
Не так давно мы посмотрели, как устроены A/Б-эксперименты в Поиске. Руководитель бригады разработки iOS-версии Яндекс.Браузера Андрей Сикерин sav42 на последней встрече CocoaHeads Russia тоже рассказывал про инфраструктуру А/Б-тестирования, только уже в своем проекте.
— Привет, меня зовут Андрей Сикерин, я разрабатываю Яндекс.Браузер для iOS. Я хочу рассказать, что представляет собой платформа экспериментов браузера для iOS, как мы научились ее использовать, поддержали ее более продвинутые возможности, как диагностировать и отлаживать фичи, раскатываемые с помощью системы экспериментов, а еще о том, что же такое источник энтропии и где же хранится монетка.
Итак, начнем. Мы в Браузере для iOS никогда не раскатываем фичу на пользователей сразу. Сначала мы проводим А/Б-тестирование, анализируем продуктовые и технические метрики, чтобы понять, как раскатываемая фича влияет на пользователя, нравится она ему или нет, просаживает ли она какие-то технические метрики. Для этого мы используем аналитику. Наша аналитика выглядит примерно так:
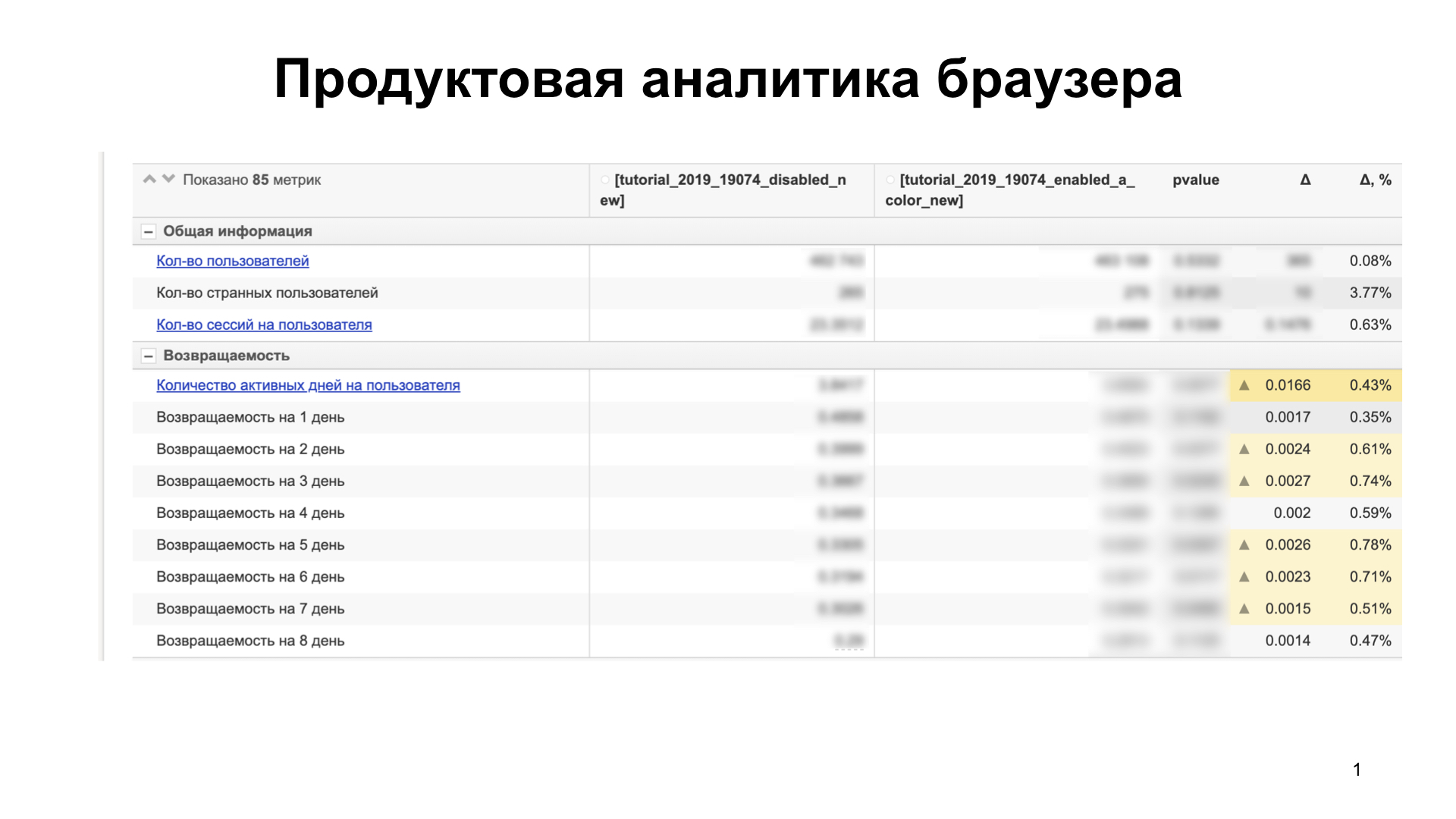
Здесь порядка 85 метрик. Мы сравниваем несколько групп пользователей. Предположим, это увеличивает наши метрики — например, способность продукта удерживать пользователей (retention) — и не просаживает другие, которые не представлены на слайде. Значит, пользователям фича нравится и можно катить на большую группу пользователей.
Если же все-таки мы что-то просаживаем, то разбираемся, почему. Строим гипотезы, подтверждаем их. Если мы просаживаем технические метрики — это является блокером. Исправляем их и перепроводим эксперимент заново. И так пока не прокрасим все. Таким образом, мы выкатываем фичу, которая не является источником регресса.
Давайте расскажу об исходной системе экспериментов, которыми мы пользовались. Она была уже достаточно развита. Потом расскажу, что нас не устраивало.

Первое — она основана на системе экспериментов Chromium и была поддержана в iOS не полностью. Второе — она изначально умела раскатывать фичи на разные группы пользователей и имела систему фильтров, на которую можно было задать требования к устройствам. То есть — версию приложения, из которой фича доступна, локаль устройства — допустим, мы хотим эксперимент только для русской локали. Или версию iOS, на которой эта фича будет доступна, или дату, до которой этот эксперимент будет валидным — например, если мы хотим проводить эксперимент только до какой-то даты. В общем, было множество тегов и это было достаточно удобно.
Сама система экспериментов состоит из файла, в котором содержатся описания конфигураций экспериментов. То есть для одного эксперимента может быть сразу несколько конфигураций. Этот файл — текстовый, он компилируется в protobuf и выкладывается на сервер.
Каждая конфигурация состоит из групп. Есть эксперимент, у него несколько конфигураций, и в каждой из них — несколько групп. Фича в коде привязывается к имени активной группы активной конфигурации. Может показаться достаточно сложным, но сейчас я подробно объясню, что это такое.

Как это работает технически? Файл с описаниями всех конфигураций выкладывается на сервер. При запуске он скачивается браузером с сервера и сохраняется на диск. При следующем запуске мы декодируем этот файл самым первым в цепочке инициализации приложения. И для каждого уникального эксперимента находим одну конфигурацию, которая будет активна.
Активной может стать та конфигурация, которая подходит под заданные и описанные в ней условия. Если есть несколько активных конфигураций, которые подходят под заданные условия, то активируется та конфигурация, которая будет выше в файле.
Дальше в активной конфигурации бросается монетка. Монетка бросается локально, и согласно этой монетке определенным способом, про который я расскажу дальше, выбирается активная группа эксперимента. И именно к имени активной группы эксперимента мы привязываемся в коде, проверяя, доступна наша фича или нет.
Ключевой особенностью этой системы является то, что она ничего сама по себе не хранит. То есть, у нее нет какого-то хранилища на диске. Каждый запуск — мы берем файл, начинаем его калькулировать, находим активную конфигурацию. Внутри конфигурации, согласно монетке, находим активную группу, и система экспериментов для этого эксперимента говорит: выбрана вот эта группа. То есть все калькулируется, ничего не хранится.

Давайте я, собственно, покажу вам файл с описаниями экспериментов. В браузере есть такая фича — Переводчик. Она раскатывалась в эксперименте. Файл начинается с блока study. Конфигурация любого эксперимента начинается с этого блока. Эксперимент называется translator. Таких блоков study с этим именем может быть несколько. И внутри блока study есть много блоков experiment, котоым присвоены различные имена. В данном случае мы видим группу эксперимента enabled. И есть блок filter, который, собственно, и описывает, при каких условиях эта конфигурация может стать активной, то есть ее критерии.
Здесь есть два тега — channel и ya_min_version. Channel означает вид сборки. Тут указана BETA, значит, именно эта конфигурация в файле может стать активной только для тех сборок, которые мы посылаем в TestFlight. Для App Store-сборки эта конфигурация по критерию channel не может стать активной.
ya_min_version означает, что с минимальной версией приложения 19.3.4.43 эта конфигурация может стать активной. Собственно, в этой версии приложения фича уже приобрела такой вид, что можно ее включать.
Это простейшее описание группы конфигурации эксперимента translator. Таких блоков study в файле может быть много. С помощью тегов в блоке filter мы задаем их для разных каналов, для внутренних сборок, для BETA-сборок, для различных критериев.
Здесь одна группа эксперимента, которая называется enabled, и у нее есть тег probability weight, вес группы эксперимента. Это целое неотрицательное число, используемое для определения активной группы в тот момент, когда подкидывается монетка.
Давайте представим, что эта конфигурация на слайде стала активной. То есть мы действительно поставили приложение с public beta, и у нас действительно версия 19.3.4.43 и далее. Как же кинется монетка? Монетка — это случайное число, которое генерируется локально от нуля до единицы.
Чтобы во время следующего запуска мы попадали в ту же самую группу, оно хранится на диске. Пока будем считать так. Далее расскажу, как сделать так, чтобы она не хранилась. Выкидывается монетка. Предположим, выкидывается 0,5. Данная монетка масштабируется в отрезок от нуля до суммы групп экспериментов. В данном случае у нас одна группа enabled, вес у нее 1000, то есть сумма всех групп будет 1000. «0,5» масштабируется в значение 500. Соответственно, все группы экспериментов разбивают отрезок от нуля до суммы экспериментов га промежутки. И активной становится та группа, в чей промежуток будет указывать масштабированное значение монетки.
Имя активной группы экспериментов мы можем спросить в коде и таким образом определить доступность — нужно нам включать фичу или нет.
Дальше мы посмотрим более сложные конфигурации экспериментов, которые мы используем в продакшене. Во-первых, понятно, что на 100% раскатывать фичу глупо, мы используем такое только для beta или для внутренней сборки. Для продакшена мы используем следующую механику.
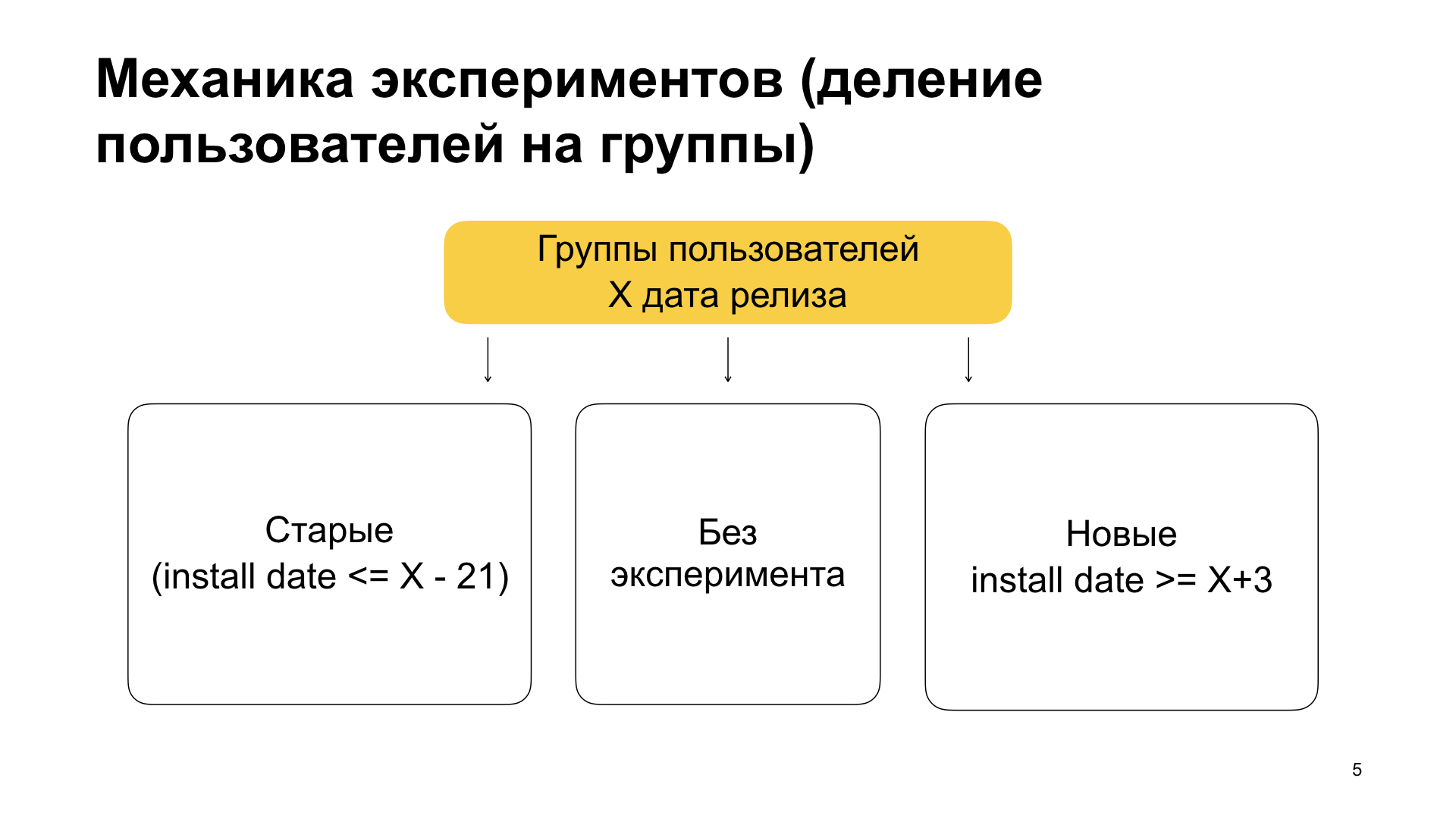
Мы делим пользователей на три группы — старые пользователи, пользователи без эксперимента и новые пользователи. По смыслу это означает следующее. Старые пользователи — это те, которые уже пользовались нашим приложением и поставили приложение с фичей поверх старой версии. То есть они уже пользовались, у них не было фичи, они ко всему привыкли и вдруг обновляют приложение, в котором есть какой-то эксперимент, новая функциональность. Потом — пользователи без эксперимента и новые пользователи. Новые — это те, которые поставили приложение начистую. То есть они никогда не пользовались Яндекс.Браузером, вдруг решили попользоваться и поставили приложение.
Каким образом мы добиваемся этого разбиения? Мы устанавливаем в блоке filter условия на теги min_install_date и max_install_date. Предположим, X равно 14 марта 2019 года — это дата релиза сборки с фичей. Тогда max_install_date для старых пользователей будет X минус 21 день, до релиза сборки с фичей. Если приложение имеет такую install date, то весьма вероятно, что его первый запуск был до релиза. А до релиза была версия без фичи. И если сейчас у него стоит, условно, версия с фичей — значит, он получил приложение с помощью апдейта.
А для новых пользователей мы выставляем min_install_date. Мы выставляем его как X плюс несколько дней. Это означает: если у него такой install date, то есть первый запуск он осуществил после даты релиза версии с фичей, то у него была чистая установка. Он сейчас имеет версию с фичей, но install date был позже, чем эта версия с фичей зарелизилась.
Таким образом, мы разбиваем пользователей на старых, без эксперимента и новых. Мы это делаем, потому что видим: поведение старых пользователей продуктово отличается от поведения новых пользователей. Соответственно, мы можем, допустим, не прокраситься в группе со старыми пользователями, но прокраситься в группе с новыми, или наоборот. Если мы будем делать эксперимент на всей массе, то можем этого не увидеть.

Давайте рассмотрим вот такой эксперимент. Мы видим следующую конфигурацию эксперимента — Переводчик для App Store, новые пользователи. Блок study, имя translator, группа enabled_new. Префикс new означает, что мы описываем конфигурацию для множества пользователей, которые новые. Вес 500 (если сумма всех весов 1000, значит, мощность этого множества — 50%). Control_new, вес 500, это вторая группа. И самое интересное — фильтры для канала STABLE, то есть для сборок, которые собираются для продакшена. Версия, в которой фича появилась: 19.4.1. И здесь есть тег min_install_date. Здесь в формате Unix time зашифровано 18 апреля 2019 года. Это несколько дней после релиза версии 19.4.1.
Здесь есть и еще одна часть кроме префикса new, это enabled и control. Вот префикс control, он не случаен. И помимо того, что мы разбиваем пользователей на новых и старых, мы разбиваем их внутри эксперимента группами еще на несколько частей.
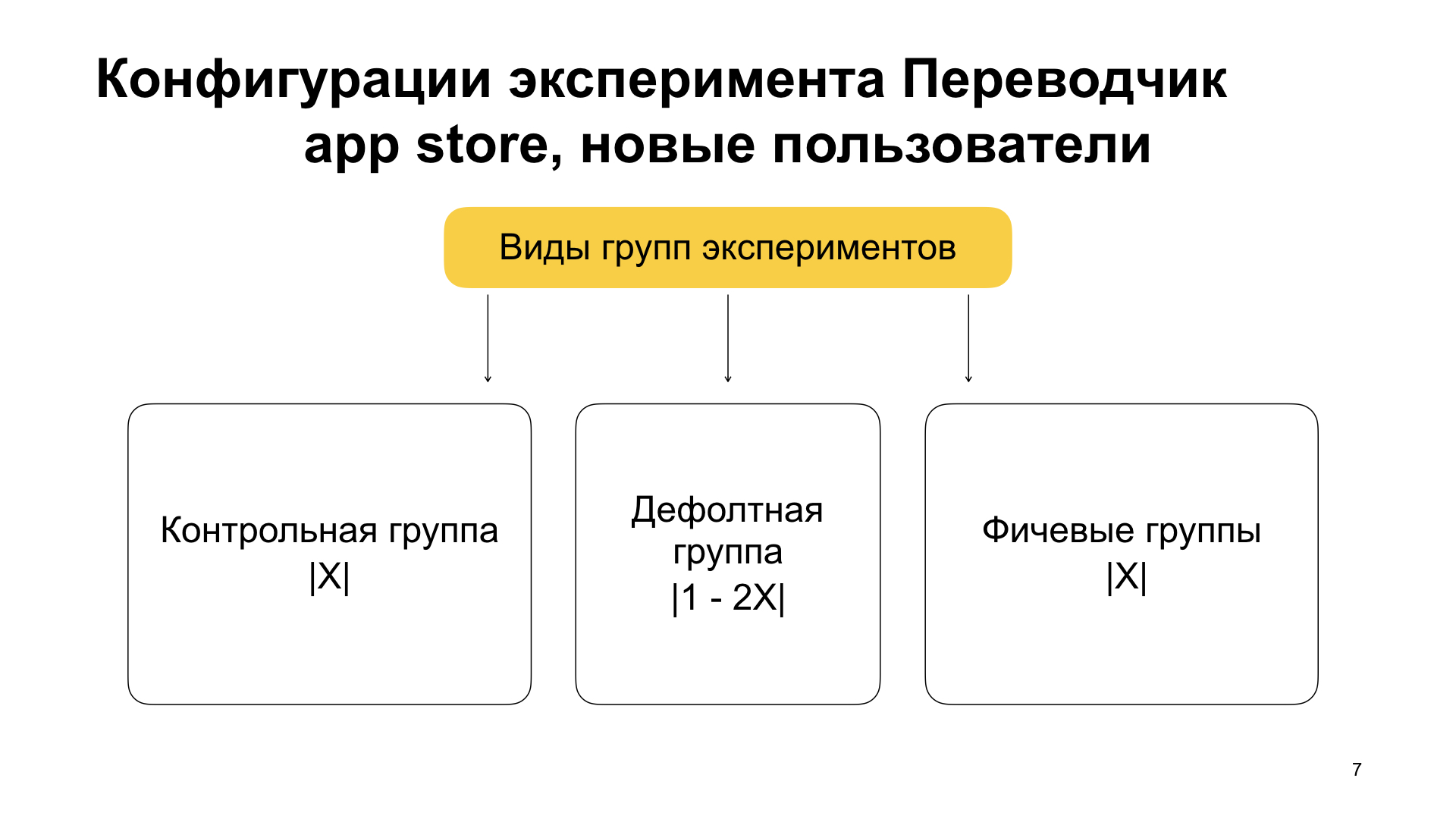
Первая часть пользователей — это контрольная группа, та, которая имеет префикс control. В ней фичи нет. У нее вес X. Также есть фичевая группа, обычно она называется enabled. Она также имеет вес X, и это важно: там фича должна включиться. И есть дефолтная группа, которая имеет вес 1 минус 2X (1000 минус 2X, так как 1000 — значение суммарного веса всех групп внутри одной конфигурации, которое принято у нас по умолчанию). Дефолтная группа тоже никакую фичу не включает. Она просто хранит пользователей, которые остались после разбиения на контрольную и фичевую. Также из нее можно перепровести эксперимент, если это нужно.

Давайте посмотрим, скажем, конфигурацию для старых пользователей. Мы увидим здесь фичевую и контрольную группу. enabled_old — фичевая. control_old, — контрольная, 10%. default_old — дефолтная, 80%.
Обратим внимание на filter, ya_min_version 19.4.1, max_install_date 28 марта 2019 года. Это дата раньше, чем дата релиза. Соответственно, это конфигурация со списком пользователей, которые получили версию 19.4.1 после апдейта. Они пользовались приложением и теперь пользуются новой версией.
Для чего нужны фичевые и контрольные группы? В той аналитике, которую я показывал на первом слайде, мы сравниваем контрольную группу и фичевую. Они обязаны быть равной мощности, чтобы их продуктовые метрики можно было сравнить.
Таким образом, мы сравниваем контрольную и фичевую группу в аналитике для разных групп пользователей, — старых и новых. Если мы все прокрашиваем, то катим фичу на 100%.

Как работает разработчик кода с этой системой? Он знает имена фичевых групп, дату, когда нужно включить фичу, и пишет некоторый слой доступа, это псевдокод, запрашивая по имени эксперимента активную группу. Ее может не быть. Собственно, все конфигурации могут не подойти под условия устройства. Тогда вернется пустая строка.
После этого, если имя активной группы является фичевой, то надо фичу включить, иначе — выключить. Далее эта функция уже используется в коде, который включает функциональность в коде браузера.

Так мы прожили с этой системой экспериментов несколько лет. Все было хорошо, но выявили ряд недостатков. Первый недостаток такого подхода, это то, что невозможно добавить новые группы эксперимента без исправления кода. То есть, если имя эксперимента маловероятно, что поменяется для фичи, то добавить еще пару дополнительных групп, это запросто может быть. Но ваш код доступности фичи таких групп не знает, потому что вы не предусмотрели это заранее. Соответственно, надо перекатывать версию, с этой версией проводить эксперименты, что является проблемой. То есть надо, именно изменив код, пересобирать и постить в App Store.
Второе, нельзя раскатить части фичи или разбить фичу на части уже после того, как вы начали эксперимент. То есть, если вы вдруг решили, что часть фичи можно было бы выкатить, а часть еще оставить в эксперименте, то так сделать нельзя, надо было заранее продумывать и разбивать эту фичу на две, и независимо их в эксперименте принимать.
Третье, нельзя конфигурировать фичу или сравнивать конфигурации. В Переводчике, например, есть параметр — время timeout к API Переводчика. То есть, если мы не успели перевести за сколько-то миллисекунд, то мы говорим, что, попробуй еще раз, ошибка, не повезло.
Задать этот timeout в эксперименте невозможно, потому что нам, либо нужно именно группы фиксировать и сразу заранее, допустим заранее иметь следующие группы — enabled_with_300_ms, enabled_with_600_ms в именах которых закодировано значение параметра. Но задать как-то именно численно параметр нельзя. Если мы это не продумали заранее, то мы уже не можем так сравнить несколько конфигураций.
Четвертое, аналитики и разработчики вынуждены согласовывать названия групп заранее. То есть чтобы разработчику начать разработку фичи, он обычно начинает, собственно, с политики доступности этой фичи. И ему нужно знать имена фичевых групп. А для этого аналитик должен объяснить механику эксперимента — будем ли мы разделять пользователей на новых и старых или все пользователи окажутся в одной группе без деления.
Или это может быть обратный эксперимент. Например, мы можем сразу посчитать, что фича включена, но иметь возможность выключить ее. Аналитику это не очень интересно, потому что фича не готова. Он определит механику эксперимента, когда она будет готова. А разработчику требуются названия групп и механика эксперимента заранее, иначе ему постоянно придется вносить изменения в код.
Мы посовещались и решили, что хватит это терпеть. Так родился проект Make Experiments Great Again.

Ключевая идея этого проекта заключается в следующем. Если раньше мы привязывались к коду, кодом к именам групп активных, которые нам передавал аналитик, то теперь мы внесли две дополнительные сущности. Это фича (Feature) и параметр фичи (FeatureParam). И, таким образом, программист придумывает фичи и фиче-параметры самостоятельно, выбирая для них идентификаторы, выбирая для них дефолтные значения, и программирует относительно них доступность фичи.
После этого он сообщает эти идентификаторы аналитику, и аналитик, продумывая механику экспериментов, указывает специальным образом их в группах эксперимента с помощью тега feature_association. Если эта группа становится активной, то не забудь, пожалуйста, включить или выключить фичу с идентификатором таким-то, и задать параметры с такими-то идентификаторами.

Как это выглядит в файле с конфигурациями экспериментов? Вот мы смотрим группу эксперимента. Имя enabled, добавляется дополнительный тег feature_association, в этом теге команды enable_feature или disable_feature, и добавляются идентификаторы.
Также есть блок param, которых может быть несколько. Тут тоже есть имя — timeout, и добавляется значение, которое надо установить.

Как это выглядит из кода? Программист объявляет сущности класса Feature и FeatureParam. И в слой доступа к фиче прописывает значения из этих примитивов. Затем он передает этот идентификатор аналитику, и он уже в файле конфигураций задает идентификаторы в блоке группы эксперимента с помощью тега feature_association. Как только группа эксперимента становится активной, значения фич и параметров с этими идентификаторами в коде задаются из файла. Если в группе нет параметров и фич — используются дефолтные значения, которые указаны из кода.
Казалось бы, что это нам дало? Во-первых, аналитику теперь при добавлении новой группы не нужно просить программиста добавить новую фичевую группу в код, потому что слой доступа к данным оперирует идентификаторами, которые не изменяются при добавлении новой группы в систему экспериментов.
Во-вторых, мы разнесли время, когда программисты придумывают эти идентификаторы для фич и параметров фич, со временем, когда аналитик разрабатывает механику эксперимента. Аналитик разрабатывает тогда, когда фича готова, а программист придумывает эти идентификаторы тогда, когда он пишет код, в самом начале.
Также это позволяет разбить фичу на части. Допустим, здесь есть фича Переводчик, translator, которая включает, собственно, Переводчик. А есть фича TranslateServiceAPITimeout, она включает дополнительную функциональность, которая может задать кастомный timeout к API Переводчика. Таким образом, мы можем сделать две группы экспериментов, в обеих из которых Переводчик включен, но при этом мы сравниваем, какое значение лучше: 300 миллисекунд или 600.
То есть можно разбить фичу на подфичи и потом часть подфич включить в эксперименте в разных группах. И сравнивать. А можно конфигурировать одну и ту же фичу разными параметрами за счет новых сущностей параметра фичи (FeatureParam).
Казалось бы, мы решили все проблемы, победа, можно праздновать. Но, нет, за нами пришли. Пришли за нами не другие разработчики, не аналитики, не менеджеры. Пришло за нами тестирование. В чем заключалась проблема тестирования?

Первая проблема, которую мы породили: нельзя задать принудительно Feature и FeatureParam. В этой системе Feature и FeatureParam задаются с сервера. Соответственно, чтобы задать с сервера Feature и FeatureParam, тестированию нужно катить файл с конфигурациями, хотя бы для внутренней сборки. Они этого не умеют. Или же попадать по-честному в группу новых пользователей, старых пользователей, что тоже очень сложно.
Во-вторых, нельзя посмотреть значение Feature&FeatureParam. Значение фич можно посмотреть косвенно, то есть мы видим «Переводчик», значит, наверное, фича включена. А вот значение FeatureParam посмотреть тяжело, потому что как мы определим, каким был таймаут к API Переводчика — 300 или 600 миллисекунд?
И третья проблема. О ней я говорил в первом пункте. Чтобы тестировщику что-то изменить, ему нужно выкатить измененный файл с конфигурациями эксперимента в продакшене. Даже если в файл с конфигурациями добавлены конфигурации с фильтром для внутренней сборки и для public beta, все равно этот файл нужно выкатить в продакшен на сервер. А выкатка в продакшен обладает определенными требованиями, определенным емким процессом.
Таким образом, мы столкнулись с проблемой: тестировщику стало тяжело тестировать еще не вышедшую фичу заранее.

Как мы решили эту проблему? Я сначала перечислю пункты с мерами, которые мы приняли, а потом расскажу подробнее о каждом из пунктов.
Первое: мы начали использовать новый сервис для выкладки файла с конфигурациями и сделали настройку подмены источника для этого файла. То есть подмену URL, на который ходит браузер, чтобы скачать файл с описанием конфигурации.
Второе: мы на служебной странице browser://version поддержали еще один параметр — show-variations-cmd. Третье: мы разработали систему вспомогательных cheat-урлов, дополняющих систему экспериментов снаружи. И четвертое: мы начали разрабатывать диагностический экран.
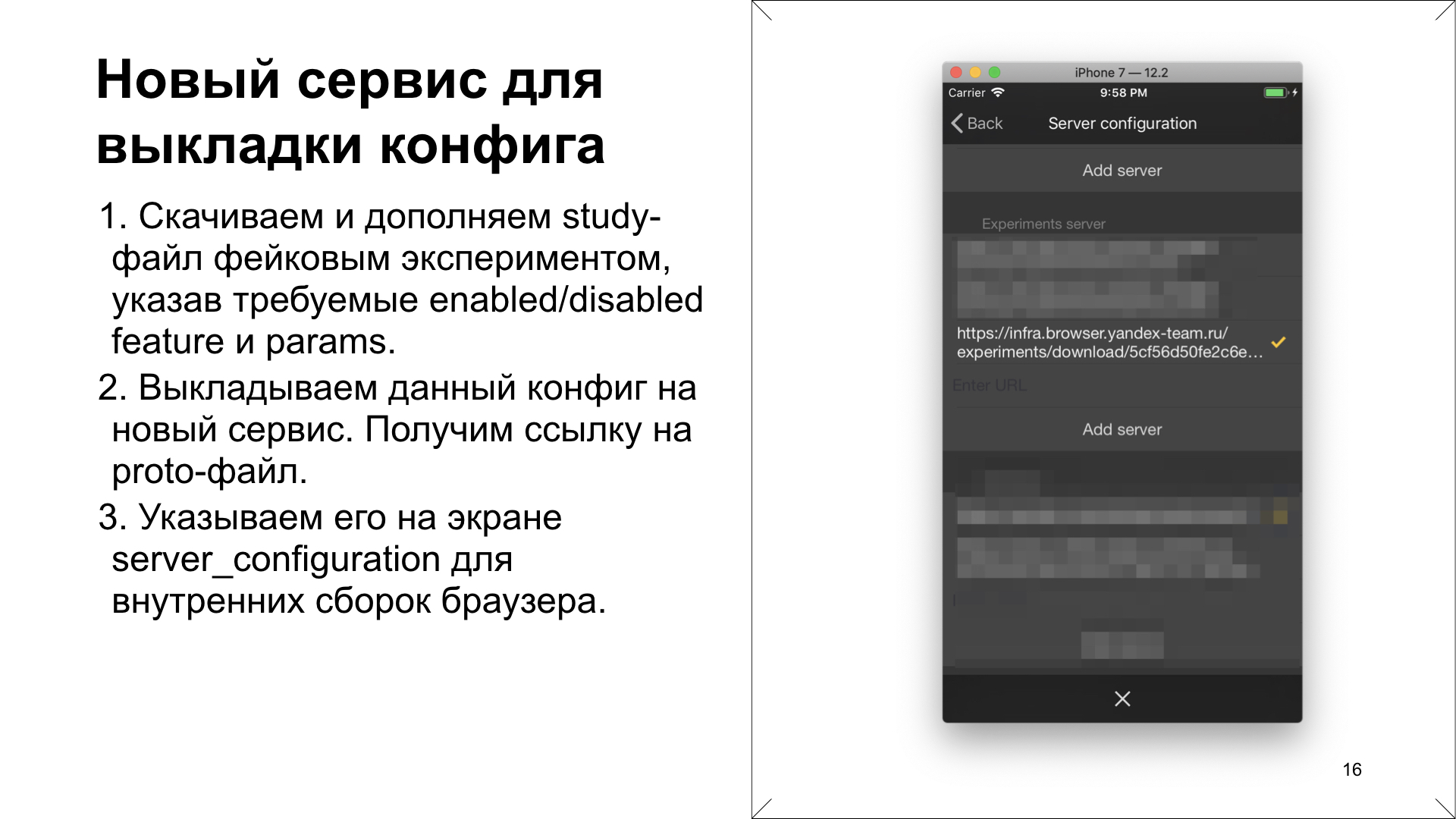
Давайте про первый пункт. Новый сервис для выкладки файла с конфигурациями заключался в том, что мы скачиваем файл с конфигурациями экспериментов в продакшене. Далее тестировщик его декодирует из proto-файла обратно в текстовый файл и после этого дополняет конфигурацию какой-то своей конструкцией, новым study-блоком, который ему нужен. Может быть, с упрощенными фильтрами. И там задает значения Feature&FeatureParam, которые ему требуются для тестирования. Он видит этот файл с конфигурациями экспериментов, и он точно знает, что в эту конфигурацию будет попадать приложение. Там ровно одна группа, значит, Feature&FeatureParam будут равны заданным.
Затем он этот текстовый файл выкладывает на новый сервис. И сервис обратно компилирует его в proto-файл и выдает ссылку. Эту ссылку он указывает на диагностическом экране. Для внутренних сборок существуют диагностические экраны, ниже один из них. Он указывает, что нужно использовать его ссылку, а не дефолтную.

Второе. Как посмотреть значение Feature&FeatureParam? Здесь мы поддержали механизмы Chromium, которые генерируют служебную страницу. Chromium генерирует дополнительный блок на странице browser://version, если указать параметр show-variations-cmd.
Этот блок состоит из трех ключей: enabled-features, force-fieldtrials и force-fieldtrials-params, который с первого взгляда похож на абракадабру. Но если разобраться, он имеет смысл. Что это означает? Это означает содержимое всей системы экспериментов, как будто мы запустили наш браузер из командной строки. Здесь написано, что Feature1 активируется экспериментом с именем trial1. Feature2 активируется экспериментом с именем trial2. Feature3 активируется просто так.
У эксперимента trial1 задана активная группа group1. У эксперимента trial2 задана активная группа group2. И последний force-fieldtrials-params, параметр означает, что если эксперимент имени trial1 попадает в группу group1, то в него нужно выставить параметры p1 равный v1, p2 равный v2. А если trial2 попадает в группу group2, то нужно выставить параметр p3 равный v3, p4 равный v4.
Может показаться запутанно, но этот код мы переиспользовали. То есть это стандартный механизм генерации служебной страницы из Chromium, который мы просто поддержали в iOS. То есть мы переиспользовали кодовую базу для того, чтобы написать свой механизм.
Давайте попробуем на примере. Наш эксперимент Переводчик ключом --force-fieldtrials=translator/enabled_new/ устанавливает группу enabled_new для эксперимента translator.
Далее идет ключ --force-fieldtrial-params==translator.enablew_new:timeout/5000, если вдруг эксперимент translator попадает в группу enabled_new, а мы видим, что в первом ключе он в нее попадает, то для эксперимента translator, для группы enabled_new нужно выставить значение параметра timeout, равное 5 000 миллисекунд.
И последний флаг --enabled-features=TranslateServiceAPITimeout<translator говорит, что если вдруг какая-то группа в эксперименте translator в эксперименте translator активна, то включите, пожалуйста, фичу TranslateServiceAPITimeout. То есть, умея читать такой формат, мы можем все содержимое системы экспериментов посмотреть, какая группа выбрана, какие в этой группе фичи были включены и какие параметры были заданы.

Также мы разработали систему вспомогательных урлов (cheat urls). Это, конечно, прекрасно, что мы можем взятьь файл с конфигурациями экспериметов, декодировать его, дополнить его определенной группой, выложить на сервер и задать эту ссылку. Но это достаточно долго. И на первых порах мы с этим жили. Но после определенного момента мы поддержали ссылку.
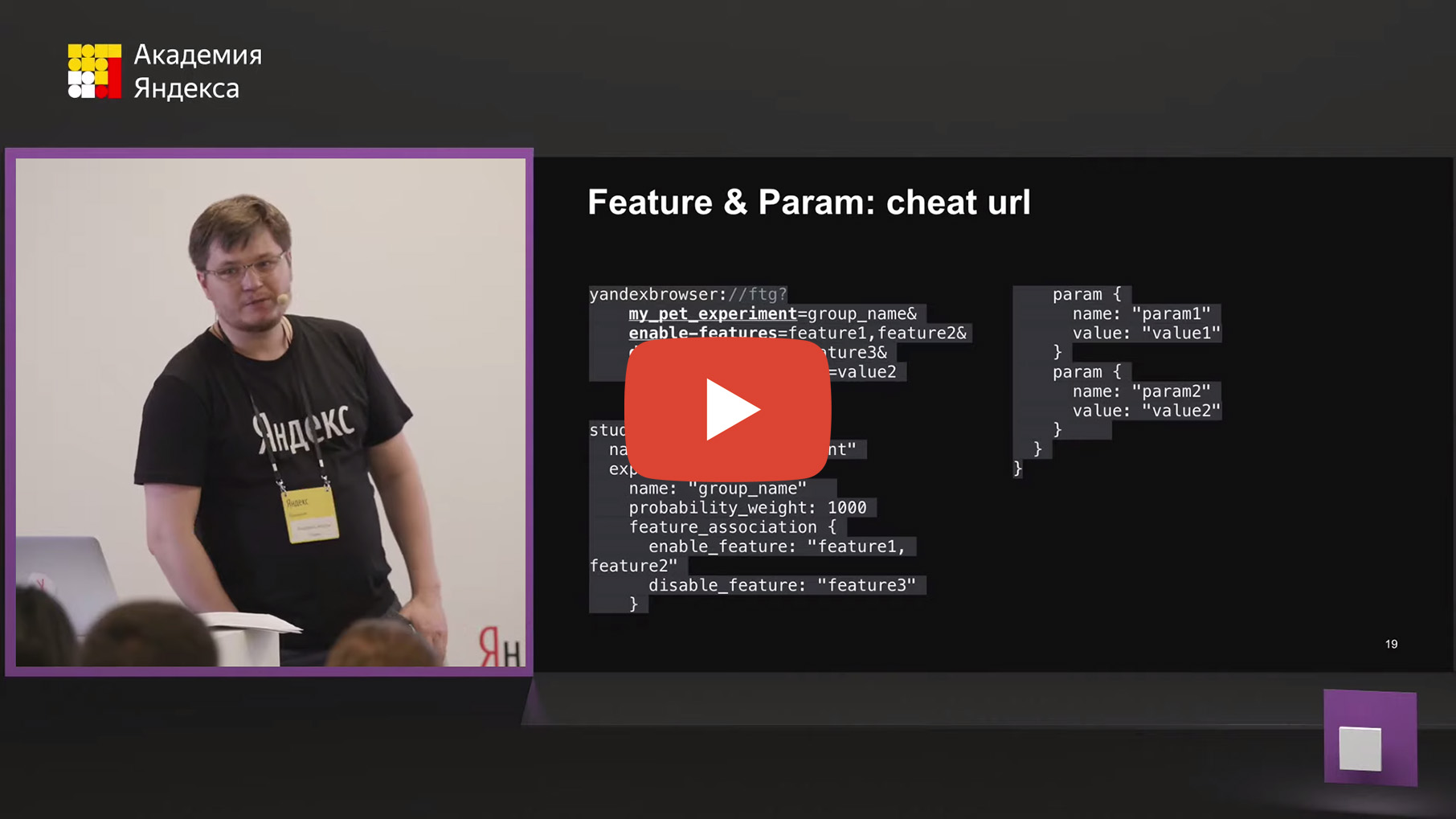
Мы разработали ссылку с кастомной схемой yandexbrowser:// (Яндекс.Браузер), которая имела следующий формат, который представлен на слайде. То есть у нее было четыре части. Первая часть это my_pet_experiment=group_name. Вторая часть, это параметр enable-features=, где перечисляется список фич который нужно включить, потом параметр disable-features=, где перечисляется список фич которые нужно выключить. И дальше идут просто параметры, которые через &.
Если вы запустите такую вспомогательную ссылку (cheat url), то система экспериментов дополнится служебной информацией. Эта служебная информация будет передаваться каждый старт, помимо, собственно, скачанного файла с конфигурациями экспериментов. И она будет генерировать конфигурацию эксперимента, из информации указанной в ссылке по шаблону представленному на слайде, которая будет в файле в самом начале. При этом она не будет содержать блок filter, поэтому эксперимент my_pet_experiment гарантированно будет попадать в группу, которую вы зададите в ссылке. Вероятность этой группы будет 1000, у нее будет feature_association, которую вы задали в ссылке, а также заданные вами параметры.
Таким образом, тестирование облегчилось. Тестировщик берет ссылку, формирует ее, запускает в приложении. И он точно уверен, что теперь именно у эксперимента с нужным именем — в данном случае my_pet_experiment — точно будут заданные значения, такие, какие он хочет. Неважно, скачала ли система экспериментов файл и какой файл она скачала, потому что этот блок study идет выше всего.
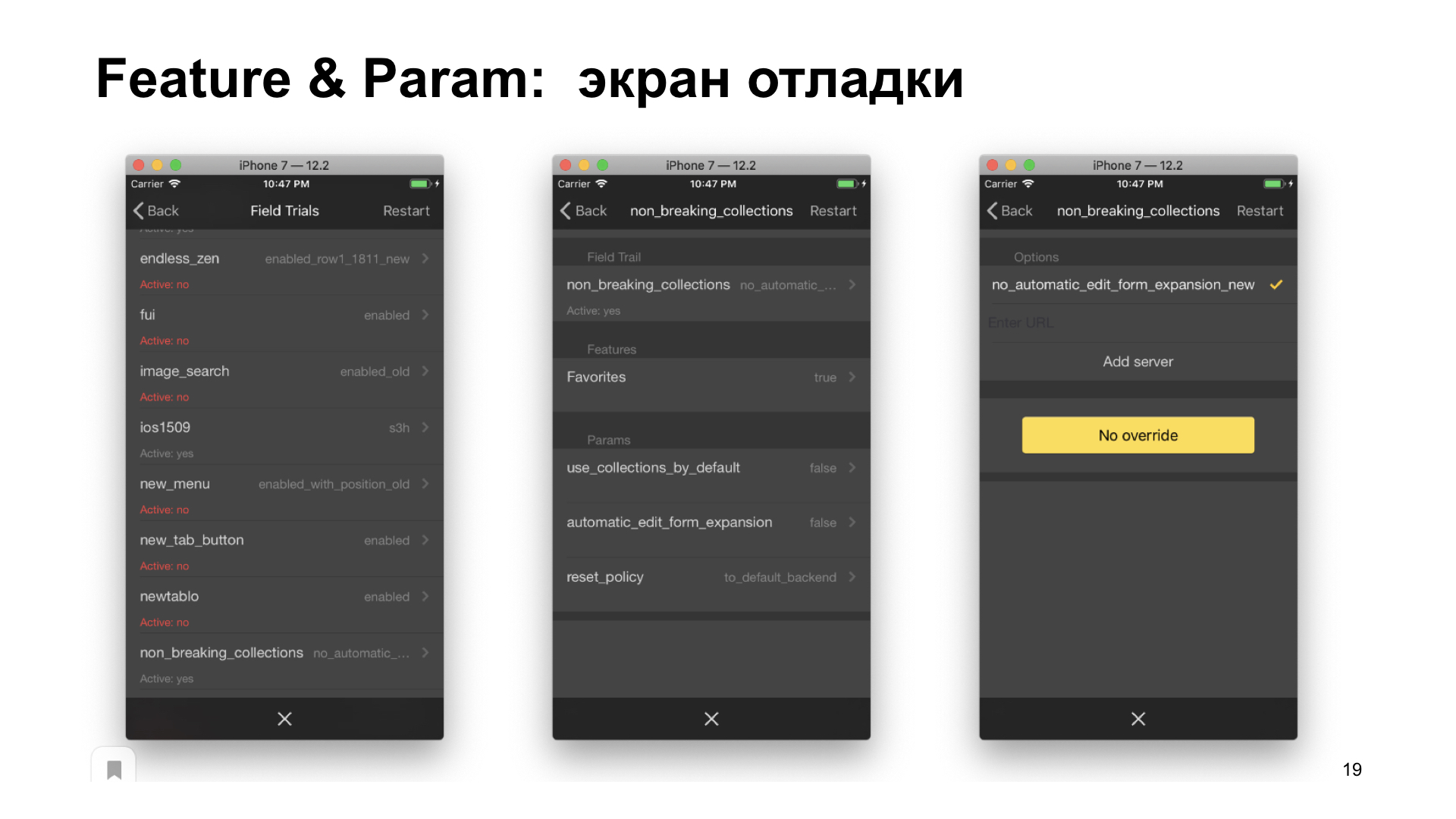
Также мы делаем экран отладки, который показывает экран значений экспериментов выбранной группы. Если зайти дальше — показываются значения фич, параметров. Еще дальше мы можем перегрузить или задать новые значения. Перечисленные меры облегчили тестирование, решили его задачи и вывели тестирование на новый уровень.
Теперь я вам расскажу, где хранится монетка и что же такое источник энтропии.

Монетка, напомню, это случайное число из промежутка от нуля до единицы, которое выкидывается для того, чтобы в активной конфигурации определить активную группу эксперимента. Оно должно храниться на диске, чтобы при следующем запуске вашего приложения вы не выбрали другую группу эксперимента. То есть если условия не изменились и вы запускаете приложение в следующий раз, вы должны попадать в ту же самую группу той же самой конфигурации.
Но хранить монетку на диске может показаться избыточно и опасно. Генерация монетки должна быть одинаковой от запуска к запуску. Казалось бы, если вы используете генератор случайных чисел, как это обеспечить? Также необходимо равномерно распределять пользователей по группам, что вообще отсекает варианты. Как же не хранить монетку, обеспечив все эти три критерия?
Это возможно. Используется следующий прием.

Генерируется случайная строка, так называемый источник энтропии. Каждое приложение в браузере хранит, например, UUID, то есть уникальным способом генерируется application Identifier, сохраняется на диск. Эта случайная строка объединяется с именем эксперимента. После этого hash переводится в значение от нуля до единицы.
Почему это работает? Будет ли это число случайным? Да, будет, потому что у вас есть случайно сгенерированный компонент в качестве UUID, то есть по всем устройствам это число будет случайное. Будет ли оно различаться на одном и том же устройстве от эксперимента к эксперименту? Да, будет, потому что вы объединяете источник энтропии с именем эксперимента. А имя эксперимента различно для разных экспериментов. Будет ли оно равномерно распределено? Если вы используете правильный hash и правильный перевод из уже сгенерированного hash в вещественное число от нуля до единицы, то будет. Как этой делать, показано в статье от Google, которая называется An Efficient Low-Entropy Provider.
Таким образом, вы можете в своей системе экспериментов хранить на диске только одно значение — UUID, а генерировать монетку, которая будет равномерно распределена, уже согласно алгоритму. Такой же алгоритм использует, например, сама система Chromium.
Какую систему экспериментов, по нашему мнению, стоит использовать? Какие критерии к ней предъявляются? Она должна быть:
Система Chromium, которую мы расширяем в Яндекс.Браузере для iOS, такими критериями обладает. Проводите ваши эксперименты, анализируйте их и делайте приложения лучше. Спасибо.
— Привет, меня зовут Андрей Сикерин, я разрабатываю Яндекс.Браузер для iOS. Я хочу рассказать, что представляет собой платформа экспериментов браузера для iOS, как мы научились ее использовать, поддержали ее более продвинутые возможности, как диагностировать и отлаживать фичи, раскатываемые с помощью системы экспериментов, а еще о том, что же такое источник энтропии и где же хранится монетка.
Итак, начнем. Мы в Браузере для iOS никогда не раскатываем фичу на пользователей сразу. Сначала мы проводим А/Б-тестирование, анализируем продуктовые и технические метрики, чтобы понять, как раскатываемая фича влияет на пользователя, нравится она ему или нет, просаживает ли она какие-то технические метрики. Для этого мы используем аналитику. Наша аналитика выглядит примерно так:
Здесь порядка 85 метрик. Мы сравниваем несколько групп пользователей. Предположим, это увеличивает наши метрики — например, способность продукта удерживать пользователей (retention) — и не просаживает другие, которые не представлены на слайде. Значит, пользователям фича нравится и можно катить на большую группу пользователей.
Если же все-таки мы что-то просаживаем, то разбираемся, почему. Строим гипотезы, подтверждаем их. Если мы просаживаем технические метрики — это является блокером. Исправляем их и перепроводим эксперимент заново. И так пока не прокрасим все. Таким образом, мы выкатываем фичу, которая не является источником регресса.
Давайте расскажу об исходной системе экспериментов, которыми мы пользовались. Она была уже достаточно развита. Потом расскажу, что нас не устраивало.
Первое — она основана на системе экспериментов Chromium и была поддержана в iOS не полностью. Второе — она изначально умела раскатывать фичи на разные группы пользователей и имела систему фильтров, на которую можно было задать требования к устройствам. То есть — версию приложения, из которой фича доступна, локаль устройства — допустим, мы хотим эксперимент только для русской локали. Или версию iOS, на которой эта фича будет доступна, или дату, до которой этот эксперимент будет валидным — например, если мы хотим проводить эксперимент только до какой-то даты. В общем, было множество тегов и это было достаточно удобно.
Сама система экспериментов состоит из файла, в котором содержатся описания конфигураций экспериментов. То есть для одного эксперимента может быть сразу несколько конфигураций. Этот файл — текстовый, он компилируется в protobuf и выкладывается на сервер.
Каждая конфигурация состоит из групп. Есть эксперимент, у него несколько конфигураций, и в каждой из них — несколько групп. Фича в коде привязывается к имени активной группы активной конфигурации. Может показаться достаточно сложным, но сейчас я подробно объясню, что это такое.
Как это работает технически? Файл с описаниями всех конфигураций выкладывается на сервер. При запуске он скачивается браузером с сервера и сохраняется на диск. При следующем запуске мы декодируем этот файл самым первым в цепочке инициализации приложения. И для каждого уникального эксперимента находим одну конфигурацию, которая будет активна.
Активной может стать та конфигурация, которая подходит под заданные и описанные в ней условия. Если есть несколько активных конфигураций, которые подходят под заданные условия, то активируется та конфигурация, которая будет выше в файле.
Дальше в активной конфигурации бросается монетка. Монетка бросается локально, и согласно этой монетке определенным способом, про который я расскажу дальше, выбирается активная группа эксперимента. И именно к имени активной группы эксперимента мы привязываемся в коде, проверяя, доступна наша фича или нет.
Ключевой особенностью этой системы является то, что она ничего сама по себе не хранит. То есть, у нее нет какого-то хранилища на диске. Каждый запуск — мы берем файл, начинаем его калькулировать, находим активную конфигурацию. Внутри конфигурации, согласно монетке, находим активную группу, и система экспериментов для этого эксперимента говорит: выбрана вот эта группа. То есть все калькулируется, ничего не хранится.
Давайте я, собственно, покажу вам файл с описаниями экспериментов. В браузере есть такая фича — Переводчик. Она раскатывалась в эксперименте. Файл начинается с блока study. Конфигурация любого эксперимента начинается с этого блока. Эксперимент называется translator. Таких блоков study с этим именем может быть несколько. И внутри блока study есть много блоков experiment, котоым присвоены различные имена. В данном случае мы видим группу эксперимента enabled. И есть блок filter, который, собственно, и описывает, при каких условиях эта конфигурация может стать активной, то есть ее критерии.
Здесь есть два тега — channel и ya_min_version. Channel означает вид сборки. Тут указана BETA, значит, именно эта конфигурация в файле может стать активной только для тех сборок, которые мы посылаем в TestFlight. Для App Store-сборки эта конфигурация по критерию channel не может стать активной.
ya_min_version означает, что с минимальной версией приложения 19.3.4.43 эта конфигурация может стать активной. Собственно, в этой версии приложения фича уже приобрела такой вид, что можно ее включать.
Это простейшее описание группы конфигурации эксперимента translator. Таких блоков study в файле может быть много. С помощью тегов в блоке filter мы задаем их для разных каналов, для внутренних сборок, для BETA-сборок, для различных критериев.
Здесь одна группа эксперимента, которая называется enabled, и у нее есть тег probability weight, вес группы эксперимента. Это целое неотрицательное число, используемое для определения активной группы в тот момент, когда подкидывается монетка.
Давайте представим, что эта конфигурация на слайде стала активной. То есть мы действительно поставили приложение с public beta, и у нас действительно версия 19.3.4.43 и далее. Как же кинется монетка? Монетка — это случайное число, которое генерируется локально от нуля до единицы.
Чтобы во время следующего запуска мы попадали в ту же самую группу, оно хранится на диске. Пока будем считать так. Далее расскажу, как сделать так, чтобы она не хранилась. Выкидывается монетка. Предположим, выкидывается 0,5. Данная монетка масштабируется в отрезок от нуля до суммы групп экспериментов. В данном случае у нас одна группа enabled, вес у нее 1000, то есть сумма всех групп будет 1000. «0,5» масштабируется в значение 500. Соответственно, все группы экспериментов разбивают отрезок от нуля до суммы экспериментов га промежутки. И активной становится та группа, в чей промежуток будет указывать масштабированное значение монетки.
Имя активной группы экспериментов мы можем спросить в коде и таким образом определить доступность — нужно нам включать фичу или нет.
Дальше мы посмотрим более сложные конфигурации экспериментов, которые мы используем в продакшене. Во-первых, понятно, что на 100% раскатывать фичу глупо, мы используем такое только для beta или для внутренней сборки. Для продакшена мы используем следующую механику.
Мы делим пользователей на три группы — старые пользователи, пользователи без эксперимента и новые пользователи. По смыслу это означает следующее. Старые пользователи — это те, которые уже пользовались нашим приложением и поставили приложение с фичей поверх старой версии. То есть они уже пользовались, у них не было фичи, они ко всему привыкли и вдруг обновляют приложение, в котором есть какой-то эксперимент, новая функциональность. Потом — пользователи без эксперимента и новые пользователи. Новые — это те, которые поставили приложение начистую. То есть они никогда не пользовались Яндекс.Браузером, вдруг решили попользоваться и поставили приложение.
Каким образом мы добиваемся этого разбиения? Мы устанавливаем в блоке filter условия на теги min_install_date и max_install_date. Предположим, X равно 14 марта 2019 года — это дата релиза сборки с фичей. Тогда max_install_date для старых пользователей будет X минус 21 день, до релиза сборки с фичей. Если приложение имеет такую install date, то весьма вероятно, что его первый запуск был до релиза. А до релиза была версия без фичи. И если сейчас у него стоит, условно, версия с фичей — значит, он получил приложение с помощью апдейта.
А для новых пользователей мы выставляем min_install_date. Мы выставляем его как X плюс несколько дней. Это означает: если у него такой install date, то есть первый запуск он осуществил после даты релиза версии с фичей, то у него была чистая установка. Он сейчас имеет версию с фичей, но install date был позже, чем эта версия с фичей зарелизилась.
Таким образом, мы разбиваем пользователей на старых, без эксперимента и новых. Мы это делаем, потому что видим: поведение старых пользователей продуктово отличается от поведения новых пользователей. Соответственно, мы можем, допустим, не прокраситься в группе со старыми пользователями, но прокраситься в группе с новыми, или наоборот. Если мы будем делать эксперимент на всей массе, то можем этого не увидеть.
Давайте рассмотрим вот такой эксперимент. Мы видим следующую конфигурацию эксперимента — Переводчик для App Store, новые пользователи. Блок study, имя translator, группа enabled_new. Префикс new означает, что мы описываем конфигурацию для множества пользователей, которые новые. Вес 500 (если сумма всех весов 1000, значит, мощность этого множества — 50%). Control_new, вес 500, это вторая группа. И самое интересное — фильтры для канала STABLE, то есть для сборок, которые собираются для продакшена. Версия, в которой фича появилась: 19.4.1. И здесь есть тег min_install_date. Здесь в формате Unix time зашифровано 18 апреля 2019 года. Это несколько дней после релиза версии 19.4.1.
Здесь есть и еще одна часть кроме префикса new, это enabled и control. Вот префикс control, он не случаен. И помимо того, что мы разбиваем пользователей на новых и старых, мы разбиваем их внутри эксперимента группами еще на несколько частей.
Первая часть пользователей — это контрольная группа, та, которая имеет префикс control. В ней фичи нет. У нее вес X. Также есть фичевая группа, обычно она называется enabled. Она также имеет вес X, и это важно: там фича должна включиться. И есть дефолтная группа, которая имеет вес 1 минус 2X (1000 минус 2X, так как 1000 — значение суммарного веса всех групп внутри одной конфигурации, которое принято у нас по умолчанию). Дефолтная группа тоже никакую фичу не включает. Она просто хранит пользователей, которые остались после разбиения на контрольную и фичевую. Также из нее можно перепровести эксперимент, если это нужно.
Давайте посмотрим, скажем, конфигурацию для старых пользователей. Мы увидим здесь фичевую и контрольную группу. enabled_old — фичевая. control_old, — контрольная, 10%. default_old — дефолтная, 80%.
Обратим внимание на filter, ya_min_version 19.4.1, max_install_date 28 марта 2019 года. Это дата раньше, чем дата релиза. Соответственно, это конфигурация со списком пользователей, которые получили версию 19.4.1 после апдейта. Они пользовались приложением и теперь пользуются новой версией.
Для чего нужны фичевые и контрольные группы? В той аналитике, которую я показывал на первом слайде, мы сравниваем контрольную группу и фичевую. Они обязаны быть равной мощности, чтобы их продуктовые метрики можно было сравнить.
Таким образом, мы сравниваем контрольную и фичевую группу в аналитике для разных групп пользователей, — старых и новых. Если мы все прокрашиваем, то катим фичу на 100%.
Как работает разработчик кода с этой системой? Он знает имена фичевых групп, дату, когда нужно включить фичу, и пишет некоторый слой доступа, это псевдокод, запрашивая по имени эксперимента активную группу. Ее может не быть. Собственно, все конфигурации могут не подойти под условия устройства. Тогда вернется пустая строка.
После этого, если имя активной группы является фичевой, то надо фичу включить, иначе — выключить. Далее эта функция уже используется в коде, который включает функциональность в коде браузера.
Так мы прожили с этой системой экспериментов несколько лет. Все было хорошо, но выявили ряд недостатков. Первый недостаток такого подхода, это то, что невозможно добавить новые группы эксперимента без исправления кода. То есть, если имя эксперимента маловероятно, что поменяется для фичи, то добавить еще пару дополнительных групп, это запросто может быть. Но ваш код доступности фичи таких групп не знает, потому что вы не предусмотрели это заранее. Соответственно, надо перекатывать версию, с этой версией проводить эксперименты, что является проблемой. То есть надо, именно изменив код, пересобирать и постить в App Store.
Второе, нельзя раскатить части фичи или разбить фичу на части уже после того, как вы начали эксперимент. То есть, если вы вдруг решили, что часть фичи можно было бы выкатить, а часть еще оставить в эксперименте, то так сделать нельзя, надо было заранее продумывать и разбивать эту фичу на две, и независимо их в эксперименте принимать.
Третье, нельзя конфигурировать фичу или сравнивать конфигурации. В Переводчике, например, есть параметр — время timeout к API Переводчика. То есть, если мы не успели перевести за сколько-то миллисекунд, то мы говорим, что, попробуй еще раз, ошибка, не повезло.
Задать этот timeout в эксперименте невозможно, потому что нам, либо нужно именно группы фиксировать и сразу заранее, допустим заранее иметь следующие группы — enabled_with_300_ms, enabled_with_600_ms в именах которых закодировано значение параметра. Но задать как-то именно численно параметр нельзя. Если мы это не продумали заранее, то мы уже не можем так сравнить несколько конфигураций.
Четвертое, аналитики и разработчики вынуждены согласовывать названия групп заранее. То есть чтобы разработчику начать разработку фичи, он обычно начинает, собственно, с политики доступности этой фичи. И ему нужно знать имена фичевых групп. А для этого аналитик должен объяснить механику эксперимента — будем ли мы разделять пользователей на новых и старых или все пользователи окажутся в одной группе без деления.
Или это может быть обратный эксперимент. Например, мы можем сразу посчитать, что фича включена, но иметь возможность выключить ее. Аналитику это не очень интересно, потому что фича не готова. Он определит механику эксперимента, когда она будет готова. А разработчику требуются названия групп и механика эксперимента заранее, иначе ему постоянно придется вносить изменения в код.
Мы посовещались и решили, что хватит это терпеть. Так родился проект Make Experiments Great Again.
Ключевая идея этого проекта заключается в следующем. Если раньше мы привязывались к коду, кодом к именам групп активных, которые нам передавал аналитик, то теперь мы внесли две дополнительные сущности. Это фича (Feature) и параметр фичи (FeatureParam). И, таким образом, программист придумывает фичи и фиче-параметры самостоятельно, выбирая для них идентификаторы, выбирая для них дефолтные значения, и программирует относительно них доступность фичи.
После этого он сообщает эти идентификаторы аналитику, и аналитик, продумывая механику экспериментов, указывает специальным образом их в группах эксперимента с помощью тега feature_association. Если эта группа становится активной, то не забудь, пожалуйста, включить или выключить фичу с идентификатором таким-то, и задать параметры с такими-то идентификаторами.
Как это выглядит в файле с конфигурациями экспериментов? Вот мы смотрим группу эксперимента. Имя enabled, добавляется дополнительный тег feature_association, в этом теге команды enable_feature или disable_feature, и добавляются идентификаторы.
Также есть блок param, которых может быть несколько. Тут тоже есть имя — timeout, и добавляется значение, которое надо установить.
Как это выглядит из кода? Программист объявляет сущности класса Feature и FeatureParam. И в слой доступа к фиче прописывает значения из этих примитивов. Затем он передает этот идентификатор аналитику, и он уже в файле конфигураций задает идентификаторы в блоке группы эксперимента с помощью тега feature_association. Как только группа эксперимента становится активной, значения фич и параметров с этими идентификаторами в коде задаются из файла. Если в группе нет параметров и фич — используются дефолтные значения, которые указаны из кода.
Казалось бы, что это нам дало? Во-первых, аналитику теперь при добавлении новой группы не нужно просить программиста добавить новую фичевую группу в код, потому что слой доступа к данным оперирует идентификаторами, которые не изменяются при добавлении новой группы в систему экспериментов.
Во-вторых, мы разнесли время, когда программисты придумывают эти идентификаторы для фич и параметров фич, со временем, когда аналитик разрабатывает механику эксперимента. Аналитик разрабатывает тогда, когда фича готова, а программист придумывает эти идентификаторы тогда, когда он пишет код, в самом начале.
Также это позволяет разбить фичу на части. Допустим, здесь есть фича Переводчик, translator, которая включает, собственно, Переводчик. А есть фича TranslateServiceAPITimeout, она включает дополнительную функциональность, которая может задать кастомный timeout к API Переводчика. Таким образом, мы можем сделать две группы экспериментов, в обеих из которых Переводчик включен, но при этом мы сравниваем, какое значение лучше: 300 миллисекунд или 600.
То есть можно разбить фичу на подфичи и потом часть подфич включить в эксперименте в разных группах. И сравнивать. А можно конфигурировать одну и ту же фичу разными параметрами за счет новых сущностей параметра фичи (FeatureParam).
Казалось бы, мы решили все проблемы, победа, можно праздновать. Но, нет, за нами пришли. Пришли за нами не другие разработчики, не аналитики, не менеджеры. Пришло за нами тестирование. В чем заключалась проблема тестирования?
Первая проблема, которую мы породили: нельзя задать принудительно Feature и FeatureParam. В этой системе Feature и FeatureParam задаются с сервера. Соответственно, чтобы задать с сервера Feature и FeatureParam, тестированию нужно катить файл с конфигурациями, хотя бы для внутренней сборки. Они этого не умеют. Или же попадать по-честному в группу новых пользователей, старых пользователей, что тоже очень сложно.
Во-вторых, нельзя посмотреть значение Feature&FeatureParam. Значение фич можно посмотреть косвенно, то есть мы видим «Переводчик», значит, наверное, фича включена. А вот значение FeatureParam посмотреть тяжело, потому что как мы определим, каким был таймаут к API Переводчика — 300 или 600 миллисекунд?
И третья проблема. О ней я говорил в первом пункте. Чтобы тестировщику что-то изменить, ему нужно выкатить измененный файл с конфигурациями эксперимента в продакшене. Даже если в файл с конфигурациями добавлены конфигурации с фильтром для внутренней сборки и для public beta, все равно этот файл нужно выкатить в продакшен на сервер. А выкатка в продакшен обладает определенными требованиями, определенным емким процессом.
Таким образом, мы столкнулись с проблемой: тестировщику стало тяжело тестировать еще не вышедшую фичу заранее.
Как мы решили эту проблему? Я сначала перечислю пункты с мерами, которые мы приняли, а потом расскажу подробнее о каждом из пунктов.
Первое: мы начали использовать новый сервис для выкладки файла с конфигурациями и сделали настройку подмены источника для этого файла. То есть подмену URL, на который ходит браузер, чтобы скачать файл с описанием конфигурации.
Второе: мы на служебной странице browser://version поддержали еще один параметр — show-variations-cmd. Третье: мы разработали систему вспомогательных cheat-урлов, дополняющих систему экспериментов снаружи. И четвертое: мы начали разрабатывать диагностический экран.
Давайте про первый пункт. Новый сервис для выкладки файла с конфигурациями заключался в том, что мы скачиваем файл с конфигурациями экспериментов в продакшене. Далее тестировщик его декодирует из proto-файла обратно в текстовый файл и после этого дополняет конфигурацию какой-то своей конструкцией, новым study-блоком, который ему нужен. Может быть, с упрощенными фильтрами. И там задает значения Feature&FeatureParam, которые ему требуются для тестирования. Он видит этот файл с конфигурациями экспериментов, и он точно знает, что в эту конфигурацию будет попадать приложение. Там ровно одна группа, значит, Feature&FeatureParam будут равны заданным.
Затем он этот текстовый файл выкладывает на новый сервис. И сервис обратно компилирует его в proto-файл и выдает ссылку. Эту ссылку он указывает на диагностическом экране. Для внутренних сборок существуют диагностические экраны, ниже один из них. Он указывает, что нужно использовать его ссылку, а не дефолтную.
Второе. Как посмотреть значение Feature&FeatureParam? Здесь мы поддержали механизмы Chromium, которые генерируют служебную страницу. Chromium генерирует дополнительный блок на странице browser://version, если указать параметр show-variations-cmd.
Этот блок состоит из трех ключей: enabled-features, force-fieldtrials и force-fieldtrials-params, который с первого взгляда похож на абракадабру. Но если разобраться, он имеет смысл. Что это означает? Это означает содержимое всей системы экспериментов, как будто мы запустили наш браузер из командной строки. Здесь написано, что Feature1 активируется экспериментом с именем trial1. Feature2 активируется экспериментом с именем trial2. Feature3 активируется просто так.
У эксперимента trial1 задана активная группа group1. У эксперимента trial2 задана активная группа group2. И последний force-fieldtrials-params, параметр означает, что если эксперимент имени trial1 попадает в группу group1, то в него нужно выставить параметры p1 равный v1, p2 равный v2. А если trial2 попадает в группу group2, то нужно выставить параметр p3 равный v3, p4 равный v4.
Может показаться запутанно, но этот код мы переиспользовали. То есть это стандартный механизм генерации служебной страницы из Chromium, который мы просто поддержали в iOS. То есть мы переиспользовали кодовую базу для того, чтобы написать свой механизм.
Давайте попробуем на примере. Наш эксперимент Переводчик ключом --force-fieldtrials=translator/enabled_new/ устанавливает группу enabled_new для эксперимента translator.
Далее идет ключ --force-fieldtrial-params==translator.enablew_new:timeout/5000, если вдруг эксперимент translator попадает в группу enabled_new, а мы видим, что в первом ключе он в нее попадает, то для эксперимента translator, для группы enabled_new нужно выставить значение параметра timeout, равное 5 000 миллисекунд.
И последний флаг --enabled-features=TranslateServiceAPITimeout<translator говорит, что если вдруг какая-то группа в эксперименте translator в эксперименте translator активна, то включите, пожалуйста, фичу TranslateServiceAPITimeout. То есть, умея читать такой формат, мы можем все содержимое системы экспериментов посмотреть, какая группа выбрана, какие в этой группе фичи были включены и какие параметры были заданы.
Также мы разработали систему вспомогательных урлов (cheat urls). Это, конечно, прекрасно, что мы можем взятьь файл с конфигурациями экспериметов, декодировать его, дополнить его определенной группой, выложить на сервер и задать эту ссылку. Но это достаточно долго. И на первых порах мы с этим жили. Но после определенного момента мы поддержали ссылку.
Мы разработали ссылку с кастомной схемой yandexbrowser:// (Яндекс.Браузер), которая имела следующий формат, который представлен на слайде. То есть у нее было четыре части. Первая часть это my_pet_experiment=group_name. Вторая часть, это параметр enable-features=, где перечисляется список фич который нужно включить, потом параметр disable-features=, где перечисляется список фич которые нужно выключить. И дальше идут просто параметры, которые через &.
Если вы запустите такую вспомогательную ссылку (cheat url), то система экспериментов дополнится служебной информацией. Эта служебная информация будет передаваться каждый старт, помимо, собственно, скачанного файла с конфигурациями экспериментов. И она будет генерировать конфигурацию эксперимента, из информации указанной в ссылке по шаблону представленному на слайде, которая будет в файле в самом начале. При этом она не будет содержать блок filter, поэтому эксперимент my_pet_experiment гарантированно будет попадать в группу, которую вы зададите в ссылке. Вероятность этой группы будет 1000, у нее будет feature_association, которую вы задали в ссылке, а также заданные вами параметры.
Таким образом, тестирование облегчилось. Тестировщик берет ссылку, формирует ее, запускает в приложении. И он точно уверен, что теперь именно у эксперимента с нужным именем — в данном случае my_pet_experiment — точно будут заданные значения, такие, какие он хочет. Неважно, скачала ли система экспериментов файл и какой файл она скачала, потому что этот блок study идет выше всего.
Также мы делаем экран отладки, который показывает экран значений экспериментов выбранной группы. Если зайти дальше — показываются значения фич, параметров. Еще дальше мы можем перегрузить или задать новые значения. Перечисленные меры облегчили тестирование, решили его задачи и вывели тестирование на новый уровень.
Теперь я вам расскажу, где хранится монетка и что же такое источник энтропии.
Монетка, напомню, это случайное число из промежутка от нуля до единицы, которое выкидывается для того, чтобы в активной конфигурации определить активную группу эксперимента. Оно должно храниться на диске, чтобы при следующем запуске вашего приложения вы не выбрали другую группу эксперимента. То есть если условия не изменились и вы запускаете приложение в следующий раз, вы должны попадать в ту же самую группу той же самой конфигурации.
Но хранить монетку на диске может показаться избыточно и опасно. Генерация монетки должна быть одинаковой от запуска к запуску. Казалось бы, если вы используете генератор случайных чисел, как это обеспечить? Также необходимо равномерно распределять пользователей по группам, что вообще отсекает варианты. Как же не хранить монетку, обеспечив все эти три критерия?
Это возможно. Используется следующий прием.
Ссылка со слайда
Генерируется случайная строка, так называемый источник энтропии. Каждое приложение в браузере хранит, например, UUID, то есть уникальным способом генерируется application Identifier, сохраняется на диск. Эта случайная строка объединяется с именем эксперимента. После этого hash переводится в значение от нуля до единицы.
Почему это работает? Будет ли это число случайным? Да, будет, потому что у вас есть случайно сгенерированный компонент в качестве UUID, то есть по всем устройствам это число будет случайное. Будет ли оно различаться на одном и том же устройстве от эксперимента к эксперименту? Да, будет, потому что вы объединяете источник энтропии с именем эксперимента. А имя эксперимента различно для разных экспериментов. Будет ли оно равномерно распределено? Если вы используете правильный hash и правильный перевод из уже сгенерированного hash в вещественное число от нуля до единицы, то будет. Как этой делать, показано в статье от Google, которая называется An Efficient Low-Entropy Provider.
Таким образом, вы можете в своей системе экспериментов хранить на диске только одно значение — UUID, а генерировать монетку, которая будет равномерно распределена, уже согласно алгоритму. Такой же алгоритм использует, например, сама система Chromium.
Какую систему экспериментов, по нашему мнению, стоит использовать? Какие критерии к ней предъявляются? Она должна быть:
- Калькулируемой: не хранить на диске информацию о выбранных группах, значениях их параметров или еще что-то. Пересчет должен происходить при каждом запуске.
- Конфигурируемой. Вы разбиваете пользователей на группы, задаете условия, при которых ваш эксперимент может быть проведен, а система сравнивает эти конфигурации между собой.
- Тестируемой. У вас должны быть механизмы, которые позволяют переопределять значения групп, фич, параметров или других необходимых вам сущностей.
- Такой, где используются разные примитивы для аналитики и для программирования.
- Расширяемой. У вас должна быть возможность посмотреть, как она работает, и адаптировать ее к своим нуждам (см. Сhromium variation service).
Система Chromium, которую мы расширяем в Яндекс.Браузере для iOS, такими критериями обладает. Проводите ваши эксперименты, анализируйте их и делайте приложения лучше. Спасибо.