

Почему мы занимаемся кодами Рида-Соломона
Одно из главных направлений работы компании YADRO — разработка систем хранения данных (СХД). Можно долго обсуждать, какие характеристики данных систем являются самыми важными с точки зрения конечного пользователя. Это может быть скорость операций ввода/вывода, стоимость владения системой, уровень энергопотребления или что-то ещё. Но все эти характеристики будут иметь смысл только в том случае, если система обеспечивает необходимый пользователю уровень сохранности данных. Как результат, для всех разработчиков подобных систем, вопросы обеспечения надёжности хранения данных выходят на первый план.
Долгое время главным игроком в сфере безопасного хранения данных оставалась технология RAID. Подобные классические решения, наряду с известными плюсами, обладают и определёнными ограничениями. К ним можно отнести:
- относительно низкий уровень защиты (например, RAID 6 поддерживает выход из строя максимум двух дисков)
- необходимость держать запасные диски
- невозможность контролировать распределение «parity» блоков (это может быть важно для определенных типов дисков)
- сложность поддержки «гетерогенных» дисков
В связи с этим, в последнее время, набирают популярность технологии, основанные на всевозможных избыточных кодах (в англоязычной литературе за подобными технологиями закрепилось название — erasure coding), которые предоставляют гораздо больше возможностей по сравнению с классическим RAID.
На данный момент наша команда занимается разработкой системы хранения данных TATLIN. По архитектуре системы мы планируем написать отдельную серию статей, тут лишь скажем, что в какой-то момент времени перед нами встала задача реализации собственной системы надёжного хранения данных. После изучения вопроса мы решили остановиться на проверенных временем кодах Рида-Соломона. Существуют готовые библиотеки (например, ISA-L от Intel или Jerasure авторства James S. Plank). В них реализованы соответствующие процедуры кодирования/декодирования. Но учитывая, что наша аппаратная платформа построена на базе архитектуры OpenPOWER, а вся логика системы реализована как модуль ядра ОС Linux, — было принято решение делать свою реализацию, оптимизированную под особенности нашей системы.
В этой первой статье я попытаюсь объяснить, о чем идет речь, когда говорят о кодах Рида-Соломона в контексте систем хранения данных. Начнем с простых примеров, которые позволят лучше уяснить сущность решаемых проблем.
Базовая задача восстановления утраченного
Предположим, что есть два произвольных целых числа и . Необходимо разработать алгоритм, который двум этим числам поставит в соответствие третье число , причём такое, что по нему будет возможно однозначно восстановить любое из двух исходных чисел при потере одного из них. Другими словами, имея пару ( и ) или ( и ), возможно однозначно восстановить или соответственно. Существует много вариантов реализации подобного алгоритма, но, вероятно, самым простым является тот, который к двум исходным числам применяет битовую операцию «Исключающее «ИЛИ» (XOR)», т.е. . Тогда для восстановления можно воспользоваться равенством (для восстановления , ).
Немного усложним задачу. Предположим, что исходных чисел не два, а три — , и . Как и прежде, нужен алгоритм, позволяющий справиться с потерей одного из исходных чисел. Легко заметить, что ничто не мешает снова использовать битовую операцию «Исключающее «ИЛИ»», . Для восстановления можно воспользоваться равенством .
Усложним задачу ещё немного. Как и прежде, имеется три числа , и , а вот потерять, в этот раз, мы можем не одно, а любые два из них. Очевидно, что просто использовать операцию «Исключающее «ИЛИ» уже не получится. Как же восстанавливать потерянные числа?
Принцип кодирования Рида-Соломона на простых примерах с картинками
Одним, из возможных путей решения данной задачи, является применение кодов Рида-Соломона. Формальное описание метода легко найти в Интернете, но основная проблема заключается в том, что людям, далеким от «полей Галуа», достаточно сложно понять, как, собственно, всё это работает. Вот, например, определение из Википедии:

Попробуем разобраться с тем, как это работает, начав с более интуитивных вещей. Для этого вернемся к нашей последней задаче. Напомним, что есть три произвольных целых числа, любые два из них могут быть потеряны, необходимо научиться восстанавливать потерянные числа по оставшимся. Для этого применим «алгебраический» подход.
Но прежде необходимо напомнить еще об одном важном моменте. Технологии восстановления данных неспроста называются методами избыточного кодирования. По исходным данным вычисляются некоторые «избыточные», которые потом позволяют восстановить потерянные. Не вдаваясь в подробности заметим, что эмпирическое правило такое — чем больше данных может быть потеряно, тем больше «избыточных» необходимо иметь. В нашем случае для восстановления двух чисел, нам придётся по некоторому алгоритму сконструировать два «избыточных». В общем случае, если нужно поддерживать потерю чисел, необходимо соответственно иметь избыточных.
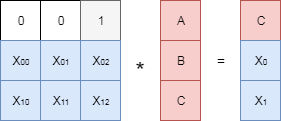
Упомянутый выше «алгебраический» подход состоит в следующем. Составляется матрица специального вида размера . Первые три строки этой матрицы образуют единичную матрицу, а последние две — это некоторые числа, о выборе которых мы поговорим позднее. В англоязычной литературе эту матрицу обычно называют generator matrix, в русскоязычной встречается несколько названий, в этой статье будет использоваться — порождающая матрица. Умножим сконструированную матрицу на вектор, составленный из исходных чисел , и .

В результате умножения матрицы на вектор с данными получаем два «избыточных» числа, обозначенных на рисунке как и . Давайте посмотрим, как с помощью этих «избыточных» данных можно восстановить, к примеру, потерянные и .
Вычеркнем из порождающей матрицы строки, соответствующие «пропавшим» данным. В нашем случае соответствует первой строке, а – второй. Полученную матрицу умножим на вектор с данными, и в результате получим следующее уравнение:
Проблема лишь в том, что и мы потеряли, и они нам теперь неизвестны. Как мы можем их найти? Есть очень элегантное решение этой проблемы.
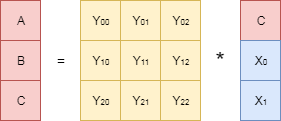
Вычеркнем соответствующие строки из порождающей матрицы и найдём обратную к ней. На рисунке эта обратная матрица обозначена как . Теперь домножим левую и правую части исходного уравнения на эту обратную матрицу:

Сокращая матрицы в левой части уравнения (произведение обратной и прямой матриц есть единичная матрица), и учитывая тот факт, что в правой части уравнения нет неизвестных параметров, получаем выражения для искомых и .
Собственно говоря, то, что мы сейчас проделали — основа всех типов кодов Рида-Соломона, применяемых в системах хранения данных. Процесс кодирования заключается в нахождении «избыточных» данных , , а процесс декодирования — в нахождении обратной матрицы и умножения её на вектор «сохранившихся» данных.
Нетрудно заметить, что рассмотренная схема может быть обобщена на произвольное количество «исходных» и «избыточных» данных. Другими словами, по исходным числам можно построить избыточных, причем всегда возможно восстановить потерю любых из чисел. В этом случае порождающая матрица будет иметь размер , а верхняя часть матрицы размером будет единичной.
Вернемся к вопросу о построении порождающей матрицы. Можем ли мы выбрать числа произвольным образом? Ответ – нет. Выбирать их нужно таким образом, чтобы вне зависимости от вычеркиваемых строк, матрица оставалась обратимой. К счастью, в математике давно известны типы матриц, обладающие нужным нам свойством. Например, матрица Коши. В этом случае сам метод кодирования часто называют методом Коши-Рида-Соломона (Cauchy-Reed-Solomon). Иногда, для этих же целей используют матрицу Вандермонда, и соответственно, метод носит название Вандермонда-Рида-Соломона (Vandermonde-Reed-Solomon).
Переходим к следующей проблеме. Для представления чисел в ЭВМ используется фиксированное число байтов. Соответственно, в наших алгоритмах мы не можем свободно оперировать произвольными рациональными, и тем более, вещественными числами. Мы просто не сможем реализовать такой алгоритм на ЭВМ. В нашем случае порождающая матрица состоит из целых чисел, но при обращении этой матрицы могут возникнуть рациональные числа, представлять которые в памяти ЭВМ проблематично. Вот мы и дошли до того места, когда на сцену выходят знаменитые поля Галуа.
Поля Галуа
Итак, что такое поля Галуа? Начнём опять с поясняющих примеров. Мы все привыкли оперировать (складывать, вычитать, умножать, делить и прочее) с числами – натуральными, рациональными, вещественными. Однако, вместо привычных чисел, мы можем начать рассматривать произвольные множества объектов (конечные и/или бесконечные) и вводить на этих множествах операции, аналогичные сложению, вычитанию и т.д. Собственно говоря, математические структуры типа групп, колец, полей — это множества, на которых введены определенные операции, причем, результаты этих операций снова принадлежат исходному множеству. Например, на множестве натуральных чисел, мы можем ввести стандартные операции сложения, вычитания и умножения. Результатом опять будет натуральное число. А вот с делением все хуже, при делении двух натуральных чисел результат может быть дробным числом.
Поле – это множество, на котором заданы операции сложения, вычитания, умножения и деления. Пример — поле рациональных чисел (дробей). Поле Галуа — конечное поле (множество, содержащее конечное количество элементов). Обычно поля Галуа обозначаются как , где — количество элементов в поле. Разработаны методы построения полей необходимой размерности (если это возможно). Конечным результатом подобных построений обычно являются таблицы сложения и умножения, которые двум элементам поля ставят в соответствие третий элемент поля.
Может возникнуть вопрос – как мы всё это будем использовать? При реализации алгоритмов на ЭВМ удобно работать с байтами. Наш алгоритм может принимать на входе байт исходных данных и вычислять по ним байт избыточных. В одном байте может содержаться 256 различных значений, поэтому, мы можем создать поле и рассчитывать избыточные байт, пользуясь арифметикой полей Галуа. Сам подход к кодированию/декодированию данных (построение порождающей матрицы, обращение матрицы, умножение матрицы на столбец) остаётся таким же, как и прежде.
Хорошо, мы в итоге научились по исходным байтам конструировать дополнительные байт, которые можно использовать при сбоях. Как это всё работает в реальных системах хранения? В реальных СХД обычно работают с блоками данных фиксированного размера (в разных системах этот размер варьируется от десятков мегабайт до гигабайтов). Этот фиксированный блок разбивается на фрагментов и по ним конструируются дополнительные фрагментов.
Процесс конструирования фрагментов происходит следующим образом. Берут по одному байту из каждого из исходных фрагментов по смещению 0. По этим данным генерируется K дополнительных байтов, каждый из который идет в соответствующие дополнительные фрагменты по смещению 0. Этот процесс повторяется для смещения – 1, 2, 3,… После того, как процедура кодирования закончена, фрагменты сохраняются на разные диски. Это можно изобразить следующим образом:

При выходе из строя одного или нескольких дисков, соответствующие потерянные фрагменты реконструируются и сохраняются на других дисках.
Теоретическая часть постепенно подходит к концу, будем надеяться, что базовый принцип кодирования и декодирования данных с использованием кодов Рида-Соломона теперь более или менее понятен. Если будет интерес к данной теме, то в следующих частях можно будет более подробно остановится на арифметике полей Галуа, реализациях алгоритма кодирования/декодирования на конкретных аппаратных платформах, поговорить про техники оптимизации.
UPD. Вынесенный из комментариев список литературы по теме (спасибо whitedruid):
— «Алгебраическая теория кодирования», Берлекэмп Э., 1971.
— «Теория кодов, исправляющих ошибки», Мак-Вильямс Ф., Слоэн Н.Дж., 1979.
— «Теория и практика кодов, контролирующих ошибки.», 1986.
— «Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение», Морелос-Сарагоса Р., 2005.
— «Кодирование с исправлением ошибок в системах цифровой связи», Кларк Дж., Кейн Дж., 1987.
— «Упаковки шаров, решетки и группы.», Конвей Дж.Н., Слоэн Н.Дж.А., 1990.
whitedruid: Книгу «Упаковка шаров, решетки и группы» сам прочёл относительно недавно — очень понравилось!
— «Введение в алгебраические коды» — лекции преподавателя МФТИ Юрия Львовича Сагаловича, оформленные в виде книги.
— «Коды Рида-Соломона с точки зрения обывателя» — написано простым языком.
— «Коды, исправляющие ошибки» — кратко, понятно и с картинками :)
— «Заметки по теории кодирования», А. Ромащенко, А. Румянцев, А. Шень, 2011 год. — своего рода «шпаргалка» — кратко, ёмко, однако требует некоторого уровня подготовки.
— Также нельзя обойти стороной семинары по «Теории кодирования», которые регулярно организуются сотрудниками «Институт проблем передачи информации им. А.А. Харкевича Российской академии наук», г. Москва. Далее — по ссылкам — можно найти много интересного по темам, связанным с математической теорией кодирования, поднимаются актуальные вопросы в рамках дисциплины. Например, про последовательное декодирование полярных и расширенных кодов Рида-Соломона. В поисковых же системах можно найти уже статьи автора.
Комментарии (29)

arandomic
24.08.2017 10:11+3«Вычеркнем из порождающей матрицы строки, соответствующие «пропавшим» данным.» — В реальной ситуации еще нужно выяснить какие данные пропали A и B или C и X0…

Sirion
24.08.2017 10:32Если данные, соответствующие каждой буковке, пишутся на свой диск, то выяснение этого вопроса тривиально, нет?
arandomic
24.08.2017 12:05+1Ну, алгоритм универсальный же.
Используется не только для восстановления данных в системах хранения информации, но и для коррекции ошибок при передаче данных.
А во входящем потоке у нас A-B-C-X0-X1 идут подряд. и тут либо добавлять еще избыточную информацию, чтобы разделить их, либо — поиск ошибок, Форни итп.
AC130
24.08.2017 19:27Вообще там есть разделение на стирания (когда приёмник уверен что конкретный бит пропал при передаче) и ошибки (когда приёмник уверен что конкретный бит — вот такой, а на самом деле он был противоположный). Способность кода исправлять что-либо зависит от его расстояния. К примеру код Хэмминга (7, 4) имеет расстояние 3 и способен исправить один бит (при отсутствии стираний), либо два стирания (предполагая что ошибок нет). Если к нему добавить доп. бит контроля чётности, то расстояние увеличится до 4 и код будет способен исправлять одновременно одну ошибку и восстанавливать одно стирание (к примеру если пропал тот самый бит чётности, то код может исправить ошибку в первых 7 битах и восстановить стёртый бит чётности).
m-a-k-s-i-m Автор
24.08.2017 10:35Да, в реальных СХД хранится информация о том, какие фрагменты присутствуют на каждом диске. При выходе диска из строя, система составляет список потерянных фрагментов и передаёт эту информацию модулю восстановления данных.

sci_nov
24.08.2017 10:35Можете что-нибудь сказать о соответствии некоторой матрицы Коши порождающему полиному согласно определения кода Рида-Соломона? Насколько я помню, полиному соответствует некоторая матрица Вандермонда. Спасибо.
whitedruid
24.08.2017 12:38+5Спасибо за статью!
В свою очередь хотел бы поделиться кратким списком литературы, а также парой ссылок — для тех, кто желает всесторонне изучить вопросы, связанные с алгебраической теорией кодирования.
Вероятно, книги уже неоднократно упоминались в статьях и комментариях по тематике, однако, на мой взгляд, список литературы никогда не бывает избыточным :)
Из закладок
— «Алгебраическая теория кодирования», Берлекэмп Э., 1971.
— «Теория кодов, исправляющих ошибки», Мак-Вильямс Ф., Слоэн Н.Дж., 1979.
— «Теория и практика кодов, контролирующих ошибки.», 1986.
— «Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение», Морелос-Сарагоса Р., 2005.
— «Кодирование с исправлением ошибок в системах цифровой связи», Кларк Дж., Кейн Дж., 1987.
— «Упаковки шаров, решетки и группы.», Конвей Дж.Н., Слоэн Н.Дж.А., 1990.
Книгу «Упаковка шаров, решетки и группы» сам прочёл относительно недавно — очень понравилось!
— «Введение в алгебраические коды» — лекции преподавателя МФТИ Юрия Львовича Сагаловича, оформленные в виде книги.
— «Коды Рида-Соломона с точки зрения обывателя» — написано простым языком.
— «Коды, исправляющие ошибки» — кратко, понятно и с картинками :)
SemenovNV
24.08.2017 12:48+1Спасибо за полезную подборку! Если не возражаете, можем добавить в конец самого поста (конечно, с упоминанием вас), чтобы больше людей увидели.
whitedruid
24.08.2017 13:22+1Нет, не возражаю. Рад, что список литературы показался Вам полезным.
Добавьте, пожалуйста, ещё один документ: «Заметки по теории кодирования», А. Ромащенко, А. Румянцев, А. Шень, 2011 год. — своего рода «шпаргалка» — кратко, ёмко, однако требует некоторого уровня подготовки.
Также нельзя обойти стороной семинары по «Теории кодирования», которые регулярно организуются сотрудниками «Институт проблем передачи информации им. А.А. Харкевича Российской академии наук», г. Москва. Ссылка на math-net.ru Далее — по ссылкам — можно найти много интересного по темам, связанным с математической теорией кодирования, поднимаются актуальные вопросы в рамках дисциплины. Например, про последовательное декодирование полярных и расширенных кодов Рида-Соломона.В поисковых же системах можно найти уже статьи автора.

LorHobbit
25.08.2017 10:04+1У покойного Криса Касперски было довольно интересное введение в предмет — «Могущество кодов Рида-Соломона или информация, воскресшая из пепла» — как всегда у автора, статья спорная и отражающая частично его собственный опыт. На данный момент статья доступна в архиве, требует гуглокапчу:
archive.li/SBMti
Dmitry88
24.08.2017 13:41Вы IBM?
SemenovNV
24.08.2017 14:23+1Нет. И на всякий случай — мы не Рид и Соломон. Мы YADRO.
Dmitry88
24.08.2017 14:27Это не звучало, как обвинение, скорее комплимент
oem.yadro.com
Ничего зазорного в OEM нет.
SemenovNV
24.08.2017 14:39Это уже обсуждалось в комментах к самой первой нашей статье.
Есть нормальный IT-бизнес, позволяющий финансировать свои разработки. Про эти разработки и пишем сюда в блог, почитайте наши статьи, вопросы к ним и ответы наших разработчиков — Хабр же технический ресурс, а не коммерческий.
Ну и на yadro.com про свои продукты пишем.Dmitry88
24.08.2017 14:50понял, удачи вам
А почему игнорируется AIX для VESNIN? Это технологическая проблема или политическая?
p.s.не мое дело, но yadro звучит отталкивающе, словно дитя СколковоSemenovNV
24.08.2017 15:14AIX требует подложки над аппаратурой в виде PowerVM, проприетарной технологии IBM, которая не доступна в OpenPOWER. Опять же, ввиду закрытости, мы не имеем возможности добавить в AIX поддержку работы на «Bare Metal». Проблема технологическая, решение которой, с политической точки зрения, никому не интересно.
Dmitry88
24.08.2017 15:17жаль, а то просадить по цене IBM не мешало бы в плане AIX серверов. Но их тоже можно понять, отдавать кусок рынка никому не хочется

Gerrr
24.08.2017 14:26Долгое время главным игроком в сфере безопасного хранения данных оставалась технология RAID.
Эту технологию сейчас кто-то смог обогнать по частоте применения? Интересно было бы прочитать кто. Даже если это произошло в какой-то конкретной сфере.
Очень буду ждать сравнения классических технологий RAID и вашей разработки. Хотя не до конца понимаю зачем свою реализацию противопоставлять самой технологии. Не правильнее ли запатентовать свой кастомный уровень.m-a-k-s-i-m Автор
24.08.2017 15:17По «частоте применения», возможно, технология RAID — лидер. По другим критериям, например, «объемы данных», картина, думаю, другая. Все известные мне «облачные» решения не используют RAID для хранения пользовательских данных. А объемы данных там гигантские. Современные классические СХД в связи с ростом объемов данных и увеличением требований к «физической» плотности систем, начинают сталкиваться с теми же ограничениями, что и «облачные системы» (где технологии RAID не находят массового применения). На самом деле, мы не противники RAID и несомненно есть и будут области, где RAID – оптимальный выбор. Мы рассматривали и такой вариант, но пришли к выводу, что использовать в нашем случае RAID — нецелесообразно.
perhamm
24.08.2017 15:23А можно Вас попросить рассказать каким образом при использовании erasure coding гарантируются различные схемы отказоустойчивости, например в документации к одному хранилищу данных написано, что поддерживаются схемы защиты 2d:1n или, например, 3d:1n_1d. То есть поддерживается выход из строя 2 дисков либо 1 ноды, а во втором случае поддерживает выход из строя 3 дисков либо 1 ноды и 1 диска. Вот как такие вещи реализуются? И означает ли это что 100% данные потеряются при выходе из строя, например, 3 дисков при схеме защиты 2d:1n? Но больше всего конечно интересен сам механизм.
m-a-k-s-i-m Автор
24.08.2017 15:48Все зависит от архитектуры системы. В нашем случае, все «головы» кластера видят один и тот же набор дисков. Выход из строя «головы» не приводит к потере данных. Только сломавшийся диск требует запуска процедуры восстановления. Когда говорят про схему кодирования N+K (в технологиях erasure coding), подразумевается, что блок с данными разбивается на N фрагментов, по ним считаются дополнительные K, и все это «разлетается» по разным дискам. У нас схема по умолчанию 12+4, соответственно любые 4 диска можно потерять.
В других СХД, архитектура может быть другой. Конкретная «голова» может отвечать за какое-либо число дисков и выход из строя «головы» равнозначен поломке всех дисков, за которые она отвечает. Если, к примеру, «голова» отвечает за 3 диска, а схема 12+4, то можно потерять или 4 диска, или 1 диск и одну «голову» или …
mnyam
m-a-k-s-i-m Автор
Была идея затронуть следующие темы:
1) Коды Рида-Соломона. Теория
2) Арифметика полей Галуа. Теория и реализация
3) Коды Рида-Соломона. Реализации
4) Коды Рида-Соломона. Программные оптимизации
5) Коды Рида-Соломона. Аппаратные оптимизации
Посмотрим, на что хватит времени…
Kolyuchkin
«Взялся за гуж, не говори, что не дюж!» С нетерпением жду продолжения))
Nick_Shl
Прочитав первое слово было подумал, что какого-то Максима хотите обозвать нехорошим словом :D
Аккуратнее надо…