

Что ж, всё плохо. Немного забавно так говорить: на конференции (Web a Quebec) было много разговоров об удивительном будущем и вещах, возможных благодаря новым технологиям. О новых средствах и устройствах, которые должны сделать нашу жизнь проще. Мои знакомые знают, что у меня обычно очень циничный взгляд на технологии; лично я боюсь всех этих умных устройств, которые реагируют на мои слова, чем восхищались другие спикеры.
В основном потому, что чем больше времени я трачу на программирование и провожу в этой отрасли, тем больше узнаю, как всё работает изнутри, и тем меньше доверия всё это мне внушает. Я подобрал изображение для слайда. Это картина «Триумф смерти» Питера Брейгеля. В некоторой степени она раскрывает моё отношение к «умному дому».

Я хочу показать, что имея даже очень простое приложение, выглядящее очень и очень разумно, и показать множество проблем и потенциальных ошибок, которые могут скрываться в нём и неприятно удивлять нас. Я хочу продемонстрировать, что сложно чувствовать себя по-настоящему в безопасности, когда дело касается кода. Это будет страшная история!

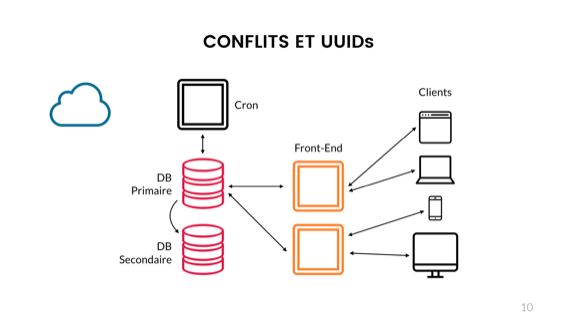
Чтобы раскрыть свою точку зрения, я начну с базового приложения, знакомого любому разработчику в этом зале. Здесь у меня маленькое веб-приложение. Справа — пользователи, они с помощью своих устройств подключаются к моему фронтенду, исполняющему код, написанный на некотором языке и отвечающий за логику приложения. Там происходит подключение к базе данных, где хранится информация. Далее — cron, он нужен для ряда фоновых задач, возможно, не особо сложных. Затем идёт облако, которое, вероятно, используется множеством других составляющих системы. Может быть, вы храните изображения в S3 или что-то ещё.
Итак, это разумное приложение, но в нём без труда найдутся проблемы: если какой-либо механизм выходит из строя — вся система перестаёт корректно функционировать. Вместо этого мы рассмотрим следующее:
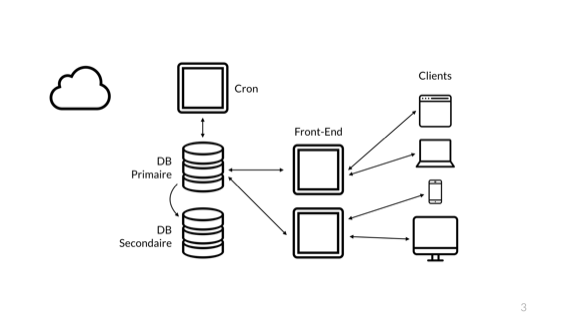
Такая схема безопаснее. Теперь у меня есть дополнительный фронт, и я могу подключать или отключать любой из них и по-прежнему оставаться доступным для клиентов. Второй узел базы данных даёт нам возможность аварийного переключения в случае возникновения проблем, но это не резервное решение. Достаточно всего одного человека, DROP TABLE users и репликацией в реальном времени, чтобы удалить таблицу «Пользователи» и потерять этот горячий резерв. Так что давайте скажем, что мы поступили разумно и создали резервную копию в этом облаке.
Таким образом, необходим только один сервер с cron, потому что асинхронные задачи можно решить и чуть позже. Так-то лучше. Наша архитектура достаточно надёжна и удобна, и теперь будем беспокоиться только о коде.

Вот несколько абстракций.
В левом верхнем углу вы видите структуры данных: деревья, карты, массивы, словари, наборы, списки и т. д. Они позволяют нам структурировать информацию во что-то большее, чем биты памяти. Очевидно, что это хорошо.
Дальше у нас идут идентификаторы. Я считаю их абстракциями. Они могут быть вашими автоинкрементными идентификаторами в базе данных, UUID или GUID, а также переменными, указателями, URL или URI. Они в основном позволяют ссылаться на элемент, часть данных или объект без необходимости его полного описания. Обычно идентификаторы связаны контекстом, который придает им смысл. Я могу сказать: «Ты Джон», и люди, которые знают конкретного Джона, будут иметь представление о том, кто такой Джон, основываясь на своём знакомом, на таких показателях, как его рост, профессия, возраст и т. д. Идентификаторы позволяют нам определить то, что поддерживает весь истинный элемент.
Тут у нас цифры. Никто из присутствующих здесь сегодня не может поднять руку и сказать, что он реализует свой собственный полусумматор в каждом своём проекте. Мы в основном просто используем напрямую цифры, а не биты, как раньше.
Внизу слева у нас сеть. Это всё просто абстракции. Ваши соединения, упорядоченные потоки данных, IP-адреса и номера портов (которые также являются идентификаторами!), пакеты и т. д. К счастью, мы не просто передаём электрические сигналы по кабелю.
Далее идёт время. И здесь я не буду его описывать. Философы, метафизики и учёные тысячелетиями спорили, чтобы приблизиться к тому, что мы сегодня понимаем под этим словом.
И далее у нас строки, формат для всего остального, что мы не знаем, как изобразить.
Каждый из этих важнейших инструментов необходим для того, чтобы мы могли работать и выполнять задачи без знаний о том, что десятилетиями создавалось наукой, математикой и техникой. Тем не менее, если мы не осознаем некоторые ограничения этих абстракций и используем их способами, которые противоречат фактическим свойствам абстракций, это может привести к необратимым последствиям.
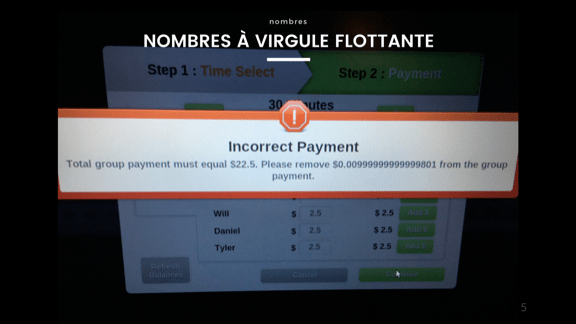
Начнём с простых чисел с плавающей запятой. Если вы когда-нибудь видели сумму 0,1 + 0,2, равную 0,30000000000000004, вы знаете, что это такое. Существует бесконечность чисел от 0,1 до 0,2, но у нас есть ограниченное количество байтов для их представления. Некоторые цифры не делятся нацело, и без работы с дробной частью будет очень сложно не потерять точность, когда компьютер начнёт подменять цифры, чтобы они приобрели смысл.
Возможно, вы встречали это при работе с деньгами. Хитрость вот в чём: не используйте числа с плавающей запятой, когда речь идёт о деньгах, если вы не хотите их потерять. Всегда берите наименьшую неделимую единицу, в которой нуждаетесь. Неважно, центы это, миллидоллары, пикодоллары или фемтодоллары — только не числа с плавающей запятой.
Я слышал об одном проекте, в котором банк пытался транслировать свои старые базы кода с помощью node.js. К несчастью для команды, никто не сказал им о том, что в JavaScript есть только числа с плавающей запятой, и команде пришлось отказаться от проекта.
Кстати говоря, языки с флоатами типа JavaScript имеют верхний предел точности целых чисел, в данном случае 253.
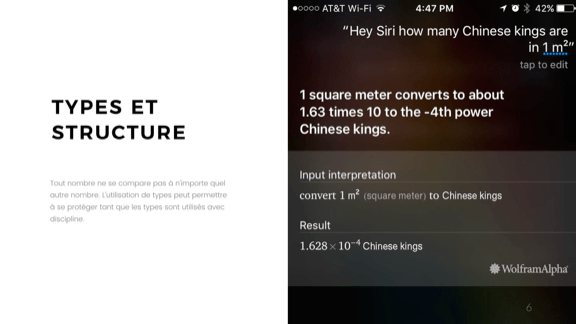
С целыми числами немного проще. Люди по большей части лучше понимают ограничения, что помогает. Но этого недостаточно: нужна правильная структура и тип использования, поскольку не все целые числа означают одно и то же. Вспомните о Mars Climate Orbiter, который потерпел неудачу, потому что одни части кода работали в имперских единицах, а другие — в метрической системе. Упс.
На изображении показан особый взгляд на эти запутанные единицы. Спросите Siri или Wolfram|Alpha, сколько китайских королей на одном квадратном метре, и вы получите 1,628 ? 10–4. Не совсем уверен, что это значит, но каждый раз это достоверно определяется.
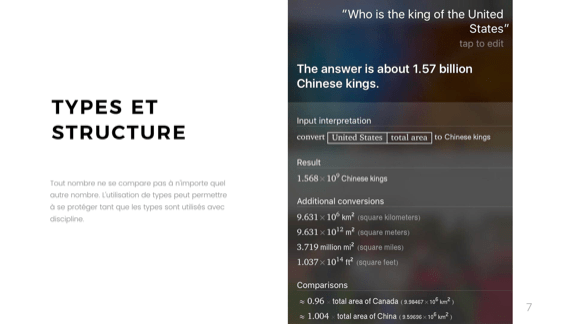
Ещё интереснее, когда добавляется языковая обработка. Я не понимаю почему, но на вопрос «Кто король Соединенных Штатов?» получаем ответ «1,57 миллиарда китайских королей».
Как правило, подобную ошибку довольно просто предотвратить. Будьте осторожны и, если имеете дело с системой причудливого типа, используйте её в полной мере. Не гонитесь за «целым» для всех своих типов; укажите, что представляют собой целые числа, какова их единица.
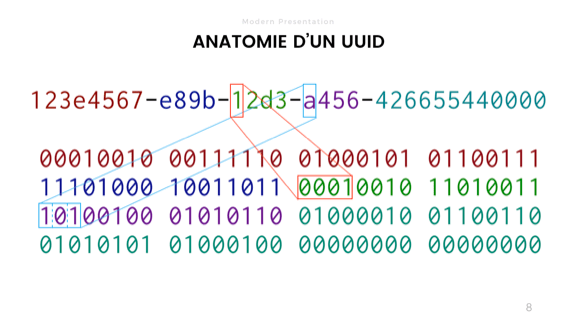
Допустим, что моё приложение отлично справляется со своей избыточностью и так же отлично справляется с манипуляцией цифрами. Возможно, у меня даже появились пользователи. Теперь мне необходимо обратить внимание на такую полезную вещь, как шардинг, или, может быть, я просто буду работать с внешними сервисами. В любом случае я, скорее всего, стану использовать UUID или GUID, поскольку они непредсказуемы и могут «гарантировать» уникальность.
UUID — это всего лишь группа битов, которые вы сравниваете. Если они все сошлись, то идентификатор прошёл проверку. Если нет, тогда он другой. Там множество разных вариантов, какие-то случайные, какие-то основаны на времени или адресе.
Как мы можем видеть, UUID — это то, что расположено на вершине слайда, с шестнадцатеричными числами, разделёнными дефисами. Это немного рискованно.

В зависимости от языка или стека, к которым вы прибегаете, у вас могут быть библиотеки, которые позволяют хранить UUID как двоичные блобы в памяти. Или же строки, где хранятся их абстрактные представления. В некоторых случаях вам придётся использовать строки в качестве промежуточного формата, например при передаче информации по различным системам, не поддерживающим необработанные двоичные данные, таким как SQL-запросы или JSON.
В этом заключается риск. По умолчанию у большинства строк в большинстве языков есть операторы сравнения, чувствительные к регистру. Значит, хотя эти три UUID идентичны в своём аутентичном двоичном представлении, они не будут сравниваться как равные строки. Чувствительность к регистру существует в любом случае и обязательно должна учитываться вашей системой, так как строковое представление не является идеальным абстрактом истинных свойств UUID.
И действительно, различные компоненты, не использующие одинаковое точное представление, могут стать серьёзной головной болью. Ваши пользователи, front-end, back-end, базы данных и облачные сервисы должны либо быть нечувствительными к регистру, либо не противоречить общему представлению.
Для определённых языков требуются особые библиотеки, одна часть которых всё сделает правильно, а от другой нельзя ждать того же. Базы данных могут быть сложными:
- Используя PostgreSQL, вы получаете нечувствительное к регистру сравнение, но представление в нижнем регистре.
- MySQL поддерживает создание UUID верхнего регистра, но не имеет формата хранения для них. Рекомендуется выбирать чувствительный к регистру VARCHAR.
- MSSQL может хранить GUID, но подходит для представления в верхнем регистре.
- Oracle может хранить необработанные данные, так что здесь не должно возникнуть проблем.
- Redis не поддерживает UUID, и, скорее всего, вам придётся использовать строку с учётом регистра.
- MongoDB всё делает правильно, с двоичным представлением.
Тем не менее даже если вы со своей стороны делаете всё безошибочно, нет никакой гарантии, что система будет работать. Достаточно всего одной подсистемы, чтобы всё разрушить. Например, внешние службы, такие как некоторые сервисы Amazon, имеют множество различных предложений, которые не всегда согласуются друг с другом (например, DynamoDB и SimpleDB чувствительны к регистру, поэтому третий сервис AWS, основывающийся на них, скорее всего, унаследует эти свойства). Если подобное произойдёт с вами, если вы, скажем, используете PostgreSQL локально и храните UUID в качестве UUID, то ничего хорошего из этого не выйдет. Теоретически объекты могут начать конфликтовать друг с другом или просто исчезнуть, поскольку ваше локальное представление нижнего регистра не существует для сервиса верхнего регистра.
Любая часть системы, действующая не так, как остальные, может вызвать проблемы. Вам придётся хранить канонический UUID (для сравнения) с его строчной копией (для его исходной версии) или изучать, как каждый сервис хранит материал. Не очень весело.

Однако сравнение строк может привести к большим неприятностям. Ещё одно интересное свойство сравниваемых строк (не только строк, но также большинства массивов и структур данных) заключается в вашем желании, чтобы операция проходила как можно быстрее.
Если я сравниваю хеши паролей, причём самый верхний из них — правильный, а второй и третий — это другие попытки, то, когда мой оператор '==' достигает разницы, он обнуляется и выдаёт false.
Это интересно, потому что продолжительность вычисления — это информация. В области безопасности и криптографии мы стремимся скрыть как можно больше информации. Взломщик может отправить множество запросов с различными предположениями, а затем посмотреть, сколько времени занимает обработка, и понять, насколько предполагаемый ответ близок к решению. Это может привести к утечке информации о значении хеша, взломщик способен предложить новые варианты, основываясь на времени.
Собственно говоря, это атака по времени. Хотя существует гораздо больше их разновидностей.

Эту проблему можно решить, заменив оператор сравнения строгой дизъюнкцией. Установите значение false, а затем проведите побитное или побайтное сравнение с XOR. Каждый раз, когда оба значения одинаковы, выдаётся 0 (false), и каждый раз, когда значения отличаются, выдаётся 1 (true). ИЛИ приводит к исходному значению, и если в итоге это не 0, то вы знаете, что есть разница.
По-прежнему необходимо быть осторожными. Нужно удостовериться, что не происходит утечки информации о количестве данных и что определённые оптимизации не причиняют вам вреда. Хорошие криптографические библиотеки делают это в любом случае. Используйте bcrypt или scrypt, и с паролями не возникнет проблем, но чем больше вы знаете, тем лучше.
Забавно, что иногда криптография требует, чтобы всё происходило как можно медленнее с точки зрения дизайна, но как можно быстрее в реализации, поскольку это предотвращает брутфорс-атаки.

Конечно, некоторые устройства принимают это слишком близко к сердцу, и их медлительность на самом деле необязательна!
Итак, у нас есть это замечательное приложение. Теперь оно прекрасно справляется с избыточностью, целыми числами, плавающими запятыми, UUID и паролями. У меня появляется намного больше пользователей, и производительность относительно времени отклика начинает снижаться. Из сообщений в блоге я узнал, что теряю важный процент пользователей, не получающих ответ каждую десятую секунду потраченного времени. Это сигнал к действию!
Некоторые операции длятся дольше и тормозят остальные. Как правило, по-настоящему трудно предугадать, что это может быть, и пиковые времена раздражают. Кому-то из команды приходит в голову идея, которая поможет решить все проблемы. Что это за идея?
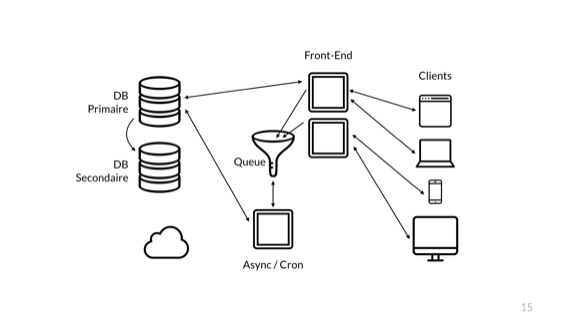
Придерживаться очереди! Внешний сервер просто отправляет простые короткие запросы в БД напрямую, а все сложные, требующие времени идут в очередь. Данные принимаются в очередь без обработки, и я могу быстро вернуть результаты пользователям.
И что же? Все мои действия возвращены. Чёрт, это даже быстрее, чем раньше!
Тем не менее есть некоторая проблема.
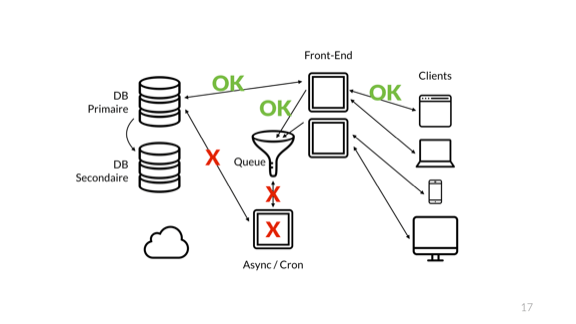
Когда мы добавили очередь, произошла интересная вещь: прекратилась передача общего состояния системы на внешний сервер. Если раньше благодаря возвращению результата от сквозной операции пользователи системы могли видеть, обработаны ли все их запросы, то внедрение очереди разрушило эту концепцию.
Сейчас внешний сервер позволяет нам узнать только о наличии прямых соединений. Мы не имеем понятия о потребителе очереди, асинхронном сервере, его способности взаимодействовать с базой данных или с самой асинхронной очередью.
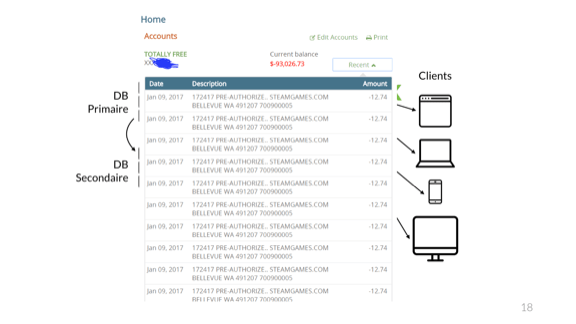
На самом деле, если работа не выполняется тщательно, события могут повторяться. Вот пользователь Reddit, который приобрёл игру за 12,74 доллара. Он купил её однократно, но получил запрос об оплате множество раз, пока на его банковском счёте не образовалось превышение кредита в –93 тыс. долларов.
Конечно, нет никакой гарантии, что эта проблема вызвана именно очередью, но очень похоже на то. Когда что-то идёт не так и сквозной поток данных загадочными способами разбивается, последствия обычно крайне заметны.
Но это ещё не всё. Причина, из-за которой моё приложение стало медленно работать: оно было перегружено. Так что сейчас я полностью отделил воспринимаемую производительность от фактической нагрузки в системе.
Независимо от того, насколько всё плохо в бэкенде, производительность фронтенда не изменяется. Эта схема работает в случае временной перегрузки для некоторых крупных операций, но не оправдывает себя, когда дело касается долгосрочной стабильности. Контролируя производительность фронтенда, мы, по сути, наблюдали за всей системой. Если разделить её на две части, мой мониторинг показывает не только работоспособность, но и производительность лишь половины системы.
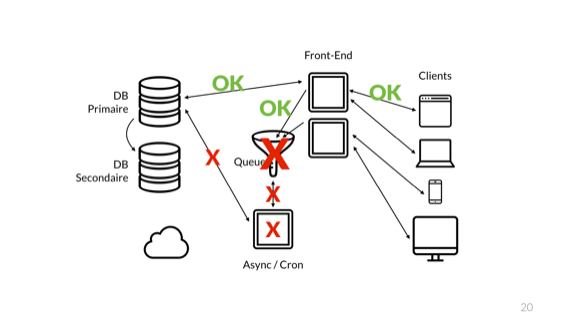
В итоге очередь переполняется и вылетает. Конечно, выходит из строя не только она.

Ошибка добирается до интерфейсных узлов, и в итоге мы получаем катастрофические сбои.
Как же нам быть? Кто-нибудь устраивает собрание, говорит, что такое недопустимо. И что делают разработчики?
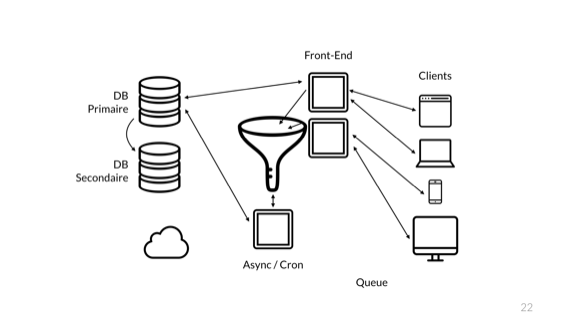
Увеличивают очередь. Но это ещё не всё. Так как во время аварии все данные в очереди были потеряны, все участники собрания также соглашаются сделать её постоянной. Это её замедляет, и, поскольку мы любим избыточность, почему бы не добавить ещё одну очередь?
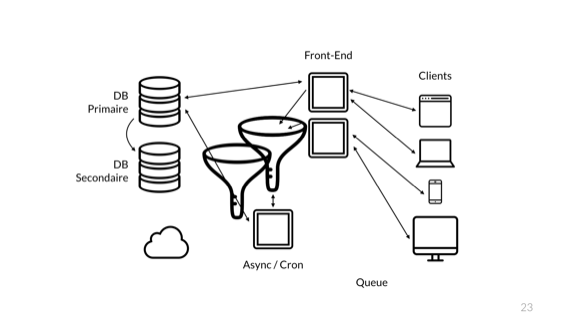
В следующий раз, когда произойдёт ошибка, мы сможем сделать то же самое.
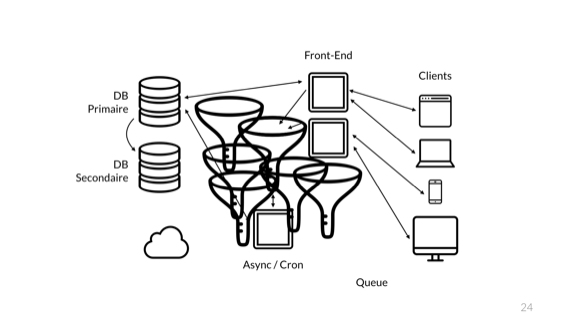
Все эти очереди — хорошее решение. Но мы крутая крупная компания, и поэтому нам нужна технология следующего поколения. Все мы знаем, что эта архитектурная схема ужасна. Итак, мы внедряем нечто особенное...
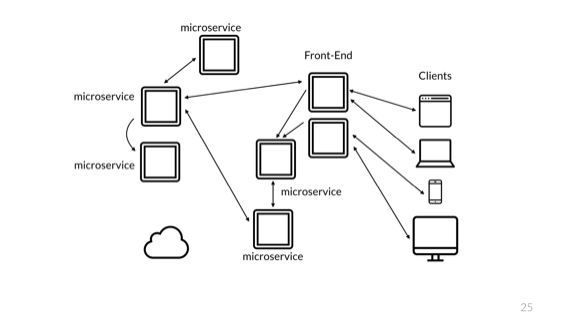
И это микросервисы!
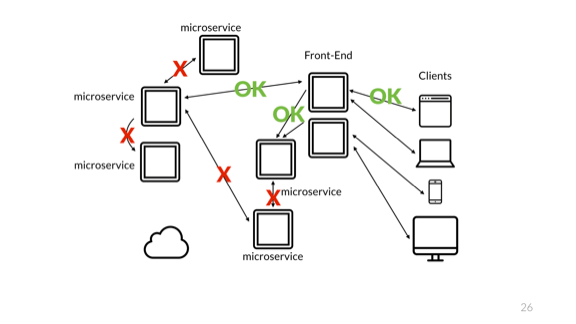
Конечно, проблема всё та же. Сложность по-прежнему связана с мониторингом только части системы. Подобные изменения в архитектуре должны быть незаметны для пользователей, но они оказывают очень важное влияние на поддержание и эксплуатацию системы.
Объединение пользователя и оператора или исключение одного из них — убийственная ошибка для вашего проекта. Операции становятся очень сложными.
Конечно, это ещё не всё! Все наши компоненты должны уметь взаимодействовать друг с другом.
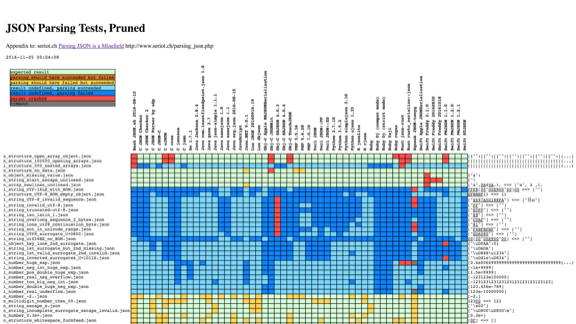
Мы могли бы выбрать что-то вроде JSON. Это диаграмма из seriot.ch, отслеживающая около 50 реализаций библиотек JSON на более чем десяти языках.
Почти каждая из них обрабатывает информацию по-своему.

Это не очень хорошо.
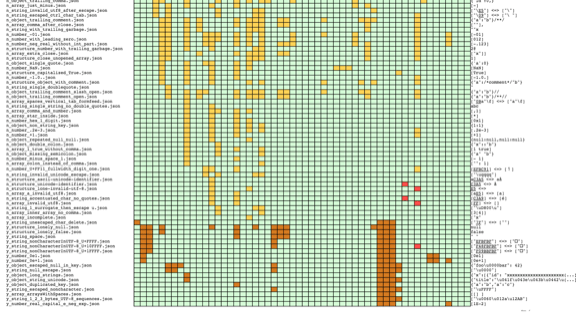
Стандарт JSON очень мал, но это, вероятно, означает, что он предоставляет пространство для интерпретации и, следовательно, для особого нестандартного поведения.
Самое интересное: если запустить несколько микросервисов и отправить всем им одинаково тщательно обработанный набор данных, это может привести к противоречивому поведению. Возьмём, к примеру, неверный JSON со множеством одинаковых ключей, имеющих разные значения. Скажем, у меня есть объект «человек», где атрибут «имя» появляется дважды, первый раз это «Марк», второй раз — «Джон».
Скорее всего, анализатор поведёт себя одним из трех способов:
- Откажется от разбора записи, как и должно быть.
- Сохранит первое имя (Марк).
- Сохранит второе имя (Джон).
Выбор последних двух способов зависит от порядка анализа (с использованием стека или по очереди).
Предположим, у меня есть три сервиса, у каждого из них — своя версия поведения. Тогда один сервис остановится и откажется обрабатывать запись, а два остальных увидят разные значения для одного и того же объекта. Необходимо обращаться с ними с осторожностью.
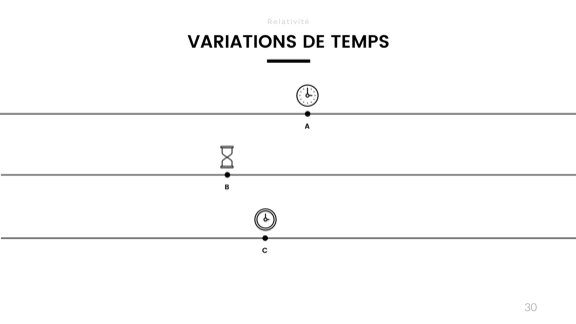
Ещё одна проблема связана со временем. Различные часы работают на разных скоростях. В прошлом году я проводил эксперимент для презентации по календарям (нет, не смейтесь, календари на самом деле очень интересны), во время которого я отключил синхронизацию часов на своём компьютере. Затем я проделал то же самое с духовкой и микроволновой печью, чтобы посмотреть, где будет наибольшее отклонение. Где-то через три-четыре недели время на микроволновке сдвинулось примерно на 3 минуты, на ноутбуке — примерно на 2 минуты и 16 секунд, а на духовке — не изменилось.
Часы отклоняются в зависимости от аппаратного обеспечения, температуры, напряжения, влажности и т. д. Они не могут оставаться точными долгое время.
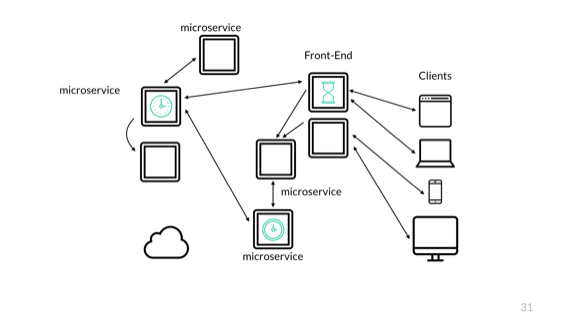
Значит, без синхронизации временные метки для одного и того же события могут разделиться и привести к разрозненным результатам. Чтобы этого избежать, необходим NTP. Вы можете мониторить время и проследить, что его отклонение незначительно. И тем не менее для событий, которые происходят очень быстро, даже у NTP может появиться достаточно способов, чтобы вызвать проблемы.
И это случается даже на одном устройстве. На прошлой работе мы как-то сломали кластер Hadoop. Вышло так, что мы запускали быстрые торги по миллисекундной шкале и отмечали время в двух точках: при получении запроса и при завершении торгов. Затем мы могли бы использовать эти данные для регистрации события и рассчитать разницу во времени, чтобы узнать, сколько длится вся обработка.
В судьбоносный день, когда транзакция выполнялась особенно быстро, NTP-синхронизация компьютерных часов привела к отклонению на какие-то доли секунды: вполне достаточно, чтобы поставить вторую временную метку перед первой. Для полного счастья это случилось примерно в полночь в последний день месяца или в какой-то другой оборот цикла.
События закончились за день до того, как начались, что очень смутило кластер, который просто упал на явно мусорных данных.
Хитрость здесь состоит в том, чтобы создать значительное различие между монотонным и системным временем.
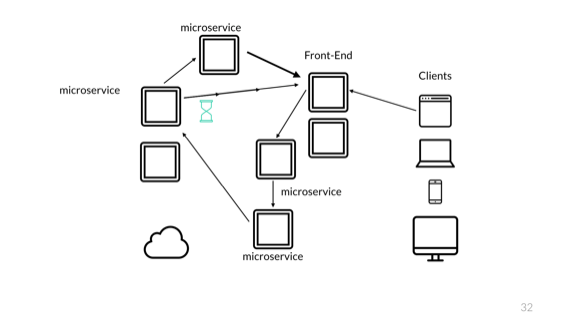
Но это ещё не всё. Время всегда порождает проблемы. Работая с подобными системами, мы можем получить совершенно разные логические окончания.
В данном случае клиент может отправить запрос, который переведёт его на первый сервис, затем на второй и на третий. Допустим, сервис подтверждает покупку товара и пересылает уведомление об этом в интерфейс. После третий сервис сразу же отправляет заказ на четвёртый сервис, который, скажем, подтверждает доставку или что-нибудь в этом роде. Он также отправляет уведомление в интерфейс.
На этой стадии благодаря сетевым задержкам в интерфейс может поступить информация о том, что отправка происходит до подтверждения покупки.
Если вы фронтенд-разработчик, вы способны предвидеть такие события и справиться с ними должным образом. Если вместо этого одни и те же события попадают в какую-либо аудиторскую систему, она вполне может принять их за ошибку, поднять тревогу, отменить отправку и т. д. Кто знает, какие ужасы произойдут.
Тогда необходимо использовать логическое время для отслеживания причинности, вместо того чтобы считать его безусловным, но это слишком обширная тема, чтобы говорить о ней здесь.
На самом деле логические ошибки весьма забавны. Они позволяют нам совершать путешествия во времени.

Но это ещё не всё. Присутствующие здесь наверняка знакомы с часовыми поясами. Но кто-нибудь здесь слышал про пояса в полчаса?
(Большинство людей поднимают руки.)
Да, такой пояс расположен в Ньюфаундленде. Это внутри страны, хорошо, что вы знаете.
Но опять же, кто знает о существовании часового пояса в четверть часа? Подобный находился в Новой Зеландии. Или что в Либерии был зафиксирован 44-минутный? Может быть, некоторые здесь слышали, что в 1927 году в часовых поясах в Китае произошли отклонения в пять минут и несколько секунд?
Но и это ещё не всё. Не всегда изменения в часовых поясах незначительны. Например, острова Самоа существуют между UTC –11 и UTC +13, полностью переключая дни. Хитрость в том, что они находятся на линии изменения даты. В 1892 году острова решили согласовать свои календари с США, исходя из рыночных соображений. В том году у них дважды было 4 июля. Первое июля, второе июля, третье июля, четвёртое июля, четвёртое июля, пятое июля...
И опять же в 2011 году (совсем недавно!) они согласовали календари с Китаем, и на этот раз на островах Самоа не было 31 декабря.
К тому же существует летнее время. Если вы знакомы с бразильскими сисадминами, вы, возможно, слышали о таком забавном факте (я не знаю, делают ли они так до сих пор), что каждый регион/провинция/штат в Бразилии ежегодно голосует за то, будут ли они придерживаться DST. Невозможно узнать заранее, надо ли обновлять файлы часовых поясов.
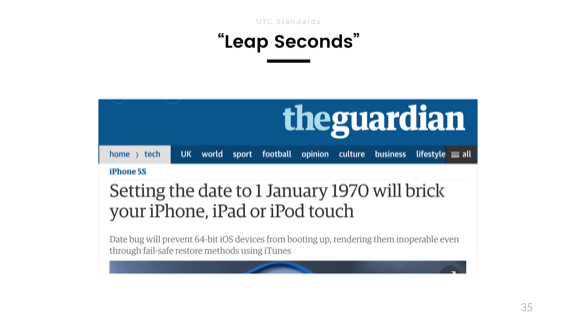
Далее, високосные секунды. Проблемы часовых поясов решит просто UTC. Но это имеет весьма интересные последствия, поскольку каждый тип всё ещё использует временные метки UNIX и свободно конвертируется между UTC и эпохой UNIX, которая начинается 1 января 1970 года.
Это связано с тем, что UTC учитывает високосные секунды, которые часто корректируются: добавляются или удаляются, основываясь на вращении по земной орбите, чтобы синхронизировать часы с реальным миром. С 1970 года мы находимся в сети 27-секундных смещений. Эпоха UNIX в наших системах не учитывает эти секунды.
Изображение, которое вы можете видеть на слайде, появилось пару лет назад из-за ошибки в iPhone, в результате которой перемотка даты на телефоне до 1 января 1970 года приводила к его поломке. Устройство считало программное обеспечение недействительным и отказывалось что-либо воспроизводить. В результате в руках оказывался девайс, который было невозможно ни отремонтировать, ни перезагрузить.
Моё личное предположение, почему это произошло (и я надеюсь, что я прав), связано с несоответствием временных представлений. Если вы используете целое число без знака — опять эти надоедливые целые числа — для представления времени, начинающегося 1 января 1970 года, в качестве эпохи, но с помощью преобразования UTC для установки даты и времени, вы получите 27, что невозможно считать целым числом без знака. Вместо желаемого результата произойдёт потеря значимости. При 32 битах устройство выдаст нам 2106 год, которого может просто не существовать в данном программном обеспечении, и это опять приведёт к поломке.

Но это ещё не всё. Далеко не всё. Здесь, в Квебеке и Северной Америке, мы используем григорианское время. Кто-нибудь из присутствующих допускал ошибки в коде, связанные с високосными годами? (Многие поднимают руки.)
Не так уж и много. Существует множество действующих календарей, имеющих правовой статус, и ещё больше — служащих для культурных целей:
- Бенгальский календарь. Солнечный, разделён на шесть сезонов по два месяца в каждом.
- Китайский календарь. Довольно запутанный лунно-солнечный календарь. Официально используется в Китае (где живёт более миллиарда человек) наряду с григорианским.
- Эфиопский календарь. Косвенно происходит от старого египетского, первого солнечного календаря, который у нас есть. Технически его високосные дни не являются частью каждого месяца. Полночь в стране начинается тогда, когда в соседних странах шесть часов утра. Местные жители гордится тем, что Эфиопию никогда не колонизировали, поэтому они, как правило, не заинтересованы в принятии других систем.
- Еврейский календарь. Один из самых старых. Одновременно и лунный, и солнечный. В нём самые сложные правила, связанные с выбором дат, которые я когда-либо видел. Простые правила выбора первого дня года могут занимать несколько страниц. Он официально используется в Израиле и имеет тот же статус, что и григорианский календарь.
- Индуистский календарь, также очень сложный для меня. Он использует как солнечные, так и лунные циклы. Интересно, что в зависимости от региона в качестве начала цикла принимается новолуние или полнолуние, поэтому в одной и той же стране один и тот же календарь даёт два разных набора дат. В совокупности с жителями Индии мы близки к трети мирового населения, которое довольно часто пользуется негригорианскими календарями.
- Также существует персидский календарь, особенности которого я сейчас не очень хорошо помню.
- И наконец, исламский календарь, который используется в Саудовской Аравии официально, а в других странах — в культурных или религиозных целях. Интересно, что он основан на наблюдениях. То есть каждый новый лунный цикл какой-то уполномоченный человек должен выйти, посмотреть на небо и сказать: «Это новолуние, у нас официально новый месяц». Раньше, когда этот календарь использовался во многих странах, месяцы могли начинаться с разных дат, поскольку в зависимости от местоположения наблюдения отличаются.
Так что да. Здесь нужно многое иметь в виду. Давайте оставим всё это сложное время и пойдём дальше.
О нет. Юникод. Осмелюсь предположить: многие в этом зале сталкивались с тем, что различные системы коверкали ваши имена. Поднимите руки. (Более половины зала поднимают руки.)
Да. Стало быть, вы знаете, как это происходит. Проблема заключается в конфликте кодировки между Latin-1 (или ISO-8859-1) и UTF-8.

Выходит так, что в нижних символах UTF-8 и ISO-8859-1 абсолютно одинаковы, а самые нижние символы разделены с ASCII.
Поэтому для получения одной и той же кодировки нам необходимо настроить каждый шаг. Сначала пользователь, затем передача данных с помощью HTTP (включая надоедливые метатеги), сами экземпляры, затем языки программирования (некоторые функции по своей сути не являются UTF-8), далее соединение с базой данных (поскольку SQL основан на тексте, он чувствителен к кодировке), а затем и сама база данных. Если вам повезёт, то ваша БД также позволит настроить конфигурацию для таблицы и для столбца.
На любом из этих шагов может произойти ошибка, и совершенно нереально определить, где именно. Данные полностью исказятся, и невозможно будет обойтись без человеческого вмешательства.

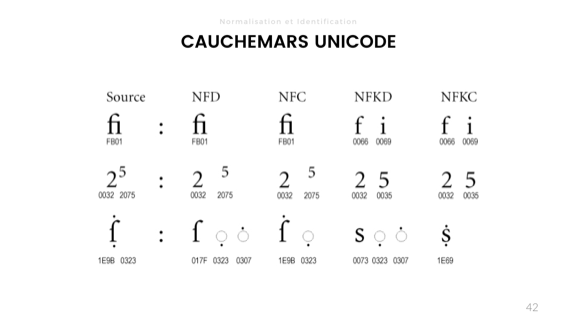
В Юникоде длина — это также переменная. Это можно объяснить четырьмя способами. Используем небольшую строку с а и лошадью в ней:
- Имеется длина в байтах, которая даёт нам 14 байтов в UTF-8, 12 в UTF-16 и 20 в UTF-32.
- В кодовой единице содержится длина, которая говорит о том, сколько комбинаций битов используется для каждой кодировки строки. В данном случае 14 для UTF-8, 6 для UTF-16 и 5 для UTF-32.
- Длина кода основана на количестве логических символов Юникода. У нас длина равна 5, так как второй символ здесь сделан с комбинированной меткой, придающей ему маленькую кривую сверху.
- Кроме того, есть кластеры графем, которые мы, люди, считаем символами. Мне нравится описывать это как «сколько раз нужно нажимать клавишу Delete, пока строка не станет пустой». Длина равна 4.
Длина может изменяться от языка к языку, когда речь заходит о кластерах графем, поэтому важна локализация.
Это весело. На прошлой работе мы один раз положили целый кластер на 40+ минут.
В бинарном протоколе требовалось указать длину сообщения в байтах, но одна из сторон указывала его в кодовых позициях(code points). Это продолжалось годами, пока мы не начали отправлять произвольные данные, передаваемые клиентами. Потребовалось около 30 секунд, чтобы кто-то ввел Юникод данные, которые десинхронизовали оба протокола и всё сломали.
Несмотря на то что мы сделали это оперативно, нам понадобилось ещё около трёх дней, чтобы решить проблему окончательно. Подходящее время для отпуска.
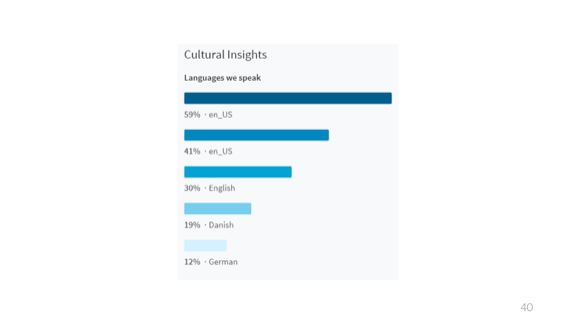
Этот опрос касается используемых языков. Не знаю, как были получены результаты, но мне они кажутся правильными.

А, как забавно. Я получил это в результате одной интересной ошибки Spotify, которая произошла несколько лет назад. Я не буду повторять, что я тогда сказал, а просто дам ссылку на сообщение в блоге.
На этом слайде объясняется нормализация Юникода. Он использовался в качестве поддержки ошибки Юникод в Spotify, так что вот ссылка на сообщение в блоге.

И теперь мы добрались до по-настоящему интересного материала! Безопасность! Это из статьи 2012 года «Самый опасный код в мире: проверка SSL-сертификатов вне браузера», которую я советую почитать.
Когда речь зашла о плохих абстракциях, дела с безопасностью обстояли хуже всего. Было обнаружено, что почти всё обследованное программное обеспечение, которое проверяло сертификаты (кроме веб-браузеров), делало это абсолютно неверно, что могло привести к атаке «человек посередине» и перехвату или изменению данных всего сеанса. Весёлые времена.

Вот хороший отрывок из библиотеки OpenSSL. С таким плохим интерфейсом многие люди пропустили критические этапы проверки.

И вот один о GnuTLS с таким же ужасным интерфейсом.

Но API cURL в PHP мой любимый. По умолчанию настройки правильные и корректные, но если вы прочтёте документ, то сможете установить для параметра CURLOPT_SSL_VERIFYHOST значение true. Проблема заключается в том, что в PHP (так же, как в C и C++) true — почти то же самое, что 1. Однако значение 1 для CURLOPT_SSL_VERIFYHOST отключает проверку. Правильное значение — 2.
Упс.

Итак, мы подошли к концепции class breaks, о которой я впервые узнал из блога Брюса Шнайера.
Идея состоит в том, что многие реальные физические системы слабы и легко ломаются. Замки на наших дверях, например. Существует множество способов их разрушить и проникнуть в дом, но каждая атака должна происходить независимо от других.
В случае с программным обеспечением у нас есть концепция class breaks, согласно которой слабое место может быть использовано для всего сразу. Это относительно новое и особенно страшное явление.

«Интернет вещей», который был воспринят как нечто поразительное на этой конференции, вызывает особое беспокойство. Реализации просто ужасны. Чем больше вы работаете с кодом, тем меньше вы верите в то, что разработчики IoT хорошо делают своё дело.
Бывают довольно интересные случаи. Например, автомобиль взломали и отправили в кювет (возможно, к этому причастна страховая компания, которая в стремлении уменьшить страховые выплаты была готова подключиться к автомобилю через сеть?), холодильники отправляют спам, устройства, подключённые к бот-сетям, роняют инфраструктуру и т. д.
Вот куда нас это привело. У нас было очень простое, на первый взгляд, приложение, но пронизанное потенциальными ошибками, о которых мы можем даже не подозревать. Тем не менее острые углы встречаются на каждом уровне системы. В чем заключается наша ответственность как разработчиков? Должны ли мы отвечать за то, о чём можем даже не знать?
Строительные нормы появились, вероятно, потому, что слишком многих людей раздавили собственные дома. На данный момент относительно небольшое количество пользователей погибло из-за плохого кода, но программное обеспечение уверенно поглощает мир. Код, который мы пишем, может оставаться где-то там на очень долгое время, намного дольше, чем нам хотелось бы. Он будет работать и после того как мы добавим некоторые быстрые исправления.
Применяем ли мы адекватные средства для обеспечения безопасности своих творений? Оставим ли мы всё как есть только потому, что ещё не убили достаточно людей? Может, мы все знаем о проблеме, но просто отрицаем свою личную ответственность, пока что-нибудь не заставит нас действовать как единое целое, чтобы добиться большего?
Я не знаю точно, но всё это очень страшно. Мне остаётся только надеяться, что я не из тех, кто в конечном счёте причинит достаточно вреда, чтобы потребовалось принимать законы. Может быть, все мы должны немного опасаться этого. Всё плохо, и в этом виноваты мы.
Комментарии (44)

Ugrum
25.04.2017 14:24+6Предлагаю тему для следующего поста:
«Как перестать бояться и начать жить.»
А то страху нагнали, аж жуть берёт (серьёзно).


vba
25.04.2017 14:51Tout n'est pas si terrible que cela
До интернета вещей, что бы улететь на машине в кювет достаточно было подержать свое рено меган под дождиком пару дней и вот на скорости 100 км в час ваша бортовая эвм выдает вам
Defaillance electroniqueвырубает мотор и вы летите в кювет из за того что не справились с поворотом.
Тема конечно требует особого внимания но паниковать уже поздно. Согласен, это скорее из оперы:
«Как перестать бояться и начать жить.»
FreeManOfPeace
25.04.2017 19:28Для возникновения такой проблемы и бортовой ЭВМ не обязательно.
У меня на машине банально трамблёр залило несмотря на защиту днища, залетающим под капот снегом, в результатате двигатель стал троить.
А в своё время на мотоцикле Ява после дождя двигатель стабильно начинал барахлить от отсыревания проводки при включении поворотника (что то в пульте видимо коротило).vba
25.04.2017 19:32+1Как там по закону Мерфи, если что то может пойти не так, то это обязательно пойдет не так.
f9k56
25.04.2017 14:52Отрицательный опыт развивает эффективнее положительного.
Dmitry_4
25.04.2017 19:29Не всегда. Напишем сайт, который ничего не делает, просто визитка. Но на 5 мегабайт. Кто-то скажет, что это плохо, а кому-то 'и так сойдет'. И это будет считаться положительным опытом — сайт-то сделан.

gag_fenix
25.04.2017 15:04Из оригинала:
On a fateful day, on a transaction that ran particularly fast, the NTP synchronization of the computer clock drifted it back by a few parts of a second, just enough to apparently allow the second timestamp to give a time prior to the first one.
Не очень понятно: ведь NTP по идее не должен откручивать часы назад, если они спешат, но разница небольшая. Он просто замедляет их. Или я не прав?arheops
25.04.2017 19:19Вы не правы, поскольку «небольшая» разница — неизвестно сколько. Раньше похожее было в dahdi asterisk.org. Просто вешался изза синхронизации. Проблема проявлялася раньше во весь рост в виртуальных контейнерах xen, позже xen немножко подкрутили это, стало чуть лучше. Но все равно проблема есть.
gag_fenix
25.04.2017 21:34неизвестно сколько
По умолчанию >128 мс http://doc.ntp.org/4.1.0/ntpd.htm
В случае автора (какие-то таймстампы с миллисекундной точностью) нужно было подкрутить настройки NTP, возможно вообще время получать от GPS+PPS.
hdfan2
25.04.2017 15:51+3В основном перевод ничего, но местами просто ужасен.
Бинарный протокол запросил длину байта по переданным ему данным, но одна из двух точек связи использовала длину кода для работы.
В бинарном протоколе требовалось указать длину сообщения в байтах, но одна из сторон указывала его в кодовых позициях (code points).
Когда дело дошло до плохих абстракций, безопасность оказалась на высоте. Она обнаружила, что почти всё обследованное программное обеспечение было вынуждено проверять сертификаты вне веб-браузеров. Это привело к критической ошибке, в результате которой могли быть пропущены атаки «человек посередине» и перехвачены или изменены данные всего сеанса.
Когда речь зашла о плохих абстракциях, дела с безопасностью обстояли хуже всего. Они [авторы упомянутой выше статьи] обнаружили, что почти всё обследованное программное обеспечение, которое проверяло сертификаты (кроме веб-браузеров), делало это абсолютно неверно, что могло привести к атаке «человек посередине» и перехвату или изменению данных всего сеанса.
С таким плохим интерфейсом многие люди пропустили критические биты проверки.
С таким плохим интерфейсом многие люди пропустили важнейшие этапы проверки.
AloneCoder
25.04.2017 17:01Спасибо, исправил! Будет здорово, если в следующий раз вы пришлете мне замечания в личку

AngReload
26.04.2017 10:43+2А мне больше нравится видеть публичную историю исправлений.

kafeman
26.04.2017 11:01Пишут в комментариях — получают минусы и просьбу писать в личку.
Пишут в личку — появляются те, кто хочет видеть «публичную историю исправлений».
Вроде за 10 лет существования Хабра уже определились, что такие комментарии с исправлениями быстро теряют свою актуальность и в дальнейшем мешают дискуссии. А если хотите следить за изменениями поста — то для этого есть специальные сайты.
vvzvlad
26.04.2017 15:14+1Если ошибка в одном слове, то смысла комментировать нет — ошибку может найти каждый, информация о ней несет мало смысла. А когда ошибка в куске перевода, и серьёзно изменяет смысл текста — информация о ней уже интересна, как сама по себе, так и как свидетельство уровня переводчика текста. Плюс — лишнее напоминание другим переводчикам "проверяйте тексты". Плюс ссылка на профиль того, кто исправляет — скорее всего у него в личке можно будет попросить консультацию по таким вопросам при переводе ещё одного текста.
Andrey_911
25.04.2017 16:45А я Очень хорошо понимаю автора этой статьи! И Полностью с ним согласен. Так-же как и он не доверяю ни технологиям «Умных домов» ни повсеместной автоматизации. Ибо Знаю, какие сбой… нет- Сбои могут иметь месть быть. И Не хочу жить в током «Умном доме». Пусть лучше в моем доме будет камин, который топится дровами. И электрогенератор, который запитывает лампочки и комп.
arheops
25.04.2017 19:22+1А у меня есть камин, который топится дровами. В прошлом году при совершенно обычной загрузке все тем же набором дров(с той же влажностью и типом) из партии в 4 метрических тонны он почемуто стрельнул угольками по 1-2см на 4 метра в другую стенку. Ночью, через 2 часа после загрузки.
Dmitry_4
25.04.2017 19:33+1Аналогично. Читая 'алгоритмы и структуры данных' Вирта, радуешься, какую же стройную систему смогли изобрести люди. И печалишься, глядя, во что её превратили сейчас...
Andrey_911
26.04.2017 09:39… и перефразируя Закон Мерфи- «Если что-то может пойти не правильно- оно пойдет не правильно.»
gag_fenix
25.04.2017 21:48Подождите, но без IoT зловещие корпорации не смогут собирать информацию, что у вас в холодильнике и как часто вы чихаете, чтобы показывать оптимизированную под ваши предпочтения рекламу.

Antelle
25.04.2017 22:22+2У вас, кажется, shift заело.
Andrey_911
26.04.2017 09:43Спасибо за беспокойство, но у меня «заел» не шифт. А Умный дом.
Antelle
26.04.2017 12:39Стало интересно. С холодильника пишете?
Andrey_911
26.04.2017 14:10-1Интерес- это похвально. Не, с холодильника писать не удобно. У меня он видимо не такой компактный, как у вас. С журнального столика пишу. Умного.

muon
26.04.2017 08:29+1Автор как будто объясняет жене, почему его уволили из программистов. Ну невозможно работать же!

AndreyDmitriev
26.04.2017 11:32Какой-то истерический крик души. Что с того, что «всё плохо»? Тыжпрограммист, ёлы палы, сделай хорошо!
Я в разработке ПО уже почти двадцать пять лет как и прошёл путь от ДВК (окей, DEC PDP-11) c 56 кБ памяти и 5 МБ жёстким диском до современных систем, так что могу окинуть взглядом технический прогресс за четверть века. У меня в общем-то нет никакой боязни перед «умными устройствами», но нет и никакой эйфории, связанной с ними. То, что мы наблюдаем — технический прогресс, который приводит к постоянно возрастающей сложности систем, причём сложность растёт едва ли не экспоненциально. Борьба с этой сложностью и постоянная подстройка под меняющиеся требования — это и есть суть работы программиста (и в этой безумной битве программист, как правило, всегда в проигрыше). Так было, есть и будет. Рождаются новые инструменты разработки, новые языки, новые методологии разработки, новые паттерны. Мы с каждой итерацией продвигаемся чуть дальше, и никто не сказал, что путь будет лёгким, но вот чтобы «всё плохо» — я так не считаю совершенно. Сейчас операционка RT11FB и ассемблер MACRO-11 кажутся мне простыми как пять копеек, а четверть века назад казались верхом совершенства. Впервые увидев Windows 3.1, я был едва ли не в шоке. На первую оконную программу я убил, наверное, неделю и тоже думал, что всё плохо. Пройдёт ещё четверть века и программисты 2050 года будут смотреть на нас нынешних, как на динозавров, и, наверное будут всё также бурчать, мол, всё плохо, опять этот полу-искуственный недо-интеллект, понимаешь, в проблеме не до конца разобрался.drafterleo
26.04.2017 11:51+1Если почитать внимательно, то в статье не только «истерический крик души», но и много прозрачных (и, главное, полезных) намёков на то, как сделать хорошо (или, по крайней мере, не оттяпать себе и другим голову клавиатурой). На мой взгляд, написано очень хорошо — много внятных иллюстраций и объяснений на пальцах критически важных вещей. А что до «эмоциональной тональности» текста — пусть это волнует разработчиков сентимент-анализа.
AndreyDmitriev
26.04.2017 12:09Да я с этим не спорю, но это всё просто текущие рабочие моменты, причём собранные в одну кучу. Начинается-то статья именно со слов «всё плохо», да и заканчивается в общем-то тем же. Впрочем оставим это сентимент-анализу, тут вы, пожалуй, правы. Я это к тому, что на самом деле в статье затронуты темы, по которым можно было бы написать три-четыре, если не больше, сугубо технических статей, описывающих текущие проблемы и способы их решения. А так — слишком поверхностно и всё в кучу — и NTP и юникод и JSON, и SSL до кучи.
michael_vostrikov
26.04.2017 14:43Некоторые цифры не делятся нацело, и без работы с дробной частью будет очень сложно не потерять точность
В двоичной системе все дробные числа периодические, кроме дробей со знаменателем, кратным 2. Не совсем очевидный факт, но в десятичной системе тоже все дроби периодические, кроме дробей со знаменателем, кратным 2 или 5. Просто используются обычно кратные, типа 0.1 и 0.2.
Если вы когда-нибудь видели сумму 0,1 + 0,2, равную 0,30000000000000004, вы знаете, что это такое.
Этой проблемы можно избежать, если ввести использование двоично-десятичнной арифметики с фиксированной точкой. Целая часть 32 бита, от 0 до 2^32-1, дробная часть 32 бита, показывает количество миллиардных долей. Можно двухмиллиардные сделать. Если больше, будут проблемы при сложении, а так можно в одной ячейке вычислять сумму и делать десятичную коррекцию с переносом. Для большинства стандартных вычислений этого хватит, для специализированных можно использовать отдельные библиотеки. Мне кажется, производительность будет выше, особенно в играх.
Тогда необходимо использовать логическое время для отслеживания причинности, вместо того чтобы считать его безусловным, но это слишком обширная тема, чтобы говорить о ней здесь.
Или монотонно возрастающий счетчик событий, у которых время просто дополнительный атрибут.

Livid
28.04.2017 19:38-1Какая-то невнятная истеричная простыня… Как обойти добрую половину перечисленных проблем, если не больше, учат на первом курсе даже в моей шараге. Если у них такая потрясающая квалификация разработчиков, что для них проблемы фиксированной запятой и отличие байт от символов (codepoint точнее) – новости… ну в общем да, у них все действительно плохо.
А их архитектору (если у них есть архитектор) надо оторвать руки от задницы и пришить к плечам. Потому что значительная часть приведенных схемок вызывает внутреннее содрогание. Х**к-х**к и в продакшен, да.
В общем я что-то не оценил. Старый уже наверное стал, прошло у меня это юношеское «все плохо».

NoRegrets
02.05.2017 21:54Небольшой оффтоп. Имхо, для больших статей, да и для небольших тоже, был бы весьма полезен конспект, который можно было открыть отдельно. Та же статья, в тезисном виде, максимум на один экран.
Возможно, что я ошибаюсь, но по моим наблюдениям, многие, увидев портянку текста, не читают ее, а 9 из 10 добавляющих статьи в закладки браузера, думающих «прочитаю позже», никогда больше эти вкладки не откроют. А потом, оценив количество закладок в браузере, они переходят к стратегии «найду и прочитаю, когда будет нужно». Хотя особо упоротые проходят перед этим еще одну стадию «оставлю вкладку со статьей открытой», набирая по 300 вкладок, которые живут у них до перезагрузки.muon
04.05.2017 07:21был бы весьма полезен конспект, который можно было открыть отдельно
Тогда будет так: читаем конспект — «всё понятно» — закрываем и не возвращаемся. Особенно если текст западного происхождения, где целая книга может быть вбиванием одной мысли.
sumanai
04.05.2017 15:44Тогда будет так: читаем конспект — «всё понятно» — закрываем и не возвращаемся
И это прекрасно- сплошная экономия времени.

Finesse
03.05.2017 01:51… но с помощью преобразования UTC для установки даты и времени, вы получите 27, что невозможно считать целым числом без знака.
Разве 27 это не целое число без знака?
sumanai
03.05.2017 15:34Неверный перевод. На самом деле там говорится о том, что UNIX Time не учитывает смещение в 27 коррекционных секунд в UTC, и если применить эту поправку к 1 января 1970 года в UNIX Time и хранить это число в без-знаковом типе, то получится -27, то есть переполнение и ошибка, что и наблюдалось на айфоне.

steamoor
03.05.2017 18:21Оригинал был на французском (canadian french), который автор потом перевёл на английский, не очень чисто. Потом этот текст перевели на русский.
Глухой телефон в действии.
Я конечно рад, что я могу читать некоторые переводы в оригинале, что я обычно и делаю. Но в этом случае даже английская версия читается с трудом.
DjOnline
04.05.2017 23:14>>Часы не могут оставаться точными долгое время.
Это конечно жесть в 21 веке.
dmitry_ch
Название у поста тоже плохое: через полгода по поиску не найти будет.
А уж тема — ух!
Godless
почему же: (через год)
— как же назывался пост где чел писал что все плохо?.. а. ну да.
dmitry_ch
«Не помню точно, кто писал и о чем, но такая там грусть была...»
Еще такого рода заголовки в СМИ сделать, и вообще будет — плохо.