
 Метод (алгоритм) Виолы и Джонса [1] является одним из способов выявления границ объектов на изображении. Хотя алгоритм, разработанный П. Виолой и М. Джонсом еще в 2001 году, был первоначально ориентирован на быстрый поиск лиц на изображениях, сейчас разнообразные вариации этого популярного алгоритма с успехом используются в различных задачах поиска границ:
Метод (алгоритм) Виолы и Джонса [1] является одним из способов выявления границ объектов на изображении. Хотя алгоритм, разработанный П. Виолой и М. Джонсом еще в 2001 году, был первоначально ориентирован на быстрый поиск лиц на изображениях, сейчас разнообразные вариации этого популярного алгоритма с успехом используются в различных задачах поиска границ:
- образов пешеходов [2],
- образов автомобилей [3],
- образов дорожных знаков [4],
а также иных объектов, присутствующих на изображениях примерно в одном ракурсе. Такого рода популярность модификаций метода Виолы и Джонса объясняется высокой точностью поиска объектов и высокую устойчивость как к геометрическим искажениям, таки и к изменениям яркости.
Описание метода Виолы и Джонса
Алгоритм Виолы и Джонса сводит задачу детектирования объектов на изображении к задаче бинарной классификации в каждой точке изображения. Метод был основан на технике "скользящего окна". Для каждого прямоугольного региона изображения, взятого со всевозможными сдвигами и масштабами, при помощи заранее обученного классификатора (детектора) должна быть проверена гипотеза о наличии или отсутствии в данном регионе объекта поиска. Полное исследование всех регионов приводит к сотням тысяч запусков классификатора на одном изображении. Именно поэтому к классификатору предъявляют два жестких требования: высокая производительность и малое число ложных срабатываний.
В указанной работе Виола и Джонс описали классификатор для человеческого лица. Обучающая выборка состояла из 4916 изображений лиц, отмасштабированных до размеров 24x24 пикселя (положительная выборка) и 9500 полноразмерных изображений, в которых не было образов лиц и из которых произвольным образом извлекались зоны, не содержащие лица (отрицательная выборка).
Для построения признакового пространства были выбраны признаки Хаара, информативными для характерных перепадов яркости. Признаки Хаара легко вычисляются с помощью интегрального представления изображения. Выяснилось, что для изображений с размерами 24x24?связано количество конфигураций одного признака 45396.
В методе Виола и Джонса был применен алгоритм AdaBoost [5], который одновременно позволяет выбрать наиболее информативные признаки и построить бинарный классификатор. Для этого с каждым признаком авторы связали слабый классификатор, представляющий одноуровневое дерево решений, которые впоследствии подаются на вход алгоритму AdaBoost.
Необходимой частью метода Виолы и Джонса является процедура объединения построенных сильных классификаторов, что позволяет существенно увеличить производительность процесса детектирования лица посредством локализации тех регионов исследуемого изображения, которые могли бы содержать образы лиц.
Как уже отмечалось выше, в алгоритме Виолы и Джонса при обучении классификаторов для описания объектов используется семейство признаков Хаара, восходящие к вейвлетам Хаара [6]. Такой выбор обусловлен в первую очередь тем фактом, что признаки Хаара позволяют адекватно описать характерные особенности детектируемых объектов, имеющим отношение к перепадам яркости. Признаки Хаара позволяют увидеть, что на изображении лица человека область глаз темнее области носа (рисунке 1г). В описываемом алгоритме были задействованы три класса признаков: 2-прямоугольные признаки (рисунок 1а), 3-прямоугольные признаки (рисунок 1б) и 4-прямоугольные признаки (рисунок 1в).
Значение каждого признака Хаара равнялось разности сумм пикселей областей изображения внутри черных и белых прямоугольников равного размера. 2-прямоугольные и 3-прямоугольные признаки Хаара могут быть ориентирован вертикально (см рисунке 1) или горизонтально. Для быстрого вычисления признаков Хаара используется интегральное представление изображения [7].
В алгоритме AdaBoost при обучении метода Виолы и Джонса в качестве слабых классификаторов применяются распознающие деревья с одним ветвлением и двумя листьями (называемые decision stump и сравнивающие значение соответствующего признака с пороговым значением). Формально слабый классификатор bj (x), основанный на признака fj, пороге ?j и четности pj определяется так:
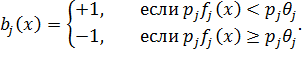
Такое множество слабых классификаторов вместе с обучающей выборкой подается на вход алгоритма AdaBoost.

Рисунок 1 — Прямоугольные признаки Хаара, используемые при обучении
классификатора: а) 2-прямоугольный признак; б) 3-прямоугольный признак;
в) 4-прямоугольный признак; г) пример расположение признака
относительно сканирующего окна (источник [7])
Каскадный классификатор (каскад) создается в предположении, что для любого исследуемого изображения количество "положительных" областей, не содержащих объект поиска, на несколько порядков превосходит количество областей, содержащих этот объект ("отрицательные" области). Для повышения быстродействия детектора объектов полезно как можно быстрее отказаться от рассмотрения отрицательные области изображения. Или количество признаков для анализа отрицательных областей должно быть существенно меньше, чем количество признаков, вычисленных для положительных областей.
Каждая область изображения, которая анализируется на предмет наличия объекта поиска, подается на вход упорядоченной последовательности классификаторов, называемых уровнями каскада. При продвижении по последовательности классификаторов вычислительная сложность уровней увеличивается. При отказе уровне классификатора от распознавания некоторой области (то есть область классифицирована как отрицательная) такая область уже не обрабатывается оставшимися классификаторами.
Для каскадного классификатора согласно его определению справедливы следующие соотношения:
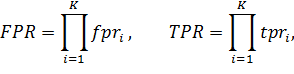
где FPR – доля ложного обнаружения каскада, TPR – доля верного обнаружения каскада, K – количество уровней каскада, fpri – доля ложного обнаружения i-го уровня каскада, tpri – доля верного обнаружения -го уровня каскада.
Предполагаемое количество вычисляемых признаков, которые будут вычислены для каждой исследуемой области, вычисляется по формуле:

где ni – количество слабых классификаторов -го уровня, pri – доля срабатываний i-го уровня.
Алгоритм обучения классификатора должен решать оптимизационную задачу, стремясь построить каскад с наилучшими показателями FPR и TPR, минимизируя при этом ожидаемое количество вычисляемых признаков N. Понятно, такую задачу решить достаточно сложно, прежде всего, из-за отсутствия четких связей между величинами FPR, TPR и N.
Известна простая идея обучения каскада на имеющейся размеченной обучающей выборке, включающей положительные и отрицательные примеры. Необходимо заранее выбрать три параметра:
- доля ложных срабатываний для каждого уровня каскада,
- доля правильных срабатываний для каждого уровня каскада,
- доля ложных срабатываний для всего каскада в целом (FPR*).
После этого каскадный классификатор строится итерационно, причем на каждой итерации проводится обучение посредством алгоритма AdaBoost. В каскад добавляются уровни до тех пор, пока не будет достигнуто целевое качество, заданное величиной FPR*. На вход обучения каждого уровня каскада должна подаваться такая обучающая выборка, в которой отрицательные примеры представляют собой ложные срабатывания каскадного классификатора, уже обученного на данный момент.
Описанный подход к обучению детектора объектов был нами исследован в задаче детектирования отсканированных образов паспорта. Обучающая выборка состояла из двух наборов:
- 1302 положительных образца (вырезанные образцы 2-ой страницы паспорта гражданина РФ) и 2000 негативных образцов (полноразмерные FullHD изображения, содержащие что угодно, кроме паспорта РФ)
1103 положительных образца (вырезанные образцы 3-ей страницы паспорта гражданина РФ) и 2000 негативных образцов (полноразмерные FullHD изображения, содержащие что угодно, кроме паспорта РФ)
Физический размер (в пикселях) для обоих классификаторов был выбран 201х141. При этом размере еще можно понять, что это верхняя или нижняя страницы (то есть класс определяется однозначно), а внутриклассовые уникальности исчезают.
В результате были обучены два классификатора
- классификатор 2-ой страницы паспорта гражданина РФ, состоящий из 8 уровней и 28 слабых классификаторов в общей сложности
- классификатор 3-ей страницы паспорта гражданина РФ, состоящий из 8 уровней и 36 слабых классификаторов.
Тестовая выборка состояла из 300 фотографий и сканов паспортов (на изображении присутствовали одновременно обе страницы). Качество привязки верхней страницы паспорта (вторая страница) составило 0,967. Качество привязки нижней страницы паспорта (третья страница) составило 0,98.
Особенности архитектуры Эльбрус
Архитектура Эльбрус относится к категории архитектур, использующих принцип широкого командного слова (Very Long Instruction Word, VLIW). На процессорах с VLIW-архитектурой компилятор формирует последовательности групп команд (широкие командные слова), в которых отсутствуют зависимости между командами внутри каждой группы и сведены к минимуму зависимости между командами в разных группах. Далее команды внутри каждой группы исполняются параллельно, что обеспечивает высокий уровень параллелизма на уровне команд.
Благодаря тому, что распараллеливание на уровне команд целиком обеспечивается оптимизирующим компилятором, аппаратура для исполнения команд значительно упрощается, поскольку теперь она не решает задач распараллеливания, как в случае, например, с архитектурой x86. Энергопотребление VLIW-процессора снижается: от него больше не требуется анализировать зависимости между операндами или переставлять операции, поскольку все эти задачи возложены на компилятор. Стоит отметить, что компилятор располагает значительно большими вычислительными и временными ресурсами, чем аппаратные анализаторы исходного кода, и поэтому может выполнять анализ тщательнее и находить больше независимых операций [8].
Кроме того, особенностью архитектуры Эльбрус являются методы работы с памятью. Часто доступ во внешнюю память может занимать значительное время и замедлять вычисления. Для решения этой проблемы используется кэширование, однако оно имеет свои недостатки, поскольку кэш имеет строго ограниченный размер и типичные алгоритмы кэширования направлены на сохранение в кэше только часто используемых данных.
Другим способом повышения эффективности доступа в память является использование методов предварительной подкачки данных. Эти методы позволяют прогнозировать обращения в память и производить подкачку данных в кэш или другое специальное устройство за некоторое время до их использования. Они делятся на программные и аппаратные. В программных методах специальные инструкции предварительной подкачки планируются на этапе компиляции. Они обрабатываются аналогично обычным обращениям в память. Аппаратные методы работают во время исполнения программы и используют для прогнозирования динамическую информацию об обращениях в память. Они требуют наличия дополнительных модулей в составе микропроцессора, однако не нуждаются в специальных инструкциях подкачки и могут работать асинхронно.
Процессоры Эльбрус поддерживают программно-аппаратный метод подкачки. При этом в аппаратную часть микропроцессора включено специальное устройство для обращения к массивам (Array Access Unit, AAU), но необходимость подкачки определяется компилятором, генерирующим специальные инструкции (инициализация AAU, запуск и останов программы предварительной подкачки, асинхронные инструкции предварительной подкачки и синхронные инструкции пересылки данных из буфера подкачки массивов (Array Prefetch Buffer, APB) в регистровый файл). Использование устройства подкачки эффективнее помещения элементов массива в кэш, поскольку элементы массивов чаще всего обрабатываются последовательно и редко используются более одного раза [9]. Однако необходимо отметить, что использование буфера предварительной подкачки на Эльбрусе возможно только при работе с выровненными данными. За счет этого чтение/запись выровненных данных происходят заметно быстрее, чем соответствующие операции для невыровненных данных.
Также микропроцессоры Эльбрус поддерживают несколько видов параллелизма помимо параллелизма на уровне команд: векторный параллелизм, параллелизм потоков управления, параллелизм задач в многомашинном комплексе.
Средства повышения производительности программного кода на платформе Эльбрус
Повысить быстродействие разработанного алгоритма на процессоре архитектуры Эльбрус можно путем использования высокопроизводительной библиотеки EML и интринсиков (англ. Intrinsics), реализующих векторный параллелизм.
Библиотека EML — высокопроизводительная библиотека, предоставляющая пользователю набор разнообразных методов для обработки сигналов, изображений, видео, а также математические функций и операции [10]. Она предназначена для использования в программах, написанных на языках С/С++. Библиотека EML включает в себя несколько следующие группы функций:
- Vector — функции для работы с массивами (векторами) данных;
- Algebra — функции линейной алгебры;
- Signal — функции обработки сигналов;
- Image — функции обработки изображений;
- Video — функции обработки видео;
- Volume — функции преобразования трехмерных структур;
- Graphics — функции для рисования фигур.Для массивов данных определены самые востребованные операции, например, сложение, поэлементное перемножение, подсчет среднего значения массива и т.д.
Разработчики могут использовать векторный параллелизм на платформе Эльбрус напрямую, то есть выполнять одну и ту же операцию над одним регистром, содержащим сразу несколько элементов данных. Для этого используются функции-интринсики, вызовы которых заменяются компилятором на высокоэффективный код для данной платформы. Микропроцессор Эльбрус-4С поддерживает набор инструкций версии 3, в котором размер регистра составляет 64 бита. С помощью регистра в 64 бита можно одновременно обработать 2 вещественных 32-битных числа, 4 16-битных целых числа или 8 8-битных целых чисел и таким образом повысить производительность. Набор интринсиков микропроцессора Эльбрус во многом схож с набором интринсиков SSE, SSE2 и включает в себя операции для преобразования данных, инициализации элементов вектора, арифметических операций, побитовых логических операций, перестановки элементов вектора и др.
Оптимизация классификатора Виолы и Джонса для архитектуры Эльбрус
Экспериментальная проверка разработанного алгоритма классификации Виолы и Джонса была выполнена в задаче детектирования третьей страницы паспорта Российской Федерации, содержащей номер и серию паспорта, а также фамилию, имя, отчество, пол, дату и место рождения гражданина РФ. Для решения этой задачи был обучен бинарный классификатор, на вход которому поступает серое изображение, приведенное к размеру 480 на 360 пикселей. В случае, если приведение к данному размеру не сохраняет пропорций входного изображения, к соответствующему размеру приводится наименьшее измерение изображения, а второе уменьшается с сохранением пропорций. Выходы классификатора интерпретируются как наличие или отсутствие страницы паспорта, ориентированной таким образом, что ее стороны параллельны краям кадра.
Разработанный классификатор оперирует модифицированными двупрямоугольными признаками Хаара, которые вычисляются на основе интегральных изображений:
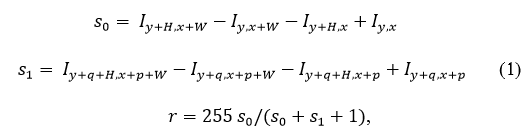
где I — интегральное изображение, W, H — ширина и высота прямоугольника, по которому вычисляется сумма, (x, y) — координата верхнего левого угла подокна, (p, q) — сдвиг второго прямоугольника для вычисления суммы, r — результат вычисления признака. В отличие от классического двупрямоугольного признака Хаара, такой признак более устойчив к изменениям яркости на исходном изображении.
В ходе детектирования эти вычисления производятся для каждого подокна исходной картинки. Поскольку для нашего классификатора шаг, с которым берутся эти подокна, равен 1 как по горизонтали, так и по вертикали, операции вида (1) для каждой строки исходной картинки легко реализовать с использованием таких векторных операций EML как:
- eml_Status eml_Vector_AddShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s len) - выполняет поэлементное сложение двух массивов типа 32-битное целое Src1 и pSrc2 с домножением на 2^shift и записывает результат в массив pDst.
- eml_Status eml_Vector_SubShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s len) - выполняет поэлементное вычитание двух массивов типа 32-битное целое Src1 и pSrc2 с домножением на 2^shift и записывает результат в массив pDst.
- eml_Status eml_Vector_AddCShift_32S(const eml_32s *pSrc, eml_32s val, eml_32s *pDst, eml_32s len, eml_32s shift) - выполняет прибавление константы val к каждому элементу массива типа 32-битное целое pSrc с домножением на 2^shift и записывает результат в массив pDst.
- eml_Status eml_Vector_DivShift_32S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift) - выполняет поэлементное деление двух массивов типа 32-битное целое Src1 и pSrc2 с домножением на 2^shift и записывает результат в массив pDst. Таким образом, вычисление 2-прямоугольных признаков Хаара было векторизовано. На рисунке 2 показано время вычисления такого признака в зависимости от количества применений классификатора по горизонтали. Эксперименты выполнялись на машине с процессором Эльбрус-4С. Можно видеть, что EML позволяет до 10 раз ускорить время вычисления 2-прямоугольного признака Хаара в процессе детектирования объекта, причем наиболее эффективно это вычислений при количестве приложений классификатора от 64 и более.
Далее оценим время классификации одного подокна в зависимости от длины исходной картинки (см. рисунок 3). Можно видеть, что использование EML позволило уменьшить время детектирования страницы паспорта РФ до 30 раз.
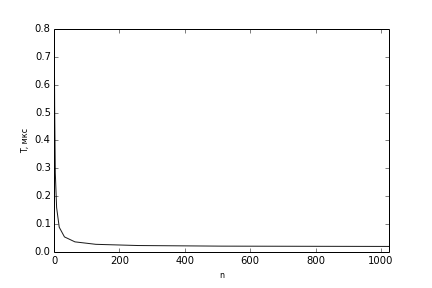
Рисунок 2 — Зависимость времени вычисления модифицированного 2-прямоугольного признака Хаара T от количества применений

Рисунок 3 — Зависимость времени вычисления классификации T от количества применений классификатора по горизонтали n
Подобные результаты значительно превзошли ожидаемые. По всей видимости, причинами этого являются особенности реализации STL (использовалась в базовой реализации) и особенности работы с памятью на Эльбрусе (например, необходимость выравнивания для использования устройства подкачки массивов — специальной фишки Эльбруса). Оказалось, что операции библиотеки EML учитывают эти обстоятельства и позволяют здорово ускорить низкоуровневые операции, не требуя от разработчика "глубокого погружения" в нюансы архитектуры.
! Посмотреть компьютеры Эльбрус и наши продукты вы можете на ChipEXPO — 2017
Список использованных источников
- Viola P., Jones M. Robust Real-time Object Detection // International Journal of Computer Vision. 2001. [7]
- Viola P., Jones M., Snow D. Detecting pedestrians using patterns of motion and appearance // Int. J. Comput. Vis. 2005. Vol. 63, № 2. P. 153–161. [30],
- Moutarde F., Stanciulescu B., Breheret A. Real-time visual detection of vehicles and pedestrians with new efficient adaBoost features // 2008 IEEE International Conference on Intelligent RObots Systems (IROS 2008). 2008. [33]
- Chen S., Hsieh J. Boosted road sign detection and recognition // 2008 Int. Conf. Mach. Learn. Cybern. 2008. № July. P. 3823–3826. [36]
- Freund Y., Schapire R.E. A decision-theoretic generalization of on-line learning and an application to boosting // Journal of Computer and System Sciences, № 55. Issue 1, August 1997, P. 119-139
- Papageorgiou C.P., Oren M., Poggio T. A general framework for object detection // Sixth Int. Conf. Comput. Vis. IEEE Cat No98CH36271. 1998. Vol. 6, № January. P. 555–562 [47]
- Crow F.C. Summed-area tables for texture mapping // ACM SIGGRAPH Computer Graphics. 1984. Vol. 18, № 3. P. 207–212 [49]
- Ким А.К., Бычков И.Н. и др. Российские технологии “Эльбрус” для персональных компьютеров, серверов и суперкомпьютеров // Современные информационные технологии и ИТ-образование, М.: Фонд содействия развитию интернет-медиа, ИТ-образования, человеческого потенциала "Лига интернет-медиа", 2014, № 10. 39-50.
- Ким А. К., Перекатов В. И., Ермаков С. Г. Микропроцессоры и вычислительные комплексы семейства «Эльбрус». — СПб.: Питер, 2013. — 272 С.
- Ишин П.А., Логинов В.Е., Васильев П.П. Ускорение вычислений с использованием высокопроизводительных математических и мультимедийных библиотек для архитектуры Эльбрус // Вестник воздушно-космической обороны, М.: Научно-производственное объединение "Алмаз" им. акад. А.А. Расплетина, 2015, № 4 (8). 64-68.
Комментарии (7)

fitbikeco
26.10.2017 11:00подсветка лиц в метро + мат. методы + эльбрус + 1984 + 1937

imaxai
26.10.2017 12:56уважаемого комментатора прошу дать ответ про то что есть сейчас:
если в этой схеме сейчас стоит Интел и известно, что вся техника Интел (АМД) может выдавать искаженный результат, путем внесения изменений удаленно со стороны разработчика платформы и когда захотят, допустим, в этой схеме стереть (исказить) все изображения. и пострадают невиновные люди. эта цена лучше, на ваш взгляд? лучше, когда, условно, одной кнопкой можно вырубить ПК во всех, скажем, паспортных столах? это, на ваш взгляд, лучше для безопасности государства и каждого отдельного гражданина? если вы с этим согласны, то вы действуете против интересов каждого отдельного гражданина РФ. но по секректу открою тайну, что что камер стоит больше наблюдений именно в «демократических» странах. удивительно, да? а казалось: надо просто подумать…Disasm
26.10.2017 13:55и известно, что вся техника Интел (АМД) может выдавать искаженный результат, путем внесения изменений удаленно со стороны разработчика платформы и когда захотят, допустим, в этой схеме стереть (исказить) все изображения
Простите, кому это известно? По-моему теория заговора в чистом виде.
erwins22
26.10.2017 14:01В Великобритании давно наступил…
Смотрю как тысячами переплывают через Ламанш, многие тонут…
Или людям вообще наплевать на слежку и они мирно работают?
imaxai
samodum
я даже удивлён, как школьники-первонахи прошли на хабр.
По статье. У метода Виолы-Джонса, скажем, для
распознаваниядетектирования лиц или номеров автомобилей, нужна определённая последовательность фич (features) или это нет так? То есть, порядок следования фич влияет на результат?SmartEngines Автор
По методу Виолы и Джонса детектор (классификатор) представляется в виде каскада сильных классификаторов. Каждый сильный классификатор состоит из слабых классификаторов. Каждый слабый классификатор базируется на одной фиче. Сильный классификатор — линейная комбинация слабых классификаторов, то есть при вычислении сильного классификатора порядок фич не важен.