
- получение заявок от пользователей на некоторые типовые последовательные «тяжелые» вычисления;
- осуществление вычислений;
- выдача информации (по запросу) об оставшемся времени вычислений;
- выдача результатов вычислений по их завершению.

Следует уточнить ряд обстоятельств исследования:
- под последовательным вычислением будем понимать вычисление, которое осуществляется не более чем одним ядром процессора (нераспараллеливаемый процесс), т.к. на данном этапе создания системы задача распараллеливания самих вычислений не стоит. В дальнейшем слово «последовательное» будем опускать;
- вычисления являются типовыми, т.е. используется один и тот же алгоритм для рассчетов, время выполнения которого для заданной вычислительной системы преимущественно зависит от размерности исходных данных (размерность обозначим числом N), а не от их фактических значений;
- вычисления предполагаются преимущественно «тяжелыми», что требует существенное время на выполнение (от секунд до часов и, возможно, более);
- предполагается неизвестным характер изменения интенсивности заявок на вычисления и соответствующие им значения размерностей N.
Первоначальные попытки автора прогнозировать время вычислений имели слабую точность. Для алгоритма «на глаз» подбиралась зависимость времени от N с помощью степенных коэффициентов так, чтобы минимизировать среднее отклонение. В результате таких пробных расчетов были получены не слишком приятные результаты:
| N | Реальное время (сек) | Расчетное время (сек) |
| 417 | 9,60 | 5,04 ± 0,96 |
| 689 | 26,20 | 18,33 ± 3,50 |
| 1165 | 78,40 | 70,56 ± 13,48 |
| 2049 | 264,60 | 300,34 ± 57,40 |
| 3001 | 654,20 | 799,24 ± 152,74 |
| 3341 | 875,80 | 1 052,50 ± 201,13 |
| 4769 | 2323,60 | 2 621,69 ± 501,01 |
| 5449 | 3424,10 | 3 690,10 ± 705,18 |
| 6129 | 4811,80 | 4 988,97 ± 953,40 |
На помощь, как это нередко бывает, пришли классики. Вспомнились давно забытые слова «интерполяция», «экстраполяция», и начались поиски в интернете в подозрении правильности выбранного направления. Был перечитан ряд постов, статей и прочих ресурсов. Главный вывод таков: для решения задачи прогнозирования значений некоторой неизвестной функции одной переменной чаще всего используют полиномы Чебышева или Лагранжа. Оказалось, что имеет смысл применять полиномы Чебышева (в принципе, их заменой мог бы стать и МНК) в тех случаях, когда нет доверия к имеющемуся набору «аргумент-значение», а полиномы Лагранжа хороши в обратном случае. Второе выглядело тем, что нужно. Действительно, почему бы не создать «идеальные» условия для тестирования алгоритма вычислений на конкретной системе (выделить ядро с нагрузкой 100%) и не набрать достаточную статистику для построения полинома Лагранжа?

«Lagrange polynomial» участника User:Acdx — Self-made, based on Image:Lagrangepolys.png. Под лицензией CC BY-SA 3.0 с сайта Викисклада.
{kind=link}
Между тем, встречаются уже реализованные алгоритмы построения полинома Лагранжа, например здесь. Адаптированный под задачу алгоритм начал показывать похожие (по модулю отклонения) результаты при экстраполяции на возрастающем наборе статистики (для прогноза при N=1165 использовалось реальное время при N=417 и N=689, для прогноза при N=2049: N=417, N=689 и N=1165, и т.д.):
| N | Реальное время (сек) | Расчетное время (сек) |
| 417 | 9,60 | - |
| 689 | 26,20 | - |
| 1165 | 78,40 | 55,25 |
| 2049 | 264,60 | 253,51 |
| 3001 | 654,20 | 617,72 |
| 3341 | 875,80 | 863,74 |
| 4769 | 2323,60 | 2899,77 |
| 5449 | 3424,10 | 2700,96 |
| 6129 | 4811,80 | 5862,79 |
При интерполяции полиномом Лагранжа результаты получились впечатляющими начиная с N=2049 (из выборки последовательно исключалось по одному измерению и производился расчет по аргументу исключенного измерения):
| N | Реальное время (сек) | Расчетное время (сек) |
| 417 | 9,60 | - |
| 689 | 26,20 | 2,58 |
| 1165 | 78,40 | 98,35 |
| 2049 | 264,60 | 245,74 |
| 3001 | 654,20 | 664,15 |
| 3341 | 875,80 | 862,91 |
| 4769 | 2323,60 | 2407,75 |
| 5449 | 3424,10 | 3251,71 |
| 6129 | 4811,80 | - |
Действительно, при N=689 и N=1165 отклонение прогнозируемого значения от реального значения составило соответственно около 90% и 25%, что недопустимо, однако, начиная с N=2049 и далее отклонение держалось в пределах 1,5-7%, что можно трактовать как хороший результат.
Полином: F(x) = -5.35771746746065e-22*x^7 + 1.23182612519573e-17*x^6 — 1.14069960055193e-13*x^5 + 5.44407657742344e-10*x^4 — 1.39944148088413e-6*x^3 + 0.00196094886960409*x^2 — 1.22001773413031*x + 263.749105425487
Степень полинома, при необходимости, можно снизить до требуемой путем легкого изменения алгоритма (в принципе, для задачи автора можно было обойтись и 3-й степенью)
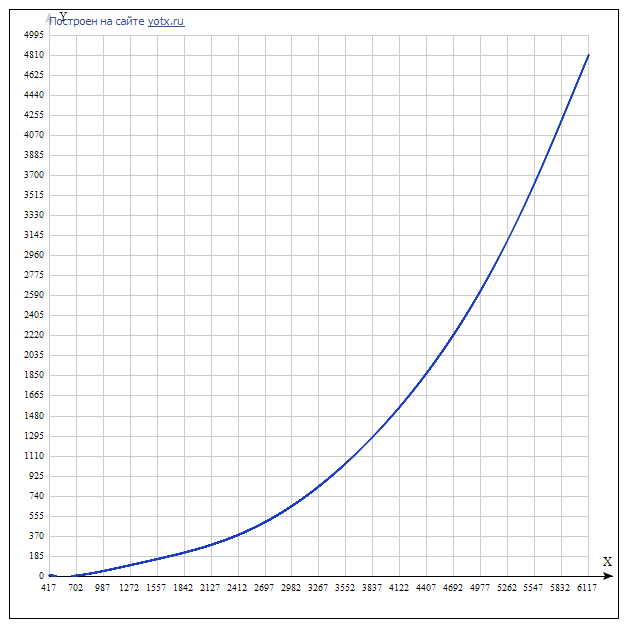
Важно отметить, что полином интерполяционный, а значит, при значениях вне диапазона [Nmin;Nmax] качество прогноза оставляет желать лучшего:
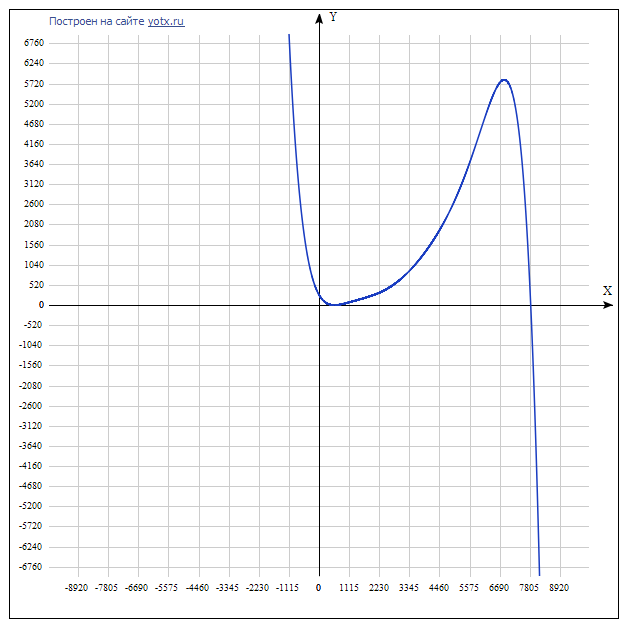
Вывод: имеет смысл заблаговременно набрать достаточную статистику в «идеальных» условиях (особенно для больших значений N), построить полином Лагранжа и при поступлении заявок получать прогноз времени их вычислений подставляя Ni в готовый полином.
Такой подход предельно понятен, однако, когда мы говорим о прогопроцессорной (многоядерной) системе, ситуация усложняется:
- Во-первых, вышеописанный подход подходит для случаев, когда число заявок (выполняемых задач) X<=Y, где Y – число ядер. Иными словами, система ни делает ничего, кроме вычислений, и каждая задача обеспечивается 100%-м ресурсом соответствующего ядра.
- Во-вторых, при X>Y ОС должна делить вычислительный ресурс между задачами (например, при ручном запуске задач в Ubuntu server 14.04 через screen вычислительный ресурс делился между задачами равномерно согласно формуле X/Y*100%).
- В-третьих, заранее неизвестен характер поступления заявок и соответствующих значений N, что делает невозможным прогноз времени по какой-либо формуле распределения вычислительного ресурса (например, для той же X/Y*100%).
Анализ данных аспектов показал, что спрогнозировать время выполнения заявки заранее невозможно, но это значение может корректироваться при наступлении некоторых событий, влияющих на текущий вычислительный ресурс, выделяемый для вычислений, с последующей выдачей пользователю. Такими событиями являются: поступление новой задачи и завершение выполняемой задачи. Именно при наступлении этих событий предлагается осуществлять коррекцию прогноза.
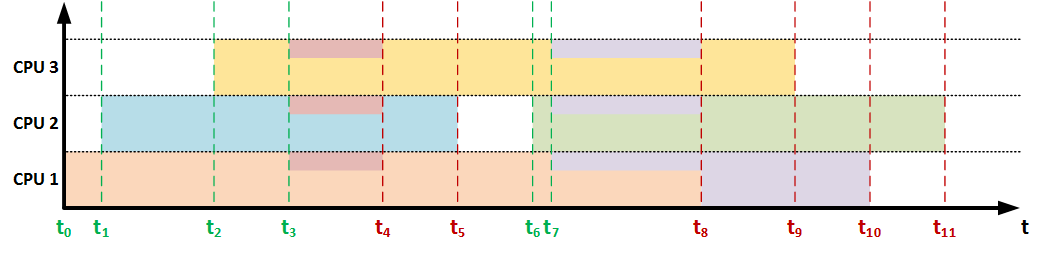
Становится ясно, что при наступлении любого из этих событий необходимо осуществить пересчет выделяемого ресурса для каждой задачи (в случаях с известным распределением ресурса между задачами) либо получить каким-либо образом это значение с помощью встроенных (языковых или операционных) средств, затем пересчитать оставшееся время с учетом выделяемого ресурса. А вот для этого-то нам необходимо знать какой объем работ уже был выполнен процессом. Поэтому предлагается организовать некоторое хранилище (возможно таблицу в СУБД), в котором будет содержаться необходимая информация, например:
| ID задачи | Начало | Конец | Lagrange(N) | Выполнено | Последний запрос | Последняя коррекция | Текущий CPU |
| 2457 | 12:46:11 | … | Lagrange(N) | 0,45324 | … | 12:46:45 | 1,00 |
| 6574 | 12:46:40 | … | Lagrange(N) | 0,08399 | … | 12:46:45 | 1,00 |
| 2623 | 12:44:23 | 12:46:45 | Lagrange(N) | 1,00 | … | 12:46:45 | 0 |
| … | … | … | … | … | … | … | … |
Предполагается реализовывать следующий алгоритм (метакод):
- При поступившем запросе пользователя о состоянии задачи:
- <Выполнено> += (<Момент запроса> — МАКС(<Последний запрос>,<Последняя коррекция>))*<Текущий CPU>/<Lagrange(N)>;
- <Последний запрос> = <Момент запроса>;
- Возврат пользователю <Выполнено> и <Текущий CPU>.
- При поступлении новой задачи:
- Создать новый <ID задачи>;
- Записать время начала выполнения в <Начало>;
- Рассчитать и записать прогноз времени выполнения в «идеальных» условиях в <Lagrange(N)>;
- <Выполнено> = 0;
- <Последний запрос> = 00:00:00;
- Вызвать процедуру коррекции.
- При завершении задачи можно удалить запись вовсе, но в любом случае вызвать процедуру коррекции.
- Процедура коррекции:
- Для всех записей: <Последняя коррекция> = <Текущее время> (имеет смысл хранить это значение где-то отдельно);
- Получить и записать для каждой задачи соответствующий <Текущий CPU>.
Вывод: имея заблаговременный прогноз для «идеальных» условий мы можем практически «на лету» корректировать прогнозируемый процент выполнения «тяжелых» последовательных вычислений при изменении нагрузки на систему и выдавать пользователю эти значения по запросу.
Конкретные реализации могут иметь свои особенности, усложняющие или упрощающие жизнь, однако целью статьи не является разбор деликатных случаев, а лишь предложение вышеизложенного подхода на справедливый суд читателя (в первую очередь на предмет жизнеспособности).
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (8)

gleb_l
29.05.2015 16:29+1Интересно. Я делал похожую штуку в системе, хранящей очередь разнотипных заданий в БД, выбираемых процессом-диспетчером на выполнение по N штук, где N — количество свободных процессов-обработчиков на момент вызова диспетчера.
Так как время выборки заданий было конечно и сравнимо с временем их выполнения, процесс-диспетчер вел статистику а) среднего времени выборки пачки заданий из БД, как функцию от M (размера пачки) и б) среднего времени выполнения заданий как функцию от типа задания и количества работающих процессов-обработчиков.
В итоге, алгоритм диспетчера был построен так, что он при свободных на текущий момент N процессах выбирал M заданий (M >= N), рассчитывая M с учетом времени выборки таким образом, что к моменту, когда выбранные из БД задания будут готовы к выполнению на процессах, какая-то часть процессов статистически завершится, и число свободных процессов будет >= M.
Palich239 Автор
29.05.2015 21:53Да, действительно, здесь налицо специфика, связанная со скоротечностью выполнения заданий.
В моей системе пока предполагаются типовые процессы, но понятно, что завести в БД поле «тип задания» и слегка переписать алгоритм не составляет труда. А вообще понравилась идея завести процессы-обработчики, мне видится это хорошим вариантом, когда речь идет о масштабируемой вычислительной системе. Добавил компьютер в сеть => добавил точку доступа в список.
Правда тут уже некая двухуровневая модель получается, надо будет еще поразмыслить на эту тему. В конце концов дешевле и надежнее расширять сеть горизонтально, а не менять «железо» всякий раз, когда клиенты затолкают друг-друга локтями донельзя)).
Кстати, по какому протоколу взаимодействие осуществлялось?gleb_l
30.05.2015 00:32Архитектура была такая — очередь заданий находилась на единственном сервере БД, к которому могло ходить от 1 до K серверов приложений, кладущих задания в очередь, либо забирающих их оттуда (через обычную сетевую SQL-коннекцию).
На каждом сервере приложения крутился 1 диспетчерский процесс и пул процессов-обработчиков. Диспетчерский процесс был придуман для того, чтобы обработчики сами в БД за заданиями не ходили, т.к. из БД выгодно забирать задания пачками.
В общем случае, некая единица работы могла содержать несколько фаз, каждая из которых представляла собой задание в очереди. В зависимости от типа задания метаданными накладывались правила, например такие, что некоторые типы были хостонезависимыми, а некоторые — требовали, чтобы задание выполнялось на том же хосте, что и хост, добавивший задание в очередь.
Кроме того, в самих метаданных задания в БД была возможность создавать начало (fork) и конец (collect) параллельных цепочек — ее логика поддерживалась внутри самой БД сторед-процедурами, которые клали, выбирали и отмечали как выполненные задания из базы.
Использовалось все это в системе распознавания изображений (конкретно типа еды по ее фотографии) — например, типичная работа содержала такую последовательность — препроцессинг -> выборка контекстов распознавания -> запихивание контекстов в очередь (точка fork) со ссылкой вперед на задание типа collect (оно делало aggregate_context_results) -> debug_out (опционально) -> save.Palich239 Автор
30.05.2015 01:14Читаю и ясно вижу — ну так и просится здесь что-то вроде сервисной шины (скажем mule esb, open esb или что-нибудь эдакое от oracle). Большинство вопросов, которые перекрывала избыточная информация в Вашей БД, как раз и реализовано в сервисных шинах. И, по идее, шина призвана выравнивать нагрузку, распихивать задачи и все такое, чтобы лишний раз не грузить сервер БД… но в Вашем случае, когда речь идет о скоротечности и массовости вычислений, не берусь утверждать, что за удобство и масштабируемость не придется платить производительностью.
А вообще — весьма занятно, не смотря на то, что мы бесконечно отдалились от темы статьи. Спасибо!
Stas911
Не понял, чем ваша задача отличается от классической задачи регрессии? Если нет — то и решать нужно алгоритмами регрессионного анализа Link
Palich239 Автор
Попробую пояснить: пользователя, приславшего исходные данные на решение, не может не интересовать сколько времени ждать результат. Пользователей несколько, а значит вычислительный ресурс делится между их задачами. Задачи приходят в неизвестные заранее моменты времени и с неизвестными размерностями, а последнее, согласно постановке задачи, определяюще влияет на время их выполнения. Иными словами, мы не можем просто запустить задачу пользователя, выдать ему некоторое предполагаемое время выполнения T и успокоиться, т.к. пока идет процесс выполнения его задачи, могут поступать/завершаться другие задачи => система может сильнее нагружается/разгружается, причем как именно — вопрос. Поэтому, имеет смысл уведомлять пользователя при изменении вычислительного ресурса, выделяемого на его задачу, и как это влияет на оставшееся время его ожидания результатов.
В такой постановке, если и возможно применение регрессивного анализа, то не слишком понятно как именно. Во всяком случае, выявление зависимостей поступления задач и их размерностей не выглядит перспективно — человек так непредсказуем... Надеюсь, мне удалось указать ключевые отличия задачи. Спасибо за комментарий!
Stas911
Собственно я говорил про построения функции зависимости времени выполнения одной задачи от размерности N (кстати, как она выглядит, было б интересно посмотреть).
Palich239 Автор
Спасибо, добавил в статью пару графиков получившейся зависимости (соответствует сложности алгоритма решения задач). Про построение полинома Лагранжа можно посмотреть здесь, а ссылка на рабочий алгоритм содержится в тексте статьи.