
Автор этого доклада уже 12 лет является сотрудником Большого адронного коллайдера (БАК), а в прошлом году начал параллельно работать в Яндексе. В своей лекции Фёдор рассказывает об общих принципах работы БАК, целях исследований, объёмах данных и о том, как эти данные обрабатываются.
Под катом — расшифровка и основная часть слайдов.
Почему я взялся за доклад с удовольствием? Практически всю свою карьеру я занимаюсь экспериментальной физикой высоких энергий. Работал более чем на пяти различных детекторах, начиная с 90-х годов прошлого века, и это исключительно интересная захватывающая работа — исследовать, находиться на самом переднем крае изучения мироздания.
Эксперименты в физике высоких энергий всегда большие, эти эксперименты достаточно дорогие, каждый следующий шаг в познании делать непросто. В частности, поэтому за каждым экспериментом, как правило, стоит некая идея, что же мы хотим проверить? Как вы знаете, существует взаимоотношение между теорией и экспериментом, это цикл познавания мира. Мы что-то наблюдаем, мы пытаемся упорядочить наше понимание, представить некие модели. Хорошие модели обладают предсказательной силой, мы можем что-то предсказать, и мы опять проверяем это экспериментально. И постепенно, идя по спирали, на каждом витке мы узнаем нечто новое.
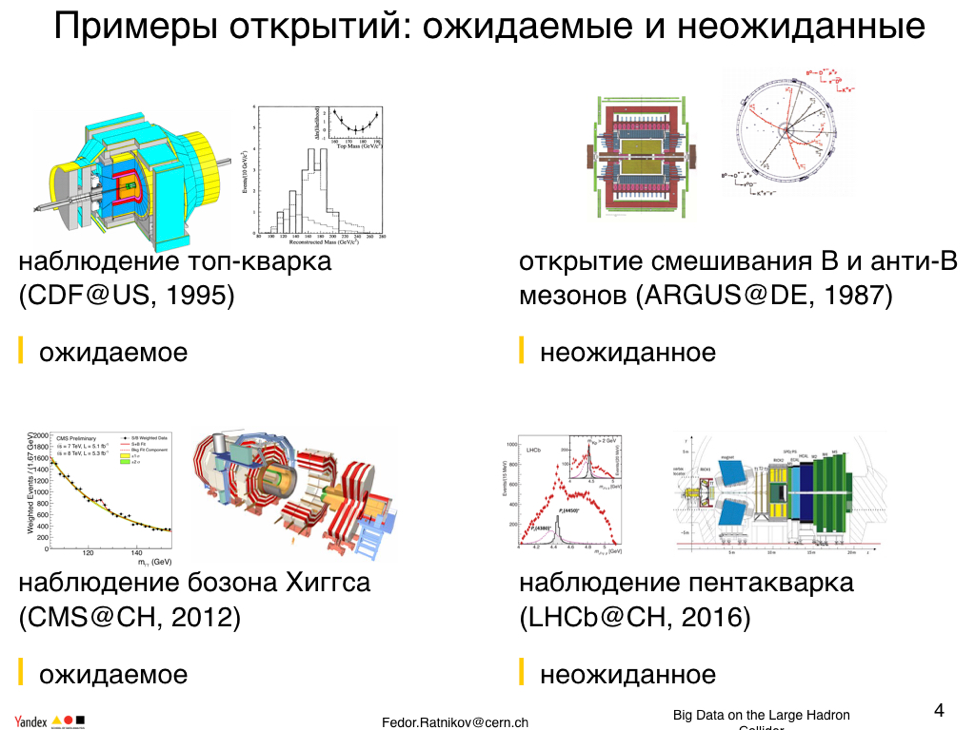
Эксперименты, в которых я работал, — как они делали открытия? Для чего, собственно, детекторы были построены? Например, детектор CDF на Тэватроне? Тэватрон был построен в первую очередь для открытия топ-кварка. Он был благополучно открыт. Кстати, именно при анализе данных топ-кварка на моей памяти впервые серьезно использовались данные анализа multi valued. По сути, еще тогда, так давно, работа строилась методом машинного обучения.
Другой эксперимент, где мне посчастливилось работать, это CMS на БАК. Физическая программа БАК была нацелена на три цели: Хиггс, суперсимметрия и кварк-глюонная плазма. Хиггс — это была цель номер один, которая была благополучно выполнена к 2012 году.
Когда мы набираем новые данные, мы ходим по неизвестной местности, мы обнаруживаем неожиданные вещи. Среди таких было открытие смешивания В-мезонов и анти-В-мезонов в прошлом веке, это несколько поменяло наше представление о стандартной модели. Это было абсолютно неожиданно.
В 2016 году эксперимент Херби наблюдал пентакварк, состояния такого типа наблюдались довольно давно, но каждый раз они рассасывались. На этот раз у меня есть ощущение, что тот объект, который наблюден, устоит. Действительно уникальный объект, это не барион, не мезон, а новое состояние материи.

Но мы все-таки поговорим про данные. На этом слайде я попытался представить, какое положение занимают данные физики высокой энергии в общей иерархии. В нынешнем мире данные правят миром, данные анализируют всюду. Эту картинку я утащил с Wired, но статистика дана на 2012 год. Каков поток данных набирается в различных сервисах? Далеко вперед с цифрой 3000 РВ вырывается вперед деловая переписка, писем мы все пишем много. На втором месте Facebook, что мы туда загружаем, котики, как ни странно, занимают второе место по объему, опережая серьезные задачи, которые, допустим, делает Google. На четвертом месте идет архив всех медицинских записей более-менее известных, которые используются для развития новых методик в медицине. И следующими идут данные БАК, порядка 15 РВ в код. На этом же уровне идут и данные с YouTube. То есть данные одного, пусть большого, но одного эксперимента конкретной области физики имеют мощность, сравнимую с самыми большими источниками данных.
Это означает, что поскольку мы не самые большие, то можем использовать передовой опыт и Google, и Facebook, и прочих промышленных сервисов. Тем не менее, у наших данных есть вполне специфические свойства, которые требуют серьезной адаптации имеющихся методов. Интересно заметить, что физика высоких энергий была драйвером компьютерных технологий с 60-х до 80-х, и тогда большие компьютерные мейнфреймы, системы хранения данных, делались именно под задачи физики высоких энергий.
После этого запретили ядерные испытания, и драйвером стало моделирование ядерных взрывов.

Зачем мы этим всем занимаемся? Владимир Игоревич примерно рассказал. Я на этой картинке попытался примерно обрисовать границу известного. По превалирующей сейчас теории, наша вселенная возникла в результате Большого взрыва, который произошел где-то 13 млрд лет назад. Вселенная возникла из сгустка энергии, который стал расширяться, там образовались частицы, они кластеризовались в атомы, в молекулы, в материю и так далее. На этой картинке изображена временная шкала того, что происходило во времена Большого взрыва.
Что происходит сейчас, когда образовались известные нам частицы — электроны, нейтроны, протоны? Мы более-менее понимаем физику этих процессов. Есть некая граница, которую я здесь изобразил и которая соответствует примерно временам 10-10 c, энергиям, достижимым на БАК сейчас. Это практически самая большая энергия, достижимая экспериментально. Это граница, за которой мы ничего четко сказать не можем. То, что находится по правую сторону при меньших энергиях, мы более-менее понимаем и проверили экспериментально. То, что находится по левую сторону… по этому поводу существуют различные теории и представления, разные ученые представляют это по-разному, и проверить это экспериментально, напрямую, довольно сложно.
Суть в том, что сегодня, когда мы исследуем физику на больших энергиях на коллайдере, мы заглядываем в очень раннюю историю Вселенной. И эта история 10-10 с. Это очень мало, это время, за которое свет проходит 3 см.

Вот несколько примеров глобальных физических вопросов, на которые мы не имеем ответов. Этих вопросов довольно много. И если задуматься, есть очень темные пятна. Темная материя и энергия. Та материя и энергия, которую мы наблюдаем, это примерно 5% от того, что мы измеряем посредством различных гравитационных наблюдений. Это примерно то же самое, что у вас квартира 20 квадратных метров, а вам приходит счет за отопление на 1000 метров, и все правильно, где-то остальные квадратные метры отапливаются, только вы не понимаете, где они. Так же и мы не понимаем, в каких частицах находится темная материя.
Мы занимаемся исследованиями новых свойств материи. В частности, на коллайдерах мы производим напрямую новые неизвестные нам частицы. Как мы это делаем? Буквально выколачиваем из ничего. Все знают формулу Эйнштейна E = mc2, но она имеет и обратное значение: если мы в одной маленькой области сосредоточим энергию, то может образоваться новая материя, пара электрона с позитроном или еще что-то. Если мы сконцентрируем достаточно много энергии, могут родиться достаточно сложные частицы, которые при этом мгновенно распадутся на обычные, известные нам. Поэтому наблюдать буквально новые необычные частицы мы не можем. Те не менее, мы можем зарегистрировать продукты их распада и извлекать оттуда информацию о том, что родилось.
Это парадигма, которой мы следуем в экспериментальной физике высоких энергий. И для этого нужен, с одной стороны, ускоритель высоких частиц, чтобы сконцентрировать энергию в определенной точке, создать эти частицы. А с другой стороны, эту точку мы должны окружить неким детектором, чтобы зафиксировать, сфотографировать продукты распада частиц.

Фотография — очень хорошая ассоциация, поскольку сейчас в детекторах бо?льшая часть информации поступает с кремниевых детекторов, которые есть ни что иное, как матрица в цифровых камерах. В CERN на БАК у нас есть четыре большие цифровые камеры. Четыре эксперимента: два общих, ATLAS и CMS, и два специализированных, HERA-B и Alice.
Что же это за камеры? Высота детектора ATLAS — 25 метров. Я постарался представить его в реальном масштабе. Масса — 150 тыс. тонн.
Вы примерно представляете размер матрицы фотоаппарата. Здесь примерно 200 квадратных метров матрицы.
На самом деле, это много слоев матрицы, чтобы регистрировать частицы, которые между ними проходят.
Самое крутое для этих экспериментов — их скорость. Они снимают со скоростью 40 млн кадров в секунду. 40 млн раз в секунду протоны в коллайдере сталкиваются с протонами. В каждом из этих столкновений возможно рождение чего-то нового. Оно бывает редко, но тем не менее, чтобы не пропустить, мы должны считывать каждое столкновение.
Записывать мы столько не можем, реально мы записываем примерно 200–500 кадров в секунду, но это тоже неплохо.
Кроме того, детекторы с этой скоростью щелкают в течение многих лет с перерывом на зимние каникулы.

На этом слайде я воспроизвожу то, что Владимир Игоревич замечательно объяснил. На правой картинке то, что он показывал. Насколько часто у нас происходят различные физические процессы в результате столкновения? В результате столкновения протонов возникает только кластер энергии, и из этой энергии может рождаться все, что угодно, что энергетически допустимо. Обычно рождается что-то обычное: пи-мезоны, протоны, электроны.
Меня спрашивали, зачем вы рождаете то, что вам не нужно? Почему вы не сделаете столкновения так, чтобы рождался бозон Хиггса и не мучались с необходимостью читать 40 млн событий в секунду? Я бы сказал, это сейчас невозможно из-за первых принципов, именно из-за того, что у нас происходит столкновение, и единственная характеристика — энергия. Кластер не знает ни про Хиггса, ни про что-либо другое. Всё, что рождается, будет рождаться случайным образом. И естественно, то, что рождается часто, мы уже наблюдали. Нам интересно то, что рождается редко.
Насколько редко? Если столкновения считываются со скоростью 40 млн столкновений в секунду, то интересные процессы, например рождение бозона Хиггса, происходят примерно от 1 до 10 раз в час. Таким образом, мы должны увидеть эти события, которые происходят столь редко, на фоне шума с точки зрения data science, который имеет частоту примерно на 10-11 порядков больше.
В качестве ассоциации: то, что мы пытаемся сделать, — увидеть снежинку определенной невиданной формы в свете фотовспышки во время снегопада и на фоне большого заснеженного поля. И честно говоря, думаю, задача со снежинкой, которую я описал, существенно проще.
Откуда мы берем данные? Первоисточником данных является детектор, который окружает точку столкновения протонов. Это то, что рождается из сгустка энергии, который возникает в результате столкновения протонов.
Детектор состоит из сабдетекторов. Знаете, когда снимаются спортивные соревнования, используется много различных камер, которые снимают с разных точек, и в результате событие как таковое видно во всем многообразии.
Аналогично устроены детекторы. Они состоят из нескольких сабдетекторов, и каждый настроен на идентификацию чего-то специального.

Здесь показан сегмент детектора CMS, у него есть сабдетекторы: силиконовый трекер, те самые силиконовые матрицы, про которые я говорил, после этого стоит электромагнитный калориметр, то есть достаточно плотная среда, в которой частицы выделяют энергию. Электромагнитные частицы — электрон и фотон — выделяют практически всю энергию, и мы имеем возможность ее измерять. Дальше стоит адронный калориметр, который является более плотным, чем электронный калориметр, и в нем уже застревают частицы — опять же, адроны, нейтральные и заряженные.
Затем стоит несколько слоев мюонной системы, которая рассчитана на регистрацию мюонов — частиц, которые достаточно мало взаимодействуют с веществом. Они заряжены и просто после себя оставляют ионизацию. На этой картинке я показываю, как мюон пролетает через детектор. Родившись в центре, он пересекает детектор, практически ничего не оставляет в калориметре, в трекере его видно как последовательность точек, и в мюонной системе он наблюдается как последовательность кластеров.
Электрон — заряженная частица, поэтому проходя через трекер она также оставляет треки, но как я говорил, она застревает в электромагнитном калориметре и отдает туда практически всю свою энергию.
Что такое электрон? Это последовательность хитов в трекере, которые лежат на одной кривой. Она, в свою очередь, соответствует определенной частице определенной энергии. Еще она соответствует энергии в электромагнитном калориметре, которая согласуется с энергией, получаемой из трекера. Таким образом, буквально получается идентификация электрона. Если мы видим подобное соответствие сигнала в трекере и в электромагнитном калориметре, тогда это скорее всего электрон.
Заряженный адрон пролетает электромагнитный калориметр почти без взаимодействия, он высаживает почти всю свою энергию в адронном калориметре. Идея та же самая: у нас есть трек, и есть соответствующий кластер энергий в калориметре. Мы их сопоставляем и можем сказать: окей, если кластер в электромагнитном калориметре, тогда это скорее всего электрон. Если кластер в адронном калориметре — тогда это скорее всего адрон.
Допустим, может образоваться фотон. Это нейтральная частица, она в магнитном поле не изгибается, летит по прямой. Более того, прошивает трекер насквозь, не оставляя там таких хитов, но оставляет кластер в электромагнитном калориметре. В результате мы видим отдельно стоящий кластер. Наш вывод: если у нас есть кластер, на который смотрит трек, — это электрон. Если же имеется кластер, на который никто не смотрит, — это фотон. Так трекеры и работают.
На этом слайде я обобщил то, как происходит идентификация частиц. Действительно, разные типы частиц имеют разные сигнатуры.

Тем не менее, с самого детектора мы получаем просто отчет. В силиконовом, допустим, детекторе просто считываем сигналы с пикселей и т. п. Мы имеем порядка миллиона засвеченных ячеек в детекторе, которые снимаются со скоростью 40 МГц. Это 40 терабайт данных в секунду.
В настоящий момент мы такой поток обрабатывать не можем, хотя технически уже приближаемся к возможностям. Поэтому данные хранятся в локальных буферах на детекторе. И за это время, используя малую толику информацию, мы должны определить: это событие совсем неинтересное или потенциально интересное, и его стоит оставить для работы? Нам необходимо это решить, подавить общий рейт на три порядка. И таким образом, как показывает красная стрелка справа, мы прыгаем от общего рейта куда-то ниже.
Это типичная задача классификации. Сейчас мы активно применяем методы машинного обучения, Яндекс в этом широко участвует — потом Таня вам всё расскажет.
Мы понизили рейт на три порядка, теперь можем выдохнуть, у нас есть немного больше времени, мы можем произвести более качественную обработку событий, можем восстановить некие локальные объекты. Еслт эти объекты, которые были восстановлены в определенных сабдетекторах, связать вместе, получается глобальное распознавание образов. Таким образом, мы подавляем еще три порядка, опять отбираем частицы, возможно, интересные от совсем неинтересных.
То, что мы отобрали здесь, идет в память и запасается в дата-центре. Мы спасаем одно событие из миллиона. Остальные события теряются безвозвратно. Так что очень важно, чтобы этот отбор имел хорошую эффективность. Если мы что-то потеряли — это уже не восстановить.
Затем наше событие записано на ленты, мы можем с ними спокойно работать, заниматься реконструкцией и анализом. И этот путь от изначальных детекторов до конечного физического результата — ни что иное, как очень агрессивное многошаговое уменьшение размерности задачи. Снимая с детектора порядка 10 млн данных, мы их сначала кластеризуем на соседние объекты, потом реконструируем в объекты типа треков частиц, после этого отбираем объекты, которые являются продуктами распада, и в конечном итоге получаем результат.

Для этого нам необходимы достаточно могучие компьютерные ресурсы. Физика высоких энергий использует распределенные компьютерные ресурсы. На этом слайде, чтобы дать идею о количестве, для коллаборации CMS используется 120 тыс. ядер и порядка 200 петабайт емкости на дисках.
Система распределенная, поэтому передача данных является важным компонентом. Технически мы для этого используем выделенные линии, практически свои каналы связи, которые применяются специально для физики высоких энергий.

На этом слайде я хотел сравнить наши задачи передачи данных с задачами передачи данных промышленными. Например — сравнить с Netflix, крупнейшим поставщиком потокового медийного контента в США. Он интересен тем, что передает примерно такое же количество данных в год, как LHC. Но задача LHC существенно сложнее. Мы передаем большее количество данных меньшему количеству клиентов, поэтому нам достаточно непросто организовать реплицирование данных. Этот тот подход, которым Netflix решает свою задачу.

Вот ресурсы, которые мы используем. Про компьютерные я говорил. Важно, что все эти ресурсы используются исследователями, и эксперименты в физике высоких частиц — это всегда огромные коллаборации. Так что в наши ресурсы должны быть объединены порядка 10 000 человек, которые с удовольствием работают синхронно. Для этого требуются соответствующие технологии, и результатом применения этих ресурсов, многогодовой работы десятка тысяч людей, является научный результат.

Пример — статья CMS, которая характеризуется как открытие бозона Хиггса. Владимир объяснял про статистику, ошибки и прочее. Вы никогда не увидите научной статьи, где написано «открытие чего-то», именно потому что совершить открытие — значит поставить точку. Нет, мы экспериментальная наука, мы что-то наблюдаем. Вывод этой статьи — что мы наблюдаем такой-то бозон с такой-то массой в таких-то пределах с такой-то вероятностью и по таким-то параметрам его свойства совпадают со свойствами бозона Хиггса.

Вот как выглядит научная статья. То же самое, 36 страниц. Половина из них — статья, 136 ссылок на научные исследования и три тысячи авторов. А людей, которые реально вложились в получение результата, еще больше. Ваш покорный слуга там же.

На этом слайде я хотел объяснить, почему мы ищем пики в распределениях, какая связь между пиками и частицами. Не буду на этом останавливаться. Причина физическая. Физика так устроена, что если у нас есть частица, которая распадается на другие частицы, то распределения вероятностей распавшихся частиц по кинематическим параметрам действительно имеют полюс. На самом деле полюс немного сдвинут, поэтому он выглядит как пик рядом с массой, с параметром, который является массой покоя той самой распадающейся частицы.

На этом слайде я радостно сообщаю, что мы нашли бозон Хиггса еще в 2012 году. Мы нашли эту самую снежинку очень специальной формы.

Вот подтверждение того, что Владимир говорил про интерпретации. В 2012 году мы обнаружили бозон Хиггса, см. картинку слева. Как мы можем подтвердить, что увидели действительно правильное измерение? Справа то же самое распределение в данных последних двух лет. Там мы видим тот же самый сигнал. Какова вероятность, что в двух совершенно независимых данных — на самом деле, новые данные набраны даже при другой энергии — одно и то же? Довольно маленькая. Но самое главное, что тот результат, который был раньше, обладал предсказательной силой. Мы предсказали, что в новых данных оно будет в этом месте, и оно действительно там есть. Всё, мы поставили галку.

В то же время в прошлом году очень похожий сигнал на правом графике, такое же превышение, было обнаружено в области 750 GeV, и теоретики, естественно, тут же подтвердили, что да, должна быть частица именно с такой массой. Правая и левая картинки статистически не сильно отличаются.
Однако в результате набора новых данных, после того, как мы увеличили статистику примерно в пять раз, результат рассосался. Это типичный пример, как более-менее похожие изначально результаты могут в конечном итоге и перейти в открытие, и рассосаться. Здесь очень много всяких подводных камней.

И заключение. Решаемые задачи уникальны, сложны, интересны. В данный момент их решают в основном физики. И именно компьютерный профессиональный опыт исключительно востребован в этой области. Физики это понимают. В Яндексе мы работаем буквально над этим — мы стараемся пропагандировать и применять методы computer science к научным исследованиям в физике высоких энергий, к экспериментам на БАК. Для этого у нас есть специальная группа.
Я оставляю свои координаты. Если будет интерес, захотите узнать побольше, я с огромным интересом пообщаюсь с людьми, welcome. И спасибо.
Под катом — расшифровка и основная часть слайдов.
Почему я взялся за доклад с удовольствием? Практически всю свою карьеру я занимаюсь экспериментальной физикой высоких энергий. Работал более чем на пяти различных детекторах, начиная с 90-х годов прошлого века, и это исключительно интересная захватывающая работа — исследовать, находиться на самом переднем крае изучения мироздания.
Эксперименты в физике высоких энергий всегда большие, эти эксперименты достаточно дорогие, каждый следующий шаг в познании делать непросто. В частности, поэтому за каждым экспериментом, как правило, стоит некая идея, что же мы хотим проверить? Как вы знаете, существует взаимоотношение между теорией и экспериментом, это цикл познавания мира. Мы что-то наблюдаем, мы пытаемся упорядочить наше понимание, представить некие модели. Хорошие модели обладают предсказательной силой, мы можем что-то предсказать, и мы опять проверяем это экспериментально. И постепенно, идя по спирали, на каждом витке мы узнаем нечто новое.
Эксперименты, в которых я работал, — как они делали открытия? Для чего, собственно, детекторы были построены? Например, детектор CDF на Тэватроне? Тэватрон был построен в первую очередь для открытия топ-кварка. Он был благополучно открыт. Кстати, именно при анализе данных топ-кварка на моей памяти впервые серьезно использовались данные анализа multi valued. По сути, еще тогда, так давно, работа строилась методом машинного обучения.
Другой эксперимент, где мне посчастливилось работать, это CMS на БАК. Физическая программа БАК была нацелена на три цели: Хиггс, суперсимметрия и кварк-глюонная плазма. Хиггс — это была цель номер один, которая была благополучно выполнена к 2012 году.
Когда мы набираем новые данные, мы ходим по неизвестной местности, мы обнаруживаем неожиданные вещи. Среди таких было открытие смешивания В-мезонов и анти-В-мезонов в прошлом веке, это несколько поменяло наше представление о стандартной модели. Это было абсолютно неожиданно.
В 2016 году эксперимент Херби наблюдал пентакварк, состояния такого типа наблюдались довольно давно, но каждый раз они рассасывались. На этот раз у меня есть ощущение, что тот объект, который наблюден, устоит. Действительно уникальный объект, это не барион, не мезон, а новое состояние материи.
Но мы все-таки поговорим про данные. На этом слайде я попытался представить, какое положение занимают данные физики высокой энергии в общей иерархии. В нынешнем мире данные правят миром, данные анализируют всюду. Эту картинку я утащил с Wired, но статистика дана на 2012 год. Каков поток данных набирается в различных сервисах? Далеко вперед с цифрой 3000 РВ вырывается вперед деловая переписка, писем мы все пишем много. На втором месте Facebook, что мы туда загружаем, котики, как ни странно, занимают второе место по объему, опережая серьезные задачи, которые, допустим, делает Google. На четвертом месте идет архив всех медицинских записей более-менее известных, которые используются для развития новых методик в медицине. И следующими идут данные БАК, порядка 15 РВ в код. На этом же уровне идут и данные с YouTube. То есть данные одного, пусть большого, но одного эксперимента конкретной области физики имеют мощность, сравнимую с самыми большими источниками данных.
Это означает, что поскольку мы не самые большие, то можем использовать передовой опыт и Google, и Facebook, и прочих промышленных сервисов. Тем не менее, у наших данных есть вполне специфические свойства, которые требуют серьезной адаптации имеющихся методов. Интересно заметить, что физика высоких энергий была драйвером компьютерных технологий с 60-х до 80-х, и тогда большие компьютерные мейнфреймы, системы хранения данных, делались именно под задачи физики высоких энергий.
После этого запретили ядерные испытания, и драйвером стало моделирование ядерных взрывов.
Зачем мы этим всем занимаемся? Владимир Игоревич примерно рассказал. Я на этой картинке попытался примерно обрисовать границу известного. По превалирующей сейчас теории, наша вселенная возникла в результате Большого взрыва, который произошел где-то 13 млрд лет назад. Вселенная возникла из сгустка энергии, который стал расширяться, там образовались частицы, они кластеризовались в атомы, в молекулы, в материю и так далее. На этой картинке изображена временная шкала того, что происходило во времена Большого взрыва.
Что происходит сейчас, когда образовались известные нам частицы — электроны, нейтроны, протоны? Мы более-менее понимаем физику этих процессов. Есть некая граница, которую я здесь изобразил и которая соответствует примерно временам 10-10 c, энергиям, достижимым на БАК сейчас. Это практически самая большая энергия, достижимая экспериментально. Это граница, за которой мы ничего четко сказать не можем. То, что находится по правую сторону при меньших энергиях, мы более-менее понимаем и проверили экспериментально. То, что находится по левую сторону… по этому поводу существуют различные теории и представления, разные ученые представляют это по-разному, и проверить это экспериментально, напрямую, довольно сложно.
Суть в том, что сегодня, когда мы исследуем физику на больших энергиях на коллайдере, мы заглядываем в очень раннюю историю Вселенной. И эта история 10-10 с. Это очень мало, это время, за которое свет проходит 3 см.
Вот несколько примеров глобальных физических вопросов, на которые мы не имеем ответов. Этих вопросов довольно много. И если задуматься, есть очень темные пятна. Темная материя и энергия. Та материя и энергия, которую мы наблюдаем, это примерно 5% от того, что мы измеряем посредством различных гравитационных наблюдений. Это примерно то же самое, что у вас квартира 20 квадратных метров, а вам приходит счет за отопление на 1000 метров, и все правильно, где-то остальные квадратные метры отапливаются, только вы не понимаете, где они. Так же и мы не понимаем, в каких частицах находится темная материя.
Мы занимаемся исследованиями новых свойств материи. В частности, на коллайдерах мы производим напрямую новые неизвестные нам частицы. Как мы это делаем? Буквально выколачиваем из ничего. Все знают формулу Эйнштейна E = mc2, но она имеет и обратное значение: если мы в одной маленькой области сосредоточим энергию, то может образоваться новая материя, пара электрона с позитроном или еще что-то. Если мы сконцентрируем достаточно много энергии, могут родиться достаточно сложные частицы, которые при этом мгновенно распадутся на обычные, известные нам. Поэтому наблюдать буквально новые необычные частицы мы не можем. Те не менее, мы можем зарегистрировать продукты их распада и извлекать оттуда информацию о том, что родилось.
Это парадигма, которой мы следуем в экспериментальной физике высоких энергий. И для этого нужен, с одной стороны, ускоритель высоких частиц, чтобы сконцентрировать энергию в определенной точке, создать эти частицы. А с другой стороны, эту точку мы должны окружить неким детектором, чтобы зафиксировать, сфотографировать продукты распада частиц.
Фотография — очень хорошая ассоциация, поскольку сейчас в детекторах бо?льшая часть информации поступает с кремниевых детекторов, которые есть ни что иное, как матрица в цифровых камерах. В CERN на БАК у нас есть четыре большие цифровые камеры. Четыре эксперимента: два общих, ATLAS и CMS, и два специализированных, HERA-B и Alice.
Что же это за камеры? Высота детектора ATLAS — 25 метров. Я постарался представить его в реальном масштабе. Масса — 150 тыс. тонн.
Вы примерно представляете размер матрицы фотоаппарата. Здесь примерно 200 квадратных метров матрицы.
На самом деле, это много слоев матрицы, чтобы регистрировать частицы, которые между ними проходят.
Самое крутое для этих экспериментов — их скорость. Они снимают со скоростью 40 млн кадров в секунду. 40 млн раз в секунду протоны в коллайдере сталкиваются с протонами. В каждом из этих столкновений возможно рождение чего-то нового. Оно бывает редко, но тем не менее, чтобы не пропустить, мы должны считывать каждое столкновение.
Записывать мы столько не можем, реально мы записываем примерно 200–500 кадров в секунду, но это тоже неплохо.
Кроме того, детекторы с этой скоростью щелкают в течение многих лет с перерывом на зимние каникулы.
На этом слайде я воспроизвожу то, что Владимир Игоревич замечательно объяснил. На правой картинке то, что он показывал. Насколько часто у нас происходят различные физические процессы в результате столкновения? В результате столкновения протонов возникает только кластер энергии, и из этой энергии может рождаться все, что угодно, что энергетически допустимо. Обычно рождается что-то обычное: пи-мезоны, протоны, электроны.
Меня спрашивали, зачем вы рождаете то, что вам не нужно? Почему вы не сделаете столкновения так, чтобы рождался бозон Хиггса и не мучались с необходимостью читать 40 млн событий в секунду? Я бы сказал, это сейчас невозможно из-за первых принципов, именно из-за того, что у нас происходит столкновение, и единственная характеристика — энергия. Кластер не знает ни про Хиггса, ни про что-либо другое. Всё, что рождается, будет рождаться случайным образом. И естественно, то, что рождается часто, мы уже наблюдали. Нам интересно то, что рождается редко.
Насколько редко? Если столкновения считываются со скоростью 40 млн столкновений в секунду, то интересные процессы, например рождение бозона Хиггса, происходят примерно от 1 до 10 раз в час. Таким образом, мы должны увидеть эти события, которые происходят столь редко, на фоне шума с точки зрения data science, который имеет частоту примерно на 10-11 порядков больше.
В качестве ассоциации: то, что мы пытаемся сделать, — увидеть снежинку определенной невиданной формы в свете фотовспышки во время снегопада и на фоне большого заснеженного поля. И честно говоря, думаю, задача со снежинкой, которую я описал, существенно проще.
Откуда мы берем данные? Первоисточником данных является детектор, который окружает точку столкновения протонов. Это то, что рождается из сгустка энергии, который возникает в результате столкновения протонов.
Детектор состоит из сабдетекторов. Знаете, когда снимаются спортивные соревнования, используется много различных камер, которые снимают с разных точек, и в результате событие как таковое видно во всем многообразии.
Аналогично устроены детекторы. Они состоят из нескольких сабдетекторов, и каждый настроен на идентификацию чего-то специального.
Здесь показан сегмент детектора CMS, у него есть сабдетекторы: силиконовый трекер, те самые силиконовые матрицы, про которые я говорил, после этого стоит электромагнитный калориметр, то есть достаточно плотная среда, в которой частицы выделяют энергию. Электромагнитные частицы — электрон и фотон — выделяют практически всю энергию, и мы имеем возможность ее измерять. Дальше стоит адронный калориметр, который является более плотным, чем электронный калориметр, и в нем уже застревают частицы — опять же, адроны, нейтральные и заряженные.
Затем стоит несколько слоев мюонной системы, которая рассчитана на регистрацию мюонов — частиц, которые достаточно мало взаимодействуют с веществом. Они заряжены и просто после себя оставляют ионизацию. На этой картинке я показываю, как мюон пролетает через детектор. Родившись в центре, он пересекает детектор, практически ничего не оставляет в калориметре, в трекере его видно как последовательность точек, и в мюонной системе он наблюдается как последовательность кластеров.
Электрон — заряженная частица, поэтому проходя через трекер она также оставляет треки, но как я говорил, она застревает в электромагнитном калориметре и отдает туда практически всю свою энергию.
Что такое электрон? Это последовательность хитов в трекере, которые лежат на одной кривой. Она, в свою очередь, соответствует определенной частице определенной энергии. Еще она соответствует энергии в электромагнитном калориметре, которая согласуется с энергией, получаемой из трекера. Таким образом, буквально получается идентификация электрона. Если мы видим подобное соответствие сигнала в трекере и в электромагнитном калориметре, тогда это скорее всего электрон.
Заряженный адрон пролетает электромагнитный калориметр почти без взаимодействия, он высаживает почти всю свою энергию в адронном калориметре. Идея та же самая: у нас есть трек, и есть соответствующий кластер энергий в калориметре. Мы их сопоставляем и можем сказать: окей, если кластер в электромагнитном калориметре, тогда это скорее всего электрон. Если кластер в адронном калориметре — тогда это скорее всего адрон.
Допустим, может образоваться фотон. Это нейтральная частица, она в магнитном поле не изгибается, летит по прямой. Более того, прошивает трекер насквозь, не оставляя там таких хитов, но оставляет кластер в электромагнитном калориметре. В результате мы видим отдельно стоящий кластер. Наш вывод: если у нас есть кластер, на который смотрит трек, — это электрон. Если же имеется кластер, на который никто не смотрит, — это фотон. Так трекеры и работают.
На этом слайде я обобщил то, как происходит идентификация частиц. Действительно, разные типы частиц имеют разные сигнатуры.
Тем не менее, с самого детектора мы получаем просто отчет. В силиконовом, допустим, детекторе просто считываем сигналы с пикселей и т. п. Мы имеем порядка миллиона засвеченных ячеек в детекторе, которые снимаются со скоростью 40 МГц. Это 40 терабайт данных в секунду.
В настоящий момент мы такой поток обрабатывать не можем, хотя технически уже приближаемся к возможностям. Поэтому данные хранятся в локальных буферах на детекторе. И за это время, используя малую толику информацию, мы должны определить: это событие совсем неинтересное или потенциально интересное, и его стоит оставить для работы? Нам необходимо это решить, подавить общий рейт на три порядка. И таким образом, как показывает красная стрелка справа, мы прыгаем от общего рейта куда-то ниже.
Это типичная задача классификации. Сейчас мы активно применяем методы машинного обучения, Яндекс в этом широко участвует — потом Таня вам всё расскажет.
Мы понизили рейт на три порядка, теперь можем выдохнуть, у нас есть немного больше времени, мы можем произвести более качественную обработку событий, можем восстановить некие локальные объекты. Еслт эти объекты, которые были восстановлены в определенных сабдетекторах, связать вместе, получается глобальное распознавание образов. Таким образом, мы подавляем еще три порядка, опять отбираем частицы, возможно, интересные от совсем неинтересных.
То, что мы отобрали здесь, идет в память и запасается в дата-центре. Мы спасаем одно событие из миллиона. Остальные события теряются безвозвратно. Так что очень важно, чтобы этот отбор имел хорошую эффективность. Если мы что-то потеряли — это уже не восстановить.
Затем наше событие записано на ленты, мы можем с ними спокойно работать, заниматься реконструкцией и анализом. И этот путь от изначальных детекторов до конечного физического результата — ни что иное, как очень агрессивное многошаговое уменьшение размерности задачи. Снимая с детектора порядка 10 млн данных, мы их сначала кластеризуем на соседние объекты, потом реконструируем в объекты типа треков частиц, после этого отбираем объекты, которые являются продуктами распада, и в конечном итоге получаем результат.
Для этого нам необходимы достаточно могучие компьютерные ресурсы. Физика высоких энергий использует распределенные компьютерные ресурсы. На этом слайде, чтобы дать идею о количестве, для коллаборации CMS используется 120 тыс. ядер и порядка 200 петабайт емкости на дисках.
Система распределенная, поэтому передача данных является важным компонентом. Технически мы для этого используем выделенные линии, практически свои каналы связи, которые применяются специально для физики высоких энергий.
На этом слайде я хотел сравнить наши задачи передачи данных с задачами передачи данных промышленными. Например — сравнить с Netflix, крупнейшим поставщиком потокового медийного контента в США. Он интересен тем, что передает примерно такое же количество данных в год, как LHC. Но задача LHC существенно сложнее. Мы передаем большее количество данных меньшему количеству клиентов, поэтому нам достаточно непросто организовать реплицирование данных. Этот тот подход, которым Netflix решает свою задачу.
Вот ресурсы, которые мы используем. Про компьютерные я говорил. Важно, что все эти ресурсы используются исследователями, и эксперименты в физике высоких частиц — это всегда огромные коллаборации. Так что в наши ресурсы должны быть объединены порядка 10 000 человек, которые с удовольствием работают синхронно. Для этого требуются соответствующие технологии, и результатом применения этих ресурсов, многогодовой работы десятка тысяч людей, является научный результат.
Пример — статья CMS, которая характеризуется как открытие бозона Хиггса. Владимир объяснял про статистику, ошибки и прочее. Вы никогда не увидите научной статьи, где написано «открытие чего-то», именно потому что совершить открытие — значит поставить точку. Нет, мы экспериментальная наука, мы что-то наблюдаем. Вывод этой статьи — что мы наблюдаем такой-то бозон с такой-то массой в таких-то пределах с такой-то вероятностью и по таким-то параметрам его свойства совпадают со свойствами бозона Хиггса.
Вот как выглядит научная статья. То же самое, 36 страниц. Половина из них — статья, 136 ссылок на научные исследования и три тысячи авторов. А людей, которые реально вложились в получение результата, еще больше. Ваш покорный слуга там же.
На этом слайде я хотел объяснить, почему мы ищем пики в распределениях, какая связь между пиками и частицами. Не буду на этом останавливаться. Причина физическая. Физика так устроена, что если у нас есть частица, которая распадается на другие частицы, то распределения вероятностей распавшихся частиц по кинематическим параметрам действительно имеют полюс. На самом деле полюс немного сдвинут, поэтому он выглядит как пик рядом с массой, с параметром, который является массой покоя той самой распадающейся частицы.
На этом слайде я радостно сообщаю, что мы нашли бозон Хиггса еще в 2012 году. Мы нашли эту самую снежинку очень специальной формы.
Вот подтверждение того, что Владимир говорил про интерпретации. В 2012 году мы обнаружили бозон Хиггса, см. картинку слева. Как мы можем подтвердить, что увидели действительно правильное измерение? Справа то же самое распределение в данных последних двух лет. Там мы видим тот же самый сигнал. Какова вероятность, что в двух совершенно независимых данных — на самом деле, новые данные набраны даже при другой энергии — одно и то же? Довольно маленькая. Но самое главное, что тот результат, который был раньше, обладал предсказательной силой. Мы предсказали, что в новых данных оно будет в этом месте, и оно действительно там есть. Всё, мы поставили галку.
В то же время в прошлом году очень похожий сигнал на правом графике, такое же превышение, было обнаружено в области 750 GeV, и теоретики, естественно, тут же подтвердили, что да, должна быть частица именно с такой массой. Правая и левая картинки статистически не сильно отличаются.
Однако в результате набора новых данных, после того, как мы увеличили статистику примерно в пять раз, результат рассосался. Это типичный пример, как более-менее похожие изначально результаты могут в конечном итоге и перейти в открытие, и рассосаться. Здесь очень много всяких подводных камней.
И заключение. Решаемые задачи уникальны, сложны, интересны. В данный момент их решают в основном физики. И именно компьютерный профессиональный опыт исключительно востребован в этой области. Физики это понимают. В Яндексе мы работаем буквально над этим — мы стараемся пропагандировать и применять методы computer science к научным исследованиям в физике высоких энергий, к экспериментам на БАК. Для этого у нас есть специальная группа.
Я оставляю свои координаты. Если будет интерес, захотите узнать побольше, я с огромным интересом пообщаюсь с людьми, welcome. И спасибо.
Поделиться с друзьями
iw2rmb
Фёдор, спасибо за интересный материал! Яндексу стоит помочь с оформлением — перерисовать изображения, составить текст вместо стенографии, снабдить субтитрами ролик.