

Иллюстрация Michael Parkes
Мы постоянно слышим, что изобретать велосипеды — плохо, но где грань между велосипедом и готовым продуктом? На каком этапе Backbone, Ember или Angular перестали быть таковыми? Об этом редко говорят. Так получилось, что последние четыре года я непрерывно занимаюсь разработкой разного рода «велосипедов» — не потому, что мне это нравится (а мне очень нравится), просто одни решения устарели, другие завязаны на специфичной технологии (например, на том же jQuery), не нужной нам, и оторвать которую равносильно написанию с нуля. Но основная проблема заключается в узкой специализации и отсутствии возможностей расширения. На том же гитхабе уйма решений, но не у каждого есть будущее. Поэтому если вы решили срочно выполнить поставленную задачу, написав, как вам кажется, отличную штуку, то не тратьте время и пожалейте других людей, которым после вас предстоит поддерживать это. С 99%-ной вероятностью они все перепишут. Так когда же можно и даже нужно изобретать собственный велосипед?
Начните с задачи, оцените ее:
- потенциал (есть ли область применения и перспективы развития, возможно, завтра это уже будет не нужно);
- обобщение (возможность применения в других задачах и проектах);
- отчуждаемость (независимость от внутренней инфраструктуры).
Эти нехитрые пункты применимы практически к любой задаче, будь то разработка фреймворка либо jQuery-плагина.
Наша же история началась три года назад: была поставлена задача «разработать почту для touch-устройств», для чего потребовалось выбрать технологию, на основе которой все и сделать. Вариантов было три:
- использовать наработки большой почты;
- взять популярный фреймворк;
- написать самим.
Использовать код большой почты не представлялось возможным — 17 лет истории дают о себе знать. Поэтому оставалось либо написать самим, либо искать готовые инструменты. Разработать основу под такую задачу весьма непросто, даже с учетом нашего опыта, потенциала у данного начиная практически нет — с огромной вероятностью это будет узкоспециализированное решение, жестко привязанное к тачу. Примерно представляя, что нам нужно, мы выбрали подходящие решения под нашу задачу (а главное — команды):
- Grunt — сборка проекта;
- RequireJS — организация модулей;
- Backbone — model, view, routing;
- Fest — шаблонизатор.
Эти нехитрые инструменты позволили быстро разработать проект и начать его реализацию. Все было хорошо, пока touch-почта не начала догонять большую по функционалу. Из-за этого многие продуктовые фичи делались дважды — сначала на большой почте, а затем и на touch.mail.ru, хотя различия в реализации были минимальны и поддавались конфигурированию. Положение усугублялось внедрением нового backend API, которое было уже не достаточно просто «дернуть и получить» ответ:
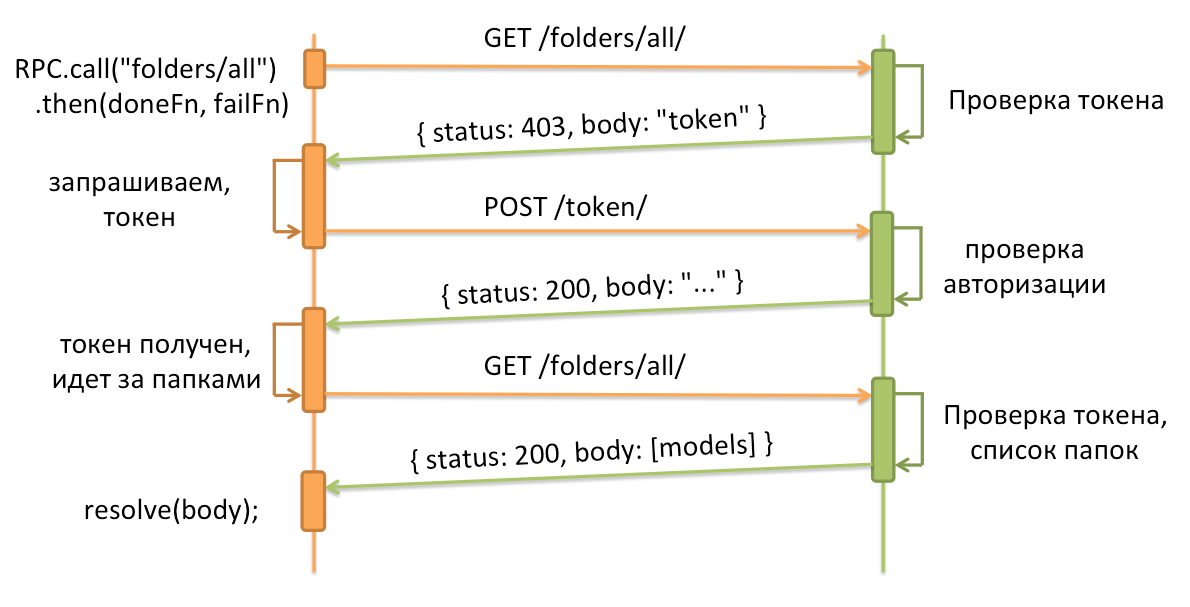
Посмотрев на все это, мы решили, что дальше так жить нельзя — двойная разработка, двойные баги, двойное тестирование, опять баги… А еще есть другие внутренние проекты, которые хотят интегрировать у себя некоторый кусочек функционала Почты.
Все говорило о необходимости общей кодовой базы, которая находилась бы в отдельном репозитории, и в рамках которой реализовались бы общие компоненты.
Суммировав наши знания по проектам, мы определили базовый набор пакетов:
- Emitter — излучатель событий;
- Promise — обещания;
- Request — отправка HTTP-запросов к серверу;
- RPC — отвечает за логику работы с серверным API;
- Model — класс модели;
- RPCModel — расширенная модель для работы через RPC;
- Model.List — класс для работы со списком моделей (коллекция).
Дальше дело за малым: на чем построить эти компоненты:
- выбрать готовые библиотеки/фреймворки;
- написать самим.
Чтобы ответить на подобный вопрос, для себя я сформулировал следующие шаги:
- составление списка готовых решений (даже подходящих не полностью);
- изучение списка (примерно неделю, далее смотрим код, поддержка, задачи на github, если такие есть, и т.п.);
- если решение не подходит под задачу, пробуем изменить задачу (идем к менеджеру/дизайнеру, предлагаем альтернативу, а не «это невозможно, все дураки»);
- если вам не подошло ничего, то готовы ли вы… (об этом чуть позже).
Поиск готовых решений
Первое, с чего нужно начать — конечно же, с определения требований, предъявляемым к решению. Это должен быть список возможностей, необходимых под конкретную задачу (которую вы перед этим уже разобрали по полочкам), плюс расширяемость. Не занимайтесь overengineering, так как ни к чему хорошему он не приведет, а только запутает и уведет от цели.
Итак, первым делом нужно было решить, что делать с моделями, на базе чего их строить. Однако необходимо учесть, что решение должно обладать следующими возможностями:
- Dot notation — доступ к свойствам модели через точечную нотацию, например, model.get(‘foo.bar.baz’);
- Getters — доступ к свойствам без `get`, model.foo // {bar: {baz: true}};
- Caching — возможность восстановления данных из localStorage или IndexedDB;
- Persist model — целостность модели.
Как я уже говорил, touch-почта, а также ряд других проектов, построены на Backbone — это хорошая основа, которая дает вам Emitter, Model, Collection, Router и View. Этим можно покрыть все наши потребности.
Все упиралось только в большую почту, на которой не было Backbone, но те модели, что были, имели схожий интерфейс (get/set).
| Backbone | Почта | |
|---|---|---|
| Dependencies | jQuery, undescore | jQuery |
| Dot notation | - | + |
| Getters | - | + |
| Caching | - | - |
| Persist model | - | + |
Как видите, выходило так, что базовых возможностей, которые есть у большой почты, не было в Backbone. Но! Backbone — устоявшийся инструмент, проверенный временем и имеющий огромное сообщество и активную поддержку, поэтому практически любые недостающие функции можно покрыть расширением, которое уже давно написано и протестировано.
Так что точечную нотацию можно получить, использовав:
Для реализации getters существуют https://github.com/asciidisco/Backbone.Mutators (но только с get).
И так далее. Увы, как бы я ни искал, так и не смог найти расширение для поддержки «целостности модели» из коробки, когда такая возможность была краеугольным камнем большой почты.
Что же такое «целостность модели»?
Рассмотрим пример получения письма:
function findOne(id) {
var dfd = $.Deferred();
var model = new Backbone.Model({id: id});
model.fetch({
success: dfd.resolve,
error: dfd.error
});
return dfd.promise();
}
// Где-то в коде #1
findOne(123).then(function (model) {
model.on("change:flag", function () { // Слушаем событие
console.log(model.get("flag"));
});
});
// Где-то #2
findOne(123).then(function (model) {
model.set("flag", true); // и ничего не происходит
});
На первый взгляд, проблему можно исправить, доработав, например, метод findOne, чтобы он запоминал promise и возвращал его:
var _promises = {}; // список обещаний
// Поиск модели
function findOne(id) {
if (_promises[id] === undefined) {
var dfd = $.Deferred();
var model = new Backbone.Model({id: id});
model.fetch({
success: dfd.resolve,
error: dfd.reject
});
_promises[id] = dfd.promise();
}
return _promises[id];
}
Но помимо поиска модели по id, есть еще получение списка моделей (коллекции). И где бы я ни получил коллекцию, она должна состоять из ссылок на экземпляры одних и тех же моделей, для поддержания целостности в любой точке приложения.
Конечно, и это можно накрутить поверх Backbone, но проблема не только с этим. Например, после выполнения любого метода коллекции, мы получаем массив на выходе.
// Отфильтруем и получим все id
var ids = collection
.where({ flag: true })
.pluck("id");
// TypeError: undefined is not a function
Таким образом, чтобы на Backbone сделать то, что мы хотим, нам надо:
- Dot notation — подключить Nested / Deep Model или писать самим;
- Сaching — ничего вразумительного не нашел;
- Persist model — писать самим.
- а ещё: логирование, моки и другие мелочи
Даже если бы удалось найти какие-то расширения, реализующие необходимые возможности, строить что-либо на этой сборной солянке я бы не рискнул — очень высока вероятность багов и конфликтов между этими расширениями, а также значительного провала в производительности. Такие возможности должны быть интегрированы в ядре самого фреймворка.
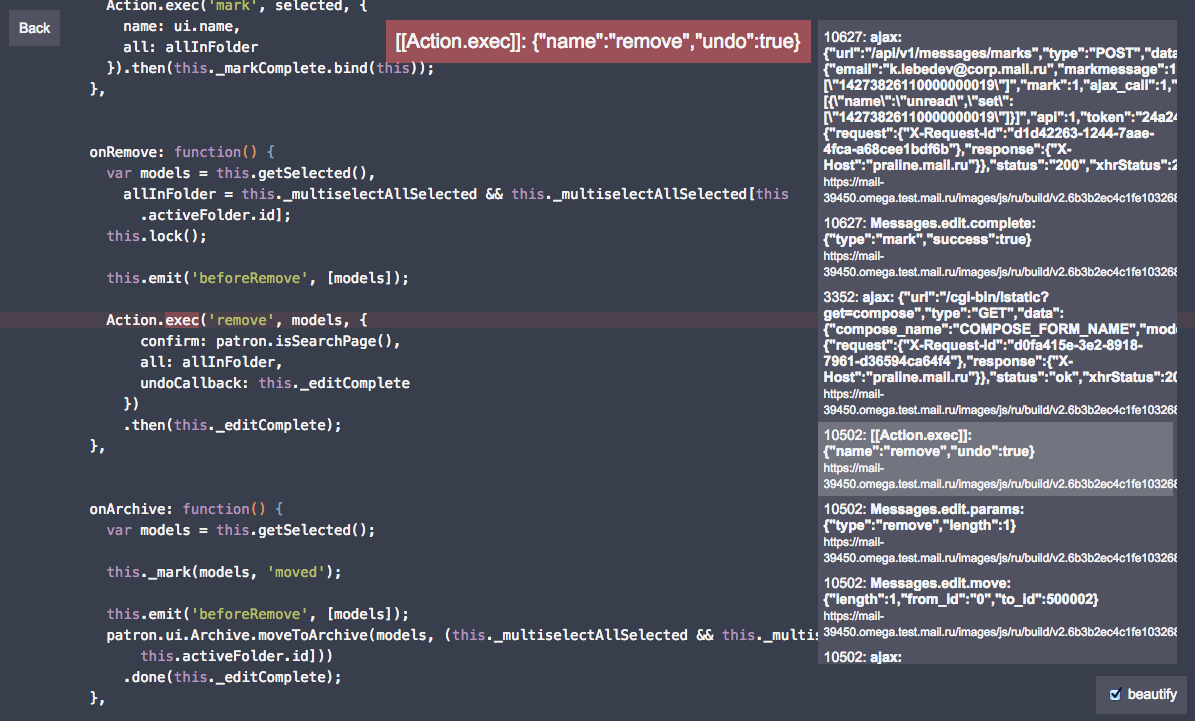
Сейчас наш логер выглядит следующим образом, рассмотрим на примере:
// Получить список папок
Folder.find({limit: 50}).then(function (folders) {
logger.add('folders', {length: folders.length});
// Найти папку «Спам» и изменить её имя
return folders.filter({type: Folder.TYPE_SMAP})[0].save({name: 'Bulk'});
});
И вывод лога:

Как видите, лог получился вложенный и кроме того, каждая запись привязана к строчке кода, что позволяет смотреть лог прямо в контексте кода через спец. интерфейс (даже если код минифицирован):
rubaxa.github.io/Error.stack
Ну, хорошо, модели напишем сами. Попробуем найти хотя бы решения для остальных компонентов. (Еще можно было сделать форк Backbone, как, например, сделали Parse.com, и я даже планировал это, но объем наших изменений сопоставим с объемом самих моделей.)
Emitter
Зайдя на github и задав «Event Emitter», вы найдете следующие библиотеки:
- EventEmitter — 1 240 (stars) / 170 (forks)
- EventEmitter2 — 1 220 / 128 (а так же EventEmitter3, который тоже набирает популярность)
- microevent — 531 / 88
- и другие
| on/off/emit | тесты | handleEvent | объект события | |
|---|---|---|---|---|
| EventEmitter2 | + | + | - | - |
| EventEmitter | + | + | - | - |
| microevent | + | - | - | - |
| jQuery | + | + | - | + |
Как видите, ни одна из них не поддерживает такие вещи, как handleEvent и объект события, да и по скорости они не шибко производительные. Но в целом подходят и могут быть использованы в качестве готового решения.
Promise
- Native Promise + полифил;
- jQuery.Deferred;
- Q, when и другие/
Q, when и другие — не только обещания, но еще вагон и тележка разного функционала, а нам нужны только обещания. Так что Native + полифил идеально подходят, если бы не одно большое но: нативные обещания несовместимы с jQuery (все из-за этого куска кода).
Request
Здесь бескрайнее море решений, которые все, как один, похожи и не имеют:
- событий (начало, конец, ошибка, потеря авторизации WiFi и т.п.);
- таймингов (время начала и конца, продолжительность запроса);
- возможности обработки ошибки и изменения результата;
- повтора запроса, например, в случае ошибки.
Ближайшим подходящим вариантом является только jQuery.ajax.
Итак, каждое решение, которое мы нашли, по разным причинам не подходит под наши требования. Например:
- Emitter — не поддерживает handleEvent и/или объект события;
- Promise — несовместим с jQuery;
- Request — ближайший аналог jQuery.
Конечно, можно было взять одно из решений, урезать себя по возможностям и завязаться на jQuery. Но эти модули не такие объемные, да и наличие jQuery не внушало оптимизма.
И в этот момент мы возвращаемся к пункту №4: Если вам не подошло ничего, то готовы ли вы…
Готовы ли вы...
- Писать общее решение, а не решать узкую задачу.
- Писать тесты и документацию.
- Поддерживать 7/24.
- Делать все это бесплатно.
Последний пункт может кому-то показаться странным, но не спешите — на самом деле это важный момент. По сути, бизнесу не важно, что у вас под капотом — его волнует прибыль (я сейчас говорю в общем), поэтому если вы настояли и даже смогли выбить время на реализацию, то поддержка будет осуществляться за ваш счет, и это будет честно — это был ваш выбор, ваше решение. Многие недооценивают этот пункт и, как мне кажется, именно поэтому гитхаб забит решениями, поддержка которых умерла буквально на следующий день. Нужно быть готовым к неиллюзорным двум-трем задачам в неделю (а дальше в день), и что за это вам максимум скажут спасибо, что уже хорошо (и это если не считать багов, которые будут, даже с тестами).
Итак, вы решили, с чего начать? Главное не кодить! Начать нужно с инфраструктуры проекта.
Инфраструктура
- Сборка grunt или gulp.
- Code style.
- Тесты, контроль покрытия и CI.
- JS, CS, TS или ES6/Babel.
- Автоматизация контроля изменений.
- Документирование кода и документация.
- Способ распространения (github, bitbucket и т.п.).
Помните, что каждый из пунктов решает конкретную задачу и очерчивает правила, которыми будут руководствоваться пользователи.
Для нас я выбрал следующий стек:
- GruntJS для сборки проекта;
- JSHint и .editconfig — снимают все вопросы и лишние холивары по поводу стиля кодирования или tab vs. space, с роботом уже не поспоришь;
- QUnit + Istanbul — тесты не только улучшат качество продукта, но и ускорят процесс разработки и рефакторинга. Покрытие даст возможность увидеть, насколько хорошо ваши тесты покрывают возможности, которые вы закладываете в api. В качестве CI был Travis, теперь Bamboo;
- ES5 + Полифилы — один из самых важных пунктов. TS, CS или ES6 — это не просто технологии. Этот выбор сильно повлияет на принятие решения — использовать ваше решение другим разработчиком или нет;
- git pre-commit-hook (JSHint) + git pre-push-hook (QUnit + Istanbul) — автоматизируйте то, что можно автоматизировать, как и установку хуков посредством preinstall или postinstall в package.json;
- JSDoc3 — документируйте и комментируйте код, современные IDE умеют строить autocomplete по JSSDK, но главное — другой разработчик, прочитав комментарий или описания параметров, быстрее вникнет в ваш код и его логику.
С чего начинает разработчик?
Заходит на github и видит:
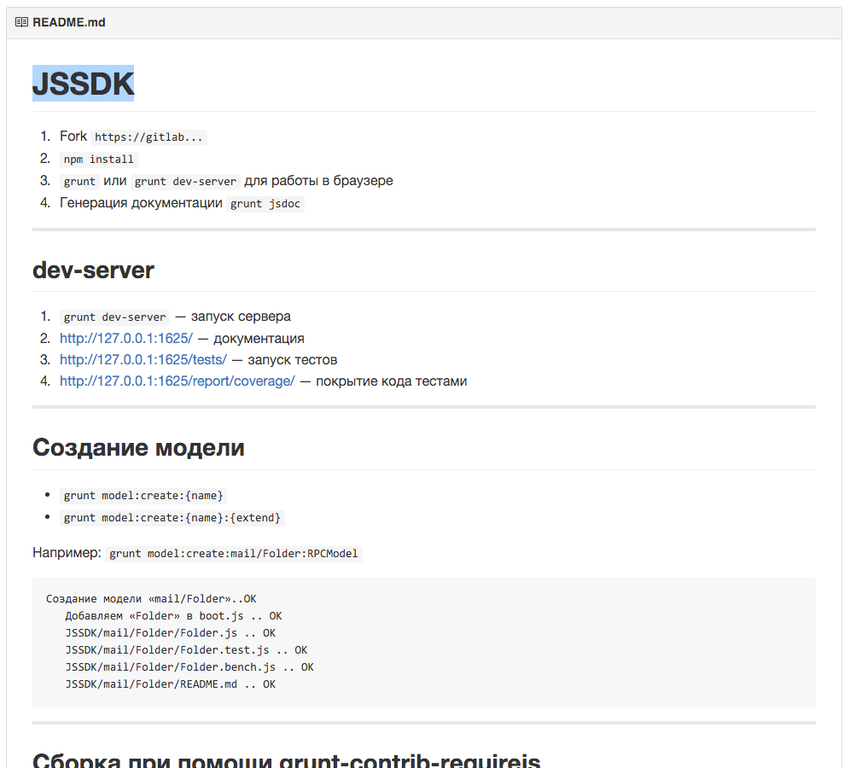
Как видите, здесь описаны шаги, которые необходимо выполнить разработчику, если он хочет использовать или разрабатывать проект.
Перейдем непосредственно к разработке.
В JSSDK каждый модуль является отдельной папкой, содержащей четыре файла. Например, Model:
- Model.js — код модуля;
- Model.tests.js — тесты;
- Model.bench.js — тесты производительности (если нужны);
- README.md — документация (генерируется по JSDoc3).
Как я уже писал, автоматизируйте все, что можно автоматизировать. Поэтому для создания модуля у нас заведен отдельный grunt task.
Так, например, будет выглядеть создание модели mail.Folder, которая наследует RPCModel:
> grunt model:create:mail/Folder:RPCModel
Создание модели «mail/Folder»..OK
Добавляем «Folder» в boot.js .. OK
JSSDK/mail/Folder/Folder.js .. OK
JSSDK/mail/Folder/Folder.test.js .. OK
JSSDK/mail/Folder/Folder.bench.js .. OK
JSSDK/mail/Folder/README.md .. OK
При разработке первым делом пишутся тесты и только потом уже код. После внесения изменений или написания нового модуля начинается самое интересное — commit и push:

git commit -am"..." — запускает grunt jshintgit push original master — запускает grunt testЕсли таск отработает с ошибкой, то commit или push не пройдут, это позволяет держать код в master всегда рабочим. Закомитить нерабочий код можно только в ветке, отличной от master. В любой другой ветке ошибки будут просто выведены на экран. Также push может не пройти из слабого покрытия тестами. Слабым мы считаем все, что меньше 100% (на текущий момент это 1 635 assertions).
Покрытие тестами
Покрытие тестами — не панацея от всех бед, оно не дает 100%-ной гарантии отсутствия багов. Главное, что дает покрытие, — возможность оценки, насколько ваши тесты затрагивают все возможности, а иногда и позволяет переосмыслить конечную реализацию того или иного куска кода.
Разработчик запускает
grunt dev-server и видит следующую картину: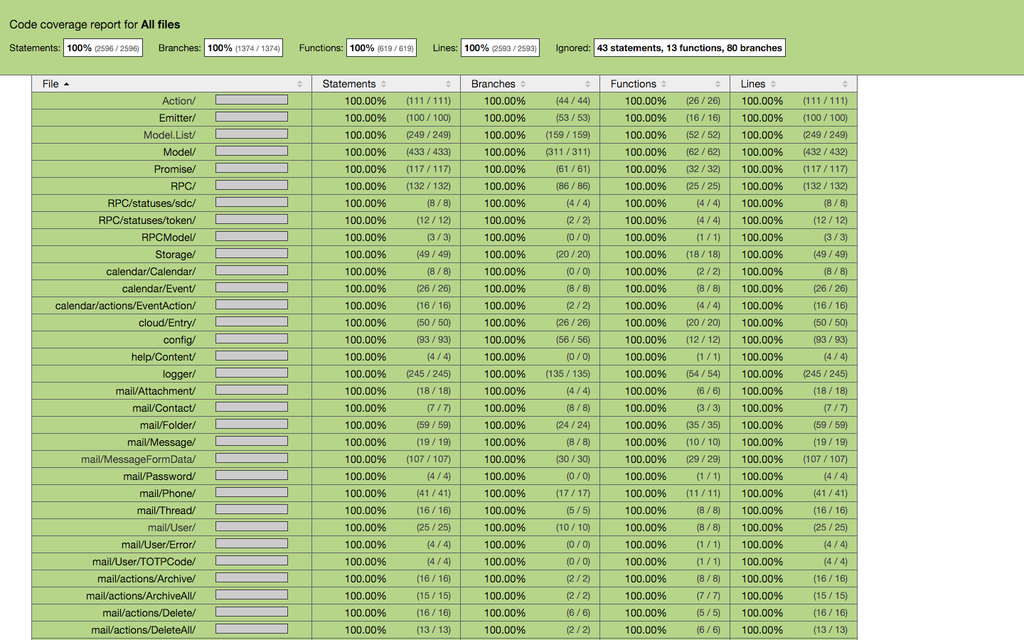
А вот сам код и его покрытие:

Документация
Финальный штрих — генерация документации. Для этого мы используем официальный JSDoc3 и свой publisher (на самом деле в npm полно подобных решений). Итоговая документация существует в двух видах, это:
- README.md;
- 127.0.0.1:1625/ — dev-server с документацией.
Вот так выглядит README.md модуля:

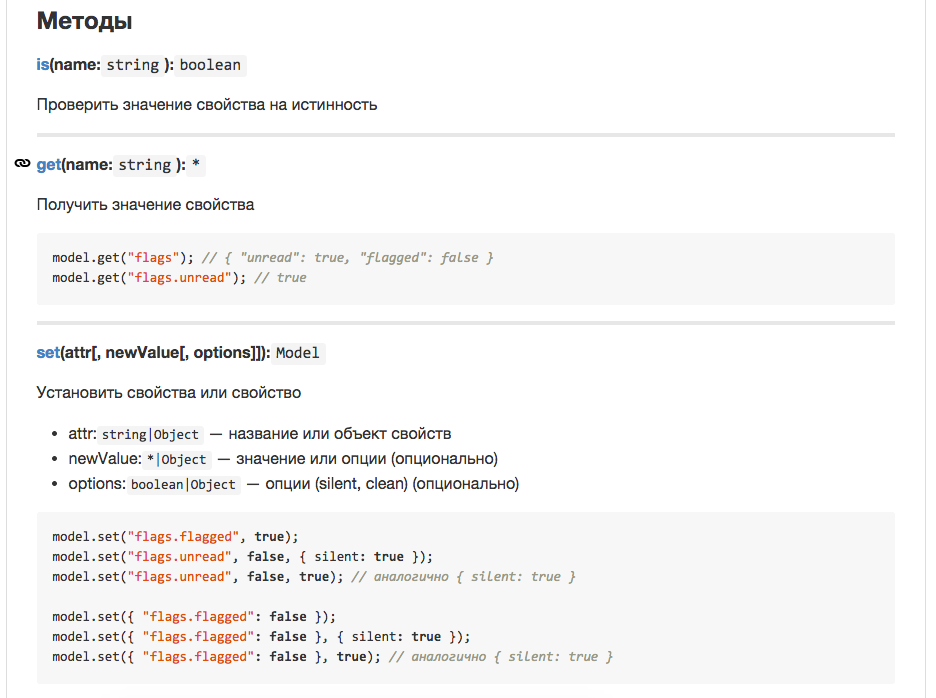
Тут мы сразу видим примеры и описание методов, а также ссылки на примеси. На каждый пункт можно дать ссылку, помимо этого, клик на имя метода позволяет быстро перейти к коду.
README.md удобен тем, что его можно посмотреть откуда угодно, без каких-либо дополнительных усилий. Но для повседневного использования есть еще и веб-интерфейс для просмотра документации, который можно поднять локально. Выглядит это следующим образом:
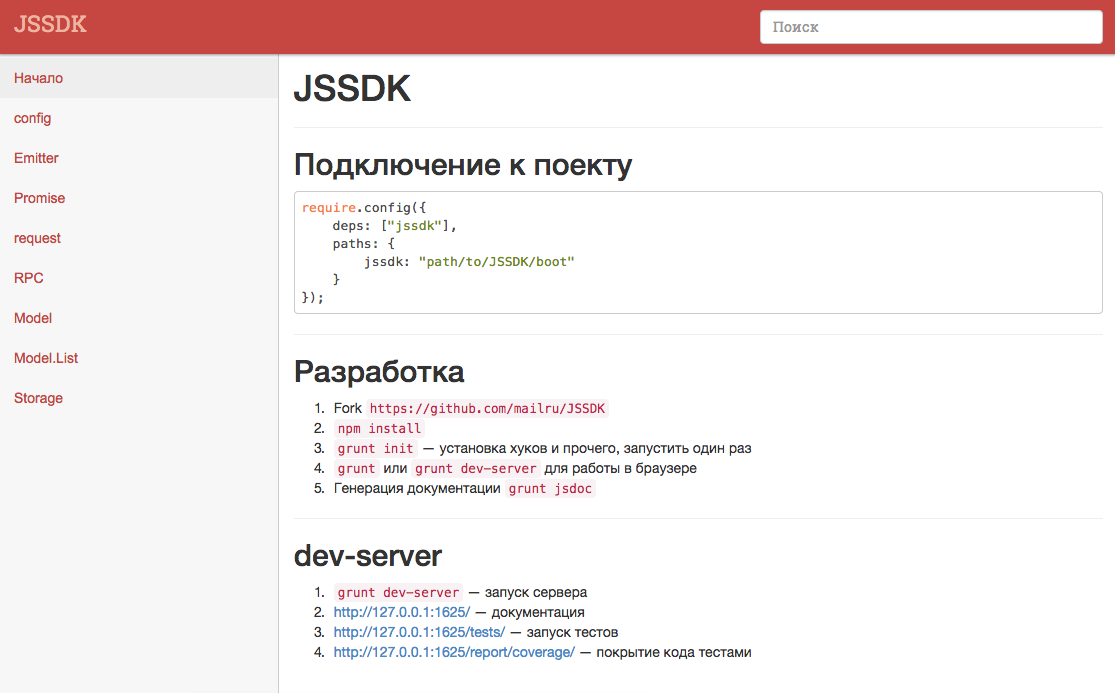
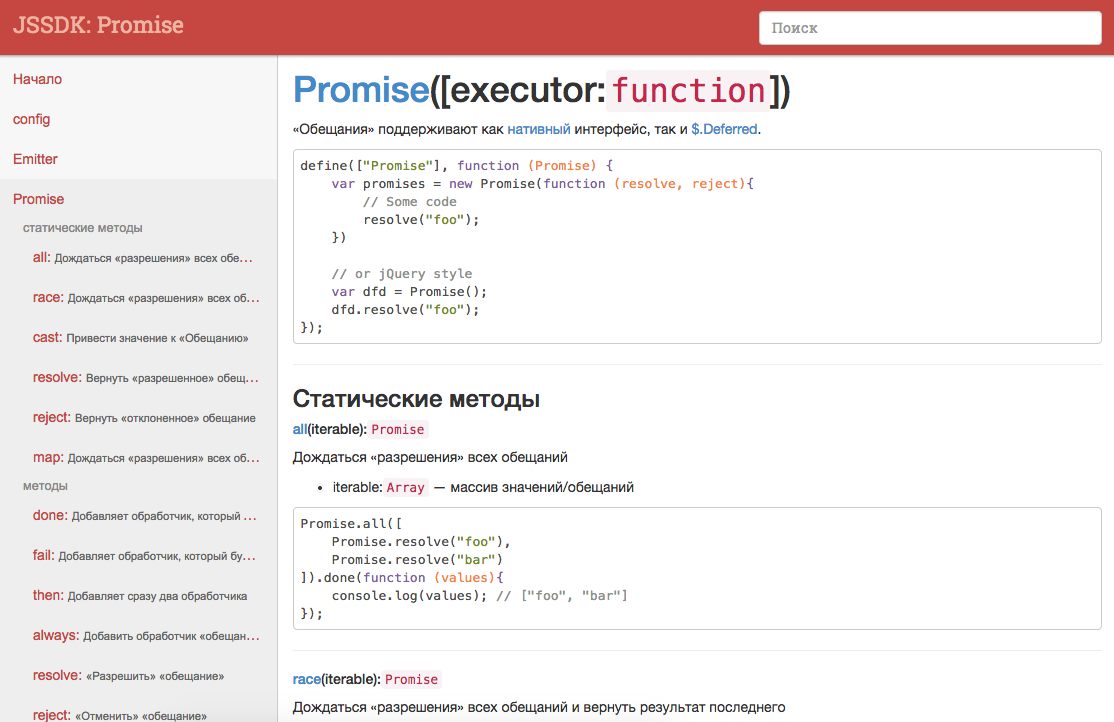
Все содержимое строится на основе md-файлов, поэтому оно так же всегда актуально. Но самое важное — одностраничное приложение, имеющее некое подобие fuzzy-поиска, который позволяет быстро перейти к нужному методу.

Главное, что все это не только не тормозит процесс разработки, но и очень сильно помогает. Бытует мнение, что тесты и документация отнимают время. Порой мне кажется, что так говорят те, кто не пробовал их писать. Но не будем об этом. Лично мне они позволили не просто улучшить качество кода, но и заметно снизить время на разработку. Второй распространенный миф состоит в том, что комментарии коду не нужны, так как код должен быть выразительным и говорить за себя… Да, все верно, но в большинстве случаев проще, а главное быстрее прочитать по-человечески, чем строить из себя интерпретатор.
В завершение скажу еще раз: всегда ищите готовое решение! Если ничего путного не находите — подумайте, как изменить задачу. Если решили писать с нуля — сделайте все возможное, чтобы решение могло жить без вашего участия. А главное — пишите инструменты, а не велосипеды. Тестируйте и документируйте! Спасибо за внимание.
Комментарии (21)

vayho
26.11.2015 16:04Не смотрели в сторону dojo + dstore + dmodel? У них на первый взгляд все почти есть, а если нету то допиливается.

RubaXa
26.11.2015 16:25Смотрел, не скажу, что внимательно, но видел. Всё же для нас самое близко был CanJS, но он очень тормозной оказался, ну и опять же Dojo. А как там с целостностью, особенно для коллекций? Ну и основная задача была объединить и интегрировать общую бизнес логику и кодовую часть «малой кровью».
vayho
27.11.2015 10:37Там есть персистентность и подписка на обновления модели. Правда мы не используем этот функционал.
RubaXa
27.11.2015 11:11Да, вчера посмотрел реализацию заметил это. Но если объективно сравнивать с нашими моделями, DModel отстает по функциональности, притом ещё критичной для нас, ну и сама реализация не шибко шустрая, а для нас это было очень важно, нам приходится работать с коллекциями до десятков тысяч моделей. Вот актуальные бенчмарки на сегодня: модель, коллекция.
{kind=link}
{kind=link}
aparamonov
27.11.2015 07:27Мне кажется, Вы rxjs переизобрели.
А почему, кстати, фреймворк не в open-source?RubaXa
27.11.2015 09:10Не, с RxJS у нас ничего общего, хотя есть ветка по интеграции, только не с ним, а с Beacon, но пока так и осталось веткой.
Не опенсорнсим, потому что задача была объединить кодовую базу, создать SDK с общими сущностями, которые можно шарить между проектами. Так что опенсорсить практически нечего, разве только Emitter, request, Model и Model.List, но подобных решений и так полно (Bacnbone, CanJS и д.р.), а та специфика, которая заложена в наши, будет не нужна для 90% разработчиков.
vintage
Зачем вам промисы, если есть атомы? http://habrahabr.ru/post/235121/
RubaXa
Эээ, даже не знаю как ответить, но никаких «атомов» нет в браузере, а вот «Обещания» есть. Во вторых, я так и не понял, как они решаю те задачи, для которых предназначены «Обещания»?
vintage
Обещания есть только в некоторых браузерах. И то появились они там лишь потому, что повсеместно используются. Если все начнут пользоваться атомами, то и они появятся в браузерах. Другое дело, что я не представляю как бороться против хайпа вокруг обещаний, заниматься отладкой кода на которых — то ещё удовольствие. В то время как есть более debug-friendly подход — fibers, но они есть только на ноде и то в виде стороннего расширения.
Атомы — обобщение над обещаниями. Или, вернее сказать, обещания — это одноразовые атомы. При этом атомы позволяют писать код в стиле fibers (с инкапсулированной асинхронностью), даже без этих самых fibers. Собственно атом можно использовать и как promise (then,catch) и как eventEmitter (on), но это скорее для совместимости, ибо куда практичней использовать их как frp-переменные (get,set), которые сами умеют вычислять своё состояние (в том числе и асинхронно), поддерживать его актуальность и освобождать память, когда в них больше нет необходимости.
Простой пример: http://jsfiddle.net/aro1fc8n/4/
RubaXa
Простите, но мне вы путаете теплое с мягким, даже не буду говорить, что издревле есть соответствующий паттерн программирования, но да ладно. Допустим, на минутку, что я согласен с вами и «атомы» лучше, тогда покажите, как мне решить следующий пример на атомах:
По поводу примера. Ваш подход очень напоминает FRP, но лично для меня, выглядит очень перегруженным. На том же RxJS/BaconJS задача будет решаться проще, а главное понятнее для человека со стороны, который ничего не слышал о подобном подходе, а это немаловажно.
vintage
О каком паттерне идёт речь?
Примерно так:
var processedData = new $jin.atom.prop({ pull: prev => {
var data = resource.json( '/path/to' ).get()
// собственно процессим
return data
}})
И далее, где потребуется:
processedData.get()
А если не потребуется, то и запроса не будет. При этом неперехваченные ошибки будут залогированы автоматом.
У меня встречный вопрос — легко ли вам будет реализовать параллельную подгрузку двух файлов и третьего, если включена соответствующая опция конфига, а если выключена, то при включении, чтобы подгрузились лишь недостающие данные? На атомах можно не задумываясь:
var mapInfo = new $jin.atom.prop({ pull: prev => {
var [ svg, regions, stat ] = $jin.atom.get([
resource.xml( 'map.svg' ),
resource.json( 'regions.json' ),
config.isStatsShowing().get()? resource.csv( 'stats.csv' ): null
])
// работаем с полученными данными
}})
И это frp и есть, а вот подход Rx/Bacon — совсем не frp. Подробности в продолжении: http://habrahabr.ru/post/240773/
RubaXa
Эээ, вот:
и задумываться не пришлось, а ведь всё это только на native api, который будет понятен каждому разработчику.
За статью спасибо, добротно написано. Но всё равно не понимаю, зачем из простого делать сложное, т.е. идея мне понятна, я вижу где её можно было бы применить, но в итоге и в тех местах всё решается через банальную подписку на события. Ну и отладка такого приложения будет то ещё веселей, хотя и с Обещаниями не всё так радужно, как хотелось бы, но всё же браузер меня предупредит о непойманном catch.
В моем понимании, технология/подход должны делать разработку проще, код легко читаемым и интуитивно понятным. Но смотря на подобные примеры, из серии «вывести координаты», я не понимаю зачем мне это, какую задачу пытался решить автор.
Я понимаю, мне хотят показать что-то большее, но увы, вижу только переусложнение.
vintage
Ваш код работает неправильно:
1. конфиг — это свойство пользователя, хранится в профиле, его тоже нужно асинхронно подгрузить (как нужно изменить код, чтобы добавить тут асинхронность? в случае атомов код использования конфига не поменяется), причём так как меняется он редко, то имеет смысл брать его из localStorage и в фоне подгрузив новую версию налету обновить приложение (с атомами опять же этот код не поменяется — изменится лишь реализация isStatsShowing)
2. когда конфиг изменится этот код у вас не будет перезапущен
3. даже если будете кидать событие и по нему перезапускать все такие цепочки, которые зависят от конфига, то у вас всё равно будет 3 запроса, вместо одного и скорее всего обновление состояния половины приложения
В том-то и дело, что атомы инкапсулируют сложность событийной системы в простой абстракции — реактивный контейнер с формулой вычисления значения. Достаточно в ней разобраться (а она весьма не сложная) и можно строить приложения любой сложности без экспоненциального увеличения багоёмкости (как из кубиков лего). Да, на простых примерах атомы не нужны. Об этом собственно и первая статья — по мере взросления приложения оно обрастает грудой костылей. Появляется необходимость кэшировать, вручную следить за необходимыми подписками, бороться с утечками, обновлять только то, что реально могло поменяться (и речь тут не только про дом).
Я могу и более реальный пример привести, с выделением абстрактных компонент, точечным изменением дома, автоматическими анимациями, лёгкой адаптацией под новые требования: https://github.com/nin-jin/pms-jin2/tree/master/demo/list
Но его же фиг поймёшь, не разобравшись в основах на простом примере.
RubaXa
Эээ, так не пойдет, условие задачи я выполнил, но оказывается, они намного объемнее и ваш пример имеем очень высокий уровень абстракции. Давайте лучше вы сделаете реально пример этой задачи на jsbin.com (значение конфига можно меня по клику по кнопке), а я сделаю точно такой-же, но так, как делал бы его обычно. Мне так было бы намного проще понять ваш подход.
vintage
Ну так оно часто так и оказывается, что задача куда объёмнее, чем кажется на первый взгляд :-)
Ок, вот небольшой пример: http://jsfiddle.net/1y10hpgs/3/
При переключении настройки происходит либо догрузка недостающих данных, либо выгрузка ненужных.
RubaXa
Будем честными, чаще это оговорено в условиях, что конкретное место должно реагировать на изменения, чаще такие места просто каскадно обновляют в зависимости от других факторов. Да, конечно, всегда можно разработать решение, которое будет всегда реагировать на все изменения, но нужно ли это? Возьмем пример из жизни: Ангуляр (да, я понимаю что это из другой области, но) по умолчанию реагировал на любые изменения, это стало его прорывом и проклятьем, очень быстро люди, а потом уже разработчики, поняли, что нужен контроль над этим механизмом и ввели одноразовые связки.
Реактивность выглядит очень круто и выводит разработку на новый уровень, но какой ценой? Оверхед космический.
По поводу примера. Подобная задача у нас решалась бы подобным образом (увы в действии могу только видео показать, т.к. это не open source). Я понимаю, что сейчас вы можете указать на различия и усложнить условия, но поверьте, всё нормально «ляжет», просто разные подходы, у нас этого продвинутые модели и коллекции.
У меня к вам ещё один вопрос, допустим есть список, который нужно перерисовывать только при добавлении и удалении элемента, если элемент изменился, то нужно обновить только связанный элемент. Как такая задача будет решаться при помощи атомов? Как я понимаю, родительский атом, который строит список по любому получит сигнал, что внутри кто-то обновился и цепочка таких нотификаций может быть очень длинной, что даст оверхед. Не думали что делать в таких ситуация?
vintage
Нет, Ангуляр именно из этой области, просто в Ангуляре бестолковая реализация frp. Чтобы узнать изменилось ли что ангуляру приходится в цикле исполнять все вотчеры. Фактически это пересчёт всего состояния приложения. Из-за такой реализации приходится минимизировать число вотчеров (в частности используя одноразовые биндинги) и максимально локализовывать обновления (например, не вызывать $timeout, а вручную дёргать те скоупы изменения в которых ожидаются). С атомами такой проблемы нет — они максимально эффективно уведомляют друг друга об изменениях, так что спящие атомы кушать не просят (но создание их большого числа не бесплатно, так что и увлекаться ими не стоит, например, разумно выделять на один дом узел не более 1-2 атомов).
Что-то я не смог разобраться в вашем интуитивно понятном коде, тупой я наверное :-)
Обсуждали обещания, стримы, а в коде ни того, ни другого.
Да и функционал не повторили (нет загрузки настроек, нет очистки памяти).
Ещё и программный код в шаблонах, фу-фу-фу :-)
Нет, атом, хранящий список, ничего не знает про состояние элементов списка, если, конечно, сам список не зависит от их состояния. Например, если у нас есть список задач (tasks) и есть список задач отсортированный по названию (sortedTasks), то второй список зависит как от исходного списка задач (tasks) так и от имён (task.name) входящих в него задач, но не зависит от имён задач в список (tasks) не входящий и не зависит от времени создания (task.created) задач. Но стоит включить сортировку по времени создания, как зависимости обновятся и отсортированный список (sortedTasks) будет уже зависеть от исходного списка задач (tasks) и их времени создания (task.created), но не от имён (task.name). При этом сам исходный список (tasks) может зависеть, например, от вебсокет канала «tasks/creator=me» и совершенно не зависеть от состояния самих задач.
Если открыть пример: http://nin-jin.github.io/demo/list/
Включить логирование: $jin2_log_filter=/./
И, например, поскроллить правый список, то можно заметить, что пересчёт идёт по кратчайшему пути:
$jin2_demo_list_app.widget_all.widgetByLetter_.scrollTop_ 40 — изменилась позиция скроллинга
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.offsetTopView_ 40 — изменилась позиция плашки группы «А»
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.version_ 1 — обновилось состояние дом-узла плашки группы «А»
RubaXa
Путь то может и кратчайший, а вот числа говорят сами за себя: dl.dropboxusercontent.com/s/snwhpszlck3sxel/Screenshot%202015-11-29%2020.07.37.png?dl=0
И это с учетом, что вас там используются спец. абстракции над элементами, списком, строкой и т.д. Не скажу, что это уже слишком большие числа, ожидал более существенной просадки. Но, если учесть кол-во кода, который это всё обслуживает и использование специализированных компонентов под задачу, все это как-то не радужно выглядит. Это всё напоминает путь ExtJS и подобных, у него есть свои плюсы и минусы, но в массы его не вывести.
Но спасибо за ликбез.
P.S. О, ещё один маленький вопрос, при разработке атомов вы пытались найти что-то подобное? Какие ещё есть решения? По ключевым словам frp только Bacon, Rx, Kefir и т.п., а вот подобного нет (максимум видел статью, которая в общих чертах описывала реализацию в Метеор).
vintage
В данном случае путь не кратчайший. Если включить логи, то можно заметить, что происходит пересчёт всех списков. Чтобы этого не происходило, нужно использовать для списков специальные атомы (о которых во второй статье в конце).
Там используется наследование компонент, чтобы продемонстрировать расширяемость — можно взять готовую компоненту и изменить любой аспект её поведения. Конечно можно было бы и вообще всё приложение в одну компоненту засунуть в «лучших» традициях ангуляра :-)
KnockoutJS — ближайший аналог атомов, только с крайне неэффективным распространением изменений и без поддержки прототипного наследования, обещаний, автоуничтожения и пр.
Aetet
А я вот одного не пойму, откуда в атомах буква F? Сколько не смотрел нигде этой буквы не увидел. Для многих она значит — отсутствие сайд-эффектов, во время вызова функций, но ведь атомы это и есть один большой сайд-эффект, разве нет?
Плюс запись
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.version_ 1
Явный признак нарушения закона деметры.
vintage
Атомы инкапсулируют в себе сайд эффекты. Ну, на сколько это возможно в императивном языке. Можно считать их монадами :-)
Не нарушает, компонента $jin2_demo_list_app владеет компонентой widget_all, которая владеет компонентой widgetByLetter_, которая владеет компонентой rowGroup_A, которая владеет атомом version_. При этом путь до объекта собирается путём склеивания идентификатора объекта и пути до властвующего над ним объекта. Это очень удобно иметь в идентификаторах элементов, логах и множествах такие пути :-)
https://habrastorage.org/files/2c6/8f4/252/2c68f4252fc84433bd1214bad03bb550.png