
Введение
В наши дни программное обеспечение обычно распространяется в виде сервисов, называемых веб-приложения (web apps) или software-as-a-service (SaaS). Приложение двенадцати факторов — это методология для создания SaaS-приложений, которые:
- Используют декларативный формат для описания процесса установки и настройки, что сводит к минимуму затраты времени и ресурсов для новых разработчиков, подключенных к проекту;
- Имеют соглашение с операционной системой, предполагающее максимальную переносимость между средами выполнения;
- Подходят для развертывания на современных облачных платформах, устраняя необходимость в серверах и системном администрировании;
- Сводят к минимуму расхождения между средой разработки и средой выполнения, что позволяет использовать непрерывное развертывание (continuous deployment) для максимальной гибкости;
- И могут масштабироваться без существенных изменений в инструментах, архитектуре и практике разработки.
Методология двенадцати факторов может быть применена для приложений, написанных на любом языке программирования, и которые используют любые комбинации сторонних служб (backing services) (базы данных, очереди сообщений, кэш-памяти, и т.д.).
Предпосылки
Участники, внёсшие вклад в этот документ, были непосредственно вовлечены в разработку и развёртывание сотен приложений и косвенно были свидетелями разработки, выполнения и масштабирования сотен тысяч приложений во время нашей работы над платформой Heroku.
В этом документе обобщается весь наш опыт использования и наблюдения за самыми разнообразными SaaS-приложениями в дикой природе. Документ является объединением трёх идеальных подходов к разработке приложений: уделение особого внимания динамике органического роста приложения с течением времени, динамике сотрудничества разработчиков, работающих над кодовой базой приложения и устранение последствий эрозии программного обеспечения.
Наша мотивация заключается в повышении осведомлённости о некоторых системных проблемах, которые мы встретили в практике разработки современных приложений, а также для того, чтобы предоставить общие основные понятия для обсуждения этих проблем и предложить набор общих концептуальных решений этих проблем с сопутствующей терминологией. Формат навеян книгами Мартина Фаулера (Martin Fowler) Patterns of Enterprise Application Architecture и Refactoring.
Кому следует читать этот документ?
Разработчикам, которые создают SaaS-приложения. Ops инженерам, выполняющим развёртывание и управление такими приложениями.
Двенадцать факторов
I. Кодовая база
Одна кодовая база, отслеживаемая в системе контроля версий, – множество развертываний
II. Зависимости
Явно объявляйте и изолируйте зависимости
III. Конфигурация
Сохраняйте конфигурацию в среде выполнения
IV. Сторонние службы (Backing Services)
Считайте сторонние службы (backing services) подключаемыми ресурсами
V. Сборка, релиз, выполнение
Строго разделяйте стадии сборки и выполнения
VI. Процессы
Запускайте приложение как один или несколько процессов не сохраняющих внутреннее состояние (stateless)
VII. Привязка портов (port binding)
Экспортируйте сервисы через привязку портов
VIII. Параллелизм
Масштабируйте приложение с помощью процессов
IX. Одноразовость (Disposability)
Максимизируйте надежность с помощью быстрого запуска и корректного завершения работы
X. Паритет разработки/работы приложения
Держите окружения разработки, промежуточного развёртывания (staging) и рабочего развёртывания (production) максимально похожими
XI. Журналирование (Logs)
Рассматривайте журнал как поток событий
XII. Задачи администрирования
Выполняйте задачи администрирования/управления с помощью разовых процессов
I. Кодовая база
Одна кодовая база, отслеживаемая в системе контроля версий, – множество развертываний
Приложение двенадцати факторов всегда отслеживается в системе контроля версий, такой как Git, Mercurial или Subversion. Копия базы данных отслеживаемых версий называется репозиторием кода (code repository), что часто сокращается до code repo или просто до репозиторий (repo)
Кодовая база – это один репозиторий (в централизованных системах контроля версий, как Subvertion) или множество репозиториев, имеющих общие начальные коммиты (в децентрализованных системах контроля версий, как Git).

Всегда есть однозначное соответствие между кодовой базой и приложением:
- Если есть несколько кодовых баз, то это не приложение — это распределенная система. Каждый компонент в распределенной системе является приложением и каждый компонент может индивидуально соответствовать двенадцати факторам.
- Факт того, что несколько приложений совместно используют тот же самый код, является нарушением двенадцати факторов. Решением в данной ситуации является выделение общего кода в библиотеки, которые могут быть подключены через менеджер зависимостей.
Существует только одна кодовая база для каждого приложения, но может быть множество развёртываний одного и того же приложения. Развёрнутым приложением (deploy) является запущенный экземпляр приложения. Как правило, это рабочее развёртывание сайта и одно или несколько промежуточных развёртываний сайта. Кроме того каждый разработчик имеет копию приложения, запущенного в его локальном окружении разработки, каждая из которых также квалифицируется как развёрнутое приложение (deploy).
Кодовая база обязана быть единой для всех развёртываний, однако разные версии одной кодовой базы могут выполняться в каждом из развертываний. Например разработчик может иметь некоторые изменения которые еще не добавлены в промежуточное развёртывание; промежуточное развёртывание может иметь некоторые изменения, которые еще не добавлены в рабочее развёртывание. Однако, все эти развёртывания используют одну и ту же кодовую базу, таким образом можно их идентифицировать как разные развертывания одного и того же приложения.
II. Зависимости
Явно объявляйте и изолируйте зависимости
Большинство языков программирования поставляются вместе с менеджером пакетов для распространения библиотек, таким как CPAN в Perl или Rubygems в Ruby. Библиотеки, устанавливаемые менеджером пакетов, могут быть установлены доступными для всей системы (так называемые “системные пакеты”) или доступными только приложению в директорию содержащую приложение (так называемые “vendoring” и “bundling”).
Приложение двенадцати факторов никогда не зависит от неявно существующих, доступных всей системе пакетов. Приложение объявляет все свои зависимости полностью и точно с помощью манифеста декларации зависимостей. Кроме того, оно использует инструмент изоляции зависимостей во время выполнения для обеспечения того, что неявные зависимости не “просочились” из окружающей системы. Полная и явная спецификация зависимостей применяется равным образом как при разработке, так и при работе приложения.
Например, Gem Bundler в Ruby использует
Gemfile как формат манифеста для объявления зависимостей и bundle exec – для изоляции зависимостей. Python имеет два различных инструмента для этих задач: Pip используется для объявления и Virtualenv – для изоляции. Даже C имеет Autoconf для объявления зависимостей, и статическое связывание может обеспечить изоляцию зависимостей. Независимо от того, какой набор инструментов используется, объявление и изоляция зависимостей должны всегда использоваться совместно – только одного из них недостаточно, чтобы удовлетворить двенадцати факторам.Одним из преимуществ явного объявления зависимостей является то, что это упрощает настройку приложения для новых разработчиков. Новый разработчик может скопировать кодовую базу приложения на свою машину, необходимыми требованиями для которой являются только наличие среды выполнения языка и менеджера пакетов. Всё необходимое для запуска кода приложения может быть настроено с помощью определённой команды настройки. Например, для Ruby/Bundler командой настройки является
bundle install, для Clojure/Leiningen это lein deps.Приложение двенадцати факторов также не полагается на неявное существование любых инструментов системы. Примером является запуск программ ImageMagick и
curl. Хотя эти инструменты могут присутствовать во многих или даже в большинстве систем, нет никакой гарантии, что они будут присутствовать на всех системах, где приложение может работать в будущем, или будет ли версия найденная в другой системе совместима с приложением. Если приложению необходимо запустить инструмент системы, то этот инструмент должен быть включен в приложение.III. Конфигурация
Сохраняйте конфигурацию в среде выполнения
Конфигурация приложения – это все, что может меняться между развёртываниями (среда разработки, промежуточное и рабочее развёртывание). Это включает в себя:
- Идентификаторы подключения к ресурсам типа базы данных, кэш-памяти и другим сторонним службам
- Регистрационные данные для подключения к внешним сервисам, например, к Amazon S3 или Twitter
- Значения зависимые от среды развёртывания такие, как каноническое имя хоста
Иногда приложения хранят конфигурации как константы в коде. Это нарушение методологии двенадцати факторов, которая требует строгого разделения конфигурации и кода. Конфигурация может существенно различаться между развертываниями, код не должен различаться.
Лакмусовой бумажкой того, правильно ли разделены конфигурация и код приложения, является факт того, что кодовая база приложения может быть в любой момент открыта в свободный доступ без компрометации каких-либо приватных данных.
Обратите внимание, что это определение “конфигурации” не включает внутренние конфигурации приложения, например такие как ‘config/routes.rb’ в Rails, или того как основные модули будут связаны в Spring. Этот тип конфигурации не меняется между развёртываниями и поэтому лучше всего держать его в коде.
Другим подходом к конфигурации является использование конфигурационных файлов, которые не сохраняются в систему контроля версия, например ‘config/database.yml’ в Rails. Это огромное улучшение перед использованием констант, которые сохраняются в коде, но по-прежнему и у этого метода есть недостатки: легко по ошибке сохранить конфигурационный файл в репозиторий; существует тенденция когда конфигурационные файлы разбросаны в разных местах и в разных форматах, из за этого становится трудно просматривать и управлять всеми настройками в одном месте. Кроме того форматы этих файлов, как правило, специфичны для конкретного языка или фрэймворка.
Приложение двенадцати факторов хранит конфигурацию в переменных окружения (часто сокращается до env vars или env). Переменные окружения легко изменить между развертываниями, не изменяя код; в отличие от файлов конфигурации, менее вероятно случайно сохранить их в репозиторий кода; и в отличие от пользовательских конфигурационных файлов или других механизмов конфигурации, таких как Java System Properties, они являются независимым от языка и операционной системы стандартом.
Другим подходом к управлению конфигурациями является группировка. Иногда приложения группируют конфигурации в именованные группы (часто называемые “окружениями”) названые по названию конкретного развертывания, например как
development, test и production окружения в Rails. Этот метод не является достаточно масштабируемым: чем больше различных развертываий приложения создается, тем больше новых имён окружений необходимо, например staging и qa. При дальнейшем росте проекта, разработчики могут добавлять свои собственные специальные окружения, такие как joes-staging, в результате происходит комбинаторный взрыв конфигураций, который делает управление развертываниями приложения очень хрупким.В приложении двенадцати факторов переменные окружения являются не связанными между собой средствами управления, где каждая переменная окружения полностью независима от других. Они никогда не группируются вместе в “окружения”, а вместо этого управляются независимо для каждого развертывания. Эта модель которая масштабируется постепенно вместе с естественным появлением большего количества развёртываний приложения за время его жизни.
IV. Сторонние службы (Backing Services)
Считайте сторонние службы (backing services) подключаемыми ресурсами
Сторонняя служба– это любая служба, которая доступна приложению по сети и необходима как часть его нормальной работы. Например, хранилища данных (например, MySQL и CouchDB), системы очередей сообщений (например, RabbitMQ и Beanstalkd), службы SMTP для исходящей электронной почты (например, Postfix) и кэширующие системы (например, Memcached).
Традиционно, сторонние службы, такие как базы данных, поддерживаются тем же самым системным администратором, который разворачивает приложение. Помимо локальных сервисов приложение может использовать сервисы, предоставленные и управляемые третьей стороной. Примеры включают в себя SMTP сервисы (например Postmark), сервисы сбора метрик (такие как New Relic и Loggly), хранилища бинарных данных (напрмер Amazon S3), а также использование API различных сервисов (таких как Twitter, Google Maps и Last.fm).
Код приложения двенадцати факторов не делает различий между локальными и сторонними сервисами. Для приложения каждый из них является подключаемым ресурсом, доступным по URL-адресу или по другой паре расположение/учётные данные, хранящимися в конфигурации. Каждое развертывание приложения двенадцати факторов должно иметь возможность заменить локальную базу данных MySQL на любую управляемую третьей стороной (например Amazon RDS) без каких либо изменений кода приложения. Аналогичным образом, локальный SMTP сервер может быть заменён сторонним (например Postmark) без изменения кода. В обоих случаях необходимо изменить только идентификатор ресурса в конфигурации.
Каждая различная сторонняя служба является ресурсом. Например, база данных MySQL является ресурсом, две базы данных MySQL (используются для фрагментации на уровне приложения) квалифицируются как два отдельных ресурса. Приложение двенадцати факторов считает эти базы данных подключенными ресурсами, что указывает на их слабое связывание с развертыванием, в котором они подключены.

Ресурсы можно по необходимости подключать к развёртыванию и отключать от развёртывания. Например, если база данных приложения функционирует некорректно из-за аппаратные проблемы, администратор может запустить новый сервер базы данных, восстановленный из последней резервной копии. Текущая рабочая база данных может быть отключена, а новая база данных подключена – всё это без каких-либо изменений кода.
V. Сборка, релиз, выполнение
Строго разделяйте стадии сборки и выполнения
Кодовая база трансформируется в развёртывание (не учитывая развёртывание для разработки) за три этапа:
- Этап сборки – это трансформация, которая преобразует репозиторий кода в исполняемый пакет, называемый сборка. Используя версию кода по указанному процессом развёртывания коммиту, этап сборки загружает сторонние зависимости и компилирует двоичные файлы и ресурсы (assets).
- Этап релиза принимает сборку, полученную на этапе сборки, и объединяет её с текущей конфигурацией развёртывания. Полученный релиз содержит сборку и конфигурацию и готов к немедленному запуску в среде выполнения.
- Этап выполнения (также известный как “runtime”) запускает приложение в среде выполнения путём запуска некоторого набора процессов приложения из определённого релиза.
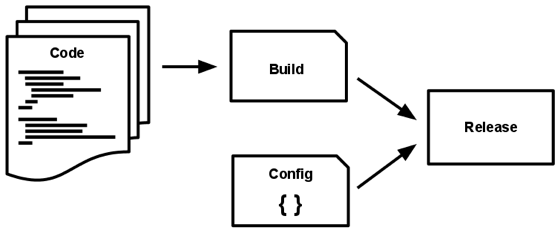
Приложение двенадцати факторов использует строгое разделение между этапами сборки, релиза и выполнения. Например, невозможно внести изменения в код во время выполнения, так как нет способа распространить эти изменения обратно на этап сборки.
Инструменты развертывания, как правило, представляют собой инструменты управления релизами, и что немаловажно, дают возможность отката к предыдущему релизу. Например инструмент развертывания Capistrano сохраняет релизы в подкаталогах каталога с именем
releases, где текущий релиз является символической ссылкой на каталог текущего релиза. Команда Capistrano rollback даёт возможность быстро откатится к предыдущему релизу.Каждый релиз должен иметь уникальный идентификатор, такой как отметка времени релиза (например
2015-04-06-15:42:17) или увеличивающееся число (например v100). Релизы могут только добавляться и каждый релиз невозможно изменить после его создания. Любые изменения обязаны создавать новый релиз.Сборка инициируется разработчиком приложения всяких раз, когда разворачивается новый код. Запуск этапа выполнения, напротив, может происходить автоматически в таких случаях, как перезагрузка сервера, или перезапуск упавшего процесса менеджером процессов. Таким образом, этап выполнения должен быть как можно более технически простым, так как проблемы, которые могут помешать приложению запуститься могут возникнуть в середине ночи, когда нет доступных разработчиков. Этап сборки может быть более сложным, так как возможные ошибки всегда видимы разработчику, который запустил развёртывание.
VI. Процессы
Запускайте приложение как один или несколько процессов, не сохраняющих внутреннее состояние (stateless)
Приложение выполняется в среде выполнения как один или несколько процессов.
В простейшем случае код является независимым скриптом, среда выполнения – ноутбуком разработчика с установленной средой исполнения языка, а процесс запускается из командной строки (например, как
python my_script.py). Другой крайний вариант – это рабочее развёртывание сложного приложения, которое может использовать много типов процессов, каждый из которых запущен в необходимом количестве экземпляров.Процессы приложения двенадцати факторов не сохраняют внутреннее состояние (stateless) и не имеют разделяемых данных (share-nothing). Любые данные, которые требуется сохранить, должны быть сохранены в хранящей состояние сторонней службе, обычно, в базе данных.
Память и файловая система процесса может быть использована в качестве временного кэша для одной транзакции. Например, загрузка, обработка и сохранение большого файла в базе данных. Приложение двенадцати факторов не предполагает, что что-либо закэшированное в памяти или на диске будет доступно следующим запросам или задачам – с большим количеством разноплановых процессов высока вероятность, что следующий запрос будет обработан другим процессом. Даже с одним запущенным процессом перезапуск (вызванный развёртыванием, изменением конфигураций или переносом процесса на другое физическое устройство) приведет к уничтожению всех локальных (памяти, файловой системы) состояний.
Упаковщики ресурсов (asset) (например, Jammit или django-compressor) используют файловую систему как кэш для скомпилированных ресурсов. Приложение двенадцати факторов предпочитает делать данную компиляцию во время этапа сборки, например, как в Rails asset pipeline, а не во время выполнения.
Некоторые веб-системы полагаются на “липкие сессий” – то есть кэшируют данные пользовательских сессии в памяти процесса приложения и ожидают того, что последующие запросы того же пользователя будут перенаправлены к тому же процессу. Липкие сессии являются нарушением двенадцати факторов и их никогда не следует использовать или полагаться на них. Данные пользовательской сессии являются хорошими кандидатами для хранилища данных, которое предоставляет функцию ограничения времени хранения, например, Memcached и Redis.
VII. Привязка портов (Port binding)
Экспортируйте сервисы через привязку портов
Иногда веб-приложения запускают внутри контейнера веб-сервера. Например, PHP-приложение может быть запущено как модуль внутри Apache HTTPD, или Java-приложение может быть запущено внутри Tomcat.
Приложение двенадцати факторов является полностью самодостаточным и не полагается на инъекцию веб-сервера во время выполнения для того, чтобы создать веб-сервис. Веб-приложение экспортирует HTTP-сервис путем привязки к порту и прослушивает запросы, поступающих на этот порт.
Во время локальной разработки разработчик переходит по URL-адресу вида
http://localhost:5000/, чтобы получить доступ к сервису, предоставляемым его приложением. При развертывании слой маршрутизации обрабатывает запросы к общедоступному хосту и перенаправляет их к привязанному к порту веб приложению.Это обычно реализуется с помощью объявления зависимости для добавления библиотеки веб-сервера к приложению такой, как Tornado в Python, Thin в Ruby, и Jetty в Java и других языках на основе JVM. Это происходит полностью в пространстве пользователя, то есть в коде приложения. Контрактом со средой исполнения является привязка приложения к порту для обработки запросов.
HTTP – это не единственный сервис, который может быть экспортирован посредством привязки порта. Почти любой тип серверного ПО может быть запущен как процесс, привязанный к порту и ожидающий входящих запросов. Примеры этого включают ejabberd (предоставляет XMPP протокол) и Redis (предоставляет Redis протокол).
Также обратите внимание, что подход привязки к порту означает, что одно приложение может выступать сторонней службой для другого приложения путём предоставления URL-адреса стороннего приложения как идентификатор ресурса в конфигурации потребляющего приложения.
VIII. Параллелизм
Масштабируйте приложение с помошью процессов
Любая компьютерная программа после запуска представляет собой один или несколько работающих процессов. Исторически веб-приложения принимали различные формы выполнения процессов. К примеру, PHP-процессы выполнятся как дочерние процессы Apache и запускаются по требованию в необходимом для обслуживания поступивших запросов количестве. Java-процессы используют противоположный подход, JVM представляет собой один монолитный мета-процесс, который резервирует большой объем системных ресурсов (процессор и память) при запуске и управляет параллельностью внутри себя с помощью нитей исполнения (threads). В обоих случаях запущенные процессы лишь минимально видны для разработчика приложения.

В приложении двенадцати факторов процессы являются сущностями первого класса. Процессы в приложении двенадцати факторов взяли сильные стороны из модели процессов unix для запуска демонов. С помощью этой модели разработчик может спроектировать своё приложение таким образом, что для обработки различной рабочей нагрузки необходимо назначить каждому типу работы своего типа процесса. Например, HTTP-запросы могут быть обработаны веб-процессом, а длительные фоновые задачи обработаны рабочим процессом.
Это не исключает возможность использования внутреннего мультиплексирования для индивидуальных процессов через потоки выполнения виртуальной машины или асинхронные/событийные модели в инструментах таких, как EventMachine, Twisted и Node.js. Но каждая индивидуальная виртуальная машина может масштабироваться только ограничено (вертикальное масштабирование), поэтому приложение должно иметь возможность быть запущенным как несколько процессов на различных физических машинах.
Модель, построенная на процессах, действительно сияет, когда приходит время масштабирования. Отсутствие разделяемых данных и горизонтальное разделение процессов приложения двенадцати факторов означает, что добавление большего параллелизма является простой и надёжной операцией. Массив процессов различного типа и количество процессов каждого типа называются формированием процессов (process formation).
Процессы приложения двенадцати факторов никогда не должны демонизироваться и записывать PID файлы. Вместо этого они должны полагаться на менеджер процессов операционной системы (например, Upstart, распределенный менеджер процессов на облачной платформе, или инструмент как Foreman в процессе разработки) для управления потоком вывода, реагирования на падения процесса и обработки инициированных пользователем перезагрузки или завершения работы.
IX. Одноразовость (Disposability)
Максимизируйте надежность с помощью быстрого запуска и корректного завершение работы
Процессы приложения двенадцати факторов являются одноразовыми, это означает, что они могут быть запущены и остановлены любой в момент. Это способствует стабильному и гибкому масштабированию, быстрому развёртыванию изменений кода и конфигураций и надежности рабочего развёртывания.
Процессы должны стараться минимизировать время запуска. В идеале процесс должен затратить всего несколько секунд от момента времени, когда выполнена команда запуска, и до того момента, когда процесс запущен и готов принимать запросы или задачи. Короткое время запуска предоставляет большую гибкость для релиза и масштабирования. Кроме того, это более надежно, так как менеджер процессов может свободно перемещать процессы на новые физические машины при необходимости.
Процессы должны завершаться корректно, когда они получают SIGTERM сигнал от диспетчера процессов. Для веб-процесса корректное завершение работы достигается путем прекращения прослушивания порта сервиса (таким образом, отказаться от каких-либо новых запросов), что позволяет завершить текущие запросы и затем завершиться. В этой модели подразумевается, что HTTP-запросы короткие (не более чем на несколько секунд), в случае длинных запросов клиент должен плавно попытаться восстановить подключение при потере соединения.
Для процесса, выполняющего фоновые задачи (worker), корректное завершение работы достигается путем возвращения текущей задачи назад в очередь задач. Например, в RabbitMQ рабочий процесс может отправлять команду
NACK; в Beanstalkd задача возвращается в очередь автоматически, когда рабочий процесс отключается. Системы, основанные на блокировках такие, как Delayed Job должны быть уведомлены, чтобы освободить блокировку задачи. В этой модели подразумевается, что все задачи являются повторно входимыми, что обычно достигается путем оборачивания результатов работы в транзакции или путем использования идемпотентных операций.Процессы также должны быть устойчивыми к внезапной смерти в случае отказа аппаратного обеспечения. Хотя это менее вероятное событие, чем корректное завершение работы сигналом
SIGTERM, оно все же может случиться. Рекомендуемым подходом является использование надежных очередей задач, таких как Beanstalkd, которые возвращают задачу в очередь когда клиент отключается или превышает лимит времени. В любом случае приложение двенадцати факторов должно проектироваться так, чтобы обрабатывать неожиданные и неизящные выключения. Архитектура только аварийного выключения (Crash-only design) доводит эту концепцию до её логического завершения.X. Паритет разработки/работы приложения
Держите окружения разработки, промежуточного развёртывания (staging) и рабочего развёртывания (production) максимально похожими
Исторически существуют значительные различия между разработкой (разработчик делает живые изменения на локальном развёртывании приложения) и работой приложения (развёртывание приложения с доступом к нему конечных пользователей). Эти различия проявляются в трех областях:
- Различие во времени: разработчик может работать с кодом, который попадёт в рабочую версию приложения только через дни, недели или даже месяцы.
- Различие персонала: разработчики пишут код, OPS инженеры разворачивают его.
- Различие инструментов: разработчики могут использовать стек технологий, такой как Nginx, SQLite, и OS X, в то время как при рабочем развертывании используются Apache, MySQL и Linux.
Приложение двенадцати факторов спроектировано для непрерывного развертывания благодаря минимизации различий между разработкой и работой приложения. Рассмотрим три различия, описанных выше:
- Сделать различие во времени небольшим: разработчик может написать код, и он будет развёрнут через несколько часов или даже минут.
- Сделать небольшими различия персонала: разработчик который написал код, активно участвует в его развертывание и наблюдет за его поведением во время работы приложения.
- Сделать различия инструментов небольшими: держать окружение разработки и работы приложения максимально похожими.
Резюмируя сказанное выше в таблицу:
| Традиционное приложение | Приложение двенадцати факторов | |
|---|---|---|
| Время между развёртываниями | Недели | Часы |
| Автор кода/тот кто разворачивает | Разные люди | Те же люди |
| Окружение разработки/работы приложения | Различные | Максимально похожие |
Сторонние службы, такие как базы данных, системы очередей сообщений и кэш, является одной из областей, где паритет при разработке и работе приложения имеет важное значение. Многие языки предоставляют библиотеки, которые упрощают доступ к сторонним службам, включая адаптеры для доступа к различных типам сервисов. Некоторые примеры, в таблице ниже.
| Тип | Язык | Библиотека | Адаптеры |
|---|---|---|---|
| База данных | Ruby/Rails | ActiveRecord | MySQL, PostgreSQL, SQLite |
| Очередь сообщений | Python/Django | Celery | RabbitMQ, Beanstalkd, Redis |
| Кэш | Ruby/Rails | ActiveSupport::Cache | Память, файловая система, Memcached |
Иногда разработчики находят удобным использовать лёгкие сторонние службы в их локальном окружении, в то время как более серьезные и надежные сторонние сервисы будут использованы в рабочем окружении. Например используют SQLite локально и PostgreSQL в рабочем окружении; или память процесса для кеширования при разработке и Memcached в рабочем окружении.
Разработчик приложения двенадцати факторов должен сопротивляется искушению использовать различные сторонние сервисы при разработке и в рабочем окружении, даже когда адаптеры теоретически абстрагированы от различий в сторонних сервисах. Различия в используемых сторонних сервисах означают, что может возникнуть крошечная несовместимость, которая станет причиной того, что код, который работал и прошёл тесты при разработке и промежуточном развёртывании не работает в рабочем окружении. Такой тип ошибок создаёт помехи, которые нивелируют преимущества непрерывного развёртывания. Стоимость этих помех и последующего восстановления непрерывного развёртывания является чрезвычайно высокой, если рассматривать в совокупности за все время существования приложения.
Установка локальных сервисов стала менее непреодолимой задачей, чем она когда то была. Современные сторонние сервисы, такие как Memcached, PostgreSQL и RabbitMQ не трудно установить и запустить благодаря современным менеджерам пакетов, таким как Homebrew и apt-get. Кроме того, декларативные инструменты подготовки окружения, такие как Chef и Puppet в сочетании с легковесным виртуальным окружением, таким как Vagrant позволяют разработчикам запустить локальное окружение которое максимально приближено к рабочему окружению. Стоимость установки и использования этих систем ниже по сравнению выгодой получаемой от паритета разработки/работы приложения и непрерывного развёртывания.
Адаптеры для различных сторонних сервисов по-прежнему полезны, потому что они позволяют портировать приложение для использования новых сторонних сервисов относительно безболезненно. Но все развёртывания приложения (окружение разработчика, промежуточное и рабочее развёртывание) должны использовать тот же тип и ту же версию каждого из сторонних сервисов.
XI. Журналирование (Logs)
Рассматривайте журнал как поток событий
Журналирование обеспечивает наглядное представление поведения работающего приложения. Обычно в серверной среде журнал записывается в файл на диске (“logfile”), но это только один из форматов вывода.
Журнал – это поток агрегированных, упорядоченных по времени событий, собранных из потоков вывода всех запущенных процессов и вспомогательных сервисов. Журнал в своём сыром виде обычно представлен текстовым форматом с одним событием на строчку (хотя трассировки исключений могут занимать несколько строк). Журнал не имеет фиксированного начала и конца, поток сообщений непрерывен, пока работает приложение.
Приложение двенадцати факторов никогда не занимается маршрутизацией и хранением своего потока вывода. Приложение не должно записывать журнал в файл и управлять файлами журналов. Вместо этого каждый выполняющийся процесс записывает свой поток событий без буферизации в стандартный вывод
stdout. Во время локальной разработки разработчик имеет возможность просматривать этот поток в терминале, чтобы наблюдать за поведением приложения.При промежуточном и рабочем развертывании поток вывода каждого процесса будет захвачен средой выполнения, собран вместе со всеми другими потоками вывода приложения и перенаправлен к одному или нескольким конечным пунктам назначения для просмотра и долгосрочной архивации. Эти конечные пункты архивации не являются видимыми для приложения и настраиваемыми приложением, вместо этого они полностью управляются средой выполнения. Маршрутизаторы журналов с открытым исходным кодом (например, Logplex и Fluent) могут быть использованы для этой цели.
Поток событий приложения может быть перенаправлен в файл или просматриваться в терминале в режиме реального времени. Наиболее значимым является то, что поток событий может быть направлен в систему индексирования и анализа журналов, такую как Splunk, или систему хранения данных общего назначения, такую как Hadoop/Hive. Эти системы обладают большими возможностями и гибкостью для досконального анализа поведения приложение в течении времени, что включает в себя:
- Поиск конкретных событий в прошлом.
- Крупномасштабные графики трендов (например, запросов в минуту).
- Активные оповещения согласно эвристическим правилам, определяемых пользователем (например, оповещение, когда количество ошибок в минуту превышает определенный порог).
- Papertrail papertrailapp.com
- Loggly www.loggly.com
- Logentries logentries.com
И достаточно мощный и гибкий в настройке стек для самостоятельного развёртывания: Elasticsearch, Logstash, Kibana (ELK).
XII. Задачи администрирования
Выполняйте задачи администрирования/управления с помощью разовых процессов
Формирование процессов является некоторым набором процессов, которые необходимы для выполнения регулярных задач приложения (таких как обработка веб-запросов), когда оно исполняется. В дополнение к этому, разработчикам периодически необходимо выполнять разовые задачи администрирования и обслуживания приложения, такие как:
- Запуск миграции базы данных (например
manage.py migrateв Django,rake db:migrateв Rails). - Запуск консоли (также известной как оболочка REPL), чтобы запустить произвольный код или проверить модели приложения с действующей базой данных. Большинство языков предоставляют REPL путем запуска интерпретатора без каких-либо аргументов (например,
pythonorperl), а в некоторых случаях имеют отдельную команду (напримерirbв Ruby,rails consoleв Rails). - Запуск разовых скриптов, хранящихся в репозитории приложения (например,
php scripts/fix_bad_records.php).
Разовые процессы администрирования следует запускать в среде идентичной регулярным длительным процессам приложения. Они запускаются на уровне релиза, используя те же кодовую базу и конфигурацию, как и любой другой процесс, выполняющий этот релиз. Код администрирования должен поставляться вместе с кодом приложения, чтобы избежать проблем синхронизации.
Те же самые методы изоляции зависимостей должны быть использованы для всех типов процессов. Например, если веб-процесс Ruby использует команду
bundle exec thin start, то для миграции базы данных следует использовать bundle exec rake db:migrate. Аналогичным образом для программы на Python с использованием Virtualenv следует использовать поставляемый bin/python как для запуска веб-сервера Tornado, так и для запуска любых manage.py процессов администрирования.Методология двенадцати факторов отдаёт предпочтение языкам, которые предоставляют REPL оболочки из коробки, и которые позволяют легко выполнять разовые скрипты. В локальном развертывании разработчики выполняют разовый процесс администрирования с помощью консольной команды внутри каталога с приложением. В рабочем развертывании разработчики могут использовать ssh или другой механизм выполнения удаленной команды, предоставленный средой выполнения, для запуска такого процесса.
Исправления ошибок и более подходящие переводы можно присылать:
- Комментарием тут
- Личным сообщением
- Пулл реквестом на GitHub
- Пулл реквестом в официальный репозиторий (когда перевод примут в основную ветку)
Спасибо amalinin и litchristina за помощь в подготовке перевода
Комментарии (5)

Jabher
26.05.2015 21:29+1Да, кстати. Для журналирования в ноде настоятельно рекомендуется joylent логгер bunyan — он как раз по умолчанию пишет прямо JSON-ом в stdout, который уже как раз можно пайпить куда надо.
Про одноразовость (disposability) — тут немножко более интересный момент, который в оригинальной статье не очень хорошо объяснен, и может быть не понятен не очень продвинутым разработчикам.
Перевод не очень точен, более верно — «утилизируемость», как есть, это гораздо более точно дает понимание происходящего: процесс действительно может быть перезапущен в любой момент времени и при этом не потеряет никаких данных. В это вкладываются два понятия: атомарность операций (процесс не умирает до завершения или отката операции) и отсутствие состояния — все хранится в БД или очереди сообщений, а процессы просто разворачиваются на имеющихся данных и работают в них. Это все делает приложение практически непотопляемым — максимум полежит немножко и дальше пойдет.
mahnunchik Автор
27.05.2015 06:42Для ноды в своё время пришлось написать свой небольшой логгер, вот предыстория toster.ru/q/38217, вот сам модуль www.npmjs.com/package/mag
«утилизируемость» — думаю лучший перевод. Мне не понравился «удаляемось», поэтому пришлось использовать «одноразовость».
IamKarlson
10.06.2015 21:27Хотел было написать чем вам не угодил Winston, но прочитав тред на тостере вопрос отпал. Тем не менее, Jabher, не bunyan'ом единым, мне вот очень нравится winston. Хотя бы тем что у него миллион транспортов. Поэтому лучше отправлять к детальному сравнению, в котором каждый может определить что ему подходит больше.
Jabher
10.06.2015 23:35Винстон плох тем, что смешивает собственно логгинг и вывод (читай, транспорты винстона). Пока ты делаешь приложение на ноде — да, винстон это круто, удобно, чувствуешь себя хипстером. Когда приходишь в более-менее серьезный проект (а я последний год кручусь в той или иной степени в энтерпрайз-левел проектах) — там стек из джавы, сей, руби и нода там появилась порой по очень странным причинам. И крутится все это на двадцати энвайроментах с разной степенью ограничений безопасности. И все логи сыпятся в какой-нибудь elasticsearch или splunk, из них всех надо вытаскивать данные… И заморачиваться с транспортами под каждый энв в условиях такого зоопарка — гемморой. Проще переложить эту работу на админов и следовать соглашению — приложение пишет в STDOUT, а окружение дальше само занимается вопросом логов.
Jabher
Дважды бы плюсанул, честное слово.
Сам хотел перевести не так давно, опередили!