

Продолжение о базе данных и деплое во второй статье.
Я начинаю публиковать серию статей о веб-разработке на Эрланге. Многие хотят попробовать Эрланг, но сталкиваются с проблемой, что вводные курсы в основном касаются Эрланга как функционального языка и далеки от реальных проектов (Learn You Some Erlang for great good! — хорошая и подробная книга). С другой стороны все обучающие материалы по веб-разработке подразумевают, что читатель уже хорошо знает Эрланг.
Эта серия статей рассчитана для разработчиков, у которых есть опыт в веб-разработке (PHP, Ruby, Java), но не имеют опыта разработки на Эрланге.
Задачей будет сделать блог. Код из статей https://github.com/denys-potapov/n2o-blog-example, готовый проект можно посмотреть по адресу http://46.101.118.21:8001/. Особенности проекта:
- обновление комментариев в реальном времени;
- авторизация через фейсбук;
- данные храним в mnesia.
В основе проекта феймворк n2o. Выбор довольно субъективен, но из живых Эрланг фреймворков, n2o мне показался наиболее «эрлангоподобным», в тоже время ChicagoBoss больше похож на MVC фреймворки в других языках.
Настраиваем окружение
Я буду настраивать окружение в Ubuntu, но схожим образом должно работать и в других ОС. Скачиваем и устанавливаем актуальную версию эрланга www.erlang-solutions.com/resources/download.html.
Менеджер зависимостей
Стандартный менеджер зависимостей в Эрланге — rebar. Но, в данной статье мы будем использовать mad от создателей n2o, который совместим с rebar конфигурацией, работает быстрее и позволяет отслеживать изменения в шаблонах.
curl -fsSL https://raw.github.com/synrc/mad/master/mad > mad
chmod +x mad
sudo cp mad /usr/local/bin/
Для отслеживание изменений файлов mad требует установки inotify-tools:
sudo apt-get install inotify-tools
Генерируем костяк приложения и запускаем его:
mad app "blog"
cd blog
mad deps compile plan repl
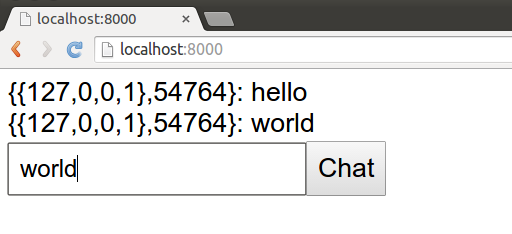
По адресу http://localhost:8001/ открывается чат, который обновляется по вебсокету в реальном времени, и можно переписываться самому с собой из разных окон.
Параметры mad отвечают за получение зависимостей и запуск приложения:
- deps — получить зависимости;
- compile — скомпилировать приложение;
- plan — создать план запуска;
- repl — запустить консоль.
Структура проекта
Структура файлов нашего проекта стандартная для Эрланг приложений:
+-- apps
+-- rebar.config
L-- sample
+-- ebin
¦ +-- ...
+-- priv
¦ +-- static
¦ ¦ ...
¦ L-- templates
¦ L-- index.html
+-- rebar.config
L-- src
+-- index.erl
+-- routes.erl
+-- sample.app.src
L-- sample.erl
+-- deps
+-- rebar.config
L-- sys.config
Подробно о структуре можно почитать в официальной документации.
Позже мы познакомимся практически со всеми файлами и папками, а пока нам надо знать, что Эрланг приложение обычно состоит из нескольких приложений, которые лежат в папке apps. У нас там одно приложение sample, в котором:
- src — исходный код;
- ebin — скомпилированные файлы;
- priv — остальные файлы проекта, в данном случае шаблоны и статика;
- index.erl — заглавная страница.
Первый код
Удалим ненужные файлы:
rm -r apps/sample/priv/static/
Для шаблонов мы используем ErlyDTL, реализацию Django Template Language на эрланге. Поэтому синтаксис будет понятен тем, кто знаком с Django-подобными шаблонизаторами (Django, Twig, Mustache).
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>{% block title %}Erlang blog example{% endblock %}</title>
<!-- Bootstrap -->
<link href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.5/css/bootstrap.min.css" rel="stylesheet">
<!-- HTML5 shim and Respond.js for IE8 support of HTML5 elements and media queries -->
<!-- WARNING: Respond.js doesn't work if you view the page via file:// -->
<!--[if lt IE 9]>
<script src="//oss.maxcdn.com/html5shiv/3.7.2/html5shiv.min.js"></script>
<script src="//oss.maxcdn.com/respond/1.4.2/respond.min.js"></script>
<![endif]-->
<style>
.container {
max-width: 40em;
}
</style>
</head>
<body>
<div class="container">
{% block content %}{% endblock %}
</div>
<script src="//ajax.googleapis.com/ajax/libs/jquery/1.11.3/jquery.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.5/js/bootstrap.min.js"></script>
</body>
</html>
apps/sample/priv/templates/index.html
{% extends "base.html" %}
{% block title %}Latest posts{% endblock %}
{% block content %}
<h1>Latest posts</h1>
{{ posts }}
{% endblock %}
Теперь откроем index.erl и заменим код на такой:
-module(index).
-compile(export_all).
-include_lib("n2o/include/wf.hrl").
-include_lib("nitro/include/nitro.hrl").
main() -> #dtl{file="index"}.
В заголовке файла мы объявляем модуль, указываем, что мы экспортируем все функции из этого модуля, и подключаем два заголовочных файла.
Функция main/1 вызывается при открытии главной страницы. Функции могут возвращать или сразу HTML, или DSL Эрланг записи, о которых мы поговорим позже. Пока мы просто возвращаем отрендеренный шаблон index. В документации к Эрлангу функции всегда пишутся как название/кратность, где кратность — количество аргументов.
Знакомимся с синтаксисом
Сейчас самое время ознакомиться с основами синтаксиса, это быстрее всего сделать на www.tryerlang.org. Мы выведем на главной странице все посты. Пока не будем использовать БД, а будем хранить посты прямо в коде.
В заголовочном файле /apps/sample/include/records.hrl опишем запись для хранения постов:
-record(post, {id, title, text, author}).
Создадим модуль /apps/sample/src/posts.erl для хранения постов. Модуль экспортирует две функции: get/0 — возвращает все посты, а get/1 — возвращает пост по Id:
-module(posts).
-export([get/0, get/1]).
-include("records.hrl").
get() -> [
#post{id=1, title="first post", text="interesting text"},
#post{id=2, title="second post", text="not interesting text"},
#post{id=3, title="third post", text="very interesting text"}
].
get(Id) -> lists:keyfind(Id, #post.id, ?MODULE:get()).
Записи в Эрланге — это синтаксический сахар, компилятор заменит записи на кортежи, а поля на индексы. Например #post.id будет заменен на 0.
DSL
Выше я писал, что функции могут возвращать Эрланг записи, которые преобразуются в HTML. Изменим наш index.erl, чтобы на странице выводился список всех постов:
-module(index).
-compile(export_all).
-include_lib("n2o/include/wf.hrl").
-include_lib("nitro/include/nitro.hrl").
-include_lib("records.hrl").
posts() -> [
#panel{body=[
#h2{body = #link{body = P#post.title, url = "/post?id=" ++ wf:to_list(P#post.id)}},
#p{body = P#post.text}
]} || P <- posts:get()].
main() -> #dtl{file="index", bindings=[{posts, posts()}]}.
Для создания страницы поста, мы в /apps/sample/src/routes.erl указываем, какой модуль будет обрабатывать наш путь:
route(<<"post">>) -> post;
Модуль apps/sample/src/post.erl просто выводит шаблон с данными поста:
модуль
-module(post).
-compile(export_all).
-include_lib("n2o/include/wf.hrl").
-include_lib("records.hrl").
main() ->
{Id, _} = string:to_integer(binary_to_list(wf:q(<<"id">>))),
Post = posts:get(Id),
#dtl{file="post", bindings=[{title, Post#post.title}, {text, Post#post.text}]}.
Шаблон:
{% extends "base.html" %}
{% block title %}{{ title }}{% endblock %}
{% block content %}
<h1>{{ title }}<br />
<small>by {{ author }}</small>
<p>{{ text }}</p>
<h3>Comments</h3>
{{ comments }}
{% endblock %}
Вебсокеты
Теперь мы подошли к самому интересному, а именно связи браузера с сервером по вебсокету. Мы сделаем комментарии к посту, которые будут обновляться в реальном времени. Для этого в базовый шаблон добавим библиотеки инициализации n2o:
<script>{{script}}</script>
<script src='/n2o/protocols/bert.js'></script>
<script src='/n2o/protocols/client.js'></script>
<script src='/n2o/protocols/nitrogen.js'></script>
<script src='/n2o/validation.js'></script>
<script src='/n2o/bullet.js'></script>
<script src='/n2o/utf8.js'></script>
<script src='/n2o/template.js'></script>
<script src='/n2o/n2o.js'></script>
<script>protos = [ $bert, $client ]; N2O_start();</script>
А в модуле post.erl добавим обработчик события и код для вывода комментариев:
main() ->
Id = wf:to_integer(wf:q(<<"id">>)),
Post = posts:get(Id),
#dtl{file="post", bindings=[{title, Post#post.title}, {text, Post#post.text}, {comments, comments()}]}.
comments() ->
[#textarea{id=comment, class=["form-control"], rows=3},
#button{id=send, class=["btn", "btn-default"], body="Post comment",postback=comment,source=[comment]} ].
event(comment) ->
wf:insert_bottom(comments, #blockquote{body = #p{body = wf:html_encode(wf:q(comment))}}).
При выводе кнопки, мы указываем, какое событие будет вызвано (postback) и какие параметры надо передать на сервер (source). В функции event(comment) мы отправляем клиенту код, чтобы добавить комментарий внизу списка. Пока этот комментарий не попадает к другим клиентам, но сейчас мы это исправим:
event(init) ->
wf:reg({post, post_id()});
event(comment) ->
wf:send({post, post_id()}, {client, wf:q(comment)});
event({client, Text}) ->
wf:insert_bottom(comments, #blockquote{body = #p{body = wf:html_encode(Text)}}).
Событие init, вызывается в момент загрузки страницы, и мы регистрируем наш процесс, что он будет получать сообщения из пула {post, post_id()}.
Вместо вывода комментария в событии event(comment), мы посылаем сообщение с новым комментарием в пул. А вывод комментария делаем в обработчике event({client, Text}). Теперь мы можем весело переписываться в чате под постом, и почти повторили код, который сгенерировал mad как костяк приложения.
В следующей статье мы будем хранить посты и комментарии в БД, и добавим авторизацию через фейсбук.
Комментарии (101)

loz
25.12.2015 00:31+6Плохая типизация в Эрланге сводит веб-программирование к написанию огромного количества кодирующего / декодирующего кода. Из формата бд в эрланговый, из эрлангового в json и тд и обратно. Получается мало универсальности и много эвристик.
Из моего опыта — код выходит намного проще, если избавиться от DTL-шаблонов, и сделать REST API с, например, ReactJS. И универсальнее, и JS как язык намного гибче.
gBear
25.12.2015 02:19+8Плохая типизация в Эрланге ...
Чего?!
… JS как язык намного гибче.
Вы, «либо крестик снимите, либо штаны наденьте» (с)

Grunya_404
25.12.2015 03:16-1эрланг намного сложнее в восприятии для веб разработчиков, чем более нативные для них *JS,php, да тот же go куда дружелюбней.
Я вот понимая всю мощь эрланга, даже не представляю для чего же эдакого может применяться такой монстр в веб проектах? расскажите подробней…
А главное как его применение обоснованно именно в архитиктурно-эксплуатационном плане, и экономически вписано в проект. Ведь разрабов пишущих эрланге, как амурских тигров, почти нет. И стоит эта разработка не мало.nwalker
25.12.2015 04:52+9Disclaimer: мой ответ может показаться чересчур восторженным, но у меня на часах почти 5 утра и я не сильно хочу заморачиваться избыточными уточнениями.
> для чего же эдакого может применяться такой монстр в веб проектах
Основной профит эрланга — можно не заморачиваясь писать сомнительный(запросы в сеть, в фс, ожидание сторонних процессов) код прямо в коде обработки пользовательских запросов и все будет ништяк, рантайм все честно разрулит, вся система не упорется(ну если только вся ОС). Пара акторов умрет в худшем случае, ну и черт с ними, все остальные продолжат работать, а в логах останется информация к размышлению — и это все из коробки, вместе с вылизанным за годы рантаймом.
Одна кодовая база и общее адресное пространство для request-responce и long living connections, in-process кэши и очереди задач и прочие подобные мелкие удобства ощутимо меняют жизнь и процесс разработки. Волосы реально становятся мягкими и шелковистыми.
Но тем не менее — не стоит писать на эрланге что-то, для чего вам хватит голого Rails. Вот когда вам захочется переписать свой код на Go, потому что вам не хватает вашего application server с блокировками воркеров на запросы в отдельные сервисы — вот тогда вот тогда очень внимательно и вдумчиво посмотрите на Erlang.
> Ведь разрабов пишущих эрланге, как амурских тигров, почти нет.
Ну, с этим сложно спорить. С другой стороны, толковых людей вообще мало и проблема скорее в этом, чем в языке.
А так эрланг очень простой. «Эрланг учится за две недели, за год можно выучить до 26 эрлангов.»
Тот же go активно продают простотой — а ведь go сильно сложнее.
BTW, IMHO, язык вообще не должен рассматриваться как проблема при поиске людей, кроме совсем запущенных случаев, вроде C++ или Scala+scalaz или Haskell, или еще чего-то в том же духе. В адекватном случае человек будет дольше вникать в проблематику проекта, язык — малая доля проблем при налаженном рабочем процессе.
> И стоит эта разработка не мало.
Вот тут мне сложно судить объективно, у меня всяческий positive bias — я уже три года пишу почти на чистом э-ге, изредка на go и python.
Да, наверное, выходит несколько дороже, но выхлоп сильно больше. Я сомневаюсь, что то, у нас есть, было бы сделано за то же время и столь же работоспособным, если бы мы не взяли эрланг со старта.
Ну и да, привет whatsapp и его 35(или 50?..) инженерам на дохреналион пользователей.
> да тот же go куда дружелюбней.
Ну вот не надо, а. Erlang очень простой, если не сказать топорный, язык, только выглядит страшно. Сильно проще Go и, кстати, не пытается прятать незнакомую семантику под внешне знакомым синтаксисом.
Реально, в эрланге есть 2.5 вещи, которые нужно понять — pattern matching, processes — акторы, high-order functions. Дальше познакомиться с application/supervisor/gen_server из OTP, усвоить meta code style — как вообще писать на языке без переменных, и можно хуяк-хуяк в продакшн.
Если кому-то хочется синтаксического сахарка — есть хипстерский и набирающий моду сейчас Elixir, есть питонообразный Efene, есть лиспы — lfe(который я не люблю, потому что он common lisp, а не clojure) и joxa(который, увы, заброшен). Если хочется метапрограммирования — в Elixir и lfe есть вполне пристойные макросы.
Go реально выигрывает только в двух вещах — статические бинарники дают простоту деплоймента, плюс там есть нормальные строки. Ну, и в его рантайме можно разобраться за считанные дни. И то, первый аргумент нивелируется отказом от релизов в Erlang-проекте, без них можно сделать достаточно простыми деплоймент и конфигурацию.Biggo
25.12.2015 09:17Одна кодовая база и общее адресное пространство для request-responce и long living connections, in-process кэши и очереди задач и прочие подобные мелкие удобства ощутимо меняют жизнь и процесс разработки. Волосы реально становятся мягкими и шелковистыми.
Тоже самое можно сказать про Go, при этом вы верно заметили, что он дает статические бинарники. А это серьезная такая плюшка.gBear
25.12.2015 13:18+3«Даладно!?» (с)
Я когда hot code swap в Go увидел — ржал в голос. Действительно «одна кодовая база». Чего уж тут.
А в «статические бинарники» erlang умел еще тогда, когда это не было модно для VM. Вы просто, судя по всему, не в курсе. А сейчас к ним еще и NiF добавились.
Go — он все таки несколько из другой песочницы :-)
Не вам… но, чтоб два раза не вставать.
Про «дорого» и т.п.: знаю проект, где есть свой AMQP брокер написанный с нуля _одним_ человеком чуть более чем за месяц. До того как взяться за эту задачу, конкретно с erlang'ом он был знаком около полугода. В отрасли, правда, к тому моменту уже был более пяти лет — т.е. к моменту перехода на erlang (с «плюсов», ага...) он был уже вполне себе зрелым разработчиком. Там был выбор… или допиливать «под себя» qpid, или таки писать свой брокер («кролик», в те времена, еще только становился на ноги ...). «Допиливать» qpid — желания как-то не возникло :-)
Про «трудно воспринимается» и т.п.: не знаю (хотя это и мало о чем говорит) ни одного зрелого разработчика (со стажем 5+ лет), который бы после перехода на erlang, _добровольно_ с него слез. А вот то, что после «заражения» — код, который «не влезает на экран» — реально «трудно воспринимать» — прекрасно знаю по себе, например :-)
nwalker
25.12.2015 15:58Да, серьезная, но единственный чисто эксплуатационный критерий, в котором go выигрывает. И то, это не окончательное решение вопроса доставки приложения в продакшн.
Если у вас, скажем, сервис запускается в docker-контейнере, какая вам разница, там внутри бинарник или снапшот кода из репозитория?
Я все думаю написать сравнительный пост про эксплуатационные качества э-га и go, руки не доходят.
merc
26.12.2015 02:28Расскажите про деплой эрланга.
С го то много не придумаешь, максимум билд в одном докер контейнере, копирование бинарника в другой (пустой) контейнер.
А с эрлангом немного сложнее как я понимаю.nwalker
26.12.2015 04:15+1У меня все просто, слизано с flussonic Макса Лапшина( erlyvideo ). Релизы не используются. Версии подкладывает rebar_vsn_plugin из тегов git. Сборка — rebar + make. В мейкфайле руками прописана некоторая часть зависимостей, типа app: lager_parse_transform_beam, для удобства.
На продакшн код попадает в deb-е, в котором file layout не отличается от версии разработчика, как оно лежит в git, но все уже заранее скомпилировано. У deb-а прописаны dependencies от esl-erlang и пакетов, требуемых для нативного кода — портов, nif, каких-то скриптов. В postinst-скрипте деба делается какая-то конфигурация — пользователь, права на директории.
Запускается приложение через run_erl под upstart — вот это на самом деле очень сложный в отладке момент, по возможности копируется из другого проекта. =)
Запуск — есть модуль с функцией start/0, в ней мы читаем конфиг — свой, не sys.config, если он плохой — валимся с каким-то вменяемым сообщением об ошибке. На основе этого своего конфига генерятся в коде конфиги приложений, от которых зависим — lager, jobs, свои приложения, кладутся в application env соответственные. В конце start запускаются otp приложения, по возможности через application:ensure_all_started(my_app) и дергается my_app:apply_config, который уже раскидает отдельные элементы env-а по подсистемам, говоря им «вот новый конфиг, примени его к себе». Да, со структурой supervision tree могут быть некоторые неудобства, но я с ними не сталкивался, у меня эта структура достаточно фиксированная.
Если очень хочется, вместо нормальной файловой структуры можно запилит один большой escript со всеми модулями и автораспаковкой прочих файлов в /tmp, но я от этого отказался — совсем уж убивает удобства от hot reload, когда хочется/нужно на скорую руку что-то поправить. В принципе, это можно попробовать делать ради самодисциплины, чтобы руки не тянулись патчить продакшн на горячую.
Флаги эмулятора типа +sbt или -name у меня захардкожены в точке запуска, но есть и варианты получше — vm.args, какой-то другой конфиг, unix env.
Много инстансов одного приложения на одной системе поднимать мне не приходилось, готовых вариантов пока нет.
Обязательно в пакете shell-скрипт, который сделает remsh в ноду приложения.
Проблем с множественными epmd у меня не было; в случае возникновения можно отдельным дебом ставить eclus — это версия epmd на go без зависимостей, и поднимать его upstart-ом до первого erlang-сервиса. По меньшей мере, как-то так мне это видится, я пока не пробовал.
Докера в продакшне у меня пока нет; в теории там могут возникнуть какие-то нюансы, типа коллизий имен нод, я их еще не продумывал. В остальном все примерно так же, либо берем докер-образ с апстартом внутри, либо просто корнем контейнера запускаем наш враппер над run_erl erl…
Да, это все абсолютная ересь по меркам «каноничной» erlang-разработки, но меня вполне устраивает.erlyvideo
26.12.2015 11:56каноничная эрланг разработка — это ересь по меркам юникса.
Отсутствие возможности в форграунде провалидировать конфиг, наличие рабочего экземпляра и потом уже демонизироваться — это всё доводит админов до истерики.nwalker
26.12.2015 23:02С конфигами это отдельная больная тема. Вообще, хранить в файле конфигурации сырой снапшот внутреннего представления, как это делается в каноничном app.config — это какой-то кромешный ужас.
Не, я понимаю, откуда оно взялось такое решение, но на сегодняшний день это не выглядит пригодным к широкому использованию.erlyvideo
27.12.2015 10:21app.config кошмарен не только своей сущностью, а ещё и той маниакальной настойчивостью, с которой его защищают.
Ты видел наши конфиги:
{vhosts, [ {cdn1, [ {hostname, "cdn1.com"}, {streams, [ {ort, [ {urls, [ {"rtmp://upstream1.com/ort", [{appUrl, "lalala.com"}]} ]} ]} ]} ]} ]}.
Но это я так записал, а юзеры то пишут:
{vhosts, [ {cdn1, [{hostname, "cdn1.com"},{streams, [{ort, [{urls, [{"rtmp://upstream1.com/ort", [{appUrl, "lalala.com"}]}]}]}]}]}]}.
и потом спрашивают, как им сбалансировать}]}]}]}]}]}]}.
А никак =)
Потому и самодельный формат конфига.
erlyvideo
26.12.2015 17:31я более того скажу: мы ещё и зависимости все в гит залили и выкинули к хренам управление их версиями.
И так удобно стало!nwalker
26.12.2015 19:49Ну, на мой вкус это уже чересчур радикально — впрочем, твоя разработка, тебе виднее.
У меня просто прибиты коммиты или теги в ребаре, мне так нормально.erlyvideo
27.12.2015 10:17как часто ты делаешь git bisect?
А как часто у тебя ребар брал и решал, что версия суб зависимости важнее, чем корневая зависимость и продакшн билд разваливался на куски?nwalker
27.12.2015 20:12+1Я, честно говоря, вообще ни разу не сталкивался с коллизиями версий зависимостей у rebar.
Везло мне, чтоли.erlyvideo
28.12.2015 13:23lager, lhttpc, jsx. У нас свои правки к ним и становится больно, когда делаешь get-deps

elimoon
02.01.2016 08:35+1С mix-ом пишешь у зависимости:
override: true
И он скачивает ту зависимость, которая тебе нужна. Не представляете, как легко стало решить все конфликты при включении даже такого dependency hell, как riak_core в elixir проект… Эти проблемы mix решает прекрасно.

UA3MQJ
25.12.2015 16:22Я периодически пишу для себя на Erlang. Причем с большими перерывами. И по прошествии времени, хочу сказать, что да, первое время Erlang отрывает башку. Но теперь я его вижу действиельно, как топор. Очень простой. Сущностей и понятий, в действительности, там мало.
Но решил я тут немного узнать про Go, но как-то не пошло. Еще мне посоветовали многообещающий Rust. Начал читать какие-то кучи… Вот надо в ерланге кучу — создаешь процесс и она варится в нем, а невозможность одновременной записи будет решена очередью сообщений. Но в принципе, могу понять, для производительности можно пережить эти типы указателей (будем считать, что если с этим работать, то все поймется и запомнится). Потом в той же статье дошел до обмена сообщениями между процессами через потоки!!! Но то, что для отправки нужно создать один поток, для приема другой. Уж не говоря о том, что это не нативно языковое и выглядит очень громоздко. Но мне показалось это все каким-то очень неудобным. Даже вот чисто логически. У каждого процесса получается указатель на поток с другим процессом. Зачем это? Если у процесса Erlang есть Pid другого процесса, то он может отправить ему сообщение. А тот может ему ответить. А куда? В сообщении просто указывается Pid с обратным адресом. Просто, понятно и надежно. Никаких тебе ненужных сущностей не создается и работает, даже если Pid на другой машине в кластере. А если мы создадим несколько воркеров, которые будут отдавать ответы одному процессу — у него на каждого будет поток? Надеюсь, там есть что-то иное, для решения этого вопроса.
В общем, так и не впечатлили меня языки, появившиеся несколько лет назад, на фоне Erlang'а. Причем чем дальше, и чем больше я пишу, допустим, какие-то свои костыли, на каком-нибудь vbs, то все больше проникаюсь продуманностью Erlang. Это просто годы разработки и опыт применения, с ними сложно бороться.
Однако, не стоит думать, что мне вообще все не нравится. Сталкивался я с python — работать понравилось. Сейчас работаю с AngularJS — ну тоже не без своих нюансов, но в целом положительные впечатления.nwalker
25.12.2015 21:06+1Rust это вообще не для нас. Rust решает проблемы людей, которые пишут на C/C++. Зачем его пытаются тащить в веб-дев, мне непонятно.
> обмена сообщениями между процессами через потоки
Это отдельная тема, CSP против акторов. Тут, кстати, есть забавный нюанс — в статически типизированных языках CSP выражается гораздо проще, мы просто делаем Channel и используем их везде, хотя это и повышает когнитивную нагрузку на разработчика. «receive» актора в этом плане гораздо более нетривиальная штука.
> А если мы создадим несколько воркеров, которые будут отдавать ответы одному процессу — у него на каждого будет поток?
По идее, для many-to-one должно быть возможно обойтись одним каналом. Но это уже зависит от реализации.
> работает, даже если Pid на другой машине в кластере.
До определенного момента работает. Изкоробочный interconnect штука не такая уж и простая, со своими подводными камнями. Впрочем, об этом я только слышал, сам не сталкивался. Детали нужно спрашивать у людей посерьезнее меня.

matiouchkine
29.12.2015 10:58+1> Если хочется метапрограммирования — в Elixir и lfe есть вполне пристойные макросы.
Основное, чем меня лично полностью покорил Elixir — это то, что макросы в нем — нативный AST. Буквально, без уточнений и ссылок мелким шрифтом. Поэтому макросы не добавляют инструкций процессора (классический пример — отладочный логгер, который в продакшн версии просто отсутствует; на C так можно было сделать с помощью `if 0`, но отсюда до прямого управления AST в compile-time — как до луны).
Так LISP же ж))), скажут мне, но нет: писать сразу все на AST довольно утомительно.
В общем, для сомневающихся: есть прекрасныя книга автора http://phoenixframework.org Криса Мак Корда «Metaprogramming Elixir» может прямо глаза открыть и заставить хохотать с «простоты» современных хипстерских языков. Плюс нативная поддержка кода на эрланге без допольнительных декораторов и — конечно — OTP.gBear
29.12.2015 13:44классический пример — отладочный логгер, который в продакшн версии просто отсутствует
Кстати, вот тут бывшие коллеги начали выкладывать в open source свои наработки (в том числе, и логгер). Каюсь, к некоторым вещам, таки причастен :-)
Поэтому остальное под спойлер ...Их логгер. Написан лет пять назад… если не раньше. Умеет много чего, в том числе и в «отсутствовать в продакшн»… а когда надо — «таки, снова быть». Само собой, без каких либо остановок ноды.
Написан «вокруг» своей же либы (pt_lib) для «облегчения» parse transormation. Если кто до этого баловался своими pt модулями, может заценить «красивости», которые она вносит в нелегкое это дело.
Отдельно, наверное, надо упомянуть спец. «логгер» для самих трансформаций. Может кому интересно будет.matiouchkine
29.12.2015 13:55Выглядит клёво. Но мы же понимаем, что вот это: https://github.com/eltex-ecss/pt_lib/blob/master/src/pt_patrol.erl#L87-L120 вообще-то попахивает, и именно от такого избавляет синтаксис Elixir, и я ровно про это написал.
Но вообще идея красивая и реализация на первый взгляд очень разумная.
gBear
29.12.2015 23:56Выглядит клёво. Но мы же понимаем, что вот это: github.com/eltex-ecss/pt_lib/blob/master/src/pt_patrol.erl#L87-L120 вообще-то попахивает, и именно от такого избавляет синтаксис Elixir, и я ровно про это написал.
Ну, так-то да :-) Вот только альтернатива — «глаза вырывает с кровью» (по первости, как раз пытались остаться в рамках оригинального синтаксиса), а без литералов — всё равно не обойтись. Но, оно на самом деле не так страшно все. Оно гигиенично и — насколько это возможно, конечно — валидируется (плюс, сам «патруль» сильно помогает при разборе полетов). К этой штуке, емнип, даже планировали «раскраску» в emacs прикрутить… но, «забили» за не надобностью… сами-то быстро втянулись :) Хотя, может быть сейчас уже сделали и это. А вот то, что доки по синтаксису этой «магии» не выложили — это я им отпишу. Возможно оно само по себе будет по интереснее, чем сам логгер.
А по поводу Элексировских макросов… тут важно понимать (я, правда, за Элексиром не слежу уже давно), что их макросы это именно _макросы_. Полного контроля над AST модуля — в отличие от pt, который позволяет вплоть до «взять все, и переписать с нуля» — они не дают (что, может быть и верно, для тех целей, что они перед собой ставили). Но, например, «нарисовать» на них какой-нибудь элегантный fun-trace — уже не получится. Ну, или я не понимаю как :-) И дело даже не в их эксплицитности… а в том, что это by design инструмент для построения DSL — «правильный», с цитированием и прочими «плюшками», но, не более того.matiouchkine
30.12.2015 11:15+1Вот да: доки были бы кстати, все-таки этот код немного не «как сделать свой первый бложег на эрланге» и про некоторые вещи хотелось бы пояснений и, особенно, кросс-ссылок. Хотя читается, должен признать, довольно легко (и приятно :).
Насчет макросов: макросы это макросы, я надеюсь, что я это понимаю. Trace, конечно, возможен: например, через @ before_compile, или напрямую с передачей имен модулей (и не нужно нарушать гигиену даже.) Я даже подумал некоторое время над тем, как можно через hygiene override отстрелить себе ногу, и, наверное, какого-нибудь монстра я и придумал бы (наподобие разобрать свой AST, запихнуть в Agent и потом невозбранно над ним тешиться откуда угодно), но тут мне приснился троллейбус и я проснулся.
Я далек от философии гоферов («мы настолько тупы, что язык от нас нужно защищать, чтобы мы не натворили глупостей»), но и зачем может потребоваться нагадить в чужой AST — мне тоже неочевидно. Ну, утрирую, да. Но все же. Я пока не сталкивался с тем, что мне не хватает макросов (которые все-таки не совсем макросы же, их лучше интерпретировать как солод первого отжима, это же просто код, который компилируется тем же компилятором, просто на первом проходе). Столкнусь — наверное, соглашусь.
Точнее, нет. Столкнусь — я импортирую ваш этот parse transformer и буду жить счастливо. Я тоже в молодости на каждый чих старался ассемблерную вставку пришпандорить, а сейчас понимаю, что есть очень специфические задачи, которые удобнее писать на низком уровне (опять реферанс в сторону трансформера) — ну так кто мешает, написал на низком и вернулся к своему _плюшевому_ синтаксису. Я же не говорю, что с появлением Elixir — эрланг надо выбросить (disclaimer: я не идиот).
Вот как-то так.
nwalker
29.12.2015 22:54Для справедивости отмечу, что «отладочный логгер, который в продакшн версии просто отсутствует» есть в lager уже очень давно без всяких макросов, на голом parse transform. В принципе, parse transform по функциональности недалеко ушли от макросов, просто менее удобны в использовании.
BTW, я считаю лисп хорошим, правильным, годным языком. Если хочешь нормальные макросы, тебе нужен лисп. Опять же, современный лисп может быть очень хорош и удобен, как показывает clojure.
Немного про макросы elixir и parse transform от Роберта Вирдинга, автора lfe — https://news.ycombinator.com/item?id=7623991erlyvideo
29.12.2015 22:57в log4erl была сделана максимально производительная штука: компиляция модуля на лету, отсекающая ненужные логгирования.
в лагере всё таки это поход в ets.
Но ни в одном логгере нет оборачивания аргументов в функцию для ленивого вычисленияnwalker
29.12.2015 23:09как-то я лажанулся.
мне казалось, он не только truncation в parse transform делает, но и лишние loglevel-ы режет. сейчас проверил — и вправду не режет.
> компиляция модуля на лету
он генерил модуль-dispatcher на основе конфигурации? если да, всецело одобряю.
вообще, на эту тему нужно поиграться с merl, но осторожно, чтобы не увлечься.
кстати, если я все правильно понимаю, протоколы elixir в develop mode работают так же.nwalker
29.12.2015 23:14ой, я вообще гоню. он в parse transform только получение метаданных подставляет и вызов lager:do_log генерит.
erlyvideo
30.12.2015 23:17нет, лагер вставляет очень жирный кусок кода, причем непонятно зачем.
Я сейчас начал насильную миграцию на свою инфраструктуру логгирования и в ней я только MODULE, FILE, LINE вставляю, остальное в рантайме добиваем.
elimoon
02.01.2016 19:26Такой код lager генерирует:
case {whereis(lager_event), lager_config:get(loglevel, {0, []})} of {undefined, _} -> fun () -> {error, lager_not_running} end(); {Pidtest10, {Leveltest10, __Tracestest10}} when __Leveltest10 band 64 /= 0 orelse __Tracestest10 /= [] -> lager:do_log(info, [{application, test}, {module, test}, {function, info}, {line, 10}, {pid, pid_to_list(self())}, {node, node()} | lager:md()], "info:~s", ["test"], 4096, 64, __Leveltest10, Tracestest10, Pidtest10); _ -> ok end.
из
lager:info("info:~s", ["test"])erlyvideo
02.01.2016 20:32мне совершенно непонятно, зачем его генерировать во время компиляции, когда стоило бы проверить как раз наличие лагера в рантайме.
matiouchkine
30.12.2015 12:17> я считаю лисп хорошим, правильным, годным языком
Язык очень годный, тут я абсолютно не спорю. Просто утомительный. С другой стороны, я прекрасно понимаю, что это уже разговор о вкусе фломастеров.
> если хочешь нормальные макросы, тебе нужен лисп
А вот перед кем в реальной жизни может встать задача «хочу нормальные макросы»? Я оперирую желаниями на более высоком уровне: «хочу решить вот эту задачу быстро и надежно». На макросах, не на макросах — мне совершенно все равно же. Я недавно утилиту небольшую на php написал просто потому, что библиотека, реализующая протокол, в выдаче гугла оказалось первой. Был бы там го, раст, си, жава, лисп, юнеймит — написал бы на них.
Даже в больших проектах, где выбор языка важен, наличие макросов как самоцель — неочевидна.
Ну а так-то я с вами согласен, разумеется.
P.S. А Вирдинг предвзят, мне кажется :)

bARmaleyKA
25.12.2015 23:34+1Ну как для чего эдакого? Вы когда по телефону мобильному говорите, голос не «виснет»? Так может быть и сайты перестанут тупить и виснуть.
loz
25.12.2015 11:51-3В эрланге плохая типизация, в JS типизация лучше, он гибче. Мне ничего не надо ни снимать, ни одевать.

bromzh
25.12.2015 12:14+2Нет уж, строгая типизация всяко лучше слабой. Неявные преобразования — зло.
loz
25.12.2015 12:28+2Я совершенно о другом. В эрланге нельзя создавать свои типы, нельзя отличить строку от списка, нельзя отличить дату / время от кортежа. Нельзя создавать свои типы. Это никак не связано с неявными преобразованиями.
gBear
25.12.2015 13:37В эрланге нельзя создавать свои типы...
?!
:-D
Понимаете… фактически, вы сейчас пытаетесь меня убедить, например, в том, что в erlang нельзя писать собственный ф-ции. Ага :-)
Что такое dialyzer (и, соответственно, typespec) вы, я так понимаю, вообще не в курсе.
Ну или это вами воспринимается как очередной «компайл-тайм хак» :-)
Тем не менее… и parse transformation и dialyzer — это _стандартные_ инструменты разработки на erlang. Рассматривать его в отрыве от этих вещей в корне не верно.
… нельзя отличить строку от списка, нельзя отличить дату / время от кортежа
И как люди живут?!
Еще раз, erlang это язык со _строгой_ динамической типизацией. При этом, у него есть замечательные инструменты для _статического_ анализа кода.
Так что, если нужно, то все эти «проблемы» решаются на раз. А вот почему это практически никогда не нужно — разговор отдельный.loz
25.12.2015 15:06+1Понимаете… фактически, вы сейчас пытаетесь меня убедить, например, в том, что в erlang нельзя писать собственный ф-ции
Это лишь твои фантазии. Я предлагаю тебе привести мне код, в котором твой совбственный тип не будет проходить проверку на стандартные функции is_list, is_tuple, is_record и другие, и окончательно унизить меня, или признать свою некомпетентность.
И как люди живут?!
Я, например, пишу за деньги на эрланге, питоне и жс. На эрланге, по сравнению с остальными двумя, очень плохо живут.
При этом, у него есть замечательные инструменты для _статического_ анализа кода.
Как мне статический анализ кода поможет конвертировать десяток моих вложенных рекордов в JSON?
Так что, если нужно, то все эти «проблемы» решаются на раз
Ну приведи решение хоть одной из них уже.gBear
25.12.2015 18:15Я предлагаю тебе привести мне код, в котором твой совбственный тип не будет проходить проверку на стандартные функции is_list, is_tuple, is_record и другие, и окончательно унизить меня, или признать свою некомпетентность.
Я бы конечно, мог в ответ попросить вас изобразить мне на JS нечто, что не будет «проходить проверку» на instanceof Object. Но, мы зайдем с другой стороны :-) Попробуйте сначала объяснить мне, какое отношение guard function имеют к _типизации_ в erlang вообще. Пытаясь типа «типизироваться» guard'ами — вы именно что играете с «instanceof Object» разного рода.
А для _типизации_ в erlang есть typespec + dialyzer.
Я, например, пишу за деньги на эрланге, питоне и жс. На эрланге, по сравнению с остальными двумя, очень плохо живут.
Если вы откровенно «забиваете» на тот же dialyzer, то понятно отчего у вас «очень плохо живут». Пытаетесь поди изображать «питона» на erlang'е ;) Если уж и parse transform для вас не более чем «компайл-тайм хак» :-)
Как мне статический анализ кода поможет конвертировать десяток моих вложенных рекордов в JSON?
Ну хотя бы тем, что может позволить выкинуть вам существенную часть runtime проверок :-) Но, для этого сначала надо typespec'и организовать на «десяток ваших вложенных рекордов» :) Ага… И глядишь — появится parse transform модуль, который все эти «кунштюки» от вас скроет. Но, вы, в любом случае, не отчаивайтесь…
Ну приведи решение хоть одной из них уже.
Выб «проблему» сначала озвучили… а то, «любой кортеж — is_tuple, любой список is_list» — это не проблема. Это решение (неудачное весьма) с помощью которого вы пытаетесь решить некую _проблему_ преобразования «десятка вложенных рекордов». Вот только в чем именно заключается проблема — нам сирым, видно и не понять никак :-)loz
25.12.2015 18:51Я бы конечно, мог в ответ попросить вас изобразить мне на JS нечто, что не будет «проходить проверку» на instanceof Object.
Для начала открой для себя, что типы и объектная система это не одно и то же. В объектной системе есть корень, она так и задумывалась, а в языках без нее есть возможность создавать собственные типы данных. А в эрланге нету.
Попробуйте сначала объяснить мне, какое отношение guard function имеют к _типизации_ в erlang вообще.
вы пытаетесь решить некую _проблему_
Элементарно, хочу я свои рекорды поконвертить в JSON, ну, чтобы отдавать в веб, показывать там юзеру. Адекватная проблема? По-моему да. Рекордов много, многие вложены друг в друга. Можно пытаться писать функцию кодирования для каждого рекорда. Минусы тут очевидны — много кода, изменяется рекорд — надо менять функции, добавился рекорд — надо писать новый функции.
Другой вариант — рекорды это захаченные кортежи (привет, «хорошая» типизация), поэтому можно поэлементно, сконвертировать. Плюсы очевидны — это универсально и отсутствуют все минусы первого подхода. Но, нам нужно узнавать типы в рантайме. И тут начинается веселье. Строку сможете отличить от списка? А юникодную строку? А юникодную строку байт? А проплист от списка? А gb_tree от кортежа? Все структуры данных слеплены из списков и кортежей, и понять где что в рантайме можно только такими же хаками.
Конвертация в JSON это ведь один из простых примеров. В эрланге, например, по этой же причичне отстутствует хоть какой-нибудь адекватный ORM (у нас, например, написан свой на твоих любимых макросах и парс трансформах, которые ущербны настолько, что рядом с лисповыми (привет из 80х (а эрланг, я напомню, делали в 90ые)) и рядом не стоят).gBear
25.12.2015 20:46Для начала открой для себя, что типы и объектная система это не одно и то же.
Мне не надо для себя ничего открывать :-) Сдается мне, я в этом разбираюсь по более вашего.
В объектной системе есть корень, она так и задумывалась
Ух ты, ух ты. Готов послушать, например, про «корень» CLOS :-)
… а в языках без нее есть возможность создавать собственные типы данных.
Яж вас правильно понимаю, что в «языках с ней» (с OS) создавать «собственное типы данных» принципиально нельзя, по-вашему?
А в эрланге нету
-type cool_utf_string() :: {cool_utf_string, unicode_binary()}
Дальше что?
Элементарно, хочу я свои рекорды поконвертить в JSON
Вот что есть «свои рекорды»? Есть у вас erlang нода. Она из вне, что получает? Что отдает? Эти самые «рекорды»? Или что? А то, сдается мне, вы сами себе выдумали проблему.
Но, нам нужно узнавать типы в рантайме.
Внезапно… если вам что-то нужно «узнавать» в runtime, то с изрядной долей вероятности (читай, за редким-редким исключением) вы что делаете не так.
Все структуры данных слеплены из списков и кортежей, и понять где что в рантайме можно только такими же хаками.
Знаете, я с таким же успехом (и пафосом) могу смело утверждать, что «все структуры данных слеплены» из байт или там октетов каких-нибудь. А всякие instanceof/typeof/is/as это «хаки», с помощью которых только и можно «понять где что в рантайме».
И? Чем одни «хаки» принципиально отличаются от других? Тем более, что реально какие-то проблемы могут быть _только_ с обработкой _слабо_ (или вообще _не_) специфицированных бинарных данных. Ведь я же вряд ли ошибусь, если возьмусь утверждать, что эти ваши «рекорды» и JSON'ы «ходят» у вас без какой либо спеки? Ведь так?
Была бы спека — был бы typespec на. Был бы typespec — был бы «типизированный» парсер/pt -> вы могли бы использовать dialyzer и вам бы ничего не нужно было «узнавать» в runtime.
Ведь вот тот же EPP 18, емнип, уж лет десять как есть. Как по вашему — почему он еще не в стандарте?
Конвертация в JSON это ведь один из простых примеров.
Еще раз. Нет никакой проблемы конвертации хоть в JSON, хоть еще куда. Есть проблема конвертации _чего угодно_ в/из. В самом лучшем случае вы получаете какой-нибудь [property(atom(), any())]. С которым — как удивительно-то — что-либо осмысленное делать действительно — проблематично.
В эрланге, например, по этой же причичне отстутствует хоть какой-нибудь адекватный ORM
Боже мой! А оно-то вам на кой нужно?! Чего вы там им делаете? Вот честно… я читаю то, что вы пишите… и реально понимаю, что вы скорее всего действительно воспроизводите на erlang какой-нибудь «питон». Точнее пытаетесь. А оно — что естественно — получается мягко говоря — со скрипом.loz
26.12.2015 11:08Ух ты, ух ты. Готов послушать, например, про «корень» CLOS :-)
www.lispworks.com/documentation/lw50/CLHS/Body/t_std_ob.htm#standard-object
Яж вас правильно понимаю, что в «языках с ней» (с OS) создавать «собственное типы данных» принципиально нельзя, по-вашему?
Нет, не правильно. Если бы ты понимал основы логики, то таких идиотских вопросов не писал бы.
-type cool_utf_string() :: {cool_utf_string, unicode_binary()}
Дальше что?
Дальше ты покажешь как мне в рантайме определить что X у меня является cool_utf_string. Это мне нужно для гварда, например.
Вот что есть «свои рекорды»? Есть у вас erlang нода. Она из вне, что получает? Что отдает? Эти самые «рекорды»? Или что? А то, сдается мне, вы сами себе выдумали проблему.
Из вне получает бинарные данные, парсит их в рекорды, сохраняет в базу. Хочется их увидеть в админке.
Вроде, особой фантазии не надо, чтобы понять что такое рекорды.
Внезапно… если вам что-то нужно «узнавать» в runtime, то с изрядной долей вероятности (читай, за редким-редким исключением) вы что делаете не так.
О, интересно. А как по твоему написана функция io:format? Как она узнает что печатать при ~p? Я часто использую перегруженные по типам аргументов функции. А зачем иначе в языке вобще гварды и паттерн матчинг? Давайте их выкинем и у нас будут функции print_float, print_int, print_string, print_binary, print_function, print_pid, и тд, такой же набор функций на каждый чих типа конвертации в JSON. Зато с типизацией будет проще, да.
Знаете, я с таким же успехом (и пафосом) могу смело утверждать, что «все структуры данных слеплены» из байт или там октетов каких-нибудь. А всякие instanceof/typeof/is/as это «хаки», с помощью которых только и можно «понять где что в рантайме».
Нет, не стаким же успехом. Проблема в том, что в эрланге строку от списка не отличить. Принципиально. В питоне или js это можно сделать.
Есть проблема конвертации _чего угодно_ в/из.
Вот именно, я же говорю, хочу написать одну функцию чтобы конвертировала все. Такая мелочь вызывает проблемы даже со стандартными типами данных, не говоря уже про юзерские рекорды.
Боже мой! А оно-то вам на кой нужно?!
Начались аргументы уровня детсада. Мне не нужно — значит никому не нужно? Может ли создатель языка программирования предусмотреть все возможные юз кейсы его использования? Правильный ответ — нет. И если я хочу что-то сделать, а меня ограничивает язык — почему я должен подстраиваться под него? Почему, вместо того, чтобы признать, что язык в этом контексте явно плох, ты принимаешься защищать его? Ты думал, что ты подаешь пример другим людям и они, вместо того, чтобы искать и пробовать то, что позволит им выражать свои мысли так, как они хотят, не спотыкаясь о проблемы дизайна конкретного языка, подстроят свой образ мышления под рамки конкретного языка и будут защищать его?gBear
28.12.2015 10:41www.lispworks.com/documentation/lw50/CLHS/Body/t_std_ob.htm#standard-object
Хорошая попытка, но… нет :-) Еще раз попробуете?
Дальше ты покажешь как мне в рантайме определить что X у меня является cool_utf_string. Это мне нужно для гварда, например.
Эээ… допустим, f({cool_utf_string, <<Data/binary>>}) ->… вас чем не устраивает?
Ну и да… откройте для себя уже dialyzer (например, тут — на пальцах и «для самых маленьких»). Он вам много интересного про ваш код расскажет :-)
Из вне получает бинарные данные, парсит их в рекорды ...
Вот давайте с этого момента и начнем. Какие вы видите проблемы с тем, чтобы распарсить бинарные данные? Их формат, надеюсь, известен. Если да, то в чем проблема получить _типизированный_ парсер?!
О, интересно. А как по твоему написана функция io:format? Как она узнает что печатать при ~p?
Я наверное вас шокирую, но таки io:format никак не «знает что печатать при ~p». Более того, она вообще ничего не «печатает» :-) Вам, похоже, для начала хорошо бы вообще узнать как io в erlang'е организован.
А зачем иначе в языке вобще гварды и паттерн матчинг?
Эээ… я вас правильно понимаю, что вы считаете, что ПМ и т.п. — это в языке все для «типизации» что-ли?! Т.е. «каноническое» f(0) -> ...; f(1) ->…. это по вашему ф-ция от разных типов?! Что это за «типы» тогда?
Нет, не стаким же успехом. Проблема в том, что в эрланге строку от списка не отличить. Принципиально. В питоне или js это можно сделать.
Ну так расскажите мне, на основе чего (хоть в js, хоть в питоне) вы решаете что «вот эта последовательность байт» — «строка». А потом покажите, что в erlang этот же подход «принципиально» не работает.
Ах… у нас же нет «последовательности байт»… у нас же типа «классы». Ну и чем оно _принципиально-то_ отличается от f(<<Data/binary>>)->{string, Data}?! Если уж вам так приспичило устраивать такого рода диспетчеризацию?
Вот именно, я же говорю, хочу написать одну функцию чтобы конвертировала все.
Еще раз… EEP 18 появилась уже очень давно. Вы с ней знакомы?
Нет абсолютно никакой проблемы преобразовать term() в любую последовательность байт заданного формата. Это означает, что и в «JSON string» мы его преобразовать можем. Есть проблема _однозначного_ преобразования — и в первую очередь: «JSON string» в term(). И это не проблема erlang. Это таков «формат» JSON. И пока, в общем виде, нет j2e(e2j(X)) == X (а его и не предвидеться, насколько я понимаю) — этого в стандарте не будет.
Сторонние парсеры есть… да, емнип, древний yaws умел в это. Если так уж это надо — пользуйте. В чем проблема-то?
Начались аргументы уровня детсада.
Да вы сначала расскажите, куда и что вы собираетесь map'ить в системе, в которой под «О» если и можно что-то понимать — так это конкретный процесс целиком? После этого, уже можно рассуждать о том, кто и в чем конкретно вас «ограничивает».loz
28.12.2015 13:36Хорошая попытка, но… нет :-) Еще раз попробуете?
По ссылке написано что это суперкласс для любого класса. Чем это не корень?
Эээ… допустим, f({cool_utf_string, <<Data/binary>>}) ->… вас чем не устраивает?
Я неточно написал, неустраивает тем, что пройдет проверку на is_tuple.
Я наверное вас шокирую, но таки io:format никак не «знает что печатать при ~p».
ОК, я конечно про форматирование io_lib, в которой, проходится весь список, чтобы проверить что он — юникодная строка: github.com/erlang/otp/blob/maint/lib/stdlib/src/io_lib.erl#L614
Вместо того, чтобы просто написать гард на проверку типа на unicode_string.
Эээ… я вас правильно понимаю, что вы считаете, что ПМ и т.п. — это в языке все для «типизации» что-ли?! Т.е. «каноническое» f(0) -> ...; f(1) ->…. это по вашему ф-ция от разных типов?! Что это за «типы» тогда?
Ты приводишь очень частный случай. В общем это f([]), f({}) f(1), f(<<«0»>>), это функция от разных типов.
Ну так расскажите мне, на основе чего (хоть в js, хоть в питоне) вы решаете что «вот эта последовательность байт» — «строка».
typeof("") -> "string" typeof([]) -> "object"
В JS, конечно, есть свои проблемы, и я не согласен что хорошо возвращать «object» на пустой список, но это другая история, тут хотя бы нет проверки каждого элемента массива.
Еще раз… EEP 18 появилась уже очень давно. Вы с ней знакомы?
json:is_object([{_,_}|_]) -> true;
Ну, такой код и я могу написать (и пришлось). По-моему он неадекватен.gBear
28.12.2015 14:50По ссылке написано что это суперкласс для любого класса. Чем это не корень?
Вообще-то по ссылке написано, что оно суперкласс _лишь_ для standart-class. А standart-class — это лишь один из.
Я неточно написал, неустраивает тем, что пройдет проверку на is_tuple.
Я не понимаю, что вас в этом пугает. Вот в JS еще нужно поискать то, что не «пройдет проверку» на instanceof Object. И?
Вместо того, чтобы просто написать гард на проверку типа на unicode_string.
Уф… Вы можете _внятно_ объяснить зачем вам именно «гард» отдельный? Чем вас так не устраивает возможность писать: f(<<Data/utf8>>) -> ...? Тем что таки надо указывать «кодировку»? Или что?
А упомянутая вами ф-ция — это, емнип, из времен до «R13». Где и как unicode_char_list используется сейчас, сказать не возьмусь. Возможно, в терминальном ПП и используется, т.к. это, емнип, вообще не менялось очень давно.
Если уж «тыкать» в что-нибудь эдакое, то «тыкать» имхо стоит в какой-нибудь io_lib:write/2. Но, эта часть действительно не менялась уже очень долго.
Ты приводишь очень частный случай. В общем это f([]), f({}) f(1), f(<<«0»>>), это функция от разных типов.
Да нет же. Если я опишу (условно) f([]) -> a;f({}) -> b; f(1) -> c. тип f будет _выведен_ как f(Type1) -> Type2 when Type1 :: [] | {} | 1, Type2 :: a | b | c.
Ну и вобще да, даже это функция от разных типов. Эти типы: Zero :: 0 и One :: 1.
Нет. Эта ф-ция от одного типа. И этот тип :: 0 | 1. Это _важно_ для понимания _типизации_ в erlang.
В JS, конечно, есть свои проблемы, и я не согласен что хорошо возвращать «object» на пустой список, но это другая история, тут хотя бы нет проверки каждого элемента массива.
Уф. Вопрос-то был в другом. Ок. Почему typeof(new String("")) — это не «string»? И даже не «String»? У вас так много литералов в коде? Или таки «динамики» в разы больше?
Ну, такой код и я могу написать (и пришлось). По-моему он неадекватен.
Тут с вами трудно не согласиться :-) Но, вы можете предложить более _адекватное_ определение?loz
28.12.2015 22:33Вообще-то по ссылке написано, что оно суперкласс _лишь_ для standart-class. А standart-class — это лишь один из.
Тогда я прошу примера, потому что даже картиночки подтверждают что это корень: sellout.github.io/media/CL-type-hierarchy.png
Я не понимаю, что вас в этом пугает.
Пугает тем, что потенциальная ошибка типов в рантайме может далеко зайти. Может, диалайзера и хватит чтобы перестать бояться.
Вот в JS еще нужно поискать то, что не «пройдет проверку» на instanceof Object. И?
Да, насчет JS я выяснил, что там почему-то у объектов нет ссылки на прототип, поэтому все плохо и все мои сообщения о сравнении системы типов эрланга и JS можно считать ошибочными.
Уф… Вы можете _внятно_ объяснить зачем вам именно «гард» отдельный?
Чтобы не проверять каждый элемент в списке, что как минимум не эффективно.
А упомянутая вами ф-ция — это, емнип, из времен до «R13».
Времена не важны, важно то, что почти вся стдлиба работает со строками как со списками.
Нет. Эта ф-ция от одного типа. И этот тип :: 0 | 1. Это _важно_ для понимания _типизации_ в erlang.
Так можно дойти до того, что все типизировать через any(). Какие ограничения накладывать уже выбирает программист в зависимости от условий.
Но, вы можете предложить более _адекватное_ определение?
Да, конечно, ввести систему типов, пусть и на этих пресловутых кортежах, можно ведь абстрагировать от программиста. И тогда проверка на проплист будет не [{_, _}] а {proplist, _}, а еще лучше — абстрагированный гард is_proplist/1.gBear
28.12.2015 23:50Тогда я прошу примера, потому что даже картиночки подтверждают что это корень: sellout.github.io/media/CL-type-hierarchy.png
?! Да у вас же на «картиночке» есть, например, stream, который ни разу не standart-class. Но, при этом, вполне себе класс. Только из другой «меты». Вы вообще с CLOS-то знакомы?
Может, диалайзера и хватит чтобы перестать бояться.
Не «может», а именно что «хватит». Он, собственно, для этого и придуман.
Чтобы не проверять каждый элемент в списке, что как минимум не эффективно.
В каком «списке», по-вашему, <<Data/utf8>> «проверяет каждый элемент»?! Такой синтаксис в стандарте уже года три, емнип.
Времена не важны, важно то, что почти вся стдлиба работает со строками как со списками.
Если вы внимательно посмотрите, то выяснится что «вся стдлиба» (за редким исключением типа string, re и «старья» типа io ) использует string() исключительно для формирования каких-нибудь {error, string()}. Тот же base64 работает с binary() (хотя и в «список байт» тоже умеет).
Так можно дойти до того, что все типизировать через any(). Какие ограничения накладывать уже выбирает программист в зависимости от условий.
Можно, конечно и ч/з any(). Только dialyzer «ругаться» будет. Тип этот (я, кстати, ошибся не 0|1, а 0..1) он именно, что _выведет_ даже без typespec'ов. Но, у «программиста» всегда есть возможность написать typespec, и тогда dialyzer будет опираться на него, а не выводить тип из вариантов использования.
Да, конечно, ввести систему типов, пусть и на этих пресловутых кортежах, можно ведь абстрагировать от программиста. И тогда проверка на проплист будет не [{_, _}] а {proplist, _}, а еще лучше — абстрагированный гард is_proplist/1.
:-) Система типов erlang — наслаждайтесь. Именно по этой «бумажке» и работает dialyzer. Уверяю вас, проблема «разбора» JSON совсем не в этом :-)
loz
28.12.2015 13:43Т.е. «каноническое» f(0) -> ...; f(1) ->…. это по вашему ф-ция от разных типов?! Что это за «типы» тогда?
Ну и вобще да, даже это функция от разных типов. Эти типы: Zero :: 0 и One :: 1.
erlyvideo
26.12.2015 08:35+1ага. А в яваскрипте очень легко отличить список от хеш-таблицы.
loz
26.12.2015 10:45+1А там это не требуется, так как есть какая-никакая объектная система.
erlyvideo
26.12.2015 11:56+1требуется, конечно. Иначе это не было бы Второй Неразрешимой Проблемой Яваскрипта.
loz
28.12.2015 13:08Array.isArray разве не определяет список?
erlyvideo
28.12.2015 13:25Возможно определяет, но там же, где работает из коробки fetch и какие-нибудь polymers.
А на остальных N% браузеров нет.loz
28.12.2015 13:40Ты же понимаешь, что это проблема конкретных реализаций. К языку / стандарту напрямую это не имеет отношения. С таким же успехом можно взять студенческий сишный комилятор, не умеющий в структуры и утверждать что в сях нет структур.
nwalker
25.12.2015 03:37+1> из эрлангового в json
Достаточно простой record-to-json(через proplist) делается в одну функцию при использовании exprecs (https://github.com/uwiger/parse_trans/blob/master/doc/exprecs.md) — parse transform, который генерит много функций для работы с рекордами. Дописать exprecs для генерации to_map/from_map должно быть не так уж сложно.
Простой пример из моего продакшн-кода
https://gist.github.com/nwalker/816618e162fc2f5010af
Результат функции to_proplist/1 должен спокойно прожевать любой JSON-энкодер.
Конечно, с композитными типами данных, типа дат, будет сложнее — но так оно и нигде не просто, JSON так себе формат для этого.loz
25.12.2015 11:49-2Ээ, да нет, вобще-то в любых языках с минимальной поддержкой интерфейсов JSON кодирование просто вызывает соответствующий метод у сущности, и никаких компайл-тайм хаки не нужны.
nwalker
26.12.2015 04:33Будем честны — ну все и не везде так просто, даже если забыть про парсинг JSON.
Продолжая быть честными — да, в эрланге очень не хватает какого-то рантайм-полиморфизма и dynamic dispatch. Но чего нет, того нет, и как это вообще впилить в имеющийся рантайм, ничего не потеряв — неясно.
erlyvideo
26.12.2015 08:34это практически исчезло с нынешими мапами. Из БД приезжает map, он же в json и так же обратно.

HDDimon
25.12.2015 11:22Если вы пишите статью для начинающих, то новичков нужно сразу приучать к хорошему стилю. В вашем случае, нет ни одного описания типов.
www.erlang.org/doc/reference_manual/typespec.html

sokal32
25.12.2015 11:38+1Опять сраный DSL. Так уже никто не пишет, лет 5. Правильно человек выше заметил, лучше бы для примера WS/HTTP API и клиент на JS. Но плюсану, люблю Erlang!)

5HT
25.12.2015 11:57+2WebSharper на F#, Scala Lift, Ocaml Ocsigen, на BlazeHtml все используют DSL.
На Эрланге по любому писать лучше чем на HTML, тем более в едином AST.
Кроме того nitro DSL уже давно вынесен из n2o, так что n2o занимает теперь только 1200 LOC.
merc
25.12.2015 14:57-1Erlang + что-то-еще (почему не cowboy?) это как страшный сон после Elixir + Phoenix.
Я попробовал Elixir, писать на Erlang больше руки не поднимаются.nwalker
25.12.2015 22:01cowboy — низкоуровневый HTTP-сервер. n2o работает поверх него.
Elixir — довольно неоднозначная штука. С одной стороны — протоколы и макросы это отлично. С другой — от всей темы вокруг Elixir настолько невыносимо пахнет наихудшим хипстерством, что как-то боязно подходить.
Ну и да, как его интегрировать в эрланг-проект до сих пор неясно.merc
25.12.2015 22:50А вы пробовали эликсир? После него за эрланг садиться не хочется.
Как по мне, в эликсире только лучшее от хипстерства: один микс чего стоит. Если вас это пугает — это странно.
Пишут его люди компетентные и адекватные (Jose Valim вопросов не вызывает). В продакшене крутится много где. В виртуальную машину эрланга изменения не вносит, так что все рок солид.
В эранг проект интегровать никак. А вот отдельный сервис рядом поставить — самое оноnwalker
26.12.2015 01:02Нет, у меня нет пока эликсира в проектах, мне нормально с эрлангом. Mix — а что мне тот mix, если я на rebar-е и мэйкфайлах могу изобразить такое, что потом сам рад не буду. =)
Было бы интересно поиграться с ecto, но вывешивать в отдельную ноду работу с БД — это на мой взгляд несколько чересчур.merc
26.12.2015 02:20Попробуйте, рекомендую. Я сел решать задачки с эйлерпроджект и мне очень понравилось.
Инфраструктура важна. Зачем вам ребар и мейкфайлы, если есть микс? Они не нужны.
Не совсем понял про ноду и экто.nwalker
26.12.2015 03:30> Зачем вам ребар и мейкфайлы, если есть микс? Они не нужны.
Да тут как посмотреть. Я, например, не уверен, нужен ли мне микс, когда есть ребар и мэйфайлы. Они же абсолютно эквивалентны.
И вот именно этот подход «зачем X и Y, если есть Z, который наш» в эликсире и его комьюнити совсем не нравится. Например, «зачем нам старый source file layout, мы запилим свой, абсолютно несовместимый». «Зачем нам встраивание в pure erlang проекты» туда же. Мне гораздо ближе подход clojure — «мы сделаем язык в обе стороны интероперабельный с хостовым и все будет прекрасно», это гораздо прагматичнее на мой взгляд.
Про ноду и экто — ну тут ведь как. Вот есть у меня готовое приложение на эрланге, здоровенное. И главная проблема в нем — в базу ходить больно и убого. И хочется чего-нибудь, что походило бы на нормальный генератор запросов, и вот есть ecto, но прикрутить его не получится, кроме как поднять отдельную ноду, где будет жить эликсирный код общения с БД.
erlyvideo
26.12.2015 08:42с тем же успехом ты можешь поставить рядом питон и получить реально нормальную ноду по работе с БД =)
elimoon
02.01.2016 08:40Можно Elixir — подключить к Erlang проекту. После компиляции весь Elixir и все Elixir проекты ничто иное, как точно такие же .beam файлы и OTP приложения, как и от erlang проекта. В конечном итоге — Elixir — это просто OTP приложение. И функции Elixir-овского кода из Erlang-а можно вызывать.
erlyvideo
26.12.2015 08:41«люди компетентные» и «В эранг проект интегровать никак» вместе никак не вяжется.
Проблема эликсира в том, что с самого момента, как его подобрал Хосе Валим у него не было никаких внятных явных целей. Если бы их формулировали и обсуждали, то момент плавного внедрения, а следовательно и использования эликсира в эрланговском коде поднимался бы и решался бы.
В эрланге очень серьезная инженерная культура. Принятые решения оказываются удачными в течении 10 лет и более. На этом фоне эликсир выглядит суетой сует.
mix интересен только для старта совсем новичкам. Ничего жизненно необходимого в менеджере пакетов нет. Мы вот все свои зависимости внесли в гит и вздохнули спокойно.
develop7
26.12.2015 10:01Кстати, про инженерную культуру и суету сует. Ecto — по-прежнему самый вменяемый DBAL под BEAM VM?
erlyvideo
26.12.2015 11:57не могу сказать, потому что он у меня ни разу не заработал из-за нелепых детских ошибок, как-то наивное предположение о том, что коннект к БД будет без пароля.
develop7
26.12.2015 13:49elimoon
02.01.2016 01:18При том, очень сильно не договаривает. Пароль к базе данных существует с версии 0.1.0. С версии 0.10.0 использовали в разработке, с версии 0.12.0 мы используем ecto в production, где пароль и подавно во всех версиях работает.
develop7
02.01.2016 13:43«софт, за которым не следишь специально, не развивается вообще»
elimoon
02.01.2016 16:12Я не мог не прокомментировать этот комментарий, так как мы ecto используем с версии помойму 0.10.0 или может даже раньше, уже как год и пароль там точно работал всегда, а посмотрев историю и тесты ecto — то видно, что к базе данных она ходит по паролю с самой первой версии, ещё с 0.1.0: github.com/elixir-lang/ecto/blob/v0.1.0/integration_test/pg/test_helper.exs#L23
erlyvideo
02.01.2016 17:02когда создаешь приложение и сразу с базой данных, скрипты вокруг феникса и экто думают, что пароля не будет.
Если постгрес требует пароль, то скрипт молча зависает на бесконечность.elimoon
02.01.2016 17:14Странно, у меня phoenix приложения всегда генерировались с непустыми паролями. Но, баг такой действительно был: github.com/elixir-lang/ecto/commit/5cda8545a8ec2f45d7e699abb6307bd16cf6712d
elimoon
02.01.2016 01:14А что мешает использовать эликсир в эрланговском коде? Помимо прямого использования эликсировских макро из эрланга (что по логичным причинам невозможно).
nwalker
02.01.2016 22:34Ок, идем от начала.
Есть эрланг-проект, собирается ребаром, основным является именно он. На эликсире только прослойка для работы с БД с ecto — абсолютно нормальные требования, на мой взгляд.
Тем более, что ecto — единственная причина вообще заморачиваться.
А дальше начинается ожидаемое. rebar_elixir_plugin не умеет в app-файлы в принципе. ecto из ребара не собирается. То есть, ради использования одной библиотеки мне нужно менять систему сборки проекта. Приехали.
Уже на этом этапе можно закрывать тему, но немного заглянув вперед, мы узнаем, что на каждый чих нужно писать враппер-функцию erlang map -> ecto struct. А то и erlang record -> ecto struct. Что ecto жестко привязан к эликсирному логгеру, как результат нам нужно конфигурить два логгера при старте — потому что у нас уже есть логгер, какой проект без логгера.
Да, я не умею готовить эликсир. Но мне не кажется, что интеграция с хостовым языком должна выглядеть так.
Я, может быть, не поленюсь все же собрать что-то работающее через неделю-другую, если не забуду. Просто ради интереса. Но не думаю, что проделаю подобное с каким-то рабочим проектом, кроме как ради job safety.erlyvideo
03.01.2016 15:48с логгерами вообще беда. Как указать нужный логгер библиотеке, я ума не приложу.
erlyvideo
03.01.2016 16:24я от себя добавлю: мы почти готовы отказаться от ребара, как только разберемся с компиляцией C-шников (и выкинуть бы ещё неотому), так что хер с ним с ребаром, сами скомпиляем.
develop7
26.12.2015 09:56С другой — от всей темы вокруг Elixir настолько невыносимо пахнет наихудшим хипстерством, что как-то боязно подходить.
люблю подробную и качественную аргументацию. жаль только, в этот раз опять не завезли.erlyvideo
03.01.2016 15:49develop7 habrahabr.ru/post/273979/#comment_8724463
Можешь сюда прокомментировать. Если можно, то покажи, пожалуйста, на примере как воткнуть экто в рабочую программу на эрланге, это было бы просто замечательно.
elimoon
02.01.2016 01:03+1Elixir — это стандартное OTP приложение, где-то на просторах гитхаба есть даже rebar плагин для компиляции эликсир кода. Т.е. путь интеграции простой — все приложения под Elixir, как и сам Elixir — это OTP приложения со всем вытекающим, а для компиляции есть rebar плагин. Так же, как из Elixir-а легко и просто вызывать Erlang код, так же и из Erlang-а легко и просто вызывать Elixir код. Единственное, что не интегрируется в erlang приложение напрямую — это использование Elixir-овских макро из Erlang кода по вполне понятным причинам.
НО: спрос на использование Elixir из Erlang-а сверхнизкий, потому что люди, которые садятся за Elixir в конечном итоге используют Erlang из Elixir-а из-за удобства, что есть в Elixir-е (это и mix и exrm и много других факторов, которые сделаны более удобно, чем аналогичные под Erlang), соответственно всё, что есть (rebar плагин) для обратной интеграции никак не поддерживается из-за спроса равного или стремящемуся нулю. А вот с другой стороны, где к чисто Erlang проектам прилагается mix.exs фаил встречается очень часто, при том, что в одной команде, которую я знаю некоторые разработчики настолько были в восторге от Elixir-а, что строили и тестировали Erlang(без единой строчки кода на Elixir) проекты с помощью mix-а и зависимости тянули с помощью mix-а.erlyvideo
03.01.2016 16:25спрос на использование эликсира из эрланга низкий не потому, что он низкий, а потому что этот момент не проработан.
erlyvideo
26.12.2015 11:58Денис, а зачем вы используете mnesia? Это же совершенный антипаттерн сегодня.

PatapSmile
26.12.2015 15:05Я использую github.com/synrc/kvs поверх БД. Там можно выбрать из нескольких бекендов, и mnesia не надо устанавливать и настраивать. Но, в следующих статьях я напишу, как заменить mnesia на MongoDB.

mag2000
28.12.2015 09:31откуда инфа, Максим?
erlyvideo
28.12.2015 13:26от общей практики использования и «общественного мнения».
БД не переживает нетсплит, не имеет удобного консольного клиента, крайне сложные миграции, отсутствует вменяемый дисковый бекенд (dets боль).
Для чего-то была хороша, но в целом её забросили.mag2000
28.12.2015 15:29а как же
— WhatsApp? http://www.erlang-factory.com/static/upload/media/1394350183453526efsf2014whatsappscaling.pdf
— Observer с подключением к удаленной ноде?
— Дисковый бэкенд недавно реализованный в KVS https://github.com/synrc/kvs/releases/tag/2.11
и если бы мы говорили об «общественном мнении» то можно было написать всего две строки:
PHP
/threadmag2000
28.12.2015 15:35PS. К чему я это всё. мнезия крайне резвая. не помню уже во сколько раз она обгоняет redis но со счетов бы я её точно не списывал, тем более в вебе где от базы надо по сути принеси-подай.
nwalker
28.12.2015 16:59> Дисковый бэкенд недавно реализованный в KVS
Он на DETS, DETS — плохой. У него время восстановления после некорректного закрытия растет как бы не экспоненциально от размера таблицы. Как следствие, и mnesia не очень. Были какие-то попытки в нее вкорячить leveldb в качестве дискового бэкэнда, я не знаю их текущий статус.
> WhatsApp
Они как-то умеют ее готовить.
> Observer с подключением к удаленной ноде
Это вместо человеческого консольного клиента? Ну нет, все же не то. Опять же, это требует сильно больше знаний, чем есть у некого рандомного веб-разработчика.
erlyvideo
29.12.2015 15:12observer =)
покажите мне, пожалуйста, бекап скрипт, который раз в сутки по крону дампит мнезию и заливает на S3, я с интересом посмотрю.
От всех баз данных везде нужно: принеси, подай, положи. Любое приложение начинается с «а, в этот раз обойдемся парой табличек», а через два месяца уже думаем «ну почему всё так сложно выходит», а через год улыбаемся, потому что сложность ещё впереди.
Мнезия может обгонять редис прежде всего за счет того, что не нужно ходить по сети. Других причин быть быстрее редиса особо не видно. Это 1-2 миллисекунды и это очень серьезно, потому что у ets характерное время доступа — доли мкс, т.е. в 1000 раз быстрее.
Мы пользуемся ets очень активно. Может быть пользовались бы мнезией, если бы она не гадила на диск, но не можем из-за этого. Она интересна как ram-only база, но дисковый бекенд у неё отсутствует. Его надо было последние 10 лет развивать, но этого не делали и поэтому бытует такое мнение, что мнезия — БД для конфигурации. Т.е. 10-50 мегабайт предел того, что имеет смысл хранить в ней персистентно.
DETS попросту нерабочая штука: при неудачном рестарте его надо удалять, а не пытаться восстанавливать, а на ходу оно иногда просто рассыпается под нагрузкой.
vvoznesensky
30.12.2015 07:42Привет. Не кажется ли автору, что имеет смысл махнуть сразу в Elixir? Ruby-подобный синтакс, есть дополнительные возможности к Erlang.
erlyvideo
30.12.2015 23:18+1давно уже не существует Эликсира с Ruby-подобным синтаксисом (года три как). В нынешнем он не руби-подобен.
{kind=link}
goooseman
Невозможно залогинеться через Facebook, т.к. приложение в Facebook находится в dev режиме.
Необходимо зайти в Facebook developers и установить production режим
PatapSmile
Спасибо, исправил