
При работе с API больших языковых моделей я привык к определенной предсказуемости. Для моих исследовательских задач, экспериментов с кодом и повседневной рутины дневные расходы на API обычно колеблются в предсказуемом и комфортном диапазоне 3-4 евро. Это стало своего рода фоновым шумом, константой, на которую я перестал обращать внимание.
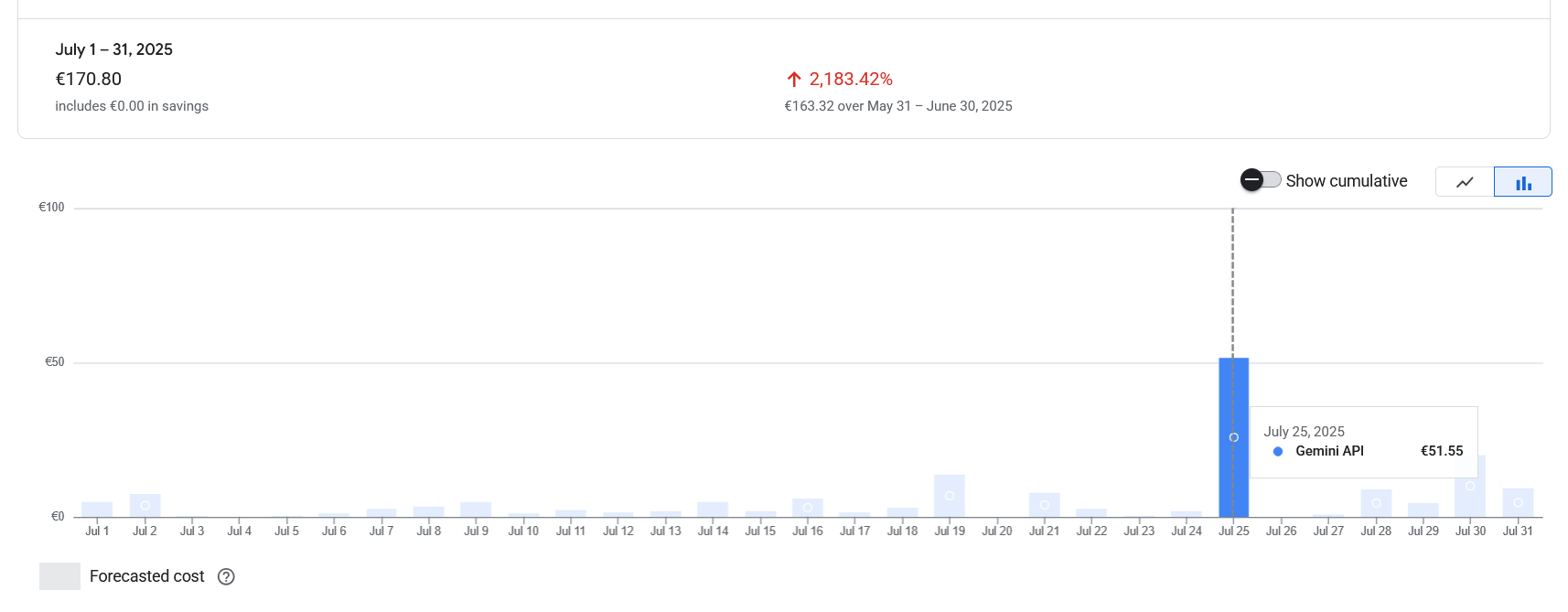
Но в конце июля я увидел в биллинге Google API картину, которая заставила меня остановиться и задуматься. Вместо привычной цифры там красовалась аномалия — €51.
Моей первой реакцией было, конечно, недоумение. Что я такого делал, чтобы сгенерировать расходы, в десять с лишним раз превышающие норму? Это был не просто результат особенно продуктивного дня или затянувшегося сеанса генерации. Ответ крылся глубже. В тот день я глубоко погрузился в рефакторинг кода своего блога, и чтобы получить от модели максимально качественные и контекстно-зависимые рекомендации, я скармливал ей целые модули и сопутствующую документацию. В какой-то момент размер контекста, который я подавал модели в одном диалоге, впервые перевалил за критическую отметку в 200 тысяч токенов. И именно в этот момент я, сам того не зная, пересек невидимую черту. Оказалось, что у «памяти» LLM есть своя цена, и она растет совсем нелинейно.
Эта ситуация очень похожа на логику ценообразования в грузоперевозках. Пока ваш груз умещается в стандартный морской контейнер, его доставка — это отлаженный, предсказуемый и относительно недорогой процесс. Логистические компании оперируют стандартными тарифами, и вы платите понятную цену за объем и вес. Но стоит вам попытаться отправить деталь, которая хотя бы на сантиметр превышает габариты этого контейнера, как вы попадаете в совершенно другую лигу. Ваш груз мгновенно получает статус «негабаритного». И вы платите уже не просто за лишний сантиметр, а по совершенно иному тарифу — за спецразрешения, разработку особого маршрута, возможно, даже за сопровождение. Цена возрастает не на проценты, а в разы. Вы платите за сложность.
С контекстом LLM происходит то же самое. Пока он находится в пределах некоего «стандартного» окна, цена предсказуема. Но как только вы его превышаете, вы начинаете платить за «негабаритный» вычислительный груз.
И этот всплеск в моем биллинге — не ошибка и не баг. Это задокументированная, фундаментальная особенность работы системы, экономическая реальность, продиктованная законами математики, которые лежат в основе современных LLM. Чтобы понять, почему она существует, как с ней работать и, что самое главное, как ее контролировать, нам нужно заглянуть под капот и разобрать на части сам механизм «памяти» LLM.

Магия и математика механизма "Внимания"
Итак, мы столкнулись с «негабаритным тарифом» за контекст. Чтобы понять его природу, нужно отказаться от интуитивного, человеческого представления о памяти. Нам кажется, что память — это пассивный склад, куда мы просто добавляем новые факты. Но для большой языковой модели «память» — это не хранилище, а непрерывный, активный и невероятно дорогой вычислительный процесс. Имя этому процессу — механизм Внимания (Attention).
Когда мы даем модели длинный текст, она не «читает» его последовательно, как человек, от начала до конца, складывая информацию в некий буфер. Вместо этого происходит нечто гораздо более сложное. Для генерации каждого нового слова или токена модель заново «оглядывается» на весь предоставленный ей контекст — от самого первого до последнего слова — и пытается понять, какие из предыдущих частей текста наиболее важны для следующего шага. Она буквально взвешивает важность каждого слова по отношению к каждому другому слову, чтобы построить наиболее вероятное продолжение.
Как это выглядит на практике?
Чтобы это не было голословным утверждением, давайте посмотрим, как это реализовано в большинстве современных SDK, на примере google-genai. Когда мы используем удобный объект chat, мы интуитивно чувствуем, что модель "помнит" диалог. Но как?
from google import genai
# Инициализируем клиент
client = genai.Client()
# Создаем сессию чата. SDK будет управлять состоянием за нас.
chat = client.chats.create(model="gemini-2.5-flash")
# 1. Отправляем первое сообщение
response = chat.send_message("У меня дома 2 собаки.")
print(response.text)
# > Отлично! Собаки — прекрасные компаньоны. Чем я могу помочь?
# 2. Отправляем второе сообщение
response = chat.send_message("Сколько всего лап в моем доме?")
print(response.text)
# > В вашем доме 8 лап (по 4 у каждой из двух собак).
# 3. Давайте посмотрим, что на самом деле "помнит" SDK
for message in chat.get_history(): print(f' роль: {message.role}, текст: "{message.parts[0].text}"')
# Вывод истории:
# > роль: user, текст: "У меня дома 2 собаки."
# > роль: model, текст: "Отлично! Собаки — прекрасные компаньоны. Чем я могу помочь?"
# > роль: user, текст: "Сколько всего лап в моем доме?"
# > роль: model, текст: "В вашем доме 8 лап (по 4 у каждой из двух собак)."
SDK элегантно абстрагирует от нас эту сложность, но под капотом происходит ровно то, о чем мы говорим. Когда мы вызываем chat.send_message() второй раз с вопросом "Сколько всего лап в моем доме?", по сети отправляется не только этот новый вопрос. Отправляется вся накопленная история диалога, которую мы видим в выводе chat.get_history(). Модель получает полный контекст, чтобы дать корректный ответ "8".
Это как если бы вы каждый раз пересказывали собеседнику весь предыдущий разговор с самого начала, прежде чем задать новый вопрос. И именно этот постоянно растущий «снежный ком» контекста и попадает под каток квадратичной сложности.
Эту сверхспособность, позволяющую моделям сохранять нить повествования даже в очень длинных диалогах и генерировать поразительно связный текст, я уже подробно разбирал в статье «Что на самом деле происходит под капотом у LLM?». Но сейчас для нас важен не сам факт ее существования, а ее вычислительная стоимость.
И вот здесь кроется корень экспоненциальной стоимости. Сложность этих вычислений растет нелинейно, а точнее, почти квадратично (O(n²)) по отношению к длине контекста (n). Говоря проще: если вы удваиваете количество токенов в промпте, вы примерно учетверяете объем вычислений, необходимых для генерации следующего токена. Увеличили контекст в 10 раз — получили стократный рост вычислительной нагрузки.
Чтобы это стало нагляднее, давайте воспользуемся аналогией. Представьте, что модель — это не просто читатель, а гениальный дирижер гигантского оркестра, где каждый музыкант — это один токен в вашем контексте.
С оркестром из 10 музыкантов (10 токенов) дирижер справляется играючи. Перед каждой новой нотой он может легко оглянуться на всех, учесть партию каждого и создать идеальную гармонию.
Теперь в его оркестре 100 музыкантов. Задача усложнилась. Чтобы следующая нота прозвучала гармонично, ему нужно учесть, что играют скрипки, как отвечают им духовые, какой ритм задает перкуссия. Это уже требует серьезной концентрации.
А теперь представьте наш случай — оркестр из 200 000 музыкантов-токенов. Перед тем как дать отмашку для каждой новой ноты, дирижер должен мгновенно оценить вклад каждого из двухсот тысяч исполнителей, проанализировать их взаимосвязи и решить, кто должен звучать громче, а кто — тише. Этот титанический, почти невозможный труд и есть механизм «Внимания». И именно за эту колоссальную вычислительную работу мы и платим по «негабаритному тарифу».
Каждый новый токен, который мы добавляем в контекст, не просто занимает место — он экспоненциально усложняет работу дирижера-модели, делая каждый следующий шаг всё более дорогим и сложным.

Контекст в масштабе. Тройной вызов: цена, качество и скорость
Теперь, когда мы понимаем, что за каждым токеном в большом контексте стоит квадратично растущая вычислительная нагрузка, гонка за миллионные контекстные окна, которую мы наблюдаем на рынке, перестает выглядеть как простой маркетинговый ход. Это уже не соревнование «у кого больше», а сложнейший инженерный компромисс. Каждый провайдер ищет свой собственный баланс между тремя конкурирующими силами: ценой, качеством и скоростью.
Чтобы увидеть это наглядно, достаточно взглянуть на карту современных флагманских моделей. Я свел ключевые параметры в одну таблицу, которая, по сути, является не прайс-листом, а срезом инженерных решений разных компаний.
Модель |
Разработчик |
Размер контекста (токены) |
Цена за 1М токенов на вход ($) |
Цена за 1М кешированных токенов ($) |
Цена за 1М токенов на выход ($) |
|---|---|---|---|---|---|
GPT-4.1 |
OpenAI |
1M |
$2.00 |
$0.50 |
$8.00 |
GPT-4.1 Mini |
OpenAI |
1M |
$0.40 |
$0.10 |
$1.60 |
GPT-4.1 Nano |
OpenAI |
1M |
$0.10 |
$0.025 |
$0.40 |
Claude Sonnet 4 |
Anthropic |
200k |
$3.00 |
$0.30 (чтение) |
$15.00 |
Gemini 2.5 Pro |
1M |
$1.25 (≤200k) / $2.50 (>200k) |
$0.31 (≤200k) / $0.625 (>200k) |
$10.00 (≤200k) / $15.00 (>200k) |
|
Gemini 2.5 Flash |
1M |
$0.30 |
$0.075 |
$2.50 |
|
DeepSeek V3 |
DeepSeek |
64k |
$0.27 |
$0.07 |
$1.10 |
DeepSeek R1 |
DeepSeek |
64k |
$0.55 |
$0.14 |
$2.19 |
Прежде чем мы перейдем к анализу, взгляните на столбец — кешированные токены. Провайдеры ведь тоже понимают, что заставлять пользователей платить полную цену за повторную обработку одного и того же гигантского контекста — это путь в никуда. Поэтому почти все они внедрили механизм Context Caching (или Prompt Caching). Его идея гениальна в своей простоте. Если вы раз за разом отправляете модели один и тот же системный промпт или большой документ, меняя лишь последнюю часть запроса, кеширование позволяет заплатить полную стоимость за обработку этого неизменного «префикса» только один раз. Модель сохраняет его внутреннее представление (те самые вычисленные состояния механизма Внимания), и при последующих вызовах вы платите за него по льготному тарифу, который может быть на 75-80% ниже базового.
Это как если бы наш дирижер-модель, один раз разучив сложнейшую партитуру для своего оркестра из 200 000 музыкантов, сохранил все свои пометки. В следующий раз, когда его просят исполнить ту же партитуру, но с другой кодой, ему не нужно заново анализировать всю симфонию — он просто открывает готовую, «кешированную» партитуру и дописывает финал. Это драматически снижает стоимость для сценариев, где большая часть контекста статична: например, RAG-системы, чат-боты с длинной предысторией или анализ данных на основе одного и того же документа.
А теперь вернемся к строке Gemini 2.5 Pro. Вот оно, то самое техническое объяснение моего «негабаритного тарифа» из первого акта, воплощенное в официальной политике ценообразования. Google недвусмысленно говорит: даже с учетом кеширования, как только ваш новый, некешированный контекст превышает 200 тысяч токенов, цена для вас удваивается. Это не маркетинговая уловка, это честное признание физических ограничений. Это плата за экспоненциально возросшую сложность вычислений механизма Внимания, о которой мы говорили во второй части статьи.
Но цена — это лишь вершина айсберга. Два других компромисса еще более коварны.
Качество: Исследования и практика показывают, что с ростом контекста модели начинают страдать от проблемы, известной как «иголка в стоге сена» (needle in a haystack). Если поместить один важный факт в середину огромного документа, модель с высокой вероятностью его проигнорирует. Ее внимание демонстрирует так называемую U-образную кривую: она отлично помнит информацию в самом начале и в самом конце промпта, но «проваливается» в середине. Возвращаясь к нашей аналогии с дирижером, это легко объяснимо. Когда в оркестре 200 000 музыкантов, дирижер физически не может уделить равное внимание каждому. Он фокусируется на первых рядах (начало контекста) и на солистах, которые готовятся вступить (конец контекста), а где-то в середине огромного зала отдельные инструменты просто теряются в общем гуле.
Скорость: Это самый очевидный компромисс. Больше вычислений — больше времени на ответ. Для простых запросов это может быть незаметно, но в интерактивных приложениях или сложных цепочках вызовов задержка, вызванная обработкой гигантского контекста, может стать критической.
Справедливости ради, нужно сказать, что индустрия не стоит на месте и активно ищет способы обойти «проклятие квадратичной сложности». На горизонте появляются альтернативные архитектуры, которые пытаются разорвать эту порочную связь между размером контекста и объемом вычислений. Как я отмечал в своем анализе архитектуры MiniMax-M1, некоторые разработчики экспериментируют с гибридными подходами, сочетая стандартное внимание с техниками вроде Mixture-of-Experts (MoE), где для ответа активируется не вся модель, а лишь часть ее «экспертов», или линейным вниманием, которое пытается аппроксимировать результат с меньшими затратами. Но пока эти решения не стали мейнстримом и не доказали свою эффективность в масштабе, мы, как пользователи и инженеры, вынуждены работать с реальностью, продиктованной классическим механизмом Внимания.

Инструменты архитектора. Пять хаков для управления контекстом
Итак, мы диагностировали проблему: большой контекст — это дорого, медленно и потенциально неточно. Мы стоим перед тройным инженерным вызовом. Но вместо того чтобы пассивно принимать эти ограничения как данность, мы можем взять управление в свои руки. Прежде чем мы перейдем к фундаментальному, архитектурному сдвигу, давайте вооружимся набором тактических приемов. Я называю это «контекстной гигиеной» — набором простых, но мощных привычек, которые позволяют держать модель в тонусе.
Вот пять конкретных приемов, которые я активно использую:
1. "Последнее слово"
Это самый простой и удивительно эффективный прием. Его суть — в конце очень длинного промпта, после тысяч токенов описаний, примеров и данных, вы кратко и четко повторяете самую главную инструкцию. Этот хак — прямое противоядие от той самой U-образной кривой внимания, о которой мы говорили. Зная, что модель лучше всего «слышит» то, что находится в самом конце контекста, мы сознательно помещаем туда самую важную команду. Например, после десяти страниц технического задания на разработку модуля, ваш промпт может заканчиваться так: «...таким образом, система должна быть отказоустойчивой. Ключевая задача: на основе всего вышеизложенного, напиши спецификацию API для сервиса аутентификации в формате OpenAPI 3.0.» Эта последняя фраза работает как мощный фокус для «внимания» модели.
2. "Принудительная инъекция"
В ходе долгого, многоэтапного диалога модель неизбежно начинает терять фокус. Ранние, но важные детали могут «утонуть» в середине контекста. Чтобы «освежить» память модели, можно использовать прием принудительной инъекции. Вы просто вставляете в диалог сообщение от своего имени (от лица user), которое не просит ничего сгенерировать, а лишь суммирует ключевые факты. Например: «Прежде чем продолжим, давай зафиксируем: 1. Мы используем базу данных PostgreSQL. 2. Аутентификация через JWT-токены. 3. Главный приоритет — скорость ответа. Теперь, с учетом этого, предложи схему кэширования.». Это как если бы режиссер остановил репетицию и громко напомнил актерам ключевую мотивацию их персонажей. Вы вручную создаете новый, высокоприоритетный «островок памяти» в конце контекста.
3. "Структурный якорь"
Одна из причин, по которой модели могут «галлюцинировать» или уходить в сторону, — слишком большая свобода. Ограничивая эту свободу, мы можем направить ее вычислительные ресурсы в нужное русло. Вместо того чтобы просить «проанализируй текст и дай выводы», предоставьте ей «шаблон» для заполнения. Это может быть структура в Markdown, заготовка JSON-объекта или любой другой формат. Например: «Проанализируй отчет об ошибках и заполни следующую JSON-структуру: {"summary": "", "root_cause_hypothesis": "", "suggested_fix": "", "required_tests": []}». Такой подход не только гарантирует получение ответа в нужном формате, но и служит «якорем» для внимания модели, заставляя ее искать конкретные сущности в тексте.
4. "Ручная суммаризация"
Этот прием похож на «принудительную инъекцию», но здесь мы делегируем работу самой модели. Когда диалог становится слишком длинным и запутанным, попросите модель саму подвести итог. «Отлично, мы многое обсудили. Пожалуйста, сделай краткое саммари нашего диалога, выделив 3-5 ключевых решений, которые мы приняли.» Получив этот сжатый конспект, вы можете скопировать его и начать новый диалог, вставив его в начало. Вы фактически вручную сжимаете контекст, отбрасывая «воду» и оставляя только концентрат информации.
5. Принцип разделения мощностей
До этого момента мы фокусировались на том, как управлять контекстом для одной, обычно флагманской, модели. Но что, если самый большой рычаг оптимизации лежит не внутри диалога, а в выборе самого собеседника? Этот хак основан на простой, но мощной идее: перестаньте использовать одну дорогую модель для всех задач.
Это похоже на то, как если бы вы имели ящик с инструментами, но для любой работы — от закручивания крошечного винтика в очках до сноса стены — хватались за самую тяжелую кувалду. Это неэффективно и разорительно. Для простой классификации текста, извлечения фактов или краткой суммаризации идеально подойдет быстрая и дешевая модель вроде Qwen3, которую можно развернуть локально на своем железе. Но когда дело доходит до сложного логического рассуждения или генерации кода по комплексной спецификации — вот тут мы и вызываем «тяжелую артиллерию» в виде reasoning модели Gemini 2.5 Pro.
На практике это реализуется через создание простого «модельного роутера» на входе вашей системы. Первый, очень дешевый вызов к быстрой модели может проанализировать запрос пользователя и определить его сложность. "Это простой вопрос? Отправляем к 'Flash'-модели. Требуется генерация кода? Переключаемся на 'Pro'". Такой подход особенно силен, если учесть, что разные модели имеют разную специализацию. Как я отмечал в своем прошлом анализе, некоторые модели могут быть лучшими в задачах использования API, а другие — в креативном письме. Использование каскада из моделей-специалистов позволяет не только радикально снизить затраты, но и повысить итоговое качество.
Эти тактические приемы помогут вам в повседневной работе. Они — первая помощь, которая позволяет быстро и эффективно решать проблемы здесь и сейчас. Но чтобы перейти от латания дыр к строительству надежных систем, нам нужно подняться на уровень выше. Нам нужно перестать думать о промптах и начать думать о контексте.

Сдвиг парадигмы. Добро пожаловать в эру Инженерии Контекста
Все, что мы обсуждали до этого — тактические хитрости — было лишь первой помощью. Но даже такой мощный архитектурный подход, как RAG (Retrieval-Augmented Generation), который многие сегодня считают панацеей, на самом деле является лишь одним из компонентов более глобального явления. Мы подбирались к краю новой дисциплины, которая только сейчас получает свое имя — Инженерия Контекста (Context Engineering). Впервые кристаллизовавшись в сообществе вокруг таких проектов, как репозиторий Context Engineering , это направление сегодня растет настолько бурно, что уже появляются и фундаментальные обзорные статьи, анализирующие более 1400 работ, и агрегаторы лучших практик. Андрей Карпатый, один из самых глубоких мыслителей в области ИИ, недавно сформулировал это так: «Инженерия контекста — это тонкое искусство и наука заполнения окна контекста только нужной информацией для следующего шага».
Это определение — ключ ко всему. Оно смещает фокус с написания идеальной инструкции на проектирование идеальной информационной среды. Как метко подмечено в сообществе: если промпт-инженерия — это то, что вы говорите модели, то инженерия контекста — это всё остальное, что модель видит. И это «всё остальное» гораздо важнее.
Чтобы понять эту дисциплину, давайте расширим наше определение «контекста». Это не просто промпт. Это полный информационный пакет, который модель получает в момент вызова. Судя по лучшим практикам, которые я проанализировал, он состоит из множества динамически собираемых компонентов:
Инструкции / Системный промпт: Глобальные правила поведения модели.
Запрос пользователя: Непосредственная задача.
Состояние / История: Краткосрочная память о текущем диалоге.
Долгосрочная память: Постоянная база знаний о пользователе, его предпочтениях и прошлых проектах.
Извлеченная информация (RAG): Внешние, актуальные данные из документов, баз данных или API.
Доступные инструменты: Определения функций, которые модель может вызвать.
Структура вывода: Требования к формату ответа (например, JSON-схема).
Этот практический список компонентов, по сути, является отражением формальной таксономии, предложенной в том самом исследовании "A Survey of Context Engineering". В нем выделяются три кита: Извлечение и Генерация Контекста (куда входит RAG), Обработка Контекста (структурирование, самосовершенствование) и Управление Контекстом (память, оптимизация). Наша работа как инженеров — построить систему, которая управляет всеми этими элементами.
Инженерия Контекста — это дисциплина проектирования динамических систем, которые в реальном времени собирают все эти компоненты, чтобы дать модели всё необходимое для решения задачи. И важность этого подхода невозможно переоценить. Как показывает практика, большинство провалов агентов — это не провалы модели, а провалы контекста. Модель не может прочитать наши мысли. "Мусор на входе — мусор на выходе".
Разница между плохим и хорошим контекстом — это разница между бесполезным демо и «магическим» продуктом. Один из комментаторов поделился блестящим примером. Представьте, что AI-агент получает письмо: «Привет, сможем завтра быстренько созвониться?»
«Дешевый демо» агент с бедным контекстом видит только этот текст. Его ответ будет роботизированным и бесполезным: «Спасибо за ваше сообщение. Завтра мне подходит. В какое время вам было бы удобно?»
«Магический» агент, работающий на принципах инженерии контекста, перед вызовом LLM соберет богатый контекст: ваш календарь (который показывает, что вы заняты), историю переписки с этим человеком (чтобы понять нужный тон), список контактов (чтобы идентифицировать его как важного партнера) и доступ к инструменту
send_invite. И только после этого сгенерирует ответ: «Привет, Джим! Завтра у меня всё забито, встречи одна за другой. В четверг утром свободно, как тебе? Уже кинул приглашение, дай знать, если подходит.»
Магия — не в модели. Магия — в контексте.
Этот подход уже подтверждается и научными исследованиями. Мы видим, как исследователи из IBM Zurich, предоставляя модели набор «когнитивных инструментов» (по сути, хорошо структурированный контекст для рассуждения), повышают ее эффективность на 62%. А работы из ICML Princeton объясняют, почему это работает, показывая, что внутри LLM спонтанно возникают символьные механизмы для обработки структурированной информации.
Инженерия контекста — это не просто новый модный термин. Это фундаментальный сдвиг от написания строк к проектированию систем. Мы перестаем быть дрессировщиками и становимся архитекторами познания.

Закат промпт-инженера, рассвет архитектора контекста
Наше расследование, начавшееся с аномального счета на €51, привело нас к неожиданному и фундаментальному выводу. Мы прошли путь от экономического симптома к его математической причине (квадратичная сложность), от тактических приемов «контекстной гигиены» к пониманию новой инженерной парадигмы.
Становится очевидно: эпоха, в которой главным навыком была способность написать хитроумный промпт, подходит к концу. Промпт-инженерия не исчезает, но становится лишь одним, самым базовым элементом — «атомом» — в гораздо более сложной и важной дисциплине. Мы вступаем в эру Инженерии Контекста.
Настоящее мастерство теперь заключается не в том, чтобы написать инструкцию, а в том, чтобы спроектировать для модели идеальную информационную среду. Это работа Архитектора Контекста, и его задачи напрямую вытекают из тех самых формальных компонентов Инженерии Контекста, которые мы обсуждали. Она включает в себя:
Выбор материалов: Подбор правильных моделей для каждой подзадачи.
Проектирование логистики: Построение RAG-систем для своевременной подачи релевантной информации.
Создание инструментов: Разработку «когнитивных инструментов» и структурированных шаблонов, которые направляют рассуждения модели.
Организацию рабочего пространства: Структурирование всего контекста (данные, примеры, схемы) на языке, понятном внутренним символьным механизмам модели.
Управление проектом: Оркестрацию многошаговых цепочек и мультиагентных систем.
Главный вопрос сегодня — уже не «какую модель выбрать?». Доступ к мощным LLM становится стандартным инструментом. Ключевой вопрос звучит иначе: «Как стать тем, кто умеет строить системы, в которых эти модели способны проявить свой максимальный потенциал?».
Цель больше не в том, чтобы просто избегать галлюцинаций. Цель в том, чтобы контролировать их — создавать и проектировать то самое информационное поле, в котором рождается осмысленное и полезное рассуждение. Мы становимся архитекторами искусственного познания.
Оставайтесь любопытными.
Взгляд инди-хакера на AI и разработку: глубокое погружение в языковые модели, гаджеты и self-hosting через практический опыт в моем телеграм канале.
Комментарии (10)

Nara111
06.08.2025 07:44Что такое в шапке таблицы "размер контекста"? Откуда термин? Может, все же "размер контекстного окна"? Если это оно, то у DeepSeek R1 размер контекстного окна 128к, не 64к.
Странная аналогия с оркестром. Обычно в такой аналогии оркестранты - это не токены, а распределенные процессы/экземпляры - Техники, лайты, гибриды и т.д.

xonika9 Автор
06.08.2025 07:44Оба термина часто используются взаимозаменяемо в повседневной речи, однако, строго говоря, это разные вещи.
Информация о контексте из официальной документации - https://api-docs.deepseek.com/quick_start/pricing. В некоторых источниках также указано 128k или 164k.

snakes_are_long
06.08.2025 07:44Gemini использовался для редактирования текста? чувствуется его стиль =)
сама использую саммари и некоторые из предложенных техник как в повседневном общении, так и во время разработки.
ещё можно выгрузить весь диалог в текстовый файл и передать его ИИ в начале диалога и попросить подхватить. насколько я понимаю он не будет загружать текст из диалога постоянно, а так же сам внутри сделает саммари, но помимо самого саммари у него будет и диалог. т.е. блокнот и шпаргалка к блокноту. для написания кода мы таким методом не пользуемся, это в основном метод для сохранения персоны. такой метод делает эмерджентную персону более стабильной и переносимой между разными инстансами
так же вы можете использовать разные инстансы ИИ для работы с контекстом (диалогом выгруженным в текстовый файл)
классная штука - современные ллм не требуют разметки данных и сами отлично по тексту хорошо понимают чья где реплика
вы можете загрузить код в один инстанс и попросить составить документацию, обсудить с ним архитектуру, составить план разработки/рефакторинга
затем вы можете передать выгруженный диалог и документацию инстансу с дип рисерчем что бы он проверил все ваши архитектурные изыскания на соответствие best practices например
вы можете использовать инстансы с дип рисерчем для обогащения контекста других инстансов - опять же через составление документации. каждый раз когда чувствуется что ИИ надо погуглить - можно использовать для этого дип рисерч

tkutru
06.08.2025 07:44В ведении - попытка очень сложным языком донести простую мысль: ЛЮБОЙ облачный сервис несёт ДОПОЛНИТЕЛЬНЫЕ риски и ограничения.
Начиная от вендор лока и заканчивая непредвиденными расходами. Надо изучать условия и тарифы, настраивать бюджетные политики, алерты и прочее. Короче, работать и думать САМОСТОЯТЕЛЬНО. ИИ тут непричём.
Как стать тем, кто умеет строить системы, в которых эти модели способны проявить свой максимальный потенциал?
Проблема в том, что "максимальный потенциал" модели, в плане здравого смысла, всё ещё сильно отстаёт от человеческого. Это просто ещё один инструмент, эффективный в определенных ситуациях и в правильных руках. Как молоток, микроскоп или калькулятор.

Viacheslav-hub
06.08.2025 07:44Но, заметьте, что вы уже сравниваете эту технологию с человеком, разве этого мало?) Это уже первый звоночек. Все же это искусственно созданная вещь)
Но я с вами согласен

{kind=link}

katyastorm
06.08.2025 07:44Добрый день,
Спасибо за такую большую и многогранную статью.
Во время прочтения появился ряд мыслей и вопросов:
1) Откуда взялась именно квадратичная сложность?
2) Интересно, что только у Гугла есть плата за длину... Я даже подумала, что на самом деле моделей у них меньше окном, чем они заявляют, а все, что превышает, они закидывают в RAG. Или просто они решили пойти по собственному пути.
3) Спасибо за открытие для меня понятия контекстный инжиниринг, теперь знаю, чем я балуюсь на работе :)
David_Osipov
Вот это определённо полезная статья! Я тоже перехожу черту 200к, пока разрабатываю свой сайт на Astro. До многого путём проб и ошибок дошёл сам, а теперь хотя бы смогу систематизировать и научиться новому.
xonika9 Автор
Какими ассистентами для написания кода пользуетесь?
David_Osipov
Хах, у меня свой путь. Я - посредник между оркестратором Gemini 2.5 Pro и Github Copilot (Claude Sonnet 4)