

Всем привет!
Сегодня мы поговорим про распознавание доменов, сгенерированных при помощи алгоритмов генерации доменных имен. Посмотрим на существующие методы, а также предложим свой, на основе рекуррентных нейронных сетей. Интересно? Добро пожаловать под кат.
Алгоритмы Генерации Доменных Имен (DGA) представляют собой алгоритмы, используемые вредоносным программным обеспечением (malware) для генерации большого количества псевдослучайных доменных имен, которые позволят установить соединение с управляющим командным центром. Тем самым, они обеспечивают мощный слой защиты инфраструктуры для вредоносных программ. На первый взгляд, концепция создания большого количества доменных имен для установки связи не кажется сложной, но методы, используемые для создания произвольных строк, часто скрываются за разными слоями обфускации. Это делается для усложнения процесса обратной разработки и получения модели функционирования того или иного семейства алгоритмов.
Например, одним из первых случаев был компьютерный червь Conficker в 2008 году. Сегодня насчитываются подобных вредоносных программ десятки, каждая из которых представляет серьезную угрозу. Помимо этого, алгоритмы совершенствуются, их обнаружение становится сложнее.
Общий принцип работы
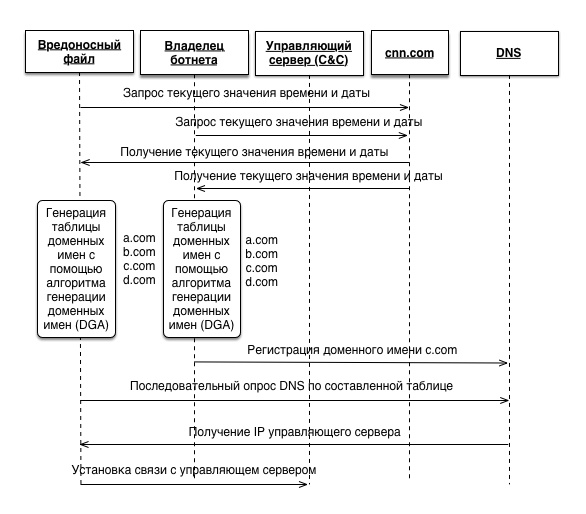
В общем случае вредоносному файлу необходим seed для инициализации генератора псевдослучайных чисел (ГПСЧ). В качестве seed может выступать любой параметр, который будет известен вредоносному файлу и владельцу ботнета. В нашем случае — это значение текущей даты и времени, взятые с ресурса cnn.com. Используя одинаковые векторы инициализации, вредоносный файл и владелец ботнета получают идентичные таблицы доменных имен. После этого владельцу ботнета достаточно зарегистрировать лишь один домен для того, чтобы вредоносный файл, рекурсивно посылая запросы к DNS-серверу, получил IP-адрес управляющего сервера для дальнейшей установки с ним соединения и получения команд.
Распознавание
В настоящее время существует множество работ, связанных c анализом алгоритмов генерации доменных имен. Некоторые из них используют методы Машинного обучения. В основном, применяются всем известные модели, которые можно встретить в среде обработки и анализа естественных языков, — модели n-gramm, TF-IDF и др.
Однако встаёт вопрос обучающей выборки. Наша выборка будет состоять из 2 классов. Первый — Legit, был взят из списка Alexa Top Million. Второй — DGA, был составлен путем обратной разработки алгоритмов генерации вредоносных доменных имен, взятых из экземпляров вредоносных программ, существующих в сети Интернет, и доступен в репозитории (https://github.com/andrewaeva/DGA).
Для начала мы попробовали подход, описанный ребятами из Сlicksecurity. Ими предлагается использование следующего списка параметров: длина, энтропия, модель TF-IDF с выделением N-gram. Первым параметром выступает длина доменного имени. Второй параметр — энтропия. Далее, была рассмотрена модель N-gram. Каждый n-gram (от 3 до 5) был представлен как вектор в n-мерном пространстве, и расстояние между ними было рассчитано с помощью скалярного произведения этих векторов. Это довольно просто реализуется при помощи библиотеки Scikit Learn.
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
alexa_vc = CountVectorizer(analyzer='char', ngram_range=(3, 5), min_df=1e-4, max_df=1.0)
counts_matrix = alexa_vc.fit_transform(dataframe_dict['alexa']['domain'])
alexa_counts = np.log10(counts_matrix.sum(axis=0).getA1())
dict_vc = CountVectorizer(analyzer='char', ngram_range=(3, 5), min_df=1e-5, max_df=1.0)
counts_matrix = dict_vc.fit_transform(word_dataframe['word'])
dict_counts = np.log10(counts_matrix.sum(axis=0).getA1())
all_domains['alexa_grams'] = alexa_counts * alexa_vc.transform(all_domains['domain']).T
all_domains['word_grams'] = dict_counts * dict_vc.transform(all_domains['domain']).T
all_domains['diff'] = all_domains['alexa_grams'] - all_domains['word_grams']В результате мы получили дополнительно 3 параметра: Alexa gram — косинусное расстояние до словаря, состоящего из доменов Alexa Top Million, Word gram — косинусное расстояние до специально составленного словаря, состоящего из наиболее употребительных слов и фраз, и параметр diff = alexa gram — word gram.
Для каждого из параметров мы построили наглядные графики. Не забудьте посмотреть :)
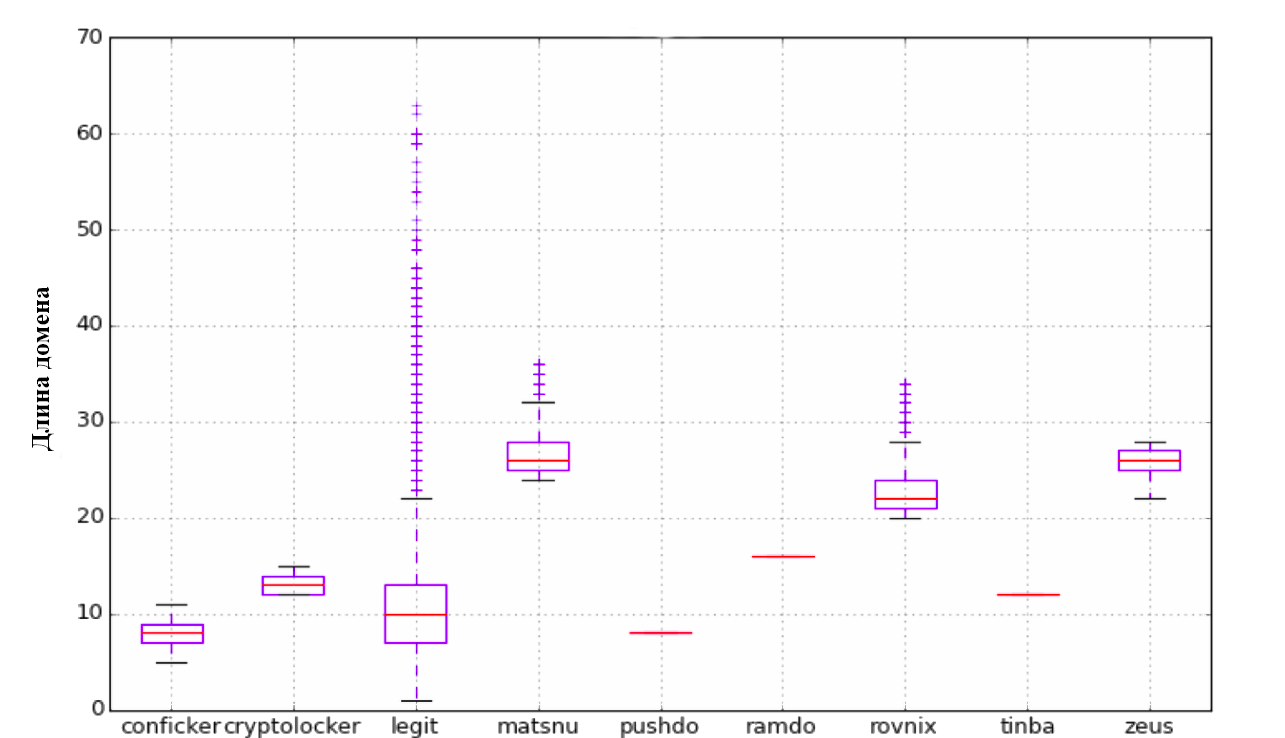
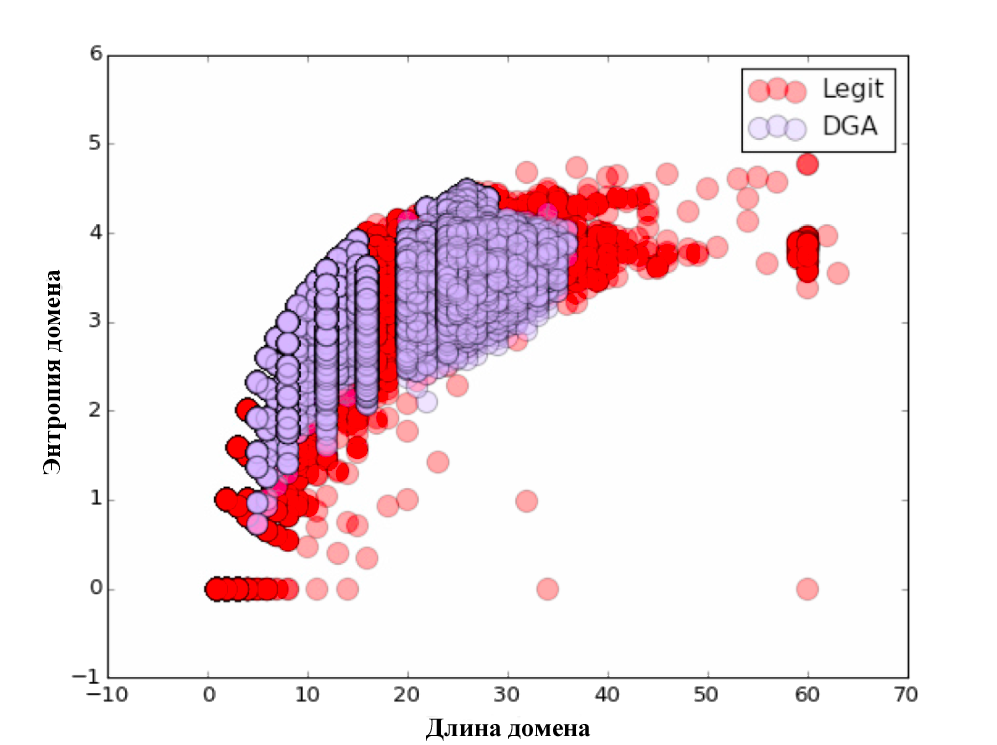

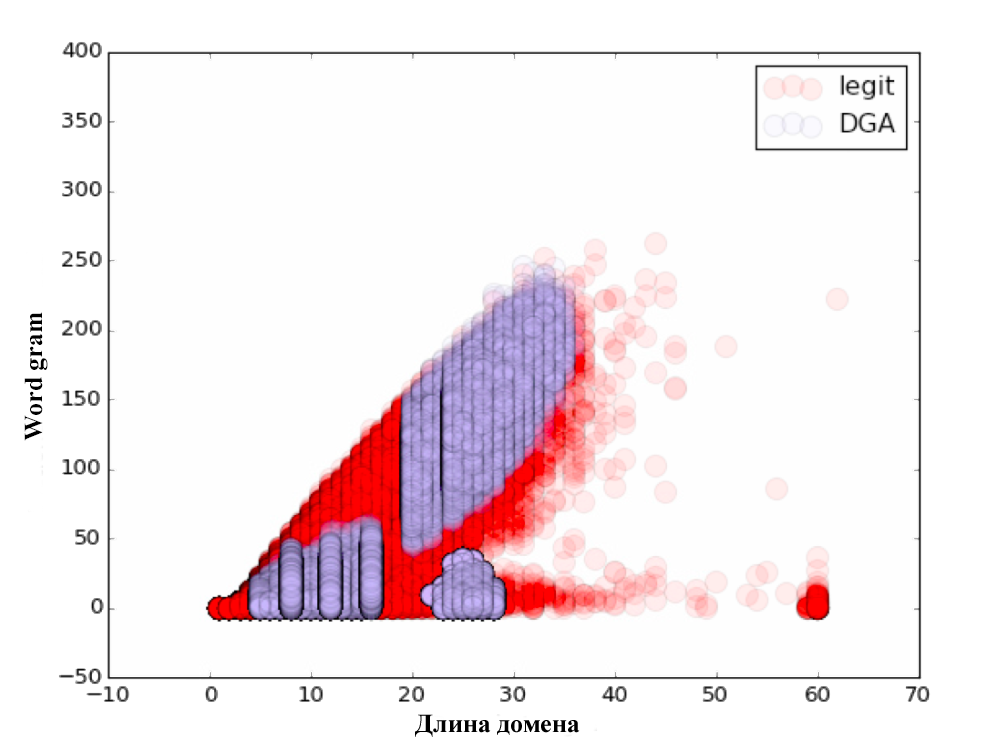
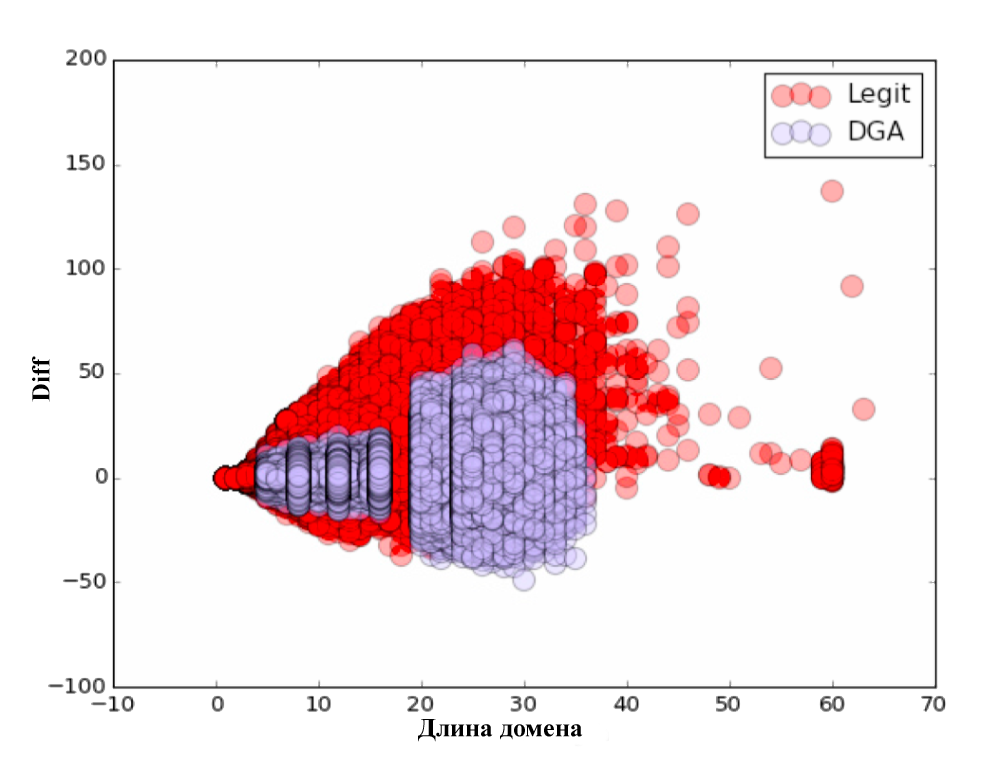
Сама классификация проводилась по принципу 80/20, т.е. обучение происходило на 80% исходных данных, а тестирование алгоритма — на оставшихся 20%. После проверки качества классификации были получены следующие результаты:
| Алгоритм | Точность классификации |
|---|---|
| Logistic Regression | 87% |
| Random Forest | 95% |
| Naive Bayes | 75% |
| Extra Tree Forest | 94,6% |
| Voting Classification | 94,7% |
Мы подумали, почему до сих пор никто не попробовал использовать нейронные сети? Нужно пробовать!
Нейронные сети
Для решения нашей проблемы мы задействовали рекуррентную нейронную сеть. Рекуррентные нейронные сети, главным образом, отличаются наличием цикла. Они позволяют сохранять и использовать информацию, полученную из предыдущих шагов нейронной сети. Каждый домен в нашем случае рассматривается как последовательность символов из фиксированного словаря, которая подаётся на вход рекуррентной нейронной сети. Обучение такой нейронной сети производится методом обратного распространения ошибки таким образом, чтобы максимизировать вероятность правильного выбора соответствующего класса.
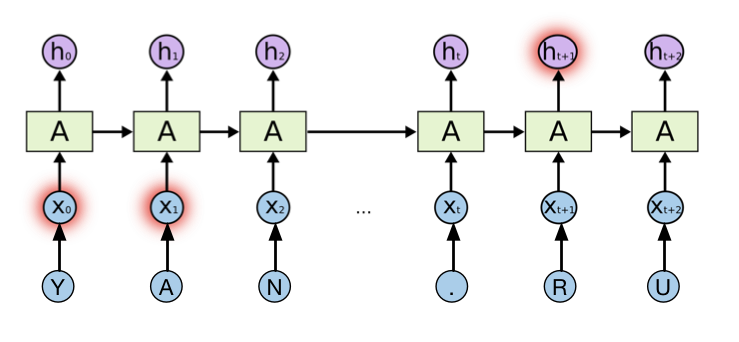
Рекуррентная нейронная сеть и Yandex.ru
Такая архитектура нейронной сети может анализировать информацию, поданную ранее для анализа данных в настоящий момент времени. Однако, на практике оказывается, что если разрыв между прошлой информацией и настоящей достаточно велик, то эта связь теряется, и подобная сеть неспособна её обрабатывать. Решение этой проблемы было найдено в 1997 году учеными Hochreiter & Schmidhuber. В своей работе они предложили новую модель рекуррентной нейронной сети, а именно Long short-therm memory. В настоящее время данная модель широко используется для решения всевозможных классов задач, таких как: распознавание речи, обработка естественных языков и др. LSTM состоит из ряда постоянно связанных подсетей, известных как блоки памяти. Вместо одного слоя неи?роннои? сети, в данной? модели используется 4 слоя, взаимодеи?ствующих особым образом. В своей модели мы будем использовать разновидность модели LSTM, а именно Gated Recurrent Unit (GRU). Подробнее о LSTM и GRU можно почитать в замечательной статье (http://colah.github.io/posts/2015-08-Understanding-LSTMs/), а мы двинемся дальше.
Для реализации нашей модели будем использовать Python и всеми любимые библиотеки Theano (https://pypi.python.org/pypi/Theano) и Lasagne (https://pypi.python.org/pypi/Lasagne/0.1).
Загрузим наши данные в память (да, мы ленивые) и проведем предобработку:
import numpy as np
import pandas as pd
import theano
import theano.tensor as T
import lasagne
dataset = pd.read_csv('/home/andrw/dataset_all_2class.csv', sep = ',')
dataset.head()
chars = dataset['domain'].tolist()
chars = ''.join(chars)
chars = list(set(chars))
print chars
# ['-', '.', '1', '0', '3', '2', '5', '4', '7', '6', '9', '8', '_', 'a', 'c', 'b', 'e', 'd', 'g', 'f', 'i', 'h', 'k', 'j', 'm', 'l', 'o', 'n', 'q', 'p', 's', 'r', 'u', 't', 'w', 'v', 'y', 'x', 'z']
classes = dataset['class'].tolist()
classes = list(set(classes))
print classes
#['dga', 'legit']Теперь закодируем наш домен в последовательность и сформируем массивы X, y, маску M. Зачем нужна маска? Всё просто, Карл! Домены-то различной длины.
char_to_ix = { ch:i for i,ch in enumerate(chars) }
ix_to_char = { i:ch for i,ch in enumerate(chars) }
class_to_y = { cl:i for i,cl in enumerate(classes) }
NUM_VOCAB = len(chars)
NUM_CLASS = len(classes)
NUM_CHARS = 75
N = len(dataset.index)
X = np.zeros((N, NUM_CHARS)).astype('int32')
M = np.zeros((N, NUM_CHARS)).astype('float32')
Y = np.zeros(N).astype('int32')
for i, r in dataset.iterrows():
inputs = [char_to_ix[ch] for ch in r['domain']]
length = len(inputs)
X[i,:length] = np.array(inputs)
M[i,:length] = np.ones(length)
Y[i] = class_to_y[r['class']]Сформируем тренировочную и тестовую выборку:
rand_indx = np.random.randint(N, size=N)
X = X[rand_indx,:]
M = M[rand_indx,:]
Y = Y[rand_indx]
Ntrain = int(N * 0.75)
Ntest = N - Ntrain
Xtrain = X[:Ntrain,:]
Mtrain = M[:Ntrain,:]
Ytrain = Y[:Ntrain]
Xtest = X[Ntrain:,:]
Mtest = M[Ntrain:,:]
Ytest = Y[Ntrain:]Теперь все готово, чтобы описать архитектуру нашей сети, которая выглядит, как показано на рисунке. Для классификации мы будем передавать состояние последнего скрытого слоя в Softmax слой, выход которого мы можем интерпретировать как вероятности принадлежности домена к одному из классов (вредоносных или легитимных).

BATCH_SIZE = 100
NUM_UNITS_ENC = 128
x_sym = T.imatrix()
y_sym = T.ivector()
xmask_sym = T.matrix()
Tdata = np.random.randint(0,10,size=(BATCH_SIZE, NUM_CHARS)).astype('int32')
Tmask = np.ones((BATCH_SIZE, NUM_CHARS)).astype('float32')
l_in = lasagne.layers.InputLayer((None, None))
l_emb = lasagne.layers.EmbeddingLayer(l_in, NUM_VOCAB, NUM_VOCAB, name='Embedding')
l_mask_enc = lasagne.layers.InputLayer((None, None))
l_enc = lasagne.layers.GRULayer(l_emb, num_units=NUM_UNITS_ENC, name='GRUEncoder', mask_input=l_mask_enc)
l_last_hid = lasagne.layers.SliceLayer(l_enc, indices=-1, axis=1, name='LastState')
l_softmax = lasagne.layers.DenseLayer(l_last_hid, num_units=NUM_CLASS, nonlinearity=lasagne.nonlinearities.softmax, name='SoftmaxOutput')
output_train = lasagne.layers.get_output(l_softmax, inputs={l_in: x_sym, l_mask_enc: xmask_sym}, deterministic=False)
total_cost = T.nnet.categorical_crossentropy(output_train, y_sym.flatten())
mean_cost = T.mean(total_cost)
#accuracy function
argmax = T.argmax(output_train, axis=-1)
eq = T.eq(argmax,y_sym)
acc = T.mean(eq)
all_parameters = lasagne.layers.get_all_params([l_softmax], trainable=True)
all_grads = T.grad(mean_cost, all_parameters)
all_grads_clip = [T.clip(g,-1,1) for g in all_grads]
all_grads_norm = lasagne.updates.total_norm_constraint(all_grads_clip, 1)
updates = lasagne.updates.adam(all_grads_norm, all_parameters, learning_rate=0.005)
train_func_a = theano.function([x_sym, y_sym, xmask_sym], mean_cost, updates=updates)
test_func_a = theano.function([x_sym, y_sym, xmask_sym], accОбучаем нашу модель, разбив выборку на батчи по 100 доменных имен. В результате, получаем следующий график:
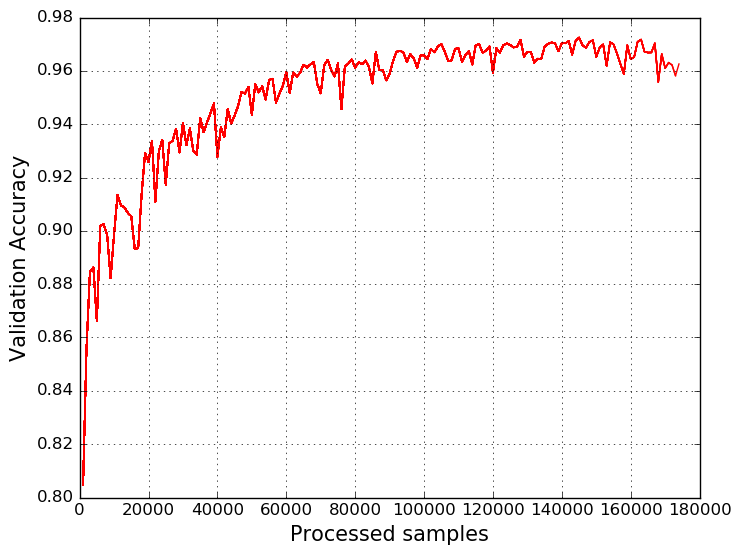
В заключение можно сказать, что полученная модель нисколько не уступает алгоритму Random Forest, а даже превосходит его. Кроме этого, нашу модель можно совершенствовать и дальше, например, добавив в неё реверсивный проход по доменному имени или включив в модель механизм внимания (Attention LSTM). Ну а для темы машинного обучения в информационной безопасности всё только начинается :)
References
- https://github.com/ClickSecurity/data_hacking/blob/master/dga_detection/DGA_Domain_Detection.ipynb
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://github.com/andrewaeva/DGA/
- http://openbooks.ifmo.ru/ru/collections_article/997/raspoznavanie_i_klassifikaciya_vredonosnyh_domennyh_imen.html
- http://openbooks.ifmo.ru/ru/collections_article/4053/analiz_algoritmov_generacii_vredonosnyh_domennyh_imen_i_metody_ih_raspoznavaniya_s_ispolzovaniem_rekurrentnyh_neyronnyh_setey.htm
Абакумов Андрей, Digital Security
lostpassword
Рыбка.
На пятом графике я вижу рыбку!
Morfin_brood
Я вижу половинку сердца с большим рожком мороженного
ajaxtpm
А в чем принципиальная разница от подхода из этой статьи?
Andrewaeva
Принципиальное отличие заключается в использовании рекуррентных нейронных сетей, а не простой N-gram модели с использованием линейных классификаторов или решающих деревьев. В конечном итоге использование модели Biderection GRU, в совокупности с механизмом внимания показывают результат, превосходящий модели, построенные только на энтропии, N-gram моделях и моделях, использующих алгоритм TF-IDF.
sim0nsays
Клево! Больше нейросетей! А расскажите какие-нибудь детали про процесс войны за обучение? Что попробовали и не сработало? Как выбирали толщину? Какой размер датесета?
В общем, больше мяса!
Andrewaeva
Воу, тут материала наверно на ещё одну статью :)
Если из интересного и кратко, то я был удивлен, что SVM — не выстрелило, а оптимальным количеством units для нейронной сети стало 128. Их увеличение до 256 или 512 только ухудшало модель — почему, загадка.
Пробовал разные алгоритмы градиентного спуска — остановился на Adam.
Ну а самая сложная модель, которую попробовал выглядит примерно так.
tsvetkovpa
А последний график построен по Training Set или по Test Set?
Andrewaeva
Точность на тестовой выборке