
Сетевой стек Linux по умолчанию замечательно работает на десктопах. На серверах с нагрузкой чуть выше средней уже приходится разбираться как всё нужно правильно настраивать. На моей текущей работе этим приходится заниматься едва ли не в промышленных масштабах, так что без автоматизации никуда – объяснять каждому коллеге что и как устроено долго, а заставлять людей читать ?300 страниц английского текста, перемешанного с кодом на C… Можно и нужно, но результаты будут не через час и не через день. Поэтому я попробовал накидать набор утилит для тюнинга сетевого стека и руководство по их использованию, не уходящее в специфические детали определённых задач, которое при этом остаётся достаточно компактным для того, чтобы его можно было прочитать меньше чем за час и вынести из него хоть какую-то пользу.
Чего нужно добиться?
Главная задача при тюнинге сетевого стека (не важно, какую роль выполняет сервер — роутер, анализатор трафика, веб-сервер, принимающий большие объёмы трафика) – равномерно распределить нагрузку по обработке пакетов между ядрами процессора. Желательно с учётом принадлежности CPU и сетевой карты к одной NUMA-ноде, а также не создавая при этом лишних перекидываний пакета между ядрами.
Перед главной задачей, выполняется первостепенная задача — подбор аппаратной части, само собой с учётом того, какие задачи лежат на сервере, откуда и сколько приходит и уходит трафика и т.д.
Рекомендации по подбору железа
- Двухпроцессорный сервер не будет полезен, если трафик приходит только на одну сетевую карту.
- Отдельные NUMA-ноды не будут полезны, если трафик приходит в порты одной сетевой карты.
- Нет смысла покупать сервер с числом ядер большим, чем суммарное число очередей сетевых карт.
- В случае с сетевыми картами с одной очередью распределить нагрузку между ядрами можно с помощью RPS, но потери при копировании пакетов в память это не устранит.
- Hyper-Threading не приносит пользы и выключается в BIOS (тем более в Skylake и Kaby Lake с ним проблемы)
- Выбирайте процессор с частотой ядер не менее 2.5GHz и большим объёмом L3 и остальных кэшей.
- Используйте DDR4-память.
- Выбирайте сетевые карты, поддерживающие размер RX-буферов до 2048 и более.
Таким образом, если дано 2+ источника объёма трафика больше 2 Гбит/сек, то стоит задуматься о сервере с числом процессоров и NUMA-нод, а также числу сетевых карт (не портов), равных числу этих источников.
"Господи, я не хочу в этом разбираться!"
И не нужно. Я уже разобрался и, чтобы не тратить время на то, чтобы объяснять это коллегам, написал набор утилит — netutils-linux. Написаны на Python, проверены на версиях 2.6, 2.7, 3.4, 3.6.
network-top
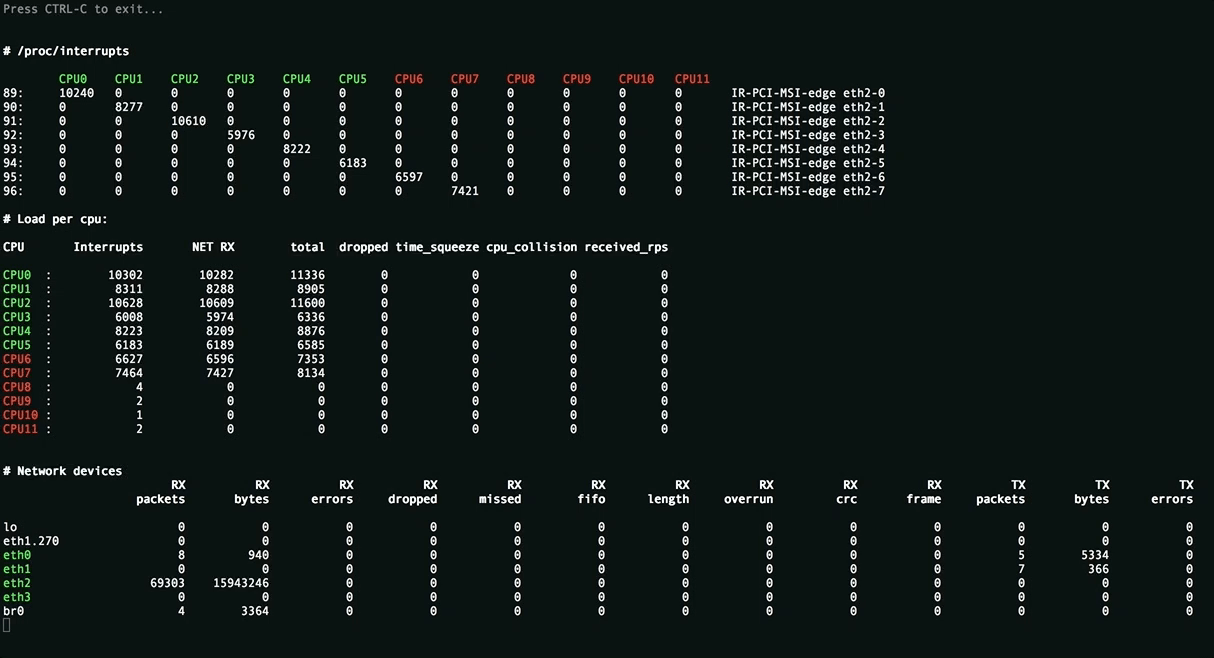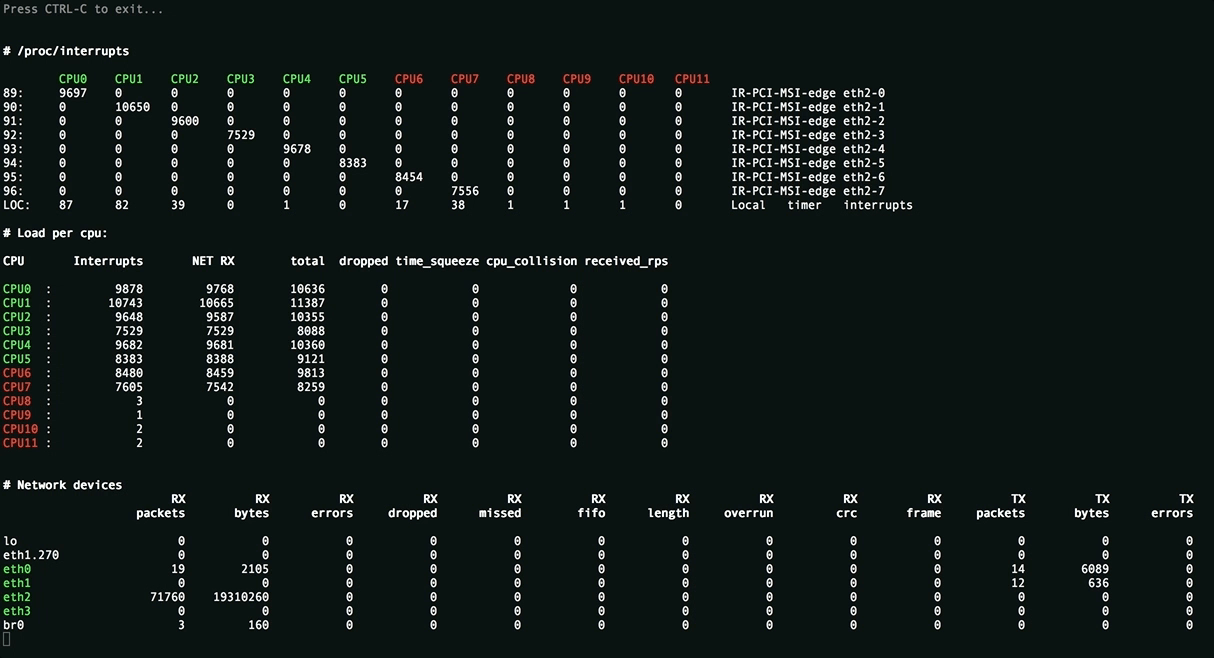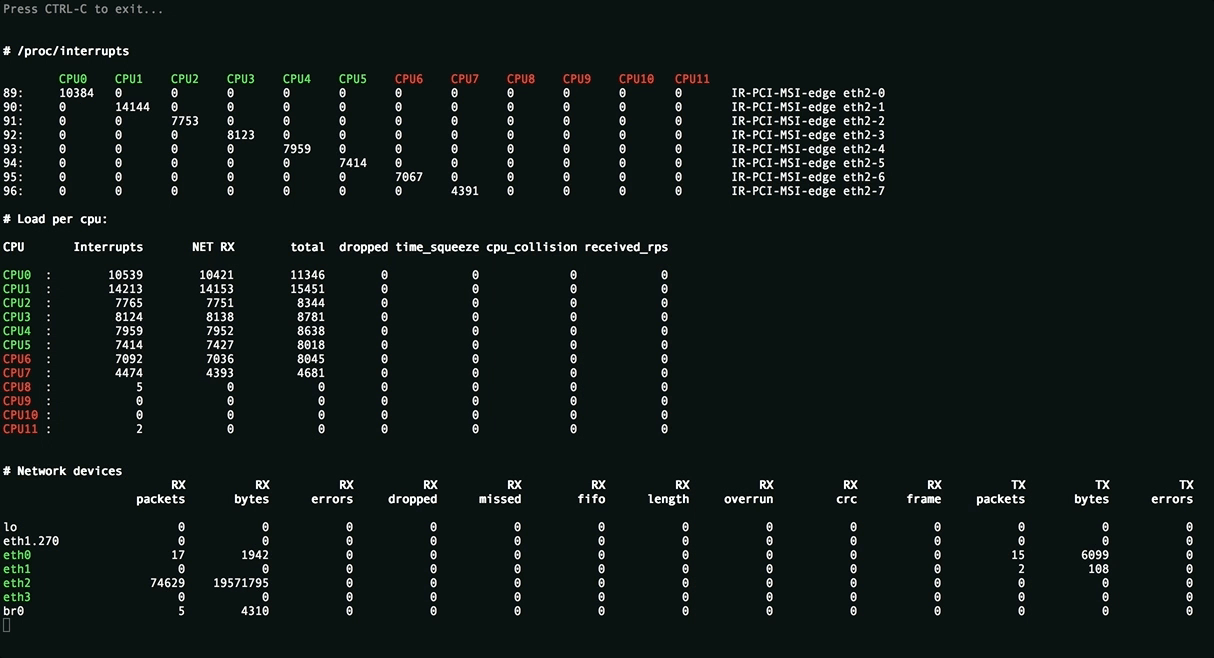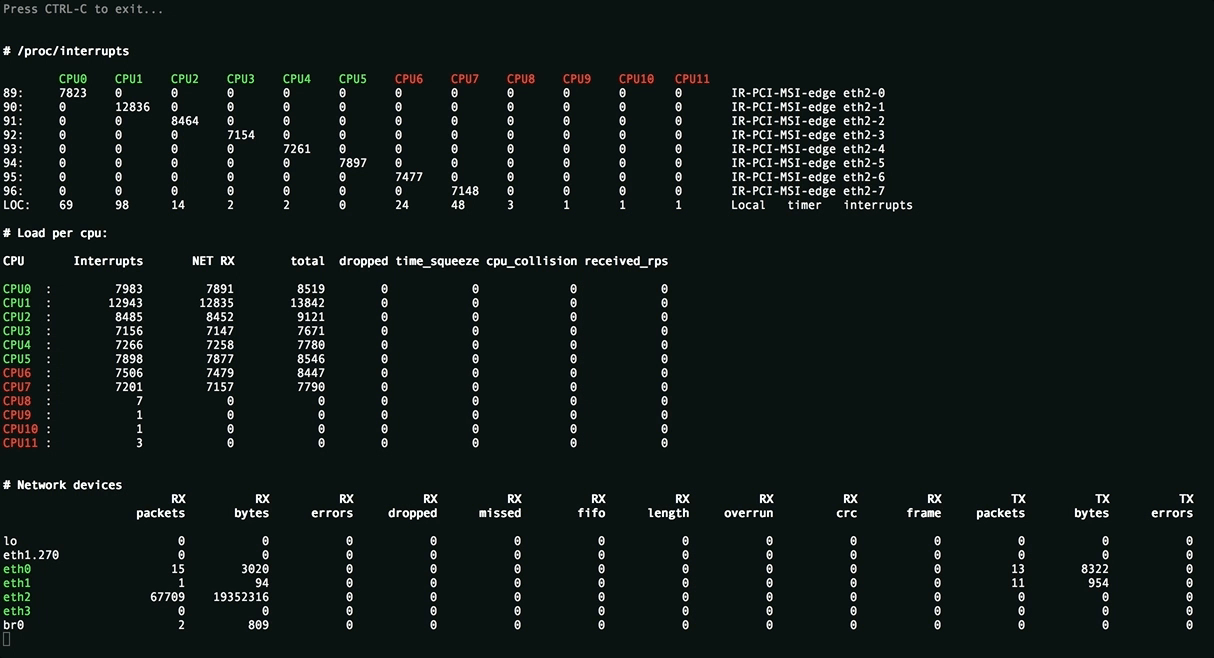
Эта утилита нужна для оценки применённых настроек и отображает равномерность распределения нагрузки (прерывания, softirqs, число пакетов в секунду на ядро процессора) на ресурсы сервера, всевозможные ошибки обработки пакетов. Значения, превышающие пороговые подсвечиваются.
rss-ladder
# rss-ladder eth1 0
- distributing interrupts of eth1 (-TxRx) on socket 0:"
- eth1: irq 67 eth1-TxRx-0 -> 0
- eth1: irq 68 eth1-TxRx-1 -> 1
- eth1: irq 69 eth1-TxRx-2 -> 2
- eth1: irq 70 eth1-TxRx-3 -> 3
- eth1: irq 71 eth1-TxRx-4 -> 8
- eth1: irq 72 eth1-TxRx-5 -> 9
- eth1: irq 73 eth1-TxRx-6 -> 10
- eth1: irq 74 eth1-TxRx-7 -> 11Эта утилита распределяет прерывания сетевой карты на ядра выбранного физического процессора (по умолчанию на нулевой).
server-info
# server-info rate
cpu:
BogoMIPS: 7
CPU MHz: 7
CPU(s): 1
Core(s) per socket: 1
L3 cache: 1
Socket(s): 10
Thread(s) per core: 10
Vendor ID: 10
disk:
vda:
size: 1
type: 1
memory:
MemTotal: 1
SwapTotal: 10
net:
eth1:
buffers:
cur: 5
max: 10
driver: 1
queues: 1
system:
Hypervisor vendor: 1
Virtualization type: 1Данная утилита позволяет сделать две вещи:
server-info show: посмотреть, что за железо вообще установлено на сервере. В целом похоже на велосипед, повторяющийlshw, но с акцентом на интересующие нас параметры.server-info rate: найти узкие места в аппаратном обеспечении сервера. В целом похоже на индекс производительности Windows, но опять же с акцентом на интересующие нас параметры. Оценка производится по шкале от 1 до 10.
Прочие утилиты
rx-buffers-increaseавтоматически увеличивает буфер выбранной сетевой карты до оптимального значения.maximize-cpu-freqотключает плавающую частоту процессора. Энергопотребление будет повышенным, но это не ноутбук без зарядного устройства, а сервер, который обрабатывает гигабиты трафика.
Господи, я хочу в этом разбираться!
Прочитайте статьи про:
Эти статьи вдохновили меня на написание этих утилит .
Также хорошую статью написали в блоге одноклассников 2 года назад.
Обычные кейсы
Но руководство по запуску утилит само по себе мало что говорит о том, как именно их нужно применять в зависимости от ситуации. Приведём несколько примеров.
Пример 1. Максимально простой.
Дано:
- один процессор с 4 ядрами
- одна 1 Гбит/сек сетевая карта (eth0) с 4 combined очередями
- входящий объём трафика 600 Мбит/сек, исходящего нет.
- все очереди висят на CPU0, суммарно на нём ?55000 прерываний и 350000 пакетов в секунду, из них около 200 пакетов/сек теряются сетевой картой. Остальные 3 ядра простаивают
Решение:
- распределяем очереди между ядрами командой
rss-ladder eth0 - увеличиваем ей буфер командой
rx-buffers-increase eth0
Пример 2. Чуть сложнее.
Дано:
- два процессора с 8 ядрами
- две NUMA-ноды
- Две двухпортовые 10 Гбит/сек сетевые карты (eth0, eth1, eth2, eth3), у каждого порта 16 очередей, все привязаны к node0, входящий объём трафика: 3 Гбит/сек на каждую
- 1 х 1 Гбит/сек сетевая карта, 4 очереди, привязана к node0, исходящий объём трафика: 100 Мбит/сек.
Решение:
1 Переткнуть одну из 10 Гбит/сек сетевых карт в другой PCI-слот, привязанный к NUMA node1.
2 Уменьшить число combined очередей для 10гбитных портов до числа ядер одного физического процессора:
for dev in eth0 eth1 eth2 eth3; do
ethtool -L $dev combined 8
done3 Распределить прерывания портов eth0, eth1 на ядра процессора, попадающие в NUMA node0, а портов eth2, eth3 на ядра процессора, попадающие в NUMA node1:
rss-ladder eth0 0
rss-ladder eth1 0
rss-ladder eth2 1
rss-ladder eth3 14 Увеличить eth0, eth1, eth2, eth3 RX-буферы:
for dev in eth0 eth1 eth2 eth3; do
rx-buffers-increase $dev
doneНеобычные кейсы
Не всегда всё идёт идеально:
- Встречались сетевые карты, теряющие пакеты (missed) в случае использования RSS на несколько ядер в одной NUMA-ноде. Решение странное, но рабочее — 6 RX-очередей привязаны к CPU0, в rps_cpus каждой очереди записана маска процессоров 111110, потери пропали.
- Встречались сетевые карты mellanox и intel (X710) продолжающие работать при прекратившемся росте счётчиков прерываний. Трафик в tcpdump имелся, нагрузка, создаваемая сетевыми картами висела на CPU0. Нормальная работа восстановилась после включения и выключения RPS. Почему — неизвестно.
- Некоторые SFP-модули для Intel 82599ES при обновлении драйвера (сборка ixgbe из исходников с sourceforge) "пропадают" из списка сетевых карт. При этом в lspci этот порт отображается, второй аналогичный порт работает, а в dmesg на оба порта одинаковые warning'и. Помогает флаг
unsupported_sfp=1,1при загрузке модуля ixgbe. По хорошему, однако, стоит купить supported sfp. - Некоторые драйверы сетевых карт подстраивают число очередей только под равные степени двойки значения (что обидно на 6-ядерных процессорах).
Update: после публикации автор осознал, что люди используют не только RHEL-based дистрибутивы для сетевых задач, а тесты в debian на наборах данных, собранных в RHEL-based системах, не отлавливают кучу багов. Большое спасибо всем сообщившим о том, что что-то не работает в Ubuntu/Debian/Altlinux! Все баги исправлены в релизе 2.0.10
Комментарии (41)

lexore
27.06.2017 19:32Как расшифровывается RPS в данном конткесте, если не секрет?
a5b
27.06.2017 19:43+1RPS: Receive Packet Steering, программный аналог аппаратного Receive-Side Scaling (RSS). Обе технологии позволяют распределять входящие пакеты по очередям в зависимости от хеша нескольких байтов заголовка (фильтра).
https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Performance_Tuning_Guide/network-rps.html
https://www.kernel.org/doc/Documentation/networking/scaling.txt
RSS: Receive Side Scaling
Contemporary NICs support multiple receive and transmit descriptor queues (multi-queue). On reception, a NIC can send different packets to different queues to distribute processing among CPUs. The NIC distributes packets by
applying a filter to each packet that assigns it to one of a small number of logical flows. Packets for each flow are steered to a separate receive queue, which in turn can be processed by separate CPUs. This mechanism is
generally known as “Receive-side Scaling” (RSS). The goal of RSS and the other scaling techniques is to increase performance uniformly.
…
Receive Packet Steering (RPS) is logically a software implementation of RSS. Being in software, it is necessarily called later in the datapath. Whereas RSS selects the queue and hence CPU that will run the hardware
interrupt handler, RPS selects the CPU to perform protocol processing above the interrupt handler. This is accomplished by placing the packet on the desired CPU’s backlog queue and waking up the CPU for processing.
RPS has some advantages over RSS:
1) it can be used with any NIC,
2) software filters can easily be added to hash over new protocols,
3) it does not increase hardware device interrupt rate (although it does introduce inter-processor interrupts (IPIs)).
RPS is called during bottom half of the receive interrupt handler, when a driver sends a packet up the network stack with netif_rx() or netif_receive_skb(). These call the get_rps_cpu() function, which selects the queue that should process a packet.
JovanottiRU
27.06.2017 21:20+1При запуске выдает следующее:
/usr/local/bin/network-top Traceback (most recent call last): File "/usr/local/bin/network-top", line 3, in <module> from netutils_linux_monitoring import NetworkTop File "/usr/local/lib/python2.7/dist-packages/netutils_linux_monitoring/__init__.py", line 1, in <module> from netutils_linux_monitoring.irqtop import IrqTop File "/usr/local/lib/python2.7/dist-packages/netutils_linux_monitoring/irqtop.py", line 7, in <module> from netutils_linux_monitoring.base_top import BaseTop File "/usr/local/lib/python2.7/dist-packages/netutils_linux_monitoring/base_top.py", line 7, in <module> from netutils_linux_monitoring.colors import wrap File "/usr/local/lib/python2.7/dist-packages/netutils_linux_monitoring/colors.py", line 7, in <module> 2: Fore.LIGHTYELLOW_EX, AttributeError: 'AnsiCodes' object has no attribute 'LIGHTYELLOW_EX'

weirded
27.06.2017 21:24Подскажите пожалуйста:
- какой дистрибутив linux вы используете.
- что выдаёт
set | egrep '^(TERM|LC|LANG).*='

JovanottiRU
27.06.2017 21:34Ubuntu 14.04.4 LTS
LANG=en_US.UTF-8
LANGUAGE=en_US:en
TERM=xtermweirded
27.06.2017 21:37Спасибо, создал issue на эту тему, попробую завтра вечером починить.
weirded
27.06.2017 22:26Развернул на digitalocean виртуалку:
Ubuntu 14.04.5 LANG=en_US.UTF-8 LANGUAGE=en_US:en TERM=xterm
Работает прекрасно. На всякий случай посмотрел исходники colorama, про все эти LIGHT..._EX:
These are fairly well supported, but not part of the standard.
Обвесил своеобразным костылём это дело, сейчас вместо ошибки скорее всего будет подсвечивать значения зеленоватым вместо жёлтого, скорее всего.
Обновиться можно с помощью
pip install --upgrade netutils-linux, билд в котором это поправлено: 2.0.4

SergeyD
28.06.2017 00:25+1weirded
Ubuntu 12.04
TERM=screen-bce
LANG=en_US.UTF-8
LANGUAGE=en_US:en
# rss-ladder eth1 0 - distribute interrupts of eth1 (-rx-) on socket 0 lscpu: unrecognized option '--extended=CPU,SOCKET'SergeyD
28.06.2017 00:28Ubuntu 16.04.2
TERM=xterm (xfce-terminal)
LANG=ru_RU.UTF-8
LANGUAGE=ru_RU:ru:en
# rss-ladder eth1 0 - distribute interrupts of eth1 (-rx-) on socket 0 - eth1: irq 128 1572865-edge -> eth1-rx-0 /usr/local/bin/rss-ladder: строка 80: echo: ошибка записи: Недопустимый аргументSergeyD
28.06.2017 00:32weirded
28.06.2017 09:09С 12.04 все в порядке в 2.0.5?
SergeyD
28.06.2017 11:28Не совсем, оно как-будто 2-х ядер не видит. Всё на первое вешает.
Написал в issue.weirded
28.06.2017 12:03А, понял. Там логика для раздельных RX и TX очередей следующая:
- Размазываем лесенкой все RX очереди по ядрам.
- Размазываем лесенкой все TX очереди по ядрам.
Собственно это он и делает, а поскольку RX очередь одна и TX очередь одна — обе очереди падают на 0 ядро.
В феврале ещё думал как лучше поступать в этом кейсе:
https://github.com/strizhechenko/netutils-linux/issues/8
пришёл к тому что нужно пилить тулзу которая работает со списком сетевых карт, но в итоге отложил на далёкое потом, т.к. она должна учитывать очень много факторов, которые сильно варьируются в зависимости от времени (рейт прерываний, типы очередей, объёмы трафика, суммарные ресурсы сервера) и это сложно.

9660
28.06.2017 09:13+1В debian и производных нет /etc/sysconfig/network-scripts/
Поэтому
rx-buffers-increase eth0
Traceback (most recent call last):
File "/usr/local/bin/rx-buffers-increase", line 24, in main()
File "/usr/local/bin/rx-buffers-increase", line 20, in main
RxBuffersIncreaser(dev, upper_bound).apply()
File "/usr/local/lib/python2.7/dist-packages/netutils_linux_tuning/rx_buffers.py", line 64, in apply
self.investigate()
File "/usr/local/lib/python2.7/dist-packages/netutils_linux_tuning/rx_buffers.py", line 33, in investigate
with open(path.join(ns, 'ifcfg-' + self.dev)) as config:
IOError: [Errno 2] No such file or directory: '/etc/sysconfig/network-scripts/ifcfg-eth0'
Templier
28.06.2017 10:53Актуально ли это для виртуальных серверов, куда проброшен зеркальный трафик?
weirded
28.06.2017 11:10Отчасти да, но это нужно делать:
- На виртуалке.
- На хосте.
- Ковырять дополнительно прямой проброс железа (ядер и сетёвок) в виртуалку.
и всё равно хорошей производительности в итоге не добиться.
Но если идеальная работа не преследуется, то вполне сойдёт :)
undro
28.06.2017 11:08gentoo:
network-topTraceback (most recent call last):
File "/usr/bin/network-top", line 7, in NetworkTop().run()
File "/usr/lib64/python2.7/site-packages/netutils_linux_monitoring/network_top.py", line 24, in __init__
self.parse_options()
File "/usr/lib64/python2.7/site-packages/netutils_linux_monitoring/network_top.py", line 117, in parse_options
top.post_optparse()
File "/usr/lib64/python2.7/site-packages/netutils_linux_monitoring/link_rate.py", line 152, in post_optparse
self.numa = Numa(self.options.devices, self.options.random)
File "/usr/lib64/python2.7/site-packages/netutils_linux_monitoring/numa.py", line 34, in __init__
self.detect_layouts()
File "/usr/lib64/python2.7/site-packages/netutils_linux_monitoring/numa.py", line 77, in detect_layouts
layouts = [list(map(int, row.split(b',')[2:4])) for row in rows]
ValueError: invalid literal for int() with base 10: ''weirded
28.06.2017 20:33Если в 2.0.8 повторяется, можете скинуть вывод
lscpu -p?undro
05.07.2017 09:05В 2.0.10 было так же.
Сейчас накатил 2.1.1. Работает :)weirded
05.07.2017 09:1132 битная система, полагаю?
undro
05.07.2017 09:42Нет, экспериментировал на такой машине:
undro netutils-linux # uname -a
Linux undro 4.4.21-gentoo #1 SMP Wed Feb 15 05:32:25 VLAT 2017 x86_64 Intel(R) Core(TM) i5-2500 CPU @ 3.30GHz GenuineIntel GNU/Linux
undro netutils-linux # lscpu -p
# The following is the parsable format, which can be fed to other
# programs. Each different item in every column has an unique ID
# starting from zero.
# CPU,Core,Socket,Node,,L1d,L1i,L2,L3
0,0,0,,,0,0,0,0
1,1,0,,,1,1,1,0
2,2,0,,,2,2,2,0
3,3,0,,,3,3,3,0

dmitrysamsonov
04.07.2017 10:50+2Отличные тулзы, спасибо!
Нет смысла покупать сервер с числом ядер большим, чем суммарное число очередей сетевых карт.
Вот это очень спорно (особенно перед следующей строчкой про RPS). Потому что сервера занимаются не только обработкой пакетов, но ещё и крутят какое-то приложение, работающее с данными из этих пакетов. И приложению дополнительные (пусть и виртуальные) ядра могут вполне быть на руку. В нашем случае, например, как раз больше трафика удаётся обработать с включенным HT.
Ещё, пользователи тулзов наверняка оценили бы возможность настраивать ещё и RFS и XPS.weirded
05.07.2017 06:15Не, вы правы конечно, если прибить запуск юзерспэйс приложений на ядра не занимающиеся обработкой пакетов — профит будет, но в случае если это тупая молотилка трафика (в основном такими занимаюсь, небольшая профессиональная деформация) — то вряд ли.
Про RFS — тут опять же надо вклиниваться в процесс запуска приложения, которое должно определенный сорт трафика потреблять, а не только выполнить правильную команду для ethtool. Что-то универсальное для этого запилить сложновато. Хотя, если есть идеи — welcome to the github issues, я бы с удовольствием сделал.
dmitrysamsonov
05.07.2017 10:02+1Для RFS достаточно включить RPS и задать ненулевое значение в файлах /sys/class/net/eth*/queues/rx-*/rps_flow_cnt. Подробнее в https://www.kernel.org/doc/Documentation/networking/scaling.txt.
Это улучшайзер RPS, который запоминает на каком ядре находится процесс, обрабатывающий соединение.
AlexeyAB
05.07.2017 16:15Согласен, тем более RFS умеет избегать «out of order packets» при миграции потоков приложения по ядрам, т.е. даже если потоки не привязаны к ядрам — это не критично: https://www.kernel.org/doc/Documentation/networking/scaling.txt
When the scheduler moves a thread to a new CPU while it has outstanding
receive packets on the old CPU, packets may arrive out of order. To
avoid this, RFS uses a second flow table to track outstanding packets
for each flow
(привязка приложения к нодам во время запуска приложения (numactl, taskset) или потоков к ядрам на уровне приложения (sched_setaffinity, pthread_setaffinity_np) — очень полезная, но отдельная задача)
При RPS один и тот же пакет обрабатывается в kernel-space TCP/IP-stack на одном CPU-Core, и затем в user-space вашего приложения в потоке работающем на другом CPU-Core, это добавляет лишний обмен между ядрами процессора.
При RFS все пакеты одного соединения обрабатываются в kernel-space и user-space на одном ядре.weirded
06.07.2017 23:00Пардон, попутал с Receive Flow Hash Indirectiction.
Да, RFS уместен, в случае если кто-то в userspace пакетики получает, но в случае форварда это, как мне кажется только лишний оверхед (прыжок пакета в Flow Table).
chabapok
04.07.2017 14:09Хм. У меня network-top показывает 2 строки:
# /proc/interrupts
CPU0 CPU1 CPU2 CPU3
31 26 196 94 interrupts
81 67 60 43 interrupts
Столбцы — ясно. Но что означают строки — непонятно.weirded
05.07.2017 06:06По дефолту он скрывает строки, в которых все прерывания подрастают меньше, чем на 80 в секунду. Его цель показать то, что несет большую часть нагрузки на ядра процессора/выявлять шторм прерываний. Можете использовать:
network-top -l 0
AlexeyAB
05.07.2017 16:31Хорошая статья. Готовый код всегда лучше общих рассуждений.
Встречались сетевые карты mellanox ...
Используете библиотеку VMA для обмена по LAN если на обоих серверах установлены Mellanox Ethernet-карты, или в ваших кейсах почти весь трафик внешний?
http://www.mellanox.com/page/software_vma?mtag=vma
The result is a reduction in latency by as much as 300% and an increase in application throughput by as much as 200% per server as compared to applications running on standard Ethernet or InfiniBand interconnect networks.

WST
Пользуясь внезапно подвернувшимся случаем, хочу ещё раз поблагодарить вас за ваши продукты :)