
После того, как в предыдущих статьях данной серии обзоров распределённого Java-фреймворка Apache Ignite мы сделали первые шаги, познакомились с основными принципами построения топологии и даже сделали стартер для Spring Boot, неизбежно встаёт вопрос о кэшировании, которое является одной из основных функций Ignite. Прежде всего, хотелось бы понять, нужно ли оно, когда библиотек для кэширования на Java и так полным-полно. Тем, что предоставляется реализация стандарта JCache (JSR 107) и возможность распределённого кэширования в наше время удивить сложно. Поэтому прежде чем (или вместо того чтобы) рассматривать функциональные возможности кэша Apache Ignite, мне бы хотелось посмотреть, насколько он быстр.

Для исследования применялся бенчмарк cache2k-benchmark, разработанный с целью доказательства того, что у библиотеки cache2k кэш самый быстрый. Вот заодно и проверим. Настоящая статья не преследует цель всеобъемлющего тестирования производительности, или хотя бы научно достоверного, пусть этим занимаются разработчики Apache Ignite. Мы просто посмотрим на порядок величин, основные особенности и взаимное расположение в рейтинге, в котором будут ещё cache2k и нативный кэш на ConcurrentHashMap.
В части методики тестирования я не стал изобретать велосипед, и взял ту, которая описана для cache2k. Она состоит в том, что с помощью основанной на JMH библиотеки производится сравнение производительности выполнения ряда типовых операций:
В качестве эталона в методике рассматриваются значения, получаемые для реализации кэша на основе ConcurrentHashMap, поскольку предполагается, что быстрее некуда. Соответственно во всех номинациях борьба идёт за второе место. В cache2k-benchmark (далее CB) реализованы сценарии для cache2k и ряда других провайдеров: Caffeine, EhCache, Guava, Infinispan, TCache, а также нативная реализация на основе ConcurrentHashMap. В CB реализованы и другие бенчмарки, но мы ограничимся этими двумя.
Измерения производились в следующих условиях:
Работа кэша Apache Ignite исследовалась в нескольких режимах, различающихся по топологии (тут рекомендуется вспомнить базовые понятия о топологии Apache Ignite) и распределению нагрузки:
Согласно требованиям CB был реализован класс IgniteCacheFactory (код доступен в GitHub, основан на форке CB). Сервер и клиент создаются со следующими настройками:
Важно, чтобы настройки кэша для клиента и сервера были одинаковыми.
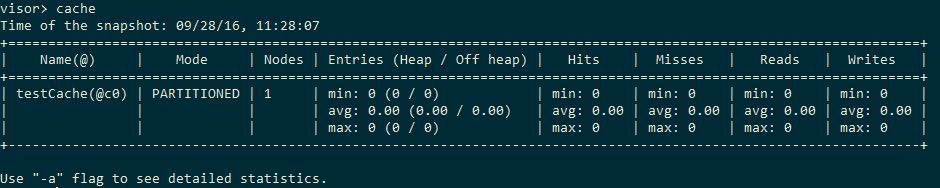
Сервер будет создаваться из командной строки вне теста с помощью той же JVM с опциями -Xms1g -Xmx14g -server -XX:+AggressiveOpts -XX:MaxMetaspaceSize=256m, то есть я ему даю почти всю память. Запустим сервер и подключимся к нему визором (за подробностями отсылаю ко второй статье серии). С помощью команды cache убеждаемся, что кэш существует и девственно чист:
Со CB подключаемся с помощью класса
Здесь мы подключаемся в режиме клиента к нашему серверу и берём у него кэш. Важно по завершении теста остановить клиент, иначе JMH ругается на то, что по завершении теста остались работающие потоки — Ignite для своего функционирования создаёт их множество. Также прошу отметить, что в зачёт идёт время на удаление кэша после каждой итерации. Будем считать это издержками метода исследования, то есть мы смотрим не только производительность самого кэша, но и затраты на его администрирование.
После сборки проекта через mvn clean install можно запускать тесты, например командой
java -jar <BENCHMARK_HOME>\benchmarks.jar PopulateParallelOnceBenchmark -jvmArgs "-server -Xmx14G -XX:+UseG1GC -XX:+UseBiasedLocking -XX:+UseCompressedOops" -gc true -f 2 -wi 3 -w 5s -i 3 -r 30s -t 2 -p cacheFactory=org.cache2k.benchmark.thirdparty.IgniteCacheFactory -rf json -rff e:\tmp\1.json. Настройки JMH взяты из оригинального бенчмарка, мы их обсуждать тут не будем. Параметр "-t 1" указывает количество потоков, которыми мы работаем с кэшем. Памяти я указывал 14Gb, на всякий случай. "-f 2" означает, что для исполнения теста будет подниматься два форка JVM, это способствует резкому уменьшению доверительного интервала (столбец «error» в выводе JMH).
Сначала прогоним тест для Apache Ignite с cacheMode=LOCAL. Поскольку в этом случае во взаимодействии с сервером никакого смысла нет, узел для тестирования подымем в серверном режиме и не будем ни к кому подключаться. Измеряется время, которое потребовалось на то, чтобы закэшировать числа от 1 до 1млн, 2млн, 4млн, 8млн. Для количества потоков 1, 4 и 8 (у меня 8-ядерный процессор) результаты будут такими:
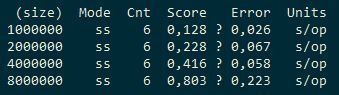
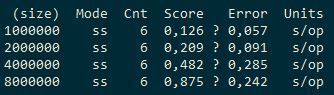
Видим, что если 4 потока быстрее 1 потока примерно вдвое, то добавление ещё 4 потоков даёт выигрыш примерно 20%. То есть масштабирование нелинейное. Для сравнения посмотрим, что покажут ConcurrentHashMap и cache2k.
ConcurrentHashMap:
cache2k:
Таким образом, в локальном режиме при вставке кэш Ignite примерно в 10 раз медленнее ConcurrentHashMap и в 4-5 раз медленнее cache2k. Далее попробуем оценить, какой оверхед даёт партиционирование кэша между двумя серверными узлами на одной машине (то есть кэш будет делиться пополам) — разработчики Ignite предприняли шаги, чтобы он не был гигантским. Они, например, используют собственную сериализацию, которая по их словам в 20 раз быстрее родной. Во время исполнения теста можно посмотреть визор, теперь в этом есть смысл, у нас топология:
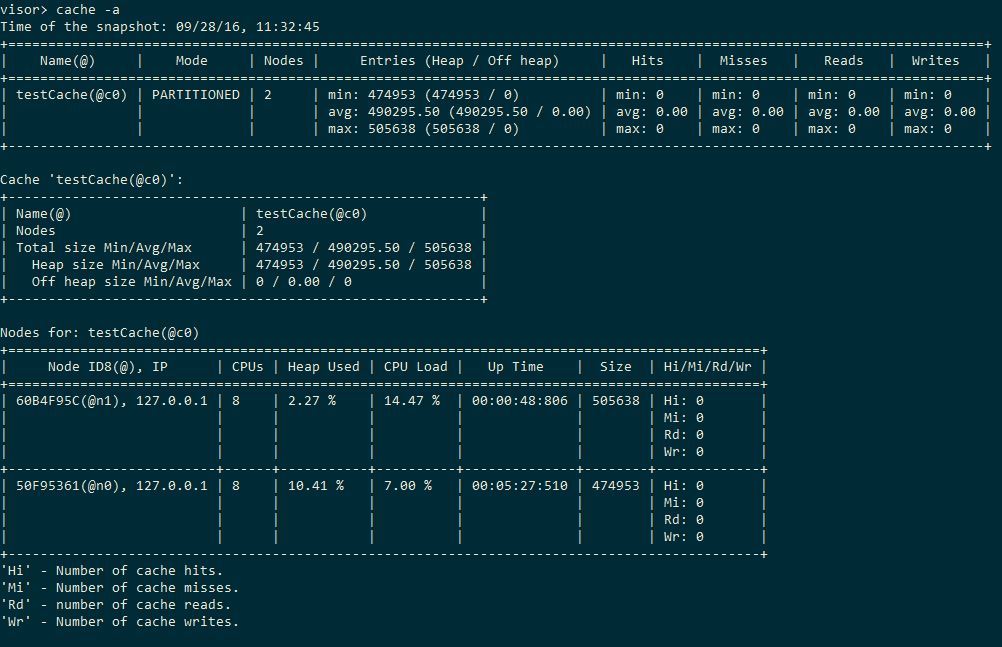
По окончании мы видим вот такие душераздирающие цифры:

То есть партиционирование кэша нам обошлось весьма не дёшево, раз в 10 стало хуже. Режим кэша REPLICATED не исследовался, в нём данные бы хранились в обоих узлах.
Чтобы не усложнять картину множеством параметров, этот тест проведём в 4 потока, Ignite запустим только локально. Здесь используем ReadOnlyBenchmark. Кэш наполняется 100k записями и различным случайным образом из него выбираются значения, с различным hit rate. Измеряется число операций в секунду.
Вот данные Cache2k/ConcurrentHashMap/Ignite:
То есть, Cache2k в 1.5-2.5 раза хуже ConcurrentHashMap, а Ignite ещё в 2-3 раза хуже.
Таким образом, Ignite мягко говоря не потрясает скоростью своего кэширования. Попытаюсь заранее ответить на возможные упрёки:
Ну и так далее. В общем, по моему впечатлению, Ignite следует использовать как архитектурный каркас для распределённых приложений, а не как источник получения производительности. Хотя, возможно, он способен ускорить что-то ещё более тормознутое. IMHO, разумеется.
Приглашаю делиться своими наблюдениями о производительности Ignite.
Для исследования применялся бенчмарк cache2k-benchmark, разработанный с целью доказательства того, что у библиотеки cache2k кэш самый быстрый. Вот заодно и проверим. Настоящая статья не преследует цель всеобъемлющего тестирования производительности, или хотя бы научно достоверного, пусть этим занимаются разработчики Apache Ignite. Мы просто посмотрим на порядок величин, основные особенности и взаимное расположение в рейтинге, в котором будут ещё cache2k и нативный кэш на ConcurrentHashMap.
Методика тестирования
В части методики тестирования я не стал изобретать велосипед, и взял ту, которая описана для cache2k. Она состоит в том, что с помощью основанной на JMH библиотеки производится сравнение производительности выполнения ряда типовых операций:
- Наполнение кэша в несколько потоков
- Производительность в режиме read-only
В качестве эталона в методике рассматриваются значения, получаемые для реализации кэша на основе ConcurrentHashMap, поскольку предполагается, что быстрее некуда. Соответственно во всех номинациях борьба идёт за второе место. В cache2k-benchmark (далее CB) реализованы сценарии для cache2k и ряда других провайдеров: Caffeine, EhCache, Guava, Infinispan, TCache, а также нативная реализация на основе ConcurrentHashMap. В CB реализованы и другие бенчмарки, но мы ограничимся этими двумя.
Измерения производились в следующих условиях:
- JDK 1.8.0_45
- JMH 1.11.3
- Intel i7-6700 3.40Ghz 16Gb RAM
- Windows 7 x64
- JVM flags: -server -Xmx2G
- Apache Ignite 1.7.0
Работа кэша Apache Ignite исследовалась в нескольких режимах, различающихся по топологии (тут рекомендуется вспомнить базовые понятия о топологии Apache Ignite) и распределению нагрузки:
- Локальный кэш (cacheMode=LOCAL) на серверном узле;
- Распределённый кэш на 1 машине (cacheMode=PARTITIONED, FULL_ASYNC), сервер-сервер;
Согласно требованиям CB был реализован класс IgniteCacheFactory (код доступен в GitHub, основан на форке CB). Сервер и клиент создаются со следующими настройками:
Конфигурация сервера
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="ignite.cfg-server" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="gridName" value="testGrid"/>
<property name="clientMode" value="false"/>
<property name="peerClassLoadingEnabled" value="false"/>
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="testCache"/>
<property name="cacheMode" value="LOCAL"/>
<property name="statisticsEnabled" value="false" />
<property name="writeSynchronizationMode" value="FULL_ASYNC"/>
</bean>
</list>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder">
<property name="addresses">
<list>
<value>127.0.0.1:47520..47529</value>
</list>
</property>
</bean>
</property>
<property name="localAddress" value="localhost"/>
</bean>
</property>
<property name="communicationSpi">
<bean class="org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi">
<property name="localAddress" value="localhost"/>
</bean>
</property>
</bean>
</beans>
Важно, чтобы настройки кэша для клиента и сервера были одинаковыми.
Сервер будет создаваться из командной строки вне теста с помощью той же JVM с опциями -Xms1g -Xmx14g -server -XX:+AggressiveOpts -XX:MaxMetaspaceSize=256m, то есть я ему даю почти всю память. Запустим сервер и подключимся к нему визором (за подробностями отсылаю ко второй статье серии). С помощью команды cache убеждаемся, что кэш существует и девственно чист:
Со CB подключаемся с помощью класса
Фабрика кэша для бенчмарка
public class IgniteCacheFactory extends BenchmarkCacheFactory {
static final String CACHE_NAME = "testCache";
static IgniteCache cache;
static Ignite ignite;
static synchronized IgniteCache getIgniteCache() {
if (ignite == null)
ignite = Ignition.ignite("testGrid");
if (cache == null)
cache = ignite.getOrCreateCache(CACHE_NAME);
return cache;
}
@Override
public BenchmarkCache<Integer, Integer> create(int _maxElements) {
return new MyBenchmarkCache(getIgniteCache());
}
static class MyBenchmarkCache extends BenchmarkCache<Integer, Integer> {
IgniteCache<Integer, Integer> cache;
MyBenchmarkCache(IgniteCache<Integer, Integer> cache) {
this.cache = cache;
}
@Override
public Integer getIfPresent(final Integer key) {
return cache.get(key);
}
@Override
public void put(Integer key, Integer value) {
cache.put(key, value);
}
@Override
public void destroy() {
cache.destroy();
}
@Override
public int getCacheSize() {
return cache.localSize();
}
@Override
public String getStatistics() {
return cache.toString() + ": size=" + cache.size();
}
}
}
Здесь мы подключаемся в режиме клиента к нашему серверу и берём у него кэш. Важно по завершении теста остановить клиент, иначе JMH ругается на то, что по завершении теста остались работающие потоки — Ignite для своего функционирования создаёт их множество. Также прошу отметить, что в зачёт идёт время на удаление кэша после каждой итерации. Будем считать это издержками метода исследования, то есть мы смотрим не только производительность самого кэша, но и затраты на его администрирование.
Класс бенчмарка
@State(Scope.Benchmark)
public class IgnitePopulateParallelOnceBenchmark extends PopulateParallelOnceBenchmark {
Ignite ignite;
{
if (ignite == null)
ignite = Ignition.start("ignite/ignite-cache.xml");
}
@TearDown(Level.Trial)
public void destroy() {
if (ignite != null) {
ignite.close();
ignite = null;
}
}
}
Результаты
После сборки проекта через mvn clean install можно запускать тесты, например командой
java -jar <BENCHMARK_HOME>\benchmarks.jar PopulateParallelOnceBenchmark -jvmArgs "-server -Xmx14G -XX:+UseG1GC -XX:+UseBiasedLocking -XX:+UseCompressedOops" -gc true -f 2 -wi 3 -w 5s -i 3 -r 30s -t 2 -p cacheFactory=org.cache2k.benchmark.thirdparty.IgniteCacheFactory -rf json -rff e:\tmp\1.json. Настройки JMH взяты из оригинального бенчмарка, мы их обсуждать тут не будем. Параметр "-t 1" указывает количество потоков, которыми мы работаем с кэшем. Памяти я указывал 14Gb, на всякий случай. "-f 2" означает, что для исполнения теста будет подниматься два форка JVM, это способствует резкому уменьшению доверительного интервала (столбец «error» в выводе JMH).
Наполнение кэша в несколько потоков
Сначала прогоним тест для Apache Ignite с cacheMode=LOCAL. Поскольку в этом случае во взаимодействии с сервером никакого смысла нет, узел для тестирования подымем в серверном режиме и не будем ни к кому подключаться. Измеряется время, которое потребовалось на то, чтобы закэшировать числа от 1 до 1млн, 2млн, 4млн, 8млн. Для количества потоков 1, 4 и 8 (у меня 8-ядерный процессор) результаты будут такими:
 |
 |
 |
Видим, что если 4 потока быстрее 1 потока примерно вдвое, то добавление ещё 4 потоков даёт выигрыш примерно 20%. То есть масштабирование нелинейное. Для сравнения посмотрим, что покажут ConcurrentHashMap и cache2k.
ConcurrentHashMap:
 |
 |
 |
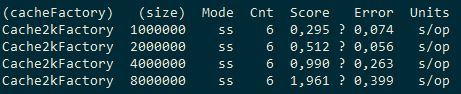
cache2k:
 |
 |
 |
Таким образом, в локальном режиме при вставке кэш Ignite примерно в 10 раз медленнее ConcurrentHashMap и в 4-5 раз медленнее cache2k. Далее попробуем оценить, какой оверхед даёт партиционирование кэша между двумя серверными узлами на одной машине (то есть кэш будет делиться пополам) — разработчики Ignite предприняли шаги, чтобы он не был гигантским. Они, например, используют собственную сериализацию, которая по их словам в 20 раз быстрее родной. Во время исполнения теста можно посмотреть визор, теперь в этом есть смысл, у нас топология:
По окончании мы видим вот такие душераздирающие цифры:
То есть партиционирование кэша нам обошлось весьма не дёшево, раз в 10 стало хуже. Режим кэша REPLICATED не исследовался, в нём данные бы хранились в обоих узлах.
Только чтение
Чтобы не усложнять картину множеством параметров, этот тест проведём в 4 потока, Ignite запустим только локально. Здесь используем ReadOnlyBenchmark. Кэш наполняется 100k записями и различным случайным образом из него выбираются значения, с различным hit rate. Измеряется число операций в секунду.
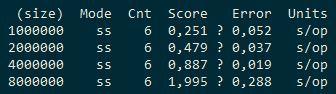
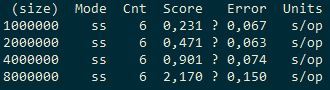
Вот данные Cache2k/ConcurrentHashMap/Ignite:
 |
 |
 |
То есть, Cache2k в 1.5-2.5 раза хуже ConcurrentHashMap, а Ignite ещё в 2-3 раза хуже.
Выводы
Таким образом, Ignite мягко говоря не потрясает скоростью своего кэширования. Попытаюсь заранее ответить на возможные упрёки:
- Я просто не умею его готовить, и если Ignite оттюнить, то будет лучше. Что ж всё, если оттюнить, будет лучше. Исследовалась работа в дефолтной конфигурации, в 90% случаев она и в продакшене будет такая же;
- Яблоки и бананы, продукты разного класса, микроскопом гвозди и т.п. Хотя, возможно, следовало сравнивать с чем-то более навороченным типа Inifinispan, от Ignite в данном исследовании никто не требовал невозможного;
- Устранить overhead, вынести за скобки дорогие операции поднятия узла и создания/удаления кэша, уменьшить частоту hearthbeat и т.п. Но мы же не коня в вакууме меряем?;
- Этот продукт не предназначен для локального использования, нужно enterprise-оборудование. Возможно, но это только размажет весь overhead по топологии, а тут мы его увидели весь разом. Во время тестирования %% CPU и памяти ни разу не достигали 100%;
- Такова специфика продукта. Можно посмотреть на приведённые результаты как на очень достойные, учитывая, невероятную мощь Ignite. Необходимо учитывать, что кэширование осуществляется в другой поток, через сокеты и т.д. С другой стороны, Ignite по-другому и не имеет.
Ну и так далее. В общем, по моему впечатлению, Ignite следует использовать как архитектурный каркас для распределённых приложений, а не как источник получения производительности. Хотя, возможно, он способен ускорить что-то ещё более тормознутое. IMHO, разумеется.
Приглашаю делиться своими наблюдениями о производительности Ignite.
Ссылки
Поделиться с друзьями
Комментарии (3)

kefirr
28.09.2016 19:11+1Сравнение, мягко говоря, не очень корректное. ConcurrentHashMap тупо хранит ссылки на объекты в памяти, а Ignite — это распределённый кэш, там затраты на сериализацию, передачу по сети (если ключ на другой ноде) и многое другое.
Ignite нужен, когда данные не влезают в память одной машины.
A_Gura
Методика тестирования действительно имеет ряд минусов:
Как вы правильно заметили, умение готовить Ignite может кардинально изменить значения бенчмарков. Хотя, скорее всего, полученные значения будут несколько хуже чем у cache2k, в силу его заточенности под локальный кэш.
kmorozov
Согласен с критикой. Единственное, что я не уверен, действительно ли идёт в зачёт поднятие узла и удаление кэша. Надо посмотреть, как там устроено в JMH, может сервисные операции выносятся за скобки.