

Вы тоже находите смайлы презабавнейшим феноменом?
В доисторические времена, когда я еще был школьником и только начинал постигать прелести интернета, с первых же добавленных в ICQ контактов смайлы ежедневно меня веселили: ну действительно, представьте, что ваш собеседник корчит рожу, которую шлет вам смайлом!
С тех пор утекло много воды, а я так и не повзрослел: все продолжаю иногда улыбаться присланным мне смайлам, представляя отправителя с глазами разного размера или дурацкой улыбкой на все лицо. Но не все так плохо, ведь с другой стороны я стал разработчиком и специалистом в анализе данных и машинном обучении! И вот, в прошлом году, мое внимание привлекла относительно новая, но интересная и будоражащая воображение технология глубокого обучения. Сотни умнейших ученых и крутейших инженеров планеты годами работали над его проблемами, и вот, наконец, обучать глубокие нейронные сети стало не сложнее "классических" методов, вроде обычных регрессий и деревянных ансамблей. И тут я вспомнил про смайлы!
Представьте, что чтобы отправить смайл, вы и вправду могли бы скорчить рожу, как бы было круто? Это отличное упражнение по глубокому обучению, решил я, и взялся за работу.
Глубокое обучение в гараже — Братство данных
Глубокое обучение в гараже — Две сети
Глубокое обучение в гараже — Возвращение смайлов
Тех, кто открыл пост целиком, попробую не разочаровать, и не повторять сюжетную линию бесчисленных постов в интернетах, в которых берут готовую модель из статьи, льют тонны данных в сеть и волшебным образом все получается. Я старался подойти к делу более методически, провести множество экспериментов, подробно изучить результаты и сделать разумные (ха-ха, надеюсь!) выводы. Более того, получить в результате, если не готовую для использования в реальном продакшене модель, то хотя бы концептуально способную работать в реалтайме при приложении понятных инженерных усилий.
Моя история — это не волшебная сказка о том, как по мановению руки и запуску простого скрипта, получаются невероятные результаты. Эта история идущих друг за другом неудач, которые медленно но верно превозмогались долгими исследованиями современных и не очень статей и бесчисленными экспериментами.
Дисклеймер
Многие вопросы в этом цикле статей остались не освещены: как подбирать и менять скорость обучения, как настраивать топологии, как конкретно обрабатывать используемые наборы данных. Мне хотелось написать о проекте в целом и рассказать о принципиальных проблемах вставших передо мной и их возможных решениях, а не зарываться в детали.
Еще хочу заранее извиниться, за дикое количество англицизмов: в этой области русскоязычной литературы почти нет, и писал я как уж привык, хотя кое-где и старался использовать русские аналоги.
Все материалы, наборы данных, картинки и видео взяты из открытых источников и использованы исключительно в образовательных целях.
Весла в воду!
Для начала, тулчейн: я решил выбрать для себя достаточно взрослый, но при этом максимально гибкий инструментарий. Это сразу отбросило Caffe и разные хардкорные С++ библиотеки, в конце концов, это же исследовательский проект!
В принципе, (на тот момент) оставались только Theano и Torch (tensorflow еще не вышел). И Python и Lua я хорошо знаю и имею довольно большой опыт с обоими языками, так что выбор был чисто вкусовой: я выбрал Theano просто потому, что он мне показался гибче, ведь он хоть и поддерживает примитивы глубокого обучения, но вообще он строит произвольные символьные выражения, и кажется более обобщенным. В качестве компенсации готовым кирпичикам-слоям, которые есть в Torch и нет в Theano, я решил использовать Lasagne, в сущности те же самые кирпичики, но поверх Theano.
Сразу скажу, что выбирал я не достаточно осведомленно, а именно, не имея еще никакого опыта с сетями, так что в процессе я много раз пожалел и разжалел назад, что не выбрал Torch. В итоге, до сих пор не определился, что лучше :)
Итак, выбрали платформу, можно кодить! Но что?
Задача
Продуктово все более или менее понятно: я хочу отправлять смайлы не выбирая их из списка, а, изображая их на лице. Итого, я хочу корчить рожу, фотографироваться, и система, в идеале, за меня должна понять, какой смайл я изображаю и вписать его в сообщение. Сразу разочарую: до прототипа в виде плагина к скайпу, вотсапу или хэнгауту так и не дошло (пока?), не хватает времени, доделал я только систему из сетей.
По счастью, такие продуктовые требования легко преобразовать в технологические: нам нужно, простыми словами, уметь преобразовывать селфи в смайл!
Для того, чтобы преобразовывать лицо в смайл, его нужно сначала найти и выделить (мы же не хотим заставлять пользователя выравнивать лицо в экране, правда?).
Итак, алгоритм:
- Ищем лицо.
- Вырезаем.
- Преобразовываем в смайл.
- ??????
- PROFIT!
Все, можно учить!
Только чему? Сначала разберемся с детекцией лиц. Интернеты пестрят статьями про классификацию изображений. Но нам, первым делом, нужна не классификация, а детекция! И это гораздо сложнее. К счастью, тут появляется первый важный инсайт: детекцию можно свести к классификации. Давайте возьмем нашу сеть, и применим ее не ко всему изображению, а ко всем квадратным окнам внутри этого изображения. А точнее, не ко всем, а к окнам нескольких размеров со смещением (4 i, 4 j) по (x, y), где i, j из (0, ceil(w / 4)), (0, ceil(h / 4)).
Получается алгоритм (полупсевдокод):
def windows(img):
window_size = min(img.height, img.width)
while not_too_small(window_size):
y = 0
while y < img.height:
while x < img.width:
yield (x, y, x + window_size, y + window_size)
x += dx
if pixels_x_left_unyilded():
yield (img.width - window_size, y, img.width, y + window_size)
y += dy
if pixels_y_left_unyilded():
while x < img.width:
yield (x, img.hight - window_size, x + window_size, img.hight + window_size)
x += dx
window_size /= resizing_factor
dx /= resizing_factor
dy /= resizing_factorИтого, мы ресайзим изображение в несколько разных масштабов и для каждого масштаба ездим окном фиксированного размера с шагом в 4 пикселя. И выполняем классификацию каждого квадрата лицо/не лицо. После этого у нас, конечно, получится много квадратов, загоревшихся для каждого лица, так что их надо будет как-то слить. Алгоритмы можно придумывать разные, умные и не очень, но я просто выбираю лучший загоревшийся квадрат среди сильно пересекающихся:
def filter_frames(frames):
res = []
while len(frames) > 0:
frames.sort(by=probability_of_face)
res.append(frames[0])
frames = frames[1:]
for f in frames:
if intersection(res[-1], f) > big_enough:
frames.remove(f)Таки учим?
А что? По счастливой отнюдь не случайности я уже заранее вооружился знаниями из нескольких текстовых и видео курсов по глубокому обучению, нескольких интересных блогов и достаточно большого набора прочтенных статей по современным исследованиям (большим по меркам месяца, на тот момент, подготовки, но тем не менее, мне хватило).
Если хотим работать с изображениями — используем конволюционные сети. No exceptions.
На самом деле, есть и другое мнение от великих умов на этом поприще: правильно использовать обычные слои, а конволюции — от лукавого. Ведь, по сути, они являют собой не что иное как обычные же слои, но с "захардкоженным" свойством независимости от положения объекта. Но это свойство, во-первых, можно было бы и выучить самой сетью, а во-вторых, оно вообще не корректно, ведь во время детекции положение нам как раз важно!
Плохой новостью для такого подхода является неспособность его осуществления на современном железе, так что откладываем этот вариант на десяток лет и делаем конволюционные сети.
И тут нам очень везет, ведь это довольно просто! По примеру первого эпического прорыва CNN — AlexNet, архитектуру которого повторить довольно просто: бери себе конволюционно-пулинговых слоев, сколько можешь позволить, а сверху парочку полносвязных. Чем больше сеть, тем лучше, за исключением того, что она очень легко переобучается, но, слава Хинтону, с этим очень легко справиться с помощью техники под названием dropout и небольшого затухания весов на всякий случай.
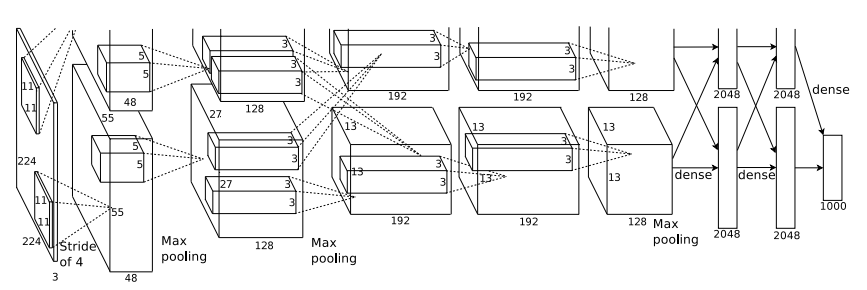
Моя первая, еще маленькая, сеть:
def build_net12(input):
network = lasagne.layers.InputLayer(shape=(None, 3, 12, 12), input_var=input)
network = lasagne.layers.dropout(network, p=.1)
network = conv(network, num_filters=16, filter_size=(3, 3), nonlin=relu)
network = max_pool(network)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=16, nonlin=relu)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), num_units=2, nonlin=relu)
return networkМаленькая она в основном потому, что на тот момент у меня еще не было доступных GPU и я оптимизировал на CPU, что очень медленно.
Ну учим уже наконец?
А на чем? К счастью, добрые люди создали множество открытых датасетов для задач распознавания и детекции лиц. Я первым делом взял датасет под названием FFDB. В нем достаточно много фотографий, на которых лица выделены эллипсами (не прямо поверх фоток, а отдельно выписаны параметры эллипса в текстовом файле). Этот датасет можно использовать только в образовательных целях, но у нас ведь именно такие цели, правда? :) Дополнительно, я туда добросил немного данных, размеченных мной самим и полученных с фотографий, аналогичных КПДВ.
Все есть, пошли учить!
Пошли. И сразу, волшебным образом, получилось!
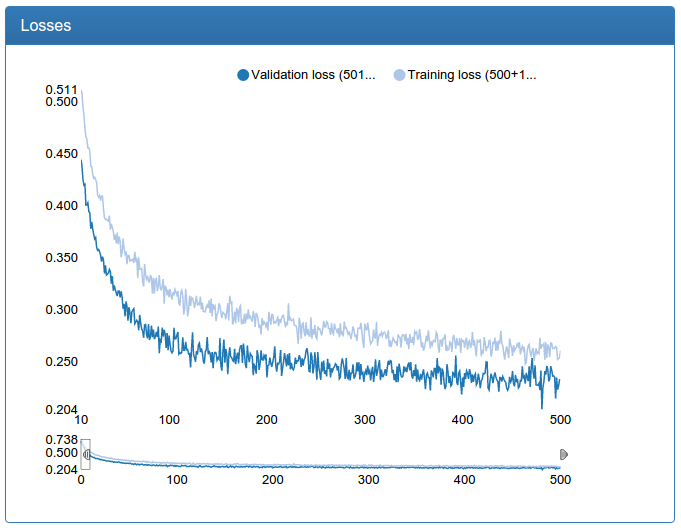
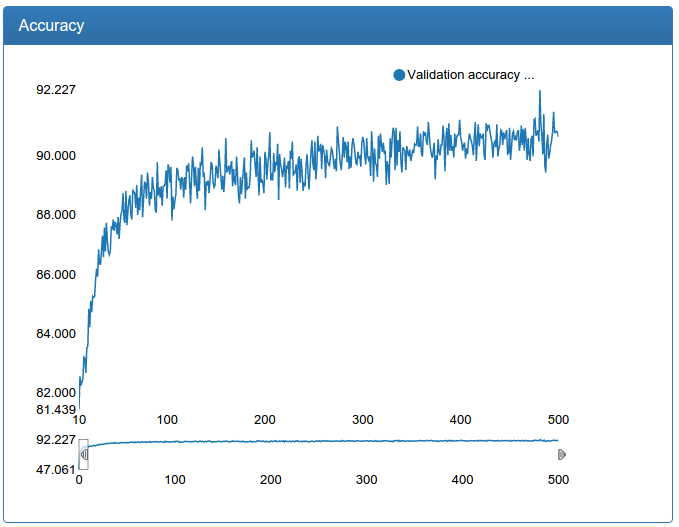

Скриншоты сделаны в специально разработанной мной системе мониторинга обучения нейронных сетей под названием DeepEvent, о которой я напишу в отдельной статье, если будет интерес.
Первые 10 итераций обучения обрезаны просто потому, что они мало что говорят и сильно зависят от случайной инициализации весов.
В примере работы красным отмечены все окна, в которых сеть нашла лицо, зеленым отмечены окна, оставшиеся после фильтрации.
Еще признаюсь, что тут есть небольшой обман: все графики были сделаны сильно позже не на тех самых экспериментах, а на чуть более продвинутых и где надо починенных, но аналогичных. Дело в том, что DeepEvent был разработан совсем не сразу и результаты первых экспериментов утеряны навечно. Хотя, как сейчас помню, вот эта сеть в самом начале давала не 92%, а около 89.5%.
И тут же мы видим, что хоть сеть и показывает заоблачные для таких малых усилий со стороны меня 92%, настоящее качество детекции оставляет желать лучшего. Что делать? Надо учить сеть побольше!
def build_net48(input):
network = lasagne.layers.InputLayer(shape=(None, 3, 48, 48), input_var=input)
network = lasagne.layers.dropout(network, p=.1)
network = conv(network, num_filters=64, filter_size=(5, 5), nolin=relu)
network = max_pool(network)
network = conv(network, num_filters=64, filter_size=(5, 5), nolin=relu)
network = max_pool(network)
network = conv(network, num_filters=64, filter_size=(3, 3), nolin=relu)
network = max_pool(network)
network = conv(network, num_filters=64, filter_size=(3, 3), nolin=relu)
network = max_pool(network)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), nolin=relu, num_units=256)
network = DenseLayer(lasagne.layers.dropout(network, p=.5), nolin=relu, num_units=2)
return networkИ ничего не выходит. Оказывается, что часто забывают рассказать в статьях, для глубокого обучения нужно много данных. Очень много. С вышеописанным датасетом у меня вышло достойно обучить небольшую модель, но небольшая модель не давала качества, которого хотелось. Большая же модель никак не сходилась в нормальные минимумы, а если уменьшать пороги дропаута, быстро переобучалась, что логично: большой модели не составляет труда просто запомнить небольшой объем обучающих данных.
Аугментация
Ну хорошо, рассудил я, нам надо больше данных — сделаем больше данных! И реализовал процесс, который, как я впоследствии узнал, называется аугментация данных: это когда к исходным данным применяются преобразования, что эффективно увеличивает размер обучающей выборки в сотни, а то и тысячи раз.
Итак, для каждого примера с вероятностью 0.5 отражаем его по горизонтали, ведь от этого не меняется класс лицо/не лицо. Так же, каждый для каждого лица я взял не исходный квадрат, полученный из эллипса, присутствовавшего в датасете, а квадрат во-первых случайно слегка увеличенный (или уменьшенный) в некотором интервале, а во-вторых, после этого случайно слегка сдвинутый по x и y в некоторых интервалах.
Дополнительно, позже я еще придумал брать не сам этот квадрат, а его, но случайно слегка растянутого либо по x либо по y (50/50). В результате чего получается вырезанный из картинки прямоугольник с лицом, который потом надо превратить в квадрат сжатием. Отличие этого преобразования в том, что предыдущее изменяет размеры и положение квадрата но не деформирует само лицо, а это преобразование деформирует лицо: слегка растягивает/сжимает его либо по вертикали либо по горизонтали.
Псевдокод аугментации:
def get_rnd_img_frame(img, box, net_input_size):
box = move_box(box, random(minx, maxx), random(miny, maxy))
box = scale_box(box, random(minscale, maxscale))
if random.random() >= 0.5:
stretch_x, stretch_y = random(1., stretchx), 1
else:
stretch_x, stretch_y = 1, random(1., stretchy)
box = stretch_box(box, stretch_x, stretch_y)
frame = img.crop(box)
if random() > 0.5:
frame = mirror(frame)
return frame.resize((net_input_size.x, net_input_size.y))С помощью вышеописанных комбинаций, я получил эффективно бесконечный набор данных: вероятность повтора картинки за 500 эпох обучения по моим прикидкам была где-то в районе десятой доли процента для моего размера картинок.
Вот результаты той же маленькой модели, но с дополненными обучающим и тестовым множествами:

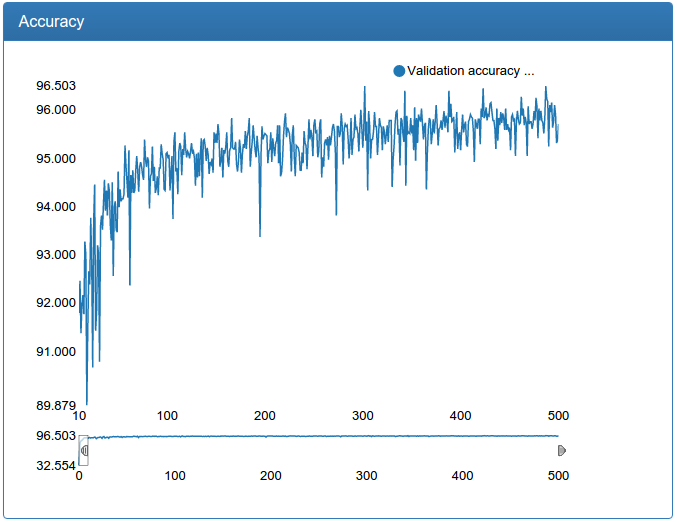

На примере работы теперь есть еще синие квадраты, из за того, что я разделил фильтрацию на две стадии: сначала фильтруются только окна каждого размера в отдельности, выбирая лучшие среди своего размера (синие), и глобально среди всех размеров (зеленые), заодно, почему-то я уменьшил шаг скольжения окна.
Оптимизация I
Правда, взамен малому объему обучающих данных я получил другую проблему: для потенциально бесконечного объема данных нужен потенциально бесконечно мощный компьютер! Или умный трюк. Так как я больше специализируюсь по софтварной части, я решил, что потенциально бесконечно мощный компьютер я построю в следующий раз, а текущую проблему решу умным трюком: не буду заранее генерировать датасет для обучения и грузить его целиком в память, а построю заранее некий индекс с исходным недополненным датасетом, который я буду дополнять прямо в рантайме. В сущности, прямо во время итерации для каждого объекта в минибатче я вызываю вышеприведенный алгоритм и получаю дополненные данные, сгенерированные на лету.
С этим, кстати, связана забавная история. Когда я отладил все это на CPU и пошел запускать на GPU я увидел бешеную просадку производительности: сами посудите, алгоритм аугментации содержит кучу логики, после которой идет еще и отражение и ресайз картинки! И так для всех 1024 элементов минибатча, умножить на несколько десятков минибатчей на итерацию!
В общем, понятное дело, меня это категорически не устроило, и я пошел разбираться. И оказалось, что все вполне логично: в однопоточной python-программе GPU просто-напросто спит, пока CPU не спеша генерирует минибатч. Лень — это плохо, с ней надо бороться и я решил, что GPU должно впахивать, аки раб на галерах, каждое доступное мне мгновение!
Решение? Не блокировать GPU! Давайте, CPU будет асинхронно готовить следующий батч, пока GPU учит сеть на текущем. Так я и сделал. И я был абсолютно уверен в успехе этой операции, но меня ждало разочарование: это почти не помогло. Оказалось, что CPU работает гораздо дольше, чем GPU, особенно на небольших сетях, и GPU все равно спит большую часть времени.
Ну что ж, зря что ли я проектировал все эти веб-сервисы? Как оптимизировать параллельную примерно одинаковую read-only обработку большого массива объектов? Шардинг (оно же MapReduce)! Давайте, решил я, запустим много процессов и каждому выдадим кусочек минибатча, который они будут обрабатывать, складывать результаты в очередь и тут же, не ожидая, обрабатывать кусок следующего минибатча, если очередь не переполнена. Дополнительно, запустим еще один процесс, который будет слушать эту очередь, понимать, к какому минибатчу относится кусок, собирать из кусков минибатч и складывать его во вторую очередь, из которой уже забирает данные основной процесс, работающий с GPU.
И, наконец, вооружившись сервером с 32 вычислительными ядрами и запустив генерацию дополненных данных в 32 процесса (+ два почти всегда ждущих на очереди или GPU) и загрузив его по самое не хочу, начиная со второй эпохи GPU почти перестало спать.
Ура, учим!
Итак, теперь можно научить уже не игрушечную модель нормальных размеров и, успех!, при правильной настройке она не переобучается и не болтается вне минимумов.
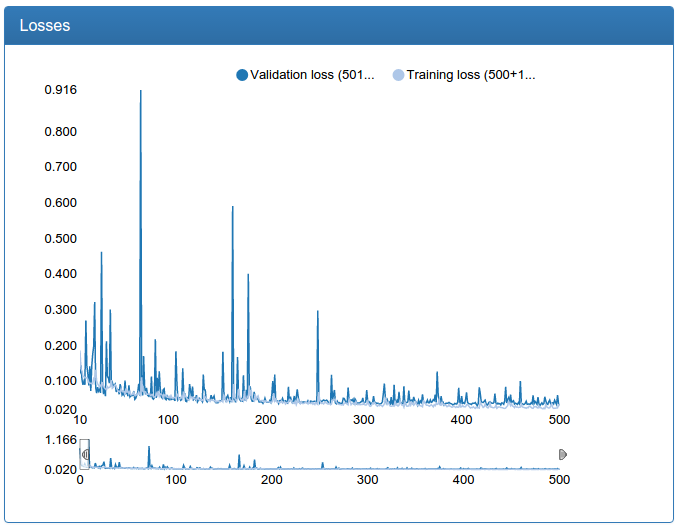
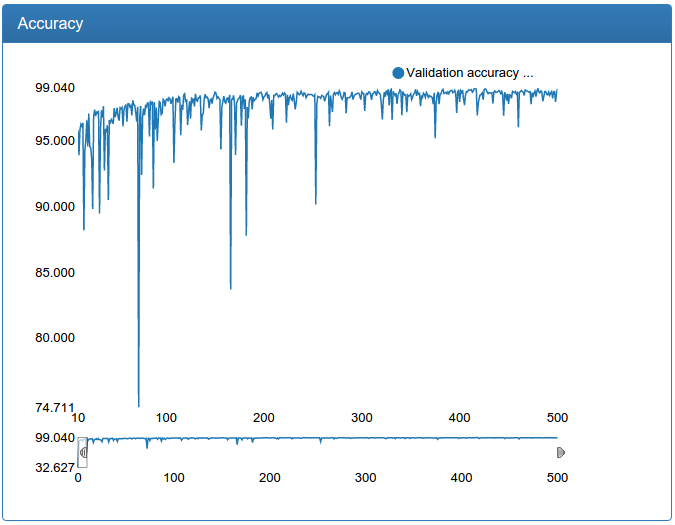

Здесь явно видно, как появляются стремные всплески в процессе обучения (почему — будет дальше), но в итоге все становится более или менее хорошо, хотя все-таки слегка болтуче.
В следующих сериях:
Еще больше данных, еще больше сетей, калибрация, поражающие воображение ансамбли сетей, современные технологии, больше картинок, девочек и драмы!