
Будем получать биржевые данные Forex от одного из брокеров, сохраним в базу данных PostgreSQL и попробуем найти закономерности при помощи алгоритмов машинного обучения.
В статье есть несколько приятных бонусов в виде кода на Python — Вы сможете сами проанализировать любые (почти) биржевые данные (или значения индикаторов), запустить собственного торгового робота и проверить любую торговую стратегию.
Все условия и определения паттернов в статье приведены для примера, вы можете использовать любые критерии.
Что такое паттерн и как его использовать?
Паттерн — это устойчивая, повторяющаяся фигура последовательных биржевых данных, после возникновения которой цена с большой вероятностью изменится в нужную сторону.
Проанализировать статистику, для того, чтобы найти повторяющиеся закономерности — задача не из легких, но если зависимости удается найти, то предсказать движение цены удается достаточно точно. При помощи методов машинного обучения поиск паттернов сводится к выбору наилучшего классификатора — алгоритма, обучающегося на исторических данных и прогнозирующего движение цены с определенной вероятностью.
Такой механизм вполне может стать частью успешной торговой стратегии в совокупности с другими методами анализа рынка.
Подготовка
- Для того, чтобы получать исторические данные и выставлять заявки на Forex через RESTv20 API, нам потребуется demo счет у известного брокера. Регистрация занимает минуту, после чего Вы получаете token (уникальный ключ для доступа) и номер счета.
- Необходим Python версии 2.7 с установленными библиотеками: oandapyV20, sklearn, matplotlib, numpy, psycopg2. Их можно установить через pip.
- Необходим PostgreSQL, у меня версия 9.6.
Описание модели
Самое первое, что нужно описать — собственно, исторические данные.
Создадим класс Candle, который будет хранить информацию о каждой свече:
class Candle:
def __init__(self, datetime, ask, bid, volume):
self.datetime = datetime
self.ask = ask
self.bid = bid
self.volume = volume
Описание паттерна будет таким:
class Pattern:
result = ''
serie = list()
def __init__(self, serie, result):
self.serie = serie
self.result = result
Каждой серии данных будет соответствовать результат, в нашем случае, покупка или продажа.
Здесь нужно не забыть, что нас интересует форма. Это значит, просто ценами паттерн описывать не верно, необходима их нормализация. Об этом ниже.
 Введем еще два параметра:
Введем еще два параметра:- Длина серии (Length) — количество последовательных элементов в серии паттерна
- Ширина окна (window size) — количество последовательных элементов после серии, для хотя бы одного из которых выполняется условие выбора паттерна
Какими будут условия для выбора паттернов? — такими, чтобы получить прибыль:
Если мы покупаем по цене ask = X, то продать должны по возросшей цене bid > X. И наоборот, если мы продаем по цене bid = Y, то купить должны по цене ask < Y. В этом изменение цены будет больше спреда на момент покупки, и мы получим прибыль.
Сегодня я предлагаю использовать эти простые правила для отбора паттернов, но, на самом деле, чтобы все хорошо работало, к ним нужно добавить несколько фильтров. Это я предлагаю сделать Вам позже самостоятельно. Не забывайте, что выбор исходных данных (периода, рынка, инструмента и тп) очень важен — где-то паттерны есть, а где-то нет. Или нужно изменить условия их отбора.
Получаем данные
Получим данные от брокера и сохраним их в БД PostgreSQL. Первым делом, создадим класс, который будет загружать данные:
import pandas
from oandapyV20.endpoints import instruments
class StockDataDownloader(object):
def get_data_from_finam(self, ticker, period, marketCode, insCode, dateFrom, dateTo):
"""Downloads data from FINAM.ru stock service"""
addres = 'http://export.finam.ru/data.txt?market=' + str(marketCode) + '&em=' + str(insCode) + '&code=' + ticker + '&df=' + str(dateFrom.day) + '&mf=' + str(dateFrom.month-1) + '&yf=' + str(dateFrom.year) + '&dt=' + str(dateTo.day) + '&mt=' + str(dateTo.month-1) + '&yt=' + str(dateTo.year) + '&p=' + str(period + 2) + 'data&e=.txt&cn=GAZP&dtf=4&tmf=4&MSOR=1&sep=1&sep2=1&datf=5&at=1'
return pandas.read_csv(addres)
def get_data_from_oanda_fx(self, API, insName, timeFrame, dateFrom, dateTo):
params = 'granularity=%s&from=%s&to=%s&price=BA' % (timeFrame, dateFrom.isoformat('T') + 'Z', dateTo.isoformat('T') + 'Z')
r = instruments.InstrumentsCandles(insName, params=params)
API.request(r)
return r.response
Бонус: я оставил в этом классе метод, который загружает любые исторические данные с Финама. Это очень удобно, потому что можно проанализировать как Forex, так и рынки ММВБ и ФОРТС. Минус только в том, что данные могут быть загружены с периодом не менее 1 минуты, в то время как второй метод может загрузить 5-секундные свечи.
Теперь сделаем простой скрипт, которые загружает данные в БД:
import psycopg2
from StockDataDownloader import StockDataDownloader
from Conf import DbConfig, Config
from datetime import datetime, timedelta
import oandapyV20
import re
step = 60*360 # download step, s
daysTotal = 150 # download period, days
dbConf = DbConfig.DbConfig()
conf = Config.Config()
connect = psycopg2.connect(database=dbConf.dbname, user=dbConf.user, host=dbConf.address, password=dbConf.password)
cursor = connect.cursor()
print 'Successfully connected'
cursor.execute("SELECT * FROM pg_tables WHERE schemaname='public';")
tables = list()
for row in cursor:
tables.append(row[1])
for name in tables:
cmd = "DROP TABLE " + name
print cmd
cursor.execute(cmd)
connect.commit()
tName = conf.insName.lower()
cmd = ('CREATE TABLE public."{0}" (' 'datetimestamp TIMESTAMP WITHOUT TIME ZONE NOT NULL,' 'ask FLOAT NOT NULL,' 'bid FLOAT NOT NULL,' 'volume FLOAT NOT NULL,' 'CONSTRAINT "PK_ID" PRIMARY KEY ("datetimestamp"));' 'CREATE UNIQUE INDEX timestamp_idx ON {0} ("datetimestamp");').format(tName)
cursor.execute(cmd)
connect.commit()
print 'Created table', tName
downloader = StockDataDownloader.StockDataDownloader()
oanda = oandapyV20.API(environment=conf.env, access_token=conf.token)
def parse_date(ts):
# parse date in UNIX time stamp
return datetime.fromtimestamp(float(ts))
date = datetime.utcnow() - timedelta(days=daysTotal)
dateStop = datetime.utcnow()
candleDiff = conf.candleDiff
if conf.candlePeriod == 'M':
candleDiff = candleDiff * 60
if conf.candlePeriod == 'H':
candleDiff = candleDiff * 3600
last_id = datetime.min
while date < dateStop - timedelta(seconds=step):
dateFrom = date
dateTo = date + timedelta(seconds=step)
data = downloader.get_data_from_oanda_fx(oanda, conf.insName, '{0}{1}'.format(conf.candlePeriod, conf.candleDiff),
dateFrom, dateTo)
if len(data.get('candles')) > 0:
cmd = ''
cmd = ('INSERT INTO {0} VALUES').format(tName)
cmd_bulk = ''
for candle in data.get('candles'):
id = parse_date(candle.get('time'))
volume = candle.get('volume')
if volume != 0 and id!=last_id:
cmd_bulk = cmd_bulk + ("(TIMESTAMP '{0}',{1},{2},{3}),\n"
.format(id, candle.get('ask')['c'], candle.get('bid')['c'],
volume))
last_id = id
if len(cmd_bulk) > 0:
cmd = cmd + cmd_bulk[:-2] + ';'
cursor.execute(cmd)
connect.commit()
print ("Saved candles from {0} to {1}".format(dateFrom, dateTo))
date = dateTo
cmd = "REINDEX INDEX timestamp_idx;"
print cmd
cursor.execute(cmd)
connect.commit()
connect.close()
Если вы внимательно посмотрите на данные от Oanda, то увидите, что некоторые свечи пропущены. Причем, чем меньше период загружаемых данных, тем больше пропусков. Это не ошибка, а связано с тем, что цена за время пропусков не изменилась. Поэтому есть два способа загрузки таких данных — сохранять как есть, или добавлять пропущенные свечи со значениями, аналогичными последней свече от брокера с нулевым объемом. В репозитории на Github реализованы оба варианта, последний закомментирован. Так же, если Вы посчитаете нужным добавлять пропущенные свечи, есть скрипт DbCheck.py, проверяющий правильность последовательности свечей для этого случая.
Анализ данных
Сделаем простой класс, который будет содержать методы для поиска паттернов и преобразовывать их в векторы для алгоритмов машинного обучения:
import psycopg2
from Conf import DbConfig, Config
from Desc.Candle import Candle
from Desc.Pattern import Pattern
import numpy
def get_patterns_for_window_and_num(window, length, limit=None):
conf = Config.Config()
dbConf = DbConfig.DbConfig()
connect = psycopg2.connect(database=dbConf.dbname, user=dbConf.user, host=dbConf.address, password=dbConf.password)
cursor = connect.cursor()
print 'Successfully connected'
tName = conf.insName.lower()
cmd = 'SELECT COUNT(*) FROM {0};'.format(tName)
cursor.execute(cmd)
totalCount = cursor.fetchone()[0]
print 'Total items count {0}'.format(totalCount)
cmd = 'SELECT * FROM {0} ORDER BY datetimestamp'.format(tName)
if limit is None:
cmd = '{0};'.format(cmd)
else:
cmd = '{0} LIMIT {1};'.format(cmd, limit)
cursor.execute(cmd)
wl = list()
patterns = list()
profits = list()
indicies = list()
i = 1
for row in cursor:
nextCandle = Candle(row[0], row[1], row[2], row[3])
wl.append(nextCandle)
print 'Row {0} of {1}, {2:.3f}% total'.format(i, totalCount, 100*(float(i)/float(totalCount)))
if len(wl) == window+length:
# find pattern of 0..length elements
# that indicates price falls / grows
# in the next window elements to get profit
candle = wl[length-1]
ind = length + 1
# take real data only
if candle.volume != 0:
while ind <= window + length:
iCandle = wl[ind-1]
# define patterns for analyzing iCandle
if iCandle.volume != 0:
if iCandle.bid > candle.ask:
# buy pattern
p = Pattern(wl[:length],'buy')
patterns.append(p)
indicies.append(ind - length)
profits.append(iCandle.bid - candle.ask)
break
if iCandle.ask < candle.bid:
# sell pattern
p = Pattern(wl[:length],'sell')
patterns.append(p)
indicies.append(ind - length)
profits.append(candle.bid - iCandle.ask)
break
ind = ind + 1
wl.pop(0)
i = i + 1
print 'Total patterns: {0}'.format(len(patterns))
print 'Mean index[after]: {0}'.format(numpy.mean(indicies))
print 'Mean profit: {0}'.format(numpy.mean(profits))
connect.close()
return patterns
def pattern_serie_to_vector(pattern):
sum = 0
for candle in pattern.serie:
sum = sum + float(candle.ask + candle.bid) / 2;
mean = sum / len(pattern.serie)
vec = []
for candle in pattern.serie:
vec = numpy.hstack((vec, [ (candle.ask+candle.bid) / (2 * mean) ]))
return vec
def get_x_y_for_patterns(patterns, expected_result):
X = []
y = []
for p in patterns:
X.append(pattern_serie_to_vector(p))
if (p.result == expected_result):
y.append(1)
else:
y.append(0)
return X, y
В первом методе как раз описываются условия для выбора паттернов, а последний возвращает векторы для алгоритмов. Обратите внимание на метод pattern_serie_to_vector, который нормализует данные. Как уже говорилось выше, цены могут быть разные, а форма одинаковая (аналог в тех анализе — паттерн треугольник, неважно какие цены, важно взаимное расположение последовательных свечей).
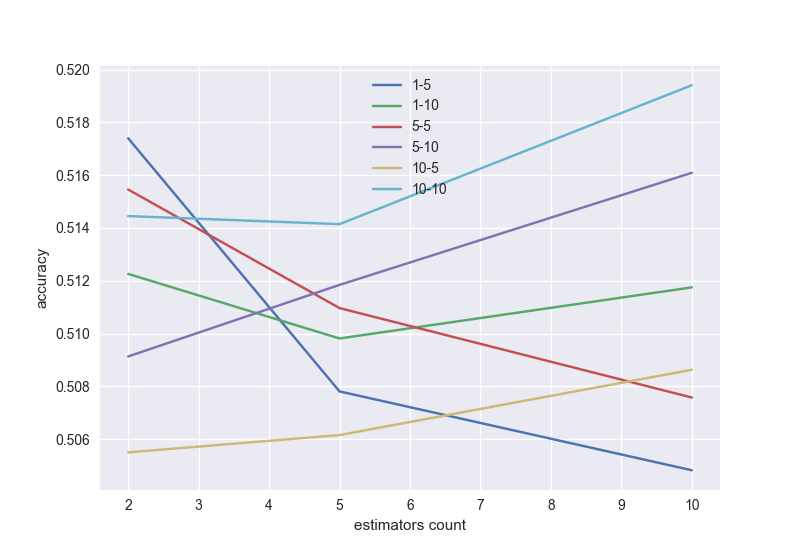
А теперь самое интересное, проверим результат работы двух классификаторов — градиентного бустинга и линейной регрессии. Будем оценивать площать под ROC кривой (AUC_ROC) для кроссвалидации по 5 блокам, в зависимости от настроек алгоритма.
Напоминаю, что площадь под ROC кривой меняет свое значение от 0.5 (самый плохой классификатор) до 1 (самый лучший классификатор). Наша цель — получить хотя бы 0.8.
Проверим несколько классификаторов и выберем наилучший, а так же длину серии паттерна и окно.
Градиентный бустинг с возможным перебором по длине серии и окну (в хорошей модели с увеличением числа деревьев точность должна расти, поэтому надо выбрать подходящую длину серии и окно):
# gradient boosting
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import KFold, cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
from PatternsCollector import get_patterns_for_window_and_num, get_x_y_for_patterns
import seaborn
nums = [2,5,10]
i = 0
wrange = [1,5,10]
lrange = [5,10]
values = list()
legends = list()
for wnd in wrange:
for l in lrange:
scores = []
patterns = get_patterns_for_window_and_num(wnd, l)
X, y = get_x_y_for_patterns(patterns, 'buy')
for n in nums:
i = i+1
kf = KFold(n_splits=5, shuffle=True, random_state=100)
model = GradientBoostingClassifier(n_estimators=n, random_state=100)
ms = cross_val_score(model, X, y, cv=kf, scoring='roc_auc')
scores.append(np.mean(ms))
print 'Calculated {0}-{1}, num={2}, {3:.3f}%'.format(wnd, l, n, 100 * i/float((len(nums)*len(wrange)*len(lrange))))
values.append(scores)
legends.append('{0}-{1}'.format(wnd, l))
plt.xlabel('estimators count')
plt.ylabel('accuracy')
for v in values:
plt.plot(nums, v)
plt.legend(legends)
plt.show()
Аналогично, линейная регрессия с настройкой параметров:
# logistic regression
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from PatternsCollector import get_patterns_for_window_and_num, get_x_y_for_patterns
from sklearn.model_selection import KFold, cross_val_score
import numpy as np
import matplotlib.pyplot as plt
import seaborn
cr = [10.0 ** i for i in range(-3, 1)]
i = 0
wrange = [1,5,10]
lrange = [5, 10]
values = list()
legends = list()
for wnd in wrange:
for l in lrange:
scores = []
patterns = get_patterns_for_window_and_num(wnd, l)
X, y = get_x_y_for_patterns(patterns, 'buy')
sc = StandardScaler()
X_sc = sc.fit_transform(X)
for c in cr:
i = i+1
kf = KFold(n_splits=5, shuffle=True, random_state=100)
model = LogisticRegression(C=c, random_state=100)
ms = cross_val_score(model, X_sc, y, cv=kf, scoring='roc_auc')
scores.append(np.mean(ms))
print 'Calculated {0}-{1}, C={2}, {3:.3f}%'.format(wnd, l, c, 100 * i/float((len(cr)*len(wrange)*len(lrange))))
values.append(scores)
legends.append('{0}-{1}'.format(wnd, l))
plt.xlabel('C value')
plt.ylabel('accuracy')
for v in values:
plt.plot(cr, v)
plt.legend(legends)
plt.show()

Как я уже говорил, условия неполные. Поэтому получаем точность всего 0.52. Но если вы их дополните, то точность будет лучше. Можете попробовать другие алгоритмы — нейросети, random forest и многие другие. Нужно не забыть про проблему переобучения — например, при большом числе деревьев в градиентном бустинге.
Проверка на ошибки в коде: если вместо реальных данных в БД взять от них sin(), то для обоих классификаторов AUC_ROC на кроссвалидации будет 0.96.
Торговый робот
В заключение предлагаю вам код торгового робота, который может ставить заявки как на demo счете, так и на реальном. Самое главное — при закрытии сделок он строит гистограмму профитов по сделке, основываясь на информации, полученной от брокера. То есть, вы реально сможете проверить, как работает ваша торговая стратегия.
import datetime
from datetime import datetime
from os import path
import matplotlib.pyplot as plt
import oandapyV20
import oandapyV20.endpoints.orders as orders
import oandapyV20.endpoints.positions as positions
from oandapyV20.contrib.requests import MarketOrderRequest
from oandapyV20.contrib.requests import TakeProfitDetails, StopLossDetails
from oandapyV20.endpoints.accounts import AccountDetails
from oandapyV20.endpoints.pricing import PricingInfo
from Conf.Config import Config
import seaborn
config = Config()
oanda = oandapyV20.API(environment=config.env, access_token = config.token)
pReq = PricingInfo(config.account_id, 'instruments='+config.insName)
asks = list()
bids = list()
long_time = datetime.now()
short_time = datetime.now()
if config.write_back_log:
f_back_log = open(path.relpath(config.back_log_path + '/' + config.insName + '_' + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))+'.log', 'a');
time = 0
times = list()
last_ask = 0
last_bid = 0
if config.write_back_log:
print 'Backlog file name:', f_back_log.name
f_back_log.write('DateTime,Instrument,ASK,BID,Price change,Status, Spread, Result \n')
def process_data(ask, bid, status):
global last_result
global last_ask
global last_bid
global long_time
global short_time
if status != 'tradeable':
print config.insName, 'is halted.'
return
asks.append(ask)
bids.append(bid)
times.append(time)
# --- begin strategy here ---
# --- end strategy here ---
if len(asks) > config.maxLength:
asks.pop(0)
if len(bids) > config.maxLength:
bids.pop(0)
if len(times) > config.maxLength:
times.pop(0)
if config.write_back_log:
f_back_log.write('%s,%s,%s,%s,%s,%s,%s \n' % (datetime.datetime.now(), config.insName, pReq.response.get('prices')[0].get('asks')[1].get('price'), pReq.response.get('prices')[0].get('bids')[1].get('price'), pChange, ask-bid, result))
def do_long(ask):
if config.take_profit_value!=0 or config.stop_loss_value!=0:
order = MarketOrderRequest(instrument=config.insName,
units=config.lot_size,
takeProfitOnFill=TakeProfitDetails(price=ask+config.take_profit_value).data,
stopLossOnFill=StopLossDetails(price=ask-config.stop_loss_value).data)
else:
order = MarketOrderRequest(instrument=config.insName,
units=config.lot_size)
r = orders.OrderCreate(config.account_id, data=order.data)
resp = oanda.request(r)
print resp
price = resp.get('orderFillTransaction').get('price')
print time, 's: BUY price =', price
return float(price)
def do_short(bid):
if config.take_profit_value!=0 or config.stop_loss_value!=0:
order = MarketOrderRequest(instrument=config.insName,
units=-config.lot_size,
takeProfitOnFill=TakeProfitDetails(price=bid+config.take_profit_value).data,
stopLossOnFill=StopLossDetails(price=bid-config.stop_loss_value).data)
else:
order = MarketOrderRequest(instrument=config.insName,
units=-config.lot_size)
r = orders.OrderCreate(config.account_id, data=order.data)
resp = oanda.request(r)
print resp
price = resp.get('orderFillTransaction').get('price')
print time, 's: SELL price =', price
return float(price)
def do_close_long():
try:
r = positions.PositionClose(config.account_id, 'EUR_USD', {"longUnits": "ALL"})
resp = oanda.request(r)
print resp
pl = resp.get('longOrderFillTransaction').get('pl')
real_profits.append(float(pl))
print time, 's: Closed. Profit = ', pl, ' price = ', resp.get('longOrderFillTransaction').get('price')
except:
print 'No long units to close'
def do_close_short():
try:
r = positions.PositionClose(config.account_id, 'EUR_USD', {"shortUnits": "ALL"})
resp = oanda.request(r)
print resp
pl = resp.get('shortOrderFillTransaction').get('tradesClosed')[0].get('realizedPL')
real_profits.append(float(pl))
print time, 's: Closed. Profit = ', pl, ' price = ', resp.get('shortOrderFillTransaction').get('price')
except:
print 'No short units to close'
def get_bal():
r = AccountDetails(config.account_id)
return oanda.request(r).get('account').get('balance')
plt.ion()
plt.grid(True)
do_close_long()
do_close_short()
real_profits = list()
while True:
try:
oanda.request(pReq)
ask = float(pReq.response.get('prices')[0].get('asks')[0].get('price'))
bid = float(pReq.response.get('prices')[0].get('bids')[0].get('price'))
status = pReq.response.get('prices')[0].get('status')
process_data(ask, bid, status)
plt.clf()
plt.subplot(1,2,1)
plt.plot(times, asks, color='red', label='ASK')
plt.plot(times, bids, color='blue', label='BID')
if last_ask!=0:
plt.axhline(last_ask, linestyle=':', color='red', label='curr ASK')
if last_bid!=0:
plt.axhline(last_bid, linestyle=':', color='blue', label='curr BID')
plt.xlabel('Time, s')
plt.ylabel('Price change')
plt.legend(loc='upper left')
plt.subplot(1, 2, 2)
plt.hist(real_profits, label='Profits')
plt.legend(loc='upper left')
plt.xlabel('Profits')
plt.ylabel('Counts')
plt.tight_layout()
except Exception as e:
print e
plt.pause(config.period)
time = time + config.period
Полный исходный код здесь.
Я надеюсь, что сэкономил время тем, кому интересен алготрейдинг. Ведь теперь для проверки Ваших идей вам нужно лишь немного поменять код, запустить робота и получить статистику по Вашим сделкам от брокера. И вы можете проанализировать почти любые биржевые данные.
Отдельное спасибо хочу сказать авторам курса от Яндекс по машинному обучению на Coursera. А так же Andrew Ng за замечательные лекции на этом же ресурсе.
UPDATE:
А вот что получается на градиентном бустинге по склееному фьючерсу SI с финама за последний год (если под критерием выбора паттерна понимать скачок цены на 1% в нужную сторону):

И это уже неплохой результат. Матожидание в плюс.
А тут как раз Альфа Директ выпустил новый серверный API :)
Комментарии (39)

prefrontalCortex
19.03.2017 14:25+1Необходим Python версии 2.7
Бог с вами, ещё бы Windows XP посоветовали использовать.

AntonioGrande
19.03.2017 14:26Берите любой, все равно пришлось все переделывать на мой любимый C#. Иначе очень все медленно. Питон хорош для описания модели и первичной ее проверки.
immaculate
19.03.2017 19:21Вообще, ваш код Python сильно от C# не отличается, по крайней мере с визуально-эстетической точки зрения. :)

bioroot
19.03.2017 18:10В целом интересно, но мне кажется, что прототипировать можно быстрее. В Forex Club отдают архив с данными по валютной паре с точностью до минуты. PostgreSQL отлично умеет перелопачивать данные в одной табличке и переливать результат в другую. Теоретически, туда даже можно подтыкать Python, но мне всегда хватало PL/pgSQL. К этому безобразию можно добавить RapidMiner (правда, в бесплатной версии ограничение на 10000 примеров в выборке). В результате за пару вечеров ленивого тыкания удалось получить множество разнообразных способов подбрасывания монетки.)
Ivan22
20.03.2017 09:54+1подскажите алгоритм линейной регресии для pg/plSQL.
p.s. И логистической регрессии тоже.
Заранее спасибоbioroot
20.03.2017 14:06К сожалению, не подскажу, т.к. никогда не решал подобные задачи на уровне базы. Тут как раз разумнее было бы использовать PL/Py или PL/R. Я на уровне базы делал предварительную обработку данных, с получением средних значений, локальных максимумов и минимумов, разброса и тому подобного со скользящим окном. Потом уже из таблички причёсанных и дополненных данных делал выборку в RapidMiner и гонял их через разные модели от kNN до нейронных сетей. Как и писал выше, получил много разных способов подбрасывания монетки.
amaksr
19.03.2017 18:29Нет смысла проверять стратегию через счет брокера, так как очень долго нужно ждать данных для статистически надежного подтверждения или опровержения. Гораздо проще и быстрее будет прогнать ее на тех же исторических данных, но за более поздний (по сравнению с обучением) период. Счет у брокера вообще на этом этапе не нужен.
AntonioGrande
19.03.2017 19:06Нет смысла проверять стратегию через счет брокера, так как очень долго нужно ждать данных для статистически надежного подтверждения или опровержения. Гораздо проще и быстрее будет прогнать ее на тех же исторических данных, но за более поздний (по сравнению с обучением) период. Счет у брокера вообще на этом этапе не нужен.
Как показывает опыт, это не работает. Сколько есть стратегий, прекрасно работающих на исторических данных за более поздний срок, но не работающих на реальном рынке.
AntonioGrande
19.03.2017 19:52Добавлю, что на более поздних (относительно обучения) данных проверять алгоритм нужно, конечно же, в первую очередь. А потом у брокера.

mezastel
19.03.2017 22:21+1Я еще никогда не видел систематизируемых паттерном на графике цены одного отдельно взятого инструмента (о сотона, почему опять FX?). Зато подобные эффекты порой просматриваются в микроструктуре, т.е. в поведении участников на краях стакана. Но даже там против маркетмейкеров мало что можно сделать — разве что немного выкусывать у них маржу.

Zoomerman
19.03.2017 23:47+8Три года посвятил изучению такой методики алготрейдинга…
Поверьте, тут рыбы нет!..
Факторов, влияющих на котировки в разы больше, чем предоставляют брокеры.
А обучение на основе частичных знаний ни к чему полезному не приводит.dshap
21.03.2017 15:41+1Могу добавить, что у дирекционных алгоритмов при систематической торговле в текущих рыночных реалиях очень мало перспектив. Максимум, можно получить небольшой перевес на коротком промежутке времени.
Ol5xHd
21.03.2017 17:23А где, как вы считаете рыба есть? Есть способ покорить рынок?
dshap
21.03.2017 20:14Ну если, скажем, 10% годовых для вас приемлемый результат, то, варианты, конечно, есть. Вообще, на рынках довольно много нерегулярностей, но в деньгах, это может быть не очень много. И главное понять где, и в каких случаях, другие игроки рынка будут готовы отдать вам свои деньги. К теме статьи это, правда, никак не относится.
mezastel
22.03.2017 16:48Один способ покорить рынок — стать маркетмейкером. Сразу льготные условия от биржы (дисконт или бесплатные транзакции, возможность открытия двунаправленных позиция, итп) и маржа течет в карман. Смотрите Robot Panda например. Но если серьезно, конкуренция бешеная.
Финансовая инженерия — это наука, ей нужно долго учиться чтобы хоть копеечку вынуть с рынка.

konstando
21.03.2017 17:23А кто сказал, что будет легко?
Если модель плохо описывает реальный рынок, это проблема модели. Значит её нужно модернизировать.
Люди торгуют же десятилетиями по паттернам руками. И вполне успешно.

ArtVol
21.03.2017 17:23Полностью с вами согласен. Форекса, как такового рынка вообще нет… Есть сделки между крупными мировыми банками, которые двигают цены… Где стакан котировок, где заявки… Ребят о каком вы АПИ говорите…
NumLock
22.03.2017 17:32Заниматься трейдингом по паттернам из прошлых торгов это шаманство. Это тоже самое что предсказание погоды по времени, когда люди на работу приходят.
Почему бы не привязать робота к внешним показателям из интернета? Например, к новостям из банков.AntonioGrande
22.03.2017 17:32Уже год работаем в этом направлении.
recovered_uranium
23.03.2017 03:52только учтите, что будете конкурировать с теми же банками, т.е. шансы на успех минимальные.
murdemon
22.03.2017 17:33А есть возможность в подобных системах использовать аналитику экспертов? (те если есть аналитика за прошлый период где 10 экспертов, каждый день проставляют от 0-10 возможность того что курс будет падать или расти) И учитывать эти данные в поиске паттернов? (результат в этом случаи должен быть более устойчивый) И где можно найти подобную аналитику?
AntonioGrande
22.03.2017 17:34Если есть такие данные, было бы очень интересно посмотреть.
recovered_uranium
23.03.2017 03:54широко известный факт, что аналитики транслируют статус кво с лагом. тут тоже рыбы нет)
recovered_uranium
22.03.2017 17:33Вы планируете заниматься трейдингом? Или это прикладная задача к изучению алгоритмов машинного обучения?

slonoslon
У такого применения кросс-валидации есть принципиальный недостаток. Оно игнорирует факт изменчивости рынка — в частности то, что паттерны не живут вечно. Когда мы проводим обучение скажем на данных за 2014 и 2016 годы, а тестирование на 2015 — получаем завышенную оценку качества предсказания. Более корректная методика — всегда проводить тестирование только на данных, более поздних относительно обучающего набора.
AntonioGrande
Абсолютно согласен.
AntonioGrande
Чтобы учесть факт изменчивости рынка нужно изменить пару строчек в коде, спасибо! очень правильная мысль, если предположить, что паттерны не существуют постоянно.
riky
вы же не один паттерны используете. а действия других игроков на бирже влияют на котировки.
чем больше людей находят и используют их тем быстрее они будут умирать.
особенно если паттерны найдены по одному алгоритму.
такая теория эволюции дарвина для биржи.
встает вопрос, есть ли смысл вообще тестировать на исторических данных? (уточню, на каком периоде есть смысл тестировать)