

Валентин Васильев (Machinio.com)
Что же такое Browser Fingerprint? Или идентификация браузеров. Очень простая формулировка — это присвоение идентификатора браузеру. Формулировка простая, но идея очень сложная и интересная. Для чего она используется? Для чего мы хотим присвоить браузеру идентификатор?
- Мы хотим учитывать наших пользователей. Мы хотим знать, пришел ли пользователь к нам первый раз, пришел он во второй раз или в третий. Если пользователь пришел во второй раз, мы хотим знать, на какие страницы он заходил, что он до этого делал. С анонимными пользователями это невозможно. Если у вас есть система учета записей, пользователь логинится, мы все про него знаем — мы знаем его учетную запись, его персональные данные, мы можем привязать любые действия к этому пользователю. Здесь все просто. В случае с анонимными пользователями все становится гораздо сложнее.
- Второй сценарий — персональная реклама. Это сейчас везде. Мы заходим, и вдруг нам показывают рекламу каких-нибудь пирожков, которые мы хотели купить еще вчера. Как это делается? Это делается через идентификацию пользователей.
- Третий сценарий — внутренняя аналитика. Если вы используете, помимо Google Analytics или Яндекс, собственную самописную систему аналитики, Fingerprint JS и Browser Fingerprint, в целом, может вам помочь в достижении почти полной идентификации анонимных пользователей. Вы сможете увидеть, что пользователь делал на вашем сайте, на какие страницы заходил, какие ссылки он щелкал и т.д. И построить на основе этого целую картину, карту действий пользователя. Все это достигается при помощи этой техники — Browser Fingerprinting.

Почему бы для этой цели не использовать просто http cookie? Ведь это очень просто, и все это умеют делать. Работает это, вы все знаете как.
Пользователь приходит на ваш сайт, мы читаем его cookie, если там есть какой-то идентификатор, значит, он у нас уже был, и мы знаем, кто он такой. Мы выполняем всю нашу аналитику, трекинг и т.д. в привязке к этому пользователю.
Если там идентификатора нет, значит, пользователь пришел к нам впервые. Мы генерируем идентификатор уникальный, GUI, бинарную строку какую-то, записываем это в cookie, и потом, когда пользователь придет в следующий раз, мы этот cookie прочитаем и поймем, что этот пользователь к нам пришел во второй, третий и последующий разы.
У сookie есть один большой недостаток — его можно очистить. Любой, даже технически неподкованный пользователь знает, как очищать cookie. Он нажимает «Настройки», заходит и очищает. Все, пользователь становится опять для вас анонимным, вы не знаете, кто он такой.
Все современные браузеры, даже Internet Explorer, кажется, предлагают режим инкогнито. Это такой режим, когда ничего не сохраняется, и когда пользователь посетил ваш сайт в этом режиме, он не оставляет никаких следов. Следующий раз, когда он зайдет в режиме инкогнито, вы опять же не узнаете, кто он такой и был ли он у вас до этого. Т.е. в режиме инкогнито http cookie работать не будут.
В настоящее время в связи с популярностью таких персонажей как Сноуден и т.д. многие предпочитают разные режимы приватности, анонимности в Интернете, режимы, плагины и что угодно. Все это препятствует трекингу и идентификации в Интернете. Многие пользователи этим пользуются, даже не понимая, зачем. Просто устанавливают, просто потому, что это модно. И они становятся для вас опять же анонимными. Http cookie в этом случае работать не будут.
Как программисты пытались и пытаются решить эту проблему?
Наиболее успешным проектом в сфере сохранения информации в cookie так, чтобы невозможно было ее удалить, на мой взгляд, является проект evercookie, или persistent cookie — неудаляемый cookie, трудно удаляемый cookie. Суть его заключается в том, что evercookie не просто хранит информацию в одном хранилище, таком как http cookie, он использует все доступные хранилища современных браузеров. И хранит вашу информацию, например, идентификатор. Начинает он использовать http cookies, записывает идентификатор туда, затем, если в браузере доступен Flash, он использует local shared objects для записи информации в т.н. Flash cookies.

Flash cookies до недавнего времени не очищались, когда вы очищали cookie. Лишь последние версии Google Chrome умеют очищать Flash cookie, когда вы очищаете обычные cookie. Т.е. до недавнего времени Flash cookies были практически неудаляемыми. Существовала специальная страница на сайте macromedia, куда нужно было зайти, нажать кнопку: «Да, я хочу очистить Flash cookies», и тогда они очищаются, т.е. без этой страницы было очистить невозможно.

Далее, evercookie использует Silverlight Cookies. По-другому они называются Isolated Storage. Это специальное выделенное место на жестком диске компьютера пользователя, куда пишется cookie информация. Найти это место невозможно, если вы не знаете точный путь. Оно прячется где-то в документах, Setting’ах, если на Windows, глубоко в недрах компьютера. И эти данные удалить, при помощи очистки cookie невозможно.

Далее. Evercookie использует такую инновационную технику как PNG Cookies. Суть заключается в том, что браузер отдает картинку, в которой в байты этой картинки закодирована информация, которую вы сохранили, например, идентификатор. Эта картинка отдается с директивой кэширования навсегда, допустим, на следующие 50 лет. Браузер кэширует эту картинку, а затем при последующем посещении пользователем при помощи Canvas API считываются байты из этой картинки, и восстанавливается та информация, которую вы хотели сохранить в cookie. Т.о. даже если пользователь очистил cookie, эта картинка с закодированным cookie в PNG по-прежнему будет находиться в кэше браузера, и Canvas API сможет ее считать при последующем посещении.

Evercookie использует все доступные хранилища браузера — современный HTML 5 стандарт, Session Storage, Local Storage, Indexed DB и другие.

Также используется ETag header — это http заголовок, очень короткий, но в нем можно закодировать какую-то информацию, и если установлен Java, то используется java presistence API.

Evercookie — очень умный плагин, который может сохранять ваши данные практически везде. Для обычного пользователя, который не знает всего этого, удалить эти cookies просто невозможно. Нужно посетить 6-8 мест на жестком диске, проделать ряд манипуляций для того, чтобы только их очистить. Поэтому обычный пользователь, когда посещает сайт, который использует evercookie, наверняка не будет анонимным.
Несмотря на все это, evercookie не работает в инкогнито режиме. Как только вы зашли в инкогнито режим, никакие данные не сохраняются на диске, потому что это основополагающая суть инкогнито режима — вы должны быть анонимными. А еvercookie использует хранение на жестком диске, которое в этом режиме не работает.

FingerprintJS — это маленькая библиотечка, которую я написал, и которая пытается решить эти проблемы. Я расскажу, как она это делает, и что из этого получилось.
Написал я ее в 2012 году. Я тогда работал в «КупиКупон» Ruby разработчиком. И у меня была задача сделать такую систему аналитики, чтобы учитывать не просто залогиненных пользователей, т.е. тех пользователей, которые есть у нас в системе, а также анонимных пользователей. Конкретно на сайте «КупиКупон» было много анонимных пользователей, потому что люди часто приходили извне посмотреть на какие-то купоны, скидки, предложения, у них ни у кого не было учетной записи, и поэтому система трекинга, система отслеживания посещаемых страниц, нажатия на кнопки — все это не работало, потому что пользователи были анонимными.
FingerprintJS, вообще, не использует cookie. Никакая информация не сохраняется на жестком диске компьютера, где установлен браузер. Работает в инкогнито режиме, потому что в принципе не использует хранение на жестком диске. Не имеет зависимостей, работает даже без jQuery, и размер — 1,2 Кб gzipped.

На данный момент используется в таких компаниях как Baidu, это Google в Китае, MasterCard, сайт президента США, AddThis — сайт размещениz виджетов и т.д.
Эта библиотека быстро стала очень популярной. Она используется примерно на 6-7% всех самых посещаемых сайтов в Интернете на данный момент.
Как она работает, расскажу детально. Суть ее в том, что код этой библиотеки опрашивает браузер пользователя на предмет всех специфичных и уникальных настроек и данных для этого браузера и для этой системы, для компьютера. Эти данные объединяются в огромную строку, затем они подаются на вход функции хэширования. Функция хэширования берет эти данные и превращает их в компактные красивые идентификаторы. Как детально это работает, я расскажу.
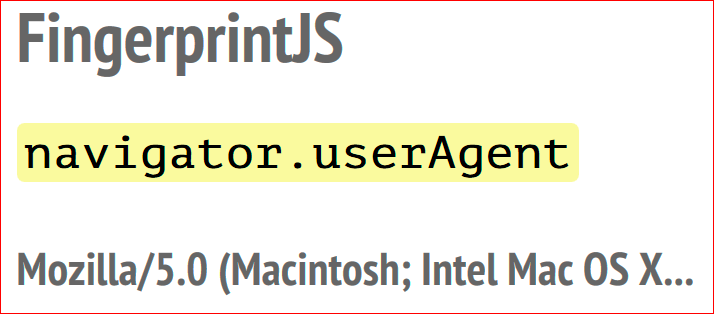
Сначала считывается userAgent navigator. Допустим, тут он обрезан, это присоединяется к итоговой строке отпечатка.

Считывается язык браузера — какой у вас язык — английский, русский, португальский и т.д. Тоже присоединяется к строке отпечатка.
Считывается часовой пояс, это количество минут от UTC:
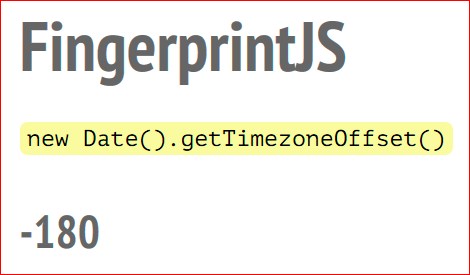
–180.
Это –3, получается Москва.

Далее получается размер экрана, массив, глубина цвета экрана.

Затем происходит получение всех поддерживаемых HTML5 технологий, т.е. у каждого браузера поддержка отличается. FingerprintJS пытается определить, какие поддерживаются, какие — нет, и для каждой технологии результат опроса наличия этой технологии и степень ее поддержки прибавляется к итоговой функции отпечатка.

SessionStorage, LocalStorage, IndexedDB, OpenDatabase и другие всевозможные.
Опрашиваются данные, специфичные для пользователя и для платформы, такие как настройка doNotTrack (очень иронично, что настройка doNotTrack используется как раз для трекинга), cpuClass процессора, platform и другие данные.

Здесь у вас может возникнуть закономерный вопрос — ведь у очень многих пользователей эти данные они одинаковые? Допустим, пользователь живет в Москве, у него будет одинаковый язык, последний Chrome, у него будет все практически одинаково, и все эти строки, которые были получены на данном этапе, будут одинаковые. Как это поможет идентифицировать пользователя?
Есть еще 2 способа, которые добавляют уникальности.
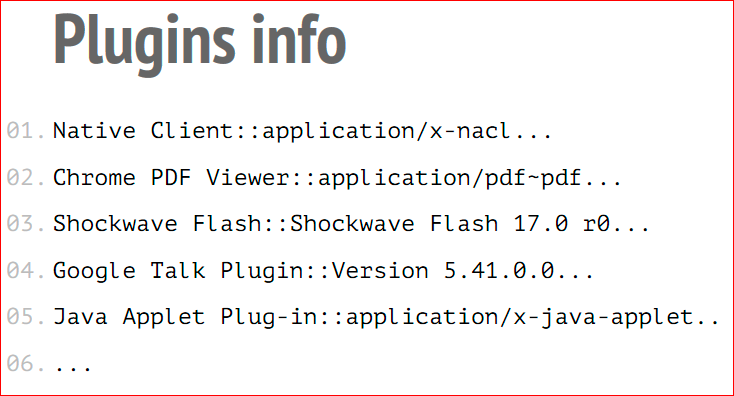
- Первый — это информация о плагинах. Код опрашивает наличие всех установленных плагинов в системе. Для каждого плагина получается его описание и название.А также, что очень важно, список всех мультимедиа типов или main типов, которые поддерживают этот плагин. Вся эта информация объединяется в огромный массив строк, и этот массив тоже конкатенируется и прибавляется к строке отпечатка. Как вы понимаете, на каждом компьютере список плагинов свой, достаточно уникальный, и версии плагинов могут быть свои, и список поддерживаемых main типов тоже будет свой.

- Следующее — к строке отпечатка прибавляется т.н. Сanvas Fingerprint. Это еще одна техника, которая позволяет повысить точность. Суть ее заключается в том, что на скрытом Сanvas элементе рисуется определенный текст с определенными наложенными на него эффектами. И затем полученное изображение сериализуется в байтовый массив и преобразовывается в base64 при помощи вызова canvas.toDataULR().
У вас тут возникает вопрос: как это тоже помогает идентифицировать? Неожиданное для меня было исследование, которое я нашел. Оно говорит о том, что прорисовка шрифтов, в частности, в Canvas API, очень платформозависима. Внешне идентичные одинаковые изображения, нарисованные в разных браузерах, будут преобразованы в разный байтовый массив. Почему? Это зависит от процессора, видеокарты, драйверов видеокарты, системных библиотек, таких как direct X, систем отрисовки шрифтов, теней — все это на каждом компьютере может быть свое, поэтому результирующий байтовый массив будет отличаться практически на каждом компьютере, где будет разная аппаратная и программная начинка. И эта длинная строка, полученная при сериализации Сanvas будет присоединена к итоговому отпечатку, и мы получим огромную строку.
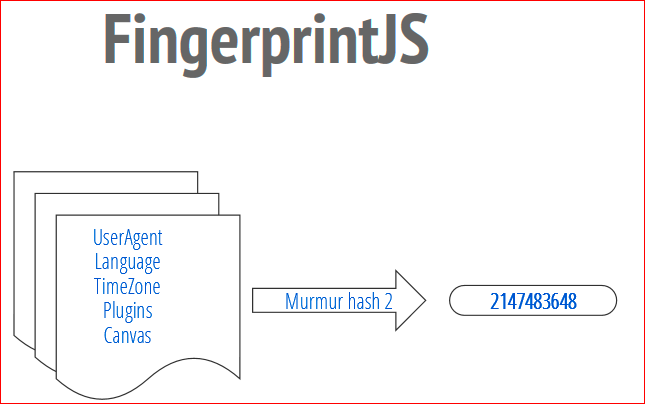
Тут показано, как это работает. Мы получаем все эти данные. Потом мы передаем их в функцию хэширования, в FingerprintJS используется nomo hash2, и на выходе мы получаем 32-х битное число. Это и есть ваш идентификатор. Т.о., когда пользователь заходит на наш сайт, ему присваивается номер. Этот номер вы считываете и используете, как хотите, — вы базируете на нем свою аналитику и т.д.
Тут вопрос: насколько уникально и точно определение? Исследование, за основу которого было взято, было сделано компанией Electronic Frontier Foundation, у них был проект Panopticlick. Оно говорит, что уникальность составляет порядка 94%, но на реальных данных, которые были у меня, уникальность составляла около 90%-91%.
Библиотеку стало использовать много людей и компаний, и с течением времени выявился ряд недостатков. Т.е. она неидеальна, у нее есть недостатки. Самый главный недостаток — то, что точность идентификации только 90%, но есть и другие недостатки.

- UserAgent. У современных браузеров UserAgent меняется очень часто, каждые два месяца выходит новая версия Google Chrome. UserAgent будет меняться, потому что та версия Google Chrome, которая защита в UserAgent будет отличаться. А это означает, что UserAgent будет влиять на итоговый отпечаток. Если выходит новый браузер, итоговый отпечаток изменится, потому что с точки зрения FingerprintJS это будет новый пользователь.
- IPhone, IPad и другие продукты Apple. Дело в том, что они очень униформенные, одинаковые с точки зрения аппаратной реализации. У них у всех одинаковые процессоры. Если мы возьмем, конечно, отдельно взятую модель, допустим IPhone 5S, у всех IPhone 5S будет одинаковый процессор, одинаковый графический ускоритель и одинаковые системные библиотеки, и плагины там будут одинаковые, но на самом деле их там нет. Это означает, что тот байтовый массив, полученный с Сanvas Fingerprint, будет одинаков для всех версий IPhone 5S, а это значит, что точность идентификации для продуктов Apple будет ниже.
- Internet Explorer и Китай. Не подозревал о существовании этой проблемы, но потом я узнал, что используется в Китае очень много старых версий IE, и для того, чтобы получить список плагинов, нужно иметь названия всех плагинов заранее. Потому что для того, чтобы проверить, есть плагин или нет, в IE просто невозможно вызвать, например, navigator.plugins. Это не будет работать. Нужно взять и каждый плагин попытаться инстанциировать как active ex объект. Если он создался, то значит все хорошо. Если выброшена ошибка, значит, что плагины в IE не установлены. Список плагинов для IE у меня был, но он был коротким — порядка десяти плагинов. У меня не было определения тех плагинов, которые популярны в Китае, таких как QQ, baidu и др. Там очень много плагинов, которые используются только там. Эти плагины я не проверял, и список плагинов для Китая конкретно был меньше.
- Другой недостаток первой версии — это отсутствие интеграции с Flash и Silverlight, а интеграция с этими плагинами позволяет улучшить качество Fingerprint.
- И последняя, но достаточно серьезная вещь, которая недавно обрушилась на FingerprintJS, — это то что, начиная с версии 42, Google Chrome просто перестал активировать все те плагины, которые работают через NPAPI. NPAPI — это очень старый API для инстанциирования плагинов, он был разработан еще компанией «Nextkey». Он так и назывется — «Nextkey plugin API». Все плагины, которые работают и опираются на этот протокол, на этот API, перестали загружаться, и поэтому ни Silverlight, ни Java, а эти два плагина наиболее популярны, которые работают через NPAPI, не отображаются в FingerprintJS — они ни коем образом не определяются, и список их main типов тоже не отображается. Это значит, что в Chrome 42 и старше точность FingerprintJS снижена за счет этой проблемы.
Поэтому, проанализировав все это, а сейчас я тоже использую FingerprintJS, я пришел к выводу, что пора разрабатывать новую библиотеку, которая будет практически лишена всех существующих недостатков.
Я ее начал делать совсем недавно, разработка ведется на github.
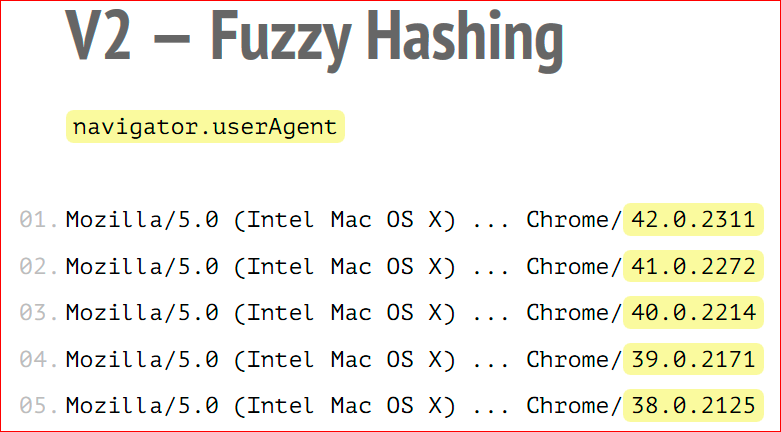
Как она решает существующие проблемы? Самое главное — используется фазихэширование или localsensitivehash, или нечеткое хэширование. Такое хэширование, которое не меняется, даже если в обычном хэшировании, если вы измените хотя бы один байт входящей информации, выходящая строка тоже изменится, причем кардинальным образом. В фазихэшировании этого не происходит, тут есть порог чувствительности, когда определенный процент входящих данных может измениться, что не повлияет на исходящий отпечаток. Допустим, если поменялась в UserAgent только версия браузера, это случается очень часто, допустим, в Chrome, то результирующий отпечаток будет одинаковым, потому что версия составляет 3 или 5 % от общей длины от UserAgent.

Второе — в FingerprintJS 2 используется определение установленных шрифтов, всех шрифтов, которые установлены в системе. Чем это полезно? Если вы поставили программу, допустим, adobe pdf, то вы добавляете в систему шрифты.
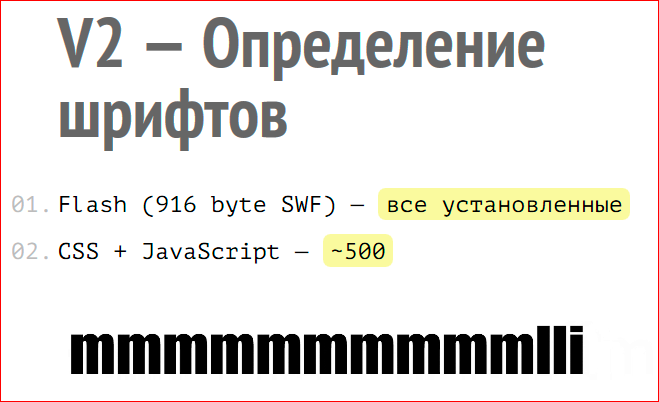
Если вы поставили Microsoft Office, вы добавляете в систему шрифты; если вы поставили какой-нибудь Quick office, который имеет собственные шрифты, вы опять же добавляете в систему шрифты. И поэтому у вас может быть два абсолютно одинаковых компьютера, но на одном установлен Office, а на другом — нет. Это значит, что на первом, где нет Office, будет 320 доступных шрифтов, а, где есть Office — 1700 шрифтов. И значит, что вы сможете получить все шрифты, которые есть на этом компьютере, опять же, для итогового отпечатка. Это будет два разных отпечатка, потому что шрифты разные.
По умолчанию используется Flash, маленький swf файл размером 916 байт. Он получает список всех установленных шрифтов, причем в платформозависимом порядке, т.к. они доступны в системе, так они и будут возвращены. Если Flash не установлен, используется такая техника, она называется site chanel technic. Она впервые была опубликована на сайте lalit.org. Это определение наличия шрифта с помощью javascript only. Как это делается? Для каждого референтного шрифта, который задан по умолчанию в браузере или в системе, измеряется его ширина и высота, и этот массив ширины и высоты сохраняется. Затем к скрытому тексту (текст, кстати, огромный, допустим, 72 пикселя) применяется другой шрифт. Если этот шрифт есть в системе, текст изменит свои габариты правильно, и код, который изменяет высоту и ширину, получит новый массив, с высотой и шириной. Если он отличается от референтного, от того, который был получен при запросе дефолтного шрифта, значит, этот шрифт установлен. Если не отличается, значит, этого шрифта нет.
Очень простая идея, но она работает. На данный момент этот код может достоверно определить около 500 шрифтов без использования Flash. И, соответственно, тот компьютер, где есть Microsoft Office, и тот, где его нет, будут по-разному определены в FingerprintJS 2 за счет этой техники.

Третье отличие — WebGL Fingerprint. Это развитие идеи Сanvas Fingerprint. Суть его заключается в том, что рисуются 3D треугольники (на слайде не очень хорошо видно, но это 3D). На него накладываются эффекты, градиент, разная анизотропная фильтрация и т.д. И затем он преобразуется в байтовый массив. Результирующий байтовый массив, как и в случае с Canvas Fingerprint, будет разный на многих компьютерах. Потом к этому байтовому массиву еще добавляется информация о платформозависимых константах, которые определены в WebGL. Т.е. в WebGL есть набор констант, которые должны быть обязательно в реализации. Это глубина цвета, максимальный размер текстур… Этих констант очень много, их десятки. Код опрашивает все эти константы и, понятное дело, что на android-девайсах эти константы будут отличаться, там глубина цвета может быть другой, чем на Windows или чем на linux’е. Он опрашивает все эти константы, все это опять же складывается в огромный массив, и все это добавляется к сериализованному изображению 3D треугольника, который нарисован при помощи аппаратных эффектов.
Тут тоже такой вопрос: как это помогает идентифцировать? 3D графика очень платформозависима, версия драйверов, версия видеокарты, стандарт OpenGL в системе, версия шейдерного языка, — все это будет влиять на то, как внутри будет нарисовано это изображение. И когда оно будет преобразовано в байтовый массив, оно будет разное на многих компьютерах.
Почему WebGl Fingerprint важен? Потому что IOS 8.1 поддерживает WebGL, а это помогает идентифицировать IOS девайсы, о проблеме идентификации которых я упоминал. Поэтому WebGL повышает точность Fingerprint.

Что еще предстоит реализовать?
Как я говорил, библиотека находится в разработке и не все вещи, которые я бы хотел в ней сделать, сделаны. Вокруг нее уже есть небольшое сообщество разработчиков. Я, кстати, приглашаю всех желающих участвовать в разработке — она очень интересная, мы очень неформальны, каждый предлагает идеи, там достаточно интересно.
Что предстоит еще реализовать? WebRTC Fingerprinting.
WebRTC — это стандарт peer-to-peer коммуникаций через аудиопотоки, или это стандарт аудиокоммуникаций в современных браузерах. Он позволяет делать аудиозвонки и т.д., он поддерживается в FireFox и будет скоро поддерживаться в других браузерах.
Реализация WebRTC стандарта тоже платформозависима, она будет зависеть от той видеокарты, которая установлена в системе, от драйверов на звук и т.д. Поэтому, измеряя разные уровни латентности, разные уровни поддержки WebRTC и констант, которые зашиты в этом формате, можно получить разные итоговые отпечатки для разных компьютеров.
Будет использоваться больше плагинов для IE. Будут использованы те плагины, которые популярны в разных странах — Китае, Индии и т.д., т.е. растущие информационные рынки. В первой версии недостаточно внимания было уделено этой проблеме, а во второй версии это будет решено.
Больше информации будет собираться об ОС. Как мы это будем делать? Будет использоваться интеграция с Flash и Silverlight. Flash позволяет получать информацию о системе, такую как версия ядра, патч левел ядра. Silverlight, если на Windows, позволяет получить версию Windows, bild, номер Windows, все это доступно через Silverlight.
Пару слов о Silverlight, почему интеграция с sliverlight тоже достаточно важна? Может быть, в России Silverlight плагин не очень популярен, но в США, например, есть сервис стримингового видео Netflix, который транслирует видео, и я знаю точно, что они используют Silverlight. Ввиду того, что он поддерживает DRM (это система ограничения цифровых прав на контент), т.к. Netflix часто показывают разные свежие голливудские фильмы, они используют Silverlight для того, чтобы это видео не расходилось по Интернету. Поэтому в США у многих десктопных пользователей Интернета установлен Silverlight плагин, который, кстати, доступен и на Mac’е тоже, помимо Windows.
Будет реализовано определение наличия нескольких мониторов. Если мы запросим размеры через javascript, то получим просто два числа — это ширина и высота экрана. Если мы сделаем то же самое через Flash API, Actionscript API, мы получим массив массивов. Это значит, что если установлено несколько мониторов, где каждый подмассив — это будет размер экрана каждого монитора. Если разработчик сидит за пятью мониторами, он получит массив массивов из пяти элементов, т. о., мы узнаем, что человек сидит за пятью мониторами, а не за основным монитором, который вернул бы javascript.
Все эти данные в совокупности позволяют на данный момент получить точность определения порядка 94-95%. Но, как вы понимаете, это недостаточная точность идентификации. Тут встает вопрос: каким образом это можно улучшить, и можно ли это улучшить? Я считаю, что можно. Цель этого проекта — достичь 100% идентификации так, чтобы можно было опираться на Fingerprint в 100% случаях и гарантированно сказать: «Да, этот пользователь к нам приходил; да, я все о нем знаю, несмотря на то, что он использует инкогнито mode, tor сеть…». Не важно, все это будет определено.

Контакты
» github
» Machinio.com
Этот доклад — расшифровка одного из лучших выступлений на конференции фронтенд-разработчиков FrontendConf.
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая FrontendConf.
Комментарии (157)

Saffron
06.02.2017 23:27+13> Многие пользователи этим пользуются, даже не понимая, зачем
Один раз увидишь на один и тот же товар разные ценники в разных браузерах — сразу поймёшь зачем.

Xaber
06.02.2017 23:39+42Это всё спамеров и чёрных сеошников напоминает. Человек использует режим инкогнито, использует DoNotTrack (на сколько я понимаю есть какой-то свод правил которые хорошо бы соблюдать), но вам плевать, вам нужна слежка, нужен контроль, вы готовы искать лазейки/способы.
Надеюсь найдутся люди которые напишут, как с такими бешеными скриптами бороться.
Stalker_RED
07.02.2017 01:09Так пишут потихоньку. Whonix, tor-browser и подобные технологии.
идея в том, чтобы выдавать либо рандомные «отпечатки» каждый раз либо одинаковые для большого кол-ва людей.
Saffron
07.02.2017 01:56+1Что делать — понятно. Отдельный браузер или мощный плагин для существующих (как вивальди и опера), который будет сфокусирован на противодействии слежке.
Если достаточно чтения сайтов, то лучшее их вообще открывать в phantomjs, парсить и выдавать пользователю готовый результат.
Если требуется писать — то сложнее, надо запускать браузер в виртуалке и ходить через него как через прокси, управляя через selenium.
Если у тебя есть любимый сайт, на который ты ходишь каждый день, то лучше сделать для него собственный, открытый клиент. Пусть он будет плохеньким и некрасивым, зато без закладок. Если разработчик не предоставляет API или ограничивает его, или требует регистрации и одобрения клиента, то просто берёшь веб версию и работаешь с ней через selenium.
Можно ещё пойти по пути антивирусов — хранить базу сигнатур вредоносных джава скриптов и блокировать/подменять эти скрипты при загрузке.
Кто это будет делать и на какие деньги — большой вопрос. Слежку за пользователями окупают сами пользователи, которых дурят и заставляют платить больше. А на разницу нанимают программистов, которые пишут шпионский софт. Кто будет платить программистам за то, что они будут защищать пользователей от обмана?
Можно писать на энтузиазме, свободный софт существует и работает, и это доказано. Но этот путь хорош, когда нет спешки — ты постепенно шаг за шагом реализуешь все требуемые фичи. Но у этого пути возникают трудности, когда время давит и нужно соревноваться. Слежка за пользователями и защита от неё — это соревнование снаряда и брони. При этом на стороне слежки работают разработчики коммерческих браузеров, они постоянно вводят новые бесполезные фичи, которые увеличивают поверхность атаки.
Уж насколько велика потребность людей в антивирусах, большая база пользователей, а свободных опенсорсных антивирусов считай что нет, а те, что есть, свежие вирусы распознают очень плохо.
Можно попробовать толкать эту систему мобильным пользователям. Мобильный интернет — всегда дорогой, лимитированный и иногда ещё и медленный. Поэтому сервер может загружать и парсить сайты, удалять весь мусор и пересылать в сжатом виде мобильному клиенту. Желающие ставят себе на десктоп и роутят через домашний интернет, для тех кто хочет «вжух-и-работает» можно продавать аренду серверной части
kost
07.02.2017 03:10+2I am careful in how I use the Internet.
I generally do not connect to web sites from my own machine, aside from a few sites I have some special relationship with. I usually fetch web pages from other sites by sending mail to a program (see git://git.gnu.org/womb/hacks.git) that fetches them, much like wget, and then mails them back to me. Then I look at them using a web browser, unless it is easy to see the text in the HTML page directly. I usually try lynx first, then a graphical browser if the page needs it (using konqueror, which won't fetch from other sites in such a situation).
https://stallman.org/stallman-computing.html
DAlex
07.02.2017 07:19На сколько я понимаю, Tor browser (Tor project) предоставляет защиту от снятия отпечатка
immaculate
07.02.2017 08:01+14И еще теперь понятно, почему современный веб такой тормозной. С одной стороны, засилье всяких node.js/react и прочих модных технологий, с другой стороны — при каждой загрузке страницы может выполняться такой вот фингерпринтинг, который загружает все возможные шрифты, рендерит и сериализует картинки, загружает все плагины.
А мы все голову ломаем: почему покупаешь новый компьютер, с более быстрым процессором, большим объемом RAM, SSD, а браузер как тормозил, так и тормозит…

scarab
07.02.2017 18:12Это как раз в том числе защита от спамеров и чёрных сеошников. Я в своё время немало времени потратил, реализуя аналогичную технологию на одном крупном чате с целью защиты от злостных спамеров и матершинников. Урода банишь, он регистрирует новый аккаунт и продолжает заниматься тем же самым. Но если раньше даже тривиальный бан по IP-адресу обойти было относительно сложно — надо было искать прокси-сервера, перебирать — то сейчас, благодаря борцам за приватность и неотслеживаемость, любой дебил, поставивший себе фригейт, может принести немало вреда.
И да, мне нафиг не нужно следить за пользователем. Но я хочу понимать, что юзер vasya и юзер petya на моём сайте — это одно и то же лицо.
Tor в этом плане более благороден. Да, он крайне усложняет отслеживание пользователя — но он не стесняется сказать, что это Tor, список выходных узлов опубликован и обновляется. Поэтому доступ через Tor можно вообще блокировать.
DnV
08.02.2017 08:33В описанных вами сценариях скрипт никак не поможет, он же выполняется на стороне клиента и злостные товарищи легко и весело ответят каждый раз новым рандомным хешем. На самом деле, скрипт именно про попытку пасти добропорядочных пользователей, включая явно запрещающих это делать.
Arta
08.02.2017 11:47Как раз для описанного случая скрипт подходит прекрасно — в сочетании с другими мерами он повышает стоимость таких атак, прекрасно отсеивает мамкиных спамеров и упрощает жизнь модераторам сообщества.

funca
06.02.2017 23:58-1Интересно, а AddBlock и компанию нельзя использовать для той же цели, ведь правила фильтрации у пользователей могут отличаться?

dom1n1k
06.02.2017 23:58+7Даже если на конкретный момент юзеру пофиг, оказался ли он в статистике какого-то магазина или нет, бороться всё равно нужно. Хотя бы даже по причине того, что технологии эти развиваются совершенно безумными темпами и непонятно, к чему это приведет через 5-10 лет. И вполне может оказаться, что то, что сегодня было пофиг, завтра всплывет в самом неожиданном месте и неожиданным образом. А обратно уже не вернешь.

ivan386
07.02.2017 00:02+2Хорошо у меня Javascript по умолчанию отключен.

Antelle
07.02.2017 00:25+2Вас можно трекнуть по HSTS, сначала показав 100 картинок с разных доменов, а потом проверив, отправит ли браузер запрос.

andreymal
07.02.2017 01:01+1Отключен он мало у кого, значит по этому признаку тоже можно идентифицировать :D
ivan386
07.02.2017 01:15Ну допустим можно узнать примерное количество людей с отключёнными скриптами по умолчанию по количеству пользователей дополнения NoScript: 2 172 292
В хроме можно отключить без дополнений и включать индивидуально для каждого сайта.
В мобильном хроме также можно отключить но добавлять сайты в список исключений очень не удобно.
Есть сайты которые вполне работают без скриптов а если их включить то начинается треш из потоков рекламы и кучи банеров.
dom1n1k
07.02.2017 01:22Имеется в виду, что можно-то можно, но мало кто это делает.
Если взять те 2 млн человек и размазать по всему земному шару, да потом сопоставить с вашим айпишничком и провайдером (т.е. улица, дом) — то там уже спрятаться за малой выборкой будет сложнее.

Acuna
07.02.2017 03:52Хочу спросить, пользуясь случаем, а как Вы пользуетесь сайтами, которые используют JS в виде jQuery, AJAX, да и те же соц. сети (предполагаю ответ «не пользуюсь», однако только на них свет клином не сошелся)? Мне кажется это вообще как интернет нулевых. А как же вебдваноль?)
ivan386
07.02.2017 10:53+2Там где мне необходим доступ к поному функционалу я добавляю в исключения. А если я попал из поиска или по ссылке на сайт который без скриптов показывает пустое окно я его просто закрываю.
Сам стараюсь делать сайты которые работают и с отключенными скриптами.
Acuna
10.02.2017 00:37-1А, ясно, благодарю. Но как-то не знаю, неужели стоит себя лишать всех прелестей современного интернета и постоянно натыкаться на неработающий функционал, если придерживаться банальных и очевидных правил поведения, таких как не кликать по ссылкам в письмах, полученных от неизвестных людей (да и от известных тоже, особенно если оно содержит слишком уж вызывающие призывы пройти по ссылке), пользоваться только Ебеями/Амазонами для покупок в сети, не переходить по сайтам, выданных по запросу «мокрые киски смотреть без регистрации и смс» и так далее? Да и вообще если вести себя честно, то чего и бояться? Если, конечно, только есть что скрывать… Или Вы типа просто как-бы не согласны с тем, что Ваши данные могут быть доступны кому-то еще? Однако последнее — это как не пользоваться услугами почты, только потому, что для получения отправлений там необходим паспорт. Но это уже она, родименькая, тут уже к доктору надо…
ivan386
10.02.2017 01:41+1Когда я ищу какую либо информацию в интернете мне приходится посещать много различных сайтов разного уровня качества. Какой нибудь из этих сайтов мог запросто повесить браузер скриптами. Также со скриптами появлялась реклама со всех щелей которая перекрывала контент и браузер жрал кучу памяти и притормаживал.
Отслеживание мне также не нравиться. Причём я знаю уровень отслеживания пользователя так как сам пользуюсь метрикой и вижу каждое движение мышки и каждую напечатанную буковку посетителем в вебвизоре. Может скоро они пойдут дальше и будут записывать с вебки и микрофона реакцию посетителя на контент.
Меня напрягает рекламма которая предлагает товары и услуги в соответствии с недавней моей активностью.
Acuna
10.02.2017 23:15Хм… Сам посещаю помойки еще те, плюс сам занимаюсь разработкой (тоже программер), от рекламы стоит банальный адблок, браузер летает, хотя комп по характеристикам только чтобы блокнот открыть. Вебвизором и сам пользуюсь, но опять же, смотря что вводить. Если я захожу на сайт в поисках детских товаров — определенно запросы на соответствующую тематику не могут заинтересовать кого-бы то ни было в принципе, ибо ищется все в рамках сайта, на котором я, собссно, и нахожусь. Другой вопрос, когда они касаются фото из каталогов детского нижнего белья — тут да…
Ну а благодаря такого рода рекламе я иногда нахожу весьма интересные товары. Но тема рекламы холиварна по своей сути, соглашусь, да, так что ладно…
P. S. Ни в коем случае не пытаюсь вывести Вас на чистую воду, это дело каждого, это больше даже мои мысли в слух, не более. По мне все-равно, это как в примере с почтой…
gearbox
10.02.2017 22:04>Да и вообще если вести себя честно, то чего и бояться?
С этой фразой пойдете на толпишку гопников в темной подворотне?
Я к тому что сайты имеют обыкновение быть взломанными, любого уровня и любой сложности, интернет не песочница с розовыми понями, какающими бабочками.Acuna
10.02.2017 23:07Вы… Вы это мне говорите?) Сижу спокойно лет 15, имея только антивирусник (и то народ поговаривает, что в нем смысла особого нет). JS включен, деньги на карте до сих пор на месте, значит перехватчиков нет. Да и антивирусник (см. по рекурсии).
Говорю о честности в виде хранения/распространения определенного контента. Напоровшись на гопников в тюрьму не сядешь, чего нельзя сказать про интернеты.herr_kaizer
12.02.2017 21:19+1Ошибка выжившего.
Acuna
12.02.2017 23:26Я понимаю, просто хочется сохранять оптимизм даже в этих ситуациях. Особенно когда эти ситуации складываются так, как нужно.
Iv38
07.02.2017 11:59Увы, это не поможет. Браузерные отпечатки часто используют именно крупные важные сайты (в статье даже есть несколько примеров), которые как раз могут диктовать свою волю пользователям в некоторой степени. Скажем, чисто гипотетически, заходите вы на Яндекс с ноускриптом, а поисковик без скриптов отказывается работать. Вы можете включить скрипты, но вы подозреваете, что тогда Яндекс будет вас отслеживать. И вы вместо этого идете к конкуренту — в Гугл. А там точно такая же ситуация. Еще раз повторюсь, эти компании я выбрал просто для примера и ни в чем конкретно их не обвиняю. Это так же могут быть крупные магазины или другие важные сервисы.
dvor
07.02.2017 13:08+2После этого вы идете в DuckDuckGo и радуетесь жизни. Я понимаю, что компании были выбраны просто для примера, я же лишний раз упомянул хороший сервис.
dom1n1k
07.02.2017 17:18Если бы он ещё что-то искал, цены ему не было бы :)
selivanov_pavel
07.02.2017 17:41+1Я заменил дефолтный поиск в браузере на DuckDuckGo, в принципе в 95% случаев его хватает, очень редко когда он не находит нужного и приходится дёргать гугл.
dom1n1k
07.02.2017 17:53Не верю. Пользовался им эксперимента ради довольно долгое время — в ~2/3 случаев выдача неудовлетворительная, даже когда скармливаешь ему почти точные цитаты.
selivanov_pavel
07.02.2017 17:56Возможно, зависит от того как искать. Я обычно ищу английский текст, и добавляю уточняющие слова. В таком духе: «rsyslog v8 doc filters».
Saffron
07.02.2017 13:12+1> А там точно такая же ситуация
вот за что люблю гугл-поиск, так это за то, что он работает без джаваскрипта. А если таких поисковиков не останется — буду пилить скрипт-костыль на phantomjs
turone
07.02.2017 00:06-2Можно ведь повысить точность, если вначале использовать просто куки и другие методы — проверять, если не сработали, то запускать FingerprintJS. В 95% случаев пользователи не в инкогнито и куки не чистят. Итого имеем точность 90% от 5% FingerprintJS +95% = 99,5%.
ivan386
07.02.2017 00:12Скорей всего их используют вместе. И если куки сотрут по отпечатку их установят заново.
ivlis
07.02.2017 00:20+7Теперь самый главный вопрос, как это всё заблочить нафиг?
Надо, видимо, какой-то плагин, который на всё machine specific будет выдавать каждый раз рандомный мусор.Antelle
07.02.2017 00:24http://www.chromium.org/Home/chromium-security/client-identification-mechanisms
TL;DR: incognito не спасёт, плагины и отключение js тоже. Если надо анонимность — браузер на виртуалке с чистой операцинокой + VPN, после сеанса серфинга удалить.ivlis
07.02.2017 00:27А тут много не надо. Достаточно попадать в один параметр, чтобы портить id. Скажем в режиме инкогнито я выдерну один монитор или разрешение сменю и всё.
Antelle
07.02.2017 00:27Вот, например, взгляните: http://www.radicalresearch.co.uk/lab/hstssupercookies
ivlis
07.02.2017 00:30Свежий профиль хрома спасает вроде бы.
Antelle
07.02.2017 00:33Оно в профиле и хранится, кажется, да. В целом я с вами согласен, хочется плагин (а лучше более качественную поддержку incognito в браузерах), который будет знать о таких штуках и подставлять рандомный мусор, придумать бы только, как это сделать.
ivlis
07.02.2017 00:42Надо бы даже не мусор, а что-то очень обычное, типа как у всех с некоторым распределением. Одноклассники, почта на мейлру, яндекс-бар, вот это всё :)

totalcount
07.02.2017 00:33Вот такая штука HSTS Super Cookies портит влёт.
gearbox
07.02.2017 11:33Вы уверены (в смысле сами проверяли)? Я в код расширения не лез, но вот здесь пишут как чистить историю hsts, а судя по этому топику — прямого доступа к chrome://net-internals/ chrome-extensions не имеют.
Это не говоря уже о том что в сафари так вообще надо ручками файлик удалять.
Также есть различия у разных браузеров по передаче hsts кук в приватный режим — здесь народ отмечает разницу между оперой, фоксом и вивальди. Старый топик, с тех пор наверно поменялось многое, надо проверять.

DjPhoeniX
07.02.2017 01:09+5Это натуральная гонка вооружений. Между маркетологами, которые готовы удавиться ради сотой доли процента в каком-нибудь ARPDAU, и пользователями, которых заколебало, что нельзя уже и шагу ступить, чтобы тебя не «посчитали». Надеюсь, победят последние. Ибо вы зае…
// сам как-то внедрял, по требованию руководства, подобную систему в одно из приложений. Простите. Не хотел. Кстати, увеличить показатели не помогло, да.
dom1n1k
07.02.2017 01:19Рандомный мусор, наверное, нехорошо, потому что он он будет выделяться в общей статистике.
Нужно либо просто пустоту (нишмагла определить), либо рандомный отклик из пула наиболее популярных.
Некоторое время назад тут кто-то рекламировал свое расширение для подмены UA. Довольно быстро выяснилось, что левый UA во-первых выделяется, а во-вторых некоторые сайты ломаются (например, Google Docs). Нужно брать 10-20 самых популярных версий браузеров (имеется в виду полные версии вплоть до билда) и швырять что-то из них. Аналогично с разрешениями экранов и прочим. Канвас лучше всего, вероятно, всё-таки пустота.
selivanov_pavel
07.02.2017 00:58+131. Это ужасно, потому что нарушает приватность пользователей.
Не стоит думать, что приватность нужна только преступникам или потребителям детского порно. Пользователь, вводящий в поисковой системе запрос «рак крови лучшие клиники отзывы», совершенно не ожидает, что эта информация попадёт к куче посторонних лиц, включая например его работодателя. Пользователь нетрадиционной сексуальной ориентации, живущий в нетерпимом к таким людям обществе, рискует своим благополучием и здоровьем, просто общаясь на тематических сайтах. Пользователь, покупающий платную мед. страховку, не должен обнаружить, что для него лично она стоит в 3 раза дороже, потому что у страховщика информация о его здоровье полнее, чем у врача в поликлинике. Пользователь, придерживающийся оппозиционных к текущей системе власти взглядов, не должен стать мишенью противодействия гос. машины. И так далее. Это даёт потенциально огромную власть над человеком организациям, которым этот человек никакой власти передавать не соглашался.
2. Это прекрасно, потому что разработка ведётся открыто, и можно требовать у производителей браузеров и ОС внедрять меры противодействия.
3. Если в комментариях ещё не упомянули Tails и Whonix, то буду первым. Сборки Linux для запуска в виртуалке и анонимной работы. Умеют противодействовать многим из перечисленных техник.
andreymal
07.02.2017 01:02+5А потом мы удивляемся, почему простые на вид сайты дичайше тормозят.
Stalker_RED
07.02.2017 01:13Можно не просто удивляться, а посмотреть в профайлере чем именно нагружает конкретный сайт. Собирает ли он данные, майнит биткоины или просто какой-то рукожоп прикрутил очень красивую анимацию.
Благо профайлер есть в большинстве современных браузеров.
Ну и в черный список WebOfTrust такие сайты.andreymal
07.02.2017 01:14+5Ну и в черный список WebOfTrust такие сайты.
В чёрный список надо и сам WebOfTrust )
selivanov_pavel
07.02.2017 01:16+4Это вот это Web of Trust — сервис Web of Trust продавал собранные данные о своих пользователях сторонним лицам?
Sayonji
07.02.2017 04:47-1Почему WebGl Fingerprint важен? Потому что IOS 8.1 поддерживает WebGL, а это помогает идентифицировать IOS девайсы, о проблеме идентификации которых я упоминал.
Вот это не понял. Если у пользователей разные айфоны, то их совсем легко различить по разрешению экрана и другим простым признакам. Перед этим в статье упомяналась сложность именно идентификации двоих людей на двух одинаковых айфонах. Как детальная информация о рендеринге поможет тут, если у телефонов 100% идентичная начинка и софт?DnV
07.02.2017 07:39+1Да никак, в приватном режиме так даже между сессиями не различить пользователей одной модели айфона. А с тором тем более влажным мечтам автора не суждено сбыться, так как там намерено унифицируются и подчищаются все отслеживаемые параметры.
Другой вопрос, почему вдруг недостаточно 90%? Кажется, этого наоборот больше чем достаточно для маркетинговых целей, и даже можно было бы быть человеком и пожертвовать ещё 10% на уважение DoNotTrack. А пока автору «иронично» — и ему нет уважения.
rhangelxs
07.02.2017 05:49А веса для каждого признака используются? Насколько я понимаю, более стабильным и в то же время дифференцирующим признакам можно добавить больший вес…

cl0ne
07.02.2017 07:19+13D графика очень платформозависима, версия драйверов, версия видеокарты, стандарт OpenGL в системе, версия шейдерного языка, — все это будет влиять на то, как внутри будет нарисовано это изображение.
Если вы поставили Microsoft Office, вы добавляете в систему шрифты; если вы поставили какой-нибудь Quick office, который имеет собственные шрифты, вы опять же добавляете в систему шрифты. И поэтому у вас может быть два абсолютно одинаковых компьютера, но на одном установлен Office, а на другом — нет. Это значит, что на первом, где нет Office, будет 320 доступных шрифтов, а, где есть Office — 1700 шрифтов. И значит, что вы сможете получить все шрифты, которые есть на этом компьютере, опять же, для итогового отпечатка. Это будет два разных отпечатка, потому что шрифты разные.
Обновили драйвера, поменяли видеокарту, добавили/удалили шрифты — фингерпринт новый?
ainu
07.02.2017 09:55Да, но изменён чуть-чуть. В статье про это написано, называется фазихэширование. Изменение небольшого фрагмента немного меняет хеш, но он похож на старый.

qw1
07.02.2017 21:18+1Никаких чуть-чуть. В отпечатке canvas пол-пиксела влево-вправо или цвет чуть зеленее — это другая система, на это и расчёт, что чуть-чуть другое = другая машина.
А фаззи-хеши — это дальние планы автора. В разрабатываемой либе v2 их нет (специально скачал проект и прочитал весь код, благо там немного).
MaxKorz
07.02.2017 07:19Комментаторы смешные. Этот плагин выложен на гитхабе еще в декабре 2012 года. И на комментарии «Это ужасно, потому что нарушает приватность пользователей.» без смеха не получается смотреть. 4 года плагин лежал, все его использовали, он никому не мешал, а сейчас решили обновить версию, про новую версию выложили статью, и все вдруг все полезли искать методы защиты. То есть пока об скрипте-шпионе не напишут статью, никто не пошевелится от него защищаться. И не важно, сколько он работал до этого. А сколько же тогда плагинов, про котрорые никто не пишет? Даже с учетом того, что у них исходный код открыт. А сколько с закрытым исходным кодом?
Iv38
07.02.2017 11:47+1Так-то Илья Кантор написал статью "Способы идентификации в интернете" еще в 2010. Не то чтобы это что-то новое. Но раз уж есть свежая статья, почему бы не обсудить проблему в очередной раз, тем более, что методики меняются.
SmallSharky
07.02.2017 07:19+1Можно еще сделать плагин, который впихивает в страницу скрипт, позволяющий рандомизировать показания целевого скрипта. Но это лишь как заплатка годится, имхо.

olegbunin
07.02.2017 07:21+6Коллеги, хочу напомнить, что мы — профессионалы в первую очередь. Поэтому мы с вами должны изучать и знать разные технологии, даже те, которые не используются на благо общества.
Большинство приёмов, которые сейчас используются в разработке высоконагруженных систем, впервые были опробованы в разработке порносайтов. И что теперь? Балансировку не изучать?
То, что технология используется для нарушения приватности, не означает, что мы, как профессионалы, не должны знать о том, как она устроена.em92
07.02.2017 09:59>
То, что технология используется для нарушения приватности, не означает, что мы, как профессионалы, не должны знать о том, как она устроена.
Спасибо за то, что дали знать про эту технологию. Будем изучать, как ей противодействовать.
asegrenev
07.02.2017 11:53Более того, некоторым приходится это использовать против недобросовестных посетителей. Ограниченный по времени полный функционал (для полноценного тестирования) без подобных инструментов трекинга просто превращается в халяву для особенно "экономных".
immaculate
09.02.2017 10:34Стоит ли так заморачиваться? Особо экономные все равно не заплатят за продукт.
mortimoro
09.02.2017 12:08Во-первых, если твой продукт будет очень нужен, то купят, пусть даже не за свои деньги. Во-вторых, они раструбят на всех форумах о твоем продукте: «Помогите взломать суперпуперпрограмму Васи Пупкина», «Дайте кряк к суперпуперпрограмме Васи Пупкина» и т.д. — это бесплатная реклама. В-третьих, если у тебя не будут воровать, ты сможешь снизить цену до приемлемого уровня и даже самые «экономные» могут решить, что это небольшие деньги за такую классную прогу.
habradante
09.02.2017 14:09+1В-третьих, если у тебя не будут воровать, ты сможешь снизить цену до приемлемого уровня
Это неверно, т.к. в цену программного продукта не закладывается стоимость спираченных версий.
и даже самые «экономные» могут решить, что это небольшие деньги за такую классную прогу.
Тоже неверно, т.к. между платой, пусть даже и в 1коп, и «халявой» всегда победит халява.
Единственный вариант — сделать доступ к халяве настолько сложным, что труд по доставанию халявы станет соразмерен цене покупки. Т.е. если вы заблокируете сайт с халявой в поисковой выдаче, то большинство неопытных пользователей не станут дальше копать, т.к. для них труд по доставанию пиратки станет слишком сложным. Но останутся профи, для которых найти ту же халяву в Tor или еще где-нибудь, без прямой ссылки из поисковика, дело несложное. Такие все равно не купят.mortimoro
10.02.2017 15:31В цену продукта закладываются затраты на его производство и поддержку. Когда затраты окупаются, производитель имеет возможность снизить цену и увеличить тем самым круг пользователей и свою прибыль. Но если продукт просто крадут все кому не лень, то затраты не окупятся никогда.
Да и то, на сиюминутную наживу обычно рассчитывают только разработчики-одиночки, не сильно разбирающиеся в бизнесе. Серьезные производители просчитывают все риски и гарантия защищенности продукта дает им возможность захватить рынок за счет низкой цены — им важнее не мгновенную прибыль поиметь от продажи продукта, а захватить сегмент рынка и постепенно его раскручивать за счет ассортимента предоставляемых услуг.
В моей предыдущей компании мы вообще многие сервисы бесплатно предоставляли, несмотря на большие затраты на их производство, и тем самым выбили с рынка слабых конкурентов. Часть их клиентов досталась нам и мы заработали на них больше, чем могли бы заработать на этих сервисах, давая к ним доступ платно. И так как мы давали сервисы бесплатно, воровать у нас ничего не нужно было.habradante
10.02.2017 15:42+1Сервисы и коробочные продукты, которые можно «скачать» и кряки к которым ищут — это сильно разные вещи.
mortimoro
13.02.2017 18:58+1Мы сделали сервисами то, что конкуренты продавали в коробках, и тем самым обеспечили доступ клиентам из любой точки земного шара, где есть инет. У нас полностью была исключена возможность того, что клиент попытается нас обмануть, потому мы не несли непредвиденных убытков. Если бы у нас воровали, нам бы пришлось компенсировать затраты за счет клиентов, чтобы не уйти в минус. Потому зависимость между ценой продукта и воровством очень даже имеется.
Если бы разработчик, выпуская продукт, мог точно рассчитывать, что продукт честно купит миллион человек, он бы мог поставить цену 1$ и заработать лимон зелени, что весьма приятно. Но из-за того, что продукт купит 10 человек, которые его крякнут и раздадут бесплатно всем остальным, разработчик вынужден просить за него 100$, чтобы поиметь хоть какой-то интерес. А среднестатистический хомячок такую сумму платить не готов, потому и ищет кряк.wlbm_onizuka
14.02.2017 08:59такое может только большой жирный бизнес, который может инвестировать в будущее. а маленькой компании едва вставшей на ноги, большой наплыв халявщиков совсем не нужен
mortimoro
14.02.2017 11:58Маленькой компании наплыв халявщиков нужен для рекламы и раскрутки, иначе она будет оставаться маленькой еще очень долго или вообще загнется под натиском конкурирующего большого жирного бизнеса.
К примеру, бабушка вяжет дома носки и потом продает их на рынке — это маленький бизнес, рассчитанный только на входящего клиента (кто мимо проходил и увидел нужный ему товар). А вот если бабушка будет вязать носки прямо на рынке, параллельно давая мастер-классы и бесплатные консультации по вязанию и выбору нитей, это будет уже пиаркомпания, о которой очевидцы будут рассказывать своим знакомым. В данном случае, бабушка не несет дополнительных финансовых затрат на халявщиков, но недополучает прибыль из-за того, что тратит свой временной ресурс на бесплатные сервисы. Зато она получила бесплатную рекламу и заткнула за пояс не только прямых конкурентов, но и тех, кто проводит мастер-классы по вязанию за деньги. Такая инвестиция в будущее окупит себя очень быстро, потому что когда спрос превысит предложение, бабушка посадит на конвеер других бабушек, чтобы вязать больше товара, и ее доход стремительно вырастет.habradante
14.02.2017 13:58Это все красиво в теории, но не на практике. Халявщики привлекают только таких же халявщиков. А чтобы зарабатывать, продавец должен формировать ценность продукта для покупателя. Ценность же у халявы близка к нулю. И пиарить и советовать будут только тот продукт, который принес пользу для покупателя и для которого он ценен. Так что бизнесу нужны не халявщики, а клиенты для которых продукт бизнеса будет представлять ценность. И вот уже только потом клиент будет думать, стоит ли продукт того что за него просят и насколько это соотносится с той пользой, которую он получит от покупки этого продукта.
За примерами далеко ходить не надо, посмотрите стоимость продуктов Microsoft. Уж их то пиратят направо и налево, но они, почему-то, не продают свои винды и офисы за копейки. Еще в качестве примера, лицензионные игры на PC, Xbox и Playstation они стоят одинаково (+- пара долларов). Хотя, на компе пиратят, на xbox — чуть-чуть, а на PS почти нет. По Вашей логике, игры на PS должны стоить дешевле, но нет.mortimoro
14.02.2017 20:27+1На практике это тоже работает, если не лениться и не пытаться сразу нахрапом заработать на маленький остров в океане своим стартапом.
Я недавно открыл небольшую тренажерку и быстро набрал клиентуру за счет низкой цены, намного ниже конкурентов. Так вот, по основному источнику дохода (продажа абонементов) я немного в минусе, но за счет допуслуг и магазина для посетителей (обычная витрина на стенке возле входа) я уже получаю небольшой доход. Если бы я лупил такую же цену, как другие тренажерки, то ко мне никто не ходил бы, потому что условия у меня не столь комфортные — мало места, мало тренажеров, один душ, нет бассейна и т.п. Большинство стартапов выходит в ноль только спустя полгода (если доживают до этого времени) и только потом начинают зарабатывать, а я даже за первый месяц не ушел в минус, потому что не ленился каждый день переставлять тренажеры — днем помещение сдавалось в аренду под офис, а вечером тренажеры возвращались на места. А теперь фишка: я не потратил ни копейки на рекламу. Все за счет «халявщиков».
Мелкософт потому за копейки и не продает, что его пиратят и крадут его прибыль. Но он значительно снизил цену на свои продукты после того, как придумал сперва винды толкать принудительно с ноутбуками, а затем предоставлять облачные сервисы вместо коробок. Да и достойных конкурентов его продуктам до сих пор нет: линух до сих пор годится только для гиков и домохозяек, но практически непригоден для офисного планктона (малейшая проблема и человек простаивает до прихода специалиста). А ближайший бесплатный конкурент мелкоофиса — это вообще издевательство над живыми людьми, потому что как только человек сталкивается с нетривиальной задачей, которая в мелкоофисе решается в пару кликов, оказывается что надо скрипты пилить.
По играм ничего сказать не могу, потому как сам не играю и ситуацию на рынке не отслеживаю.habradante
15.02.2017 01:15(Надо сразу оговорить, что рассматривать крайние случаи, типа с первого платежа купить остров — мы не рассматриваем.)
Ну так у вас просто клиентура менее платежеспособна, чем у модных раскрученых фитнес кружков. Тут как раз клиенты не халявщики, а просто те, кто не может себе позволить ходить в более дорогие места.
Мелкософт зарабатывает на корпоративных пользователях и на сервисах. Снижать цену для рядовых пользователей им просто смысла нет, т.к. срок жизни винды (до вин 8, когда мелкомягкие изменили релизный цикл) составлял более 3 лет. 100 долларов за операционку на несколько лет цена небольшая, при цене компьютера порядка 1000 долларов. А при покупке с компьютером цена винды вообще порядка 20-30 долларов. По цене мелкософт даже не пытается конкурировать с линуксом, о чем я и говорил.
Собственно, вы сами понимаете, что ценность предоставляемая виндой выше оной у линукса (для определенных категорий пользователей). Но сравнивать винду с линуксом, для рядовых пользователей, не совсем корректно. А если брать тот же корпоративный сектор, то в нем цены выравниваются. Цена поддержки сопоставима.
asegrenev
09.02.2017 13:56Услуга стоит чтобы ее купить и после начала трекинга и прикрытия «халявы» были реальные подключения таких клиентов. Включить режим инкогнито теперь могут все не задумываясь про куки, хранилища и т п. И очень многие пользуются в нечестных целях.

BalinTomsk
07.02.2017 09:06+1рестарт снапшота vmware с рандомным прокси.
Кстати надо самосборному firefox-у сигнатуру всех браузеров отдавать.
wlbm_onizuka
07.02.2017 09:59+3Порносайты не зло. Порносайты делают то, что хочет пользователь — а значит они добро. Вы же делаете то, что пользователь явно запретил. я бы назвал это мошенничеством
olegbunin
07.02.2017 11:56Ну положим, что я ничего не делаю. Это расшифровка доклада на нашей конференции.
Порносайты незаконны в некоторых странах. Давайте я усугублю фразу — многие highload-технологии были проверены на порносайтах с детской порнографией. Это ведь зло? Мы ведь не должны из-за этого игнорировать эти технологии.
Есть много способов мошенничества, то, что это мошенничество ничего не говорит о качестве ТЕХНОЛОГИИ. Технологию надо изучать с профессиональной точки зрения.Saffron
07.02.2017 17:49+1> Мы ведь не должны из-за этого игнорировать эти технологии.
Конечно. Мы должны разрабатывать адекватный ответ. И разумеется, ни в коем случае не должны такие поганые технологии разрабатывать и внедрять сами. Никакие деньги не стоят кармы. Сегодня вы злоупотребляете доверием не подкованных в IT пользователей, а завтра лечащий врач будет злоупотреблять вашим доверием и невежеством в медицине.selivanov_pavel
07.02.2017 18:06+3Не соглашусь. Тут то же самое, что с поиском уязвимостей: если этого не делают хорошие парни, этим всё равно будут заниматься плохие, но с гораздо худшим эффектом. Гораздо лучше, чтобы такие вещи разрабатывались открыто и у всех на виду, чем по-тихому в недрах спецслужб и корпораций. Вряд ли автор https://github.com/Valve/fingerprintjs2 сделал что-то, чего раньше никто никогда не использовал. Но он сделал это открыто, и теперь мы имеем возможность об этом узнать и подумать о мерах противодействия.
Saffron
07.02.2017 20:25+1Вы слово «внедрять» пропустили. Делать proof of concept — это правильно. Делать готовые продукты — аморально.
selivanov_pavel
07.02.2017 20:33Тут соглашусь, но для маленькой javascript-библиотеки разницы между proof of concept и готовым к внедрению продуктом почти нету.

Myosotis
14.02.2017 01:34Кстати, пример proof of concept: https://amiunique.org
Сбор fingerprints в образовательных целях.

lexlex
07.02.2017 10:00Если при каждом посещении страницы с таким скриптом менять свой user-agent на случайную строку, то отпечаток будет свой для каждого посещения.
Iv38
07.02.2017 12:02Будет, но из-за фаззи-хеширования это только снизит точность. И при этом некоторые сайты будут работать некорректно.
qw1
07.02.2017 20:41из-за фаззи-хеширования это только снизит точность.
Сейчас речь не идёт о технологии, устойчивой к смене N параметров из M возможных. Для этого сайту пришлось бы хранить все параметры и сравнивать новый вектор со всеми сохранёнными, а не как сейчас — оперировать одним хешем.
Для конкретного пользователя изменения параметра сейчас либо сработает, либо не сработает, потому что подобные скрипты выдают единственный ID, а не степень близости к другим посещениям. О «точности» говорят в статистическом смысле.
Фаззи-хеш юзер-агента это классификатор типа Firefox-stable против Chromium-beta и Chrome-Release, с откидыванием номера версии, либо с разбиением множества версий на кластеры, между которыми считаем, что пользователь не переходит.
Поэтому замена Chrome на Opera в User-Agent вполне себе решение. Если скрипт продолжает идентифицировать, значит, UA в построении идентификатора вообще не используется.
kirillaristov
07.02.2017 10:00Fingerprint дает точность 90%.
Cookies дает точность выше (?) 90%.
Однако если cookies однозначно идентифицируют посетителя, то в случае fingerprint такой однозначности нет.
Тогда зачем такая неоднозначная технология?Iv38
07.02.2017 12:11Одно другого не отменяет. Браузерный отпечаток позволяет определить пользователя даже если он избавился от кук или использовал режим инкогнито. В статье упоминается, что библиотека не использует куки, но это просто потому, что идентификацию на куках можно сделать отдельно самостоятельно (и это делается почти всегда) или даже использовать evercookie, так что в этом нет необходимости.
P.S. Я к этому не имею отношения и даже осуждаю использование подобных средств идентификации.

lancettz
07.02.2017 10:00Добрый день, может у кого есть информация как можно подменить в chrome:
userAgent navigator
userAgent plugins
Ghost_nsk
07.02.2017 13:28Совсем по простому:
Object.defineProperty(window.navigator, 'userAgent', {get: function(){return 'Mozilla/5.0 some random data'}}); Object.defineProperty(window.navigator, 'plugins', {get: function(){return []}});
принимать до кода страницы плагинами для user scripthabradante
07.02.2017 14:26Идея хороша, но только с одной стороны. Она так же будет выдавать абы что для не следящих скриптов. Думаю, что надо блокировать именно скрипты, которые собирают отпечаток. Вплоть до того, что определять код таких скриптов и блокировать их.
С подсовыванием ложных данных могут возникнуть проблемы уже на этапе определения наличия флеша, он не определится и пользователь не увидит видео.DjPhoeniX
07.02.2017 14:33Флеш уже много лет у меня выставлен в режим «не пущщать, если мной явно не указано обратное». Думаю, я не один такой. Серьёзно, 2017, HTML5 и все дела…
habradante
07.02.2017 16:02+1А есть еще куча технически неподкованных людей, или просто людей, которым флеш нужен. А еще есть куча других плагинов, помимо флеша, которые так же не будут детектироваться.
qw1
07.02.2017 20:29Firefox спрашивает — сайт пытается запустить flash, разрешить?
На youtube отвечаешь «да, запомнить». На сайтах Эльдорадо/М-Видео — «нет, запомнить». И проблема исчезает.
С другими плагинами аналогично.habradante
07.02.2017 22:57Это не значит что их список нельзя вычитать. Это лишь говорит о том, что пользователю контент не активируется, но информацию о них страница все равно получит.
qw1
08.02.2017 19:29Сам по себе бит «есть flash» — это пустяки. Главное, не запустить апплет, чтобы он не вытащил из системы шрифты и прочие внутренности.
habradante
09.02.2017 10:57Они вытаскиваются не через флэш, а обычным запросом с помощью js. Не надо все сводить к одному лишь флешу. Будет флеш или не будет его, вся информация все равно будет вытащена.
qw1
09.02.2017 13:39То, с чем работает js, можно обмануть через userscript, или специальной сборкой браузера, или его настройками. А вот Flash — проблема — проприетарный блоб, в который не влезешь и ничего не подкрутишь.
habradante
09.02.2017 13:42А вы посмотрите исходник этого fingerprint2, там флеш это даже не 5% от всего. Так что не надо демонизировать его. Все остальное, что js выдергивает, перекрыть куда сложнее, ибо все эти вещи, так или иначе, нужны вполне честным скриптам.
qw1
09.02.2017 20:17вы посмотрите исходник этого fingerprint2
Смотрел. Тут два варианта. Либо автор менее уверенно пишет в AS, чем в js, и в этом конкретном проекте векторов атаки в js реализовано больше. Чтобы увидеть потенциал AS, нужно смотреть другой проект, специализирующийся на утечках через flash.
Либо второй вариант — автор понимает, что в 95% use-cases его скрипта апплет не запустится, поэтому развивать его не надо (сделаем, что попроще, и всё). Не запустится, потому что в последних версиях главных браузеров flash либо полностью отсутствует, либо требует действий пользователя для активации. Если основная польза от сайта сделана не на flash, как у twitch, к примеру, пользователь кнопку активации не нажмёт.
qw1
09.02.2017 20:23что js выдергивает, перекрыть куда сложнее
Сложнее ли? Для js можно подменить API, тупо выполнив userscript до скрипта страницы. Реализации API можно править в открытых исходниках браузера. А flash-скрипт, если уже запустил, никак не скорректируешь. Из AS же можно сделать http request без участия js, и всё — инфа утекла. Проще AS совсем не разрешать (что проблематично сделать с js)habradante
10.02.2017 11:51И эти функции перестанут работать для безопасных и нужных скриптов. Это не вариант.
qw1
10.02.2017 12:00Очень даже вариант. Выключаем на всех доменах, включаем там, где действительно нужно. Полезных сайтов, которым нужен canvas, по пальцам пересчитать.
habradante
10.02.2017 14:03+1А как быть, если JS функционал нужен, а отпечаток нет? Я думаю, что нужен способ блокировать объекты, которые хотят сразу много от браузера. Это, конечно, сложнее, но, думаю, выявлять такие объекты можно.
qw1
10.02.2017 22:58Я не предлагаю выключить js. Я предлагаю урезать некоторые возможности, вроде canvas. Вы знаете примеры сайтов, где он нужен? В крайнем случае, можно в рендер текста добавить пару случайных пикселей и «до свидания, хеш».
habradante
11.02.2017 00:29Я посещаю много сайтов, где нужен canvas, плюс он мне для разработки нужен. Библиотеки для отрисовки графиков часто используют canvas.
qw1
12.02.2017 09:16В таком случае, идеальное решение, которое всех устроит — как с flash.
Браузер спрашивает: «сайт пытается использовать canvas, разрешить?» (и галочка специально для вас — «запомнить текущий выбор и автоматически применять его в будущем»).habradante
13.02.2017 17:18Я вот сейчас реализовал блокировку canvas на чтение и заодно спрятал список шрифтов и… стал уникальным «неуловимым Джо». Идея закрывать все это хороша только при условии, что таких «закрывальщиков» станет много, иначе все равно хэш получается уникальным. Так что надо идти в сторону снижения уникальности хэша путем усреднения определяемых данных.
Saffron
11.02.2017 13:51+1Те полтора сайта, которые активно используют все возможности js и полезны можно запускать в отдельных виртуалках/firejail-ах. Самое паршивое — это возможность читать канвас, а не писать канвас. Отключи чтение канваса — у тебя останется возможность рисовать графики, но не возможность идентифицировать компьютер.
Ну и из разряда фантастики — security domain, каждый скрипт подписан, пользователь раздаёт им разрешения на доступ индивидуально. Ни один флагман js не внедрит это в своё браузер, потому что как тогда бабки на рекламе стричь с пользователей?habradante
13.02.2017 10:27Делать виртуалки для сайтов с канвой это ..., мягко говоря, перебор. А вот перегрузить апи для чтения канвы это хорошая идея. Надо попробовать.
Loki3000
07.02.2017 10:28-1Что вы кипишите? Это всего лишь технология. Как и множество других технологий, ее можно использовать как во благо, так и во вред. Используйте во благо — и будет вам счастье. Опять же, можете придумать технологию для противодействия этой — тоже благое дело (которое, кстати, тоже может быть использовано во вред:)
kernelconf
07.02.2017 11:56Выходом из ситуации может служить создание аддонов, которые динамически меняют большинство параметров по какому-нибудь непериодическому условию (нажатие кнопки, рестарт браузера).
По сути, аддоны анонимизации действуют крайне деанонимизирующе (например, меняют canvas fingerprint случайно каждый раз). Это даже хуже, чем не менять его вовсе.
Я поискал сейчас на сайте плагинов для ФурриФокса, кажется, такого нет. Обычно меняют на статистически распространённые параметры. Подкинуть им идею, что-ли.
mortimoro
07.02.2017 12:44+1Палка о двух концах: с одной стороны, как разработчику, мне интересна идентификация пользователя, но со стороны пользователя я бы хотел иметь возможность анонимизации по мере необходимости. Я уверен в том, что персональные данные моих пользователей будут использованы для защиты от злоупотребления ними и для аналитики. При этом я не уверен, что другие разработчики поступают с моими персональными данными так же корректно.
В любом случае, за статью спасибо — методики идентификации действительно оригинальны и любопытны.
mimoprohodilireshilnapisa
07.02.2017 16:20+2Немного нарягает нытье. Если таких статей не будет, это не значит, что технология исчезнет. То, что автор не дает отрицательную эмоциональную характеристику технологии не значит, что подобные статьи не нужны.
Давайте лучше подумаем, что можно с этим сделать.
Отдельный браузер и виртуалки — не вариант. Понятно, что для просмотра нехороших (очень) видео этим можно заморочиться, но для повседневного серфинга это оверкил. Трекинг пользователей описанный выше как раз и применяется для отслеживания повседневной активности. Я не хочу запускать шифрованную виртуалку, чтобы прочитать фид вк. Нужно решение максимум уровня адблока.
> http cookie
Вайт лист сайтов, которым можно сохранять куки, либо сброс после закрытия браузера. Лично для меня второй вариант не особо подходит, ибо браузер я закрываю пару раз в месяц в лучшем случае.
> flash
Слишком большая дыра, чтобы ее пытаться закрыть. Да и использовать flash в 2017 это добровольный суицид, даже хром его по-моему отключает по умолчанию уже.
> silverlight
Думаю, все то же, что и с flash. Лично ни разу не пользовался. Неплохой повод перестать пользоваться легальными стриминговыми сервисами :3
> png cookie
Отчистка кеша при перезапуске браузера/по времени.
> html5 хранилища
Аналогично, хранение только на время сеанса.
> java
>The Chrome browser does not support NPAPI plug-ins and therefore will not run all Java content
В файрфоксе ручное подтверждение запуска любых java приложений.
> user agent
Лучше всего не трогать, одинаковый у достаточно большого количества пользователей.
> language
> timezone
Важный момент, по отдельности не страшны, но вместе вполне себе. Например, таймзона +0 и язык русский будет весьма уникальной комбинацией. Английский наиболее нейтральный в качестве языка. Таймзону ради анонимности мало кто согласиться менять, так что с ней придется смириться.
Таймзоны часто сверяются с локацией текущего айпи и если они не совпадают, то велика вероятность использования впн/других анонимизирующих технологий. Так что сидеть через впн, скроля алиэкспресс не стоит.
> размер экрана
> глубина цвета
Если только у вас не 4к мониторы, параметры дефолтные у большинства.
> html5
Поправьте если ошибаюсь, но на одинаковых версиях браузера, технологии будут одинаковые. Поэтому это чистое дублирование юзерагента.
> platform specific data
Ду нот трек лучше не включать, те, кто хотят, все равно трекать будут. Остальное критично только для необычных конфигураций.
> плагины
В хроме они вроде как стандартные сейчас.
> canvas fingeprint
Идей противодействию нет. Насколько часто канва используется в вебе?
> fuzzy hash
Вот тут начинается все плохое. Если раньше было достаточно сменить любой параметр и успокоиться, то теперь нужно набирать этих параметров на определенный процент.
> fonts
Весьма уязвимое место, особенно если вы любите поустанавливать шрифты. Например, при просмотре видео с субтитрами, в которые напихали каких-нибудь элитных спираченных шрифтов.
Решением может быть удаление/установка ±10% рандомных шрифтов при запуске системы.
> webgl
Аналогично канве не очень понятно, что можно сделать. Что-то мне подсказывает, что все эти эффекты и треугольники будут сильно тормозить сайт, но все же.
> webrtc
отключается
Как мы видим, основная проблема на самом деле фаззи хеши. Если наизменять достаточно параметров, это все еще можно обойти, но если авторы станут чуть умнее и будут учитывать только сложноизменяемые вещи, типа графики или шрифтов, станет реально плохо.
Радикальным решением может быть эвристика: анализ всех скриптов и попытка выявить подозрительную активность. Если сайт с рецептами пирогов создает невидимую канву и начинает потом считывать ее попиксельно, возможно стоит заблокировать соответсвующий код. Аналогично для js проверки шрифтов.
zelenin
07.02.2017 16:32html5
Поправьте если ошибаюсь, но на одинаковых версиях браузера, технологии будут одинаковые. Поэтому это чистое дублирование юзерагента.
не совсем: с одной стороны технологии могут не различаться от версии к версии, с другой стороны юзер-агент различается на разных платформах (windows, linux итд). Таким образом, у нас есть более специфичный, но подделываемый юзер-агент, и более общий, но неподделываемый (труднее/реже) набор технологий.

redmanmale
07.02.2017 17:53canvas fingeprint
Идей противодействию нет.
Есть расширения для блокировки канваса, с правилами, исключениями.

dartraiden
07.02.2017 22:55+1Вайт лист сайтов, которым можно сохранять куки, либо сброс после закрытия браузера. Лично для меня второй вариант не особо подходит, ибо браузер я закрываю пару раз в месяц в лучшем случае.
Self-Destructing Cookies удаляет куки при закрытии вкладки, если мне не изменяет память.
webrtc
отключается
В Firefox достаточно просто настроить один параметр, убирающий утечку адресов.
selivanov_pavel
07.02.2017 23:26> Решением может быть удаление/установка ±10% рандомных шрифтов при запуске системы.
Расширение к браузеру, рандомно включающее/выключающее самые малоиспользуемые шрифты, оставляя самые распространённые. Но движок хрома так сделать по-моему не даст, только если руками под капот лезть.

ZoomLS
07.02.2017 18:17>>Все это препятствует трекингу и идентификации в Интернете.
И это правильно. Ибо нефиг. Пользователь сам должен решать, хочет он быть отслеживаемым или нет.scarab
07.02.2017 18:23-1Именно поэтому преступники надевали чёрные маски.
ZoomLS
07.02.2017 22:04+1Причём тут преступники? Речь о неприкосновенности частной жизни. За такое в приличном обществе и огребсти можно. В Европе даже за использование кук, нужно информировать пользователя, такое уж точно будет под запретом. Благо и средства блокировки от таких умников, тоже будут.
scarab
07.02.2017 23:30-2А где тут частная жизнь?
Взаимоотношения пользователя и сайта — это дело как пользователя, так и сайта.
Сайт не пытается лезть в частную жизнь пользователя, отслеживать его поведение на других сайтах (что делает, например, Google Analytics, но никто, почему-то, его тухлыми яйцами не закидывает), не пытается даже выяснить ФИО. Все данные, которые собираются сайтом — это данные, предоставляемые штатными средствами браузера и браузерных технологий.
Единственное, что пытается сделать сайт — идентифицировать собственного клиента под разными логинами, например (включая незалогиненный статус). Но факт посещения Вами любого сайта — это де-юре Ваши с ним взаимоотношения, которые касаются как его, так и Вас.
Вам нравится, я думаю, HTTPS и зелёненький сертификат, который позволяет Вам удостовериться, что посещаемый Вами сайт — это именно этот сайт, а не подделка фишеров. Тогда почему Вы отказываете сайту в праве удостовериться, что Вы — это Вы?
Почему Вас не беспокоит, что IRL банки, отели, авиакомпании, кто угодно ещё требуют предъявления паспорта? В паспорте содержится куда больше информации о Вас, чем в упомянутом отпечатке. Потому, что Вы осведомлены о факте идентификации? Ну так считайте, что Вас идентифицируют по умолчанию всегда и везде.
Не смущает ли Вас, что обычная московская карточка-проездной в метро и автобусе, «Тройка», также обладает уникальным номером, позволяющим отследить Ваши перемещения?
Не настораживает ли, что банк видит все ваши платежи, когда Вы расплачиваетесь картой? Включая сумму, место покупки, время и так далее?
А тут тривиальный отпечаток браузера вызвал столько шуму внезапно.ZoomLS
07.02.2017 23:57+2>>А где тут частная жизнь?
Повсюду.
>>Google Analytics, но никто, почему-то, его тухлыми яйцами не закидывает
Ещё как закидывают. У многих эта гадость заблокирована ещё со стороны роутера.
>>это данные, предоставляемые штатными средствами браузера и браузерных технологий.
Но как видим, можно использовать во благо, но кто-то пытается не во благо.
>>Тогда почему Вы отказываете сайту в праве удостовериться, что Вы — это Вы?
Когда пользователь этого хочет, он делает это. Но, когда он этого не хочет, а сайт лезет куда не надо. В лучшем случае, просто забить на такой сайт. В худшем, отбиваться всеми способами.
>>Ну так считайте, что Вас идентифицируют по умолчанию всегда и везде.
С чего это я должен так считать?! Ничего подобного.
>>«Тройка», также обладает уникальным номером, позволяющим отследить Ваши перемещения?
Не пользуюсь.
>>банк видит все ваши платежи, когда Вы расплачиваетесь картой?
Не расплачиваюсь картой, только наличка.
>>А тут тривиальный отпечаток браузера вызвал столько шуму внезапно.
Это вредит анонимности в сети. У пользователя должен быть выбор.
wladyspb
16.02.2017 14:41+1Банк делает мне предложение(оффер) — я пользуюсь его услугами, предоставляя информацию о себе, он со своей стороны подтверждает свою легитимность. В случае с любым сайтом, оффер — это логин. Если сайт не хочет, чтобы анонимные пользователи использовали доступную в интернете в открытом доступе информацию — она должна находится в личном разделе сайта, защищённом аутентификацией. Когда я пытаюсь попасть на эту страницу, сайт говорит мне — ты расскажи кто ты, мил человек, и тогда я тебя пущу, а иначе иди лесом. Это — оффер. А если сайт пускает меня к открытой информации, но при этом скрытно от меня проводит мою идентификацию — вне зависимости от целей — это не оффер, это слежка\шпионаж\мошенничество — называйте как хотите, но я должен быть поставлен в известность о том, что меня идентифицировали)
selivanov_pavel
07.02.2017 23:34Вот вам список ситуаций, в которые может попасть совершенно законопослушный человек:
- Импотенция для мужчины или фригидность для женщины
- СПИД (совсем необязательно входить в группу риска, достаточно неудачного переливания крови)
- Любая другая "позорная" болезнь: геморрой, простатит, недержание мочи
- Жертва изнасилования
- Нетрадиционная сексуальная ориентация
- Психологические проблемы, требующие работы со специалистом
- Серьёзный разлад в семье
Все эти люди обязаны ходить по улицам с приклеенным на груди плакатом, извещающем всех об их ситуации? Или всё-таки позводим им носить чёрные маски анонимности?
scarab
07.02.2017 23:47-2Уточните, пожалуйста, каким образом описанная в статье технология деанонимизирует перечисленные события?
Допустим, что некий гомосексуалист посещает тематический форум сексуальных меньшинств и общается там под никнеймом vasya1. Допустим, что движок этого форума использует описанную в статье библиотеку.
Что случится? Я вижу только одно: если этот человек зайдёт на этот же форум под никнеймом vasya2 — то администрация форума узнает, что это тот же человек, что и vasya1. Всё.
НИКАКОЙ дополнительной информации о пользователе, собрано не будет. Всё, что собирается — собирается штатными средствами, доступными и без технологии отпечатка.
НИКАКОЙ информации о том, какие ещё сайты посещает этот пользователь, собрано не будет.
НИКАКОГО дополнительного раскрытия информации также не произойдёт.
Зато я вижу целую кучу полезных применений. Например, борьба со спамерами, которые регистрируют сотнями поддельные аккаунты и с них спамят. То же самое с чёрными SEOшниками.
При этом: мне, как владельцу форума, не надо знать, как там этого спамера зовут и где он живёт. Мне достаточно, что он, будучи забанен под одним никнеймом, не сможет зайти и нагадить под другим.selivanov_pavel
08.02.2017 00:01Допустим, что некий гомосексуалист посещает тематический форум сексуальных меньшинств и общается там под никнеймом vasya1. Допустим, что движок этого форума использует описанную в статье библиотеку. Что случится?
На любом другом сайте можно будет встроить картинку с домена этого форума, чтобы однозначно привязать ничем не примечательного Василия Петровича к конкретному аккаунту на специфичном форуме.
Я не говорю, что все владельцы сайтов спят и видят как нагадить своим пользователям. Но если какая-то информация имеет ценность, то рано или поздно ей начнут торговать или обмениваться — разумеется, исключительно для улучшения точности таргетированной рекламы и с заботой о комфорте пользователя.
Да, эта технология может приносить и пользу тоже, но потенциальный вред так велик, что не идёт ни в какое сравнение. Это как например разрешить убивать людей, если они собираются более чем по двое во дворе вашего дома. Куча полезных применений: однозначно решит проблему с орущими посреди ночи пьяными компаниями.
scarab
08.02.2017 00:17На любом другом сайте можно будет встроить картинку с домена этого форума, чтобы однозначно привязать ничем не примечательного Василия Петровича к конкретному аккаунту на специфичном форуме.
Оп, а можно с этого места поподробнее? Возможно, я отстал от жизни и чего-то не понимаю в последних нововведениях.
Чем встраивание картинки владельцем сайта X с форума F (предположительно, это разные люди) будет отличаться в разрезе идентификации, если:
вариант 1: форум F использует технологию отпечатков браузера.
вариант 2: форум F не использует технологию отпечатков браузера.selivanov_pavel
08.02.2017 00:25Я невнимательно написал, извиняюсь. Всё сложнее конечно: форум F сможет отдавать сайту X идентификатор пользователя, как сейчас его могут отдавать например виджеты социальных сетей "авторизуйся у нас через фейсбук"(обычно с сголасия пользователя, но идея та же). То есть не пассивная картинка, а немного яваскрипта и обработчик со стороны форума F.
Кстати, если защита в форуме на продумана, то можно кстати и без ведома владельца форума вычислить: например, если ссылка на редактирование своего профиля фиксированная, не проверяет реферер, отдаётся через GET и не имеет защиты от CSRF, то можно её запросить и распарсить. Но это уже целевая атака на конкретный форум.
scarab
08.02.2017 00:32Ну хорошо, пусть даже форум дырявый и владельцу сайта X удалось вытащить идентификатор пользователя vasya1 и связать его с аккаунтом «Василий Петрович» на своём сайте. Это тривиальный cross-site scripting.
На следующий день Василий Петрович зашёл на форум под ником vasya2 и опять-таки владелец сайта X связал оба этих аккаунта. Таким образом, владелец сайта X может узнать о том, что vasya1@F и vasya2@F — это один и тот же человек.
Но причём тут браузерные отпечатки и тот факт, что где-то в базе юзеров форума F будет храниться информация о том, что vasya1 = vasya2? Если БД не утечёт — всё нормально; если утечёт — там, скорее всего, уже не до отпечатков будет.selivanov_pavel
08.02.2017 00:38+2Нет, на следующий день Василий Петрович закрыл окно с инкогнито режимом браузера, в котором открывал форум F, и из обычного браузера пошёл на другой совершенно сайт. А там скрипт рекламной сети, сотрудничающей с форумом F, распознал его профиль и предлагает ему купить всякие интересные игрушки для взрослых. И таким образом информация, которая по мнению Василия Петровича осталась в инкогнито режиме браузера, попала к третьим лицам.
scarab
08.02.2017 00:42Ответ принимаю, спасибо.
Правда, это уже торговля чужими ПД получается, причём явно без согласия владельца ПД. Но в целом — да, такое возможно.selivanov_pavel
08.02.2017 23:38Если профиль выглядит как { "name": "vasya1", "interests": ["homo_sex", "animal_sex", "submission_sex", "copro_sex"] } — то это по-моему даже персональными данными не будет считаться, пока не будет содержать однозначной привязки к конкретному человеку.
Уже сейчас практически любой сайт передает в Google Analytics и Яндекс.Метрику как минимум данные о том, в какое время с какого IP на какие страницы я заходил. Никаких проблем с ПД у них не возникает.
Но если сейчас я хотя бы могу разлогинится из своих аккаунтов, заблокировать их с помощью Ghostery и Disconnect.me, открыть инкогнито-режим наконец — то когда они внедрят(если уже не внедрили) такую технологию — у меня, как у простого пользователя, не остаётся возможности не делиться с ними своей историей посещения сайтов, интересами, местоположением, режимом дня.
Вобщем, на мой взгляд с приватностью всё очень печально и будет ещё хуже.
Myosotis
11.02.2017 11:56Можно пользоваться разными браузерами для разных целей. А один из них можно запускать из виртуалки.
selivanov_pavel
11.02.2017 18:32fingerprintjs может увидеть браузеры с одного компьютера как один аккаунт. Все браузеры на виртуалках на том же компьютере скорее всего увидит как другой аккаунт. Пользы мало — удобство работы серьёзно снижается, надо постоянно дёргаться что откуда открывать, легко перепутать, а разбиение своего виртаульного профиля на 2 или 3 почти ничего не даёт — статистики накапливается достаточно в обоих кусках профиля.
Нет, должны предприниматься другие меры: ограниченный список шрифтов в браузере, кроме сайтов-исключений; запрет canvas, кроме опять же явных исключений; возможно ещё какие-то техники, причём всё это должно идти в браузерах из коробки
qw1
12.02.2017 09:35fingerprintjs может увидеть браузеры с одного компьютера как один аккаунт.
Конкретно fingerprintjs у меня выдаёт разный хеш на трёх браузерах (IE, Chrome, Firefox). И неудивительно, User-Agent же включен в хеш.qw1
12.02.2017 09:46Для проверки взял только хеш от canvas, без каких-либо других параметров.
На одной машине в chrome, IE, firefox он различается.
В IE различается на разных машинах.
В Firefox одинаковый для одинаковой версии браузера для разных машин.
Chrome на второй машине не оказалось, чтобы проверить.
gearbox
12.02.2017 21:55Там можно указывать, что именно включать в хэш. Но да, почти все входные данные являются параметрами броузера, та что непонятно как идентифицировать машину а не броузер.
selivanov_pavel
12.02.2017 22:16fingerprintjs или fingerprintjs2? Про второй в статье вроде писали, что там фуззи-хеш и одним юзер агентом не обойдёшься. Ну и опять же, ну будет у пользователя не один сетевой профиль, а два. Невелика разница.
scarab
07.02.2017 18:22-1Спасибо за публикацию, разработка действительно интересная и полезная. И я бы не сказал, что она однозначно вредна. Как и с большинством вещей в этом мире, её можно употребить во зло, а можно на вполне адекватные цели.
Мне доводилось писать подобное, и вовсе не с целью слежки за пользователями. Слежка плоха, когда она касается посторонней деятельности пользователя (скажем, если я внедрю юзеру троян и буду следить, что он делает — это нехорошо), а вот если речь идёт об идентификации пользователя на моём сайте — я считаю, что я имею право знать, тот ли это Вася Пупкин, или не тот.
Опять же, никто не заглядывает Васе в карман, не считает деньги на его банковской карточке, не выясняет ФИО и место жительства. А идентифицировать юзера на собственном сайте, я считаю, владелец сайта имеет полное право. Кому не нравится — может идти на другие.ZoomLS
07.02.2017 22:09+1>>Кому не нравится
Кому не нравится, блокируют все эти следящие трекинги.scarab
07.02.2017 23:52-1Мысль хорошая. Пожалуй, я закрою доступ на свои проекты людям с установленным флажком DoNotTrack. Как закрыл доступ с выходных нод Tor-а (ничего хорошего, как показала практика, оттуда не приходит).
Всё честно. Если человек придёт в банк и откажется предъявить паспорт — его вежливо попросят удалиться. Я расцениваю заявления Do not track примерно так же.ZoomLS
08.02.2017 00:05DoNotTrack не даёт никаких гарантий. Это просто, как высказать своё мнение. Многие сайты даже не в курсе о существовании DoNotTrack, а чтобы ещё и учитывали — единицы.
Блокировка происходит более действенными способами. Спец плагины в браузерах, со стороны системы, роутера и т.д. Чтобы наверняка.
Кстати, с таким подходом, что будете делать, когда всех забаните? ;)
Saffron
08.02.2017 10:01+2> Как закрыл доступ с выходных нод Tor-а (ничего хорошего, как показала практика, оттуда не приходит).
Странная у вас практика. Некоторые сайты так вообще открывают своё представительство в Tor.selivanov_pavel
08.02.2017 12:38Зависит от специфики сайта. Для какой-нибудь платёжной сисемы соотношение попыток фрода через Тор к полезному трафику может быть так уныло, что проще закрыть.

Komei
08.02.2017 16:39+1А потом мы ещё удивляемся, почему это браузеры лагают и по ГБ ОЗУ кушают. Вот открываешь такой сайтик, а он начинает 1700 шрифтов тестировать (это же их нужно загружать с диска, рисовать и т.д.). Ну и остальное в том же духе. Ауж на телефонах то это как приятно или на ноутах. Я конечно понимаю желание трекинга, но честно, не нужно вести себя по скотски. Если человек уже специально ставит donottrack, то он явно намекает что своё нежелание быть отслеженным.
Scratch
Мне кажется, 32битные идентификаторы начнуть выдавать коллизии гораздо раньше, чем пойдут реальные дубликаты, точнее через 65к уников. Я бы взял хэш побольше (SipHash например)
funca
2?? это 4294967296. Вероятно еще какие-то биты можно добавлять на сервере (ip адрес, наличие проксей).
Scratch
Парадокс дней рождения говорит о том, что коллизии начнутся через 2^16, это как раз 65к