
Сейчас проходит Data Science Game — международное студенческое соревнование по анализу данных. Ребята из МГУ выиграли отборочный этап, а затем рассказали о своём решении на одной из наших тренировок по машинному обучению.
Под катом — расшифровка и большинство слайдов.
Всеволод Викулин:
— Всем привет. Мы будем рассказывать про отборочный этап международного соревнования, которое называется Data Science Game. Наша команда представляла МГУ и состояла из Дарьи, меня и еще двух человек.
Соревнование уже пытаются проводить на регулярной основе. Будем говорить про отборочный этап. Финал проводится в сентябре. Мы заняли там первое место. И отдельно приятно, что в сетке первых топовых мест, с медалями, — российские команды. Значит, российский data science всех унижает.
Переходим к постановке задач. Есть некий сайт Deezer, где можно послушать музыку. У них есть рекомендательная система Flow, которая предлагает пользователю послушать какую-то песню.
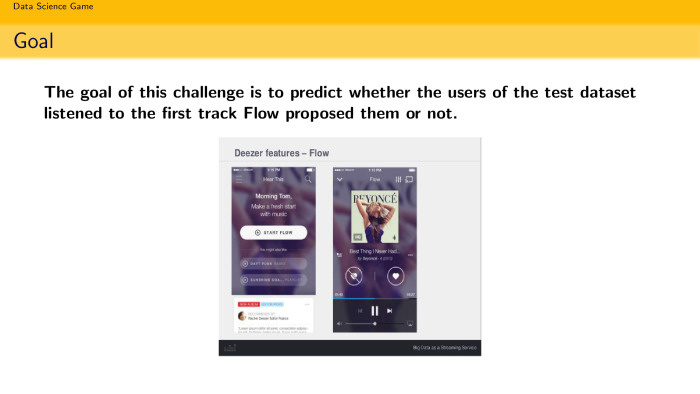
Известна статистика по пользователю: что он слушал, когда он слушал, и есть событие, что Flow рекомендует какому-то пользователю песню. Стоит задача узнать, прослушает он ее или нет. Ставится она довольно забавно. Понятие «прослушает» обозначает, прослушал ли он ее 30 секунд. Если прослушал 30 секунд и скипнул — значит, прослушал. У нас был соблазн решать супермодными схемами, которые проходят в ШАДе, какими-то коллаборативными фильтрациями, фильтрационными машинами. На самом деле все это не нужно, это все лишнее. Нужно только взять XGBoost и рассмотреть задачу классификации. Это максимально простое решение. Намайнили фичи, запихнули в XGBoost, получили какой-то score. Весь доклад состоит из построения хороших фичей.
На модель мы настолько не заморачивались, даже не тюнили, как взяли из коробки, так и поставили.

Плавно переходим к датасету. Было 7,5 млн пар user и media, то есть человек и трек с каким-то id, какие-то фичи и целевая переменная — прослушал песню больше 30 секунд или нет.
Важно, что там были не только песни, которые рекомендовала Flow. Там были еще песни, которые юзер сам прослушал или тыкнул во время онлайн-радио. И там была спецфича, которая говорила, рекомендация это или нет. При этом в самом тест-сете из 30 тыс. пар нужно было определить, 1 или 0, только для тех юзеров, которых рекомендовала система.
Мы переходим к фичам, связанным с id. Пол, возраст. Но мы знаем, что это не совсем всё.
Фичи про музыку, ее длительность, id артиста, жанр — тоже всё неважно.

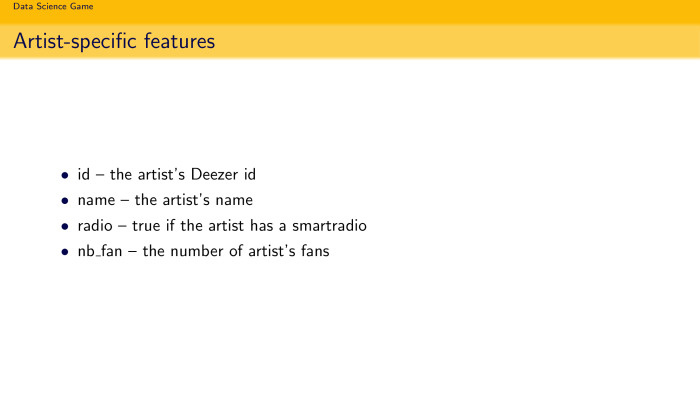
Id, на чем слушал… Мы еще распарсили их API — это было разрешено правилами конкурса — и получили некие фичи, связанные с артистом: его имя, в каком жанре он выступает, количество фанов. Но это все не очень сильно сыграло, как и фичи по альбому.

Каждый человек, который решал такие задачи, знает, что в них это не влияет. Title песни не влияет на то, послушаете вы ее или нет. Влияет одна самая важная вещь: если вы слушали эту песню или слушали песню подобного характера, то вы послушаете ее снова. Если у вас есть предпочтение послушать Beyonce, то вряд ли вы послушаете Eminem, так получилось. Поэтому нужно делать поведенческие фичи. Они больше всего влияют, и они зарешали больше всего. О них и будем говорить.

Первое хорошее расположение — построить матрицу расстояний. Вы можете померить, насколько похожи пользователи. Стандартный подход в рекомендациях: есть огромная матрица размера количество пользователей на количество пользователей, и вы хотите посмотреть, насколько пользователь А похож на пользователя Б. Как это сделать? Можно тупо взять все песни, которые послушали оба пользователя, и посмотреть, какой там distance. Человек, который любит считать все быстро, — он считает косинусы расстояний, потому что считается быстро. Вы можете быстро прикинуть здоровенную матрицу. Поскольку у нас всего несколько тысяч, вы можете даже (неразборчиво — прим. ред.). И можно кластеризовать, найти кластеры. В теории, если вы взяли кластер любителей русского рэпа… очень грустный кластер, но он будет. И понятно, что если у вас есть кластер любителей русского рэпа, послушает ли пользователь песню Beyonce? Маловероятно. Фича довольно логичная, и это первое, что приходит в голову, когда вы работаете с задачей рекомендации.
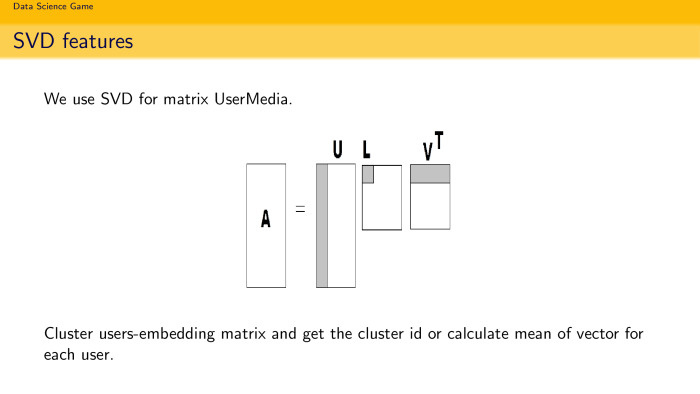
Вторая идея: все мы знаем LSA, latent semantic analysis, это часто embedding в текстовых разложениях. Почему бы не попробовать такую embedding, но уже в задаче рекомендации? У вас есть матрица А — просто матрица, по строкам то же количество юзеров, и по столбцам количество песен. 1 — если прослушал, 0 — если не прослушал. Вы можете сделать SVD разложение и взять k компонент. И считать, что k компоненты — это просто embedding юзеров в пространстве песен. Так делают в тексте, почему бы не сделать так? Тем более размер довольно здоровый, песен будет 450 тыс. разных. Матрица была, условно, 5 на 450 тыс. Она довольно здоровая, естественно, она спарсовая. Ты можешь ее спокойно разложить и получить embedding юзеров по песням. Ты можешь их кластеризовать, поискать любителей русского рэпа и посчитать средний вектор в этом embedding, использовать это как фичу.
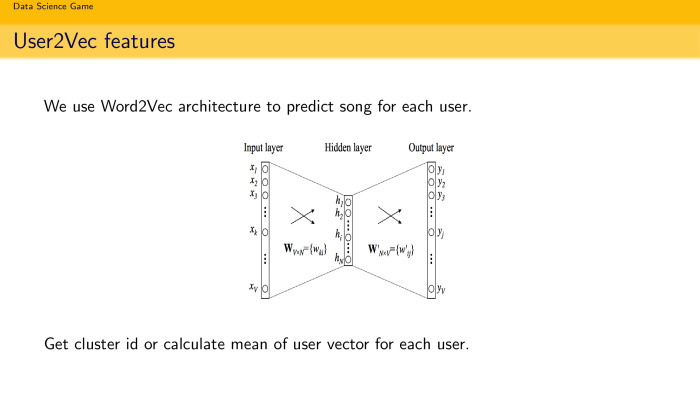
И последний кусок — user2vec. Приколюха такая, мой собственный термин. Все мы любим word2vec, потому что он работает быстро. Почему бы не использовать такую же терминологию и архитектуру, чтобы предсказывать песни? На вход ты даешь слово, если это архитектура Skebram, и предсказываешь контекст. Или ты даешь слово и предсказываешь контекст, если это Sebow (названия неточные, неразборчиво — прим. ред.). Почему бы не использовать такую же простую идею, но уже для задачи рекомендации песен? У нас есть пользователь, мы хотим его разложить на какой-то разумный вектор. Мы знаем, какие песни слушает пользователь. Мы делаем простую нейронку с одним hidden-условием, которая довольно быстро настраивается, даем на вход какое-то представление о пользователе, например longshot, а на выходе ожидаем, что он предскажет ему песню, и ставите функцию потери, какой-нибудь softmax здесь, просто прогоняете так всех пользователей. Довольно забавно, что за несколько часов вы получаете представление с открытым условием для каждого пользователя. Когда вы хотите узнать, как пользователь раскладывается по песням, вы пропускаете его через вход и смотрите значение скрытого условия. Если было 128 измерений, вы получаете 128-мерный вектор в пространстве песен. Вы тоже можете их кластеризовать и посчитать среднее. И использовать как поведенческие фичи.
А дальше о том, как делать суперсложное решение, которое привело нас к первому месту, расскажет очаровательная Дарья, ей слово.
Дарья Соболева:
— Всем привет. Меня зовут Соболева Дарья, я учусь в МГУ на третьем курсе на факультете ВМК на кафедре ММП. Да, у нас было четыре человека в команде. Два человека — Всеволод и Никита Шаповалов — занимались фича-инжинирингом, они парсили API, генерили умные фичи, а я и еще один человек, Николай Попов, строили саму модель.

Я расскажу, какие дополнительные фичи, но не такие умные, как у ребят, мы нагенерили. Обычные, которые всегда используем от соревнования к соревнованию. Хорошая практика — всегда, если у вас есть категориальные признаки, считать размер категории K, среднее значение целевой переменной внутри каждой категории. Плюс из-за того, что мы каким-то образом задействуем целевую переменную, это легко может привести к переобучению. Если у вас, например, какая-то категория слишком маленькая и состоит всего из одного значения, то среднее значение целевой переменной внутри этой категории будет просто совпадать с этой целевой переменной. То есть мы будем переобучаться.
Известная техника — сглаженная средняя целевой переменной, которая была рассказана еще Стасом Семеновым. Это формула. Давайте посчитаем глобальное среднее целевой переменной по всему сети и возьмем сглаженное отношение, то есть среднее значение целевой переменной по категории доложим на размер категории и прибавим глобальное среднее, умноженное на magic number 10. На самом деле тут должен стоять параметр альфа. Так как этот параметр надо настраивать по кроссвалидации, у нас времени было не особо, и это не особо влияло, то мы решили поставить просто 10, и оно нормально себя вело.
По этой формуле видно, что если у нас размер категории слишком маленький — например, K стремится к нулю, — то эта формула будет просто превращаться в глобальное среднее. То есть вы будете меньше переобучаться.
После фиче-инжиниринга и таких простых базовых признаков, которые мы нагенерили, мы сабмитнули решение и сразу попали в топ-2.

Затем я решила добавить несколько фичей. Я использую такую технику уже несколько соревнований подряд. Она основана на том, что если мы используем целевую переменную, мы все равно каким-то образом переобучаемся, неизбежно. Поэтому давайте попробуем придумать что-то похожее, только unsupervised, без целевой переменной. Я строю random forest и беру feature importance от него, и беру top K вещественных признаков. Считаю то же самое. Представляю, что этот вещественный признак — целевая переменная. Будем считать по ним статистику.
Чем это хорошо? В первую очередь, если у вас задача бинарной классификации, то у вас целевая переменная просто 0 и 1, и ничего хорошего по категориям, кроме как среднее или сглаженное среднее вы не посчитаете. Если у вас есть хороший вещественный признак, который коррелирует с таргетом или что-то такое, топовый по мнению random forest, то вы можете посчитать разную другую статистику и нагенерить намного больше фичей. Например, я брала максимальное, медианное, среднее, минимальное, всякие квантили. Все это можно запихнуть, и у вас будут некоторые дополнительные признаки.
После того, как мы добавили эти признаки, модель практически сразу стала… Надо заметить, что метрика качества у нас была «Укрок», и долгое время — особенно это было у команд из России — они скрывали свой score. То есть брали 1 минус score, и никто не видел, как оно там работает. Это можно иметь в виду, когда вы участвуете в таких соревнованиях. Финальный score мы узнали только на private leaderboard, а до этого мало кто его видел.
Встал вопрос о том, как валидироваться. Мы решили делать достаточно естественно. Так как в тесте были треки, которые были предложены пользователю позже, чем те, которые были в обучающей выборке, то решено было в валидацию запихнуть последний трек у каждого пользователя, последний по time stamp.
Я на всех соревнованиях стараюсь оценивать качество на трех вещах: на трейне, на валидации и на leaderboard. И желательно, чтобы они как-то коррелировали. Поэтому мы решили построить валидацию следующим образом. Вся статистика, которая считалась по целевой переменной… в текущий момент мы должны смотреть в будущее. Для этого мы брали трейн, отщипывали у каждого юзера по одному треку, засовывали это в тестовую выборку, дальше считали статистику по обучающей выборке на целевой переменной и мерджили уже с нашим новым тестовым объектом.
Мы делали так на пять треков назад, валидация была построена на пять треков назад. Как говорил Сева, там было 7,5 млн объектов, поэтому обучаться на всей истории было очень сложно.
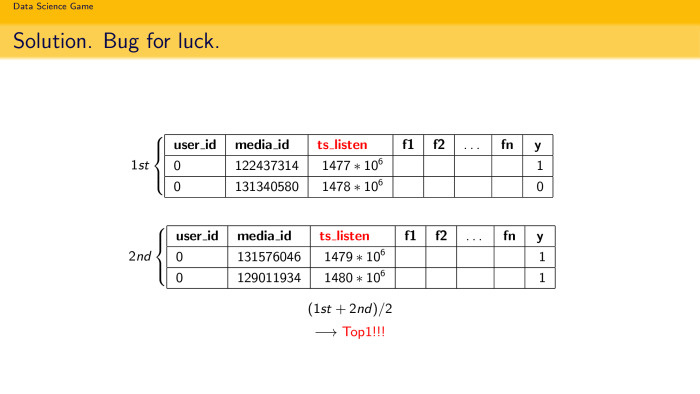
Из-за того, что памяти у нас было очень мало, мы всё делали in place. Когда в трейне мы отщипываем у каждого юзера последний трек, мы действительно удаляем его из трейна, добавляем валидацию и считаем статистику по трейну. Ну и естественно, в какой-то момент это привело к возникновению бага, который потом залетел в топ-1.
Допустим, мы пять треков отщипнули, посчитали всю статистику по обучающей выборке для этих пяти треков для каждого пользователя, сформировали одну модельку. Она обучилась, получила топ-2. Потом снова запустили тот же скрипт, где в трейне уже отсутствуют шесть последних треков у каждого пользователя. Обучили ту же самую модельку, предсказывали то же самое, только она обучалась как бы уже по седьмому, восьмому и так далее до двенадцатого трека у каждого пользователя. Обучили, она дала топ-2. А их среднее дало топ-1. Наверное, это и логично. Мы учитывали интересы пользователя в разные промежутки времени. Скорее всего, поэтому решение и взлетело.
Еще нам очень понравилось соревнование, поэтому после его завершения мы решили еще что-то попробовать. Мы стали топ-1, но при этом было желание совершенствоваться.
Я решила попробовать посчитать статистику по целевой переменной. Мы считали ее по одиночным категориям, по парам категорий (неразборчиво — прим. ред.), но я решила посчитать еще по тройкам. Значительного улучшения я не увидела, там было уже 1500 признаков, и модель достаточно сложная, ансамбль XGBoost. Так что эта идея не прошла.
Прошла другая идея. Николай Попов решил модифицировать (сбой записи — прим. ред.) песни. Мы берем два последовательных трека, прослушанных пользователем, берем «дих» времени между прослушками. Если он укладывается в длительность трека, то делим его на эту самую длительность. И получаем что-то типа рейтинга песни, а в противном случае просто проставляем исходный таргет.
Обучив всё то же самое, но посчитав статистику по преобразованному таргету, мы затем усреднили модель, посчитанную по исходному таргету и по преобразованному — и побили свое решение топ-1. Это всё.
Под катом — расшифровка и большинство слайдов.
Всеволод Викулин:
— Всем привет. Мы будем рассказывать про отборочный этап международного соревнования, которое называется Data Science Game. Наша команда представляла МГУ и состояла из Дарьи, меня и еще двух человек.
Соревнование уже пытаются проводить на регулярной основе. Будем говорить про отборочный этап. Финал проводится в сентябре. Мы заняли там первое место. И отдельно приятно, что в сетке первых топовых мест, с медалями, — российские команды. Значит, российский data science всех унижает.
Переходим к постановке задач. Есть некий сайт Deezer, где можно послушать музыку. У них есть рекомендательная система Flow, которая предлагает пользователю послушать какую-то песню.
Известна статистика по пользователю: что он слушал, когда он слушал, и есть событие, что Flow рекомендует какому-то пользователю песню. Стоит задача узнать, прослушает он ее или нет. Ставится она довольно забавно. Понятие «прослушает» обозначает, прослушал ли он ее 30 секунд. Если прослушал 30 секунд и скипнул — значит, прослушал. У нас был соблазн решать супермодными схемами, которые проходят в ШАДе, какими-то коллаборативными фильтрациями, фильтрационными машинами. На самом деле все это не нужно, это все лишнее. Нужно только взять XGBoost и рассмотреть задачу классификации. Это максимально простое решение. Намайнили фичи, запихнули в XGBoost, получили какой-то score. Весь доклад состоит из построения хороших фичей.
На модель мы настолько не заморачивались, даже не тюнили, как взяли из коробки, так и поставили.
Плавно переходим к датасету. Было 7,5 млн пар user и media, то есть человек и трек с каким-то id, какие-то фичи и целевая переменная — прослушал песню больше 30 секунд или нет.
Важно, что там были не только песни, которые рекомендовала Flow. Там были еще песни, которые юзер сам прослушал или тыкнул во время онлайн-радио. И там была спецфича, которая говорила, рекомендация это или нет. При этом в самом тест-сете из 30 тыс. пар нужно было определить, 1 или 0, только для тех юзеров, которых рекомендовала система.
Мы переходим к фичам, связанным с id. Пол, возраст. Но мы знаем, что это не совсем всё.
Фичи про музыку, ее длительность, id артиста, жанр — тоже всё неважно.
Id, на чем слушал… Мы еще распарсили их API — это было разрешено правилами конкурса — и получили некие фичи, связанные с артистом: его имя, в каком жанре он выступает, количество фанов. Но это все не очень сильно сыграло, как и фичи по альбому.
Каждый человек, который решал такие задачи, знает, что в них это не влияет. Title песни не влияет на то, послушаете вы ее или нет. Влияет одна самая важная вещь: если вы слушали эту песню или слушали песню подобного характера, то вы послушаете ее снова. Если у вас есть предпочтение послушать Beyonce, то вряд ли вы послушаете Eminem, так получилось. Поэтому нужно делать поведенческие фичи. Они больше всего влияют, и они зарешали больше всего. О них и будем говорить.
Первое хорошее расположение — построить матрицу расстояний. Вы можете померить, насколько похожи пользователи. Стандартный подход в рекомендациях: есть огромная матрица размера количество пользователей на количество пользователей, и вы хотите посмотреть, насколько пользователь А похож на пользователя Б. Как это сделать? Можно тупо взять все песни, которые послушали оба пользователя, и посмотреть, какой там distance. Человек, который любит считать все быстро, — он считает косинусы расстояний, потому что считается быстро. Вы можете быстро прикинуть здоровенную матрицу. Поскольку у нас всего несколько тысяч, вы можете даже (неразборчиво — прим. ред.). И можно кластеризовать, найти кластеры. В теории, если вы взяли кластер любителей русского рэпа… очень грустный кластер, но он будет. И понятно, что если у вас есть кластер любителей русского рэпа, послушает ли пользователь песню Beyonce? Маловероятно. Фича довольно логичная, и это первое, что приходит в голову, когда вы работаете с задачей рекомендации.
Вторая идея: все мы знаем LSA, latent semantic analysis, это часто embedding в текстовых разложениях. Почему бы не попробовать такую embedding, но уже в задаче рекомендации? У вас есть матрица А — просто матрица, по строкам то же количество юзеров, и по столбцам количество песен. 1 — если прослушал, 0 — если не прослушал. Вы можете сделать SVD разложение и взять k компонент. И считать, что k компоненты — это просто embedding юзеров в пространстве песен. Так делают в тексте, почему бы не сделать так? Тем более размер довольно здоровый, песен будет 450 тыс. разных. Матрица была, условно, 5 на 450 тыс. Она довольно здоровая, естественно, она спарсовая. Ты можешь ее спокойно разложить и получить embedding юзеров по песням. Ты можешь их кластеризовать, поискать любителей русского рэпа и посчитать средний вектор в этом embedding, использовать это как фичу.
И последний кусок — user2vec. Приколюха такая, мой собственный термин. Все мы любим word2vec, потому что он работает быстро. Почему бы не использовать такую же терминологию и архитектуру, чтобы предсказывать песни? На вход ты даешь слово, если это архитектура Skebram, и предсказываешь контекст. Или ты даешь слово и предсказываешь контекст, если это Sebow (названия неточные, неразборчиво — прим. ред.). Почему бы не использовать такую же простую идею, но уже для задачи рекомендации песен? У нас есть пользователь, мы хотим его разложить на какой-то разумный вектор. Мы знаем, какие песни слушает пользователь. Мы делаем простую нейронку с одним hidden-условием, которая довольно быстро настраивается, даем на вход какое-то представление о пользователе, например longshot, а на выходе ожидаем, что он предскажет ему песню, и ставите функцию потери, какой-нибудь softmax здесь, просто прогоняете так всех пользователей. Довольно забавно, что за несколько часов вы получаете представление с открытым условием для каждого пользователя. Когда вы хотите узнать, как пользователь раскладывается по песням, вы пропускаете его через вход и смотрите значение скрытого условия. Если было 128 измерений, вы получаете 128-мерный вектор в пространстве песен. Вы тоже можете их кластеризовать и посчитать среднее. И использовать как поведенческие фичи.
А дальше о том, как делать суперсложное решение, которое привело нас к первому месту, расскажет очаровательная Дарья, ей слово.
Дарья Соболева:
— Всем привет. Меня зовут Соболева Дарья, я учусь в МГУ на третьем курсе на факультете ВМК на кафедре ММП. Да, у нас было четыре человека в команде. Два человека — Всеволод и Никита Шаповалов — занимались фича-инжинирингом, они парсили API, генерили умные фичи, а я и еще один человек, Николай Попов, строили саму модель.
Я расскажу, какие дополнительные фичи, но не такие умные, как у ребят, мы нагенерили. Обычные, которые всегда используем от соревнования к соревнованию. Хорошая практика — всегда, если у вас есть категориальные признаки, считать размер категории K, среднее значение целевой переменной внутри каждой категории. Плюс из-за того, что мы каким-то образом задействуем целевую переменную, это легко может привести к переобучению. Если у вас, например, какая-то категория слишком маленькая и состоит всего из одного значения, то среднее значение целевой переменной внутри этой категории будет просто совпадать с этой целевой переменной. То есть мы будем переобучаться.
Известная техника — сглаженная средняя целевой переменной, которая была рассказана еще Стасом Семеновым. Это формула. Давайте посчитаем глобальное среднее целевой переменной по всему сети и возьмем сглаженное отношение, то есть среднее значение целевой переменной по категории доложим на размер категории и прибавим глобальное среднее, умноженное на magic number 10. На самом деле тут должен стоять параметр альфа. Так как этот параметр надо настраивать по кроссвалидации, у нас времени было не особо, и это не особо влияло, то мы решили поставить просто 10, и оно нормально себя вело.
По этой формуле видно, что если у нас размер категории слишком маленький — например, K стремится к нулю, — то эта формула будет просто превращаться в глобальное среднее. То есть вы будете меньше переобучаться.
После фиче-инжиниринга и таких простых базовых признаков, которые мы нагенерили, мы сабмитнули решение и сразу попали в топ-2.
Затем я решила добавить несколько фичей. Я использую такую технику уже несколько соревнований подряд. Она основана на том, что если мы используем целевую переменную, мы все равно каким-то образом переобучаемся, неизбежно. Поэтому давайте попробуем придумать что-то похожее, только unsupervised, без целевой переменной. Я строю random forest и беру feature importance от него, и беру top K вещественных признаков. Считаю то же самое. Представляю, что этот вещественный признак — целевая переменная. Будем считать по ним статистику.
Чем это хорошо? В первую очередь, если у вас задача бинарной классификации, то у вас целевая переменная просто 0 и 1, и ничего хорошего по категориям, кроме как среднее или сглаженное среднее вы не посчитаете. Если у вас есть хороший вещественный признак, который коррелирует с таргетом или что-то такое, топовый по мнению random forest, то вы можете посчитать разную другую статистику и нагенерить намного больше фичей. Например, я брала максимальное, медианное, среднее, минимальное, всякие квантили. Все это можно запихнуть, и у вас будут некоторые дополнительные признаки.
После того, как мы добавили эти признаки, модель практически сразу стала… Надо заметить, что метрика качества у нас была «Укрок», и долгое время — особенно это было у команд из России — они скрывали свой score. То есть брали 1 минус score, и никто не видел, как оно там работает. Это можно иметь в виду, когда вы участвуете в таких соревнованиях. Финальный score мы узнали только на private leaderboard, а до этого мало кто его видел.
Встал вопрос о том, как валидироваться. Мы решили делать достаточно естественно. Так как в тесте были треки, которые были предложены пользователю позже, чем те, которые были в обучающей выборке, то решено было в валидацию запихнуть последний трек у каждого пользователя, последний по time stamp.
Я на всех соревнованиях стараюсь оценивать качество на трех вещах: на трейне, на валидации и на leaderboard. И желательно, чтобы они как-то коррелировали. Поэтому мы решили построить валидацию следующим образом. Вся статистика, которая считалась по целевой переменной… в текущий момент мы должны смотреть в будущее. Для этого мы брали трейн, отщипывали у каждого юзера по одному треку, засовывали это в тестовую выборку, дальше считали статистику по обучающей выборке на целевой переменной и мерджили уже с нашим новым тестовым объектом.
Мы делали так на пять треков назад, валидация была построена на пять треков назад. Как говорил Сева, там было 7,5 млн объектов, поэтому обучаться на всей истории было очень сложно.
Из-за того, что памяти у нас было очень мало, мы всё делали in place. Когда в трейне мы отщипываем у каждого юзера последний трек, мы действительно удаляем его из трейна, добавляем валидацию и считаем статистику по трейну. Ну и естественно, в какой-то момент это привело к возникновению бага, который потом залетел в топ-1.
Допустим, мы пять треков отщипнули, посчитали всю статистику по обучающей выборке для этих пяти треков для каждого пользователя, сформировали одну модельку. Она обучилась, получила топ-2. Потом снова запустили тот же скрипт, где в трейне уже отсутствуют шесть последних треков у каждого пользователя. Обучили ту же самую модельку, предсказывали то же самое, только она обучалась как бы уже по седьмому, восьмому и так далее до двенадцатого трека у каждого пользователя. Обучили, она дала топ-2. А их среднее дало топ-1. Наверное, это и логично. Мы учитывали интересы пользователя в разные промежутки времени. Скорее всего, поэтому решение и взлетело.
Еще нам очень понравилось соревнование, поэтому после его завершения мы решили еще что-то попробовать. Мы стали топ-1, но при этом было желание совершенствоваться.
Я решила попробовать посчитать статистику по целевой переменной. Мы считали ее по одиночным категориям, по парам категорий (неразборчиво — прим. ред.), но я решила посчитать еще по тройкам. Значительного улучшения я не увидела, там было уже 1500 признаков, и модель достаточно сложная, ансамбль XGBoost. Так что эта идея не прошла.
Прошла другая идея. Николай Попов решил модифицировать (сбой записи — прим. ред.) песни. Мы берем два последовательных трека, прослушанных пользователем, берем «дих» времени между прослушками. Если он укладывается в длительность трека, то делим его на эту самую длительность. И получаем что-то типа рейтинга песни, а в противном случае просто проставляем исходный таргет.
Обучив всё то же самое, но посчитав статистику по преобразованному таргету, мы затем усреднили модель, посчитанную по исходному таргету и по преобразованному — и побили свое решение топ-1. Это всё.
Поделиться с друзьями
samizdam
Суровый оборот, хорошо что не «опускает».