

В данной статье я хотел бы поделиться своими мыслями об идеальном языке программирования общего назначения. В первую очередь — о языке, который мог бы заменить С++.
Так случилось, что языки программирования — мое хобби и мой основной интерес в сфере IT. Наверное, любой программист иногда мечтает создать свой собственный — идеальный — язык программирования. Для меня это нечто большее, чем просто мечта, фактически я уже давно собираю всю информацию по различным языкам и проектирую свой собственный язык.
На разных ресурсах я регулярно высказываюсь по вопросам этой тематики. В этой статье я попытался собрать основные мысли воедино. Мы рассмотрим основные недостатки С++, особенности других языков, которые так или иначе можно сравнивать с С++, и — самое интересное — потребности программистов в языковых фичах, на примере библиотеки Boost.
Данная статья не претендует на какую-то техническую полезность (хотя если она будет кому-то полезна, это замечательно). Это статья — приглашение к обсуждению.
С++ далеко не идеален. Думаю, любой С++ программист согласится со мной.
Недостатки С++ — это в первую очередь тяжелое наследие Си: ужасная система инклудов и полное отсутствие модульности. Включение заголовочного файла приводит по сути к включению всего содержимого файла в единицу компиляции; поскольку заголовочные файлы включают друг друга, а современные библиотеки могут содержать десятки тысяч заголовочных файлов… разумеется, это не может не сказываться на времени компиляции. Иногда помогают различные решения-хаки типа «precompiled headers» (pch), но, как показывает практика, эти решения тоже далеко не идеальны. Например, Visual C++ не позволяет создавать общие pch для нескольких проектов одного solution (при том, что в precompiled headers как правило включают действительно общие и неизменяемые заголовки — такие как stl, boost и т.п.).
Ну и конечно внутренний перфекционизм, свойственный любому программисту, решительно протестует против такой реализации — по сути костыля, подпорки под неправильную изначально архитектуру.
#define true falseКонечно же «лексический» препроцессор, еще один привет от Си, тяжелое и намертво приросшее наследие unix-way (да, когда-то это действительно была отдельная программа, и да, существуют альтернативные препроцессоры, например m4… но сейчас препроцессор однозначно воспринимается как часть языка). Но совершенно очевидно, что языку нужен некий набор возможностей, решающий задачи препроцессора (а точнее система синтаксических макросов), и это не должна быть нестандартная сторонняя программа, никак не связанная с языком.
И из относительно нового — тьюринг-полнота шаблонов, породившая адские конструкции метапрограммирования на этих самых шаблонах. Изначально предполагалось, разумеется, что шаблонные функции и классы будут использоваться исключительно для написания универсальных алгоритмов и структур данных, не зависящих от типа обрабатываемых/хранимых данных. Прекрасное применение! Но.
Отсутствие встроенных синтаксических макросов и вечное чувство голода по фичам заставили программистов создать на шаблонах полноценные метаязыки, с метатипами, метаалгоритмами, с вычислениями, выполняющимися компилятором во время компиляции… Что же в этом плохого? Да ничего, кроме того, что это — по сути своей костыли.
Но просто неприятно, когда например ключевые слова (struct) используются совсем не для того, для чего они предназначены. Ну и конечно неадекватные сообщения об ошибках, нередко возникающие из-за случайной опечатки и занимающие десятки (если не сотни) строк на одну ошибку… это поистине ужасно.
Разумеется, в С++ хватает и других недостатков — по мелочам. Так или иначе, многие из них учтены в следующем поколении языков прикладного программирования — Java и C#. Кстати, на мой вкус C# развивается наиболее динамично и органично впитывает в себя фичи из многих других языков; это отличный пример красивого и сбалансированного языка (а значит, и отличный образец, на который можно смотреть при проектировании новых языков). Но ни Java, ни C# все-же не являются языками системного программирования.
Нельзя не отметить и еще одну группу новых (относительно С++) языков, к которым я бы отнес D, Go, Rust, Swift, Nim, и заодно относительно старый Objective C (за его очень интересную особенность — рантайм).
Что же в этих языках интересного?
Начнем с D. Язык разрабатывался как «улучшенный С++», и действительно — многие концепции сделаны более грамотно. Аккуратно реализовано контрактное программирование, есть ФП, есть некая реализация метапрограммирования (но можно сделать лучше!). Язык компилируется в нативный код, а значит, может претендовать на «системность». Но я бы не выделил в D какой-то одной фичи, которая затмевает все. Тем ни менее, складывается впечатление, что язык пошел по пути С++ в части накопления «хаков», это особенно заметно при изучении кода компилятора (чем я периодически занимаюсь).
Go. Среди приятных вещей — структурная типизация интерфейсов. Возможность крайне интересная, сразу хочется воспользоваться…
Еще стоит упомянуть embedding вместо наследования. Когда смотришь на это, думаешь — а ведь это должно быть еще в Си! Настолько это просто в реализации — и, тем ни менее, как элегантно выглядит это решение. Встроенная в язык поддержка многопоточности тоже радует.
Rust. Основная фича — потрясающая система умных указателей и проверок во время компиляции. Да, это стоит брать в идеальный язык… хотя многие жалуются, что система переусложнена. В действительности в ней нет ничего лишнего, хотя я бы не стал отказываться и от классических указателей (в Rust кстати от них не отказываются, они просто завернуты в unsafe). Можно ли такое совместить? Можно. Нет ничего страшного в возможностях, страшно их отсутствие.
И еще я бы хотел упомянуть Objective C. Язык достаточно старый, но людям незнакомым с миром OSX найдут в нем много интересного. Это особая реализация ООП, в частности отправка сообщений вместо прямого вызова методов, система селекторов и метаклассов. Пришедшие в язык из Smalltalk, эти фичи позволяют в компилируемом языке делать многие удивительные вещи, достижимые только в интерпретируемых скриптах — в частности, добавлять методы в классы прямо во время выполнения программы! По-моему, прекрасная возможность.
Следующий интересный вопрос — соотношение фич языка и того, что можно вынести в библиотеки. Так сложилось, что долгое время именно С++ был самым мощным языком программирования универсального назначения (да и сейчас пожалуй остается им, несмотря на все недостатки). Альтернатив не было, но сам по себе С++ долгое время развивался достаточно медленно, а программистам всегда хочется большего! Так или иначе, но стали появляться и развиваться различные библиотеки. Несмотря на то, что стандартная библиотека уже была, многие другие библиотеки и фреймворки часто дублировали ее функциональность своими классами. Яркий пример — строки. Казалось бы, в С++ есть стандартная строка (std::string), но нет — практически каждая более-менее крупная библиотека имеет свою реализацию строк. CString (MFC/ATL), QString (Qt), TString (VCL), wxString (wxWidgets).
Та же участь постигла различные контейнеры (динамические массивы и списки), базовые классы для различных иерархий (object — правда надо признать что в стандартной библиотеке ничего подобного нет). Я уже не говорю про переопоределения простых типов, встречающиеся практически в каждой небольшой программе (даже не библиотеке). Помните всяческие UINT, uint, u32, DWORD, uint32_t… Но наиболее интересным объектом для исследования дизайна языка является пожалуй библиотека Boost (как официальная ее часть, так и библиотеки в статусе Under Constuction, находящиеся в Boost Incubator и прочие неофициальные расширения). К ней мы еще вернемся.
Сейчас же можно сказать, что С++ выглядит так: небольшое языковое ядро, небольшая стандартная библиотека, и множество сторонних библиотек, пересекающихся друг с другом и частично со стандартной библиотекой и захватывающих разные области ответственности — от эмуляции языковых фич до прикладных задач. Многие библиотеки опираются только на ядро. Примерно так:
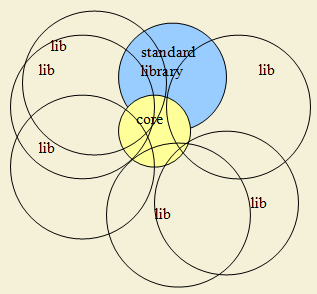
Маленькое языковое ядро не поддерживает многие языковые фичи и провоцирует программистов писать «эмуляцию языковых возможностей». Поскольку программистов много, то и соответствующих эмуляций много; они как правило несовместимы между собой; громоздки (т.к. построены на нестандартном и/или неочевидном использовании существующих языковых возможностей); трудны в компиляции и отладке, да и вообще в понимании. С другой стороны, маленькое ядро позволяет языку не содержать ничего лишнего и это хорошо (более того, это необходимо для системного программирования). Противоречие? На самом деле разрешимое противоречие. Вот моя схема организации идеального языка:
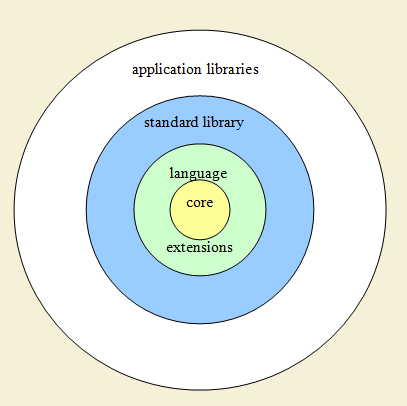
В центре — базовое языковое ядро. Вокруг него — «language extensions», языковые расширения — некие части языка, которые поддерживаются синтаксически, но которые можно включать и отключать при сборке проекта, а также заменять на свои реализации; дальше — стандартная библиотека, поддерживающая все что относится к программированию общего назначения; и вокруг — прикладные библиотеки, которые не пытаются эмулировать функции ядра, а решают чисто прикладные задачи. Прикладные библиотеки должны реализовывать специфические вещи. Это существенно важно — разница между общим и специфическим. Работа с графикой, с сетью, с железом; специфическая математика, криптография, прикладные библиотеки для каких-то особых областей; работа с разными файловыми форматами, с базами данных, с различными сервисами… все это специфические, прикладные направления, и они безусловно должны реализовывать в виде библиотек. А вот рефлексия или многопоточность, функции высшего порядка или сопрограммы — это фундаментальные с точки зрения языка вещи, и они должны поддерживаться в языке (некоторые — с возможностью замены реализации по умолчанию на что-то другое).
Вернемся к библиотеке Boost. Поговорим о Бусте как о ярчайшем примере того, что языки развиваются гораздо медленнее, чем того хотят программисты. Добрая половина библиотек Буста — это по сути эмуляция языковых фич. Возможно, когда нибудь я напишу отдельные статьи про библиотеки Буста… здесь же — лишь краткий обзор того, что там есть — в причем контексте включения этих фич непосредственно в язык программирования. У Буста есть своя классификация библиотек, с которой я не вполне согласен (хотя и цели классификации у меня другие). Часть библиотек безусловно относится к группе «стандартная библиотека»; часть — вообще прикладные библиотеки; но значительная часть — это именно то, чего не хватает в самом языке, в ядре! Я не буду здесь приводить ни своего деления, ни описания библиотек (это тема отдельной статьи, а то и нескольких). Вместо этого я просто дам список (неполный!) тех библиотек библиотек Буста, которые я бы отнес к языковому ядру:
- integer — метаинформация и трейты для целочисленных типов
- multiprecision — обертка для библиотек работы с числами произвольной точности GMP, MPIR, MPFR
- any — универсальный динамический тип
- optional — опциональный тип, maybe; по идее должен быть встроен в язык и интегрирован с nullable
- variant — алгебраический тип данных (sum-type, tagged union)
- preprocessor — метапрограммирование на сишном препроцессоре
- inentity_type — хелпер для генерации уникальных имен типов
- assign — мультиоперации, связанные с заполнением контейнеров
- mpl — контейнеры типов и операции над ними
- fusion — контейнеры типов и значений и операции над ними
- tuple — кортежи
- bind — функциональные объекты, создаваемые с помощью частичного применение функций
- function — функциональные объекты
- lambda — лямбда-функции; кстати, кое-в чем превосходящие лямбды из c++11;
- local_function — эмуляция вложенных функций
- signals2 — сигналы и слоты
- context — сохранение и восстановление состояния потока (стека и регистров)
- coroutine — реализация сопрограмм
- foreach — цикл по коллекциям
- parameter — эмуляция именованных аргументов фунций
- scope_exit — языковая конструкция, в языке D это называется scope(exit), scope(success), scope(failure), в Go — defer
- type_erasure — альтернативная реализация рантайм полиморфизма
- predef — метаинформация об ОС, компиляторе, платформе...,
- typeof — эмуляция оператора typeof / decltype
- endian — работа с числами с разным порядком байт
Напомню, что это далеко не полный список (и еще я даже не рассматриваю здесь библиотеки расширений Буста, а там тоже немало интересного — например Contract, Hana, Introspection, Mirror, Reflection...). Отмечу, что далеко не все библиотеки следует включать в языковое ядро: в общем случае, достаточно включить в ядро лишь некоторую небольшую (и по сути общую для многих библиотек) часть, и может оказаться, что многие библиотеки из этого списка вообще окажутся не нужны. Также включение в языковое ядро позволит избежать многих ограничений, накладываемых на существующие искусственные реализации различных фич. Такие прекрасные возможности, как алгебраические типы данных, универсальный динамический тип any, опциональные типы, именованные параметры конечно же лучше всего реализовать на уровне языка.
Теперь перейдем к «Language Extensions». Что это такое и зачем я это ввел?
На самом деле такие «расширения» так или иначе существуют и в С++, просто их никто не выделяет в отдельную группу. Пример — система выделения памяти в С++. Интерфейс языкового ядра — это операторы new и delete как таковые; в языковом ядре четко прописан их синтаксис, а в документации — их семантика (выделение и освобождение памяти). При этом язык предоставляет стандартную реализацию, но при желании можно переопределить эти операторы и написать свою систему выделения памяти. Второй пример — идентификация типа во время выполнения, RTTI. Пример демонстрирует другой аспект — отключаемость расширений.
Я имею большой опыт работы с микроконтроллерами, там при очень малом объеме бортовой памяти приходилось выделять память только статически — никакой «кучи» не было, и уж тем более не было RTTI.
Разница между Core и Extensions только в том, что элементы core нельзя переопределить; так, условный оператор if однозначен, его логика зашита в ядро и нет никакой возможности заменить его реализацию на что-то другое. Расширения же прописаны в ядре на уровне синтаксиса, также в языке предоставляется некая реализация по умолчанию, которая устроит 95% программистов; оставшимся 5% предлагается написать свою реализацию, тем ни менее соответствующую языковым интерфейсам, или отключить ее вовсе — для специфических случаев.
Другими такими расширениями могли бы стать
- сборка мусора (см. Rust — Gc)
- управление памятью с помощью подсчета ссылок (см. Rust — Rc, Arc)
- длинная арифметика (здесь важно то, что арифметика должна быть интегрирована в язык в том числе на уровне литералов; и длинные константы типа 128-битных чисел должны записываться естественным путем — в виде числовых литералов, одинаково для всех реализаций!)
- многопоточность (оператор go в языке go)
- рефлексия (да, существует масса способов реализовать ее вручную — но лучше компилятора с этой задачей все равно никто не справится)
- виртуальность и мультиметоды
- сигналы и слоты
- динамика в стиле objc
- встроенные скрипты
- rtti
- обработка исключений (существуют разные способы ее реализации; а бывают случаи когда она вообще не нужна)
- floating point (да, на некоторых микроконтроллерах нет FPU и работу с плавающей точкой эмулирует библиотека)
и наверное многое другое, что я не вспомнил сразу.
Под конец хочу остановиться на одном философском принципе, который лежит в основе моего представления об идеальном языке программирования. Обычно в ходе обсуждения на форумах, когда начинаешь говорить что в языке Х нет фичи Y, обязательно найдется кто-нибудь, кто скажет: ну как же, вот если взять фичи A, B и С, и прикрутить к ним костыли D, E и F, то мы получим почти Y. Да, это так. Но мне такой подход не нравится. Можно представить, что таких программистов устроит некоторый сложный путь через лабиринт. Пройти лабиринт можно, но путь кривой и неочевидный. Мне же хочется, чтобы вместо лабиринта была просторная площадь, по которой из любой точки в любую другую можно было бы пройти по прямой. Просто по прямой.
Комментарии (88)

vilgeforce
12.05.2015 01:22+1«Недостатки С++ — это в первую очередь тяжелое наследие Си: ужасная система инклудов и полное отсутствие модульности.» — это и есть самые серьезные недостатки? Автор явно придирается к мелочам :-)

AxisPod
12.05.2015 07:28+4К мелочам? Да временами это в такой ад превращается, что аж мозг выдрать хочется. До тех пор пока вы делаете софт уровня хеллоу ворлд, вы не встретите таких проблем. А когда библиотеки уровня буста, вот тогда придется поплакать и поколоться кактусом.

cdkrot
26.05.2015 20:07+2Полностью согласен, было бы замечательно, если бы люди сделали не «инновационную замену C++», а C++ но без всякой С-фигни типа той, которая написана в посте (у меня точно такое же впечатление, спасибо автор за этот пост).
Я бы ещё выкинул отношения declaring != defining. Чтобы можно было сразу писать и прототип и реализацию в одном месте. Компилятор вполне может с этим справится (см Java). (Ну и без C-хедеров само собой).
Ещё есть проблема со строками: стандартный повсеместный std::string не поддерживает unicode, есть конечно std::wstring, но кто ж его использует?
Помните всяческие UINT, uint, u32, DWORD, uint32_t…
Над системой типизации надо тоже поработать. Кстати те самые сотни строк ошибок из-за небольших ошибок тоже плод этого.

AlexPublic
12.05.2015 07:37+2Да всё там нормально у автора. Просто надо читать дальше. Упоминается и препроцессор и метапрограммирование на шаблонах и т.п. Кстати, замечу, что с другой стороны наличие этих возможностей является как раз сильной стороной языка в данный момент, т.к. позволяет делать недоступное другим языка (не считая такие далёкие от мейнстрима как D, Nemerle, Rust). ))) Т.е. проблема в кривой реализации, приводящей к сложному коду, а не в самой сущности.
Кстати, забавно что автор отдельно отметил кривую систему модульности и сомнительный препроцессор, в то время как #include формально говоря тоже является директивой препроцессора. ))) Но в общем то это тоже правильно, т.к. в других языках модульность и является отдельной вещью.cdkrot
26.05.2015 20:09Именно, модульность (как например ещё и условная компиляция) должны реализоваться на более высоком уровне, чем препроцессор C.

robert_ayrapetyan
12.05.2015 03:39+6сборка мусора (см. Rust — Gc)
Для «идеального» языка — только в полностью отключаемом варианте…
AlexPublic
12.05.2015 07:41+5По статье у меня есть только два вопроса:
1. И? Перечислены в общем то правильные и очевидные вещи, но не видно никаких практические выводов из всего этого.
2. А почему на geektimes, а не на Хабре? ) Вроде как нормальная техническая статья…
Duduka
12.05.2015 08:36А какие выводы могут следовать из посылки, что самой проблемной частью с++ является — наследие С?!
Я бы добавил — из-за слабости системы типов С! И архитектурную дыру вызванную тем бардаком, который устроила MS в комитете по стандартизации, и требование обеспечения совместимости с ее поделиями, хотя еще Фортраны были разделены на поколения и режим работы (для быстрой компиляции за счет скорости исполнения, или наоборот). Почему библиотеки 8х-9х должны компилироваться с++14/17? Все должно компилироваться своей средой 200х -с++03, старье 2010 — с++11… требование обеспечения совместимости — требование написания потенциально глючных, медленных уродцев, которые никто не проверяет на совместимость и наслоения самописных переходников.AlexPublic
12.05.2015 08:44+2Ну так заголовок статьи вроде как намекает, что она не про критику C++, а должна предлагать что-то интересное взамен. Так вот чего-то практического на эту тему я так и не увидел. Максимум общие лозунги в конце статьи, в стиле «мы за всё хорошее и против всего плохого». )))

OCTAGRAM
12.05.2015 08:25+3Objective-C со своей динамикой известен только лишь потому, что после того, как улеглась пена (а улегающаяся пена была представлена, например, Sun OBI, SGI Delta C++, эти темы обсуждались на конференциях USENIX), среди подобных подходов на плаву остался он один, и не в силу своих технических достоинств, а в силу кодовой базы, уже написанной на языке прошлого поколения. Отчасти IBM OS/2 и Apple Copland дружно сдохли, отчасти головокружение от Java, отчасти подход IBM к SOM «не доставайся же ты никому», отчасти очень малый период, когда программисты могли пощупать DTS C++, чтобы это отпечаталось в голове, и в open source проектах типа GObject был бы воплощён именно такой подход к ООП, а не тот, который в Delphi и C++.
Мне недавно удалось запустить компилятор DTS C++ от IBM, на Win8 x64 до сих пор работает, можно было бы сделать сравнение DTS C++ и Objective-C, чтобы понять, что мы потеряли. Мне вообще кажется, всем было бы лучше, если взять Foundation, AppKit и т. п. и заменить Objective-C на SOM и DTS C++ или его аналог, ускоренно повторивший эволюцию Objective-C. В WebObjects была относительно успешная замена всего на Java, в Cocoa-Java был относительно успешно работающий мост, позволяющий писать приложения на Java, из этого я делаю вывод, что возможности, не имеющие соответствия 1:1 между Objective-C и DTS C++, вроде poseAs, не помешают сделать такой переезд.
Касательно метапрограммирования, я думаю, чтобы как–то совладать с ним, можно было бы сделать возможность компилировать расширения языка в dll, и они бы манипулировали AST. Не везде будет достаточно, но тем не менее.
Языки типа ParaSail, Limbo, Erlang, Go, Rust, Cilk поднимают более общую тему — создание единого зелёнопоточного планировщика, потому что когда у каждого из этих языков планировщик свой, совмещать их все не очень очевидно, как. Пока получается только так, что у каждого из них планировщики на разных потоках OS. Подобно тому, как поверх ядер CPU работает планировщик OS, поддерживающих вытесняющую многозадачность, поверх потоков OS должен работать планировщик зелёных потоков, и у этих зелёных потоков должны быть свои зелёные мьютексы, зелёные условные переменные и т. п. Как я понимаю, такой планировщик есть у ParaSail, а у планировщиков остальных языков из списка другая модель многозадачного взаимодействия, что усложняет портирование программ, написанных в расчёте на потоки, мьютексы и условные переменные. Чтобы зелёные потоки не тратили время больше положеного, их, наверное, как–то размечать придётся, и компиляторы разных языков програмирования могут оценивать затраты CPU по–разному, не очень понятно, что с этим делать. Наверное, перекладывать задачу разметки на библиотеки времени выполнения.Duduka
12.05.2015 08:52+2Зеленые потоки без смены парадигмы программирования?! Как серьезно можно ожидать повышения быстродействия приложения, если сохраняется концепция изменяемости?! просто программы обрастут гроздями мьютексов и контроля за рейсингом( потому и ParaSail, и замена комуникациями через каналы в Лимбо и Го, обмена через общую память ), а С++ без хаков по управлению памятью ничем не будет лучше ParaSail по быстродействию. Да, и назовите библиотеки С++, которые учитывают, что будут запускаться на системах с разделенной памятью?
AlexPublic
12.05.2015 18:02Зелёные потоки без проблем реализуются на C++ с помощью сопрограмм (например Boost.Coroutine). Примеры можно глянуть скажем в Boost.Asio, где показаны образцы написания сервера на сопрограммах.
Далее, мьютексы (системные), разделяемая память и т.п. совершенно не обязательны для зелёных потоков, т.к. они могут даже не вылезать за рамки своего системного потока.
Ну и наконец, если уж говорить о межпотоковом (или даже межпроцессном или вообще межмашинном) взаимодействие, то для этих целей есть известные удобные инструменты, не зависящие от языков. Например модель акторов. И опять же на C++ мы давным давно имеем нормальные реализации этого инструмента.Duduka
13.05.2015 05:41Зеленые потоки и сопрограммы — это совершенно не пересекающиеся парадигмы (первая — одна из парадигм создания многозадачности, вторая — однопоточного безблокировочного приложения).
То что в некоторых языках есть необходимые инструменты никоим образом не делает С++ их содержащим(рантайм слабоват, даже в сравнении с явой, модулой и адой, хотя и в них многозадачность куцая, но в сравнении с С++ она там, таки есть.):
" Далее, мьютексы (системные), разделяемая память и т.п. совершенно не обязательны для зелёных потоков, т.к. они могут даже не вылезать за рамки своего системного потока. " — что?! учите многозадачность, Сэр! Я не про сопрограммы, а про зелень!
" Например модель акторов. И опять же на C++ мы давным давно имеем нормальные реализации этого инструмента. " — давным-давно, да, но не этого, а того, что получилось. Зачатки появились в Occam-2/Ada, но с-программисты всегда идут своим путем, и назовите хоть одну современную программу на С++, которая работает используя все ресурсы, что многоядерного, что много машинного окружения?AlexPublic
13.05.2015 16:26Сопрограммы — это действительно другая сущность (которая кстати используется совсем не для «безблокировочных приложений»). Но достаточно добавить к ней планировщик (в простейшем случае банальный цикл for по списку сопрограмм) и мы получим работающую реализацию зелёных потоков.
Насчёт многозадачности надо как раз кому-то другому тут поучиться. Я же точно описал где смотреть (разве что прямую ссылку не дал) примеры. В примерах Boost.Asio с помощью сопрограмм реализуется удобная организация кода для многозадачности внутри одного системного потока. Далее, мы просто запускаем нужное количество (например по числу ядер процессора) таких системных потоков и получаем идеально работающую систему.
В самом C++ имеется нормальная реализация системной многопоточности. Плюс имеются сторонние библиотеки реализующие всё что угодно. Например модель акторов можно увидеть здесь www.theron-library.com. Насчёт последнего вопроса не понял — что, у кого-то действительно есть сомнения, что на C++ тривиально пишется программа, загружающая процессор на 100%? Или что? )))
P.S. Самое забавное, что сама концепция зелёных потоков полезна для решения только очень узкого спектра проблема. Когда мы имеет тысячи одновременных маленьких задач. Т.е. что-то вроде написания высоконагруженного демона. Во всех остальных случаях системные потоки очевидно удобнее и эффективнее.Duduka
13.05.2015 17:13Про костыли буста( и множества переносимых МТ библиотек ) в курсе, но ТС писал об идеальных языках, Вы считаете, что язык должен быть костильным?
Или что! ))) полное распределение нагрузки прямо из языка. JS-ая, на ровном месте, тотальная загрузка не то!
###
P.S. Самое забавное, что сама концепция зелёных потоков полезна для решения только очень узкого спектра проблема. Когда мы имеет тысячи одновременных маленьких задач. Т.е. что-то вроде написания высоконагруженного демона. Во всех остальных случаях системные потоки очевидно удобнее и эффективнее.
###
Самое забавное, что к зеленым потокам можно свести вообще все алгоритмы выразимые на с++ ))) а эффективность системных потоков и удобство… это, м-м, на любителя ))) если не зыбывать, что зеленые строятся поверх них, не имея никакой помощи от ОС.
Единственное, с чем можно согласиться, так это с тем, что с++ никак не поддерживает создание удобных и эффективных приложений))) как и другие языки.AlexPublic
13.05.2015 19:08Ну собственно получается всё снова сводится к тому же вопросу, поднимаемому и автором статьи. При реализации любой возможности в любом языке, где нам её разместить:
1. в конструкциях языка
2. в расширениях языка
3. в стандартной библиотеке языке
4. в сторонних библиотеках языка.
В C++ системная многопоточность реализована на уровне 2 (openmp, openacc и т.п.) и 3 (std::thread и т.п.). А всяческие лёгкие потоки, пулы задач, акторы и т.п. на уровне 4 (тут есть бесчисленное количество разных библиотек).
Так где оно должно быть реализовано, чтобы с вашей точки зрения не считалось костылями? ) Обязательно на уровне 1 (как в Эрланге) что ли?
Ну и главное… Если говорить исключительно о быстродействие (и однопоточном и многопоточном), то с правильно написанным приложением на C++ вряд ли способно что-то поспорить. )))Duduka
14.05.2015 04:59### www.gamedev.ru/flame/forum/?id=168247
Наконец, хотя этот предмет не из приятных, я должен упомянуть PL/1, язык программирования, документация которого обладает устрашающими размерами и сложностью. Использование PL/1 больше всего напоминает полет на самолете с 7000 кнопок, переключателей и рычагов в кабине. Я совершенно не представляю себе, как мы можем удерживать растущие программы в голове, когда из-за своей полнейшей вычурности язык программирования — наш основной инструмент, не так ли! — ускользает из-под контроля нашего интеллекта. И если мне понадобится описать влияние, которое PL/1 может оказывать на своих пользователей, ближайшее сравнение, которое приходит мне в голову, — это наркотик. Я помню лекцию в защиту PL/1, прочитанную на симпозиуме по языкам программирования высокого уровня человеком, который представился одним из его преданных пользователей. Но после похвал в адрес PL/1 в течение часа он умудрился попросить добавить к нему около пятидесяти новых «возможностей», не предполагая, что главный источник его проблем кроется в том, что в нем уже и так слишком уж много «возможностей». Выступающий продемонстрировал все неутешительные признаки пагубной привычки, сводящейся к тому, что он впал в состояние умственного застоя и может теперь только просить еще, еще, еще… Если FORTRAN называют детским расстройством, то PL/1, с его тенденциями роста подобно опасной опухоли, может оказаться смертельной болезнью.
###
habrahabr.ru/company/hexlet/blog/248921
### Э. Дейкстра. ”Дисциплина программирования” Роль языков программирования
Я рассматриваю язык программирования преимущественно как средство для описания (потенциально весьма сложных) абстрактных конструкций. Как показано в главе «Абстракция исполнения», первейшим достоинством алгоритма является потенциальная компактность рассуждений, на которых может основываться наше проникновение в его сущность. Как только эта компактность потеряна, алгоритм в значительноймере теряет «право на существование», и поэтомумы будем стремиться к сохранению такой компактности. Соответственно и наш выбор языка программирования будет подчинен той же цели.
###
Каюсь, пока прямого ответа на Ваш вопрос не нашел, но где-то у дедов он был, суть — язык программирования — это операционная система (компьютер), и абстракты утоплены в ней, чтоб не писать все кишки в программах (тут следует пояснить — гибкость важна, но не ее выпячивание, чем меньше писать, тем лучше, как трейты за место прагм, на этапе компиляции, а не в программе, тут конечно спорный момент, но проходить джунглии из списков инстансев — это бред, по моемому, даже не костыль, а неосиляторство.).
Мы же пишем кишки сишных-тредов и считаем это простым и удобным! Сишных-тредов, юниксовских сред! И огорчаемся, что МС поменяло их описание в заголовочных файлах. И вершинной инкапсуляции считаем Эрланг! Не, серьезно?! Эток костыль к юникс-тредам? ( Единственное «да» — стеклесс-треды! все остальное — академические бредни, приводящие к тормозам. )
"… Если говорить исключительно о быстродействие (и однопоточном и многопоточном), то с правильно написанным приложением на C++ вряд ли способно что-то поспорить… " — а это просто рекламный булшит. Я застал времена, когда декус-с генерил код в разы медленнее паскаля или блиса, а фортран делал бессмысленным писанину на аде. То, что развитие опенсорсных компиляторов застряло на gcc, ником образом не значит, что с++/с приложения вообще приближаются к вершинам. Там, где даже assembler — неэффективен (распределенные вычисления/приложения, многозадачность) С++ выполняет роль баша. Да, многозадачность уровня Occam-2 должна быть в языке, SIMD-типы и управление одновременностью в распределенной сети исполнения.AlexPublic
14.05.2015 16:20Ну т.е. или мы делаем красивый язык, в котором есть сразу всё (т.е. по сути засовываем в него ОС, но тогда и получится PL/1) или делаем маленькое ядро и добиваем остальное сторонними библиотеками (но это по сути C++ и есть, если забыть о излишней сложности, вызванной в основном историческими причинами, а не излишней функциональностью).
Что касается быстродействия, то речь естественно была не о какой-то гениальности самого устройства C++ (хотя принцип «не платишь за то, что не используешь» безусловно сильно помогает), а как раз о текущей ситуации с компиляторами. К примеру тот же D теоретически мог бы быть как минимум не медленнее, а возможно и даже быстрее (за счёт наличие в языке дополнительной информации для компилятора, типа pure, immutable и т.п.) чем C++. Но на практике он уступает, как раз из-за неразвитого оптимизатора.
Да, и насчёт simd… Пока что действительно автовекторизация компилятора заметно уступает ручному кодированию. Но я думаю что тут ситуация аналогичная обычной оптимизации 20 летней давности (тогда ручной ассемблерный код гарантированно был быстрее любого компилятора). Соответственно я подозреваю, что через несколько лет автовекторизация компиляторами аналогично догонит ручной использование SIMD (собственно в специализированных SIMD языках это уже реализовано, осталось перенести это на уровень оптимизатора GCC), так что смысла во введение специальных типов не видно — компиляторы будущего должны обрабатывать подобное сами. Ну а пока хватит intrinsic'ов и обёрток типа Boost.SIMD.
Что же касается распределённых вычислений, то напомню, что там до сих пор стандартом де факто является MPI, который как раз родной для C++. ))) Хотя лично мне больше нравится модель акторов. ))) Как на уровне межпоточного взаимодействия, так и на уровне межмашинного. )Duduka
14.05.2015 17:50-1))) как раз с++ это «современный» PL/1, но с «с» синтаксисом (правда неглючного компилятора PL/1 небыло… но все еще есть куда рости, для с++)
Если засунуть все в ОС, то получится «с». А сторонние библиотеки ничем не лучше «толстого» языка (сказывается отсутствие стандартизации).AlexPublic
15.05.2015 01:50Какой же C++ современный PL/1? ) Там вообще почти ничего нет от возможностей ОС. Ни файловой системы, ни сети, ни графики, потоки вот только в последней версии добавили (в стандартную библиотеку). Да тут можно тысячи отсутствующих вещей перечислять. Какой-нибудь Python или Java на порядки богаче в этом смысле. C++ обретает силу как раз только с учётом сторонних библиотек. А вот с учётом них, C/C++ становится уже мощнее всех остальных. Собственно очень многие дополнительных возможности реализуются в других языках с помощью биндингов к этим самым C/C++ библиотекам. )))
Duduka
15.05.2015 04:27Так PL/1 их не имел, это был набор фич из разных языков того времени, и все. Какая сеть, графика, файловая система в PL/1, акститесь! Это древняя древность от IBM.
$$$ Собственно очень многие дополнительных возможности реализуются в других языках с помощью биндингов к этим самым C/C++ библиотекам.
А почему, знаете? )))

0xd34df00d
13.05.2015 12:58Почитайте пропозалы на software transactional memory.
Duduka
13.05.2015 13:21:) Вы наивно считаете, что это что-то другое?!
0xd34df00d
13.05.2015 13:27Другое по сравнению с чем?
Я наивно считаю, что это хороший подход к реализации параллельных программ без рейсингов, коммуникаций и прочего счастья.
Вот ещё атрибутpureпримут в стандарт, вообще заживём!
gcc вроде в 5.1 научился генерировать код под OpenACC, но с этим я ещё не игрался, так что не могу ничего сказать, кроме «что-то где-то слышал». Ну, это к слову о разделённой памяти и вообще гетерогенных системах.Duduka
13.05.2015 14:17Это такой же механизм разделения доступа к данным (как мьютексы, семафоры, мониторы, LockFree структуры и ...), причем мало масштабируемый, как и LockFree структуры, без рейсинга — очень оптимистично, он скрывается на уровне аппаратуры/кеша, но откат транзакции делает его ограниченным. Вы можете описать сценирий в котором STM, будет быстрее мьютексов/мониторов?
Как раз «прочее счастье» сообщений — это то, что оно единственно масштабируемый из этого списка.0xd34df00d
13.05.2015 14:46Я бы не рассматривал это как механизм разделения доступа к данным. Нет вообще никаких данных, есть их преобразования :)
При низком контеншне всё более чем отлично. А при высоком — любые примитивы синхронизации будут не очень оптимальны.
Впрочем, личный скупой опыт показывает, что если контеншн высок, значит, что-то не так с самим алгоритмом, и стоит попытаться его переделать.Duduka
13.05.2015 16:35А в таком «переделанном» варианте насколько потери при использованиии RO-структур будут заметны? И так прийдем к вменяемым алгоритмам/библиотекам, и хаскелисты опять будут повторять ну-у-мы-же-говорили.
0xd34df00d
13.05.2015 16:37Не могу судить, у меня нет бенчмарков под рукой. И вряд ли можно такие бенчмарки за вечерок-другой накропать, всё же STM подразумевает слегка другое мышление, ИМХО.
Я сам немножко хаскелист, но всё равно нежно люблю плюсы :)

NeoCode Автор
12.05.2015 15:18Расскажите подробнее, чувствуется что вы знаете что-то интересное. Насчет Sun OBI, SGI Delta C++, DTS C++…
AlexPublic
12.05.2015 17:54+1Манипуляция с AST из dll уже давно реализовано, в Nemerle. Это сейчас язык с одним из самых сильных инструментов метапрограммирования. Однако это к сожалению не помогло ему вырваться из ниши маргинальных языков. Видимо сказалась ошибка (на мой взгляд) авторов в привязке к платформе .net.
Ну и насчёт зелёных потоков… Откуда такая мания на них? ) Вообще то это инструмент подходящий только для очень специфической цели. Когда имеем тысячи одновременных маленьких задач. Т.е. что-то вроде высоконагруженного сервиса. Во всех остальных случаях системные потоки будут эффективнее.

uxgen
12.05.2015 08:58Я думаю язык будущего не будет иметь никаких спецификаций — каждый будет писать в том стиле в котором хочет, нужно будет только настроить компилятор на распознание всего этого синтаксиса. Библиотеки будут распространяться в байт-коде, чтобы не было исходников которые начнут конфликтовать или не будут компилироваться.

bogolt
12.05.2015 09:20+4Предположим что ваш идеальный язык реализуют. Думаю, что через некоторое время он сам разделится на два языка:
1. Язык минимум — все расширения отключены.
2. Язык максимум — все включено.
Просто потому что у нас есть библиотеки, и наверняка многим из них придется зависеть от каких-то расширений языка. Мы же не сможем отключить GC у нашего приложения если нам нужна библиотека написанная с его помощью.NeoCode Автор
12.05.2015 11:32+1Да, такой вопрос есть. Однозначного ответа я пока не придумал, хотя разные мысли есть…
Наверное, если библиотека реально пользуется какой-то функциональностью, и это обусловлено логикой, смыслом библиотеки — то она должна быть включена. С другой стороны, если библиотека пользуется динамическим выделением памяти и предполагается, что она должна работать как в конфигурации со сборкой мусора так и без нее, то язык должен предоставлять более абстрактные примитивы «выделить память» и «освободить память», которые будут уже подключаться — или к обычному аллокатору, или к сборке мусора (тогда «освобождение» просто сведется к обнулению ссылки)
groaner
12.05.2015 10:22Не кажется ли автору что «красивый и сбалансированный» C# уже сейчас стал излишне усложненным, слишком уж оброс сомнительной необходимости фичами и синтетическими сахарами? (А судя по направлению его развития в будущем ситуация будет только усугубляться)

KvanTTT
12.05.2015 10:59+7Он оброс дополнительными фичами и синтасическим сахаром потому что так удобней разработчикам. Вот например мне часто не хватает Null coalescing operator. Умелое использование фич только подчернет лаконичность кода.

qw1
12.05.2015 11:24+7Видимо, у каждого человека свой уровень комфортной сложности.
Кому-то бейсик в самый раз, кому-то Haskell.
Текущие обновления C# меня нисколько не смущают, пока всё делают правильно.
intet
12.05.2015 16:58+1Фичи и синтетический сахар составляет крайне малую долю в сложности языка. Зато удобства они предоставляют не мало. C# вообще уникальный язык — он один из самых молодых, но при этом имеет огромную поддержку за спиной в виде microsoft. Если бы microsoft так же поддерживала какую-нибудь альтернативу С++, то мы бы давно уже имели более удобный язык.
Buggins
12.05.2015 11:06Чем плох D? Что не так с метапрограммированием?
NeoCode Автор
12.05.2015 11:50Бессистемно как-то (по крайней мере впечатление такое, особенно после просмотра исходников компилятора). Метапрограмминг на строках вместо специальных квазицитат:
string s = "int y;"; mixin(s); // ok y = 4; // ok, mixin declared y
По сути работа со строками лишает программиста возможности использовать систему типов и концепций. Если я хочу макрос, который должен принимать первым аргументом тип, вторым — имя и третьим — операторный блок, то на строках это никак не указать явно. Пока не передам в такой макрос что-то левое и не получу загадочные ошибки компиляции…
Хотя конечно по сравнению с С++ это реальный прогресс. Надо будет собраться с мыслями и уже для Хабра сделать статейку про связь шаблонов и макросов.
В общем D вовсе не плох, но допиливать там надо многое — таково мое ИМХО :)Buggins
12.05.2015 12:32+2mixin template foo() { int y; } void fn() { mixin foo; y = 25; }NeoCode Автор
12.05.2015 13:10Да, это уже лучше (хотя синтаксис все равно производит странное впечатление, но по смыслу лучше).
В общем, философия метапрограмминга сводится к тому, что должно быть два контекста:
1. компилируемый код (и конструкции для подстановки такого кода в произвольные места — шаблоны), ключевое слово template
2. интерпретируемый во время исполнения код — macro; макросы кстати могут писаться на приизвольных языках, не обязательно на том же языке что и код. Главное, чтобы из них был доступ к AST DOM и API компилятора.
При этом в контексте компилируемого кода можно вставлять интерпретируемые на этапе компиляции конструкции (в D — static if, в C++ с некоторой натяжкой — препроцессор). Это ограниченное подмножество операторов «условной компиляции» — для более сложных вещей прелполагаются макросы.
А в интерпретируемый на этапе компиляции код можно вставлять компилируемые вставки — «квазицитаты».
Получается что два контекста симметричны друг относительно друга, и это должно быть отражено на уровне синтаксиса.
vintage
12.05.2015 15:43Рантайм интерпретация — это, мягко выражаясь, не быстро да и областей применения у неё, как мне видится, не много. Зачем вам рантайм интерпретация?
j_wayne
12.05.2015 14:17Мне не очень понятно, почему в golang надо реализовать три метода, чтобы сделать сортировку.
Обычные языки заставляют реализовать по факту, один (в виде лямбды или метода класса компаратора).
Здесь есть обсуждение: тема на StackOverflow
В конце парень показал пример, когда это хорошо работает. Очень частный, на мой взгляд. Почему так?
mbait
12.05.2015 14:27+1Зашел, чтобы увидеть комментарий, что язык — всего лишь инструмент… и не увидел =(
NeoCode Автор
12.05.2015 15:13+4Для любого X всегда найдется Y, такой, что X — всего лишь инструмент для Y :)

Flammar
13.05.2015 23:00-1Когда программа на Си или Фортране достаточно сложна, чтоб содержать «заново написанную, неспецифицированную, глючную и медленную реализацию половины языка Common Lisp», то становится видно, что Си или Фортран — это всего лишь инструмент. А написанную на нём недореализацию половины языка Common Lisp можно, в общем, не считать языком…
0xd34df00d
12.05.2015 20:09+3И из относительно нового — тьюринг-полнота шаблонов, породившая адские конструкции метапрограммирования на этих самых шаблонах.
Нет. Метапрограммирование — это прекрасно, не трогайте, пожалуйста, метапрограммирование, можете им просто не пользоваться, если что. Сугубо опциональная фича.
Но просто неприятно, когда например ключевые слова (struct) используются совсем не для того, для чего они предназначены.
deleteиdefaultиз C++11 в выражениях вида
Foo& operator= (const Foo&) = delete;
вас тоже печалят?
Да и по ряду других замечаний — подождите C++17, будет там async/await, будут корутины, будет, вероятно, ФС и сеть и ещё куча вкусных вещей.
А ещё variant — это точно костыль, такие вещи должны быть в языке вместе с паттерн-матчингом.
Да и вообще, как по мне, если немного закрыть глаза, не думать о последствиях и пофантазировать, больше всего хотелось бы развитую систему типов, без неявных преобразований, без сырых указателей с их арифметикой, и с выводом типов на уровне Хиндли-Милнера. И рефлексию времени компиляции (но на это уже тоже есть пропозалы).
BlackFoks
12.05.2015 22:17Никогда не будет идеального языка, т.к. идеал всегда устареет прежде, чем на него перейдет достаточное кол-во народа. Все существующие языки создавались ведь не с мыслью «а давайте сделаем фиговый язык». Создавалось под задачи и с учетом своего представления об идеальном.
Создадут в 2020 идеальный язык, на нем начнут писать, и потом бах, квантовые компы и все языки на помойку надо, ибо костыли для квантовых компов не айс.Duduka
13.05.2015 05:51+1Это никак не отрицает необходимости создания «идиальных» языков. Без эволюции и революций язык — мертв.

beeruser
13.05.2015 00:34Jedem das seine
A Programming Language for Games — Jonathan Blow
www.youtube.com/playlist?list=PLmV5I2fxaiCKfxMBrNsU1kgKJXD3PkyxO
www.youtube.com/playlist?list=PLmV5I2fxaiCIZVTLzofsocka2LvWBFvBa
Alexey2005
13.05.2015 15:47Я думаю, что в будущем станут рулить не языки программирования, а IDE и среды сборки.
Уже сейчас без IDE крайне неудобно работать над чем-то сложнее Hello World, а в будущем именно связка «IDE плюс среда» начнёт определять разработку, а собственно языки пойдут небольшими front-end плагинами к ней.
К этому всё идёт. Создатели нового языка, хотят они того или нет, должны подстраиваться под существующие крупные IDE, т.к. написать собственную внезапно оказывается значительно сложнее, чем придумать язык и потом состряпать к нему компилятор. А если не будет IDE, то язык не получит популярности, т.к. немного найдётся желающих набирать код в Блокноте или создавать самописные IDE на основе vim…
И вместо «я программирую на C++» или «пишу на Javascript» будут говорить, к примеру, «я программирую в Visual Studio» или «программирую в Eclipse».NeoCode Автор
14.05.2015 10:39-1Согласен полностью. У меня среди evernote-заметок, где я храню различые идеи по языкам программирования, немаленький раздел посвящен IDE; при проектировании языка учитываю связку с IDE (в частности, синтаксис языка должен строиться таким образом, чтобы было удобно работать автокомпилиту, построителю деревьев классов и прочим инструментам IDE, которые должны работать «на лету»); я даже указываю специальные рекомендации к IDE, к организации проектов и т.п., что обычно в язык не входит. А одна из первых вещей с чего я начал эксперименты со своим компилятором (форком D) — это написал простейшую IDE на Qt и делаю визуализатор AST (а затем будут визуализаторы всех преобразований внутри компилятора, вплоть до кодогенератора). То есть не только пользоваться компилятором, но даже разрарабывать его без графического интерфейса неудобно.

solver
14.05.2015 17:44Скорее будут говорить «пишу под .NET» или «пишу под JVM» или «пишу сам .NET или JVM» ))
Т.е. будет пара тройка универсальных платформ для 99% софта. Ну системное что-то, вроде C++ или Rust, на которых эти платформы и будут делать. А IDE под них уже в общем-то сформированы.
grossws
16.05.2015 00:25Системное — это C (интересно, влезет ли в эту область rust). C++ уже для прикладного софта.
AlexPublic
16.05.2015 02:06+1Пишу на C++ (с шаблонами и лямбдами) в том числе и для микроконтроллеров (причём результат местами получается эффективнее C, за счёт агрессивного инлайна у шаблонов, не говоря уже о красоте кода) — никаких проблем не видно. )))
grossws
16.05.2015 02:33Под какие контроллеры? Какой компилятор? Используете ли
-fno-exceptions?
Шаблоны определяются либо рядом, либо в заголовочниках. И в том, и в другом случае на C можно использовать static inline функции. Для иных случаев ещё неплохо работает-flto, который делает инлайн на этапе линковки.AlexPublic
16.05.2015 04:26+1Преимущественно Cortex-M0 и соответственно gcc. Да, no-exceptions и ещё десяток других флагов обычно не применяющихся на взрослых системах. Из общего разве что -std=c++14 (полиморфные лямбды очень хороши) и уровень оптимизации. )))
Ну и в любом случае, даже если добиться аналогичной производительности на C, то всё равно это будет выглядеть на порядки ужаснее и главное намного менее безопасно.
Duduka
16.05.2015 07:12Это совсем не так, были: лисп, фортран, алгол, ада и смолтолк CPU(для которых ассмом были эти языки), я застал такого «зверька» www.cs.tufts.edu/~nr/cs257/archive/ronald-brender/bliss.pdf его можно считать высокоуровневым ассемблером, или чем-то средним между асмом и с--. А еще есть оссам(-2, -пи), тоже ассемблер-подобный язык. HP LJ управляются postscript. В инферно системным языком — лимбо. И Ява… тоже системный язык… jvm, dalvik или их замена — асм, а системные языки — java инфраструктура. Диезы формально — тоже(и ОС на с-диез есть), но как-то не принято их так называть.
grossws
16.05.2015 14:26лисп, фортран, алгол, ада и смолтолк
В текущий момент это устаревшая экзотика. Широкого использования bliss сейчас тоже не заметно (при этом, по сути он не сильно далеко ушел от макроассемблера).
HP LJ управляются postscript
Да, а интерпретатор пайтона интерпретирует пайтон. Но давно ли они пишут firmware на ps?
И Ява… тоже системный язык… jvm, dalvik или их замена — асм, а системные языки — java инфраструктура. Диезы формально — тоже(и ОС на с-диез есть), но как-то не принято их так называть.
С каких пор? Даже процы с jazelle и реализации java card содержат ядро написанное на C с фрагментами ассемблера. JVM не может работать без некого системного слоя, реализующего работу с cpu, памятью и периферией. С CLR то же самое. Какой-нибудь .NET Micro Framework также работает поверх glue-кода на C и не лезет в область системного программирования. Пока CLR не реализован в железе — C# не может быть системным языком. То такими темпами у вас опкоды виртуальной машины rar'а станут системным языком.Duduka
16.05.2015 15:27ада — есть и работает там где с не допускается. Про «Экзотичность» и «устаревание» я ничего и не говорил, но они системные — да, безусловно, как и с.
ps — можно и на форте сделать, а форт чисто системный низкоуровневый.
Ява — по дизайну, количество кода на асм/с ни как не влияет на системность(osv)! (рантайм библиотеки «с» тоже имеют «асм» вставки, он не системный язык?) Диезы — аналогично (в «космос» не заглядывал, но он есть, как и дотНЕТ), по этому МС имеет право поставить себе звездочку в разделе языков системного совту.
# То такими темпами у вас опкоды виртуальной машины rar'а станут системным языком.
Системное на «D», «OCaML» писали и даже пытались ОС на Haskell, можно ли баиткод считать «асм» — да, вероятнее всего.
По этому и сказал: «Это совсем не так», более чем совсем, роль 'с' в другом, он был использован в написании юникс, а системы эмулирующие юникс логично писать на нем же. Баидинги же RSX-11 были на асм, фортран и стековых под паскаль, сишных не было. Как и другие RTOS — писали на разных языках, тут меньше зависимости от ОС и си.
Flammar
19.05.2015 14:39-1Jazelle — это расширение набора команд для ARM, типа MMX на i586, ни в коем случае не самостоятельная система команд. Видел когда-то давно упоминания контроллеров, программируемых на Java. Подозреваю, там урезанная Java, не совсем совместимая со стандартной.
grossws
19.05.2015 16:52Jazelle DBX (Direct Bytecode eXecution) allows some ARM processors to execute Java bytecode in hardware as a third execution state alongside the existing ARM and Thumb modes
Flammar
19.05.2015 14:32Про диезы слышал, правда лет 10 назад, что там «библиотечный» слой якобы очень тонкий, практически сразу — обёртка над нативными функциями из DLL. Если это было так, то движок был слишком сильно привязан к винде. Вообще, насколько совместимы диезовые виртуальные машины и программы под винды и под линукс?
Duduka
19.05.2015 17:32Космос — тоже в стагнируещем состоянии, за месяц 27 коммитов, в основном бошевская конфигурация. К винде? Скорее симуляция среды, чем полное исполнение. Хм, как понимать совместимость с ними? Космос — конструктор, на базе него на кодоплекс строят ОС, это не совсем ВМ, сама ос — скомпилированный бинарник, наличия в сборке ВМ никто не гарантирует.

bormotov
lisp-же…
nosuchip
(((((лисп))))же)
bormotov
так и не нашел, как канонически звучит фраза «внутри каждой большой программы на С обязательно найдется маленький интерпретатор Lisp», или что-то типа «каждый прогарммист на С рано или поздно напишет свой Lisp» — не помню.
Но вот пассаж автора про площадь и путь по прямой однозначно с лиспом ассоциируется (для любителей можно заменить на
форт :)
tzlom
«Любая достаточно сложная программа на Си или Фортране содержит заново написанную, неспецифицированную, глючную и медленную реализацию половины языка Common Lisp.»
vsb
en.wikipedia.org/wiki/Greenspun's_tenth_rule
Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp.
valplo
Включая и сам CL.
artemonster
Да! Да! Да! Форт и/или Лисп нужно допиливать и вводить в массы.
bormotov
с фортом, даже не знаю, а вывод лиспа в массы идет постоянно. То схему придумали, теперь вот кложа.
Боюсь, тут проблема в целеполагании — с одной стороны, нужен инструмент для решения конкретных прикладных задач, с другой — инструмент для головы того, что решает эти самые задачи, и пользуется другими инструментами.
Вон, ребята в DevZen-подкасте говорили, что хаскель нужно выучить потому, что он «голову ломает». У нас в школе в кабинете математики висела цитата Ломоносова «математику затем учить стоит, что она ум в порядок приводит» — вот это всё из той серии.
На чем именно писать конкретную задачу — вопрос второй, первый — что в творится голове у того, кто пишет.
Flammar
Похоже, не в последнюю очередь, для предотвращения этого и было придумано ООП…
bormotov
маловероятно.
отсюда: How Object-Oriented Programming Started
Людям нужны были более высоко-уровневые абстракции, они придумали как бы их записывать так, что бы было удобно выполнять на компьютерах.
Вообще вся эта тема про «идеальный язык», больше похожа на троллинг. Это как выбор идеальной женщины для любого мужчины.
Да что женщины, возьмем совсем простую штуку — нож. Что может быть проще — полоска стали, заточенная с одной стороны с ручкой, нужная для разрезания. Сколько разных ножей бывает? Почему никто не сделал «идеальный нож»?
Ответ очевиден — разные задачи, разный инструмент.
Flammar
Когда нужда в высоко-уровневых абстракциях обнаруживается по ходу дела, к третьей версии системы, тогда и начинают по-быстрому колхозить недо-ЛИСП…
Flammar
Важное уточнение, что «на С или Фортране». Про ООП такое по крайней мере уже не говорят.
bormotov
люди, которые хотя бы пролистали курс sicp, понимают, что реализовать ООП, в принципе ничего сложного.
А те, кто хотя бы читал исходники gtk, так смогут даже с примерами на перевес показать, что нет никаких сложностей писать код в ООП-стиле на plain C.
И если таки хоть немного вернуться к начальному посылу автора — всякие ограничения языков, не прихоть, а фактически или цель, или компромисс, на пути достижения цели, которую ставили перед собой авторы языка.
И если авторы Rust поставили для себя цель — решить проблемы работы с памятью, то в ходе решения и получаются все вот эти навороты, которые кажутся «переусложнены».