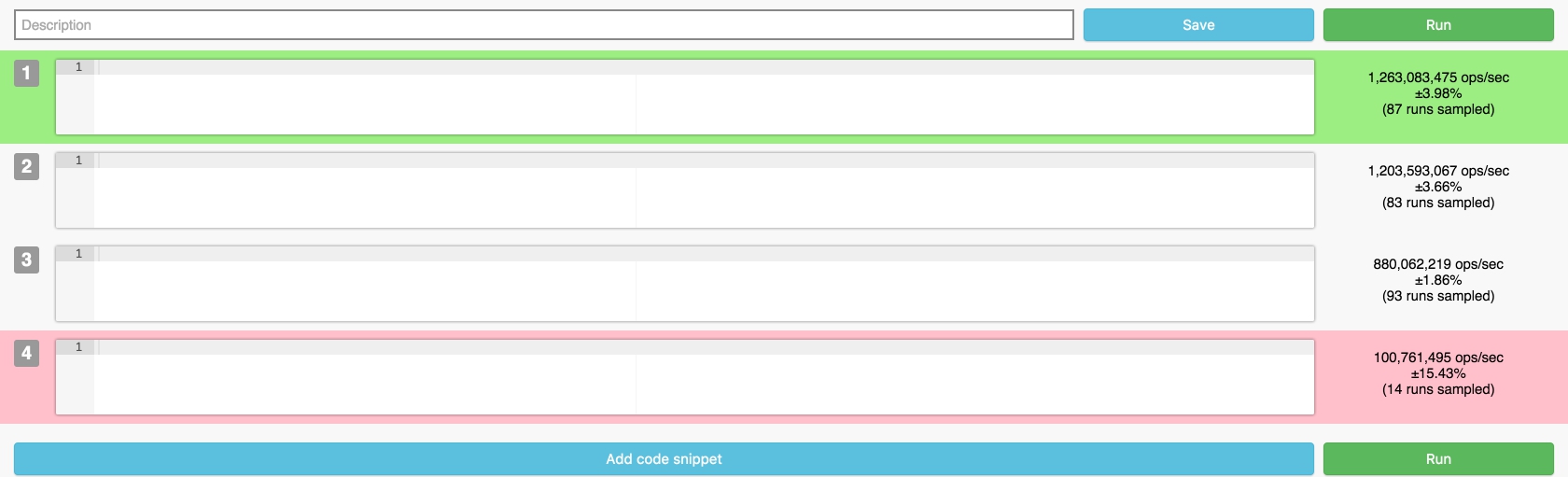
Эх, вот чего не умею, того не умею, поэтому всё выглядит так:
Интерфейс максимально информативен, отображены основные важные параметры, справа от кода теста выводится результат прогона, после завершения теста строчки подсвечиваются соответствующим цветом, а под кодом строятся графики. Setup и Teardown вынесены в «уши» внизу экрана — решение спорное, но подходит для большинства задач. В итоге вся возможная информация умещается на одном экране.
Как можно заметить, в отличие от jsperf, у меня есть подсветка кода, для этого используется Ace.
Ace — это чудесный инструмент для интеграции редактора кода в ваше приложение. Чтобы его использовать:
// Создаём инстанс
const editor = ace.edit(this.el);
// Устанавливаем тему
editor.setTheme('ace/theme/tomorrow');
// Включаем поддержку JavaScript
editor.getSession().setMode('ace/mode/javascript');
// Определяем максимальное и минимальное расширение редактора
editor.setOption('maxLines', 30);
editor.setOption('minLines', 4);
// Включаем автопрокрутку
editor.$blockScrolling = Number.POSITIVE_INFINITY;
// Подписываемся на изменения
editor.on('change', () => {
const value = editor.getValue();
// ...
});
Для прогона тестов используются Platform.js и Benchmark.js, графики рисую при помощи Google Visualization, так что результаты прогона и графики выглядят точно так же, как на jsperf.
Шаринг
Одна из фич — это шаринг теста, сейчас поддерживаются только Twitter и Facebook.
Тут особо нечего рассказывать: открываем popup с предустановленным текстом, а дальше пользователь сам решает, постить или нет.
function twitter(desc, url, tags) {
const max = 130;
const top = Math.max(Math.round((SCREEN_HEIGHT / 3) - (twttr.height / 2)), 0);
const left = Math.round((SCREEN_WIDTH / 2) - (twttr.width / 2));
const message = desc.substr(0, max - (url.length + tags.length)) + ': ' + url + ' ' + tags;
const params = 'left=' + left + ',top=' + top + ',width=' + twttr.width + ',height=' + twttr.height;
const extras = ',personalbar=0,toolbar=0,scrollbars=1,resizable=1';
window.open(twttr.url + encodeURIComponent(message), 'twitter', params + extras);
}
Вот тут интереснее, хотелось не просто ссылку постить, а сразу график в ленту. У Google Visualization есть метод получения dataURI, а у FB — Graph API, осталось их подружить:
Обвязка над Facebook SDK
const facebook = {
appId: 'XXXXXXX',
publichUrl: 'https://graph.facebook.com/me/photos',
init() {
return this._promiseInit || (this._promiseInit = new Promise(resolve => {
window.fbAsyncInit = () => {
const FB = window.FB;
FB.init({
appId: this.appId,
version: 'v2.5',
cookie: true,
oauth: true
});
resolve(FB);
};
// Стандартный код публикации
(function (d, s, id) {
var fjs = d.getElementsByTagName(s)[0], js;
if (d.getElementById(id)) {return;}
js = d.createElement(s);
js.id = id;
js.src = '//connect.facebook.net/en_US/sdk.js';
fjs.parentNode.insertBefore(js, fjs);
})(document, 'script', 'facebook-jssdk');
}));
},
login() {
return this._promiseLogin || (this._promiseLogin = this.init().then(api => {
return new Promise((resolve, reject) => {
api.login((response) => {
if (response.authResponse) {
resolve(response.authResponse.accessToken);
} else {
reject(new Error('Access denied'));
}
}, {
scope: 'publish_actions'
});
});
}));
}
};
Для преобразования dataURI используем https://github.com/blueimp/JavaScript-Canvas-to-Blob/.
И публикуем:
function facebookPublish(dataURI, message) {
return facebook.login().then(token => {
const file = dataURLtoBlob(dataURI);
const formData = new FormData();
formData.append('access_token', token);
formData.append('source', file);
formData.append('message', message);
return fetch(facebook.publishUrl, {
method: 'post',
mode: 'cors',
body: formData
});
});
}
Планы на будущее
- Поддержка ES6.
- Подключение сторонних либ для теста.
- Комментарии к бенчмарку (поддержка Markdown).
- Просмотр ревизий и fork’ов.
Полный список используемых библиотек и полифилов
- ES5 polyfill
- Promise — MDN / Promise
- fetch — Fetch API
- https://github.com/blueimp/JavaScript-Canvas-to-Blob/ — dataURI в Blob
- Ace — редактор кода (mode-javascript + theme-tomorrow)
- Platform — детектор платформы, браузера и т. п.
- Benchmark — запуск бенчмарков
- OAuth.io — сервис для работы c OAuth
- Firebase.io — NoSQL и не только
- SweetAlert — красивые алерты
Итог
Как видите, в настоящий момент можно собирать качественный прототип с помощью готовых решений и бесплатных платформ, затрачивая на это только своё время. А ведь это не просто экономия денег — это и экономия времени на выбор хостинга, установку, настройку необходимого софта и дальнейшее администрирование. Все эти проблемы исчезают, когда вы используете любой BaaS или DaaS — они дают вам готовое решение без головной боли. Плюс, если проект вырастет и окрепнет, вы всегда можете перейти на подходящий платный тариф или поднять точно такой же стек на своём хостинге.
Страница проекта: http://jsbench.github.io/
Исходный код и задачи: https://github.com/jsbench/jsbench.github.io/
Igogo2012
Ваш бенчмарк выдает разные результаты даже у пустых исходников
RubaXa
Как написано в статье, внутри используется benchmarkjs.com, это он выдает такие результаты, на jsperf ровно такая же картина с пустыми тестами. Такие результаты получаются из-за любого тормоза на вашем компьютере или переключением между вкладками, да даже движение мышки могло повлиять на результаты прогона пустышек. По сути вы протестировали работу самого benchmarkjs.
RubaXa
Да, и задача на исключение «пустышек» стоит: #15
defuz
Ага, при этом показывается погрешность результата ±4%. Это ж какая доверительная вероятность должна быть, чтобы так ошибиться? Или здесь что-то совсем не так, или этот benchmarkjs полное говнище, которое просто врет.
RubaXa
Вполне нормальная погрешность при прогоне «пустышки». На результат работы может повлиять любой «чих» в браузере во время прогона, например уход со страницы или её прокрутка, либо любые другие фоновые процессы. Если запустить этот же тест через NodeJS, будет примерно такая картина:
#1 x 749,382,154 ops/sec ±0.61% (100 runs sampled)
#2 x 753,619,434 ops/sec ±0.29% (100 runs sampled)
#3 x 748,112,204 ops/sec ±0.71% (98 runs sampled)
#4 x 742,616,805 ops/sec ±0.66% (94 runs sampled)
defuz
Фактическая погрешность то может и нормальная, только вот это не отменяет того факта, что бенчмарк тупо врет: зачем показывать пределы погрешности в несколько процентов, если на любом простом примере видно что это не правда?
RubaXa
Я так не считаю, во вторых, отличается он в Chrome/V8, например в FireFox картина ровная, как и в Safari. + у меня Chrome результаты немного отличается, первый тест чуть «медленней», последующие уже ровные.
defuz
Если у вас картина выравнивается, то и интервал погрешности должен сужаться. Если разброс большой, то интервал погрешоности тоже должен быть большой. Только это почему-то не наблюдается.
ornic
Это не погрешность измерений, а разброс результатов.
defuz
Да, и они наглядно демонстрируют, что бенчмарк не состоятелен. Кстати, разброс результатов тоже должен считаться с определенной и вполне конкретной доверительной вероятностью. А я так понимаю, никто даже не знает ни какая она, ни по какой формуле считается результат.
ornic
Очень много умных слов использовано в довольно бессмысленном тексте. :(
Каждый инструмент предназначен для своих измерений. Пример выше показывает, что для измерения холостых циклов этот инструмент не подходит — уровень шумов системы слишком высок.
В принципе, можно при тестировании любой задачи запустить что-то вроде CPUburn и получить гигантский разброс результатов. И «доказать» несостоятельность бенчмарка, в которую даже кто-то необразованный поверит.
defuz
ornic
Инструмент? Что он должен сделать? Написать — «Не трожь мышку, придурок!», — если разброс времени выполнения превышает 0.1 (взял из головы) от времени выполнения 1 итерации?
Не предполагается, что пользователь инструмента об этом должен быть в курсе и так? :)
defuz
Я же написал вам, что дожно происходить в таком случае – бенчмарк должен отобразить большой разброс времени выполнения. А пользователь уже сам должен думать, как этот диапазон сузить (что ему не трогать, какие процесы завершить, какой приоритет браузеру поставить и т.д.).
Я пишу «должен» не потому, что у бенчмарка есть какие-то там обязательства перед пользователем, а потому что так, блин, работает статистика в нашем мире. А у benchmark.js видимо какая-то инопланетная статистика используется, если исходить из того, что он показывает в качестве результата.
RubaXa
Ну тогда JS Benchmark'и не для вас, ибо другого инструмента, для быстрого сравнения производительности в js нет, точнее есть, но он уже сложней и не про бенчмарки.
RubaXa
Ну и если откинуться на спинку стула и закрыть фоновые вкладки, результат в Chrome тоже выравнивается:
defuz
Еще раз: проблема не в том, что результаты отличаются, это как раз легко объяснить, а в том, что результаты бенчмарка выглядят так, будто бы ожидаемое время работы тестов действительно отличается. Нормальный бенчмарк должен был бы в этом случае показать, что мат. ожидания сильно отличаются, но и доверительный интервал достаточно большой для того, чтобы результаты имели возможность совпасть. В этом бенчмарке этого не происходит. И речь не только о «пустых» тестах. Любые одинаковые тесты выявляют эту проблему. Предлагаете запретить запускать одинаковые тесты, чтобы не палиться?
ornic
Тут мимоходом сформулирована, ЕМНИП, одна из задач на миллион. Будем ждать выхода такого бенчмарка. :)
defuz
Вы прикалываетесь? Речь идет о правильном применении статистики, не более того. Посмотрите как работает протокол синхронизации времени NTP, как он опрашивает различные сервера и пользуется доверительными интервалами для latency, у вас же я надеюсь не возникает сомнений, что он работает?
Вот так ведет себя нормальный бенчмарк в «хороших условиях»:
А вот так этот же бенчмарк ведет себя в условиях хаотичной нагрузки на CPU для четырех идентичных тестов:
Обратите внимание, как сильно увеличился разброс во втором случае и на то, что при любых обстоятельствах все результаты лежат в пределах интервалов погрешностей друг друга.
ornic
Тут ключевое слово «хаотичной».
defuz
Объясните пожалуйста, что вы имеете ввиду. Вот результаты, когда сторонняя нагрузка случилась во время выполнения первых двух тестов, и не затронула последние два:
ornic
Видно, что нагрузка точечная, т.е. сильно изменяется разброс, но при этом среднее (или это медиана?) меняется не сильно.
Потому естественно, все средние попадают в диапазоны разброса друг-друга.
В примере с пустыми тестами же было видно, что нагрузка просто нагибает тестера, и со стороны инструмента нет никакой возможности понять, виноват в этом тестируемый код или нет.
Гипотетически. Если взять bench_b и запустить его на процессоре на 3-4 семейств старше, то его данные будут ровными (т.е. с малым разбросом), но при этом с заметно отличающимся от остальных тестов средним.
Ну или более наглядный пример: стрельба из ружья. Одно дело трясти ружье и другое — просто поменять гравитацию для одного из тестов. Инструмент не знает что происходит «снаружи», он видит только набор дырок на мишени и оценивает их кучность и место.
Равенство условий тестов между собой — задача тестировщика, а не инструмента.
ИМХО. :)
P.S. О, кто-то добрый сделал мне 1 раз в 5 минут :)
Так что отвечу на второй комментарий тоже тут.
При низких результатах разброс не обязан быть большим. Они могут быть стабильно низкими ;)
defuz
Ваш пример с ружьем и изменением гравитации не совсем корректен, потому что не соответствует тому, как работает процессор. Реально в один момент времени у вас выполняется только один поток на ядро, так что гравитация будет скорее не «постоянным» явлением (систематическая ошибка), а «периодическим» (иногда влиять на пулю, а иногда нет).
Чем больше время выполнения одной итерации, тем значительнее мешающий поток будет замедлять результаты. Если итерация теста выполняется очень быстро (например, если речь идет о пустом тесте), то довольно часто будут происходить ситуации, когда целая итерация будет выполнена в тот момент, когда мешающий поток будет спать и не будет влиять на время конкретно этой итерации вообще. Именно из-за этого будет сильно увеличиватся разброс времени выполнения.
К тому же «быстрые» тесты можно повторить большее количество раз, в то время как «тяжелые» тесты приходится выполнять меньшее количество раз, что так же сказывается на точности результатов. Так что проблема «гравитации», которую вы описали, имеет отношение только к тяжелым тестам, но никак не к быстрым тестам и тем более пустышкам. Для таких тестов ситуация будет скорее похожа на то, как если бы вы трясли ружье, но только вниз, что кстати хорошо видно в том примере, который я выше привел: медиана просела, но доверительный интервал увеличился примерно на величину проседания медианы.
Полностью согласен, но инструмент должен сигнализировать о наличии проблемы с условиями тестирования. По-этому бенчмарки не просто показывают среднее или медиану, но еще указывают доверительный интервал, который позволяет оценить, насколько сильно можно доверять результату теста.
В данном случае интервал тоже отображается, но он не корректен, и позволяет мне сделать не верный вывод о том, что результаты тестов очень точны, хотя это очевидно не так.
ornic
Я не знаю как еще переформулировать фразу так, чтобы она стала понятной.
Может быть низкий разброс результатов внутри одного тестирования, но большой разброс между тестируемыми образцами. В этом случае инструмент не способен принять решения: виноваты тестируемые скрипты (мы же подразумеваем, что они разные) или же окружающая среда, о которой инструмент не имеет представления.
Но это все, конечно, теория. :) Возможно в тех либах кривой код.
defuz
В последних двух тестах шла постоянная нагрузка на все ядра с повышенным приоритетом. Так что я не представляю, как вы практически собираетесь изменить медиану, не затронув разброс.
ornic
Этот ведь тест тоже на js, я все забываю спросить? :)
RubaXa
Ещё раз: результат идентичного куска кода будет отличаться, не сильно, но будет, происходит это из-за множества внешних, а главное внутренних факторов (фоновых процессов, применение оптимизаций и т.п.) браузерных js-движков, которые нельзя изолировать.
defuz
Последний раз: у меня нет претензий к тому, что результаты тестов отличаются, у меня претензия к тому, что библиотека не умеет правильно измерять разброс для таких результатов.
Задача бенчмарка не только посчитать среднее арифметисеское времени работы всех запусков, но и правильно оценить диапазон, в котором лежит реальное время работы. В противном случае толку от такого бенчмарка?
RubaXa
O-k-e-y.
KingOfNothing
Если кому-то еще интересно запускать тесты с jsperf на ноде, то я тут пытался автоматизировать это дело: github.com/OrKoN/jsperf
Автор, если подскажете, как правильно скачивать тесты с jsbench, то я думаю, что смогу поддерживать jsbench в том числе.
RubaXa
Сохраненный тест, это простой gist из двух файлов html и js, вот пример: gist.github.com/RubaXa/a4612afd0cd26e911ee8