
Эта статья – попытка взглянуть на программаты глазами прагматика, на примере задачи, взятой из реальной практики программирования микроконтроллеров. Однако она может заинтересовать не только embedderов, поскольку автоматный подход может эффективно использоваться для создания и драйверов и интерактивных приложений в системах основанных на обработке событий, как например Windows.
Основное преимущество автоматного подхода проявляется на этапе проектирования ПО. Автоматный подход позволяет грамотно и наглядно проектировать программы, которые по окончании проектирования могут быть реализованы совсем не как автоматы (о способах реализации автоматов мы поговорим в следующей части), а как классические структурные конструкции.
Наверное, существует не так много программистов, не слышавших о цифровых автоматах, но чтобы не отсекать аудиторию, в двух словах опишем суть. Автоматом называется цифровое устройство, построенное по принципу:
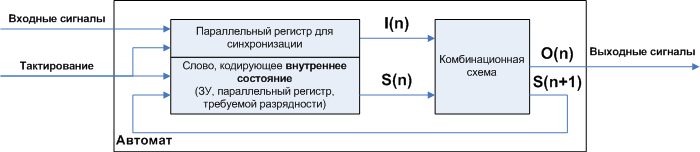
Рисунок 1. Общая структура цифровых автоматов
Где:
- комбинационная схема (КС) – цифровая логическая схема, не содержащая внутри себя элементов памяти. Т.е. её состояние определяется только тем, что у неё на входе.
- Входы КС условно делятся на две группы I(n) – внешние сигналы (входы автомата), S(n) – внутреннее состояние автомата на текущем шаге. Внутреннее состояние это, образно говоря, некий «режим», определяющий то, как автомат будет преобразовывать внешние сигналы I(n) в сигналы O(n). У классической комбинационной схемы (нет группы входов S(n)) такой «режим» только один.
- Выходы КС тоже делятся на две группы O(n) – сигналы, выходящие вовне, которые собственно и выполняют «полезную работу», S(n+1) внутреннее состояние для следующего шага. То есть, на каждом шаге автомат в зависимости от входного сигнала I(n) не только вычисляет нужный выходной сигнал O(n), но и включает себе режим обработки сигналов на следующий шаг (т.е. сигналов I(n+1) ), причём при необходимости этот режим может быть тем же самым или другим. Иными словами, можно задать требуемые режимы на любые возможные случаи последовательностей входных сигналов, что и делает автоматы столь «всемогущими».
- С целью синхронизации вводится запоминающее устройство (ЗУ, параллельный регистр) которое отделяет в цепи обратной связи слово относящееся к предыдущему шагу, от слова относящегося к следующему. Символы n и n + 1 означают текущий шаг, и следующий шаг, т.е. n соответствует не временной оси, а последовательности шагов. Шаги задаются тактовым сигналом, и через тактовый сигнал осуществляется привязка к временной оси. Шаги могут быть связаны не с периодическим тактовым сигналом, а с событием «приход сигнала I».
- Аналогичное запоминающее устройство, для той же цели вводится в канал входных сигналов I
Если вы не были знакомы с автоматами, при всей ясности объяснения польза от таких устройств не очевидна, но существует математическая абстракция, хорошо иллюстрирующая суть. Работу автомата можно наглядно описать при помощи диаграммы состояний и переходов. Ниже изображена диаграмма, описывающая работу устройства, управляющего лифтом. Это очень упрощённая диаграмма, не учитывающая процессы открытия/закрытия дверей, разгона/остановки, но она даёт наглядное представление о том, как при помощи автоматов моделируется работа объектов реального мира. Над стрелками пишется условие, при котором произойдёт переход, в овале пишется
название_состояния/что_будет_на_выходе_пока_автомат_в_этом_состоянии.

Рисунок 2. Пример диаграммы состояний и переходов
К сказанному выше добавлю, что на диаграмме показан автомат Мура. Состояние выходов такого автомата зависит от текущего состояния. Альтернатива – автомат Мили. Его выходной сигнал зависит от последнего совершённого перехода, поэтому что_будет_на_выходе записывается над соответствующей стрелкой. Несмотря на это различие автоматы Мили и Мура математически преобразуются друг в друга. Для наших познавательных целей больше подходят автоматы Мура, но в практике программирования полезны обе абстракции, поэтому в следующей части мы не обойдём вниманием и автоматы Мили.
Все более-менее сложные цифровые схемы проектируются именно как цифровые автоматы. Почему? Незаменимости автоматного подхода при проектировании цифровых схем способствуют три основных преимущества автоматного подхода:
- Декомпозиция.
- Взгляд на процессы не как на последовательность шагов, а как на совокупность всех возможных шагов.
- Математика.
Автоматы являются математической сущностью, их теория широко и глубоко проработана, что позволяет использовать для оптимизации и анализа полученных автоматов точные математические методы. С этой точки зрения разработка программ не автоматным способом, может рассматриваться как «работа гуманитария». Математические методы рассмотрены во второй части. Рассмотрим описанные преимущества, начав с декомпозиции.
Часть 1. Практическая декомпозиция.
В математической теории автоматов декомпозиция это создание из автомата, работающего по сложной диаграмме состояний и переходов, нескольких простых и понятных автоматов, которые имеют параллельное и/или последовательное соединение и дают в сумме исходный автомат. Это математическая и, следовательно, точная процедура.
Мы рассматриваем практическое автоматостроение, поэтому в первой части под декомпозицией будем понимать не математическую декомпозицию, а разбиение автомата в соответствии со здравым смыслом. Во второй части будут даны примеры математической декомпозиции.
Автоматы обычно разбиваются на операционные и на управляющие. Смысл очевиден из названия — операционный автомат это «руки», управляющий – «голова». Причём разбиение может быть многоуровневым: операционный автомат в свою очередь может быть разбит на исполнительную и руководящую части. Т.е. рука-манипулятор, может иметь свой «минимозг», транслирующий общие команды («взять предмет») в набор детальных команд, управляющих каждым «пальцем». Ещё более показательным примером является процессор, имеющий конвейеры, регистры, ALU и FPU – операционные автоматы и микропрограмму – управляющий автомат.
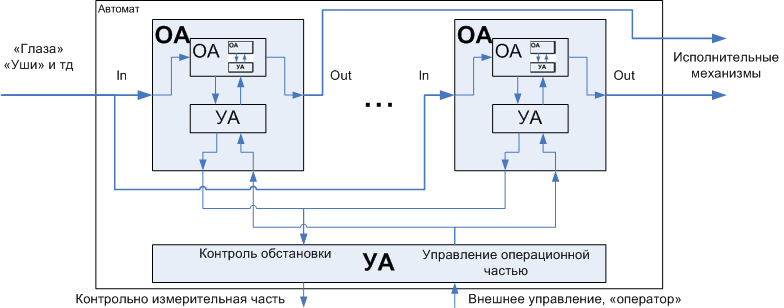
Рисунок 3. Декомпозиция автомата на операционный и управляющий
Принцип разбиения крупной задачи на мелкие подзадачи вообще-то и так широко распространён в практике программирования, это разбиение задачи на подпрограммы. Однако, автоматная интерпретация программ, т.е. представление любого программного обьекта в виде автомата, у которого есть операционная часть и управляющая часть, позволяет уйти от механистического и наивного (в хорошем смысле) дробления исходного кода и даёт набор практических соображений как именно это делать, которые заметно повышают качество программы уже на стадии её проектирования. Рассмотрим пример, который позволит вести разговор о программатах более предметно.
Постановка задачи
_____________________________________________________________________
Пусть у нас есть ч/б графический дисплей. Его видеопамять имеет стандартную побайтную организацию, в которой каждый бит представляет некую точку. Предположим, что нам нужно осуществлять вывод текста разными, не моноширинными шрифтами.

a)

б)
в)
Рисунок 4. Требования к модулю вывода на дисплей
Все символы в шрифте одной высоты, но шрифт может быть поменян «на лету», в процессе вывода одной и той же строки. Аналогично могут быть поменяны атрибуты – жирный, курсив, подчёркивание. Для управления параметрами используются esc-последовательности, к которым относится управляющий символ '\n', перевод строки, т.е. текст одной строки может быть выведен на несколько строк на дисплее. Например текст:
"Text 1 \033[7m Text 2 \033[27m \033[1m Text 3 \033[21m \n Text 42"будет отображаться так, как это показано на иллюстрации (рис.4, б)
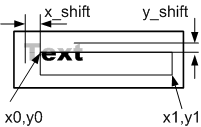
Текст выводится в область, ограниченную прямоугольником (рис.4, в) и может иметь смещение. Координаты области вывода задаются не в знакоместах, а в пикселах, координаты могут быть отрицательными, что означает выход за пределы области вывода. Текст, выходящий за границы области вывода, отсекается.
Нам нужно создать функцию, которая всё это реализует, с прототипом
void Out_text(int x0, int y0, int x1, int y1, int x_shift, int y_shift, char * Text);Это важная, базовая функция для всех операций работы с текстом: работа функции printf, реализация виртуальных окон, бегущих строк и прочее.
_____________________________________________________________________
Составление автомата (то есть модели реализуемого процесса) выполняется от общего к частному, сверху вниз, но детальная проработка модели и её программная реализация наоборот происходят снизу вверх. Это продиктовано тем, что обычно самый нижний уровень непосредственно завязан на исполнительные механизмы, что ставит нас в определённые рамки и ограничивает возможность «манёвра», в то время как более высокие уровни являются в этом отношении более гибкими, и рамки для них вытекают из реализации нижележащих автоматов.
Процесс создания программной реализации итерационный, сначала реализуется самый нижний уровень модели (разработанной сверху вниз), затем разрабатывается следующий уровень, параллельно корректируется нижележащий, после чего разработка переходит к более высокому уровню, с корректировкой нижележащих по необходимости. Грамотное проектирование требует минимальной переработки нижележащих уровней, ограничиваясь их дополнением. Окончательная реализация автоматов в виде программного кода осуществляется после составления всех автоматов, но тем не менее наброски алгоритмов выполняются параллельно проектированию автоматов. Все нижележащие выкладки были выполнены мной не после составления программы, как иллюстрация, а до создания программного кода, как важный этап проектирования. Итак, приступим к разработке.
Как следует из условия задачи, исходная последовательность символов в общем случае выглядит как: Текст1 упр1 Текст2 упр2 Текст3 упр3 Текст4 упр4 Текст5 \0
где упрN управляющие esc-последовательности, символы перевода и окончания строки которые отделяют друг от друга текстовые блоки. Разбивка текста на блоки удобна тем, что позволяет в рамках одного блока использовать максимальное количество одинаковых настроек (например высота текста и координаты начала строки).
Разработка пары ОА-УА всегда начинается с разработки ОА. ОА строится на основе наших попыток смоделировать все аспекты процесса, которым будет управлять наш автомат. В случае с дисплеем мы имеем пару самостоятельных аспектов: разбиение текста на разделённые управляющими последовательностями блоки и сборку графических данных в буфере, который будет сброшен в видеопамять. Следовательно, автомат будет состоять из двух подавтоматов, изображённых на рис. 5.
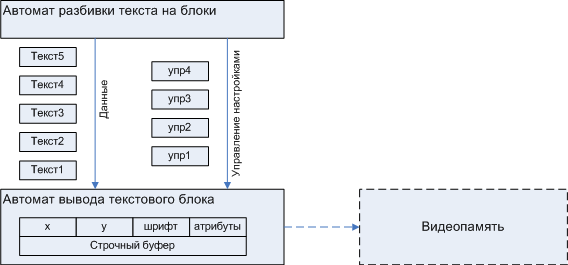
Рисунок 5. Первоначальное разбиение
Необходимость наличия промежуточного буфера сборки текстового блока обусловлена тем, что часто работа с дисплеями осуществляется по каналу связи с ограниченной по сравнению с RAM пропускной способностью, по протоколу типа:
- сначала послать команду Записать_байт (координаты байта на дисплее)
- после чего, возможно, получить подтверждение,
- и только после этого можно передавать байт.
При этом дисплеи могут принимать и сплошной поток байтов, последовательно, строка за строкой заполняя видеопамять. Эта особенность подталкивает нас к тому, чтобы собрав строку в буфере, скидывать её потоком байтов в видеопамять.
Каждый текстовый блок характеризуется координатами текстового блока x,y(относительно окна вывода), смещением x_shift, y_shift относительно координат x,y текстового блока, шрифтом и атрибутами, такими как инверсный или нет, мигающий, жирный, курсив, подчёркивание и так далее.
Автомат разбивки текста на блоки
Операционная часть автомата разбивки на блоки состоит из входного потока байтов, который разбивается на блоки. Чтобы избежать ненужного копирования, текстовые блоки это части исходной строки, которые передаются в Автомат вывода текстового блока в виде двух указателей Text_begin и Text_end.

Рисунок 6. Пояснение к ОА автомата разбивки на блоки
Автомат разбивки управляет настройками Автомата вывода текстового блока через непосредственный доступ к соответствующим переменным автомата.
Автомат разбивки текста на блоки — очень простой ОА, можно сказать, что и нет никакого автомата, всего пара указателей плюс набор меняемых переменных, но мы рассматриваем общий принцип, принцип который пригодится, при разработке второго автомата — Автомата вывода текстового блока
После того как разработан ОА несложно составить требуемый ему управляющий автомат
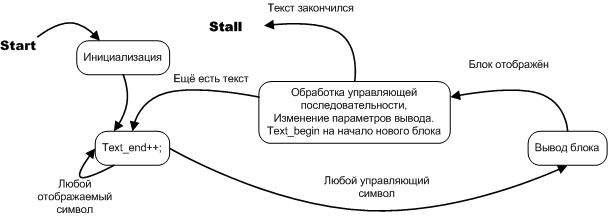
Рисунок 7. Диаграмма состояний автомата разбивки на текстовые блоки
Управляющий автомат в данном случае хорошо описывается как в терминах алгоритмической блок-схемы, так и терминах диаграммы состояний, но поскольку речь идёт об автомате, мы используем диаграмму состояний. Диаграмма состояний не только подчёркивает «автоматность» задачи, она полезна тем, что это альтернативный, более удобный вариант записи обычных программных алгоритмов. Если всмотреться в суть вопроса, диаграмма состояний это естественная форма записи программного процесса в широком смысле, в то время как алгоритмическая блок-схема это искусственная конструкция, которая уже содержит в себе особенности реализации, которые чаще всего очевидны и не требуют того, чтобы их отдельно записывали. Более того, именно эти самые особенности реализации (когда они второстепенные детали), бывает, маскируют основной замысел, выпячивая себя на первый план наряду с действительно важными деталями. В следующей части будет приведён прекрасный пример, показывающий разницу между алгоритмом заданным блок-схемой и алгоритмом заданным диаграммой состояний. Диаграмма состояний элементарно преобразуется в программный код.
Автомат вывода текстового блока
Как было показано выше, управляющие последовательности могут в том числе задавать координаты вывода очередного текстового блока. Координаты текущего текстового блока задаются переменными x, y.

Рисунок 8. Используемые при выводе текстового блока координаты
Пояснение к рисунку.
x_max, y_max – размеры дисплея
x0, y0, x1, y1 – координаты окна вывода, параметры функции Out_text
x_shift, y_shift – смещение, может быть положительным и отрицательным, влияет на расположение всех текстовых блоков.
x,y — координаты вывода текущего текстового блока, могут изменяться esc командами. Координаты отсчитываются относительно окна вывода.
Как было отмечено ранее, текст первоначально выводится в строчный буфер, после чего содержимое строчного буфера копируется в видеопамять.
В примере используется шрифт размером 5х7, но описываемый модуль поддерживает работу с символами любого размера. В результате может потребоваться крупный буфер сборки строки, что для embedderов часто является немаловажным фактором. Для минимизации буфера вместо набора параллельных регистров может использоваться один, осуществляющий «вертикальную развёртку», речь идёт о вертикальной развёртке всего текстового блока, т.е. выводится строка высотой один пиксел и шириной во весь текстовый блок.

Рисунок 9. Вертикальная развёртка при выводе текстового блока
При корректной реализации быстродействие такого варианта алгоритма почти не уступает случаю с параллельными регистрами, хотя всё же требует накладных расходов: 3 байта на символ, но позволяет вообще отказаться от строчного буфера, что для дисплея шириной 256 пикселов и символов высотой 24 пиксела даёт экономию
Из этих соотношений можно прикинуть, в каком случае экономия окажется значима. В этой статье мы рассмотрим вариант с полным строчным буфером, как более простой, оставив рассмотрение «практичного» варианта за рамками этой статьи.
Поскольку разработка пары ОА-УА всегда начинается с разработки ОА, а разработка ОА начинается с самого нижнего уровня, составим ОА для автомата вывода текста.
Операционный автомат вывода символов на экран состоит из буфера в котором собирается текстовая строка. Поскольку ширина символа не равняется ширине байта, каждый новый символ будет иметь некоторый сдвиг. Для осуществления сдвига применяется сдвиговый регистр. Если строчный буфер — набор параллельных регистров, соответствующих отдельным строкам, то сдвиговый регистр требуется один. Как видно из иллюстрации, у нас есть два сквозных счётчика Current_byte и Current_shift, которые, увеличиваясь от символа к символу, определяют величину сдвига и место, куда помещать сдвинутый символ.

Рисунок 10 а. Пояснение работы операционного автомата прорисовки текстового блока.
Собранный в строчном буфере текст скидывается в видеопамять.
Управляющий автомат для описанного операционного автомата будет таким

Рисунок 10 б. Управляющий автомат для операционного автомата прорисовки текстового блока.
// Начальные значения этих переменных задаются во время инициализации
int Current_shift, Current_byte;
// Значения этих переменных задаются на вышележащем уровне
u1x * Text;
u1x * Text_end;
tFont * Current_font;
// Указатель на массив шириной Width байтов - битовое поле выводимого символа
u1x * Symbol_array;
int Width;
// Полная длина текста в пикселах не более
int Line_width;
////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////
inline void Out_text_block ()
{
Clear_line_buffer();
// Пока не конец строки
while(Text < Text_end)
{
Width = Current_font->Width_for(*Text);
Symbol_array = Current_font->Image_for(*Text);
Line_width -= Width;
// Если символ выходит за край окна, не выводим его
if(Line_width <= 0)
break;
// Работа операционнного автомата показанного на рис 10
Out_symbol();
//Сдвигаем Current_byte, Current_shift на величину уже выведенного символа.
Current_shift += Width;
Current_byte += (Current_shift >> 3);
Current_shift = Current_shift & 0x7;
Text ++;
}// while(Text < Text_end)
Finalize:
Out_line_buffer_in_videomemory();
return;
}// inline void Out_text_block ()Примечание. Во время реального проектирования этот вариант функции не прорабатывался и приведён здесь исключительно из соображений понятности.
Наша модель описывает процесс вывода в общем, но не учитывает некоторых особенностей, которые можно проиллюстрировать чертежом рис 11.

Рисунок 11. Пояснение особенностей вывода в строчный буфер и видеобуфер.
Из этого чертежа видно, что и строчный буфер и видеопамять имеют байтовую организацию, причём окно вывода может не совпадать с границей байта в видеопамяти. То есть вывод в строчный буфер следует производить с некоторым начальным отступом чтобы можно было выполнить побайтовое копирование
Кроме этого, текст может быть смещён влево за границу окна и в этом случае часть текста не отображается, причем граница отображаемой части текста может проходить так, что часть символа отображается а часть нет.
Иными словами, при разработке операционного автомата вывода в строчный буфер следует учитывать что:
а) существуют пересекающиеся байты — байты которые содержат как старые данные из видеопамяти, так и новые данные из строчного буфера, поэтому пересекающиеся байты видеопамяти и строки из буфера маскируются взаимодополняющими масками, после чего данные пересекающихся байтов накладываются по или. Данные не пересекающихся байтов копируются в видеопамять целиком.
б) вывод текста в строчный буфер всегда начинается с нулевого байта строчного буфера, но не всегда с нулевой позиции, чаще он начинается с некоторого отступа Current_shiftначальное.
в) текст, помимо начального сдвига, связанного со значением координаты x может быть смещён за левую границу и часть текста выходящая за неё не отображается.
г) текст может выступать справа, что требует дополнительного маскирования, причём при соответствующих размерах один и тот же символ может выступать и справа и слева.
Составляя операционный автомат обязательно нужно учесть все описанные пункты, поэтому обратимся к следующей абстракции. Это (составление абстракции) тоже часть автоматного подхода — не следует пренебрегать ясным визуальным представлением задачи, хотя это не вытекает непосредственно из автоматной теории. Данная абстракция родилась после того, как я изобразил разные варианты расположения текста.
Все символы строки разделены на категории:

Рисунок 12. Категории символов, выводимых на экран, в зависимости от расположения относительно окна вывода.
Каждая категория подразумевает свой режим обработки:
- Символы не попавшие в окно вывода (1) просто игнорируются.
- Первый символ частично или целиком попавший в окно вывода (2) может требовать дополнительного по сравнению с типом 3 сдвига влево, чтобы отсечь выступающие за область вывода пикселы. Выпавшие байты и биты просто теряются.

Рисунок 13. Пояснение механизма начального сдвига. Цифры показывают порядковый номер пикселов в изображении символа.
- Символы полностью попавшие в область вывода (3) как и символы тип (2) требуют сдвига вправо, величина которого зависит от координаты символа.
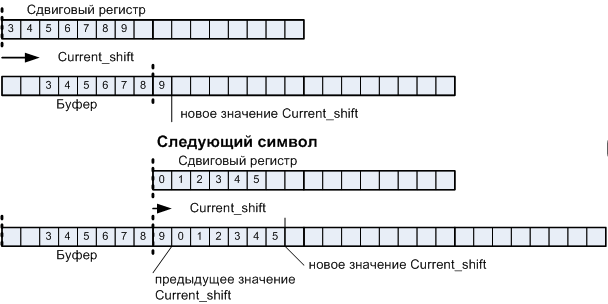
Рисунок 14. Пояснение механизма скользящего сдвига
Для первого символа выполняется и сдвиг влево и сдвиг вправо, поэтому появляется возможность сэкономить – осуществлять фактический сдвиг на разность соответствующих величин с дополнительным маскированием «выпавших» пикселов. Маска получается табличным способом, поэтому практически не требует дополнительных вычислений, но такой подход позволяет экономить до 7 сдвигов на каждый байт первого символа, что при размере символа 16*24 даёт экономию до 336 сдвигов.

Рисунок 15. Исключение двойного сдвига
Из сдвигового регистра данные скидываются в строчный буфер, который обнуляется перед началом вывода текстового блока. Данные накладываются по или.

Рисунок 16. Заполнение строчного буфера.
Биты строчного буфера, выступающие за область вывода справа (могут принадлежать и категории 2 и категории 3, помечаются апострофом) требуют дополнительного отсечения не поместившейся на экран части символа справа.

Рисунок 17. Обработка символов 2’ и 3’.
Финализация подразумевает копирование информации из строчного буфера в видеопамять, причём если крайние байты пересекающиеся (см выше), их информация считывается из видеопамяти и маскируется соответствующей маской для видеопамяти после чего отсечённый байт накладываются на содержимое строчного буфера по или, после чего все байты строчного буфера просто копируются в видеопамять.
Как было показано выше, шлифовка программной реализации происходит на последнем этапе, тем не менее, для ясности я буду приводить исходники в их окончательном виде, несмотря на то, что идея исключения двойного сдвига возникла уже в процессе оптимизации, после того, как весь модуль был отлажен, причём для этого пришлось лишь слегка изменить функцию Out_symbol. То же касается использования переменных Start_line и End_line, которые появятся лишь при разработке вышележащей функции Out_text, но при этом их добавление лишь немного повлияло на вид функции Out_symbol.
Полная версия исходника находится по ссылке, в файле Display.h/Display.cpp. Там же находится откомпилированный пример(Project1.exe). Сам проект под Builder 6
class tShift_register Symbol_buffer;
vector< tShift_register > Line_buffer;
// Значения всех этих переменных задаются на вышележащем уровне
int Start_line, End_line;
int Left_shift, Current_shift, Current_byte;
// Указатель на массив шириной Width байтов - битовое поле выводимого символа
u1x * Symbol_array;
int Width;
int bytes_Width;
//Может на байт превосходить bytes_Width, в зависимости от величины сдвига
int bytes_Width_after_shift;
inline void Out_symbol ()
{
for(int Current_line = Start_line; Current_line <= End_line; Current_line++)
{
Symbol_buffer.Clear();
////////////////////////
// Для типов 2 и 3 используется один метод Out_symbol, это фактически выбор типа символа
if(Left_shift)// тип 2
{
// Если сдвиг больше чем 8 бит имеет смысл заменить его сдвигом на целый байт
int Start_symbol_byte = Left_shift >> 3;
// void tShift_register::Load(int Start_index_in_destination, u1x * Source, int Width);
Symbol_buffer.Load(0,Symbol_array + bytes_Width * Current_line + Start_symbol_byte, bytes_Width - Start_symbol_byte);
// рис.15
// void tShift_register::Shift(int Start, int End, int Amount);
Symbol_buffer.Shift (0, bytes_Width_after_shift, Current_shift - (Left_shift & 7) );
Symbol_buffer[0] &= Masks_array__left_for_line_buffer[ Current_shift ];
// рис.16
Line_buffer[Current_line].Or(Current_byte, &Symbol_buffer[0], bytes_Width_after_shift );
}
else // тип 3
{
Symbol_buffer.Load(0,Symbol_array + bytes_Width * Current_line, bytes_Width);
// рис.14
Symbol_buffer.Shift(0, bytes_Width_after_shift, Current_shift);
// рис.16
Line_buffer[Current_line].Or(Current_byte, &Symbol_buffer[0], bytes_Width_after_shift );
}
}// for(int Current_line = Start_line, Current_line <= End_line, Current_line++)
}// inline void Out_symbol ()Переходим теперь к управляющему автомату. Алгоритм его работы интуитивно ясен из приведённого выше описания ОА. Как уже было упомянуто выше, диаграмма состояний естественная и минималистичная форма записи алгоритмов, позволяющая показать суть не засоряя чертёж второстепенными деталями, поэтому запишем алгоритм для УА в виде диаграммы состояний.

Рисунок 18. Диаграмма состояний – хорошая альтернатива классическим блок схемам.
По алгоритму записанному этой диаграммой состояний несложно составить программный код, состоящий из классических структурных конструкций — циклов и ветвлений. Это оказывается несложно в частности потому что этот направленный граф, в общем, не циклический ( то есть не содержит переходы в предыдущие состояния). Исключение составляет пара петель (состояния Тип 1 и Тип 3), которые легко разворачиваются в циклы. Однако даже для тех автоматов, которые описываются более сложным графом с циклическими путями обхода узлов, тоже можно написать структурную программу, хотя на первый взгляд эта задача может показаться трудноразрешимой и громоздкой. Прошу акцентировать внимание: поскольку диаграмма состояний имеет дело с абсолютно идентичными с точки зрения программного процесса блоками-состояниями, связи между которыми ясно и однозначно определены, это позволяет использовать для перехода между состояниями оператор goto, не нарушая структурности языка. То есть, если оператор goto будет использован для совершения переходов между состояниями автомата, это само по себе новая структура, такая же как циклы и ветвления. Эта структура называется переход между состояниями, и она обогащает инструментарий программирования. В то же время, следует понимать, что использование оператора goto вне рамок этой программной структуры по-прежнему остаётся неструктурным, т.е. ломающим стандартные структуры из которых строится программный код. Это важный момент. Возможно, потребуется время, чтобы люди привыкли и перестали бояться, но хочется верить, что новая структурная конструкция займёт достойное место в инструментарии программистов.
class tShift_register Symbol_buffer;
vector< tShift_register > Line_buffer;
tVideomemory Videomemory;
// Значения этих переменных задаются на вышележащем уровне
int Start_line, End_line;
// НАЧАЛЬНЫЕ значения этих переменных задаются на вышележащем уровне
int Left_shift, Current_shift, Current_byte;
// Значения этих переменных задаются на вышележащем уровне
u1x * Text;
u1x * Text_end;
tFont * Current_font;
// Эти переменные полностью контролируются функцией Out_text_block
// Указатель на массив шириной Width байтов - битовое поле выводимого символа
u1x * Symbol_array;
int Width;
int bytes_Width;
//Может на байт превосходить bytes_Width, в зависимости от величины сдвига
int bytes_Width_after_shift;
// Значения этих переменных задаются на вышележащем уровне
// Полная длина текста в пикселах
int Line_width;
////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////
inline void Out_text_block ()
{
Clear_line_buffer();
////////////////////////////////////////
// Далее всё как показано в диаграмме состояний
Type_1:
// Пока не конец строки
while(Text < Text_end)
{
Width = Current_font->Width_for(*Text);
// Прокручиваем символы пока не попадём в область отображения
if(Left_shift >= Width)
{
Left_shift -= Width;
Text++;
}
else
goto Type_2;
}// while(Text < Text_end)
// Конец строки
return;
////////////////////////////////////////
Type_2:
// Инициализируем
Current_byte = Current_shift >> 3;
Current_shift = Current_shift & 7;
Symbol_array = Current_font->Image_for(*Text);
bytes_Width = (Width + 7) >> 3;
bytes_Width_after_shift = (Width + Current_shift + 7) >> 3;
Line_width -= (Width - Left_shift);
// Достигли границы?
if(Line_width <= 0)
{
Width -= Left_shift;
goto Type_4;
}
Out_symbol();
// Компенсируем Left_shift
Width -= Left_shift;
Left_shift = 0;
// Любой следующий символ
Text++;
////////////////////////////////////////
Type_3:
// Конец строки?
while(Text < Text_end)
{
//Сдвигаем Current_byte, Current_shift на величину уже выведенного символа.
Current_shift += Width;
Current_byte += (Current_shift >> 3);
Current_shift = Current_shift & 0x7;
// Прокручиваем на следующий символ
Width = Current_font->Width_for(*Text);
Symbol_array = Current_font->Image_for(*Text);
bytes_Width = (Width + 7) >> 3;
bytes_Width_after_shift = (Width + Current_shift + 7) >> 3;
Line_width -= Width;
// Достигли границы?
if(Line_width <= 0)
goto Type_4;
Out_symbol();
Text++;
}// while(*Text < Text_end)
Current_shift += Width;
Current_byte += (Current_shift >> 3);
Current_shift = Current_shift & 0x7;
// Конец строки
goto Finalize;
////////////////////////////////////////
// фактически типа 4 нет это символы тип 2' и 3'
Type_4:
Out_symbol();
Current_shift += (Width + Line_width);
Current_byte += (Current_shift >> 3);
Current_shift = Current_shift & 0x7;
for(int Current_line = Start_line; Current_line <= End_line; Current_line++)
{
Line_buffer[Current_line][Current_byte] &= Masks_array__right_for_line_buffer[Current_shift];
}
Finalize:
Out_line_buffer_in_videomemory();
return;
}// inline void Out_text_block ()Этот алгоритм легко и органично, буквально 1 в 1, реализуется и на ассемблере.
Такие величины как Start_line, End_line, начальные значения Left_shift, Current_shift, Current_byte задаются на этапе инициализации процесса вывода блока. Это происходит ещё в автомате разбиения на блоки. Рассмотрим как это происходит. Напомню, что одна строка может выводиться не единственным блоком а несколькими, поэтому при выводе каждого блока мы имеем дело с параметрами показанными на рис.8.
Координаты каждого текстового блока (x,y) могут задаваться индивидуально (esc последовательности, однако есть и различие – координаты курсора задаются не в знакоместах а в пикселах). Они отсчитываются относительно координат окна вывода (x0,y0,x1,y1). Смещение x_shift, y_shift влияет на координаты каждого текстового блока. Все текстовые блоки целиком попадающие в окно вывода не обрезаются даже если задано отрицательное смещение.Обрезается только то, что не попадает в окно вывода, т.е. отрицательное смещение само по себе не критерий обрезки текстовых блоков. Для реализации описанного поведения вывод каждого текстового блока сопровождается следующими преобразованиями.
Вычисление параметров по горизонтали иллюстрирует рис. 19

Рис 19. Пояснение к вычислению параметров по горизонтали
Значение x_shift не показано, оно компенсируется добавлением к x. Параметры x_byte и Start_shift используются во время вывода в видеопамять, который осуществляется по схеме показанной на рис. 20

Рисунок 20. Вывод в видеопамять.
Процесс вывода очевиден, но не будут излишними пояснения:
- Если левый байт пересекающийся, то читается соответствующий байт видеопамяти, маскируется и накладывается на крайний левый байт строчного буфера (который уже и так замаскирован в процессе вывода в строчный буфер).
- Если правый крайний байт пересекающийся то читается соответствующий байт видеопамяти, маскируется, после чего накладывается на крайний правый байт строчного буфера (который при этом маскируется дополняющей маской).
- После этого весь строчный буфер потоком копируется в видеопамять, причём строка Start_line строчного буфера идёт в строку y буфера, и так далее вплоть до End_line и y + End_line — Start_line, соответственно, как это показано на рис 20.
Параметры Start_line и End_line определяются исходя из соображений показанных на
рис. 21.

Рис. 21. Определение параметров по вертикали.
// Стартовая инициализация
// Проверяем корректность параметров окна
////////////////////////////////////////////////////////////////////////////////////
if(x1 < x0)
{
int temp = x0;
x0 = x1;
x1 = temp;
}
if(y1 < y0)
{
int temp = y0;
y0 = y1;
y1 = temp;
}
if(x0 < 0)
{
x_shift += x0;
x0 = 0;
}
if(y0 < 0)
{
y_shift += y0;
y0 = 0;
}
if(x1 > x_max)
{
x1 = x_max;
}
if(y1 > y_max)
{
y1 = y_max;
}
// для каждого блока
inline bool Init_text_block()
{
// Компенсируем сдвиг
////////////////////////////////////////////////////////////////////////////////////
x += ( x0 + x_shift);
y += ( y0 + y_shift);
// по горизонтали
////////////////////////////////////////////////////////////////////////////////////
if (x < x0)
{
Left_shift = x - x0;
x = x0;
}
else
{
Left_shift = 0;
}
if(x >= x1)
return false;
x_byte = x >> 3;
Start_shift = Current_shift = x & 7;
Current_byte = 0;
Line_width = x1-x;
// по вертикали
////////////////////////////////////////////////////////////////////////////////////
if (y < y0)
{
Start_line = y0 - y;
y = y0;
}
else
Start_line = 0;
if(Start_line >= Current_font->Height())
return false;
if( (Current_font->Height() - Start_line) < ( y1 - y) )
End_line = Current_font->Height() - 1;
else
End_line = Start_line + (y1 - y) - 1;
return true;
}Следует добавить, что фактически выводится только содержимое текстового блока, а не всего окна вывода, ограниченного координатами x0,y0,x1,y1. При необходимости можно предварительно очищать всё окно отдельно.
Автомат разбивки исходного текста на блоки.
Диаграмма состояний и переходов уже была приведена на рис.7
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////
// Описана выше
void Out_text_block ();
inline void Control_processing ();
void Out_text (int arg_x0, int arg_y0,
int arg_x1, int arg_y1,
int arg_x_shift, int arg_y_shift,
unsigned char * argText)
{
// Инициализация
// ...
while(*Text_end)
{
//////////////////////////////////////
state__Inside_text_block:
while(1)
{
switch(*Text_end)
{
// Пока только два кода в следующей части рассмотрим этот вопрос подробнее
case '\0':
case '\n':
goto state__Out_text_block;
}
Text_end++;
}
//////////////////////////////////////
state__Out_text_block:
if( (Text_begin != Text_end) && Init_text_block())
Out_text_block();
Text_begin = Text_end;
//////////////////////////////////////
state__Control_processing:
if(*Text_end == 0)
return;
// Стоит выделить в отдельную функцию
Control_processing();
}//while(*Text_end)
}//void Out_text (int arg_x0, int arg_y0,Так в общих чертах выглядит решение задачи. По ссылке вы можете увидеть исходники и рабочую версию программы(файл Project1.exe). Единственный вопрос, который остался не раскрыт – структура функции Control_processing, которая разбирает esc-последовательности и выполняет команды. В её основе лежит ещё один тип автоматов, который заметно отличается от рассмотренных выше, но которые в то же время классика программных автоматов – символьные автоматы. Мы рассмотрим реализацию функции и автомата в следующей части и там же проведём обзор преимуществ автоматного подхода.
PS
К сожалению не получилось всё изложить в одной статье и в то же время хотелось сообщить читателям, что это не всё ), поэтому родилась такая фраза вводящая в заблуждение " и там же [во второй части] проведём обзор преимуществ автоматного подхода.". Прошу не рассматривать её как указание на то что в этой статье нет описания преимуществ. Обзор подразумевает некую сводку преимуществ. А описание преимуществ уже содержитсяздесь, так как главное преимущество — проектирование программы, данная статья показывает процесс проектирования «вживую», насколько это возможно, как последовательность этапов. А как вы оцените описание самого процесса, вы могли проследить мою авторскую мысль, или где то были какие то непонятности?
Комментарии (68)
DrPass
24.06.2017 23:03+1проведём обзор преимуществ автоматного подхода
По-моему, это должно было быть в начале первой статьи, а не в конце второй. А то на протяжении чтения неизменно сопровождает мысль «ну и зачем всё это?»
Dr_Dash
25.06.2017 11:34К сожалению не получилось всё изложить в одной статье и в то же время хотелось сообщить читателям, что это не всё ), поэтому родилась такая фраза вводящая в заблуждение. Прошу не рассматривать её как указание на то что в этой статье нет описания преимуществ. Обзор подразумевает некую сводку преимуществ. А описание преимуществ уже содержитсяздесь, так как главное преимущество — проектирование программы, данная статья показывает процесс проектирования «вживую», насколько это возможно, как последовательность этапов. А как вы оцените описание самого процесса, вы могли проследить мою авторскую мысль, или где то были какие то непонятности?

HSerg
25.06.2017 11:34Постановку задачи лучше бы явно выделить — сейчас она спрятана в тексте и ищется не так просто.
А почему для реализации был выбран древний C++ Builder 6, а не свежий C++ Builder 10 Starter Edition Free?Dr_Dash
25.06.2017 11:42Потому что мой основной IDE это IAR а Builder 6 это то, чем я довольно хорошо владею для создания проектов для ПК. Я стал переносить пример на Qt но возникли сомнения в том что если не Qt то кто, и в то же время хотелось выложить статью здесь и сейчас, поэтому решил не заморачиваться. Спасибо вам за идею насчёт Builder 10 Starter Edition Free. Если можно пару слов — вы используете её? И как Starter Edition? Не мешает работе? У меня сейчас выбор между Qt и чем нибудь из Embarcadero, можете вкратце посоветовать его или отсоветовать?
HSerg
26.06.2017 09:25На C++ Builder скорость UI-разработки на порядок выше, зато Qt позволяет разрабатывать UI-приложения под Linux. Мне для небольших ПК-разработок Starter вполне хватает, а вот для рабочих проектов его ограниченность слишком заметна (см. feature-matrix).
BelerafonL
25.06.2017 11:43+2Более сложного объяснения машины состояний ещё поискать!
Bonart
25.06.2017 21:49+1Легко — паттерн State от банды четырех

Femistoklov
26.06.2017 03:49Надеюсь, банда четырёх всё же не «изобрели» автоматы, а указали, что описывают реализацию существующего давно изученного формализма?
Scf
25.06.2017 13:00Имхо, полезно только для машин без динамической аллокации памяти или для глубокой оптимизации, т.к. код на выходе без исходной диаграммы состояний ни читать, ни тем более править не получится.
При наличии ресурсов, значительно более понятное решение можно построить в два шага:
— преобразовать входную строку в структуру данных, описывающую, что и куда рисовать
— передать эту структуру данных в рендер, который занимается отрисовкой
Siemargl
25.06.2017 13:37В нормальных FSA-либах это все есть — в начале программы описан автомат таблицей состояний — просто и понятно.

EyeGem
25.06.2017 14:48Любая однопоточная программа уже является автоматом. Когда программист пишет код, он мыслит категориями вычислений, чтений, вывода, проверок и переходов.
Дополнительный уровень абстракции (FSM/FSA-либы, ну или просто переменные кодирующие состояния) нужен только в случае асинхронных потоку исполнения входных данных т.е. ввода от пользователя, из сети, из другого потока и абстрагированному, а значит в общем случае не-синхронному, вводу от других компонент в составе того же потока.
Растеризация текстов обычно к таким не относится, поэтому ожидать здесь наличие таблицы состояний странно.
Dr_Dash
25.06.2017 14:24Дело в том что диаграмма состояний строится не для иллюстрации кода а до его создания, поэтому в данном случае она в наличии обязательна.
ответьте пожалуйста на вопрос это важно для меня, если бы у вас перед глазами была диаграмма состояний рис 18 и соответствующий ей код,(и выкладки по сдвигам и прочее — это тоже рисуется до разработки исходника и хранится с ним) вам было бы сложно разобраться в нём и, например, внести дополнения, или чего-то не хватает ещё?
Dr_Dash
25.06.2017 14:29Плюс вопрос, тоже важно ) обратили ли вы внимание что в статье делается акцент не на реализацию программы как автомата, а её проектирование, как автомата. И что на самом деле Out_text_block реализована как обычный алгоритм? Или я недостаточно акцентировал на этом внимание? Потому что в этом соль и есть, это не ещё один велосипед про UML/Boost/Statechart
Scf
25.06.2017 15:06Да, мне понравилась идея проектирования алгоритмов в виде автомата. НО — такую схему непросто переложить в код без внутреннего состояния — это же противоречит самой идее автоматов.
Человеческий разум устроен так, что ему проще понимать алгоритмы, которым скармливают данные на входе и получают данные на выходе, и результат зависит только от входа, но не от внутреннего состояния. Такие «чистые функции» проще понимать, тестировать и использовать повторно. Также их легче использовать в многопоточном окружении, что актуально для современных многоядерных серверов.
Программа, спроектированная как автомат, будет, конечно же, наиболее эффективной по цпу и памяти, но и наиболее сложной для понимания, так что, имхо, это только техника оптимизации, но не общая техника программирования:
— код, который невозможно понимать и дорабатывать без документации (к тому же, графической документации!) — это слишком дорого для большинства применений
— модификация такого кода может привести к пересмотру хранимого состояния, т.е. придется держать в уме весь код, который этим состоянием пользуется
— состояние перед началом работы нужно инициализировать — этот код тоже «хрупкий» и потребует частых доработок при внесении изменений в логику. А ошибки в нем приведут к сложным багам.
Реализация графа состояний подозрительно напоминает генеренный код — быть может, её и правда можно генерировать по графу состояний? Правда, ни один графический язык пока не взлетел, ну кроме BPML.Dr_Dash
25.06.2017 16:01такую схему непросто переложить в код без внутреннего состояния
это в точку, но когда я написал
на самом деле Out_text_block реализована как обычный алгоритм
я немного слукавил. На самом деле в этой программе есть явно выделенные состояния. Они заданы метками Type_1 и т.д. Взгляните на этот вопрос математически, программа находится на участке между Type_1 и Type_2 только когда автомат в состоянии Тип 1, и так далее. Это однозначное соответствие. Представьте что вместо метки Type_1, у нас определена функция Type_1 и в программе есть указатель на функцию Current_state (переменная текущего состояния), а вместо операторов goto Type_2 используется конструкция Current_state = Type_2. Я обязательно рассмотрю этот аспект, он изначально заложен в замысел статьи.
Человеческий разум устроен так, что ему проще понимать алгоритмы, которым скармливают данные на входе и получают данные на выходе
в точку, во второй статье важное место уделено именно этому аспекту, надеюсь, вам будет действительно интересно,
код, невозможно понимать и дорабатывать без документации (к тому же, графической документации!) —
.
Дело в том что при таком подходе графическая документация в виде диаграммы состояний предшествует созданию программы, считайте что у вас всегда под рукой. Скажите а функция Out_text_block когда у вас есть диаграмма состояний, насколько понятна?
модификация такого кода может привести к пересмотру хранимого состояния, т.е. придется держать в уме весь код, который этим состоянием пользуется
я буду рассматривать модификацию этого кода и вы сможете оценить этот процесс
состояние перед началом работы нужно инициализировать — этот код тоже «хрупкий» и потребует частых доработок при внесении изменений в логику. А ошибки в нем приведут к сложным багам.
Такое опасение имеет право на существование, но так получилось что я использую автоматы много лет и во многих проектах, и могу вас уверить, что такая проблема в общем не стоит остро. Автоматный подход не просто требует более внимательного отношения к проектированию программы, он и является элементом внимательного проектирования программы.
Всё что вы пишите это важно, я постараюсь освещать эти моменты подробно, сейчас конечно в коментах это вкратце поэтому если что-то не понятно пожалуйста пишите, я отвечу развёрнуто второй статьёй.
Реализация графа состояний подозрительно напоминает генеренный код — быть может, её и правда можно генерировать по графу состояний?
Многолетняя практика. Автоматическая генерация не самоцель. Она требует слишком детальной проработки диаграммы состояний. Диаграмма состояний должна быть ясной и без излишеств, диаграмма состояний не блок-схема, чем понятней диаграмма состояний тем проще и совершенней код. То что моя программа напоминает генеренный код прямое следствие автоматного подхода — иначе просто и не сделать, автоматный подход сам наталкивает на такую реализацию. Но обратите внимание — схемы со сдвигами это тоже немаловажная часть. Повторюсь, такой подход сам наталкивает на такие реализации.
Программа, спроектированная как автомат, будет, конечно же, наиболее эффективной по цпу и памяти, но и наиболее сложной для понимания, так что, имхо, это только техника оптимизации, но не общая техника программирования
если я смогу своими статьями раскрыть внутреннюю простоту этого подхода я окажу огромную услугу программистам будущего )), все ваши вопросы закономерны, это твердыни которые словно какое то кривое зеркало искажает красоту и естественность автоматного подхода
michael_vostrikov
27.06.2017 15:59Скажите а функция Out_text_block когда у вас есть диаграмма состояний, насколько понятна?
Абсолютно непонятна, ни с диаграммой ни без) Потому надо сначала найти соответствие между кодом и элементами диаграммы.
Dr_Dash
25.06.2017 16:10— преобразовать входную строку в структуру данных, описывающую, что и куда рисовать
— передать эту структуру данных в рендер, который занимается отрисовкой
пожалуйста про входную строку в структуру данных, описывающую, что и куда рисовать подробнее, я кажется понимаю о чём вы пишите, но не уверен что не думаю о другом.

babylon
25.06.2017 13:36+1Топикастер тоже проспал эпоху флеша и оператор gotoAndPlay. Вот где были автоматы, потоки, лейауты и всё остальное… Выходим из гибернации. Это очень нужно, но как всегда не всем.
Dr_Dash
25.06.2017 14:17Это любопытно, но флеш анимация серьёзно перекликается с программными автоматами (именно своей кадрированносьтю), спасибо за аналогию.
Indemsys
25.06.2017 15:58Если работаете с IAR то должны знать их продукт IAR Visual State
Есть бесплатная триальная версия.
Я бы рекомендовал в ней вам создавать свои автоматы.
Тогда их можно было бы скачать и оценить трудоемкость и эффективность такого подхода.
А также быстро перепроверить насколько ваша реализация отклоняется от проекта.
А рисовать на бумаге диаграммы — это, извините, анахронизм и трата времени.Dr_Dash
25.06.2017 16:05Я знаком с этим продуктом, если вы знакомы с этим продуктом и взвешенно оцените статью, увидите, здесь речь немного о разных вещах. Там реализация, а здесь сам смысл проектирования. На самом деле с реализацией проблем не возникает, я покажу разные способы. IAR Visual State это дополнение к тому что я говорю, а не антагонист
Indemsys
25.06.2017 17:33+1Понимаете, без формальных схем нарисованных в какой-то стандартной среде, которые можно запустить и проверить возникает стойкое ощущение что вы свои диаграммы нарисовали уже после того как написали программу.
И зачем-то пытаетесь убедить, что применяли автоматное программирование.
pascvilant
25.06.2017 17:17+2я вот что не понимаю.
совсем не понимаю.
каким местом это относится к автоматам?
классически должны были бы быть описания алфавитов входного, внутреннего и выходного алфавитов. Плюс матрицы переходов-выходов, в зависимости от милимура. И собственно вся прелесть автоматного подхода именно в этом: алгоритм меняется простой сменой матрицы. А еще можно приляпать вероятности (и это еще один плюс подхода — нахрен монтекарло), можно приляпать даже интервальные вероятности (с некоторыми ограничениями).
Но вот в статье я таки не увидел ни матриц, ни единого алгоритма.Dr_Dash
25.06.2017 20:45приведите пример того о чём вы говорите
Indemsys
26.06.2017 08:16Читайте Машина Тьюринга
Какую бы программу вы не написали все это можно будет интерпретировать как автомат.
Поэтому если хотите показать настоящее автоматное программирование, то программируйте сразу машину Тьюринга.Dr_Dash
26.06.2017 09:32Не соглашусь. Математически вы правы, но автомат в данном случае не столько математическая сущность сколько прагматичный подход к практическому созданию алгоритмов. Если честно, меня затруднило бы решить расписанный мной пример в виде машины Тьюринга )
Siemargl
26.06.2017 09:48Конечно, любой цифровой компьютер является конечным автоматом по определению.
Весь фокус применения этого способа — в выборе удобного разбиения происходящего процесса на состояния, чтобы это было и удобно описывать и удобно менять детализацию при дроблении состояний.Indemsys
26.06.2017 11:34Согласен полностью.
Но почему-то именно вопрос удобства и не рассматривается.
По сути автор предлагает всегда сопровождать текстовую нотацию графической.
Это удобство?
Это нужно только начинающим программистам, у которых мозг не сформировал областей нужных паттернов мышления.
Присутствие оператора switch в программе на языке C-и тоже не маркер автоматного программирования.
В принципе автоматное программирование это такой спекулятивный термин, что даже Миро Самек от него отошел.Dr_Dash
26.06.2017 21:31Это нужно только начинающим программистам, у которых мозг не сформировал областей нужных паттернов мышления.
это ваше субъективное мнение,
Присутствие оператора switch в программе на языке C-и тоже не маркер автоматного программирования.
Всё верно, маркер автоматного программирования — набор явно выделенных состояний, плюс текущее состояние задаётся конретной переменной. У меня есть хороший пример.Indemsys
27.06.2017 09:50Я думаю что тема вами пока не раскрыта.
Может следующие статьи что-то раскроют.
Жду.
Zenitchik
26.06.2017 20:51+1Автомат автомату рознь. Множество задач роскошно решается конечным автоматом, и применение МТ для них — избыточно.
michael_vostrikov
25.06.2017 20:58Какой-то слишком сложный алгоритм у вас. Попробовал реализовать, основная отрисовка занимает 100 строк.
Проверки границ только внутри функций отрисовки символа в буфер строки и буфера строки в видеопамять.
Маску наложения байтов можно вычислять на лету при выводе.
Автомат нужен разве что в разборе escape-последовательностей, как и для любой грамматики. Для остального обычный императивный код будет понятнее.
jsfiddle
Что касается вашего кода в целом. Много глобальных переменных и goto. Поддерживать такой код будет очень сложно. Поэтому программирование на автоматах редко применяется. В основном там, где много однотипных состояний и вариантов перехода между ними — например, в компиляторах.

NLO
25.06.2017 23:52НЛО прилетело и опубликовало эту надпись здесь
michael_vostrikov
26.06.2017 06:31Я так понимаю, в автомате главное это состояние, а состояние в каждой задаче разное. В тех же компиляторах задачи схожие, для них есть библиотеки (ANTLR, Bison), там есть формат описания автоматов. Там и программный код можно дописывать, так что думаю можно применить и для каких-то других задач. Просто никому это не надо, потому что сложно разбираться.
point212
27.06.2017 22:14фокус в том что любую программу можно рассматривать как автомат. У нее тоже есть состояния, есть переходы межды ними.
Вот только написана она не с использованием автоматного подхода, поэтому возникают неучтённые комбинации параметров и состояний, и всё глючит.michael_vostrikov
27.06.2017 23:14Фокус в том, что тогда состояние будет глобальным для всего кода. А переходы ничем не ограничены, можно перейти из любого места в любое. Так как состояние доступно во всех обработчиках, то возникают неучтенные комбинации где что меняется. И да, потом все глючит)
Dr_Dash
26.06.2017 09:40Если бы был некий стандарт записи автомата в какой-нибудь xml, позволяющий обмен автоматными алгоритмами, плюс некая «стандартная библиотека», возможно, все бы было иначе;
согласен с вами. Если вы так понимаете суть проблемы вам будет интересно продолжение, потому что то о чем дальше пойдёт речь находится как раз в том тренде о котором вы пишите
Dr_Dash
26.06.2017 09:36Какой-то слишком сложный алгоритм у вас…
приведите, если не сложно, что у вас получилось.
Попробовал реализовать
Маску наложения байтов можно вычислять на лету при выводе.
напишите подробнее пожалуйста, о какой маске идёт речь
Много глобальных переменных и goto. Поддерживать такой код будет очень сложно.
Это не глобальные переменные, это члены класса Display, они общедоступны для функций членов и сокрыты для доступа извне.
Dr_Dash
26.06.2017 09:58нашёл что у вас получилось, запущу это под IAR ом можно будет сравнить с цифрами на руках
michael_vostrikov
26.06.2017 10:33о какой маске идёт речь
Я про эти маски: "существуют пересекающиеся байты — байты которые содержат как старые данные из видеопамяти, так и новые данные из строчного буфера".
это члены класса Display
Да, не заметил. Но это мало что меняет. Они глобальны для всего кода отображения и меняются в разных функциях. В сочетании с goto это становится малоподдерживаемым.
Dr_Dash
26.06.2017 13:45Спасибо за весьма корректно выполненную эмуляцию, это то чего мне реально не хватало. если вы не против я возьму её как пример для своей второй части.
Dr_Dash
26.06.2017 13:52PS про маски понятно, за это тоже спасибо. это два подхода которые приятно сравнить, если есть возможность заменить 8ми байтным массивом операцию вычисления маски сдвигом на 7 позиций, лучше использовать массив, потому что взятие индекса одна операция пусть и двухтактная чем 7 сдвигов по одному такту плюс декремент счётчика один такт плюс сравнение и переход плюс ещё пара, итого 28тактов против 2х, выигрыш в производительности 14кратный!!!
michael_vostrikov
26.06.2017 14:55А, ну если на несколько бит за раз сдвинуть нельзя, то да, лучше массив.
babylon
26.06.2017 13:36goto или jump в мнгогопоточных или многокорных системах нужен в двух случаях — для переключения контекста процесса или ядра и/или для изменения порядка его выполнения. Это способ доступа к адресу элемента. Любоe Deep Learning это веха. Название статьи да — веха. Но пример на веху не тянет..
point212
27.06.2017 11:00Очень хорошая и полезная тема в целом. Автору спасибо за труд, НО… большое но…
Я считаю что статью нужно переписать.
Почему?
Вы очень быстро перешли от общего к частному, ко всем этим битовым сдвигам. Честно говоря — от этого голова болит. Вроде как хочешь почитать про FSA, а приходится следить за мыслью, что мы там делаем на битовом уровне.
Это все равно что я буду писать статью про устройство map-reduce системы, но где-то после 1/3 статьи перейду к подробностям оптимизации обмена с диском на некоторых файловых системах с учетом древних косяков API ядра под OpenBSD :) И остальные 2/3 статьи будут об этом, с примерами кода и т.п.
А хотелось бы в целом законченную статью про автоматы. С примером разработки автомата. Структурными схемами, и схемой работы каждого автомата.
Ну и краткое рассмотрение реализации автомата. Какие для этого есть библиотеки, подходы, методы. Хотя наверное это лучше в отдельной статье бы.Dr_Dash
27.06.2017 21:32одной статьёй не получается, поэтому прошу набраться терпения. Эта статья может рассматриваться как введение, иллюстрация понятия «автоматное проектирование». Сейчас я работаю над второй стаьёй где внимание уделено как философии автоматных программ так и реализации.
А хотелось бы в целом законченную статью про автоматы. С примером разработки автомата. Структурными схемами, и схемой работы каждого автомата.
но у меня же там про разработку ))). Вы просто ставите меня в тупик этой фразой, если можно то более конкретно.point212
27.06.2017 22:11Ну во первых уберите всю эту воду про сдвиговые регистры, экономию тактов и байт памяти. Всё что касается реализации алгоритма уберите из статьи. Я понимаю что это выстраданные долгими ночными часами знания, которыми хочется поделиться. Но в рамках статьи оно все абсолютно неважно и даже вредно.
Во вторых, сам пример для статьи лучше бы взять попроще. Тот который вы рассмотрели конечно удачен в плане того что тут автомат в автомате в автомате и в автомате. Но опять таки… повышать сложность нужно постепенно. Вам может и не заметно, потому что вы уже прекрасно разбираетесь в теме. Но со стороны ты только вроде что-то начинаешь понимать, и тут всё опять усложняется.
Начните с одного автомата. С проектирования его операционной части, затем управляющей.
Потом покажите как этим автоматом может пользоваться другой автомат. И так далее.
При этом сама реализация в коде не нужна. Достаточно будет диаграммы состояний.
А про реализацию в коде отдельную статью сделайте лучше. Где уже разбираются приемы при помощи которых диаграмма воплощается в код.Dr_Dash
28.06.2017 16:11Идею уловил. На самом деле трудный пример? Это сквозной и очень хороший пример. Он не такой уж сложный, просто видимо я недостаточно освещаю какие то моменты. Напишите где «и тут всё опять усложняется», я сделаю переходы более плавными и пояснения более развёрнутыми. Во второй части у меня есть разные примеры и в том числе попроще, в том числе реализация этого же примера сделанная моим коллегой, в которой я выделю операционную часть и управляющую и они действительно проще и без сдвиговых регистров. я сравниваю эти две реализации примера: по быстродействию и с точки зрения замысла и здесь сдвиговые регистры ключевой элемент, они определяют почему сделано именно так а не иначе, без них не удастся показать процесс разработки. Может быть имело смысл начать с той реализации, но она появилась как ответ на мою реализацию)))
Про реализацию в коде скорее соглашусь с вами, может её под спойлер лучше?
Dr_Dash
28.06.2017 21:32Будьте любезны, оцените изменения в тексте (начиная с рис 10 и до рис 11), стало понятней?
Siemargl
Для курсовой сгодится. От практики бесконечно далеко.
И выкладывать в опенсоурс исходники для СиБилдера6 «с торрентов» это как то за гранью разумного поведения.
Dr_Dash
Это и есть практика нас, обычных embedderов )). Этот модуль использован во множестве реальных проектов это краеугольный «кирпичик». И для курсовой это отличное задение, его можно использовать как тест на профпригодность, поэтому начинаю именно с него. Поэтому «бесконечно далеко» вызывает лишь искренне недоумение )))
Билдер в данном случае нужен для демонстрации работы модуля на ПК, сам модуль никак не завязан на Билдер, и использовался с другими IDE поэтому ваша критика как будто отчасти имеет почву но она немного мимо.
В дальнейшем я планирую давать примеры в Qt но этот пример было быстрее сделать так.
Siemargl
Кроме того, что код ужасен (я например перечень состояний автоматов с описанием даже не смог найти), для статьи важнее два негативных момента
— куча кода, не относящихся к теме статьи (напомню, она про FSA, а не про битовые сдвиги)
— было бы перед изобретением веслосипеда (я сделяль) неплохо ознакомиться с готовыми наработками. Гуглим C++ finite state machine lib
Dr_Dash
Спасибо за ваши замечания, мне важно видеть какие моменты вызывают недоумение у читателя, я с этого и начну следующую часть. Все состояния перечислены на соответствующих диаграммах, и в тексте даны их описания, просто я не хотел загромождать текст лишней информацией, но я могу добавить, приведите если не сложно, с какими именно состояниями у вас возникли сложности, возможно действительно не хватает описаний.
— весь код непосредственно иллюстрирует применение автоматного программирования для проектирования программ, а битовые сдвиги это неотъемлемая часть операционного автомата. И операционный автомат напрямую определяет то, каким будет управляющий автомат. Я верю что вы разбираетесь в автоматах состояний, но субъективно ощущается что знания у вас несколько из другой сферы, попробую объяснить. Судя по комментарию, для вас автомат это только то что непосредственно попадает под формальное определение по запросу C++ finite state machine lib, и до что вы никогда не сталкивались на деление автоматов на операционные и управляющие (может я ошибаюсь, не примите близко к сердцу) и таким образом ваше знание становится камнем преткновения: вы видите то что этот текст не повторяет то что вы привыкли слышать по этому вопросу и это вызывает подсознательную реакцию «что-то не то». Но поймите, автоматы более комплексная сфера знаний чем кажется на первый взгляд. Автоматы могут использоваться в частности для анализа символьных последовательностей и это тоже FSM, но автоматы это также и способ проектирования цифровых логических устройств, и это тоже автоматы, но акцент здесь на другое, и с этой точки зрения автомат это ряд технологических подходов. В статье я рассматриваю автомат именно с этой позиции, т.е. проектирование программного обьекта как цифрового устройства.
Siemargl
Именно так. Но поскольку программа это не цифровое устройство — то в реальности разделение на операционные и управляющие автоматы является искусственным.
С чего я и начал
Не будем далеко ходить. Вы пишете:
Но операционный автомат — это логические устройство (алгоритм), а битовый сдвиг — это технический прием формирования выходных данных на аппаратную часть. Соответственно — по теории он относится к управляющему автомату. Путаница как она есть.
Грубо говоря, управляющий автомат в софтвере — это драйвер устройства.
Dr_Dash
Но программа реализует цифровое устройство, деление между программной частью и аппаратной частью условно, процессор микроконтроллера выполняющий программу это цифровой автомат. Просто чувствуется то что вы мыслите на другом уровне абстракции. Программирование микроконтроллеров специфическая сфера, мы разрабатываем именно цифровые устройства в самом что ни на есть прямом смысле,
всё верно, логическое устройство выполняет ряд преобразований и функция Out_symbol выполняет те же преобразования которые у нас бы делали пара сдвиговых регистров в железе. Причём активно используются самые простые типы операций, и, или сдвиги, целочисленные операции, много однотипных вычислений, что оптимально для запуска на видео
процессорах на сколько я понимаю суть вопроса.
да это верно, вы прекрасно поняли суть. И драйвер много работает именно с битами и байтами, именно на таком уровне как это показано в примере. Микроконтроллер содержит огромное количество готовых встроенных устройств — таймеры цап-ацп, приёмопередатчики, и там такой подход совершенно естественен.
Cryvage
Может быть в этом и есть основная проблема? Я честно пытался въехать в статью, но после прочтения, у меня создалось ощущения оторванности теории от показанного примера. Вероятно потому что в пример тяжело въехать из-за специфики. Получается, что абстракция вроде понятна, но за кучей низкоуровневого кода её не видно.
Вначале вы пишите:
На мой взгляд, чтобы статья заинтересовала «не только embedderов», нужно как раз показать в качестве примера что-то вроде «интерактивных приложений в системах основанных на обработке событий, как например Windows».
Или же это было сказано «для красного словца», и в реальности, автоматы для прикладных программ неактуальны?
З.Ы. С++ builder 6, goto… Какая же это «новая веха»? В таком виде это даже не миф, а скорее страшилка.
Zenitchik
На goto автоматы получаются изящнее. Дело в том, что автомат хорошо описывается графом переходов, а вложенными конструкциями его описывать неудобно.
Идиосинкразия к goto развилась из-за того, что этот оператор резко понижает читаемость кода, однако, в случае конечного автомата картина обратная — здесь безусловный переход практически равноценен вызову процедуры с хвостовой оптимизацией.
babylon
Что ж там изящного? goto только для перехода внутри контента. Любой автомат можно реализовать траверсингом ast дерева. Правда ноды должны содержать специальные атрибуты "goto" со значением id записи в контекстном словаре.
Zenitchik
Можете рассказать подробнее? На вход автомата подаётся исходная строка. А в Вашем случае нужно отдельное средство для построения ast-дерева?
Dr_Dash
У меня много материала, постепенно я его изложу, и все заявленные моменты будут раскрыты, это не для красного словца. Сейчас я смотрю на отклики читателей, чтобы выбрать материал для второй части, наберитесь терпения.
Dr_Dash