

Java позволяет писать последовательный, параллельный и асинхронный код. Асинхронный — это когда регистрируется callback, который запустится после какого-либо события (например, файл прочитан). Это позволяет избежать блокировки потока, но ломает последовательность выполнения, так что на java пишут такой код скорее когда нет других вариантов. Kotlin даёт решение — корутины, с ними асинхронный код выглядит почти так же, как последовательный.
По корутинам мало статей. Конкретных примеров, показывающих их преимущества — ещё меньше.
Что нашёл:
- Избавление от callback hell. Актуально для UI
- Понравились концепции channels и actors. Они не новы, можно и без них, но для event систем должны очень хорошо подойти
- Совет от Романа Елизарова: «Корутины нужны для асинхронных задач, которые ожидают чего-либо большую часть времени»
Последнее интересно — большинство enterprise приложений всё время что-нибудь ждут: БД, другие приложения, изредка и файл нужно прочесть. И всё это может быть полностью асинхронным, а значит всё приложение можно перевести на асинхронную обработку запросов.
Итак, посмотрим как ведут себя корутины под нагрузкой.
IO vs NIO
Под NIO есть готовая обвязка для корутин. Пишем код:
suspend fun readFileAsync(): String {
val channel = AsynchronousFileChannel.open(filePath)
val bytes = ByteArray(size)
val byteBuffer = ByteBuffer.wrap(bytes)
channel.aRead(byteBuffer, 0L) /*(1)*/
/*(2)*/ channel.close()
return bytes.toString(Charset.forName("UTF-8"))
}
fun readFileSync() = file.inputStream().use {
it.readBytes(size).toString(Charset.forName("UTF-8"))
}
Как это работает
Не буду заострять внимание на синтаксисе, для этого есть короткий guide. Суть в том, что в строчке (1) вызывается метод из NIO, в котором регистрируется callback, который продолжит исполнение в точке (2). Добрый компилятор сохраняет локальные переменные метода и восстанавливает их для продолжения программы. Между (1) и (2), пока файл читается с диска, поток свободен и может, к примеру, начать читать второй файл. В случае с блокировкой для второго чтения файла, пока не окончилось первое чтение, пришлось бы создавать ещё один поток и он бы тоже заблокировался.
Измерим производительность
Берем JMH и измеряем единичный вызов. Итог: для HDD разница в пределах погрешности, для SSD NIO в корутине на 7.5% ± 0.01% быстрее. Разница небольшая, но это и не удивительно — всё упирается в скорость диска. Но в случае корутин потоки на время чтения не блокируются и могут делать другую работу.
Посмотрим, сколько ещё работы можно сделать, пока мы читаем заданное количество данных с диска. Для этого будем в ForkJoinPool подбрасывать IO и CPU задачи в определенном соотношении. Когда у нас выполнится 400 IO задач, подсчитаем, сколько чисто CPU задач было отработано. Бенчмарк
| Затраченное время (ms) | Сколько CPU задач успели выполнить | |||
|---|---|---|---|---|
| Доля IO задач | Sync | Async | Sync | Async |
| 3/4 | 117 | 116 | 497 | 584 (+17%) |
| 1/2 | 128 | 127 | 1522 | 1652 (+8%) |
| 1/4 | 163 | 164 | 4958 | 4960 |
| 1/8 | 230 | 238 (+3%) | 11381 | 11495 (+1%) |
Разница есть. Замерял на HDD, на котором единичное чтение почти не отличалось. Отдельно хочу отметить последнюю строку: await генерит относительно большое количество объектов, что дополнительно нагружает GC, это заметно на фоне нашей CPU таски, которая создает 50 объектов. Замерял отдельно: чем больше таска создает объектов, тем меньше разница между Future и await вплоть до равенства.
SQL
Нашлась одна библиотека, которая умеет работать с базой без блокировок. Она написана на scala и умеет работать только с MySql и Postgres. Если кто знает другие библиотеки — напишите в комментариях.
Await для Future из scala:
suspend fun <T> Future<T>.await(): T = suspendCancellableCoroutine { cont: CancellableContinuation<T> ->
onComplete({
if (it.isSuccess) {
cont.resume(it.get())
} else {
cont.resumeWithException(it.failed().get())
}
}, ExecutionContext.fromExecutor(ForkJoinPool.commonPool()))
}
Сделал пару табличек в Postgres, специально без индексов, чтобы тайминг был заметен, базу запустил в докере, выдав 4 логических процессора. СonnectionPool ограничил в 4. Каждый запрос к приложению делал три последовательных обращения к базе.
Spring позволяет довольно просто сделать асинхронный http сервер, для этого достаточно из метода контроллера возвращать DeferredResult вместо MyClasss, а уже потом заполнять DeferredResult (в другом потоке). Для удобства написал маленькую обертку (цифрами обозначил реальный порядок выполнения):
@GetMapping("/async")
fun async(): DeferredResult<Response> = asyncResponse {
(4) //code that produce Response
}
fun <R> asyncResponse(body: suspend CoroutineScope.() -> R): DeferredResult<R> {
(1) val result = DeferredResult<R>() //пока пустой
(2) launch(CommonPool) { //запускаем корутину
try {
(5) result.setResult(body.invoke(this))
} catch (e: Exception) {
(5') result.setErrorResult(e)
}
}
(3) return result //возвращаем DeferredResult, всё ещё пустой
}
Отдельной проблемой было решить, какое ожидание соединения из пула выставить для sync и async вариантов. Для sync выставляется в мс, а для async — в штуках. Решил, что средний запрос в базу ~30мс, поэтому время поделил на 30 — получил штуки (оказалось, ошибся где-то на треть).
Приложение запустил, выдав один логический процессор. На другой машине поставил яндекс танк и расстрелял приложение. К моему удивлению разницы не было… до 50 rps (слева async, справа sync).
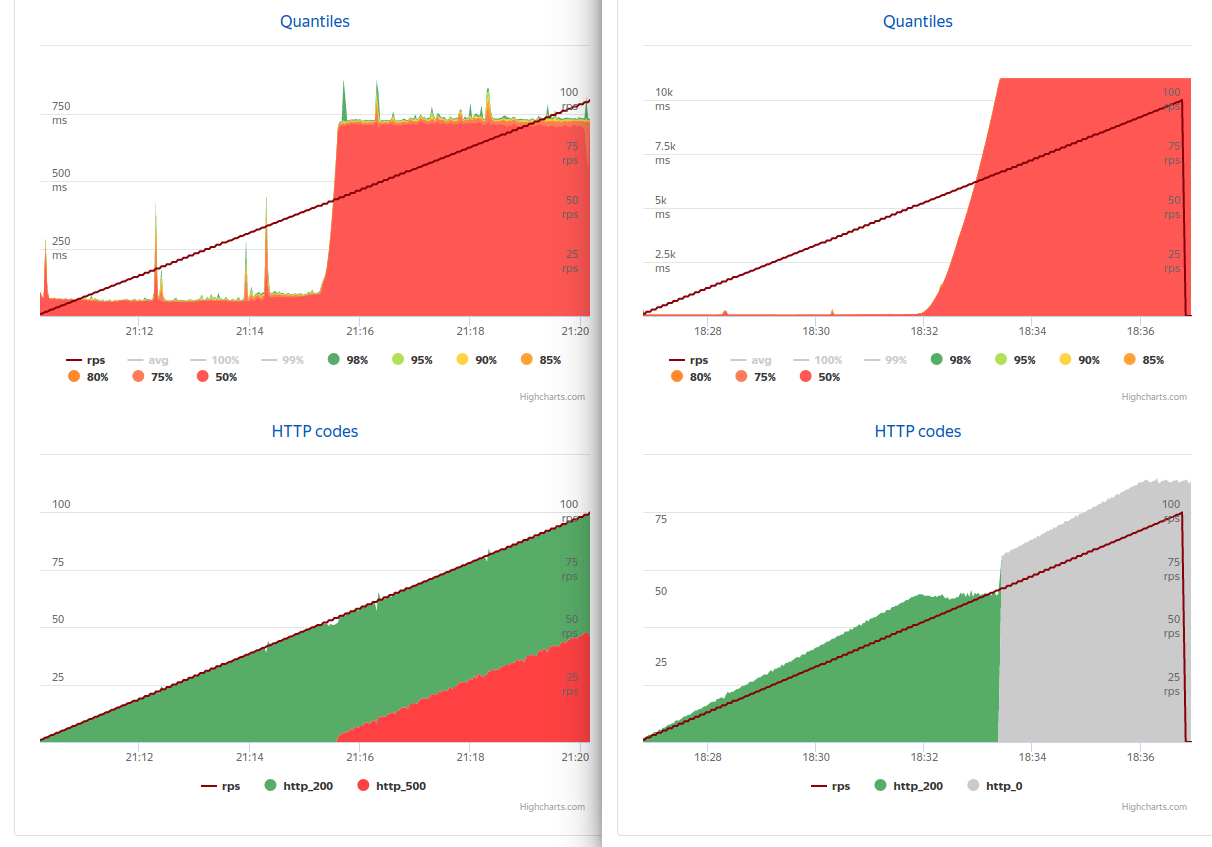
После 50 rps переставало хватать 4 соединений (средний timing к этому моменту — 80 rps) и синхронная версия к 66rps доходила до 11 секунд и умирала — начинала отвечать только timeout на любой запрос (даже если убрать нагрузку вообще), а асинхронная к 54rps переходила на 730мс и начинала обрабатывать ровно столько запросов, сколько позволяла база, по всем остальным — 500, при этом ошибки практически всегда отбрасывались моментально.
При запуске приложения с восемью логическими процессорами картина немного изменилась (слева async, справа sync)
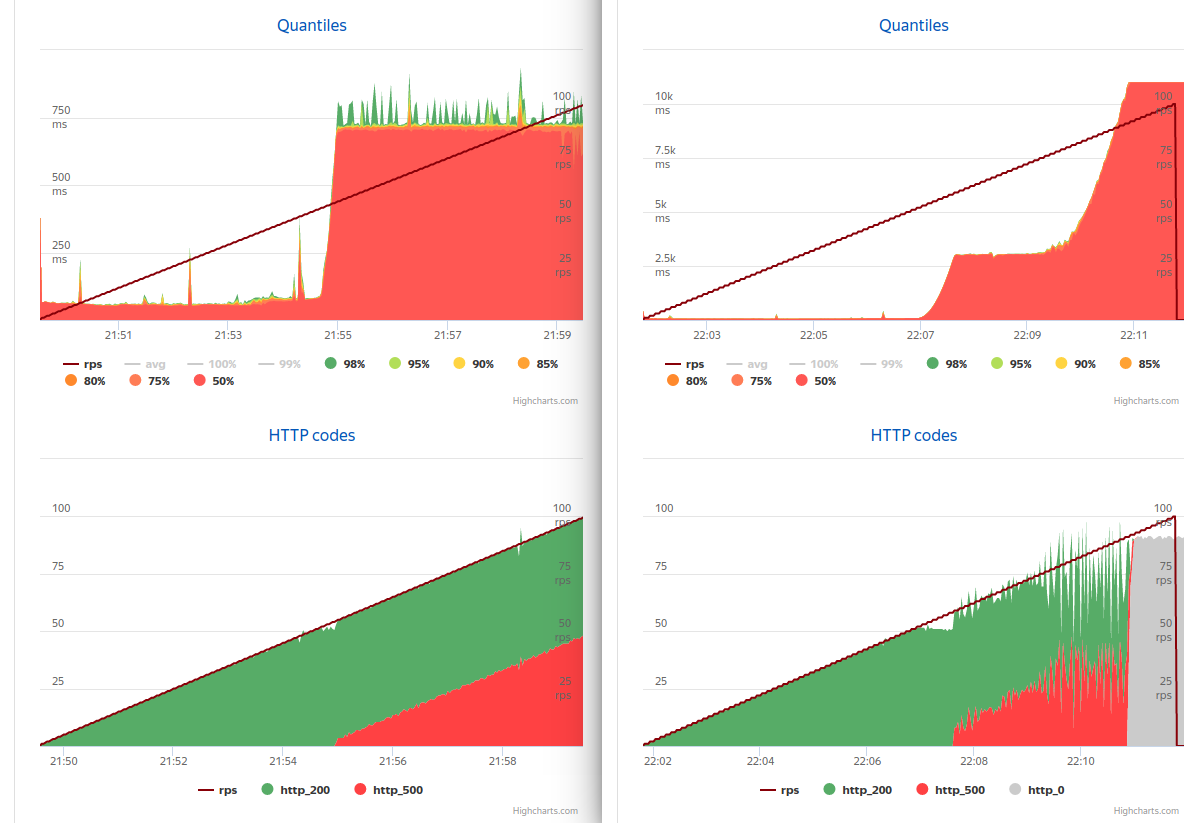
Синхронная версия от 60 до 80rps отвечала за 3 секунды, отбрасывая лишние запросы, и полностью переставала отвечать только к 91rps.
Отчего так вышло? Tomcat создает до 200 (по умолчанию) потоков на обработку входящих запросов. Когда запросов приходит больше, чем можно обработать, они создаются все и через некоторое время оказываются все заблокированными. При этом каждый запрос должен получить коннект 3 раза и каждый раз ждет по секунде. В случае с асинхронным вариантом, запрос не ждет какое-либо время, а смотрит, сколько ещё желающих на этот ресурс и отсылает ошибку, если желающих слишком много. В моём случае ограничение было в 33 при 4 коннектах, что, наверное, многовато. При уменьшении этого числа получим более приемлемую скорость ответа при перегрузках сервера.
HTTP
Плавный отказ — это хорошо, но интересно, можно ли получить прирост производительности в штатных ситуациях.
На этот раз приложение ходило по http на заглушку, заглушка отвечала с задержкой (от 1.5 мс). Делал два варианта: 100 последовательных и 100 параллельных (batch) запросов на заглушку. Замерял с помощью JMH в 1 и 6 потоков (имитировал разную нагрузку).
| Последовательно (avg ms) | Параллельно (avg ms) | |||||
|---|---|---|---|---|---|---|
| Sync | Async | ? | Sync | Async | ? | |
| 1core / 1 jmh thread | 160.3 ± 1.8 | 154.1 ± 1.0 | 4.0% ± 1.7% | 163.9 ± 2.4 | 10.7 ± 0.3 | 1438.3% ± 4.6% |
| 2core / 1 jmh thread | 159.3 ± 1.0 | 156.3 ± 0.7 | 1.9% ± 1.1% | 57.6 ± 0.5 | 15.4 ± 0.2 | 274.0% ± 1.9% |
| 4core / 1 jmh thread | 159.0 ± 1.1 | 157.4 ± 1.3 | 1.0% ± 1.5% | 25.7 ± 0.2 | 14.8 ± 0.3 | 74.3% ± 2.8% |
| 1core / 6 jmh thread | 146.8 ± 2.5 | 146.3 ± 2.5 | 0.4% ± 3.4% | 984.8 ± 34.2 | 79.3 ± 3.7 | 1141.6% ± 5.1% |
| 2core / 6 jmh thread | 151.3 ± 1.6 | 143.8 ± 1.9 | 5.2% ± 2.3% | 343.9 ± 17.2 | 86.7 ± 3.7 | 296.5% ± 6.3% |
| 4core / 6 jmh thread | 152.3 ± 1.5 | 144.7 ± 1.2 | 5.2% ± 1.8% | 135.0 ± 3.0 | 81.7 ± 4.8 | 65.2% ± 8.1% |
Даже при последовательных запросах мы получаем прирост, ну а при батче… Конечно, если мы добавим процессоров, картина для синхронного варианта станет значительно лучше. Так, увеличив ресурсы в 4 раза, мы получим прирост синхронного варианта в 6.5 раз, но так и не достигнем скорости async. При этом скорость работы async не зависит от количества процессоров.
О плохом
- Как я уже упоминал, выполнять в async очень маленькие задачи не выгодно. Впрочем, не думаю, что в этом есть необходимость.
- Надо следить за блокирующим кодом. Наверное, в этом случае следует завести отдельный threadPool для их выполнения.
- ThreadLocal можно забыть. Корутина восстанавливается в случайном потоке из предоставленного пула (в случае NIO, его даже указать нельзя...). RequestScope, думаю, тоже перестанет работать (не пробовал). Тем не менее есть CoroutineContext, к которому можно что-нибудь привязать, но передавать его надо будет все-равно явно.
- Java мир привык к блокировкам, поэтому неблокирующих библиотек МАЛО.
Послевкусие
Корутины можно и нужно применять. На них можно писать приложения, которым потребуется меньше процессоров, чтобы работать с той же скоростью. Моё впечатление — в большинстве случаев достаточно будет 1-2 ядер.
Да, ещё и подарок в виде отказоустойчивости.
Я надеюсь, постепенно появятся best practices, так как сейчас паттерны по работе с channels лучше искать в Go, async/await — в C#, yield — C# и python.
P.S.:
исходники
Послевкусие от Kotlin, часть 1
Послевкусие от Kotlin, часть 2
Hixon10
Спасибо за статью! Побольше бы таких, с графиками, исследованиями, а не маркетингово дерьма из рекламных блогов.
Лично я в JVM мире на корутины смотрю лишь, как на более простой способ написания асинхронного кода, который является таковым по своей природе. Например, сходить за новой картинкой в бэграунде мобильного приложения.
Как только речь заходит о реальных вычислениях, мы имеем целый ряд проблем:
1) Корутины реализованы, как сахар над JVM-тредами, которые, в конечном итоге, являются OS-тредами. Конечно, JVM-треды сидят в пуле, но anyway это треды со всеми плюсами и минусами. Важно понимать, что Корутины реализованы поверх JVM, а не внутри неё.
В противовес можно рассмотреть самые популярные корутины — Goroutines. Они реализованы в рантайме языка. Создать миллион Горутин — как два пальца об асфальт. А причина проста — горутина потребляет ВСЕГО несколько КБ памяти, а переключение контекста между Горутинами — стоит ничего. blog.nindalf.com/how-goroutines-work
2) В джаве, конечно, много проблем с тестами такого плана, как в статье. Столько приложений, и в каждом свой пул. Туда глянешь — пул томката из спринга. Сюда глянешь — вылезет дефолтный ForkJoinPool. И потом сидишь, чешешь репу: «а из-за кого это я просел по перфомансу»? «Может мой вебсёрвер кончился, аль я где-то все треды заблочил?».
gnefedev Автор
Корутины тоже существуют только в рантайме языка и используют тред пул, если можно так выразиться, как среду исполнения. Насколько я понимаю, переключения контекстов минимальны — таски подбрасываются в очередь для CommonPool и потоки оттуда их забирают, не отдавая контроль операционной системе.
Сейчас для интереса запустил миллион корутин у себя на компе (простой async/await). Заняло 830мс, отъело 1,3 Мб, т.е. 132 бита на корутину. Замер пальцем в небо, без прогрева и т.д., но порядок такой.
Hixon10
Извиняюсь, если говорю ерунду, но я вижу Горутины vs Корутины так (буду благодарен, если поправите меня):
1) Котлиновские корутины реализованы в виде FSM — github.com/Kotlin/kotlin-coroutines/blob/master/kotlin-coroutines-informal.md#implementation-details
Условно говоря, любая корутина — это Континуейшен, который компилится в один класс (или вообще происходит оптимизация, и нет никакого класса, в том случае, если отложенный вызов происходит в самом конце корутины — tail calls оптимизация).
Следовательно, на корутину можно смотреть, как на упорядоченный набор Тасков, разделяющих между собой Контекст корутины. Таск может выполняться в любом Java треде.
2) Горутины менеджерятся рантаймом Го. Они не позволяют пользователю явно указать, где нужно закончить/отложить вычисления. Вместо этого Горутины сами откладывают вычисления, если происходит IO блокировка, либо блокировка на примитивах синхронизации.
За счёт этого факта, а также за счёт того, что в Go реализована для горутин кооперативная многозадачность в userspace, то переключение контекста между Горутинами стоит практически ничего (так как мы точно знаем, какие регистры нам нужны в этот момент времени) — goo.gl/gGtWmB
3) Рассмотрим теперь Корутины vs Горутины. Пусть каждая из них засаспендилась, и нам требуется выбрать какую-то другую Ко(Го)рутину для исполнения. Тогда в Котлине нам придётся восстановить все возможные регистры, как в обычном, честном thread context switch. В то время, как в Го — мы поменяем лишь пару регистров (спасибо рантайму Го за это).
Кажется, что в этом месте мы имеет большую перфоманс разницу. Или я где-то ошибся в рассуждениях?
mayorovp
Все строго наоборот. В "корутинах" (формально, stackless coroutines) каждый фрагмент выполнения является отдельным вызовом функции — а потому нет никакой необходимости сохранять регистры между вызовами. Все требуемое состояние уже сохранено в полях сгенерированного объекта и лежит в куче.
В "горутинах" (формально, stackfull coroutines) происходит самое настоящее переключение контекста, пусть и без захода в ядро. Поэтому тут приходится по-честному сохранять и восстанавливать регистры.
Возможно, без примера несколько непонятно. Допустим, у нас есть вот такой код:
В случае stackless coroutines [JIT-]компилятор знает в какой момент может произойти приостановка и может ли она произойти в принципе. Исходя из этого можно принять решение о том где хранить переменную
a— в стеке, в куче или в регистре.В случае stackfull coroutines компилятор не знает в какой момент может произойти приостановка, она может произойти в любой из трех функций глубоко в стеке вызовов. Поэтому он не может принимать решение о размещении переменной
aв регистре с учетом возможных приостановок. А значит, нужно либо в принципе отказываться от размещения переменных в регистрах — либо же код приостановки должен учитывать что в любом регистре могло быть сохранено что-то полезное.gnefedev Автор
Специально писал такие тесты, чтобы было поближе к жизни. Вряд ли кто-то ради корутин слезет со спринга. А вот на Jetty пересесть можно. Примерно глянул в ту сторону, к Jetty можно свой тред пул подбросить. Но надо разбираться, что от этого пула ждет сам Jetty, так что углубляться пока не стал.
alek_sys
Начиная с версии 5 Spring вполне умеет быть реактивным.
Более того, корутины без проблем живут в Spring — т.к. он использует Project Reactor для асинхронности, а у kotlinx.coroutines есть поддержка Reactor.
Вообще, странно противопоставлять "спринг", Jetty и/или корутины, это как бы ортогональные вещи.