
Вместо вступления...
В дипломах и диссертациях где-то в начале обычно должна формулироваться проблема. Но то, что я опишу ниже, скорее даже не проблема, а стремление сделать приложение юзабельнее и окружающий мир немножечко прекраснее. Это один из тех моментов в моей жизни, где я спрашиваю себя, а можно ли сделать лучше? А после этого пытаюсь найти способы это сделать. Иногда у меня это получается, иногда я понимаю, что сделать лучше либо невозможно, либо на это стоит затратить столько усилий, что это в конечном итоге потеряет всякий смысл. В конце концов, это
Формулировка задачи
Начну с того, что компания, где я работаю, занимается разработкой высоконагруженных сайтов. Приложения, над которыми на текущий момент мне удалось потрудиться, по своей большей части, являются неким прикрытым авторизацией интерфейсом доступа к внутренним АПИ заказчика. Логики там немного и она распределена примерно в равных пропорциях между frontend'ом и backend'ом. Большинство ключевой бизнес-логики лежит именно в этих АПИ, а сайты, видимые конечному клиенту, являются их консьюмерами.
Иногда получается так, что сторонние по отношению к сайту API отвечают на запросы пользователя весьма продолжительное время. Иногда это временный эффект, иногда постоянный. Так как приложения по природе своей — высоконагруженные, нельзя допустить, чтобы запросы пользователя находились в подвисшем состоянии долгое время, иначе это может грозить нам постоянно увеличивающимся количеством открытых сокетов, быстро пополняющуюся очередь не отвеченных запросов на сервере, а ещё — большим количеством клиентов, волнующихся и переживающих, почему их любимый сайт открывается так долго. С API мы ничего сделать не можем. И в связи с этим с очень давних времен у нас на балансировщике было введено ограничение на длительность выполнения запроса, равное 5 секундам. Это в первую очередь накладывает ограничения на архитектуру приложения, так как подразумевает ещё больше асинхронного взаимодействия, вследствие чего решает вышеописанную проблему. Сам сайт открывается быстро, а уже на открытой странице крутятся индикаторы загрузки, которые в конце концов выдадут какой-то результат пользователю. Будет это тем, что пользователь ожидает увидеть, или же ошибкой уже не играет большого значения, и это будет уже совсем другой историей…

Внимательный читатель заметит: но если ограничение стоит на все запросы, то оно ведь распространяется и на AJAX-запросы тоже. Все правильно. Я вообще не знаю способа отличить AJAX-запрос от обычного перехода на страницу, 100% работающего во всех случаях. Поэтому долгие AJAX-запросы реализуются по следующему принципу: с клиента мы делаем запрос на сервер, сервер создает Task и ассоциирует с ним определенный GUID, затем возвращает этот GUID клиенту, а клиент получает результат по данному GUID, когда он придет на сервер от API. На этом этапе мы почти подобрались к сути моей
Все запросы и ответы к этим API мы должны логировать и хранить для разбора полетов, а из логов мы должны получать максимум полезной информации: вызванный action/controller, IP, URI, логин пользователя и т.д. и т.п. Когда же я в первый раз с помощью NLog'а залогировал свой запрос/ответ в моем ASP.NET Core приложении, то в принципе я не удивился, увидев в ElasticSearch что-то вроде:
2017-09-23 23:15:53.4287|0|AspNetCoreApp.Services.LongRespondingService|TRACE|/| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http:///В то же время в конфигурации NLog все выглядело достаточно правильно и в качестве layout было установлено следующее:
${longdate}|${event-properties:item=EventId.Id}|${logger}|${uppercase:${level}}|${aspnet-mvc-controller}/${aspnet-mvc-action}| ${message} (${callsite}:${callsite-linenumber})| url:${aspnet-request-url}Проблема здесь в том, что ответ от API приходит уже после окончания выполнения запроса клиентом (ему то возвращается всего лишь GUID). Вот тут то я и начал думать о возможных способах решения этой проблемы…
Возможные решения проблемы
Конечно, любую проблему можно устранить несколькими способами. Причем забить на нее — тоже один из приёмов, которым иногда не стоит пренебрегать. Но поговорим всеж-таки о реальных способах решения и их последствиях.
Передавать ID задачи в метод обращения к API
Наверное, это первое, что только может прийти в голову. Мы генерируем GUID, логируем этот GUID еще до выхода из action'а и передаем его в сервис работы с API.
Проблемы этого подхода — очевидны. Мы должны передавать этот ID в абсолютно все методы обращения к сторонним API. При этом, если мы захотим переиспользовать данный кусочек где-то еще, где такая функциональность не требуется, то нам это очень сильно будет мешать.
Ситуация усугубляется, если перед отдачей данных клиенту, мы хотим их каким-то образом обработать, упростить или агрегировать. Это относится к бизнес-логике и ее следует вынести в отдельный кусочек. Получается, что этот кусочек, который должен оставаться максимально независимым, будет тоже работать с этим идентификатором! Так дела не делаются, поэтому рассмотрим другие способы.
Сохранить ID задачи в CallContext
Если мы подумаем, какие средства нам предоставляет фрэймворк для этих целей, то первым делом вспомним про CallContext с его LogicalSetData/LogicalGetData. Используя эти методы, можно сохранить ID задачи в CallContext'e, а .NET (лучше сказать, .NET 4.5) сам позаботится о том, чтобы новые потоки автоматически получили доступ к этим же данным. Внутри фрэймворка это реализуется с помощью паттерна, чем-то напоминающего Memento, который должны использовать все методы запуска нового потока/задачи:
// Перед запуском задачи делаем snapshot текущего состояния
var ec = ExecutionContext.Capture();
...
// Разворачиваем сохраненный snapshot в новом потоке
ExecutionContext.Run(ec, obj =>
{
// snapshot на этом этапе уже развернут, поэтому здесь вызывается уже пользовательский код
}, state);
Теперь когда мы знаем, как сохранить ID, а затем получить его в нашей task'е, мы можем в каждое наше логируемое сообщение, включить этот идентификатор. Можно сделать это непосредственно при вызове метода логирования. Или, чтобы не засорять слой доступа к данным, можно использовать возможности вашего логгера. В NLog, например, есть Layout Renderers.
Также в крайнем случае можно написать свой логгер. В ASP.NET Core всё логирование осуществляется с помощью специальных интерфейсов, расположенных в пространстве имен Microsoft.Extensions.Logging, которые внедряются в класс посредством DI. Поэтому нам достаточно реализовать два интерфейса: ILogger и ILoggerProvider. Думаю, такой вариант может оказаться полезным, если ваш логгер не поддерживает расширения.
А чтобы все получилось так, как надо, рекомендую ознакомиться со статьей Stephen'а Cleary. В ней нет привязки к .NET Core (в 2013 году его просто-напросто еще не было), но что-то полезное для себя там точно можно подчеркнуть.
Недостаток данного подхода в том, что в лог будут попадать сообщения с идентификатором и чтобы получить полную картину нужно будет искать HTTP-запрос с этим же ID. Про производительность я промолчу, так как, даже если и будет какая-та просадка, то по сравнению с другими вещами это будет казаться несоизмеримо малым значением.
А что, если подумать, почему это не работает?
Как я уже говорил, в лог к нам сыпятся сообщения вида:
2017-09-23 23:15:53.4287|0|AspNetCoreApp.Services.LongRespondingService|TRACE|/| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http:///Т.е. все, что связано с IHttpContext просто зануляется. Оно вроде как и понятно: выполнение запроса то закончилось, поэтому NLog и не может получить данные, т.е. ссылки на HttpContext просто уже нет.
Наконец-то, я решил посмотреть, а как собственно NLog получает ссылку на HttpContext вне контроллера. Так как с SynchronizationContext'ом и HttpContext.Current в .NET Core было покончено (да, это снова Stephen Cleary), значит должен быть какой-то другой способ это сделать.

Поковырявшись в исходниках NLog, я нашел некий IHttpContextAccessor. Жажда понять, что все таки здесь происходит, заставила меня снова залезть в GitHub и посмотреть, что же представляет из себя эта магическая штука с одним свойством. Оказалось, что это просто абстракция над AsyncLocal, который по сути является новой версией LogicalCallContext (те самые методы LogicalSetData / LogicalGetData). Кстати, для .NET Framework'а так было не всегда.
После этого я задал себе вопрос: а почему собственно тогда это не работает? Мы запускаем Task стандартным способом, никакого неуправляемого кода тут нет… Запустив дебаггер, чтобы посмотреть, что происходит с HttpContext в момент вызова метода логирования, я увидел, что HttpContext есть, но свойства в нем все обнулены за исключением Request.Scheme, которое в момент вызова равно «http». Вот и получается, что в логе у меня вместо урла — странное "
http:///".Итак, получается, что в целях повышения производительности ASP.NET Core где-то внутри себя обнуляет HttpContext'ы и переиспользует их. Видимо, такие тонкости вкупе и позволяют достичь значительного преимущества по сравнению со стареньким ASP.NET MVC.
Что же я мог с этим сделать? Да просто сохранить текущее состояние HttpContext'а! Я написал простой сервис с единственным методом CloneCurrentContext, который я зарегистрировал в DI-контейнере.
public class HttpContextPreserver : IHttpContextPreserver
{
private readonly IHttpContextAccessor _httpContextAccessor;
ILogger _logger;
public HttpContextPreserver(IHttpContextAccessor httpContextAccessor, ILogger<HttpContextPreserver> logger)
{
_httpContextAccessor = httpContextAccessor;
_logger = logger;
}
public void CloneCurrentContext()
{
var httpContext = _httpContextAccessor.HttpContext;
var feature = httpContext.Features.Get<IHttpRequestFeature>();
feature = new HttpRequestFeature()
{
Scheme = feature.Scheme,
Body = feature.Body,
Headers = new HeaderDictionary(feature.Headers.ToDictionary(kvp => kvp.Key, kvp => kvp.Value)),
Method = feature.Method,
Path = feature.Path,
PathBase = feature.PathBase,
Protocol = feature.Protocol,
QueryString = feature.QueryString,
RawTarget = feature.RawTarget
};
var itemsFeature = httpContext.Features.Get<IItemsFeature>();
itemsFeature = new ItemsFeature()
{
Items = itemsFeature?.Items.ToDictionary(kvp => kvp.Key, kvp => kvp.Value)
};
var routingFeature = httpContext.Features.Get<IRoutingFeature>();
routingFeature = new RoutingFeature()
{
RouteData = routingFeature.RouteData
};
var connectionFeature = httpContext.Features.Get<IHttpConnectionFeature>();
connectionFeature = new HttpConnectionFeature()
{
ConnectionId = connectionFeature?.ConnectionId,
LocalIpAddress = connectionFeature?.LocalIpAddress,
RemoteIpAddress = connectionFeature?.RemoteIpAddress,
};
var collection = new FeatureCollection();
collection.Set(feature);
collection.Set(itemsFeature);
collection.Set(connectionFeature);
collection.Set(routingFeature);
var newContext = new DefaultHttpContext(collection);
_httpContextAccessor.HttpContext = newContext;
}
}
public interface IHttpContextPreserver
{
void CloneCurrentContext();
}
Я не использовал deep cloner, так как это добавило бы тяжелую рефлексию в проект. А нужно это мне всего в одном единственном месте. Поэтому я просто создаю новый HttpContext на базе существующего и копирую в него только то, что будет полезно увидеть в логе при анализе инцидентов (action|controller, url, ip и т.п.). Копируется не вся информация.
Теперь запустив приложение, я увидел примерно следующие счастливые строчки:
2017-10-08 20:29:25.3015|0|AspNetCoreApp.Services.LongRespondingService|TRACE|Home/Test| DoJob method is starting (AspNetCoreApp.Services.LongRespondingService.DoJob:0)| url:http://localhost/Test/1
2017-10-08 20:29:34.3322|0|AspNetCoreApp.Services.LongRespondingService|TRACE|Home/Test| DoJob method is ending (AspNetCoreApp.Services.LongRespondingService+<DoJob>d__3.MoveNext:0)| url:http://localhost/Test/1
А это означало для меня маленькую победу, которой я и делюсь здесь с вами. Кто что об этом думает?
Чтобы удостовериться, что я ничего себе не надумал ложного, я написал маленький функционально-нагрузочный тест, который можно найти в моем репозитории на github'е вместе с сервисом. При запуске 5000 одновременных тасков, тест прошел успешно.
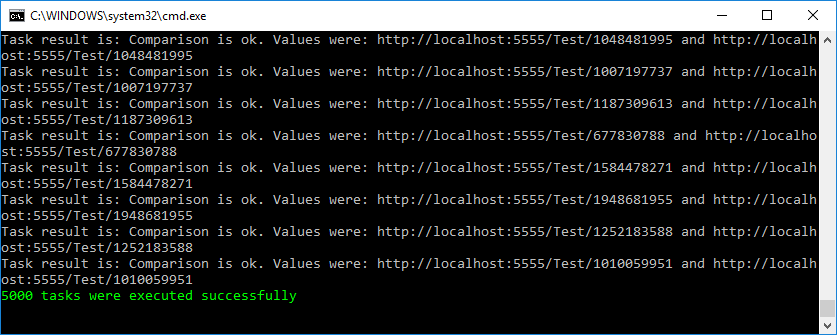
Кстати, благодаря архитектуре ASP.NET Core такие тесты можно писать легко и непринужденно. Нужно всего лишь запустить полноценный сервер внутри теста и обратиться к нему через настоящий сокет:
protected TestFixture(bool fixHttpContext, string solutionRelativeTargetProjectParentDir)
{
var startupAssembly = typeof(TStartup).Assembly;
var contentRoot = GetProjectPath(solutionRelativeTargetProjectParentDir, startupAssembly);
Console.WriteLine($"Content root: {contentRoot}");
var builder = new WebHostBuilder()
.UseKestrel()
.UseContentRoot(contentRoot)
.ConfigureServices(InitializeServices)
.UseEnvironment(fixHttpContext ? "Good" : "Bad")
.UseStartup(typeof(TStartup))
.UseUrls(BaseAddress);
_host = builder.Build();
_host.Start();
}Еще один довод к использованию ASP.NET Core в своих проектах.
Итоги
Мне очень понравился ASP.NET Core во всех аспектах его реализации. В нем заложена большая гибкость и одновременно лёгкость всей платформы. За счет абстракций для абсолютно всей функциональности можно делать любые вещи и настраивать всю платформу под себя, свою команду и свои методы разработки. Кроссплатформенность пока не доведена до совершенства, но Microsoft к этому стремится, и когда-нибудь (пусть может и не скоро) у них должно это получиться.
Ссылка на github
Комментарии (19)

lair
09.10.2017 00:08Если мы подумаем, какие средства нам предоставляет фрэймворк для этих целей, то первым делом вспомним про CallContext с его LogicalSetData/LogicalGetData. [...] Внутри фрэймворка это реализуется с помощью паттерна, чем-то напоминающего Memento, который должны использовать все методы запуска нового потока/задачи
Подождите, так надо обычному коду на .net core это писать, или нет? Я как-то привык думать (на основании той самой статьи Клири), что этот контекст двигается с нами автоматически.

Dobby007 Автор
09.10.2017 00:35-1Немного вас не понял. ExecutionContext двигается с нами, да. Но чтобы какую-то инфу двигать, нужно же вызывать как раз методы LogicalSetData/LogicalGetData.
lair
09.10.2017 00:37Я вот про это:
var ec = ExecutionContext.Capture(); ... ExecutionContext.Run(ec, obj => { ... }, state);
Это в .net core нужно, чтобы ExecutionContext двигался?

kekekeks
09.10.2017 00:57-1Из-за этой штуки в Akka.NET нет по-настоящему нативной поддержки тасков к акторам. Сохранение лишнего хлама в контексте приводит к серьёзным тормозам.
lair
09.10.2017 11:44Оу-воу, а можно с этого места поподробнее? Интересно и "нет нативной поддержки" (а то я там помню и асинки внутри таска, и PipeTo), и что именно с тормозами — они возникают из самого факта наличия ExecutionContext или из того, сколько конкретный программист туда данных положит?
kekekeks
09.10.2017 12:34Асинки внутри таска там сделаны костылями через остановку актора и/или стэш сообщений. Само ядро обработки очередей сообщений про асинхронность ничего не знает. Тормоза возникали из самого факта обращений к контексту, в который пытались запихнуть ActorContext. Единственный способом обойти эти ограничения и сделать так, чтобы не тормозило — отказаться от thread-local переменных, но они слишком много где используются.

hVostt
09.10.2017 00:12Вы не думали на тему использования инструментов типа Quartz.NET? И сохранять не HttpContext, ведь это абсолютно нелогично, так как задача у вас выполняется не в контексте запроса, значит копировать/сохранять/эмулировать его — будет большой обман, а тупо персистить информацию о полученном запросе, только то, что нужно, при создании задачи?
Dobby007 Автор
09.10.2017 00:32Quartz.NET — это планировщик задач, так? Тогда у меня получится то же самое, что и способ с сохранением ID из статьи, только здесь еще и добавляется внешний инструмент. Планировщики задач это нужная штука при больших задачах, требующих последовательности/консистентности. А при таких маленьких задачах, как получение данных о пользователе, я считаю, это лишнее. Насчет нелогичности — спорный момент. Запрос к АПИ начинается во время запроса пользователя к сайту. Здесь же выигрыш в том, что в логе мы видим сразу всю инфу, а не ковыряем разные источники в ее поисках.
hVostt
09.10.2017 01:02Абсолютно ни одной предпосылки для того, чтобы момент можно было даже с огромным натягом назвать «спорным». Клиент сделал запрос к серверу, получил ответ. Всё что происходит до получение ответа — это обработка запроса. Клиент получил некий ID, и через некоторое время сделал ещё один запрос с этим ID, это уже другой запрос, другой контекст. Если вам так важно в логе видеть URL запроса, с которого была инициирована задача, привяжите её к ID, но эмулировать контекст запроса, которого ни по каким понятиям нет, это антипаттерн, введение в заблуждение и костыль, который здесь ничего не решает, только создаёт проблемы. Выигрыша никакого, вы просто смастерили костыль, который будет вводить людей в заблуждение. Так мне это видится :)

Flaksirus
09.10.2017 10:40Я вот тоже ни разу не понял зачем такой геморой, когда легко выделяется некоторый менеджер задач, в интерфейсе которого будет генерация задачи, получение её состояния, и вероятно её остановки и удаление из очереди. Так можно даже реализовать ограничение на одновременную обработку задач…
Dobby007 Автор
09.10.2017 10:49Значит, вы считаете, что лучше логировать информацию о запросе отдельно, логировать запрос/ответ от АПИ, а потом это всё сопоставлять вручную по идентификатору при инцидентах. Понятно :)
hVostt
09.10.2017 01:05Насчёт кварца, вы зря пытаетесь оперировать величиной задач. У задачи есть контекст, который перситится, куда вы можете сохранить и ID и URL и всё остальное, выполнение задач отлично журналируется и управляются планировщиком, также можно масштабировать при необходимости, есть отдельный UI, в котором вы можете смотреть чего там сейчас происходит, чего отвалилось и почему. Огромная задача или нет, не имеет значения.
nomoreload
09.10.2017 08:59Советую ещё на Hangfire посмотреть — тоже весьма годный планировщик. К слову, есть порт под .NET Core. Имеет реализации хранилищ под разные СУБД, позволяет запускать таски на нескольких серверах, хранит всю историю, позволяет запускать и перезапускать таски вручную, из коробки имеет дашборд и интегрирован с DI. Единственный минус — синхронный API. Так что для вызова асинхронных методов — GetAwaiter().GetResult()

VanquisherWinbringer
10.10.2017 23:52Еще один минус — минимальный крон для задачи у Hangfire 1 минута. +- он раз в 15 секунд свое хранилище опрашивает.
kekekeks
System.Threading.SynchronizationContextв .NET Core никуда не делся и нормально поддерживается всей инфраструктурой TPL, включая async/await. Вот ASP.NET Core, да, свой контекст синхронизации больше не выставляет. Но он этого и на полном фреймворке не делает.Dobby007 Автор
Хорошее замечание.
Не делает. Сайт из примера крутится на полном фреймворке (Target Framework у него — .NET Framework 4.6.2).