

Привет всем читателям Habrahabr, в этой статье я хочу поделиться с Вами моим опытом в изучении нейронных сетей и, как следствие, их реализации, с помощью языка программирования Java, на платформе Android. Мое знакомство с нейронными сетями произошло, когда вышло приложение Prisma. Оно обрабатывает любую фотографию, с помощью нейронных сетей, и воспроизводит ее с нуля, используя выбранный стиль. Заинтересовавшись этим, я бросился искать статьи и «туториалы», в первую очередь, на Хабре. И к моему великому удивлению, я не нашел ни одну статью, которая четко и поэтапно расписывала алгоритм работы нейронных сетей. Информация была разрознена и в ней отсутствовали ключевые моменты. Также, большинство авторов бросается показывать код на том или ином языке программирования, не прибегая к детальным объяснениям.
Поэтому сейчас, когда я достаточно хорошо освоил нейронные сети и нашел огромное количество информации с разных иностранных порталов, я хотел бы поделиться этим с людьми в серии публикаций, где я соберу всю информацию, которая потребуется вам, если вы только начинаете знакомство с нейронными сетями. В этой статье, я не буду делать сильный акцент на Java и буду объяснять все на примерах, чтобы вы сами смогли перенести это на любой, нужный вам язык программирования. В последующих статьях, я расскажу о своем приложении, написанном под андроид, которое предсказывает движение акций или валюты. Иными словами, всех желающих окунуться в мир нейронных сетей и жаждущих простого и доступного изложения информации или просто тех, кто что-то не понял и хочет подтянуть, добро пожаловать под кат.
Первым и самым важным моим открытием был плейлист американского программиста Джеффа Хитона, в котором он подробно и наглядно разбирает принципы работы нейронных сетей и их классификации. После просмотра этого плейлиста, я решил создать свою нейронную сеть, начав с самого простого примера. Вам наверняка известно, что когда ты только начинаешь учить новый язык, первой твоей программой будет Hello World. Это своего рода традиция. В мире машинного обучения тоже есть свой Hello world и это нейросеть решающая проблему исключающего или(XOR). Таблица исключающего или выглядит следующим образом:
| a | b | c |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Что такое нейронная сеть?
Нейронная сеть — это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1, Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей — это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация — распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание — возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание — в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?
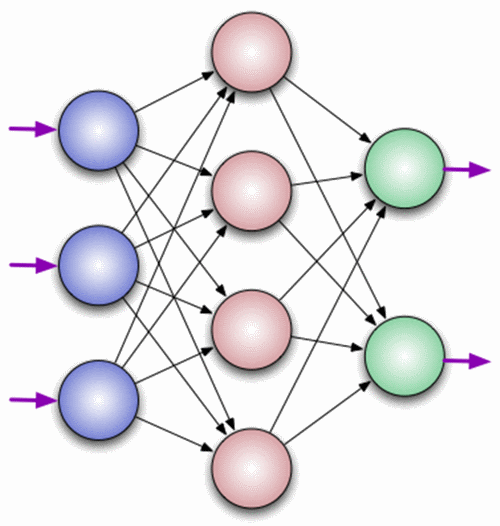
Нейрон — это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.
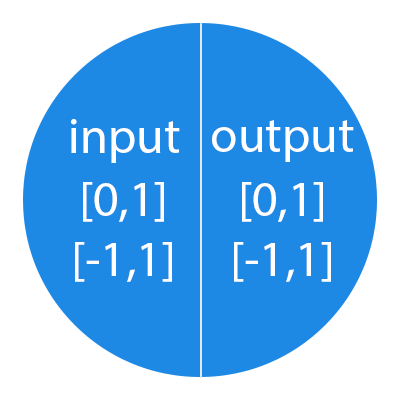
Важно помнить, что нейроны оперируют числами в диапазоне [0,1] или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ — это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр — вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример — смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов — это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить, что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?
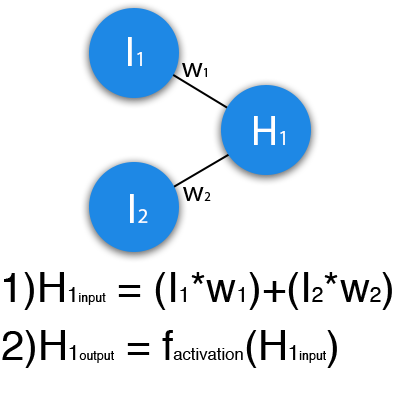
В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H — скрытый нейрон, а буквой w — веса. Из формулы видно, что входная информация — это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации — это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия — это диапазон значений.
Линейная функция
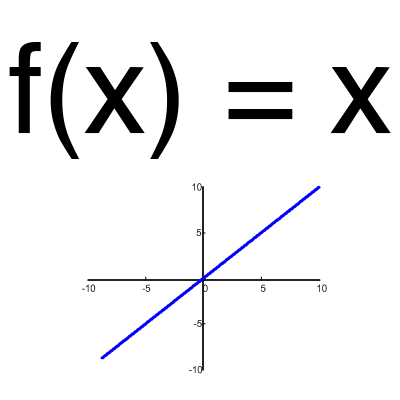
Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид
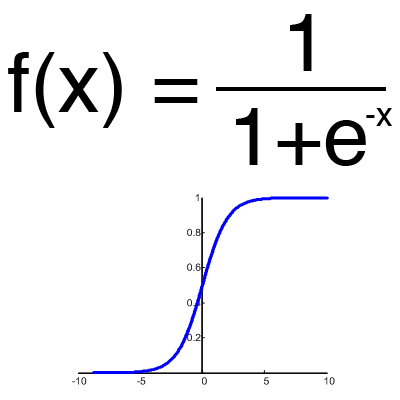
Это самая распространенная функция активации, ее диапазон значений [0,1]. Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс
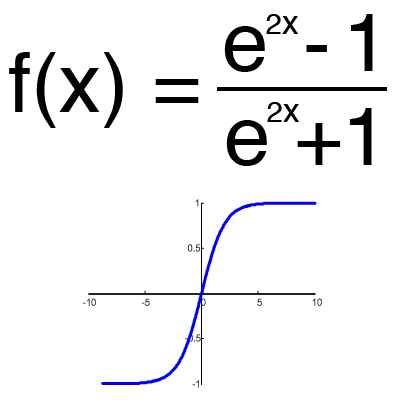
Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет — это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.

Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка — это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.
MSE
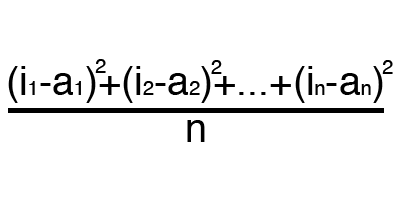
Root MSE
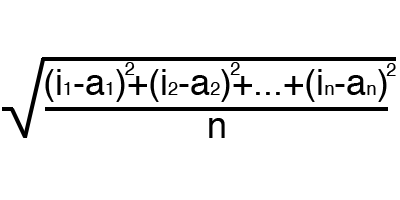
Arctan
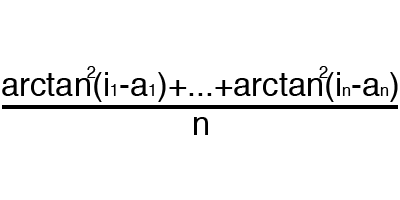
Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Задача
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE.
Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.

H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат — 0.33, ошибка — 45%.
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Использованные ресурсы:
— Раз
— Два
— Три
Комментарии (58)

BubaVV
12.10.2016 16:22Вот близкая по духу, но более краткая статья: https://habrahabr.ru/post/271563/. Для библиографии

dcc0
12.10.2016 16:30Я уже цитировал, но этот материал крайне рекомендую для просмотра. «Показывается пример синхронной работы нейронной сети Хопфилда (сеть Литтла)». Лекция Кирсанова.
https://www.youtube.com/watch?v=W7ux1RfOQeM

SerhiyRomanov
12.10.2016 16:48Огромное спасибо за статью! С нетерпением жду продолжения!
Aclz
12.10.2016 16:58+1А чего ждать, в инете есть куча законченных циклов по нейросетям. Есть даже стенфордские лекции в открытом доступе.
svistkovr
12.10.2016 16:52+3Очень много терминологии вырвано из контекста и непонятно как все связано воедино.
Можете поправить терминологию и формулы, добавьте русский перевод:
- MSE(Mean Squared Error) переводиться как среднеквадратичная ошибка
- Root MSE по формуле — среднеквадратическое отклонение.
- Arctan — вырвано из контекста, непонятно что значит формула и термин в тексте.



Valle
12.10.2016 18:15Интересно, почему в большинстве таких статей обязательно есть тангенс, но про ReLU как будто никто и не знает?

Dark_Daiver
12.10.2016 18:18>Функция активации — это способ нормализации входных данных
Если честно, то мне казалось что это больше способ привнести нелинейность в сеть

mpakep
12.10.2016 18:22-1Не покидает ощущение, что наука о нейросетях находится сейчас в состоянии космологии лет 300 назад, когда люди только начали составлять каталоги увиденного и придумывать названия для происходящих процессов. Есть несколько параметров из за которых сегодняшние нейросети даже отдаленно нельзя сравнивать с ИИ. Что то не то когда есть необходимость у четкой установке количества слоев и каждой из них имеет специализацию. В этом и заключается разум, чтобы самому решить сколько слоев и какие ему необходимы. Задачи в зависимости от сложности могут обойтись отрицанием, парой синапсов и так далее по мере возрастания. В основе сети должен быть механизм ее усложнения в случае необходимости и упрощения в случае упрощения задачи причем в базовой комплектации. Иначе это узкоспециализированное решение под конкретные задачи.

bask
13.10.2016 12:32А зачем их сравнивать с ИИ?
Нейросети вполне успешно решают свои практические задачи. И этого достаточно.
Dark_Daiver
12.10.2016 19:41+2Есть еще несколько замечаний по статье
>Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3)
На самом деле современные сети (те что Deep Learning) могут состоять из десятков слоев. (а то и сотен, если речь идет о Residual сетях)
>нейроны оперируют числами в диапазоне [0,1] или [-1,1]
Мне кажется это справедливо больше для тех случаев, когда сеть использует сигмоиду (или подобную ей) ф-ию активации. Тот же ReLU на выходе дает [0, inf)
>Важно помнить, что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Было бы очень круто рассказать почему это важно
>Тренировочный сет — это последовательность данных, которыми оперирует нейронная сеть
Ну скорее набор данных на которых сеть обучается (тренируется). Работать сеть может и на данных которых в обучающем сете нет. За это и любим.
>Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат
На самом деле совсем не обязательно. Как минимум из-за того, что может наступить переобучение.
>Ошибка — это процентная величина
Совсем не обязательно
>Ошибка формируется каждую эпоху и должна идти на спад
На самом деле не всегда, и все сильно зависит от метода оптимизации. В общем случае, у вас может быть такая ситуация, когда на некотором шаге ошибка выше чем на предыдущем, потому что из-за большого шага вы пролетели локальный минимум и выскочили на «склон» другого минимума.
В случае же семейства SGD, которое используется сейчас практически в любом Machine Learning алгоритме, у вас ошибка будет постоянно скакать то вверх, то вниз.
Кроме описания разных функций ошибки было бы хорошо описать в каких случаях какая ф-ия лучше подходит
Vokanim13
12.10.2016 20:42Скажите пожалуйста, функция активации выходного нейрона (допустим сигмоидальная) имеет диапазон значений от 0 до 1, то есть на выходе мы имеем показатель не выше единицы, а если на выходе нам необходимо иметь значение больше 1, тогда как поступить????

Arnis71
12.10.2016 20:55В таком случае у вас два варианта. Первый — это использовать другую функцию активации, например ReLU, как было подмечено выше в комментариях. Либо, если вы только начинаете разбираться в нейронных сетях, то вам просто нужно найти способ привести ваши значения к нужному диапазону или нормализовать их. Например, когда я писал нейронную сеть для курса акций, я бы мог подавать на вход текущую цену и ждать в ответ другую. Но цены акций могут принимать различные значения. Поэтому, вместо того чтобы подавать на вход цену акций, я вычисляю разницу цен и получаю определенный процент от -100% до +100% или -1 до +1. И нет проблем :)
Samehadar
12.10.2016 22:20А где, собственно, Java и Android?
Arnis71
12.10.2016 22:21Будет в следующих статьях. Это лишь вводная часть.
Samehadar
12.10.2016 22:34В этой статье я не буду делать сильный акцент на Java
Я не хочу показаться каким-то «хейтером», но на мой взгляд надо было прямо так и написать, что в этой статье не будет ничего ни про Java ни про Android тем более.
И что за странная мода пошла на хабре такая, дробить цельную статью на мелкие части без видимых на то причин?)Arnis71
12.10.2016 22:41+2Я написал про Java и Android, чтобы читателю было понятно, в каком направлении будет развиваться тематика моих статей. А на счет дробления, советую перечитать заголовок статьи. Для тех, кто только начинает изучение НН и не имеет при себе никакого опыта в этой сфере, данного материала будет более чем достаточно, чтобы войти в тему и попутно не расплавить себе мозги.

shaman4d
12.10.2016 23:05+1Господи, ну наконец-то нормально рассказали. Уважаемый автор пишите продолжение, пожалуйста.
gaploid
12.10.2016 23:37А есть у кого нибудь ссылка на описание всех этих метрик RAE, MSE, R^2 желательно с визуализацией и на пальцах, я все время в них путаюсь.
Idot
13.10.2016 11:07А будет про то как работает Нейронная Сеть у Норнов из Creatures?
Тогда компьютеры были слабые, но вполне тянули целый зверинец с норнами, гренделями и эттинами. Причём у норнов было большое число лобных долей.

Varim
13.10.2016 12:19А где написано как ошибка выхода текущего сета (или итерации?) влияет на веса входов?
Предположу что должна быть обратная связь.
Или это в следующей части? Наверно тогда стоит части делать покрупнее.Arnis71
13.10.2016 12:21Не совсем понял вас. Что за веса входов? Если вы про входные нейроны, то у них нет весов. Их вход — это данные из тренировочного сета.
Varim
13.10.2016 15:24веса входов — разве W1 W2 W3 W4 W5 W6 — это не веса входов нейронов?
не понятно как ошибочное значение на выходном нейроне переопределяет веса входов W1 — W6 что бы на следующем шаге было минимизированно отклонение от идеального резултата
jomeverest
13.10.2016 13:55А дальше-то что? Как корректируются веса, какой-нибудь алгоритм есть, или про это в следующей части?
Arnis71
13.10.2016 13:57Да, все будет в следующей части. Я уже понял, что всем нужно больше информации.
jomeverest
13.10.2016 14:39Вообще здорово, что вы решили написать статью про НС. Наконец-то становиться понятно что там внутри конкретно происходит. Насколько я понял, НС — это просто функция, дающая соответствие набору чисел другой набор чисел.
Arnis71
13.10.2016 14:47Рад что вам понравилась статья. На счет функции, это не совсем правильное предположение. НС это не функция и не искусственный интеллект. Вам так показалось, потому что — это самый примитивный пример, однако, если вы посмотрите на рекуррентные или многослойные сети это уже не будет казаться так просто. Я думаю вам все станет понятно в следующей статье, где я более подробно опишу работу НС.
Dark_Daiver
13.10.2016 17:56А собственно почему нельзя рассматривать feed forward neural network как ф-ию? Входы есть, выходы тоже есть, отображение входов в выходы тоже присутствует.
kdenisk
14.10.2016 17:48Так и есть. Нейронная сеть — это способ приближения функции из многомерного пространства X в многомерное пространство Y. На входе задачи у вас есть тренировочное множество
T={(x, y)}, где x ? X, а y ? Y
на котором вы обучаете свою нейронную сеть, чтобы она приближала точки из этого множества как можно лучше. То, насколько хорошо сеть приближает точки из T, определяется величиной ошибки. После обучения ваша НС способна вычислять значение в любой точке из области определения.
Одна из причин успеха нейронных сетей в том, что они хорошо приближают сильно нелинейные функции. Но как и в остальных алгоритмах, у НС есть ряд подстроечных параметров и если промахнуться с ними, то приближение будет работать плохо.
Varim
13.10.2016 15:33Подозреваю что самая главная суть и проблема НС это регулирование весов при обучении.
Часть могла бы быть отличной если бы была не такой короткой, тут гораздо лучше описано чем в других статьях, но оборвалась на самом интересном месте.
С нетерпением жду продолжения

Reposlav
13.10.2016 16:20+1Спасибо, очень хорошая статья! Очень надеюсь, что будет продолжение, потому что все предыдущие попытки других авторов заканчивались на первой статье.

TimKruz
13.10.2016 22:20ИМХО, мало подробностей, всё в слишком общих чертах. Интересно знать, почему в ИНС всё именно так, а не иначе — откуда взялись все эти формулы, по каким принципам разрабатывают новые ИНС…
Ибо всё, что написано в этой статье, я несколько лет назад узнал из других статей на Хабре…
Пробовал сделать собственную ИНС — упёрся в непонимание механики ИНС в общем масштабе. Как работает отдельный нейрон — ясно, это сумматор с порогом; как работает вся ИНС — совершенно не ясно… Какие данные подавать на входы, какие данные ожидать на выходе, как обучать…
И ведь в живой ЦНС всё совсем не так, как в ИНС — там нейроны связываются с тысячами других нейронов в самых разных местах сети (аксоны длиной до метра), а не последовательно, есть разные типы нейронов и различные по строению структуры из нейронов (колонки к примеру), есть время жизни нейрона и его связей, миграция нейронов из одних участков в другие, и тому подобное… То есть ИНС — очень грубая модель, но непонятно, почему одни качества ЦНС отбросили, а другие — нет…
Из-за непонимания нейросетей, я стремлюсь реализовать механизм, реализующий те же функции, что и нейросети, только проще для понимания. Остановился пока на нечётком поиске по ассоциативной базе данных — классифицирует, предсказывает и распознаёт; учится полученная система мгновенно, но поисковый алгоритм нужно оптимизировать (примерно знаю, как). Вся проблема в кодировании исходной информации; с текстом всё ясно — буквы/слова/предложения, а каким образом загнать изображение или звук в текст — вариантов море, но неизвестно, какой из них лучше/правильнее…Arnis71
13.10.2016 22:22Я понял вас. Если есть желание, можете написать мне в ЛС и я вам помогу понять все пункты которые вы перечислили:)
Varim
14.10.2016 02:13+1Мне очевидно что ИНС вообще ничем на естественные НС не похожи.
Поэтому всегда удивляет почему упоминают естественные нейроны.
ИНС решают какие то задачи и это отлично.
Но зачем «математическую абстракцию» путать с очень далекой реальностью…
masai
14.10.2016 02:55-1Материалов на русском языке огромное количество. Признаться, не очень понятно, чем ваша статья отличается от тех, что находятся по запросу «нейронные сети». И, к слову, «тренировочный сет» по-русски называется обучающей выборкой, arctan — arctg, sigmoid — сигмоида и т. д. Признайтесь, ведь вы не особо на русском и искали, так?
То, что у вас что-то получилось и вы тратите время (я и сам знаю, что написать даже короткую статью нелегко) — это замечательно! Но все же нужно тщательнее прорабатывать материал. У вас много неточностей, недомолвок. Вы не раз говорите, что нужно делать так-то, но не объясняете почему. Особенно, если вы ориентируетесь на начинающих.
Varim
14.10.2016 03:13Как по мне так «тренировочный сет» лучше чем «обучающей выборкой», гораздо понятней.
Если объяснять не основную мысль, а отвлекаться на побочные нюансы, то статья не получилась бы такой понятной.
Для начинающих как раз нужен прямолинейный старт, а для продолжающих уже подойдут нюансы — почему именно так, а как можно иначе и т.д.
Плохо что части дробленые, потеряется сутьDark_Daiver
14.10.2016 07:20+2>«тренировочный сет» лучше чем «обучающей выборкой»
Только вот «обучающая выборка» это практически общепринятый термин

TimeCoder
14.10.2016 18:01Спасибо за статью, одна из самых понятных по данной теме! Прошу вас продолжить серию, поскольку сочетание хорошего слога и четкости мысли — явление редкое.
Считайте это философией, но мои мысли относительно сетей ушли примерно в следующую тему. Фактически, сеть представляет собой совокупность причинно-следственных связей, работа сети — это проявление принципа причинности в условиях, близких к реальным (множество систем, суперпозиция действий), обучение сети — это универсальный принцип эволюции систем.
Сложно подобрать слова (мысль не до конца оформилась), но попробую перефразировать так: если машина Тьюринга — это универсальная абстракция вычислимости, то нейронная сеть — это универсальная абстракция реальности (совокупности причинно-следственных связей между взаимодействующими объектами).
Отсюда возникает более прикладной вопрос. Существует ли какая-то модель, теория того, каковы границы применимости сетей на практике? Что она не способна решить? Ну например, точность распознавания символов у сетей меньше, чем у человека. Если добавить слоев, сделать сеть очень большой — это повысит точность? Неужели решение ЛЮБОЙ когнитивной задачи это подбор коэффициентов синапсов? Или же есть класс задач, которые сетями не решаемы в принципе?
И совсем прикладной вопрос. Например, я хочу обучить сеть классифицировать изображение. На вход я подаю все пиксели, фактически выстроив изображение в цепочку значений, нормированных до диапазона 0..1, так? Допустим, всего возможно 4 варианта (грубо говоря, я измеряю насыщенность картинки, и эти варианты «низкая», «средняя», «высокая», «крайне высокая»). Что с выходом, он должен быть один (и тогда варианты «ответов» это 0, 0.33, 0.66, 1), или их должно быть 4, и варианты ответов — это единица на одном из выходов с нулями на остальных?kdenisk
14.10.2016 18:36+1Сеть не умеет думать логически и строить рассуждения, т.е. вы никогда не вытащите из НС почему она так решила. Так математика отработала! Но в этом и вся мощь нейросеток. Ведь любой алгоритм, чтобы он работал, нужно сперва осознать. А НС сама обучается, по сути автоматически извлекая из данных статистику и корреляции.
Технологии, думающей как человек, но в основу которой не положен алгоритм, я пока не видел. Придумывать, изобретать — всё это остаётся за людьми.
Отвечая на ваш прикладной вопрос. Можно и так, и так. Т.е. у вас на выходе либо скаляр в диапазоне от 0 до 1, который вы можете пороговой функцией сводить к ближайшему из четырёх вариантов. Либо четырёхвектор, но значения его координат, опять же, будут нечёткими, в диапазоне от 0 до 1. Далее вы можете посчитать расстояние до ваших четырёх базисных точек (1, 0, 0, 0)… (0, 0, 0, 1) и выбрать ту, к которой вектор-ответ ближе.masai
14.10.2016 22:45вы никогда не вытащите из НС почему она так решила. Так математика отработала! Но в этом и вся мощь нейросеток.
Это имеет и обратную сторону. Обучив сеть мы не получаем нового знания, оно остаётся внутри сети.
kdenisk
14.10.2016 23:05Да, так и есть. Единственный способ получить знание из нейронки — это подать ей на вход вектор и получить результат. В этом смысле НС — и есть знание. Просто оно представлено в формате, несовместимом с форматом человеческого мышления (этакая неосознанная компетенция).
masai
14.10.2016 20:44универсальная абстракция реальности
Не совсем понял, что это и как это знание применять. Мне кажется, вы переоцениваете сети. Это рядовой метод машинного обучения, который, к слову, не так уже и часто применяется. Просто вокруг него сложился некий ореол романтики из-за поверхностной схожести в работой мозга. Это не значит, что это плохой метод. Просто вы слишком большие надежды на него возлагаете. :)
Существует ли какая-то модель, теория того, каковы границы применимости сетей на практике?
Конечно. Например, есть теорема Горбаня о том, что нейронные сети — это универсальный аппроксиматор. Но не ищите в этом особо глубокого смысла. Скажем, те же многочлены согласно теореме Вейерштрасса — тоже универсальный аппроксиматор. Просто им не повезло с названием и аналогиями в биологии.
Что она не способна решить?
А что неспособна решить машина Тьюринга? Тут проблема не в том, что сеть может или нет, а в том, что обучать её сложно, так как это в сводится к задаче оптимизации сложной функции и есть риск попасть в локальный минимум, переобучить и так далее.
Если добавить слоев, сделать сеть очень большой — это повысит точность?
Повысит, но это на самом деле плохо, так как приводит к переобученности. Часто сети наоборот, прореживают, чтобы снизить точность.
Неужели решение ЛЮБОЙ когнитивной задачи это подбор коэффициентов синапсов?
Почему вы так решили?
Или же есть класс задач, которые сетями не решаемы в принципе?
Тут опять же проблема не в принципиальной разрешимости, а в том, мы даже разрешимые не всегда хорошо решаем.
dcc0
Строгая дизъюнкция или сложение по модулю два или же исключа?ющее «ИЛИ». А вот «исключительное или» как-то жестоко.
Arnis71
Спасибо, исправил.