

Мы уже привыкли к постоянному и безудержному росту объёма информации в сети. Остановить или замедлить этот процесс никому не под силу, да и смысла в этом нет. Все знают, что интернет огромен, как по количеству данных, так и по поголовью сайтов. Но насколько он велик? Можно ли как-то оценить, хотя бы приблизительно, сколько петабайт бегает по кабелям, опутывающим планету? Сколько сайтов ждут посетителей на сотнях тысяч серверов? Этим вопросом задаются многие, в том числе и учёные, которые пытаются разработать подходы к оценке безбрежного моря информации, называемого интернетом.
Всемирная сеть — очень оживлённое место. Согласно сервису Internet Live Stats, каждую секунду в Google делается более 50 000 поисковых запросов, просматривается 120 000 видео на Youtube, отправляется почти 2,5 млн электронных писем. Да, весьма впечатляет, но всё же эти данные не позволяют в полной мере представить себе размеры интернета. В сентябре 2014 года общее количество сайтов перевалило за миллиард, и сегодня их примерно 1,018 млрд. А ведь здесь ещё не подсчитана так называемая «глубокая паутина» (Deep Web), то есть совокупность сайтов, не индексируемых поисковиками. Как указывается на Википедии, это не синоним «тёмной паутины», к которой в первую очередь относятся ресурсы, на которых ведётся всевозможная противоправная деятельность. Тем не менее, контент в «глубокой паутине» может быть как совершенно безобидным (например, онлайновые базы данных), так и совершенно непригодным для глаз законопослушной публики (к примеру, торговые площадки чёрного рынка с доступом только через Tor). Хотя Tor’ом пользуются далеко не только нечистые на руку люди, но и вполне чистые перед законом пользователи, алчущие сетевой анонимности.
Конечно, вышеприведённая оценка численности веб-сайтов является приблизительной. Сайты возникают и исчезают, к тому же размеры глубокой и тёмной паутин определить практически невозможно. Поэтому даже приблизительно оценивать размеры сети по этому критерию весьма непросто. Но одно несомненно — сеть постоянно растёт.
Всё дело в данных
Если одних только веб-сайтов более миллиарда, то отдельных страницы гораздо больше. Например, на ресурсе WorldWideWebSize представлена оценка размера интернета именно по количеству страниц. Методика подсчёта разработана Морисом де Кундером (Maurice de Kunder), опубликовавшим её в феврале этого года. Вкратце: сначала система осуществляет поиск в Google и Bing по списку из 50 распространённых английских слов. На основании оценки частоты этих слов в печатных источниках полученные результаты экстраполируются, корректируются, вводится поправка на совпадения результатов по разным поисковикам, и в результате получается некая оценка. На сегодняшний день размер интернета оценивается в 4,58 млрд отдельных веб-страниц. Правда, речь идёт об англоязычном сегменте сети. Для сравнения, там же указан размер голландского сегмента — 225 млн страниц.
Но веб-страница в качестве единицы измерения — вещь слишком абстрактная. Куда интереснее оценить размер интернета с точки зрения объёма информации. Но и здесь есть нюансы. Какую именно информацию считать? Передаваемую или обрабатываемую? Если, к примеру, нас интересует информация передаваемая, то и здесь можно считать по-разному: сколько данных может быть передано за единицу времени, или сколько передано фактически.
Одним из способов оценки циркулирующей в интернете информации является измерение трафика. Согласно данным Cisco, к концу 2016 года по всему миру будет передано 1,1 зеттабайта данных. А в 2019 году объём трафика удвоится, достигнув 2 зеттабайт в год. Да, это ОЧЕНЬ много, но как можно попытаться представить себе 1021 байт? Как услужливо подсказывается в инфографике от той же Cisco, 1 зеттабайт эквивалентен 36 000 лет HDTV-видео. И понадобится 5 лет для просмотра видео, передаваемого по миру каждую секунду. Правда, там было предсказано, что этот порог трафика мы перейдём в конце 2015, ну ничего, немного не угадали.
В 2011 году было опубликовано исследование, согласно которому, в 2007 году человечество хранило на всех своих цифровых устройствах и носителях примерно 2,4 х 1021 бит информации, то есть 0,3 зеттабайта. Суммарная вычислительная мощность мирового парка вычислительных устройств «общего назначения» достигала 6,4 х 1012 MIPS. Любопытно, что 25% от этой величины приходилось на игровые приставки, 6% — на мобильные телефоны, 0,5% — на суперкомпьютеры. При этом суммарная мощность специализированных вычислительных устройств оценивалась в 1,9 х 1014 MIPS (на два порядка больше), причём 97% приходилось на… видеокарты. Конечно, с тех пор прошло целых 9 лет. Но очень примерно оценить текущее положение дел можно исходя из того, что за период 2000-2007 среднегодовой рост объёмов хранимой информации составил 26%, а вычислительной мощности — 64%. Учитывая развитие и удешевление носителей, а также замедление прироста вычислительной мощности процессоров, предположим, что количество информации на носителях растёт на 30% в год, а вычислительная мощность — на 60%. Тогда объём хранимых данных в 2016 году можно оценить на уровне 1,96 х 1022 бит = 2,45 зеттабайта, а вычислительную мощность персональных компьютеров, смартфонов, планшетов и приставок на уровне 2,75 х 1014 MIPS.
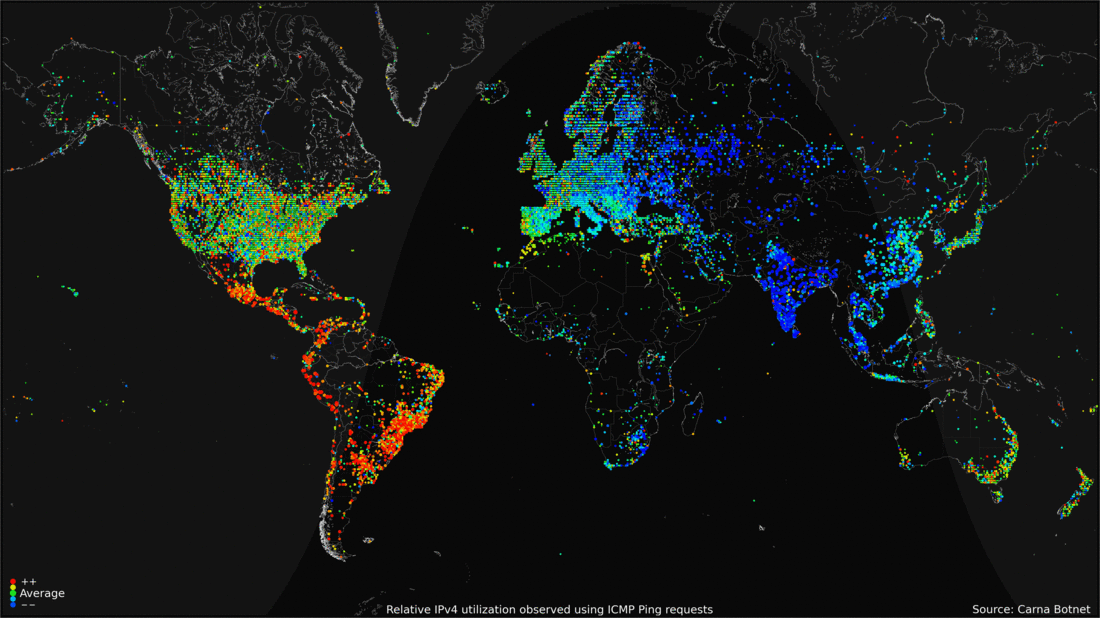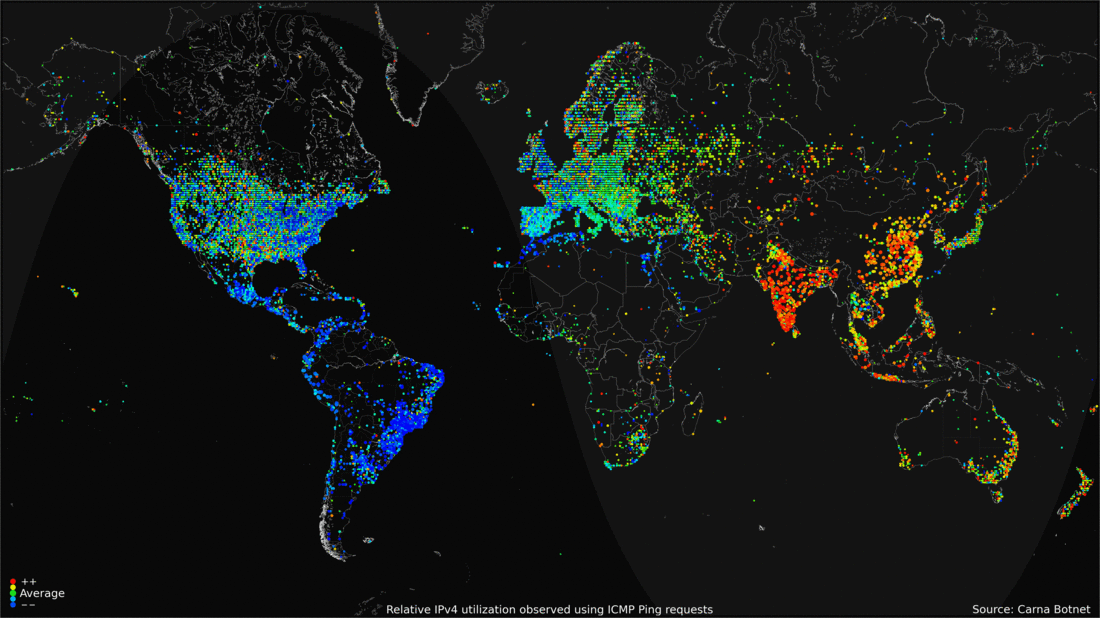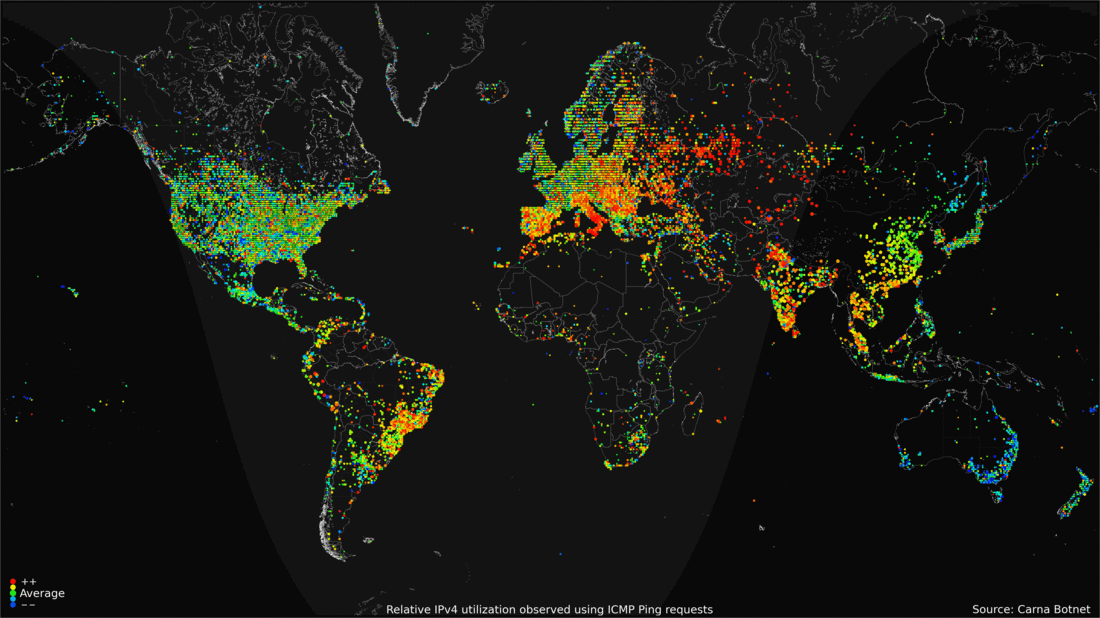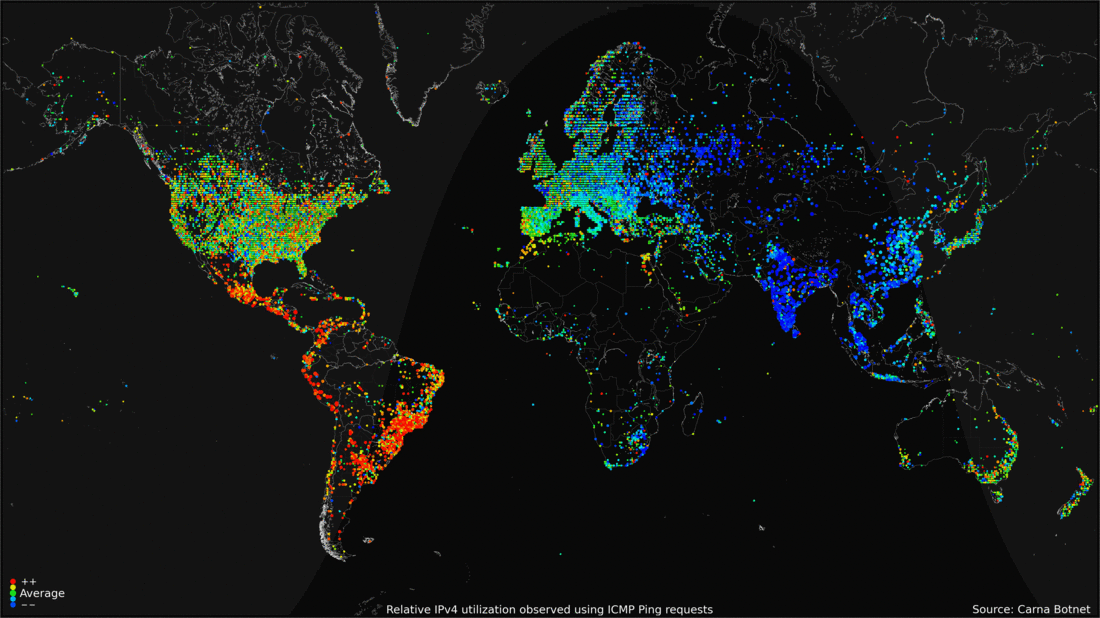
В 2012 году появилось любопытное исследование количества используемых на тот момент IPv4-адресов. Изюминка в том, что информация была получена с помощью глобального сканирования интернета силами огромной хакерской ботнет-сети из 420 тыс. узлов.
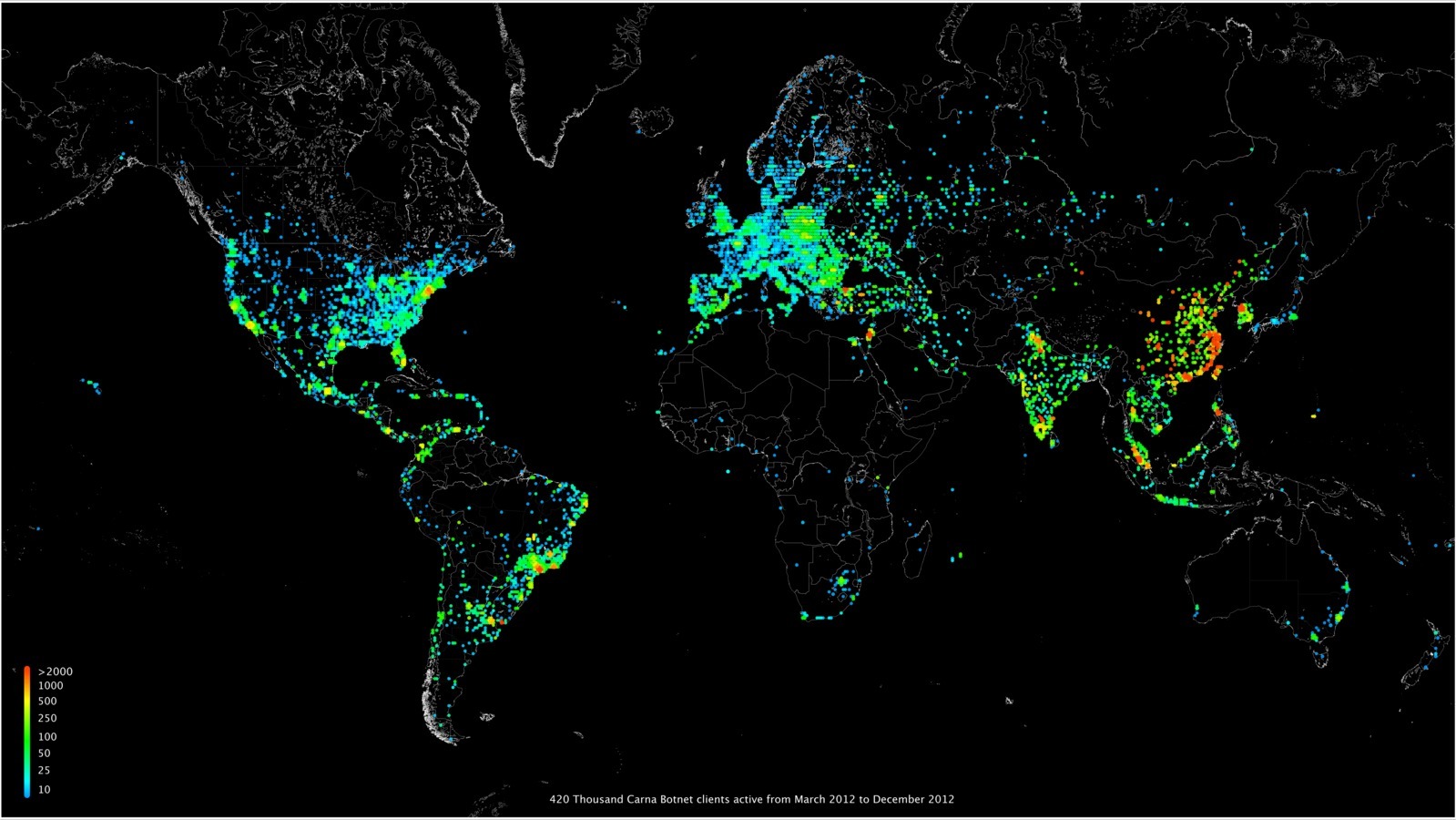
После сбора информации и алгоритмической обработки выяснилось, что одновременно активными были около 1,3 млрд IP-адресов. Ещё 2,3 млрд бездействовали.
Физическое воплощение
Несмотря на восход цифрового века, для многих из нас биты и байты остаются понятиями несколько абстрактными. Ну, раньше память измеряли мегабайтами, теперь гигабайтами. А что если попробовать представить размер интернета в каком-то вещественном воплощении? В 2015 году двое учёных предложили использовать для оценки настоящие бумажные страницы А4. Взяв за основу данные с вышеупомянутого сервиса WorldWideWebSize, они решили считать каждую веб-страницу эквивалентной 30 страницам бумажным. Получили 4,54 х 109 х 30 = 1,36 х 1011 страниц А4. Но с точки зрения человеческого восприятия это ничем не лучше тех же байтов. Поэтому бумагу привязали к… амазонским джунглям. Согласно расчёту авторов, для изготовления вышеуказанного количества бумаги нужно 8 011 765 деревьев, что эквивалентно 113 км2 джунглей, то есть 0,002% от общей площади амазонских зарослей. Хотя позднее в газете Washington Post предположили, что 30 страниц — слишком много, и одну веб-страницу правильнее приравнять к 6,5 страницам А4. Тогда весь интернет можно распечатать на 305,5 млрд бумажных листов.
Но всё это справедливо лишь для текстовой информации, которая занимает далеко не самую большую долю от общего объёма данных. Согласно Cisco, в 2015 году на одно только видео приходилось 27 500 петабайт в месяц, а совокупный трафик веб-сайтов, электронной почты и «данных» — 7 700 петабайт. Немногим меньше пришлось на передачу файлов — 6 100 петабайт. Если кто забыл, петабайт равен миллиону гигабайт. Так что амазонские джунгли никак не позволят представить объёмы данных в интернете.
В упомянутом выше исследовании от 2011 года предлагалось визуализировать с помощью компакт-дисков. Как утверждают авторы, в 2007 году 94% все информации было представлено в цифровом виде — 277,3 оптимально сжатых эксабайта (термин, обозначающий сжатие данных с помощью наиболее эффективных алгоритмов, доступных в 2007 году). Если записать всё это богатство на DVD (по 4,7 Гб), то получим 59 000 000 000 болванок. Если считать толщину одного диска равной 1,2 мм, то эта стопка будет высотой 70 800 км. Для сравнения, длина экватора равна 40 000 км, а общая протяжённость государственной границы России — 61 000 км. Причём это объём данных по состоянию на 2007 год! Теперь попробуем таким же образом оценить общий объём трафика, который прогнозируется на этот год — 1,1 зеттабайта. Получим стопку DVD-дисков высотой 280 850 км. Тут уже впору переходить на космические сравнения: среднее расстояние до Луны составляет 385 000 км.
Другая аналогия: общая производительность всех вычислительных устройств в 2007 году достигала 6,4 х 1018 инструкций/сек. Если принять, что в человеческом мозге 100 млрд нейронов, каждый из которых имеет 1000 связей с соседними нейронами и посылает до 1000 импульсов в секунду, то максимальное количество нейронных импульсов в мозге равно 1017.

Глядя на все эти десятки в больших степенях возникает устойчивое ощущение информационного потопа. Радует хотя бы то, что наши вычислительные мощности растут быстрее, чем идёт накопление информации. Так что остаётся надеяться лишь на то, что нам удастся разработать системы искусственного интеллекта, которые будут способны худо-бедно обрабатывать и анализировать всё увеличивающиеся объёмы данных. Ведь одно дело, научить компьютер анализировать текст, а что делать с изображениями? Не говоря уже о когнитивной обработке видео. В конце концов, миром будут править те, кто сможет извлечь как можно больше пользы из всех этих петабайт, заполняющих всемирную сеть.
Комментарии (17)

norlin
28.04.2016 12:41А в этих оценках учитывается дублирование информации? И если да – то на каком уровне? Например, 2 одинаковых видео в разном качестве — считать дубликатами или нет?
Вообще, интересно было бы посмотреть на оценку (и методики оценки) объёма уникальной информации в сети. И насколько оно соответствует уникальной информации, в принципе известной человечеству (другими словами – оценить объём «неоцифрованой» уникальной информации).
Vjatcheslav3345
28.04.2016 13:05Википедия говорит — «В то же время, информация из баз данных, доступная пользователям через поисковые веб-формы (но не по гиперссылкам), остаётся недоступной для робота, неспособного в режиме реального времени правильно заполнить форму значениями (другими словами, сформировать запрос к базе данных). Таким образом, значительная часть Всемирной паутины оказывается скрыта от поисковых роботов. Используя аналогию, информация, будучи недоступной для поисковых систем, находится «на глубине» (от англ. deep)»
А разве нельзя привязывать к полям формы ключевые слова-значения типа «Фамилия», "№ автомобиля" и тогда и робот сможет спросить у баз то что спросил у него человек и проиндексировать её содержимое и составить, скажем, частотные словари.
taujavarob
28.04.2016 20:05>А разве нельзя привязывать к полям формы ключевые слова-значения типа «Фамилия», "№ автомобиля" и тогда и робот сможет спросить у баз то что спросил у него человек и проиндексировать её содержимое и составить, скажем, частотные словари.
Поступают иначе — роботу для его (робота) индексирования, предлагают информацию в виде специально подготовленной страницы (той, что получит и пользователь обратившись к базе с запросом) и робот эту страницу и покажет на своей( своей поисковой системе — Гугл и т.п.) странице выдачи результатов поиска.

strelokr
28.04.2016 13:11Интересная инфографина активности в день. Заметно что дальний восток и Восточная европа имеют тенденцию к серьезному увеличению количества активных клиентов ближе к концу дня. Люди приходят домой, включают компы, планшеты и прочее.
Mr_Destiny
28.04.2016 13:20Забавно то что индусы просыпаются почти все одновременно, а к вечеру активность сворачивается.
%здесь может быть глупая шутка про индийских программистов%, но я думаю все более прозаично — у большинства есть доступ к интернету только с работы и/или нет времени на развлечения вечером.
Сейчас присмотрелся — у американцев тоже нет особого всплеска активности по вечерам, только утром, а потом затухание.Mad__Max
30.04.2016 03:23На «синхронности» индусов еще существенно сказывается как минимум то, что такая немаленькая страна целиком в одном единственным часом поясе живет — типовой рабочий день начинается и заканчивается на всей территории одновременно. Поэтому нет «волны» прокатывающейся вслед за солнцем как к примеру в европе на которую 4 часовых пояса приходится.

pudovMaxim
28.04.2016 13:21Интересно наблюдать активность на анимации. В США в течении суток относительно мягкие изменения, но зато есть круглосуточные горячие точки. А вот Европа и Азия очень сильно меняют активность с утра к вечеру. И еще очень видно, что под вечер во всем мире нагрузка увеличивается, а в США слегка падает.
localhost_maxigame
28.04.2016 13:45Интересно, сколько из этого объема занимает действительно полезная информация, а сколько страницы вида «отправьте СМС с текстом...»
JJJJoke
28.04.2016 14:07Судя по последней картинке, Земля превращается в огромную сеть (нейронную?). Есть ли сравнения головного мозга и земли со всей ее интернет-инфраструктурой по какой-либо метрике?
P.S.: Скоро наша планета превратится в «живой мозг» аналогично сюжету «Аватара».
Sild
28.04.2016 14:11Судя по растранжириванию ресурсов, более вероятно превращение планеты в мертвый мозг.

sumanai
28.04.2016 16:30> P.S.: Скоро наша планета превратится в «живой мозг» аналогично сюжету «Аватара».
И будет требовать всё больше смешных котиков с ютуба!
Enam
28.04.2016 14:07Интересно, не были ли нарушены чьи-либо права использованием кадра из фильма про Плоский мир (поправьте, если я ошибаюсь)?
KennyGin
28.04.2016 20:47А вам правда это интересно?
Enam
29.04.2016 16:57Ну я же поинтересовался, вдруг кто-то владеющей полной информацией уточнит. Уже привычно смотрятся фотографии из стоков с указанием стока/автора во многих новостях, за исключением понятных случаев: сгенерированные изображения (графики), скриншоты, собственные фотографии.
Правовой вопрос использования изображений мне понятен на бытовом уровне; в качестве основного правила: «не твоё — не трогай».
Uris
Любопытно знать сколько электроэнергии потребляет сеть и каков баланс в мировом энергетическом балансе. 3%? 5%? 25%?
Kanut79
Если я не совсем ошибаюсь, то 5% перешагнули где-то четыре-пять лет назад. Просто тогда об этом передача была и как-то цифра в памяти осталась.
Но хоть убей не помню как они там это рассчитывали.