

Для целого ряда приложений, связанных с мониторингом интернет-ресурсов и сбором статистики, актуальна задача поиска текстовой информации в сети. Для чего именно это может пригодится и как это сделать?
Если интересно, то Добро пожаловать под кат!
Яркими примерами являются задачи копирайтинга, поиск заимствований, утечек документов, в конце концов. Нужен ли для этого свой краулер или можно воспользоваться поисковиками? В ходе решения этого вопроса возникла идея написать “краулер для краулера”, другими словами, сбор данных с поисковиков по заданному запросу.
Первый резонный вопрос: почему не использовать штатное API поисковика? Если мы используем только один поисковик, то можно и API, но для этого надо будет следить за его изменениями и править свой код. Мы же решили сделать универсальный механизм: заменив XPath в настройках, можно настроиться на работу с любыми поисковыми системами (но не ограничиваться ими). Разумеется, пришлось предусмотреть работу со списком прокси, чтобы, во-первых, не забанили, а, во-вторых, чтобы можно было получать поисковую выдачу для разных регионов (по geoIP используемого прокси).
При построении структуры приложения был сделан шаг в сторону кросс-платформенной разработки, с использованием микросервисной архитектуры на основе docker контейнеров.
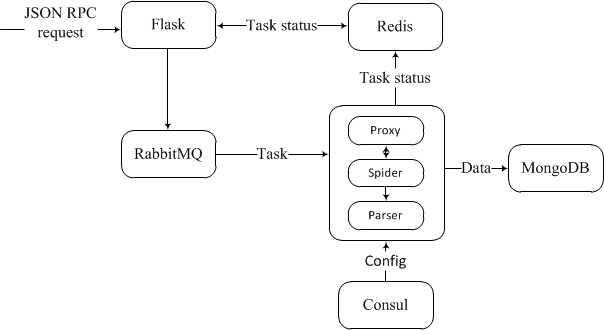
Схема работы приложения предельно проста: интерфейс взаимодействия с системой реализован на flask, на вход которого ожидается запрос формата JSON-RPC, имеющий следующий вид:
requests.post('http://127.0.0.1:5000/social', json={
"jsonrpc":"2.0",
'id':123,
'method':'initialize',
'params':{
'settings':{
'searcher':'<твой любимый поисковик>',
'search_q':[
'why people hate php'
],
'count':1
}
}
})Далее инициализируется задача в очереди RabbitMQ. Когда приходит её очередь выполнения, модуль обработки задач принимает её в разработку. При выполнении процесса предоставляется актуальный proxy, создается эмулятор работы браузера.
Для чего же нам использовать ту злосчастную эмуляцию, а не использовать всеми любимый requests? Ответ прост:
- для решения проблемы с динамически подгружаемым контентом;
притворяться ужом(пользователем с реальным браузером) для отсрочки блокировки прокси.
Для этого и используется selenium webdriver, который позволяет нам получить страницу в том виде в котором ее получает пользователь в своем браузере (со всеми отработавшими скриптами и проверками), и, в случае необходимости, дает возможность имитировать действия на странице, к примеру, для получения следующей порции данных.
К счастью, в большинстве поисковых систем процесс получения следующей страницы происходит путем перехода по заранее скомпонованной ссылке, и его можно реализовать при помощи GET запросов, инкрементируя её номер.
Как только желаемая страница нами получена, дело остается за малым и его с радостью выполнит parser (с использованием сконструированного нами конфига, содержащего Xpath необходимых элементов), который, в свою очередь, отправит интересующую нас информацию в MongoDB.
На каждом этапе выполнения в Redis указывается статус обработки задачи, основываясь на ее id.
Рассмотрим возможные проблемы, с которыми мы можем столкнуться:
- Реклама в выдаче — зашумляет данные, раздувает базу;
- Сайты могут подгружать контент динамически, например, при прокручивании страницы;
- Капча — ну здесь всё очевидно.
Если же сайт маскирует рекламу среди полезного контента, то нам на помощь приходит firefox webdriver + adblock + selenium. Однако, в случае поисковиков, реклама достаточно просто выявляется при помощи XPATH и убирается из выдачи.
Итак, капча — наш злейший враг.
Распознавать её — задача нетривиальная и требует значительных ресурсов для реализации. Значит будем искать путь обхода.
И нами он был найден! Для этого мы и будем использовать прокси. Как оказалось, большая часть прокси, находящихся в открытом доступе, не позволяет обойти нашего оппонента (так как уже давно скисли и забанены), ситуация с платными прокси обстоит немного лучше, но тоже не идеальна (и все-таки дает нам лучик света в темном царстве).
Первая мысль — поиграться с user-agent. Экспериментальным путем выяснено, частая ротация user-agent лишь приближала прокси к преждевременной кончине (блокировку прокси поисковыми сервисами никто не отменял). Верным решением для продления жизни прокси оказалось включение таймаута на его использование, запросы должны идти с некоторой задержкой. Это, конечно, не панацея, но лучше, чем ничего.
Также можно использовать антикапча сервис, но это уже совсем другая история…
Как результат мы получили архитектуру и прототип системы, позволяющую производить сбор данных с поисковых и других источников.
Спасибо за внимание.
Комментарии (11)

dernasherbrezon
26.10.2017 12:42Схема работы приложения предельно проста
RabbitMQ, Consul и две базы данных не выглядит простым.
Ладно, Consul еще понятно — наверное используется для масштабирования.
Но зачем две почти одинаковые базы? Зачем RabbitMQ?
mixamax Автор
26.10.2017 12:56RabbitMQ — очередь тасков на случай, если нагрузка по запросам возрастёт. В MongoDB хранятся данные по скачанным результатам, в то время как Redis используется как кеш для сохранения статусов обратки.
dernasherbrezon
26.10.2017 17:49Вы ответили на вопрос "что они делают?", но не "зачем они там?".
mixamax Автор
26.10.2017 22:53Про rabbit написано выше. Redis используется, чтобы не дёргать лишний раз основную БД. Конечно, можно всё реализовать через MongoDB в т.ч. и очередь, но лучше использовать инструменты, предназначенные для этих целей.

ilyaplot
26.10.2017 14:12включение таймаута на его использование, запросы должны идти с некоторой задержкой
Были в моей практике серверы, которые выдавали бан на основе анализа таймаута между запросами. Теперь я всегда устанавливаю рандомный таймаут.
Еще один прием — обязательно передаю HTTP referer. В больщинстве случаев он должен быть известен, но я не думаю, что кто-то заморачивался с проверками его корректности. Он просто должен быть.
Так же, я встречал системы, которые используют mousmove для проверки на ботов. Приходилось эмулировать запросы подобных скриптов на сервер, которые отрабатывали в течение 10-20 секунд после скачивания страницы.mixamax Автор
26.10.2017 15:13Про рандомный таймаут — да, это полезное дополнение. Если говорить про заголовки HTTP, тот тут уже не только referer, лучше на этапе анализа ресурсов изучить запросы и передаваемые хедеры. В некоторых случаях оказывается, что требуется нечто большее…
Анализ поведения пользователя на сайте (mousemove и подобные) по большей части появляется в задачах связанных с накруткой активности/просмотров. В этом случае надо уже придумывать более сложные механизмы и сценарии поведения, но это уже другая задача.

vtulin
27.10.2017 17:30Наверное правильнее всё же назвать «Парсер для краулера», он же у вас не убегает за пределы поисковиков. Или я не догнал? Вон тот «Spider» в центре это кто такой?
mixamax Автор
27.10.2017 22:51На текущий момент не убегает, в дальнейшем предполагается нарастить этот функционал. Тот «Spider», который в центре отвечает за переход между страницами выдачи и скачивание их.
kruslan
Вместо прокси лучше тор.
mixamax Автор
Пробовали. Тор быстро блокировался. Да и скорость тора несколько ниже.
kruslan
Ну у нас обратный опыт ;)