
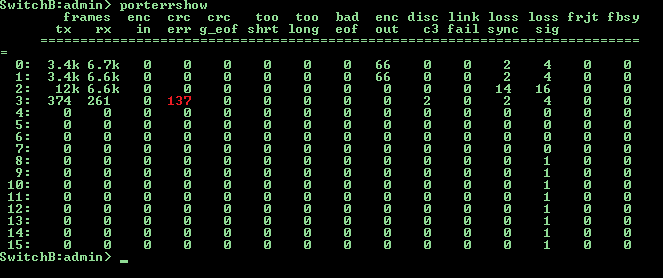
Нередко на сети хранения данных возникают такие неприятные вещи, как рост числа ошибок на портах и увеличение уровня затухания сигнала на sfp модулях. Принимая во внимание высокий уровень надежности SAN инфраструктуры, состоящей из двух и более фабрик, вероятность возникновения аварийной ситуации не так велика, но наложение негативных факторов может привести к потере данных или деградации производительности. К примеру, представьте себе ситуацию: на одной из фабрик проводится обновление FOS, все работает через вторую фабрику, а на ней между коммутатором к которому подключен дисковый массив и коммутатором к которому подключены серверы начинают быстро расти CRC ошибки на одном из транковых портов. Или еще хуже, пропадает линк из-за понижения уровня сигнала, вызванного повышением температуры SFP модуля, которая в свою очередь возросла из-за повысившейся утилизации данного канала. В таких случаях обычно говорят: «Ну кто же знал» или «100% надежных систем не бывает» и тд.
Грамотная архитектура + правильный мониторинг = отказоустойчивость
Итак проблема обозначена, необходимо разработать комплекс мер по повышению отказоустойчивости сети хранения данных, его можно разделить на два этапа:
- приведение архитектуры сети хранения данных в соответствие с «SAN best practices»
- развертывание системы мониторинга
Если про SAN best practices есть много литературы и курсов обучения, и можно пригласить крутых специалистов из интегратора для проведения экспертизы, то выбрать верный способ создать хорошую систему мониторинга SAN сети не так легко. Это можно объяснить жесткой привязкой: разработчик ПО — изготовитель коммутаторов. Я конечно не хочу сказать, что Cisco Fabric Manager или Brocade Network Advisor плохи, но они не позволяют делать все то, что необходимо на мой взгляд для повышения отказоустойчивости SAN сети.
Что делать
И так, задача поставлена, необходимо найти путь решения, часто это может осложняться отсутствием денег в бюджете на этот год, или неосведомленностью интегратора о существовании подходящего ПО, но это не проблема т.к. все необходимые компоненты есть в свободном доступе и требуется лишь заставить это все работать.
Разберем реализацию мониторинга CRC ошибок на портах SAN свичей brocade, большинство остальных параметров можно мониторить аналогичным образом.
Шаг первый, протокол сбора данных
Информацию о числе CRC ошибок можно получать с коммутаторов разными способами (snmp, https, telnet и ssh) мой выбор пал на последний т.к. telnet не безопасен и его лучше отключать, https сложен для извлечения конкретных значений, а snmp дерево может значительно меняться как на разных свичах, так и при переходе на новый FOS.
Шаг второй, метод сбора данных
Для работы с ssh лучше всего адаптирован linux в связке bash+expect, этим методом можно подключаться по ssh с диалоговым вводом команд.
Шаг третий, где хранить
Тут большой разницы нет, можно хранить хоть в текстовых файлах, но мы рассмотрим пример с mysql. Весь мониторинг реализован в двух скриптах:
porterrshow.sh — сбор информации и поиск инкремента значений CRC ошибок
expect.tcl — подключение по ssh
и трех txt файлах:
temp.txt — буфер данных
switches.txt — список san свичей в формате имя логин пароль на каждой строке
crc.txt — отчет о найденных CRC ошибках
Select запрос ищет инкремент роста CRC ошибок по сравнению с данными полученными один час назад, соответственно запуск скрипта необходимо производить один раз в час, причем начать и закончить свою работу скрипт должен в одном и том же часу. Данное ограничение можно легко обойти, если ввести поле порядкового номера запуска скрипта, либо потерять в производительности и задать более сложное условие выборки значений времени. На сервере должны быть установлены пакеты expect, mysql и ssh клиент. В базе данных dbname должен присутствовать пользователь user с правами на чтение и запись в таблицу tablename. В таблице tablename получаем данные аналогичные выводу команды porterrshow на свиче + дата и время.
porterrshow.sh
#!/bin/bash
rm /var/scripts/temp.txt #Удаляем ранее созданный temp.txt
while read line #Читаем строку из файла switches.txt
do read sw user pass <<< $line #Разбиваем строку на переменные
n=0 #Обнуляем счетчик
while read line; #Читаем строку из вывода expect.tcl
do array[n]="$line"; n=$[n+1]; #Заполняем массив строками из вывода expect.tcl
done < <(/var/scripts/expect.tcl $sw $user $pass porterrshow) #Отправляем данные в цикл
if echo ${array[4]} | grep -q '='; #Проверяем с какой строки начинается вывод полезной информации
then k=5;
else k=4;
fi;
for i in `seq $k $[n-1]`; #В последней строке данных нет
do read a1 a2 a3 a4 a5 a6 a7 a8 a9 a10 a11 a12 a13 a14 a15 a16 a17 a18 a19 <<< ${array[i]}; #Разбиваем строку на значения
(echo $sw,${a1%:},`date +%F`,`date +%T`,$a2,$a3,$a4,$a5,$a6,$a7,$a8,$a9,$a10,$a11,$a12,$a13,$a14,$a15,$a16,$a17) >> temp.txt #Формируем подгрузочный файл
done;
done < /var/scripts/switches.txt #Читаем файл со списком свичей
mysql -uuser -ppass dbname << EOF;
LOAD DATA LOCAL INFILE "temp.txt" INTO TABLE tablename FIELDS TERMINATED BY ',';
EOF
#Загружаем данные в БД
(mysql -uuser -ppass dbname << EOF
select new.switch, new.port, new.crcerr-old.crcerr from tablename new, tablename old where new.switch=old.switch and new.port=old.port and new.date=old.date and new.crcerr!=old.crcerr and new.crcerr!=0 and new.date=curdate() and hour(new.time)=hour(now()) and hour(old.time)=hour(now())-1;
EOF
) > /var/scripts/crc.txt #Проверяем инкремент CRC по портам и пишем отчет в файл
if grep -q 'switch' /var/scripts/crc.txt
then
cat /var/scripts/crc.txt | mailx -r SAN_Switch_CRC_Tester -s "CRC errors is increased" sanadmin1@mywork.com
fi
#Отправляем информацию администратору
expect.tcl
#!/usr/bin/expect
#Устанавливаем таймаут соединения 10 сек
set timeout 10
#Проверям число параметров передаваемых скрипту
if {$argc != 4} {
puts "Usage $argv0 host user pass command"
exit 1}
#Назначаем параметры переменным
set host [lindex $argv 0]
set user [lindex $argv 1]
set pass [lindex $argv 2]
set command [lindex $argv 3]
#Производим подключение по SSH
spawn ssh -oStrictHostKeyChecking=no -oCheckHostIP=no $user@$host $command
expect *assword:
send "$pass\r"
expect eof
Комментарии (28)

blind_oracle
12.04.2016 14:46+1Какой-то вы изобрели
ужасный колхозвелосипед.
а snmp дерево может значительно меняться как на разных свичах, так и при переходе на новый FOS.
Это что-то странное, есть MIB-ы в которых всё что надо прописано обычно достаточно жёстко. Если Brocade меняет MIBы на ходу, это камень в их огород. С таким же успехом может смениться и CLI, который вы в своих скриптах эксплуатируете.
Правильным способом было бы использовать Zabbix + Low level discovery по SNMP.
Оно и порты само обнаружит, и триггеры необходимые по шаблону создаст и письмо или смску пришлёт когда проблему обнаружит.
А то, что в статье — костыль.
ESergey
12.04.2016 15:42-1Если Brocade меняет MIBы на ходу, это камень в их огород. С таким же успехом может смениться и CLI, который вы в своих скриптах эксплуатируете.
Если вы обратите внимание ссылка то для каждой версии FOS свой MIB, и в этом нет ничего плохого, т.к. появляются новые опции и нужно как то продавать BNA)
С формулировкой «костыль» не согласен, система сама в себе, на FOS начиная с 6-ой версии вывод параится корректно, вся настройка и сопровождение заключается в добавлении новой строки в список свичей, никакого дискаверинга при добавлении нового порта в продуктивный vSAN — не требуется.blind_oracle
12.04.2016 15:52и в этом нет ничего плохого, т.к. появляются новые опции
Дерево OIDов конкретной железки обычно разделено на множество разных MIBов и добавление новых опций приводит к изменению лишь некоторых из них. В любом случае, как я говорил, с CLi может быть так же.
С формулировкой «костыль» не согласен, система сама в себе, на FOS начиная с 6-ой версии вывод параится корректно, вся настройка и сопровождение заключается в добавлении новой строки в список свичей, никакого дискаверинга при добавлении нового порта в продуктивный vSAN — не требуется.
Всё это прекрасно, но ваше решение от этого не становится менее велосипедным или костыльным.
Вместо того, чтобы почитать мануал к Zabbix и реализовать нормальную схему, в которой мониторились бы все необходимые параметры ваших коммутаторов, а не только CRC у SFP, вы написали костыль который делает только одно.
А если понадобится мониторить процессор, память или температуру — накидаете ещё пару костылей?ESergey
12.04.2016 16:02А если понадобится мониторить процессор, память или температуру — накидаете ещё пару костылей?
Для мониторинга показателей жизнедеятельности самого свича (ping, cpu, fan, ps, и тд.) как раз лучше использовать zabbix или подобное. Здесь все просто, добавил устройство, и забыл.blind_oracle
12.04.2016 16:09Чем же ошибки CRC на портах так принципиально отличаются от других параметров?
ESergey
12.04.2016 16:33Процессор, вентилятор или блок питания, присутствует в конфигурации свича изначально. И если даже блок питания воткнули потом, все равно будет ветка состояния всех вентиляторов, БП, CPU и тд. и если в этой ветке видим красный флаг, то что-то не в порядке. При использовании vSAN, при первичном дискаверинге устройства, порты находящиесы в другом vSAN не будут найдены и появятся только при повторном дискаверинге или прописыванию ветки вручную.
blind_oracle
12.04.2016 16:37+1В заббиксе обнаружение новых итемов на хостах происходит с некоторой заданной периодичностью, допустим раз в 10 минут. Причём для каждого типа можно указать свою периодичность. Так что не вижу никакой проблемы — все нужные порты обнаружатся автоматически через заданное время.
ESergey
12.04.2016 17:08В теории да, а на практике даже ручной дискаверинг не всегда отрабатывал корректно. Можно было углубиться в допиливание имеющийся системы, но непонятно сколько времени на это бы ушло + интереснее было решить проблему подойдя с другой стороны.
blind_oracle
12.04.2016 17:24Нет никаких проблем с дискаверингом в заббиксе. Он проходится по SNMP дереву указанному и формирует необходимые итемы и триггеры, если их нет. Всё.
ESergey
12.04.2016 15:55В комментариях через один упоминание про zabbix, а есть ли живые примеры реализации на zabbix или zabbix подобных системах, мониторинга crc ошибок, и уровня затухания сигнала на sfp модулях?
blind_oracle
12.04.2016 16:12У меня это всё прекрасно мониторилось именно Zabbix-ом, я же не просто теорию вещаю.
Железяки были, если говорить про SAN, Cisco MDS 9148. Но и Ethernet коммутаторы мониторились аналогично, принципиальной разницы между ними никакой нет.ESergey
12.04.2016 16:37Виртуальные фабрики использовались?
blind_oracle
12.04.2016 16:46Использовался дефолтный VSAN=1, других не было. Мне кажется это не особо относится к мониторингу параметров SFP на коммутаторах.
KorP
В любой инфраструктуре должно быть средство централизованного мониторинга, Nagios и Zabbix являются бесплатными и широкоиспользуемыми решениями, которое это в состоянии мониторить…
ESergey
Zabbix Nagios и Cacti системы ориентированные на работу с SNMP и Syslog, если сеть хранения данных не большая, то они подойдут, но если в сети сотни коммутаторов этот метод не будет оптимальным т.к. в мониторинге нужно описывать каждый порт, и если он не был в нужном vSAN изначально, то автоматически он не отдискавериться
blind_oracle
Это почему?
ESergey
Хороший вопрос, иногда проходит, иногда приходиться пересоздавать устройство, но это не принципиально, главное что все равно приходиться подкручивать мониторинг, при изменении конфигурации vSAN. Если таких изменений много, то это дополнительные трудозатраты и увеличение влияния человеческого фактора. А при жестком правиле составления имени свича, можно вообще ничего не менять в мониторинге, все появится само)
Добавил имя в ДНС, и он уже на мониторинге.
KorP
Если у вас такая инфраструктура, что одних только SAN коммутаторов — сотни, и вы это мониторите подобными скриптами… Ну жалко мне вас, что ещё сказать. Ну и видимо вам нужны хорошие специалисты по Zabbixу. У нас конечно не сотни коммутаторов, но проблем мы не испытываем никаких.
ESergey
Коммутаторы мониторятся одновременно 3-мя системами, каждая выполняет свои роли: одна мониторит линки и жизненно важные показатели свичей, вторая собирает полные метрики фабрик, но плохо умеет предупреждать о возможной аварии, третья как раз описана в данной статье, уже внедряется четвертая, которая должна заменить все остальные, но надежна невелика.
KorP
При всём уважении, но называть этот наколенный скрипт СИСТЕМОЙ и ставить её в один ряд с полноценными система мониторинга… или остальные 2 системы — аналогичные скрипты?
Очень интересно было бы узнать где вы так инфраструктуру мониторите
ESergey
Остальные 3 системы — лицензионное ПО купленное за деньги, причем не малые. Скрипт можете называть как угодно, иногда чем проще тем лучше. Один скрипт конечно не система, но десяток подобных скриптов позволяет автоматизировать много полезных задач. Zabbix нам в этом не помог, но мы на него не в обиде и удачно пользуем для других целей. По предыдущему опыту внедрения систем управления blade серверами, могу сказать одно: тот функционал, который был нам нужен, за пару дней мы написали на коленке сами еще 5 лет назад, у вендора он появился только год назад, и то за деньги.
KorP
Остальные 3 системы — лицензионное ПО купленное за деньги
третья как раз описана в данной статье
нет-нет, вы не подумайте что я к словам то придираюсь, я просто пытаюсь понять — что же за такие бестолковые системы, за немалые, как я думаю деньги, не в состоянии покрыть ваши нужды, которые покрываются данным скриптом, накиданном за сколько? за обеденный перерыв? Я повторю вопрос — может вам просто найти более квалифицированных специалистов по системам мониторинга? У нас заббикс прекрасно отлавливает ошибки на брокейдах, а вы упорно продолжаете убеждать читателей, что ваш скрипт на много лучше любой системы мониторинга и в частности заббиска. Где тут ребята из Badoo? Они вас быстро на путь истинный наставят :)))
ESergey
Я не никого не убеждаю
я просто уверенв том, что заббикс хуже, это прекрасная система, я хотел рассказать, что есть другой способ, у него есть как плюсы так и минусы.Вполне толковые системы, но одна не умеет автоматом дискаверить новые порты, а вторая бывает запаздывает с оповещением.
В скриптовом методе есть еще преимущества, например можно настроить сверку залогиненных устройств по WWN, проверку системного таймера, проверку целостности фабрики, отслеживать появление новых WWN, и много еще чего хорошего. Как сделать это на заббиксе я не знаю(
Кстати если есть контакты людей, которые могут написать подобную вещь за обеденный перерыв (45 мин)
и не хотят очень много денег, поделитесь пожалуйста.vadoo
В том же cacti данные можно получать через скрипт. Например, в случае, если с snmp надо хитро работать
ESergey
Почти в каждой системе мониторинга есть такая возможность, вопрос как потом будет обрабатываться полученный ответ.
DenIvEvg
Вы меня опередили… :)