
Как работает ArrayList, вполне понятно. Есть много статей по этому поводу, часть из них иллюстрированы замечательными картинками, так что даже новичкам становится сразу все ясно. К лучшим статьям на эту тему я отношу «Структуры данных в картинках. ArrayList», написанную tarzan82.
Этот же автор описывает принципы работы LinkedList, однако часть данных устарела еще с выходом Java 7, поэтому попытка детально разобраться, что происходит внутри этой коллекции, по рисункам tarzan82 уже сложно. Да и в других источниках я не встретила понятных картинок, потому и возникла идея написать эту статью.
Итак, LinkedList — класс, реализующий два интерфейса — List и Deque. Это обеспечивает возможность создания двунаправленной очереди из любых (в том числе и null) элементов. Каждый объект, помещенный в связанный список, является узлом (нодом). Каждый узел содержит элемент, ссылку на предыдущий и следующий узел. Фактически связанный список состоит из последовательности узлов, каждый из которых предназначен для хранения объекта определенного при создании типа.

Разберемся, что же происходит, когда мы пишем уже простые и привычные строки кода.
1. Создание связанного списка
LinkedList<Integer> numbers = new LinkedList<>();Данный код создает объект класса LinkedList и сохраняет его в ссылке numbers. Созданный объект предназначен для хранения целых чисел (Integer). Пока этот объект пуст.
Класс LinkedList содержит три поля:
// модификатор transient указывает на то, что данное свойство класса нельзя
// сериализировать
transient int size = 0;
transient Node<E> first;
transient Node<E> last;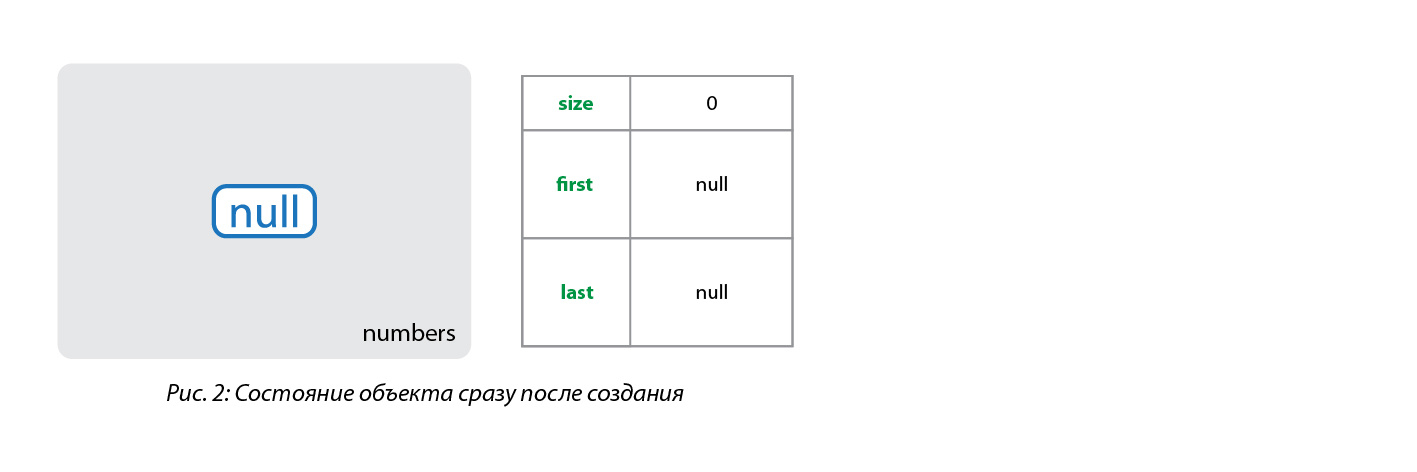
2. Добавление объекта в конец связанного списка
numbers.add(8);Данный код добавляет число 8 в конец ранее созданного списка. Под «капотом» этот метод вызывает ряд других методов, обеспечивающих создание объекта типа Integer, создание нового узла, установку объекта класса Integer в поле item этого узла, добавление узла в конец списка и установку ссылок на соседние узлы.
Для установки ссылок на предыдущий и следующий элементы LinkedList использует объекты своего вложенного класса Node:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}При каждом добавлении объекта в список создается один новый узел, а также изменяются значения полей связанного списка (size, first, last).
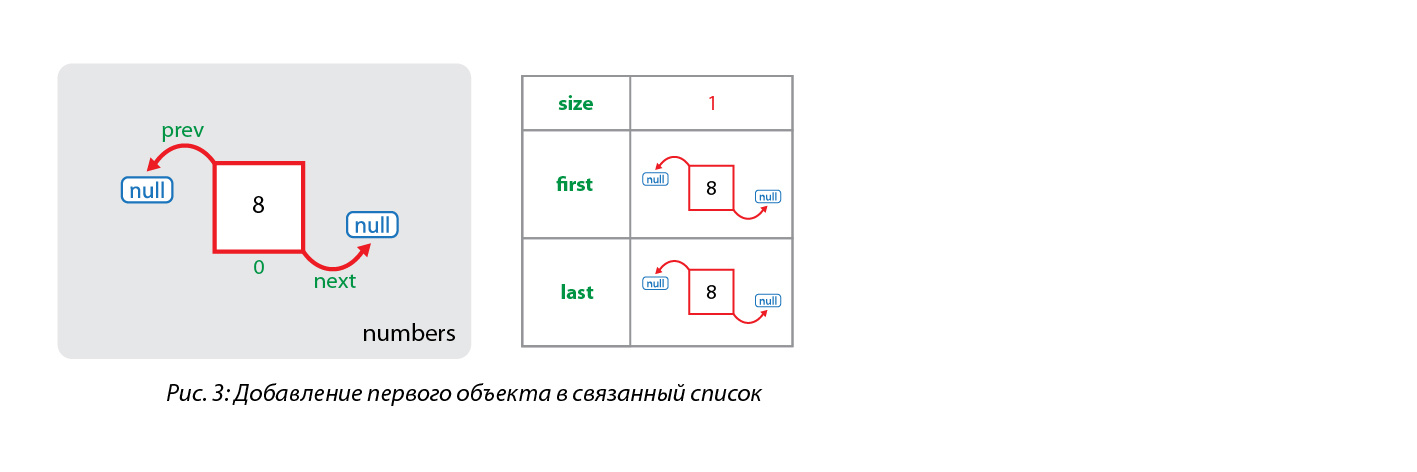
В случае с добавлением первого элемента создается узел, у которого предыдущий и следующий элементы отсутствуют, т.е. являются null, размер коллекции увеличивается на 1, а созданный узел устанавливается как первый и последний элемент коллекции.
Добавим еще один элемент в нашу коллекцию:
numbers.add(5);Сначала создается узел для нового элемента (число 5) и устанавливается ссылка на существующий элемент (узел с числом 8) коллекции как на предыдущий, а следующим элементом у созданного узла остается null. Также этот новый узел сохраняется в переменную связанного списка last:
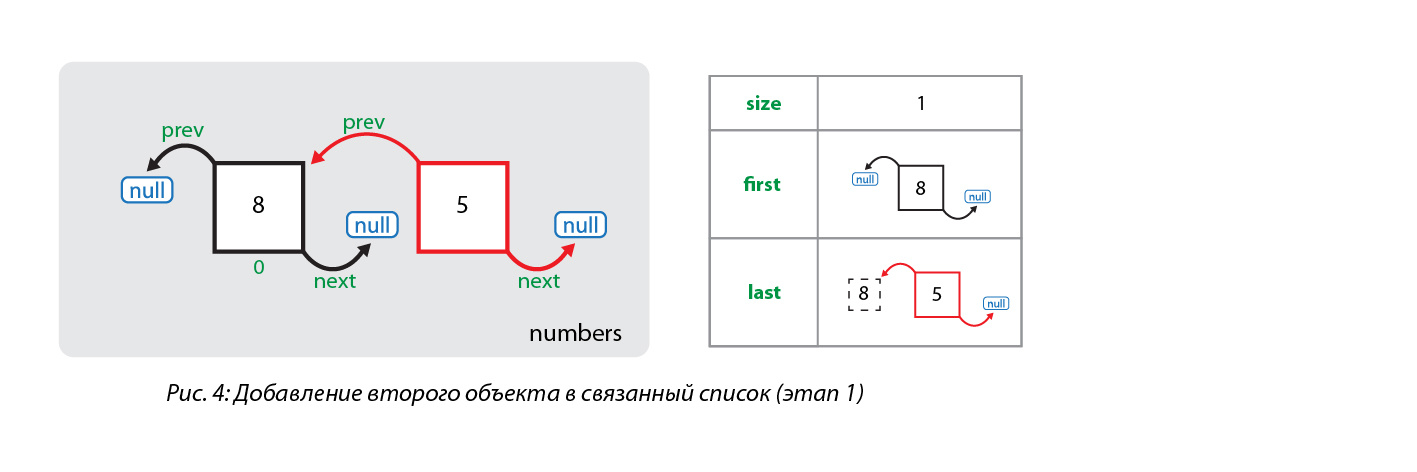
Как можно увидеть на рис. 4, первый элемент коллекции (под индексом 0) пока ссылается на null как на следующий элемент. Теперь эта ссылка заменяется и первый элемент начинает ссылаться на второй элемент коллекции (под индексом 1), а также увеличивается размер коллекции:

3. Добавление объекта в середину связанного списка
numbers.add(1, 13);LinkedList позволяет добавить элемент в середину списка. Для этого используется метод add(index, element), где index — это место в списке, куда будет вставлен элемент element.
Как и метод add(element), данный метод вызывает несколько других методов. Сначала осуществляется проверка значения index, которое должно быть положительным числом, меньшим или равным размеру списка. Если index не удовлетворит этим условиям, то будет сгенирировано исключение IndexOutOfBoundsException.
Затем, если index равен размеру коллеции, то осуществляются действия, описанные в п. 2, так как фактически необходимо вставить элемент в конец существующего списка.
Если же index не равен size списка, то осуществляется вставка перед элементом, который до этой вставки имеет заданный индекс, т.е. в данном случае перед узлом со значением 5.
Для начала с помощью метода node(index) определяется узел, находящийся в данный момент под индексом, под который нам необходимо вставить новый узел. Поиск данного узла осуществляется с помощью простого цикла for по половине списка (в зависимости от значения индекса — либо с начала до элемента, либо с конца до элемента). Далее создается узел для нового элемента (число 13), ссылка на предыдущий элемент устанавливается на узел, в котором элементом является число 8, а ссылка на следующий элемент устанавливается на узел, в котором элементом является число 5. Ссылки ранее существующих узлов пока не изменены:
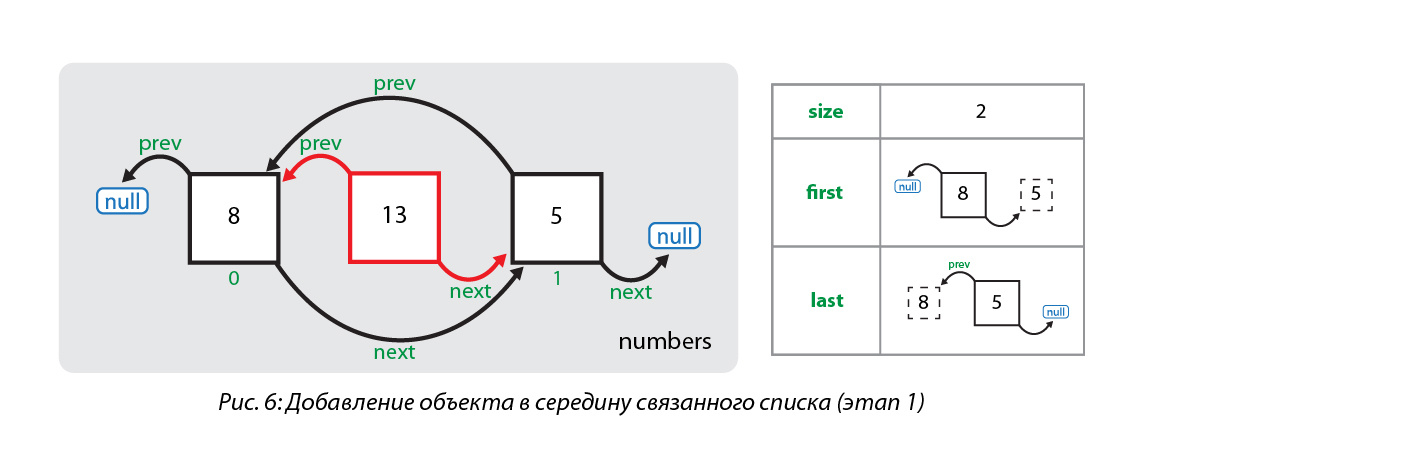
Теперь последовательно заменяются ссылки: для элемента, следующего за новым элементом, заменяется ссылка на предыдущий элемент (теперь она указывает на узел со значением 13), для предшествующего новому элементу заменяется ссылка на следующий элемент (теперь она указывает на узел со значением 5). И в последнюю очередь увеличивается размер списка:
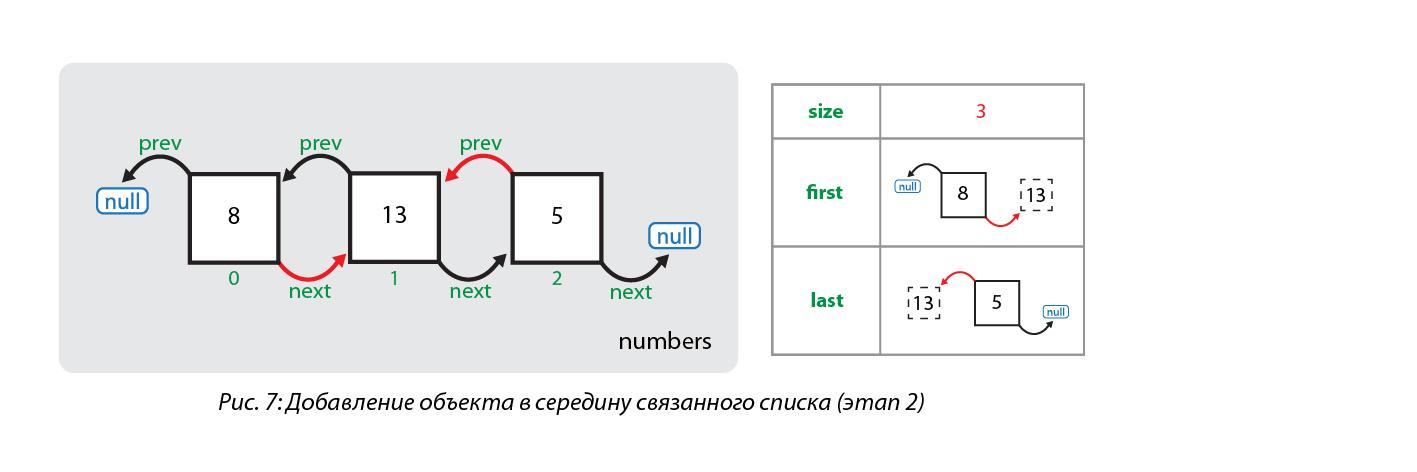
4. Удаление объекта из списка
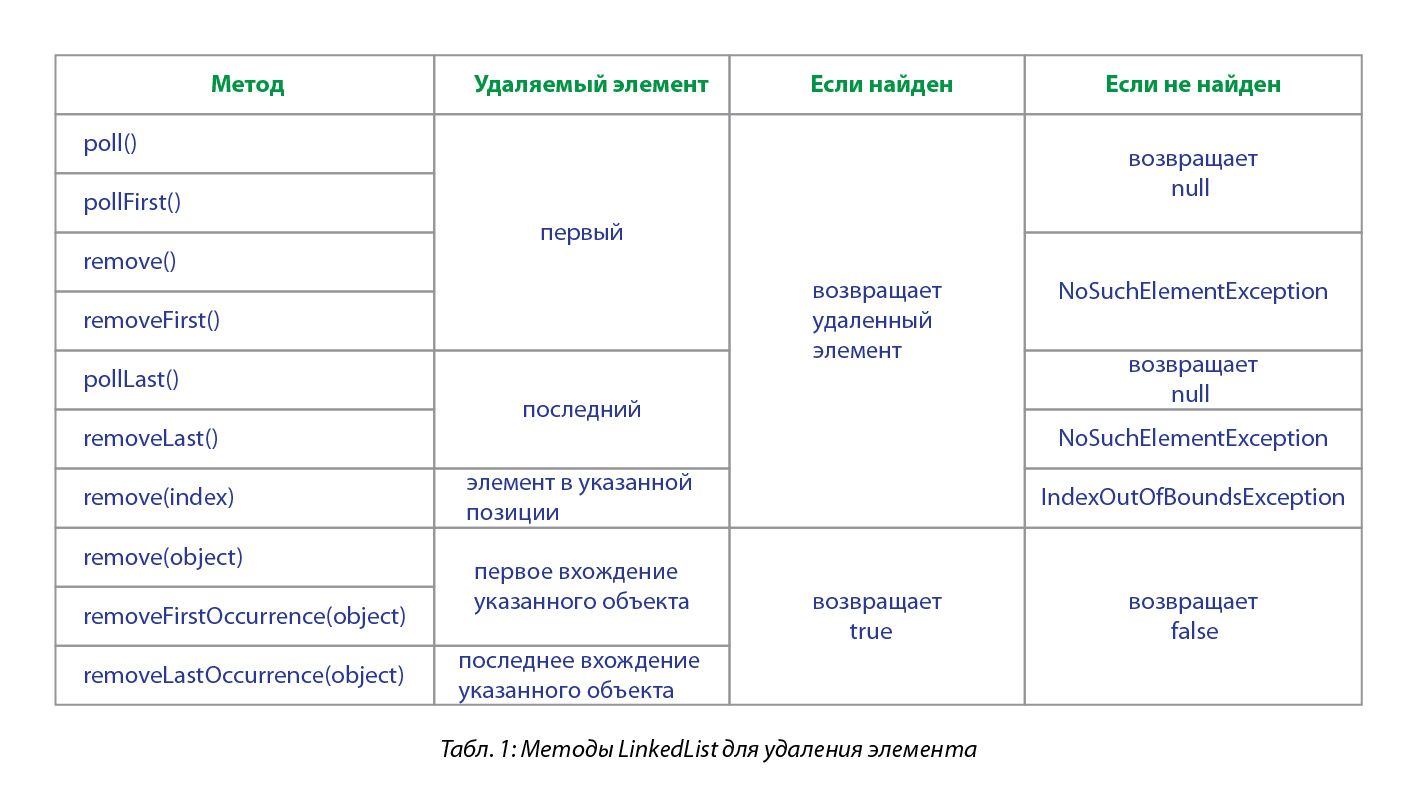
Для удаления одного элемента из списка класс LinkedList предлагает нам аж 10 методов, различающихся по типу возвращаемого значения, наличию или отсутствию выбрасываемых исключений, а также способу указания, какой именно элемент следует удалить:
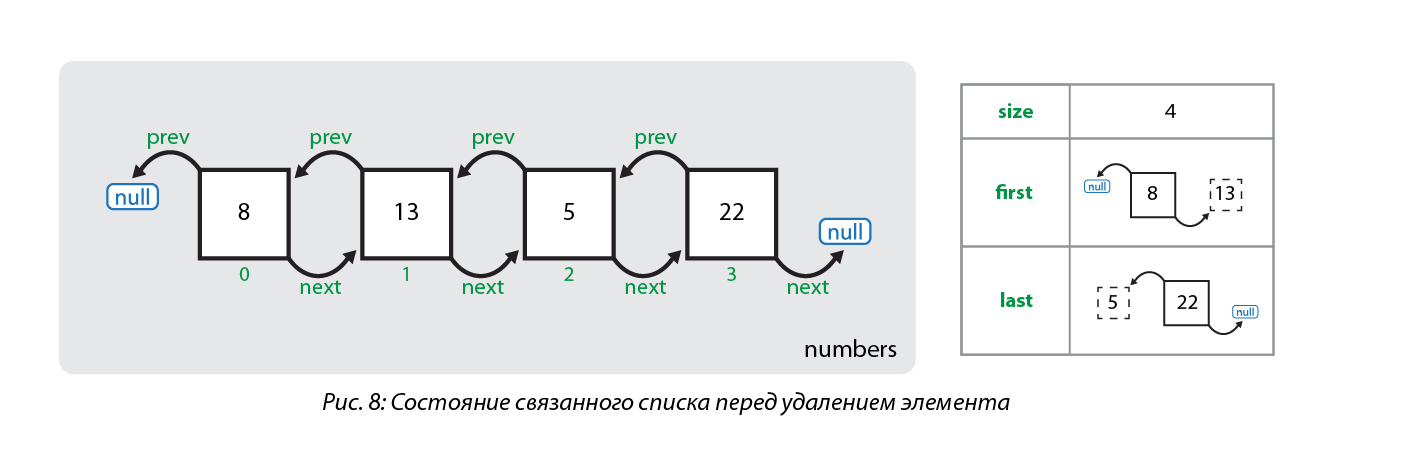
Рассмотрим удаление элемента из связанного списка по его значению. Удалим элемент со значением 5 из нижепредставленного списка:
numbers.remove(Integer.valueOf(5));Обратите внимание, что принимаемым значением в методе remove(object) является именно объект, если же мы попытаемся удалить элемент со значением 5 следующей строкой
numbers.remove(5);то получим IndexOutOfBoundsException, т.к. компиллятор воспримет число 5 как индекс и вызовет метод remove(index).
Итак, что же происходит при вызове метода remove(object)? Сначала искомый объект сравнивается по порядку со всеми элементами, сохраненными в узлах списка, начиная с нулевого узла. Когда найден узел, элемент которого равен искомому объекту, первым делом элемент сохраняется в отдельной переменной. Потом переопределяются ссылки соседних узлов так, чтобы они указывали друг на друга:
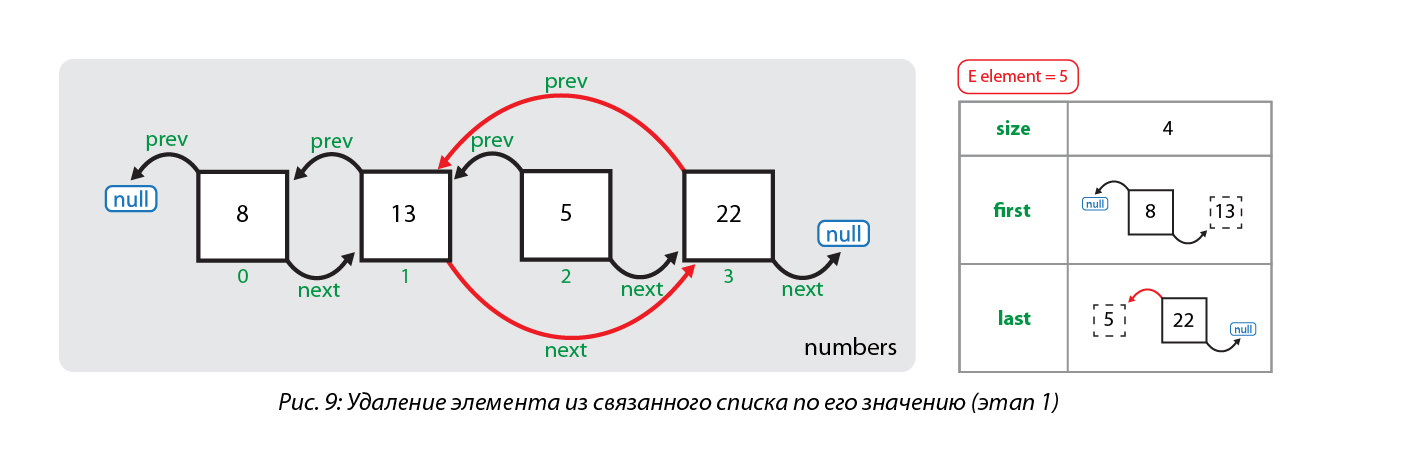
Затем обнуляется значение узла, который содержит удаляемый объект, а также уменьшается размер коллекции:
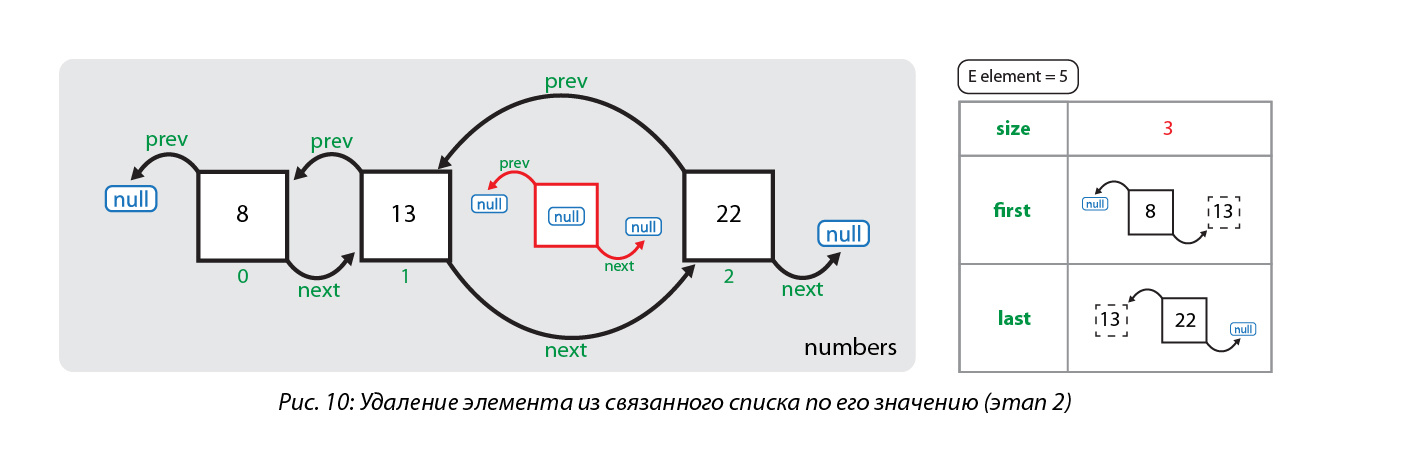
Теперь вернемся к тому моменту, что элемент из удаляемого узла мы сохраняли в памяти. Зачем мы это делали, спросите вы, если эти данные мы нигде дальше не использовали. Дело в том, что рассматриваемый нами метод в результате своей работу не возвращает удаленный элемент, потому данные, возврещенные вызванным в рамках работы метода unlink(node), вызванного методом remove(object), просто не понадобились. А вот когда мы используем метод remove(index), также вызывающий метод unlink(node), то значение данного элемента последовательно возвращается сначала методом unlink(node), а затем и методом remove(index). Похожая ситуация наблюдается и в остальных методах, возвращающих значение удаленного элемента, только внутри вызываются другие методы, отсоединяющие ссылку: в методах poll(), pollFirst(), remove() и removeFirst() это метод unlinkFirst(node), а в методах pollLast() и removeLast() — метод unlinkLast(node).
Итак, что следует помнить о LinkedList, решая, использовать ли данную коллекцию:
- не синхронизирована;
- позволяет хранить любые объекты, в том числе null и повторяющиеся;
- за константное время O(1) выполняются операции вставки и удаления первого и последнего элемента, операции вставки и удаления элемента из середины списка (не учитывая время поиска позиции вставки элемента);
- за линейное время O(n) выполняются операции поиска элемента по индексу и по значению.
Ссылки
Исходный код LinkedList (JDK 8)
Документация LinkedList
Комментарии (39)
Iqorek
09.09.2017 22:20+11Объяснение хорошее, хотел бы добавить, что часто ArrayList даст фору LinkedList, даже там где, где вычислительная сложность у последнего лучше. Связано это с тем, при расчете вычислительной сложности, не учитывается особенности работы кеша. Когда в кеш загружается массив ArrayList, он делает это максимально быстро, все элементы находятся последовательно в одной области памяти. Объекты же связанного листа могут быть разбросаны в памяти и их придется загружать в кеш поштучно, что относительно дорого.

aamonster
10.09.2017 08:43+3Зря вы не упомянули add/remove в итераторе, это существенная часть внутреннего устройства (единственная реализация за O(1))

olegchir
10.09.2017 12:14+8Как давно признался Шипилёву автор LinkedList,

Рекомендую прочитать весь тред.
twitter.com/joshbloch/status/583813919019573248


vedenin1980
10.09.2017 16:45+4Поавила использования LinkedList:
1. Не существует задач когда стоит использовать LinkedList,
2. Если у вас такая задача см. пункт 1,
Надо часто удалять из середины? Используйте ArrayList заменяя элементы на null, а потом их игнорируяя. При слишком большом кол-ве null — можно создать новый лист без null.
Надо всавлять в начало — переверните ArrayList и вставляйте в конец, С двух сторон — просто используйте 2 листа,
Надо вставлять в середину много элементом — используйте временный лист и addAll,
В конце концов, самое лучшее используйте TreeList из Apache коллекций. Не хотите /не можете тянуть зависимость? Просто скопируйте ее код.
Это осуждалось уже в моей статье
asm0dey
11.09.2017 07:38Его удобно использовать в качестве Dequeue. Каждый раз когда мне нужно решать какую-то задачу со стеком — использую его.
vedenin1980
11.09.2017 07:47Так-то ArrayList тоже может использоватся для этого, добавление и удаление из конца вообще очень быстрое, разве что интерфейса он не реализует и писать чуть дольше, но можно увереным что он не станет узким местом в производительности.
asm0dey
11.09.2017 10:20А как работает удаление из начала?
vedenin1980
11.09.2017 12:45Если все равно на производительность — то точно так же, если нет см. мой пост выше.
asm0dey
11.09.2017 13:08Это был риторический вопрос. Понятно что удаление из начала линкдлиста очень быстро, так же как и получение знаечния оттуда. Поэтому если нам надо Dequeue — LinkedList хорошая структура данных.
vedenin1980
11.09.2017 13:30Когда говорят «очевидно/понятно/несомненно» темную сторону силы вижу я. Нет, не понятно и не очевидно, что будет быстрее (вы, видимо, совсем не смотрели мой комментарий и комментарии выше, в том числе от того кто написал LinkedList и те кто занимается производительностью JVM).
Придумайте любую задачу и тест производительности, а перепишу с использованием ArrayList (на крайний случай двух ArrayList) реализацию быстрее. Я уже не говорю о TreeList от апача, которые быстрее будет практически всегда.
И это не говоря о диких расходах памяти (намного больших чем ArrayList) и мусора для сборщикаasm0dey
11.09.2017 14:27Лист, обёмом в полтора миллиарда long. Удаляем элемент по 0 индексу. Замеряем время до конца операции. Сравниваем ArrayList и LinkedList.
vedenin1980
11.09.2017 16:17Не вопрос, заменяем элемент ArrayList на null и меняем внутренний индекс первого элемента. И замеряем скорость.
public class MyList { private List<Long> list = new ArrayList<Long>(1500000000); private int firstIndex; public Long remove(int index) { Long old = list.set(index + firstIndex, null); if(index == 0) { firstIndex++; } return old; } ... }
При вставке в первый элемент проводим обратную операцию (на случай вставки до удаления можно изначально начинать с firstIndex равным 10-30% от ожидаемого размера коллекции).asm0dey
11.09.2017 16:26Не, я прошу удалить первый элемент с помощью remove(0). Чтобы работало как popFirst(). А вы предлагает саблисты использовать. Что ошибкоопасно. Да и итератор если получить — нас итератор от основного листа вернётся.
И раз уж мы тут говорим про сравнение листов — то ArrayList на 3 миллиарда элементов тоже не сделаешь.vedenin1980
11.09.2017 16:38А вы предлагает саблисты использовать. Что ошибкоопасно.
Не хотите писать руками используйте (или скопируйте) TreeList от апача.
Да и итератор если получить — нас итератор от основного листа вернётся.
Кто сказал? Сложно написать свой итератор?
И раз уж мы тут говорим про сравнение листов — то ArrayList на 3 миллиарда элементов тоже не сделаешь.
С такими запросами вам классы BigList нужныasm0dey
11.09.2017 17:28Вы сказали что ArrayList всегда лучше. Нет. С остальным я и не спорил. Писать свой итератор — плохо потому что можно наошибаться. И вообще свой код писать опасно.
vedenin1980
11.09.2017 16:29Учитывая что линкедлист занимает в 6 раз больше памяти (не говоря уже о 3 миллиардах объектов для сборщика), мы можем выделять в обе стороны по 100% запасу и все равно выиграем линкедлист в 2 раза по памяти.
asm0dey
11.09.2017 17:34Я скорость предлагаю мерить, а не память. Вы сказали вам подобрать пример когда ArrayList эффективнее чем LinkedList. Я подобрал и сказал что именно мы выигрываем. Почему вы мне говорите про то что мы на линдлисте проигрываем по памяти мне абсолютно непонятно. А ещё мы по скорости случайного доступа!
vedenin1980
11.09.2017 17:49Я сказал, что нет задач для которых использование LinkedList имело бы смысл даже чисто по производительности, так как есть возможность либо написать свой код, либо использовать намного лучшие аналоги из сторонних коллекций (проверенные и оттестированные), если так уж не хочется свой код.
О чем вы спорите я тоже не знаю.
alexeykuzmin0
11.09.2017 13:54А разве в Java нет чего-нибудь вроде std::deque из c++ STL? Если нет, возможно, эффективнее будет реализовать руками, чем использовать LinkedList.
Он работает примерно следующим образом: храним массив (одним куском) + его размер, и два указателя на него: на первый элемент дека и на следующий после последнего.
При добавлении в конец или начало: смотрим, есть ли у нас свободное место в массиве. Если нет — выделяем новый массив в X (от 1 до 2) раз больше текущего и все элементы перемещаем в него. Дальше добавляем новый элемент по указателю на конец или начало, сдвигая его в нужную сторону. Сложность получается O(N) в случае увеличения размера, но, учитывая экспоненциальность выделения памяти, в среднем O(1).
В итоге у нас добавление и удаление элементов как в начало, так и в конец за O(1), а еще за O(1) поиск элемента по индексу и вообще все cache friendly.asm0dey
11.09.2017 15:33ArrayDeque.
alexeykuzmin0
11.09.2017 16:12Тогда почему бы не использовать его вместо LinkedList в качестве дека?
asm0dey
11.09.2017 16:16Допустим у меня в стеке должно лежить 3 миллиарда элементов…
alexeykuzmin0
11.09.2017 16:36Допустим. И?
Например, я вижу такое существенное отличие в данном случае, как экономия 6 млрд указателей (48 Гб памяти) по сравнению с LinkedList. Да и скорость итерирования за счет лучшего использования кеша будет лучше.alexeykuzmin0
11.09.2017 16:44PS: Сорри, возможно, я что-то как-то не так понимаю, ибо с C# сто лет как не работал, а когда работал, это было несерьезно. Но концепция дека на массиве от этого хуже не становится. В c++ нет ну вообще никаких проблем с тем, чтобы сделать std::deque (или std::vector, если такой класс пишется самостоятельно) на 3 млрд элементов.
asm0dey
11.09.2017 16:59В массиве не помещается 3 миллиарда элементов. Но вообще-то да, экономим мы либо память, либо процессор.
alexeykuzmin0
11.09.2017 17:05Это какое-то ограничение C#? Ну, тогда можно написать свой массив, который будет лишен этого недостатка.
Для хранения, скажем, 3 млрд 32-битных чисел в массиве нам нужно 3*4=12 Гб памяти, а для хранения их же в списке нам уже потребуется 3*(4 + 2*8)=60 Гб памяти. Как может такое быть, что первое не умещается в память, а второе умещается?asm0dey
11.09.2017 17:30Про шарп ничего ен знаю, тольк опро джаву, которую тут вроде бы и обсуждали. В массив в джаве в принципе не умещается больше чем Integer.MAX_VALUE элементов. А вот в линкдлисте таких ограничений нет.
vedenin1980
11.09.2017 17:45А вот в линкдлисте таких ограничений нет.
Правда нет? То есть то что все методы интерфейса List принимают только int в качестве индекса вас не смущает?
А то что внутренне поле size у LinkedList тоже int — тоже не наводит на смутные сомнения, что больше Integer.MAX_VALUE элементов в LinkedList никак не влезет?asm0dey
11.09.2017 23:20Ладно, вот тут неправ, признаю. А там проверки или overflow сработает и мы сможем нафигачить столько элементов сколько захотим?

poxvuibr
11.09.2017 14:01Поавила использования LinkedList:
- Не существует задач когда стоит использовать LinkedList,
- Если у вас такая задача см. пункт 1,
А как насчёт кейса, когда нужна стабильная производительность? Когда просадок на вырастание внутреннего массива надо избегать?
vedenin1980
11.09.2017 14:14+2Тогда заранее можно выделить память с запасом, LinkedList в разы больше памяти ест. Ну и стабильно плохая производительность вряд ли лучше очень хорошей производительностью с ростом до чуть менее хорошей. Выделение массива не так сильно влияет на производительность, так как там используется системная функция выделения куска памяти и копирования, в большинстве случаев по сравнению с запуском сборщика (а LinkedList куда больше объектов создает) расширения массива нечто почти незаметное.

batyrmastyr
12.09.2017 08:42Правила именования листов:
1. Если перед вами лист дерева (структура данных или растение) — называйте его листом.
2. Если перед вами лист бумаги — называйте его листом.
2. Если перед вами ArrrayList или LinkedList — называйте их списками (точнее, списочным массивом и связанным списком). Вы, конечно, можете называть их и листами, но это так же неправильно, как называть их деревьями, массивами, графами, кошками или космическими кораблями.
fly_style
Как раз сложность поиска элемента в двусвязном списке как раз O(N), и это надо прямо указывать. А то у меня от этой вставки и удаления из середины за О(1) глаза на лоб вылезли.
Из приятного — наглядность картинок порадовала. Продолжайте пробовать писать, но что-то более существенное и интересное, ибо то, что написано здесь — прям для совсем начинающих.
Prototik
Ну, справделивости ради — через итераторы сложность удаления будет как-раз O(1). А вот если удалять по индексу/элементу — тут всё печально, да…
vedenin1980
Но нужно до элемента доитерироватся, а это печально. Если стоять на месте и вставлять элементв временный лист и addAll часто оптимальнее.